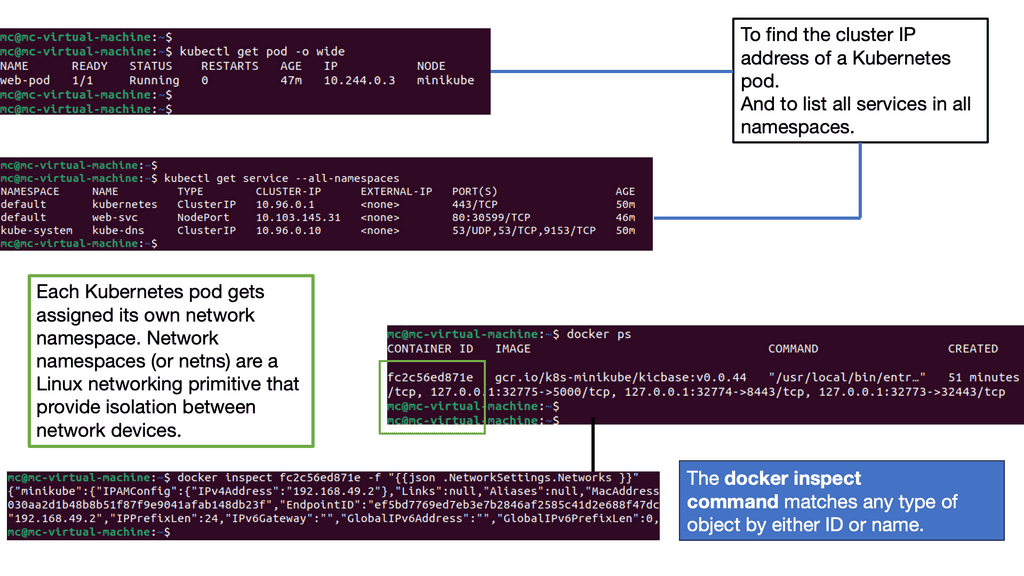
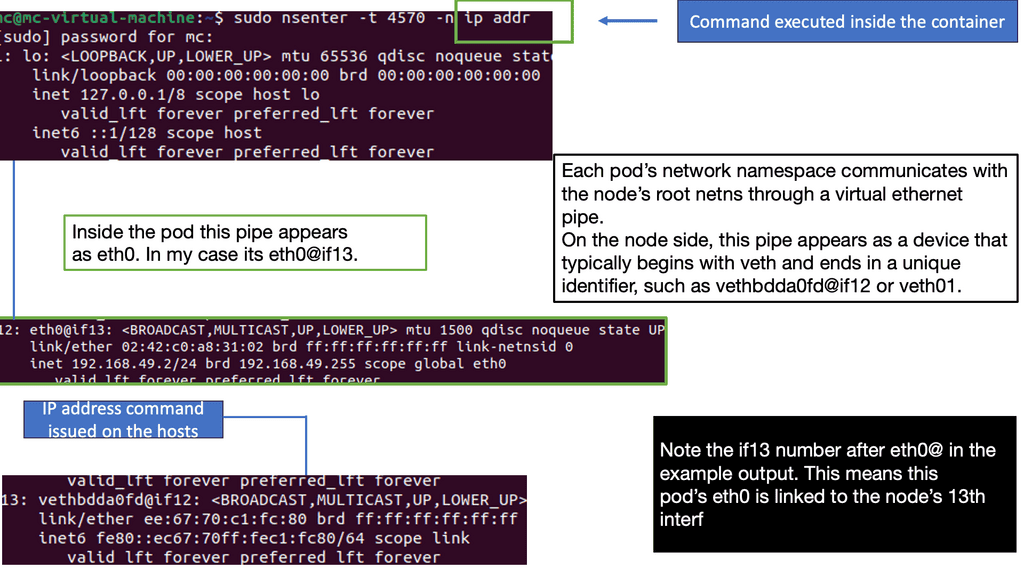
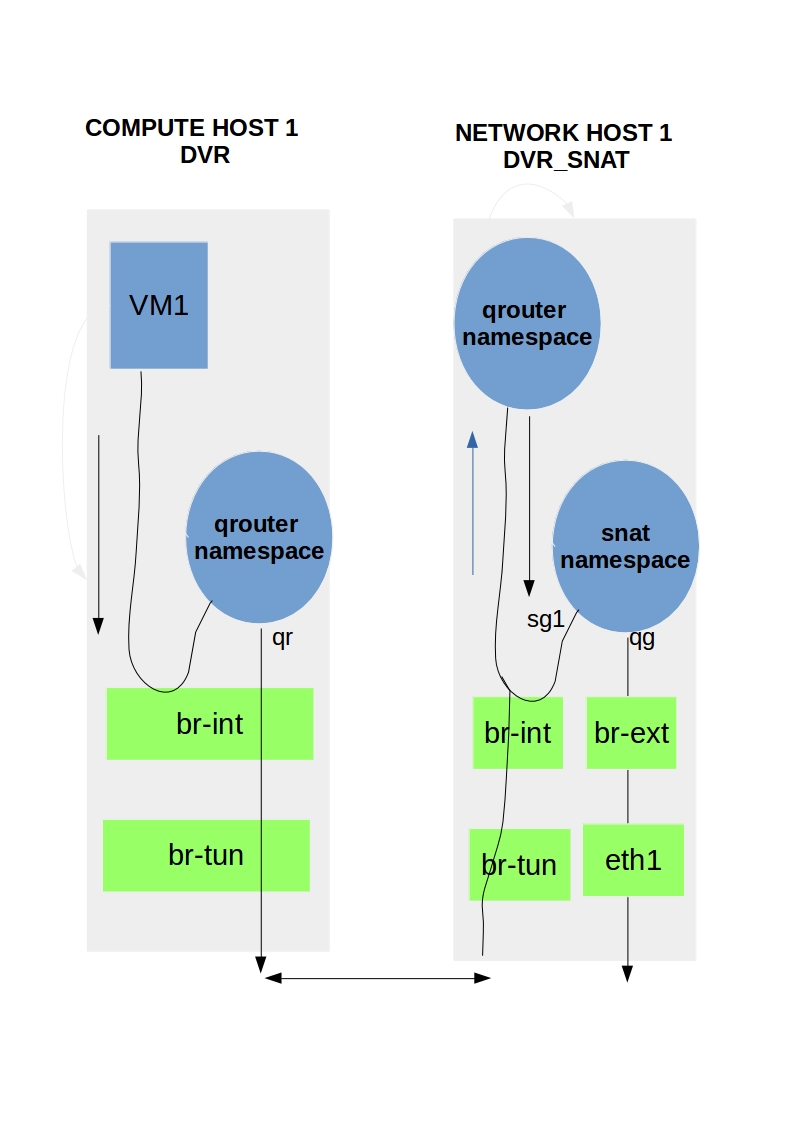
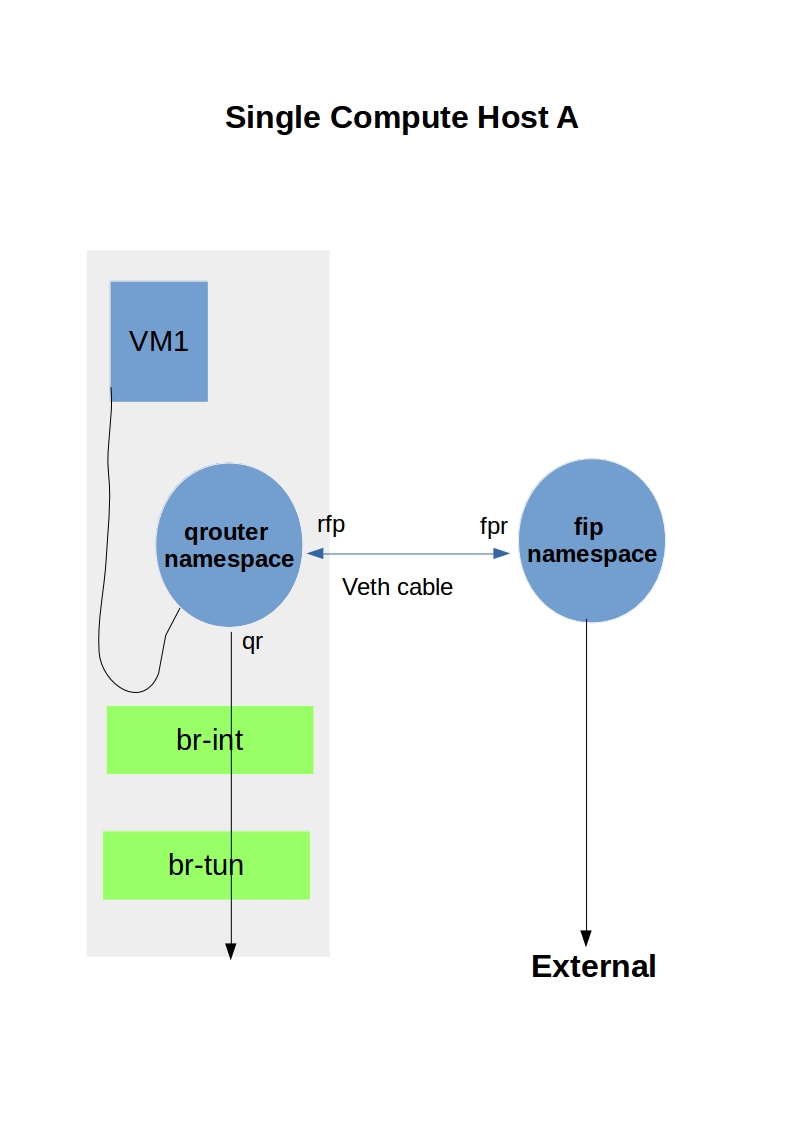
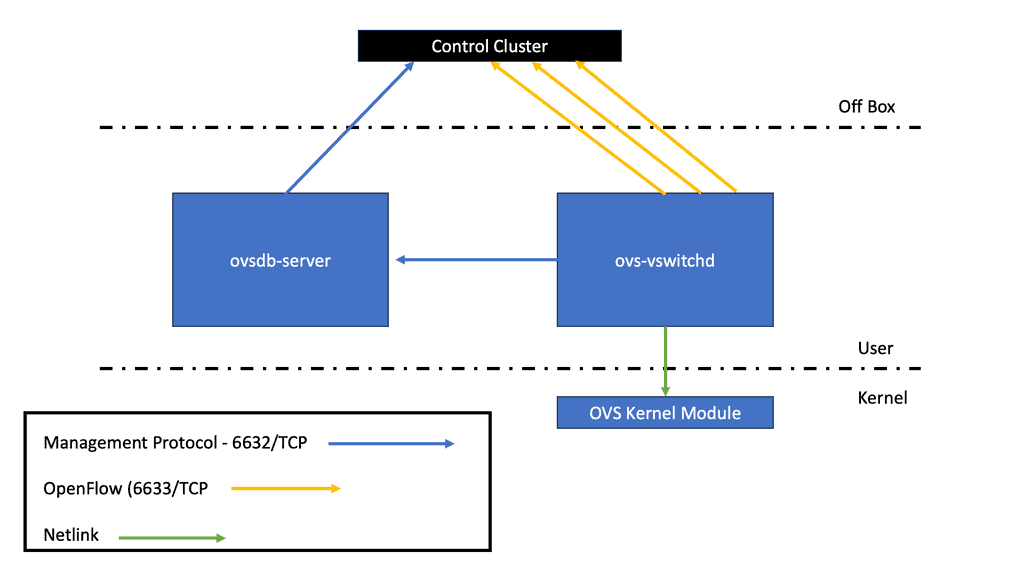
Wireless Communication Protocol
– 6LoWPAN, at its core, is a wireless communication protocol that enables the transmission of IPv6 packets over low-power and constrained networks. It leverages the power of IPv6 to provide unique addresses to each device, facilitating seamless connectivity and interoperability. With its efficient compression techniques, 6LoWPAN optimizes data transmission, making it suitable for resource-constrained devices and networks.
– The adoption of 6LoWPAN brings forth a multitude of benefits. Firstly, it enables the integration of a vast number of devices into the IoT ecosystem, creating a rich network of interconnected systems. Additionally, 6LoWPAN’s low-power characteristics make it ideal for battery-operated devices, extending their lifespan. Moreover, its compatibility with IPv6 ensures scalability and future-proofing, allowing for easy integration with existing infrastructure.
– 6LoWPAN finds its applications in various domains, ranging from smart homes and industrial automation to healthcare and agriculture. In smart homes, 6LoWPAN enables seamless communication between different devices, enabling automation and enhanced user experiences. Similarly, in industrial automation, 6LoWPAN plays a vital role in connecting sensors and actuators, enabling real-time monitoring and control. In healthcare, 6LoWPAN facilitates the deployment of wearable devices and remote patient monitoring systems, improving healthcare outcomes.
– While 6LoWPAN has immense potential, it also faces certain challenges. The limited bandwidth and range of low-power networks can pose constraints on data transmission and coverage. Interoperability between different 6LoWPAN implementations also needs to be addressed to ensure seamless communication across various systems. However, ongoing research and development efforts aim to overcome these challenges and further enhance the capabilities of 6LoWPAN.
Key Point: IPv6 and IoT
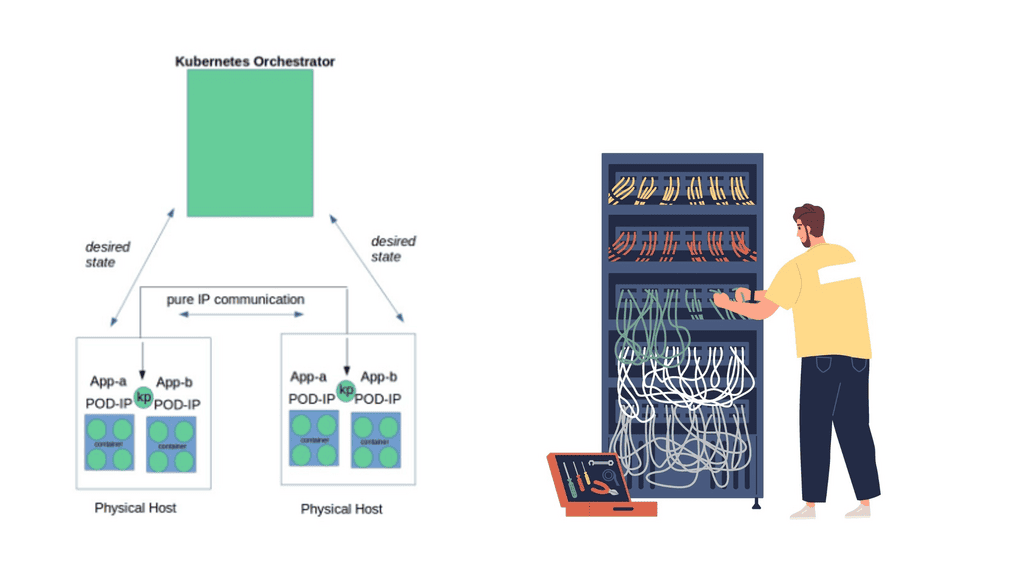
An IPv6 protocol called 6LoWPAN extends IPv6 to low-power personal area networks. Wireless Personal Area Networks, or WPANs, are the target of this protocol. WPANs are wireless personal area networks (PANs) that connect devices in a person’s workspace. IPv6 is supported by 6LoWPAN. IPv6, or Internet Protocol Version 6, enables communication over the Internet. Besides providing a large number of addresses, it is also faster and more reliable.
6LoWPAN was initially designed to replace conventional methods of transmitting information. However, due to its limited processing capabilities, IPv6 is not efficient. It only enables smaller devices with minimal processing capabilities to communicate. Furthermore, it has a low bit rate, a short range, and a memory requirement. Edge routers and sensor nodes make up the system. Almost any IoT device, such as streetlights with LEDs, can now connect to the network and transmit data, such as streetlights with LEDs, for instance.
6LoWPAN’s key Features and Applications
One of 6LoWPAN’s key features is its ability to compress IPv6 packets, reducing their size and conserving valuable network resources. This compression technique allows IoT devices with limited resources, such as low-power sensors, to operate efficiently within the network. Additionally, 6LoWPAN supports mesh networking, enabling devices to relay data for improved coverage and network resilience. With its lightweight nature and adaptability, 6LoWPAN provides a cost-effective and scalable solution for IoT connectivity.
6LoWPAN’s applications are vast and diverse. Its low power consumption and support for IPv6 make it particularly suitable for smart home automation systems, where numerous IoT devices need to communicate with each other seamlessly. Furthermore, 6LoWPAN finds applications in industrial settings, enabling efficient monitoring and control of various processes. From healthcare and agriculture to transportation and environmental monitoring, 6LoWPAN empowers many IoT applications.
**The Role of Connectivity Requirements**
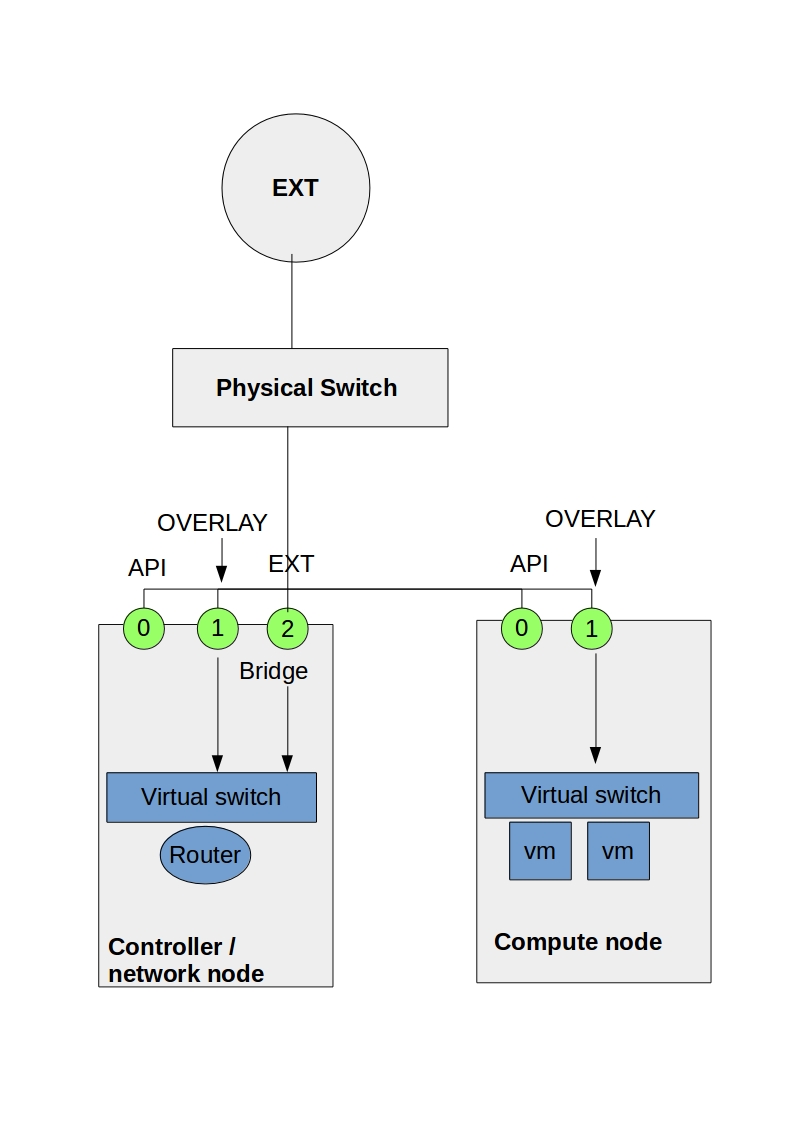
Consistent connectivity with Internet of Things access technologies locally among IoT things and to remote cloud or on-premise IoT platforms requires having the correct type of network infrastructure that suits the characteristics of IoT devices. It is expensive, and we are seeing short-range Low-Power and long-range Low-Power networks deployment in the IoT world. 6LoWPAN IoT, IPv6, and 6LoWPAN range compression and IPv6 fragmentation techniques enable IP on even the smallest devices, offering direct IP addressing and a NAT-free world.
**New Design Approaches**
Depending on device requirements and characteristics, the Internet of Things networking design might consist of several “type” centric design approaches. For example, we can select thing-centric, gateway-centric, smartphone-centric, and cloud-centric designs based on IoT device requirements.
If slow and expensive satellite links result in a thing-centric design, some processing may need to be performed locally. Other device types require local gateway support, while others communicate directly to the IoT platform.
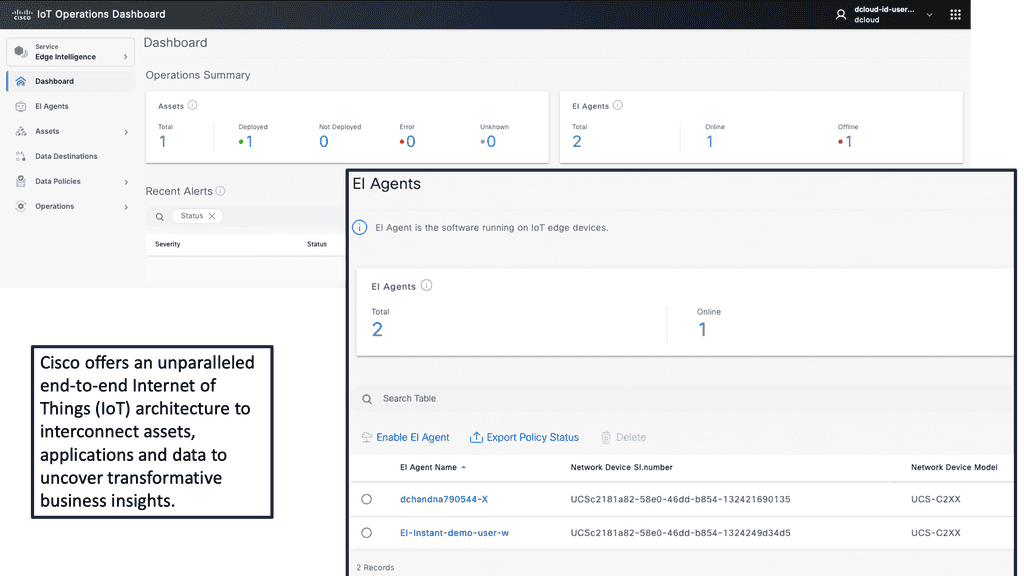
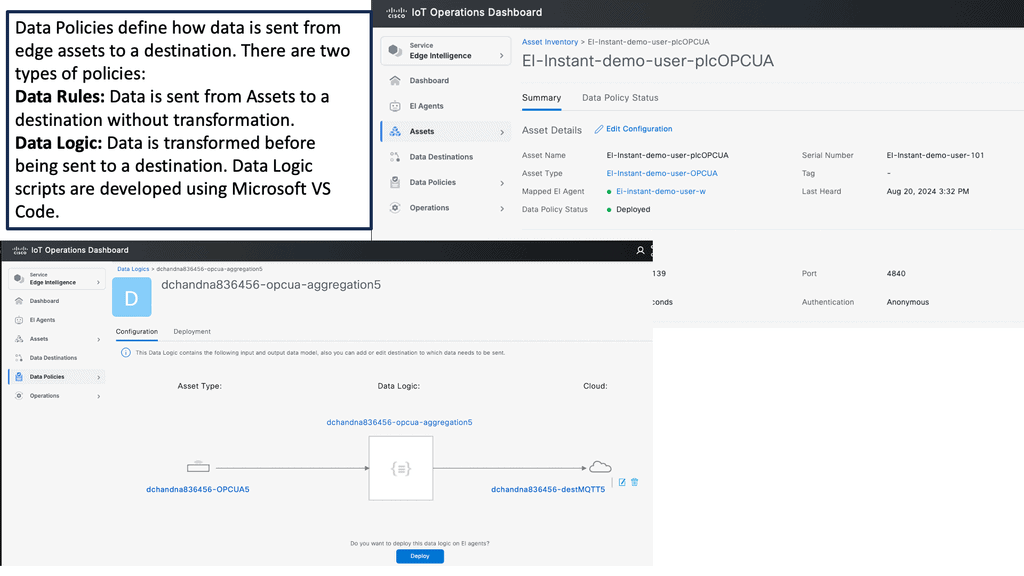
Example Product: Cisco IoT Operations Dashboard
### Introduction to Cisco IoT Operations Dashboard
In an era where the Internet of Things (IoT) is revolutionizing industries, the Cisco IoT Operations Dashboard stands out as a crucial tool for managing and optimizing IoT deployments. This powerful platform offers real-time insights, enhanced security, and streamlined operations, making it indispensable for businesses looking to harness the full potential of their IoT solutions.
### Real-Time Monitoring and Insights
One of the standout features of the Cisco IoT Operations Dashboard is its ability to provide real-time monitoring and insights. With this tool, businesses can keep an eye on their IoT devices and networks around the clock. This continuous monitoring allows for immediate detection of issues, enabling swift responses that minimize downtime and maintain operational efficiency. The dashboard presents data in an intuitive and accessible format, making it easier for teams to stay informed and make data-driven decisions.
### Enhanced Security for IoT Deployments
Security is a paramount concern in the world of IoT, where devices are often spread across various locations and networks. The Cisco IoT Operations Dashboard addresses this challenge by offering robust security features. It includes advanced threat detection and response capabilities, ensuring that any potential vulnerabilities are quickly identified and mitigated. This proactive approach to security helps protect sensitive data and maintain the integrity of IoT systems, giving businesses peace of mind.
### Streamlined Operations and Management
Managing a large number of IoT devices can be a daunting task. The Cisco IoT Operations Dashboard simplifies this process by providing a centralized platform for device management. Whether it’s onboarding new devices, updating software, or configuring settings, the dashboard makes these tasks straightforward and efficient. This streamlining of operations not only saves time but also reduces the risk of errors, leading to smoother and more reliable IoT deployments.
### Scalability and Flexibility
As businesses grow and their IoT needs evolve, scalability becomes a critical factor. The Cisco IoT Operations Dashboard is designed with scalability in mind, allowing companies to easily expand their IoT deployments without compromising performance. Additionally, the platform’s flexibility means it can be tailored to meet the specific needs of various industries, from manufacturing to healthcare. This adaptability ensures that businesses can continue to leverage the dashboard’s capabilities as their IoT initiatives mature.
Before you proceed, you may find the following helpful post for pre-information:
The two dominant modern network architectures are cloud computing and the Internet of Things (IoT), sometimes called fog computing. The future of the Internet will involve many IoT objects that use standard communications architectures to provide services to end users.
Tens of billions of such devices are envisioned to be interconnected. This will introduce interactions between the physical world and computing, digital content, analysis, applications, and services. The resulting networking paradigm is called the Internet of Things (IoT).
Factors Influencing 6LoWPAN Range:
a) Transmission Power: The transmission power of a 6LoWPAN device plays a significant role in determining its range. Higher transmission power allows devices to communicate over considerable distances and consumes more energy, impacting battery life.
b) Environment: The physical environment in which 6LoWPAN devices operate can affect their effective range. Obstacles such as walls, buildings, and interference from other wireless devices can attenuate the signal strength, reducing the range.
c) Antenna Design: The design and placement of antennas in 6LoWPAN devices can impact their range. Optimized antenna designs can enhance signal propagation and improve the network’s overall range.
Extending 6LoWPAN Range:
While 6LoWPAN networks have a limited range by design, there are several techniques to extend their coverage:
a) Mesh Topology: Implementing a mesh topology allows devices to relay messages to each other, expanding the network’s coverage. By relaying packets, devices can communicate beyond their direct range, effectively extending the overall range of the network.
b) Signal Amplification: Using signal amplification techniques, such as increasing the transmission power or employing external amplifiers, can boost the signal strength and extend the range of 6LoWPAN devices.
c) Repeater Nodes: Deploying additional repeater nodes within the network can help bridge communication gaps and extend the range. These nodes receive and retransmit packets, allowing devices to communicate with each other even when they are out of direct range.
Considerations for 6LoWPAN Range Optimization:
To optimize the range of a 6LoWPAN network, it is essential to consider the following factors:
a) Power Consumption: Increasing the transmission power to extend the range can lead to higher power consumption. Balancing range and power efficiency is essential to ensure optimal device performance and battery life.
b) Network Density: The number of devices within a 6LoWPAN network can impact the overall range. Higher device density may require additional repeater nodes or signal amplification to maintain effective communication across the network.
c) Environmental Constraints: Understanding the physical environment and any potential obstacles is crucial for optimizing the range of a 6LoWPAN network. Conducting site surveys and considering the placement of devices and repeaters can significantly enhance network coverage.
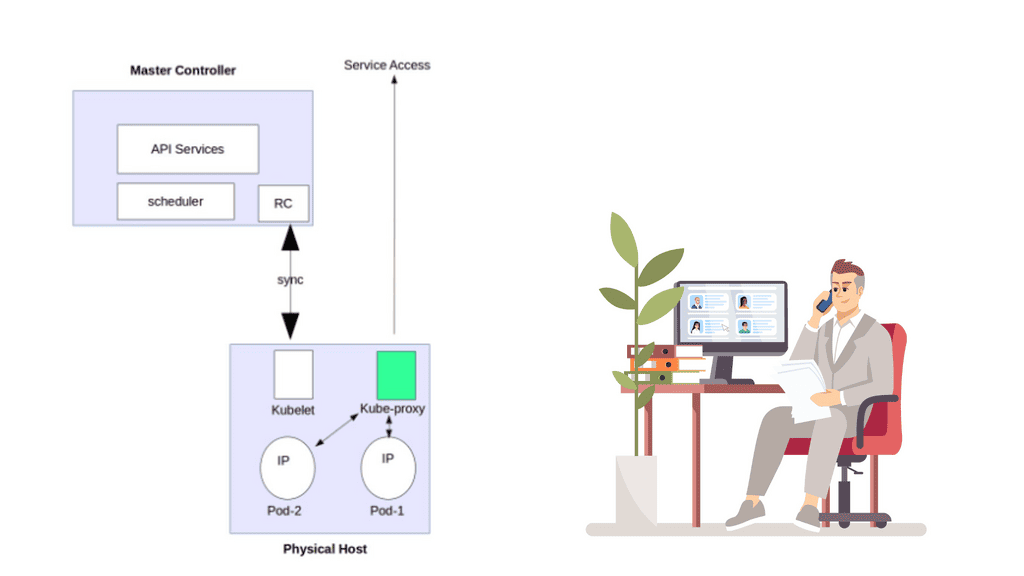
**6LoWPAN Range: IoT Networking**
The Internet of Things networking design is device-type-driven and depends on the devices’ memory and processing power. These devices drive a new network paradigm, a paradigm no longer well-defined with boundaries. It is dynamic and extended to the edge where IoT devices are located. It is no longer static, as some of these devices and sensors move and sleep as required.
There are many factors to consider when selecting wireless infrastructure. It would be best if you took into consideration
- Range,
- Power consumption and battery life,
- Data requirements,
- Security, and
- Endpoint and operational costs of IoT devices.
These characteristics will dictate the type of network and may even result in a combination of technologies.
Similar to how applications drive the network design in a non-IoT network, the IoT device and the application it serves drive the network design in the IoT atmosphere.
Cellular connectivity is the most widely deployed network. Still, the Internet of Things networking is expensive per node and has poor battery life as there will be way more IoT endpoints than cellular phones. New types of networks are needed.
Cellular networks are not agile enough, and provisioning takes ages. Smart IoT devices require more signaling than what traditional cellular networks are used to carrying. Devices require bi-directional signaling between each other or remote servers, which needs to be reliable. Reach is also a challenge when connecting far-flung IoT devices.
- Two types of networks are commonly deployed in the IoT world: short-range Low-Power and long-range Low-Power networks.
Internet of Things networking: Short-range low-power
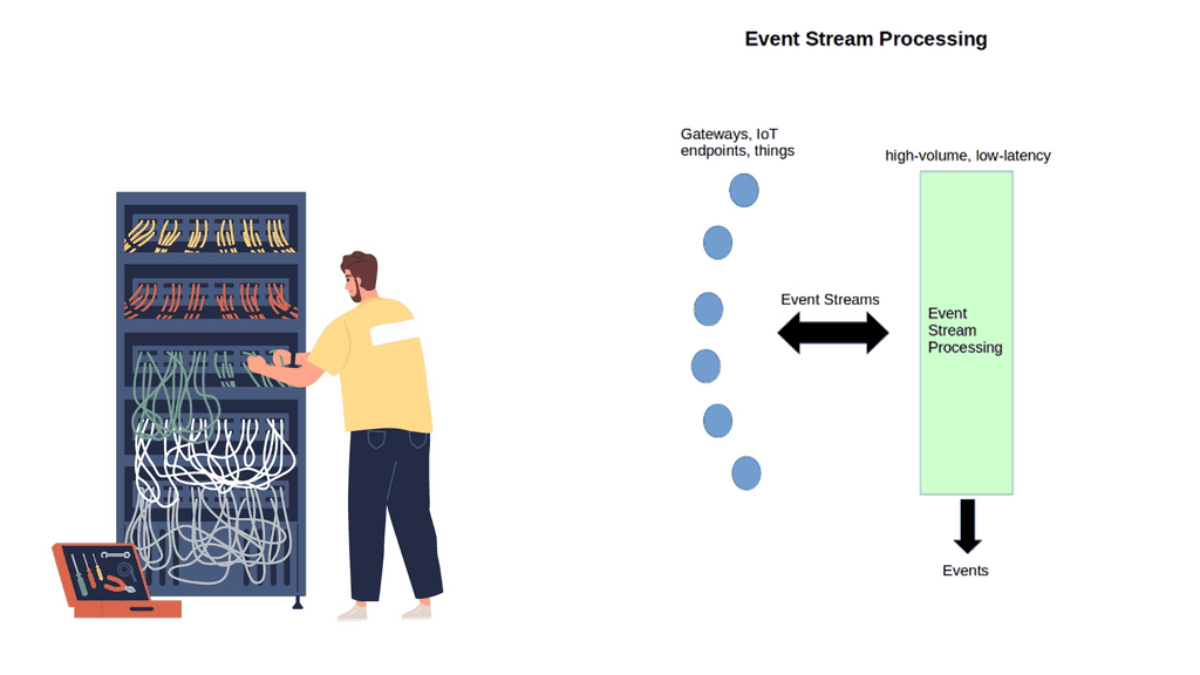
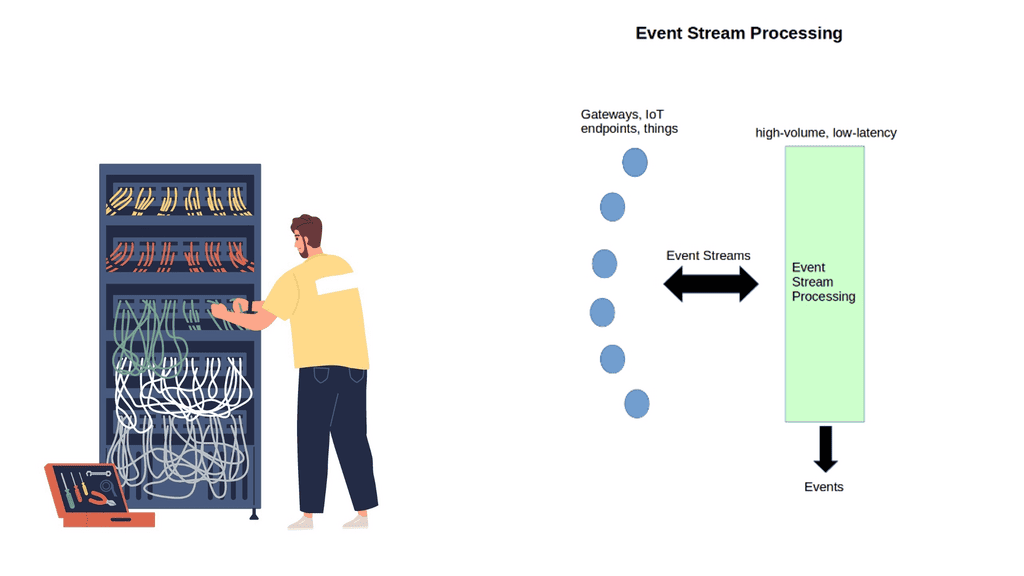
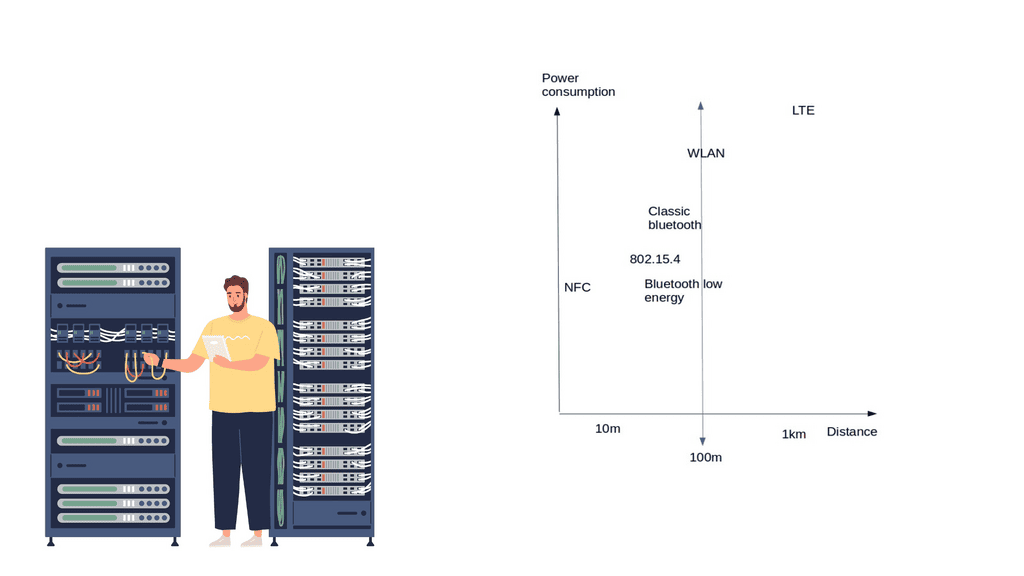
New devices, data types, and traffic profiles result in new access networks for the “last 100 meters of connectivity”. As a result, we see the introduction of many different types of technologies at this layer – Z-Wave, ZigBee, Bluetooth, IEEE 802.15.4, 6LoWPAN Range, RFID, Edge, and Near Field Communication ( NFC ).
Devices that live on short-range networks have particular characteristics:
- Low cost.
- With low power consumption, energy is potentially harvested from another power source.
- It is short-range and has the potential for extension with a router or repeater.
These networks usually offer a range of around 10 – 100 meters, 5 – 10 years of battery life, low bandwidth requirements, and low endpoint costs. Potentially consist of 100 – 150 adjacent devices, usually deployed in the smart home/office space.
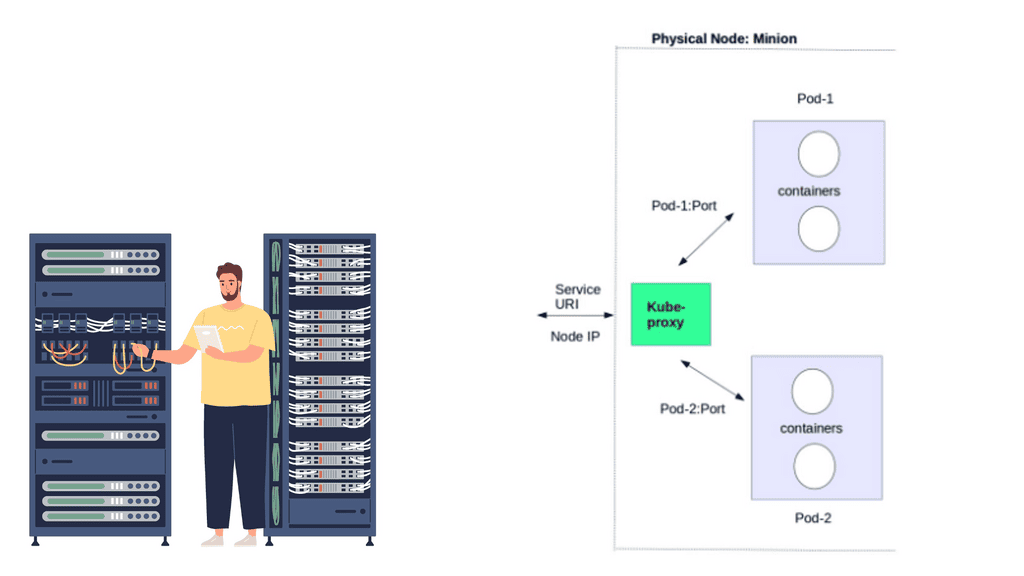
The topologies include point-to-point, star, and mesh. A gateway device usually acts as a bridge or interface linking the outside network to the internal short-range network. A gateway could be as simple as a smartphone or mobile device. For example, a smartphone could be the temporary gateway when it approaches the sensor or device in an access control system.
Short-range low-power technologies
- Bluetooth low energy ( BLE ) or Bluetooth smart
Bluetooth Smart has the most extensive ecosystem with widespread smartphone integration. It fits into many sectors, including home and building, health and fitness, security, and remote control. Most smart devices, including adult toys, use Bluetooth technology.
That being said, when using Bluetooth technology, there is always a risk of being targeted by hackers. In recent years, more and more people have started to worry about Bluetooth toys getting hacked.
Nonetheless, as long as people take necessary precautions, their chances of getting hacked are relatively low. Moreover, Bluetooth has the potential for less power consumption than IEEE 802.15.4 and looks strong as a leader in the last 100 meters.
Recently, with Bluetooth 4.2, BLE devices can directly access the Internet with 6LoWPAN IoT. It has a similar range to Classic Bluetooth and additional functionality to reduce power consumption. In addition, BLE is reliable because of its support for adaptive frequency hopping ( AFH ).
The data rate and range depict whether you can use BLE or not. If your application sends small chunks of data, you’re fine, but if you want to send large file transfers, you should look for an alternative technology. The range is suited for 50 – 150 meters, and the max data rate is 1 Mbps.
6LoWPAN IoT
6LoWPAN Range: IEEE 802.15.4 wireless
IEEE 802.15.4 will be the niche wireless technology of the future. It already has an established home and building automation base—the IEEE 802.15.4 market targets small battery-powered devices that wake up for some time and return to sleep. IEEE 802.15.4 consists of low-bit, low-power, and low-cost endpoints. The main emphasis is on low-cost communication between nearby devices.
It is only the physical and MAC layers and doesn’t provide anything on top of that. This is where, for example, ZigBee and 6LoWPAN IoT come into play. Specifications such as 6LoWPAN IoT and ZigBee are built on the IEEE 802.15.4 standard and add additional functionality to the upper layers. 15.4 has simple addressing with no routing. It has star and peer-to-peer topologies. Mesh topologies are supported, but you must add layers not defined by default in IEEE.
ZigBee
ZigBee is suited for applications with infrequent data transfers of around 250 kbps and a low range between 10 – 100m. It’s a very low-cost and straightforward network compared to Bluetooth and Wi-Fi. However, it is a proprietary solution, and there is no ZigBee support for the Linux kernel, resulting in a significant performance hit for userspace interaction.
This is one of the reasons why the 6LoWPAN range would be a better option, which also runs on top of IEEE 802.15.4. NFC ( Near Field Communication ) has low power but is very short-range, enabling a simple 2-way interaction. An example would be a contactless payment transaction. WLAN (Wi-Fi) has a large ecosystem but high power consumption.
Low-power wide-area network (LPWAN) or low-power network (LPN)
BLE, ZigBee, and Wi-Fi are not designed for long-range performance, and traditional Cellular networks are costly and consume much power. On the other hand, power networks are a class of wireless networks consisting of constrained devices that process power, memory, and battery life. The battery’s length depends on the power consumption, and low power consumption enables devices to last up to 10 years on a battery.
Receiver Sensitivity
When a device transmits a signal, it needs energy from the receiving side to detect it. As always, a certain amount of power is lost during transmission. One of the reasons for LPWAN’s long reach is high receiver sensitivity. Receiver sensitivities in LPWAN operate at -130 dBm; typically, in other wireless technologies, this would be 90 – 110 dBm. Receiver sensitivity operating at -130 can detect 10,000 times quicker than at -90.
It offers long-range communication at a meager bit rate. LPWAN has a much longer range than Wi-Fi and is more cost-effective than cellular networks. Each node can be up to 10 km from the gateway. Data rates are low. Usually, only 20 – 256 bytes per message are sent daily.
These networks are optimized for specific types of data transfers consisting of small, intermittent data blocks. Not all IoT applications transmit large amounts of data. For example, a parking garage sensor only transmits when a parking space is occupied or empty. Devices within these networks are generally cheap at £5 per module and optimized for low throughput.
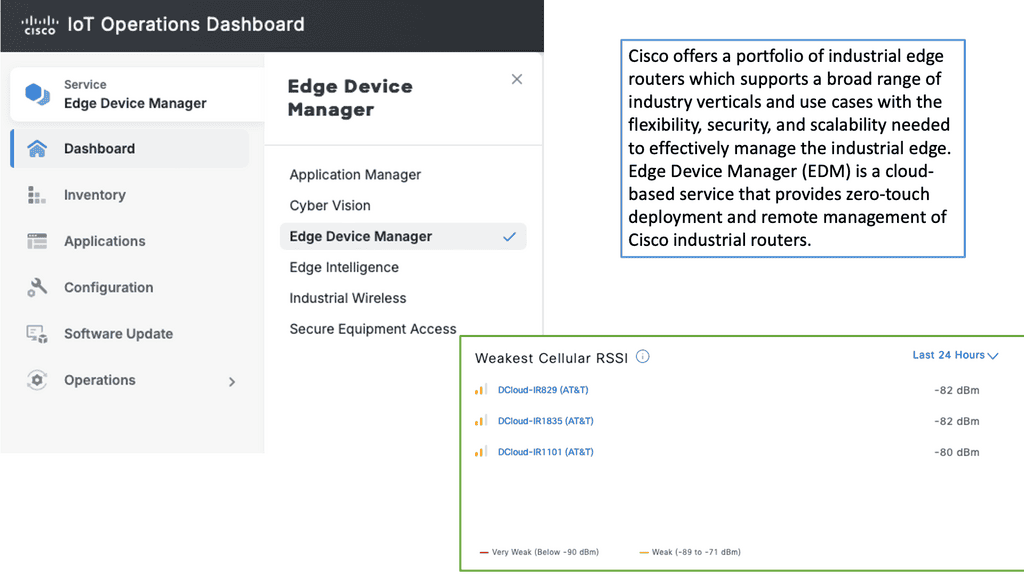
Example Product: Cisco Edge Device Manager
**Understanding Cisco Edge Device Manager**
Cisco Edge Device Manager is a robust solution that provides centralized management for edge devices connected to your network. It offers a user-friendly interface that allows administrators to monitor, configure, and troubleshoot devices remotely. This means less time spent on manual configurations and more time focusing on strategic initiatives. Key features include real-time monitoring, automated updates, and secure connectivity, all designed to ensure your edge devices operate efficiently and securely.
**Seamless Integration with Cisco IoT Operations Dashboard**
One of the standout features of Cisco Edge Device Manager is its seamless integration with the Cisco IoT Operations Dashboard. This integration allows for a holistic view of your IoT ecosystem, providing valuable insights into device performance and network health. The dashboard offers advanced analytics, alerting systems, and reporting tools that help you make data-driven decisions. By combining these two powerful tools, businesses can achieve greater operational efficiency and improved device management.
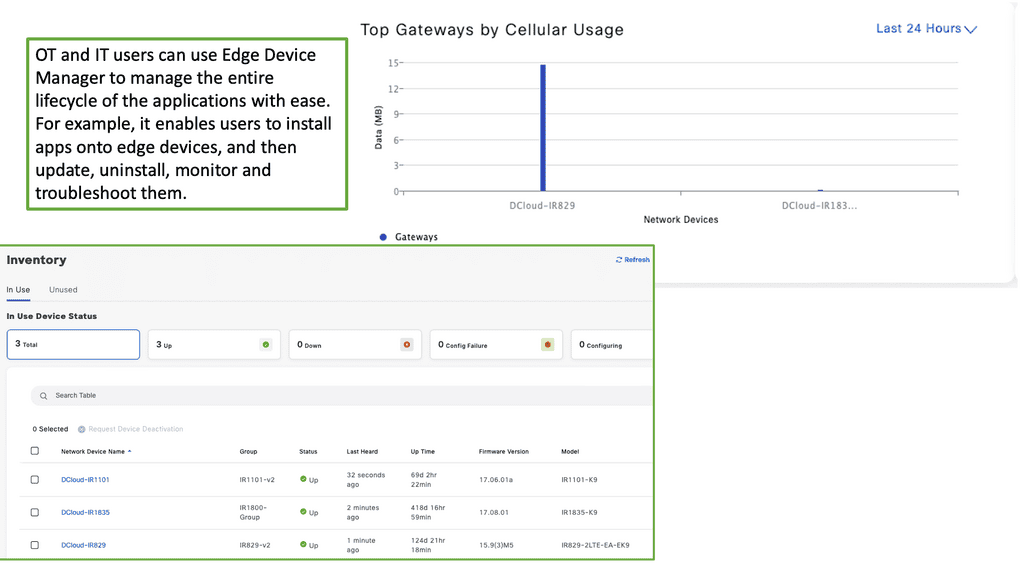
**Key Benefits of Using Cisco Edge Device Manager**
1. **Enhanced Visibility**: Gain real-time insights into the status and performance of your edge devices, allowing for proactive management and swift issue resolution.
2. **Increased Security**: With built-in security features, Cisco Edge Device Manager ensures that your devices and data remain protected from cyber threats.
3. **Scalability**: As your IoT network grows, Cisco Edge Device Manager scales with it, accommodating an increasing number of devices without compromising performance.
4. **Cost Efficiency**: Reduce operational costs by automating routine tasks and minimizing the need for on-site maintenance.
**Practical Applications**
Cisco Edge Device Manager is not just a tool for IT departments; it has practical applications across various industries. For example, in manufacturing, it can monitor and manage IoT-enabled machinery to optimize production lines. In retail, it can ensure that connected devices, such as smart shelves and digital signage, operate seamlessly. In healthcare, it can manage medical IoT devices to ensure patient safety and operational efficiency. The versatility of Cisco Edge Device Manager makes it a valuable asset for any organization leveraging IoT technology.
IPv6 and IoT
All the emerging IoT standards are moving towards IPv6 and 6LoWPAN IoT. There is a considerable adoption of IPv6 in the last mile of connectivity. Deploying IPv6 brings many benefits. However, take note of IPv6 attacks. It overcomes problems with NAT, providing proper end-to-end connectivity and directly addressing end hosts. It has mobility support and stateless address autoconfiguration.
The fundamental problem with NAT is performance. Performance gets very painful when everything is NAT’d for an IoT device to be contacted from the outside. NAT also breaks flexibility in networking as an IoT device can only be accessed if it first contacts.
This breaks proper end-to-end connectivity, and sharing IoT infrastructure among providers is challenging. We need a NAT-free, scalable network that IPv4 cannot offer, a solution that does not require gateways or translation devices and only adds to network complexity.
It’s far better to use IPv6 and 6LowPANn IoT than proprietary protocols. It’s proven to work, and we have much operational experience. With 6LoWPAN, IPv6 can be compressed into a couple of bytes of data, which is helpful for small and power-constrained devices.
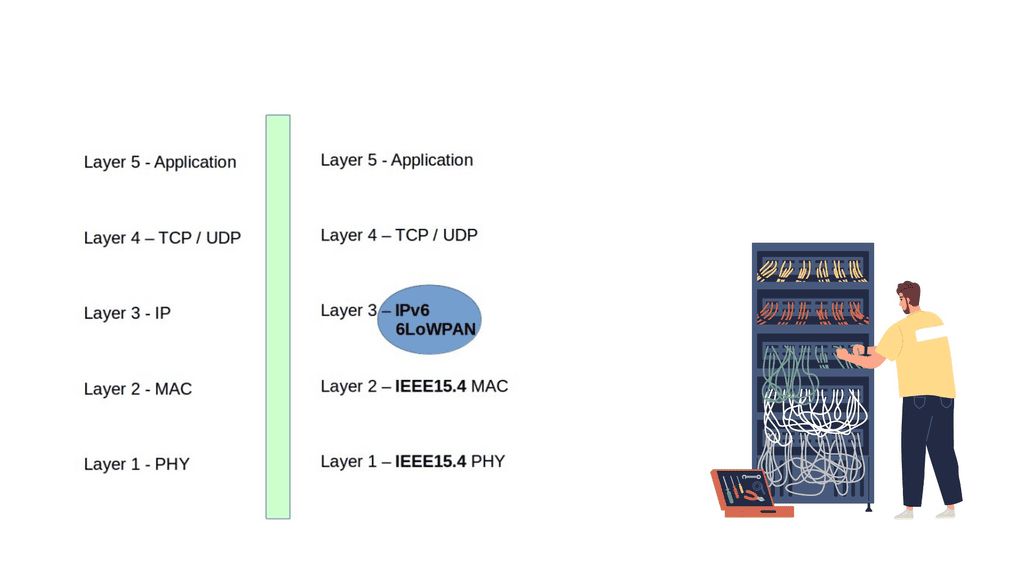
6LoWPAN Range on IEEE 802.15.4 networks
6LoWPAN is all about transmitting IP over IEEE 802.15.4 networks. As the name suggests, its IPv6 over LoWPAN ( IEEE 802.15.4 ) enables IP to be used on the smallest devices. Rather than using an IoT application protocol like Bluetooth and ZigBee, 6LoWPAN IoT is a network layer protocol with frequency band and physical layer freedom. It’s suitable for small nodes ( 10 kilobytes of RAM ) and sensor networks for machine-to-machine communication.
15.4 has four types of frames 1) Beacon, 2) MAC command, 3) ACK, and 4) Data – this is where the IPv6 RA packets must be carried.
6LoWPAN is an adaption layer between the data link and network layer ( RFC 4944 ). It becomes part of the network layer. So, instead of using IPv6 natively on the MAC layer, they have a shim layer that adapts between the data and network layer. As a network layer protocol, it doesn’t provide any functionality above layer 3. As a result, it is often used in conjunction with Constrained Application protocols ( CoAP ) and MQTT ( machine-to-machine (M2M)/”Internet of Things ) protocols.
6LoWPAN Range: Header compression and fragmentation
IPv6 allows a maximum packet size of 1280 bytes. However, the maximum transfer size 802.15.4 is a 127-byte MTU, meaning a complete IPv6 packet does not fit in a 15.4 frame. By default, a 127-byte 15.4 frame only leaves 33 bytes for the payload. This small frame-size support is one of the reasons why deploying a full IP stack would be challenging. A couple of things must be done to make this work and compliant with IPv6 standards. To use IPv6, we need to adjust header overhead and adaptations for MTU size.
The first thing we must do is bring fragmentation back to IPv6. To allow such packets, we define a fragmentation scheme. The 11-bit fragmentation header allows for a 2048-byte packet size with fragmentation. However, many tables in the IPv6 header are static, and you might not need them. So, the version will always be 0, and so will the traffic class and flow label.
Finally, for the Internet of Things networking, remember that the entire TCP/IP stack is not one size fits all and would certainly reach hardware limitations on small devices. It’s better to use UDP ( DTLS ) instead of TCP. Packet loss on the lossy network may invoke additional latencies while TCP carries out retransmissions. You can still use TCP, but it won’t be optimized, and the headers will not be compressed.
6LoWPAN technology offers a low-power and cost-effective solution for IoT deployments. By understanding the factors influencing its range, implementing range-extending techniques, and optimizing network parameters, organizations can ensure reliable connectivity and seamless communication within their IoT ecosystems. As the IoT landscape continues to evolve, 6LoWPAN will remain a vital connectivity option, enabling innovative applications and driving the growth of the IoT industry.