
Understanding Docker Security
The Importance of Container Security
As the use of Docker containers grows, so does the potential attack surface. Containers are often deployed in large numbers, and any vulnerability can lead to significant breaches. Understanding the importance of container security is the first step in defending your applications. Ensuring that your containers are secure helps protect sensitive data, maintain application integrity, and uphold your organization’s reputation.
Docker provides numerous security features, such as isolated containers, resource limitations, and image signing. However, misconfigurations or overlooking certain best practices can leave Docker environments vulnerable to potential threats.Understanding the fundamentals of Docker security is essential to ensure a strong security foundation.
Containerization offers process-level isolation, which enhances security by preventing application conflicts and limiting the potential impact of vulnerabilities. Docker achieves this isolation through the use of namespaces and control groups.
**Docker Container Security: Best Practices and Strategies**
### Understanding Docker and Its Popularity
Docker has revolutionized the way we think about software deployment and scalability. By packaging applications and their dependencies into containers, developers can ensure consistency across various environments. This portability is a primary reason for Docker’s widespread adoption in the tech industry. However, with great power comes great responsibility, and securing these containers is crucial for maintaining the integrity and reliability of applications.
### The Importance of Container Security
As the use of Docker containers grows, so does the potential attack surface. Containers are often deployed in large numbers, and any vulnerability can lead to significant breaches. Understanding the importance of container security is the first step in defending your applications. Ensuring that your containers are secure helps protect sensitive data, maintain application integrity, and uphold your organization’s reputation.
### Best Practices for Securing Docker Containers
1. **Use Official and Trusted Images**: Always start with images from trusted sources, such as Docker Hub’s official repository. These images are maintained and updated regularly, reducing the risk of vulnerabilities.
2. **Regularly Update and Patch**: Just as with any software, keeping your container images up to date is crucial. Regular updates and patches can fix known vulnerabilities and improve overall security.
3. **Limit Container Privileges**: Containers should run with the least privileges necessary. Avoid running containers as the root user and apply the principle of least privilege to minimize potential damage from an attack.
4. **Implement Network Segmentation**: Isolate your containers by using Docker’s network features. This segmentation limits communication to only what is necessary, reducing the risk of lateral movement by attackers.
5. **Monitor and Log Activity**: Continuous monitoring and logging of container activity can help detect unusual patterns or potential breaches. Tools like Docker Security Scanning and third-party solutions can provide insights into container behavior.
Example: Container segmentation
Containers can be part of two networks. Consider the bridge network a standard switch, except it is virtual. Anything attached can communicate. So, if we have a container with two virtual ethernet cards connected to two different switches, the container is in two networks.
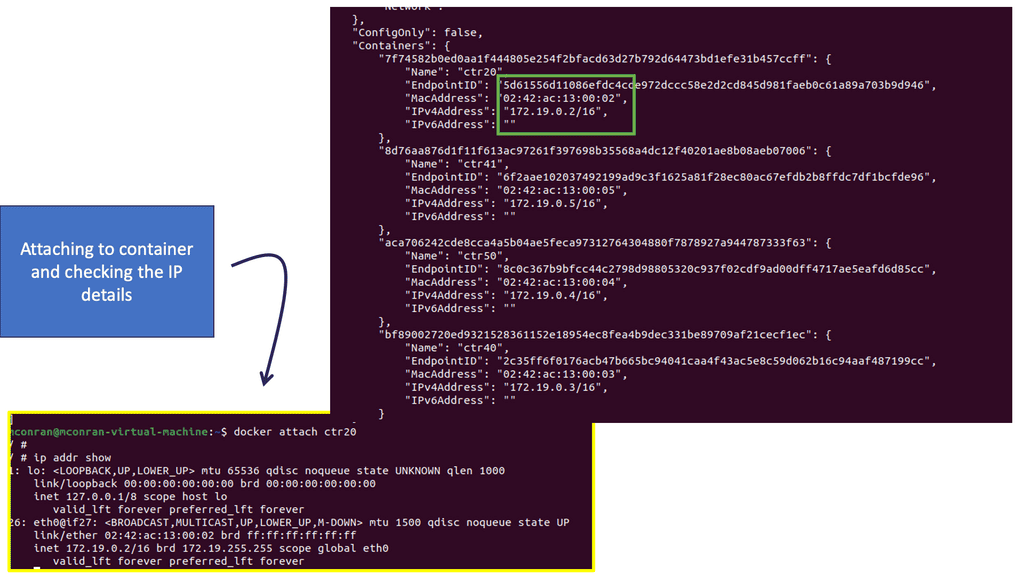
Personal Note: Docker Security Vendors
In addition to docker security best practices that we will dicuss soon, leveraging modern tools and technologies can significantly enhance Docker container security. Security solutions such as Aqua Security, Sysdig Secure, and Twistlock offer advanced features like vulnerability scanning, runtime defense, and compliance checks. Incorporating these tools into your security strategy can provide an added layer of protection against sophisticated threats.
Docker Security Key Points
-Building your Docker images on a solid foundation is crucial for container security. Employing secure image practices includes regularly updating base images, minimizing the software installed within the container, and scanning images for vulnerabilities using tools like Docker Security Scanning.
-Controlling access to Docker containers is vital in maintaining their security. This involves utilizing user namespaces, restricting container capabilities, and employing role-based access control (RBAC) to limit privileges and prevent unauthorized access.
-Keeping a close eye on container activities is essential for identifying potential security breaches. Implementing centralized logging and monitoring solutions helps track and analyze container events, enabling timely detection and response to any suspicious or malicious activities.
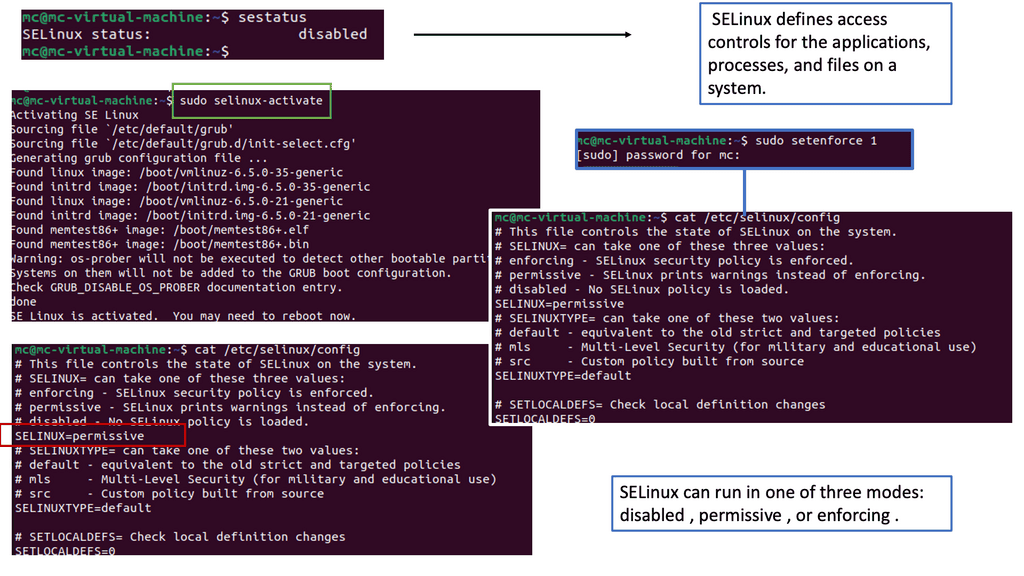
Docker offers numerous security features, such as isolation, resource management, and process restrictions. However, these features alone may not provide sufficient protection against sophisticated attacks. That’s where SELinux steps in.
A. SELinux: Security Framework
SELinux is a security framework integrated into the Linux kernel. It provides an additional layer of access control policies, enforcing mandatory access controls (MAC) beyond the traditional discretionary access controls (DAC). By leveraging SELinux, administrators can define fine-grained policies that govern processes’ behavior and limit their access to critical resources.
Docker has built-in support for SELinux, allowing users to enable and enforce SELinux policies on containers and their underlying hosts. By enforcing SELinux policies, containers are further isolated from the host system, reducing the potential impact of a compromised container on the overall infrastructure.
B. Namespaces and Control Groups
The building blocks for Docker security options and implementing Docker security best practices, such as the Kernel primitives, have been around for a long time, so they are not all new when considering their security. However, the container itself is not a kernel construct; it is an abstraction of using features of the host operating system kernel. For Docker container security and building a Docker sandbox, these kernel primitives are the namespaces and control groups that allow the abstraction of the container.
-Namespaces provide processes with isolated instances of various system resources. They allow for resource virtualization, ensuring that processes within one namespace cannot interfere with processes in another. Namespaces provide separation at different levels, such as mount points, network interfaces, process IDs, and more. By doing so, they enable enhanced resource utilization and security.
-Control groups, called cgroups, allow for resource limitation, prioritization, and monitoring. They allow administrators to allocate resources, such as CPU, memory, disk I/O, and network bandwidth, to specific groups of processes. Control groups ensure fair distribution of resources among different applications or users, preventing resource hogging and improving overall system performance.
Namespaces and control groups offer a wide range of applications and benefits. In containerization technologies like Docker, namespaces provide the foundation for creating isolated environments, allowing multiple containers to run on a single host without interference. Control groups, on the other hand, enable fine-grained resource control and optimization within these containers, ensuring fair resource allocation and preventing resource contention.
C. The Role of Kernel Primitives
To build a docker sandbox, Docker uses control groups to control workloads’ resources to host resources. As a result, Docker allows you to implement system controls with these container workloads quickly. Fortunately, much of the control group complexity is hidden behind the Docker API, making containers and Container Networking much easier to use.
Then, we have namespaces that control what a container can see. A namespace allows us to take an O/S with all its resources, such as filesystems, and carve it into virtual operating systems called containers. Namespaces are like visual boundaries, and there are several different namespaces.
Example Techniques: Docker Bench Security
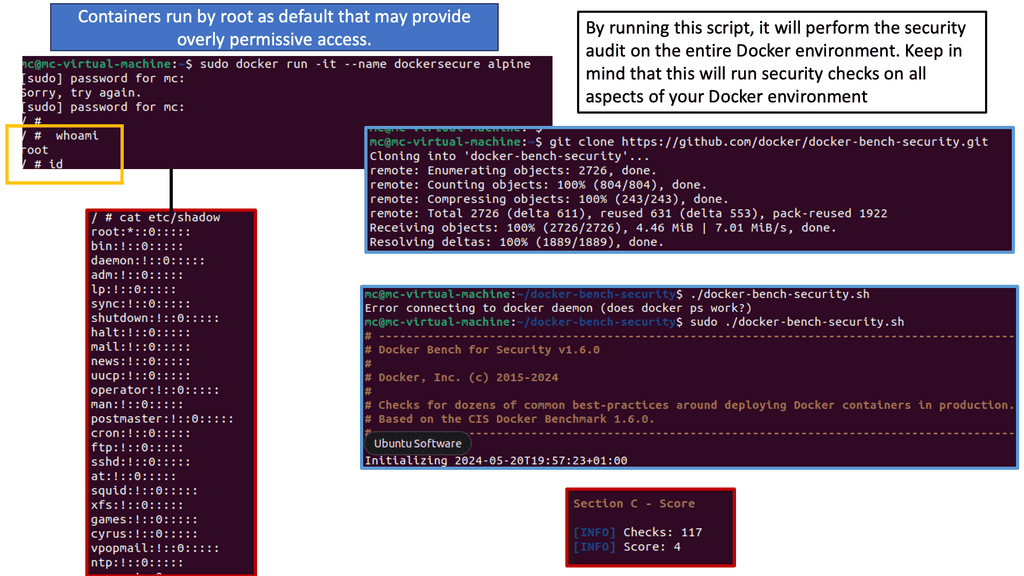
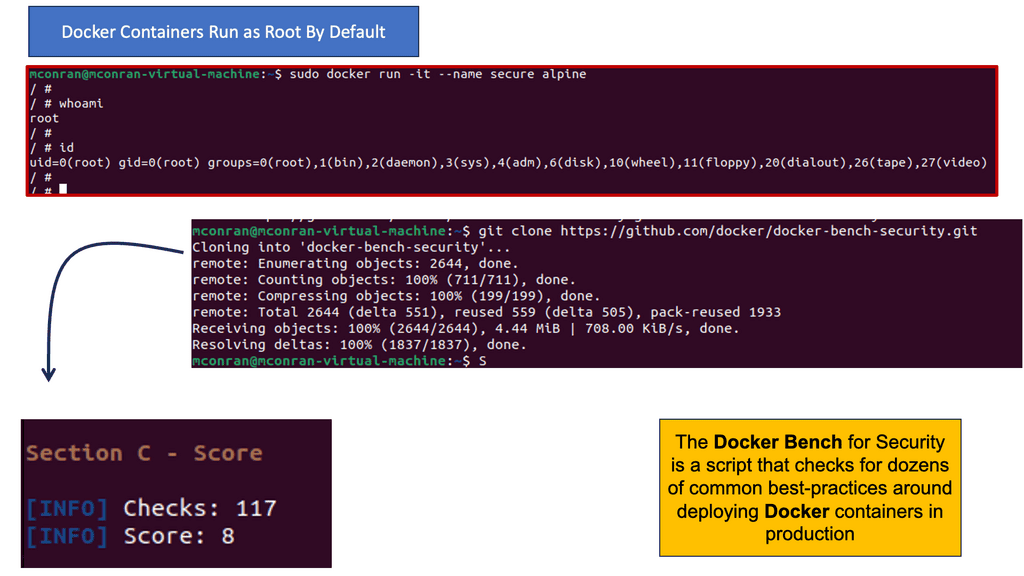
Docker Bench is an open-source tool developed by Docker, Inc. It aims to provide a standardized way of assessing Docker security configurations. By running Docker Bench, we can identify security weaknesses, misconfigurations, and potential vulnerabilities in our Docker setup. The tool provides a comprehensive checklist based on industry best practices, including security recommendations from Docker themselves.
To enhance Docker security using Docker Bench, we must follow a few simple steps. First, we need to install Docker Bench on our host machine. Once installed, we can execute the tool to assess our Docker environment. Docker Bench will evaluate various aspects, such as Docker daemon configuration, host security settings, container configurations, and more. It will then provide a detailed report highlighting areas requiring attention.
Privilege Escalation: The Importance of a Sandbox
During an attack, your initial entry point into a Linux system is via a low-privileged account, which provides you with a low-privileged shell. To obtain root-level access, you need to escalate your privileges. This is generally done by starting with enumeration.
Sometimes, your target machine may have misconfigurations that you could leverage to escalate your privileges. Here, we will look for misconfigurations, particularly those that leverage the SUID (Set User Identification) permission.
The SUID permission allows low-privileged users to run an executable with the file system permissions of its owner. For example, if the system installs an executable globally, that executable would run as root.
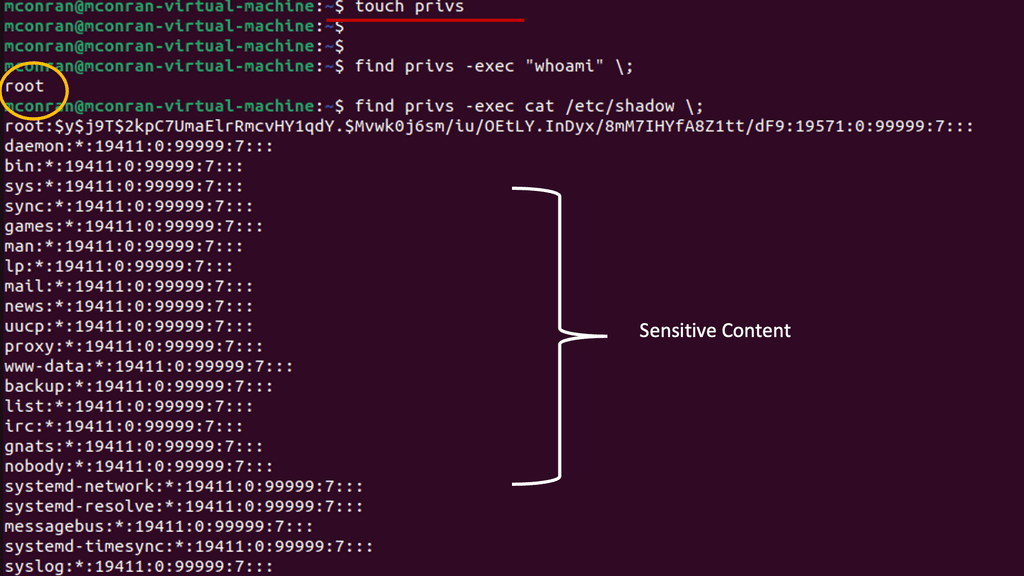
Note: A quick way to find all executables with SUID permission is to execute the command labeled Number 1 in the screenshot below. I’m just running Ubuntu on a VM. To illustrate how the SUID permission can be abused for privilege escalation, you will use the found executable labeled number 2.
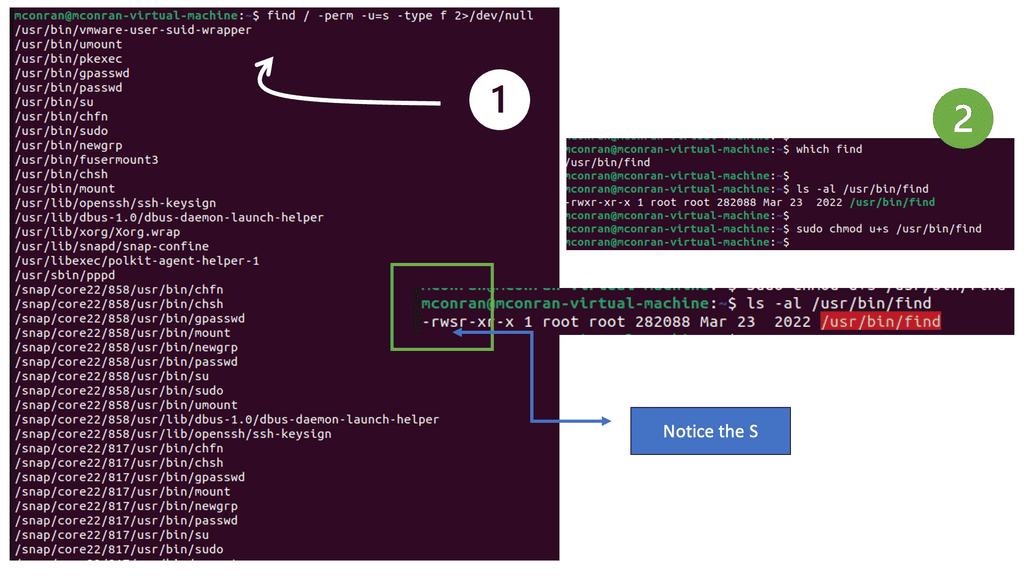
Analysis:
- After setting the SUID permission, re-run the command to find all executables. You will see /usr/bin/find now appears in the list.
- Since find has the SUID permission, you can leverage it to execute commands in the root context.
- You should now see the contents of the /etc/shadow file. This file is not visible without root permissions. You can leverage additional commands to execute more tasks and gain a high-privilege backdoor from here.
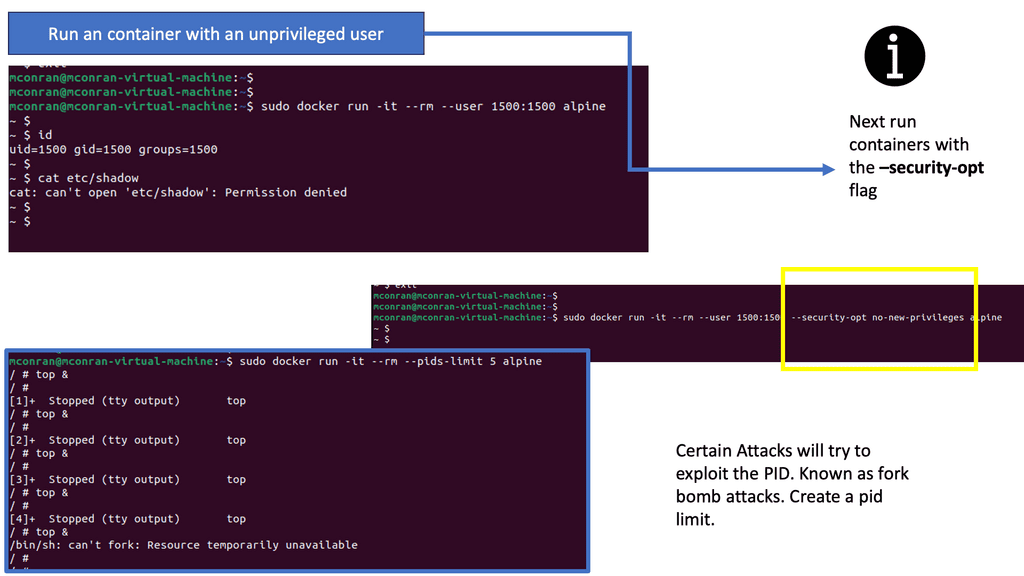
The following example shows running a container with an unprivileged user, not a root user. Therefore, we are not roots inside the container. With this example, we are using user ID 1500. Notice how we can’t access the /etc/shadow password file, which is a file that needs root privileges to open. To mitigate the risks associated with running containers as root, organizations should adopt the following best practices:
Proactive Measures to Mitigate Privilege Escalation:
To safeguard against privilege escalation attacks, individuals and organizations should consider implementing the following measures:
1. Regular Software Updates:
Keeping operating systems, applications, and software up to date with the latest security patches helps mitigate vulnerabilities that can be exploited for privilege escalation.
2. Strong Access Controls:
Implementing robust access control mechanisms, such as the principle of least privilege, helps limit user privileges to the minimum level necessary for their tasks, reducing the potential impact of privilege escalation attacks.
3. Multi-factor Authentication:
Enforcing multi-factor authentication adds an extra layer of security, making it more difficult for attackers to gain unauthorized access even if they possess stolen credentials.
4. Security Audits and Penetration Testing:
Regular security audits and penetration testing can identify vulnerabilities and potential privilege escalation paths, allowing proactive remediation before attackers can exploit them.
**Containerized Processes**
Containers are often referred to as “containerized processes.” Essentially, a container is a Linux process running on a host machine. However, the process has a limited view of the host and can access a subtree of the filesystem. Therefore, it would be best to consider a container a process with a restricted view.
Namespace and resource restrictions provide the limited view offered by control groups. The inside of the container looks similar to that of a V.M. with isolated processes, networking, and file system access. However, it seems like a normal process running on the host machine from the outside.
**Container Security**
One of the leading security flaws to point out when building a docker sandbox is that containers, by default, run as root. Notice in the example below that we have a tool run on the Docker host that can perform an initial security scan – called Docker Bench. Remember that running containers as root comes with inherent security risks that organizations must consider carefully. Here are some key concerns:
Note:
1. Exploitation of Vulnerabilities: Running containers as root increases the potential impact of vulnerabilities within the container. If an attacker gains access to a container running as root, they can potentially escalate their privileges and compromise the host system.
2. Escaping Container Isolation: Containers rely on a combination of kernel namespaces, cgroups, and other isolation mechanisms to provide separation from the host and other containers. Running containers as root increases the risk of an attacker exploiting a vulnerability within the container to escape this isolation and gain unauthorized access to the host system.
3. Unauthorized System Access: If a container running as root is compromised, the attacker may gain full access to the underlying host system, potentially leading to unauthorized system modifications, data breaches, or even the compromise of other containers running on the same host.
Ensuring Kubernetes Security
As with any technology, security is paramount when it comes to Kubernetes. Securing Kubernetes clusters involves multiple layers, starting with the control plane. It’s crucial to limit access to the Kubernetes API server by implementing authentication and authorization mechanisms. Role-Based Access Control (RBAC) is a vital feature that helps define permissions for users and applications, ensuring that only authorized entities can perform specific actions.
Network policies also play a critical role in securing Kubernetes environments. By restricting communication between pods and services, network policies help mitigate the risk of unauthorized access. Additionally, regular audits and monitoring are essential to detect and respond to potential threats in real-time.


**Best Practices for Managing Kubernetes Clusters**
Effective management of Kubernetes clusters requires adherence to certain best practices. First and foremost, it’s important to keep all Kubernetes components up to date. Regular updates not only provide new features but also address security vulnerabilities.
Another best practice is to implement resource requests and limits for containers. By defining these parameters, you can ensure that applications have the necessary resources to function optimally while preventing any single application from monopolizing the cluster’s resources.
Lastly, consider using namespaces to organize resources within a cluster. Namespaces provide a way to divide cluster resources between multiple users or teams, improving resource allocation and management.

Related: For additional pre-information, you may find the following helpful.
Understanding Containers
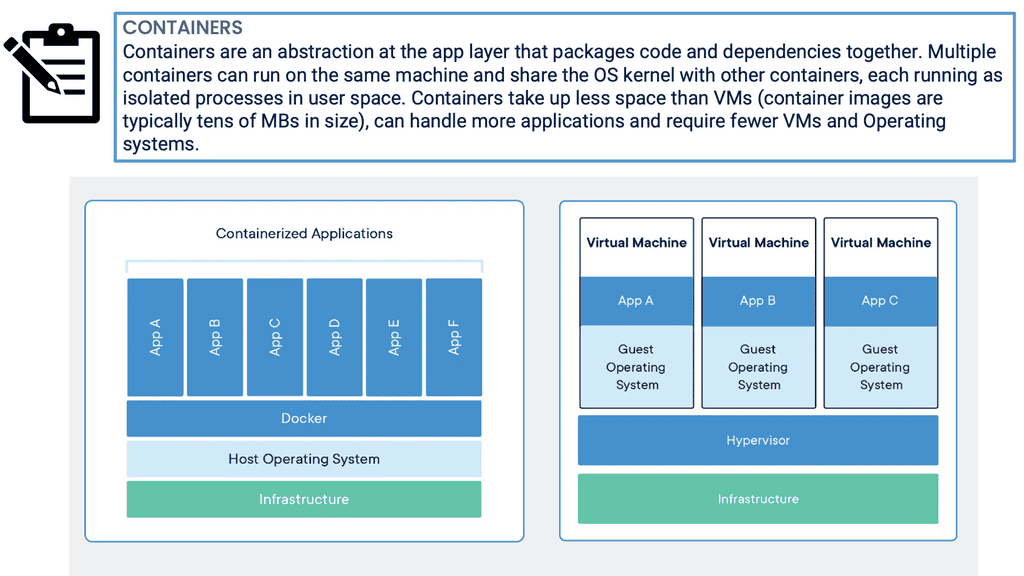
For a long time, big web-scale players have been operating container technologies to manage the weaknesses of the VM model. In the container model, the container is analogous to the VM. However, a significant difference is that containers do not require their full-blown OS. Instead, all containers operating on a single host share the host’s OS.
This frees up many system resources, such as CPU, RAM, and storage. Containers are again fast to start and ultra-portable. Consequently, moving containers with their application workloads from your laptop to the cloud and then to VMs or bare metal in your data center is a breeze.
Sandbox containers
– Sandbox containers are a virtualization technology that provides a secure environment for applications and services to run in. They are lightweight, isolated environments that run applications and services safely without impacting the underlying host.
– This virtualization technology enables rapid application deployment while providing a secure environment to isolate, monitor, and control access to data and resources. Sandbox containers are becoming increasingly popular as they offer an easy, cost-effective way to securely deploy and manage applications and services.
– Sandbox containers can also be used for testing, providing a safe and isolated environment for running experiments. In addition, they are highly scalable and can quickly and easily deploy applications across multiple machines. This makes them ideal for large-scale projects, as they can quickly deploy and manage applications on a large scale. The following figures provide information that is generic to sandbox containers.
Benefits of Using a Docker Sandbox:
1. Replicating Production Environment: A Docker sandbox allows developers to create a replica of the production environment. This ensures the application runs consistently across different environments, reducing the chances of unexpected issues when the code is deployed.
2. Isolated Development Environment: With Docker, developers can create a self-contained environment with all the necessary dependencies. This eliminates the hassle of manually setting up development environments and ensures team consistency.
3. Fast and Easy Testing: Docker sandboxes simplify testing applications in different scenarios. By creating multiple sandboxes, developers can test various configurations, such as different operating systems, libraries, or databases, without interfering with each other.

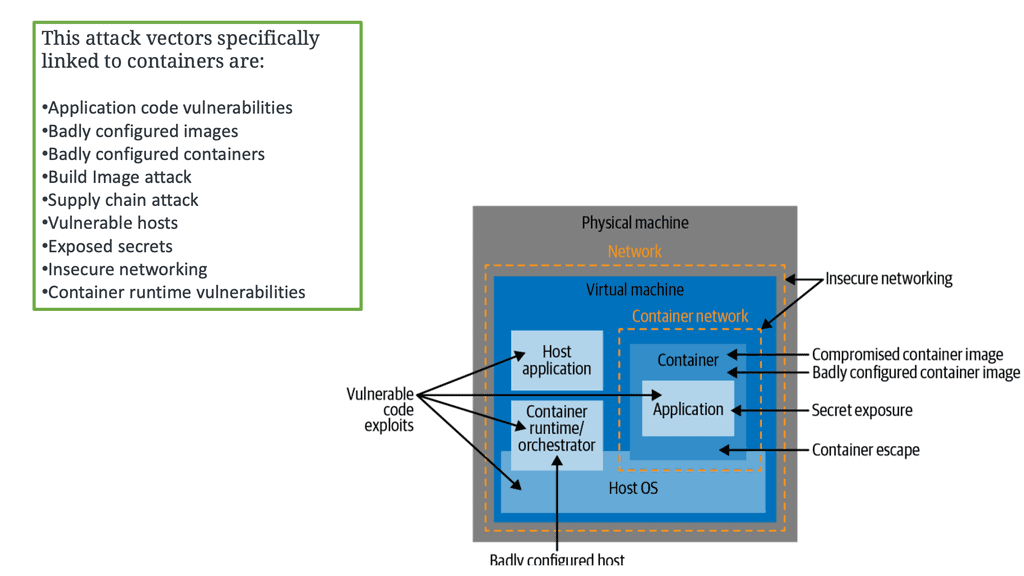
Understanding the Risks: Docker containers present unique security challenges that must be addressed. We will delve into the potential risks associated with containerization, including container breakouts, image vulnerabilities, and compromised host systems.
Implementing Container Isolation: One fundamental aspect of securing Docker containers is isolating them from each other and the host system. We will explore techniques such as namespace and cgroup isolation and use security profiles to strengthen container isolation and prevent unauthorized access.
Regular Image Updates and Vulnerability Scanning: Keeping your Docker images up to date is vital for maintaining a secure container environment. We will discuss the importance of regularly updating base images and utilizing vulnerability scanning tools to identify and patch potential security vulnerabilities in your container images.
Container Runtime Security: The container runtime environment plays a significant role in container security. We will explore runtime security measures such as seccomp profiles, AppArmor, and SELinux to enforce fine-grained access controls and reduce the attack surface of your Docker containers.
Monitoring and Auditing Container Activities
Effective monitoring and auditing mechanisms are essential for promptly detecting and responding to security incidents. We will explore tools and techniques for monitoring container activities, logging container events, and implementing intrusion detection systems specific to Docker containers.
**Step-by-Step Guide to Building a Docker Sandbox**
Step 1: Install Docker:
The first step is to install Docker on your machine. Docker provides installation packages for various operating systems, including Windows, macOS, and Linux. Visit the official Docker website and follow the installation instructions specific to your operating system.
Step 2: Set Up Dockerfile:
A Dockerfile is a text file that contains instructions for building a Docker image. Create a new ” Dockerfile ” file and define the base image, dependencies, and any necessary configuration. This file serves as the blueprint for your Docker sandbox.
Step 3: Build the Docker Image:
Once the Dockerfile is ready, you can build the Docker image by running the “docker build” command. This command reads the instructions from the Dockerfile and creates a reusable image that can be used to run containers.
Step 4: Create a Docker Container:
Once you have built the Docker image, you can create a container based on it. Containers are instances of Docker images that can be started, stopped, and managed. Use the “docker run” command to create a container from the image you built.
Step 5: Configure the Sandbox:
Customize the Docker container to match your requirements. This may include installing additional software, setting environment variables, or exposing ports for communication. Use the Docker container’s terminal to make these configurations.
Step 6: Test and Iterate:
Once the sandbox is configured, you can test your application within the Docker environment. Use the container’s terminal to execute commands, run tests, and verify that your application behaves as expected. If necessary, make further adjustments to the container’s configuration and iterate until you achieve the desired results.
**Docker Container Security: Building a Docker Sandbox**
So, we have some foundational docker container security that has been here for some time. A Linux side of security will give us things such as namespace, control groups we have just mentioned, secure computing (seccomp), AppArmor, and SELinux that provide isolation and resource protection. Consider these security technologies to be the first layer of security that is closer to the workload. Then, we can expand from there and create additional layers of protection, creating an in-depth defense strategy.

How to create a Docker sandbox environment
As a first layer to creating a Docker sandbox, you must consider the available security module templates. Several security modules can be implemented that can help you enable fine-grained access control or system resources hardening your containerized environment. More than likely, your distribution comes with a security model template for Docker containers, and you can use these out of the box for some use cases.
However, you may need to tailor the out-of-the-box default templates for other use cases. Templates for Secure Computing, AppArmor, and SELinux will be available. These templates, the Dockerfile, and workload best practices will give you an extra safety net.
Docker container security and protection
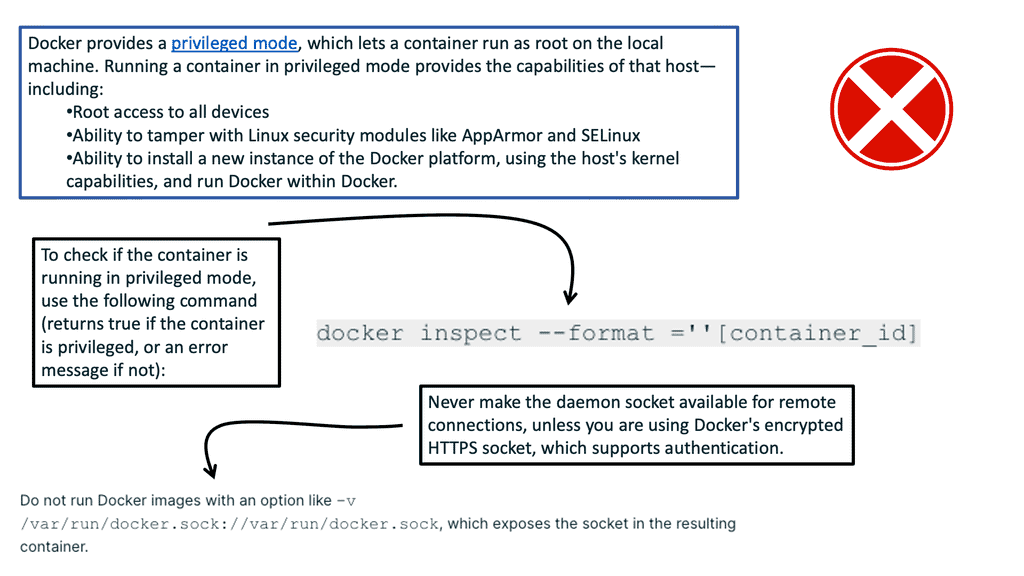
Containers run as root by default.
The first thing to consider when starting Docker container security is that containers run as root by default and share the Kernel of the Host OS. They rely on the boundaries created by namespaces for isolation and control groups to prevent one container from consuming resources negatively. So here, we can avoid things like a noisy neighbor, where one application uses up all resources on the system, preventing other applications from performing adequately on the same system.
In the early days of containers, this is how container protection started with namespace and control groups, and the protection was not perfect. For example, it cannot prevent all interference in resources the operating system kernel does not manage.
So, we need to move to a higher abstraction layer with container images. The container images encapsulate your application code and any dependencies, third-party packages, and libraries. Images are our built assets representing all the fields to run our application on top of the Linux kernel. In addition, images are used to create containers so that we can provide additional Docker container security here.

Security concerns. Image and supply chain
To run a container, we need to pull images. The images are pulled locally or from remote registries; we can have vulnerabilities here. Your hosts connected to the registry may be secure, but that does not mean the image you are pulling is secure. Traditional security appliances are blind to malware and other image vulnerabilities as they are looking for different signatures. There are several security concerns here.
Users can pull full or bloated images from untrusted registries or images containing malware. As a result, we need to consider the container threats in both runtimes and the supply chain for adequate container security.
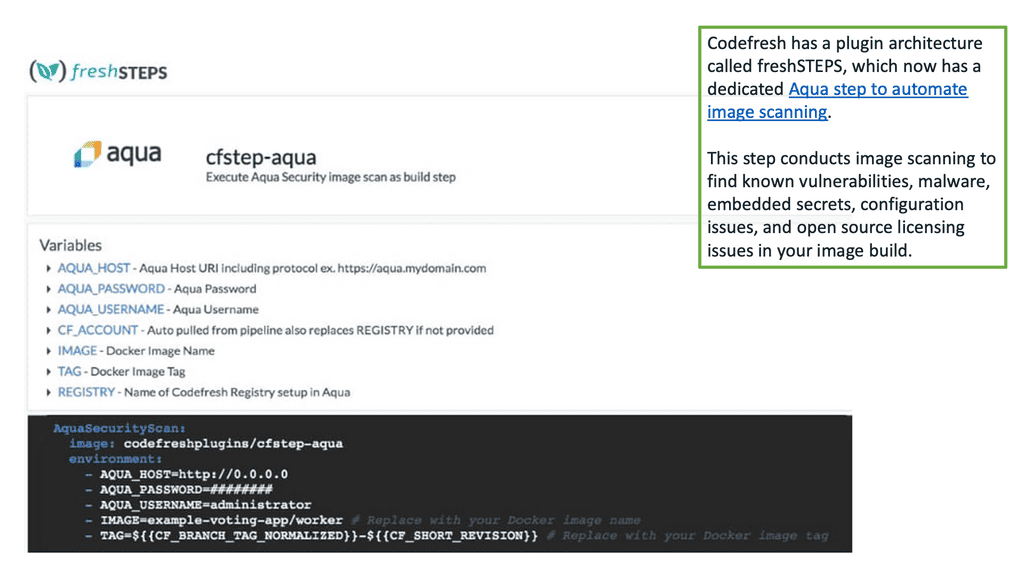
Scanning Docker images during the CI stage provides a quick and short feedback loop on security as images are built. You want to discover unsecured images well before you deploy them and enable developers to fix them quickly rather than wait until issues are found in production.
You should also avoid unsecured images in your testing/staging environments, as they could also be targets for attack. For example, we have image scanning from Aqua, and image assurance can be implemented in several CI/CD tools, including the Codefresh CI/CD platform.
Note:
1. Principle of Least Privilege: Avoid running containers as root whenever possible. Instead, use non-root users within the container and assign only the necessary privileges required for the application to function correctly.
2. User Namespace Mapping: Utilize user namespace mapping to map non-root users inside the container to a different user outside the container. This helps provide an additional layer of isolation and restricts the impact of any potential compromise.
3. Secure Image Sources: Ensure container images from trusted sources are obtained in your environment. Regularly update and patch container images to minimize the risk of known vulnerabilities.
4. Container Runtime Security: Implement runtime security measures such as container runtime security policies, secure configuration practices, and regular vulnerability scanning to detect and prevent potential security breaches.
Security concerns: Container breakouts
The container process is visible from the host. Therefore, if a bad actor gets access to the host with the correct privileges, it can compromise all the containers on the host. If an application can read the memory that belongs to your application, it can access your data. So, you need to ensure that your applications are safely isolated from each other. If your application runs on separate physical machines, accessing another application’s memory is impossible. From the security perspective, physical isolation is the strongest but is often not always possible.
If a host gets compromised, all containers running on the host are potentially compromised, too, especially if the attacker gains root or elevates their privileges, such as a member of the Docker Group.
Your host must be locked down and secured, making container breakouts difficult. Also, remember that it’s hard to orchestrate a container breakout. Still, it is not hard to misconfigure a container with additional or excessive privileges that make a container breakout easy.
The role of the Kernel: Potential attack vector
The Kernel manages its userspace processes and assigns memory to each process. So, it’s up to the Kernel to ensure that one application can’t access the memory allocated to another. The Kernel is hardened and battle-tested, but it is complex, and complexity is the number one enemy of good security. You cannot rule out a bug in how the Kernel manages memory; an attacker could exploit that bug to access the memory of other applications.
**Hypervisor: Better isolation? Kernel attack surface**
So, does the Hypervisor give you better isolation than a Kernel gives to its process? The critical point is that a kernel is complex and constantly evolving; as crucial as it manages memory and device access, the Hypervisor has a more specific role. As a result, the hypervisors are smaller and more straightforward than whole Linux kernels.
What happens if you compare the lines of code in the Linux Kernel to that of an open-source hypervisor? Less code means less complexity, resulting in a smaller attack surface—a more minor attack surface increases the likelihood of a bad actor finding an exploitable flaw.
With a kernel, the userspace process allows some visibility of each other. For example, you can run specific CLI commands and see the running processes on the same machine. Furthermore, you can access information about those processes with the correct permissions.
This fundamentally differs between the container and V.M. Many consider the container weaker in isolation. With a V.M., you can’t see one machine’s process from another. The fact that containers share a kernel means they have weaker isolation than the V.M. For this reason and from the security perspective, you can place containers into V.Ms.
Docker Security Best Practices – Goal1: Strengthen isolation: Namespaces
One of the main building blocks of containers is a Linux construct called the namespace, which provides a security layer for your applications running inside containers. For example, you can limit what that process can see by putting a process in a namespace. A namespace fools a process that it uniquely has access to. In reality, other processes in their namespace can access similar resources in their isolated environments. The resources belong to the host system.
Docker Security Best Practices – Goal2: Strengthen isolation: Access control
Access control is about managing who can access what on a system. We inherited Unix’s Discretionary Access Control (DAC) features from Linux. Unfortunately, they are constrained, and there are only a few ways to control access to objects. If you want a more fine-grained approach, we have Mandatory Access Control (MAC), which is policy-driven and granular for many object types.
We have a few solutions for MAC. For example, SELinux was in Kernel in 2003 and AppArmor in 2010. These are the most popular in the Linux domain, and these are implemented as modules via the LSM framework.
SELinux was created by the National Security Agency (NSA ) to protect systems and was integrated into the Linux Kernel. It is a Linux kernel security module that has access controls, integrity controls, and role-based access controls (RBAC)
Docker Security Best Practices – Goal3: Strengthen isolation: AppArmor
AppArmor applies access control on an application-by-application basis. To use it, you associate an AppArmor security profile with each program. Docker loads a default profile for the container’s default. Keep in mind that this is used and not on the Docker Daemon. The “default profile” is called docker-default. Docker describes it as moderately protective while providing broad application capability.
So, instantiating a container uses the “docker default” policy unless you override it with the “security-opt” flag. This policy is crafted for the general use case. The default profile is applied to all container workloads if the host has AppArmor enabled.
Docker Security Best Practices – Goal4: Strengthen isolation: Control groups
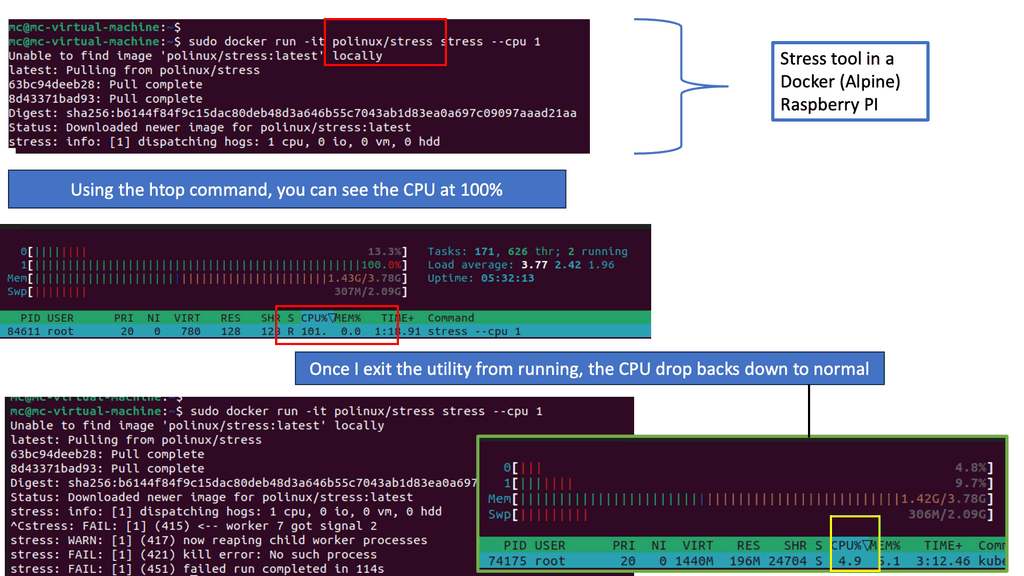
Containers should not starve other containers from using all the memory or other host resources. So, we can use control groups to limit resources available to different Linux processes. Control Groups control hosts’ resources and are essential for fending Denial-of-Service Attacks. If a function is allowed to consume, for example, unlimited memory, it can starve other processes on the same host of that host resource.
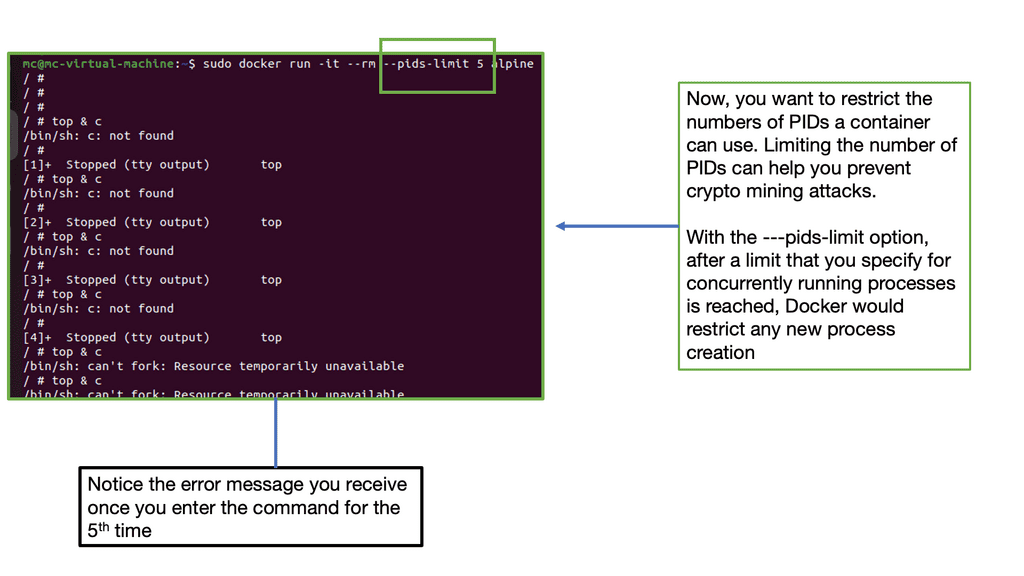
This could be done inadvertently through a memory leak in the application or maliciously due to a resource exhaustion attack that takes advantage of a memory leak. The container can fork as many processes (PID ) as the max configured for the host kernel.
Unchecked, this is a significant avenue as a DoS. A container should be limited to the number of processors required through the CLI. A control group called PID determines the number of processes allowed within a control group to prevent a fork bomb attack. This can be done with the PID subsystem.
Docker Security Best Practices – Goal5: Strengthen isolation: Highlighting system calls
System calls run in the Kernel space, with the highest privilege level and kernel and device drivers. At the same time, a user application runs in the user space, which has fewer privileges. When an application that runs in user space needs to carry out such tasks as cloning a process, it does this via the Kernel, and the Kernel carries out the operation on behalf of the userspace process. This represents an attack surface for a bad actor to play with.
Docker Security Best Practices – Goal6: Security standpoint: Limit the system calls
So, you want to limit the system calls available to an application. If a process is compromised, it may invoke system calls it may not ordinarily use. This could potentially lead to further compromisation. It would help if you aimed to remove system calls that are not required and reduce the available attack surface. As a result, it will reduce the risk of compromise and risk to the containerized workloads.
Docker Security Best Practices – Goal7: Secure Computing Mode
Secure Computing Mode (seccomp) is a Linux kernel feature that restricts the actions available within the containers. For example, there are over 300+ syscalls in the Linux system call interface, and your container is unlikely to need access. For instance, if you don’t want containers to change kernel modules. Therefore, they do not need to call the “create” module, “delete” module, or “init”_module.” Seccomp profiles are applied to a process that determines whether or not a given system call is permitted. Here, we can list or blocklist a set of system calls.
The default seccomp profile sets the Kernel’s action when a container process attempts to execute a system call. An allowed action specifies an unconditional list of permitted system calls.
For Docker container security, the default seccomp profile blocks over 40 syscalls without ill effects on the containerized applications. You may want to tailor this to suit your security needs, restrict it further, and limit your container to a smaller group of syscalls. It is recommended that each application have a seccomp profile that permits precisely the same syscalls it needs to function. This will follow the security principle of the least privileged.

- Fortinet’s new FortiOS 7.4 enhances SASE - April 5, 2023
- Comcast SD-WAN Expansion to SMBs - April 4, 2023
- Cisco CloudLock - April 4, 2023