**Section 1: The Anatomy of a Cloud Data Center**
At their core, cloud data centers are vast facilities housing thousands of servers that store, manage, and process data. These centers are strategically located around the globe to ensure efficient data delivery and redundancy. They consist of several key components, including server racks, cooling systems, power supplies, and network infrastructure. Each component plays a crucial role in maintaining the reliability and performance of the data center, ensuring your data is accessible 24/7.
**Section 2: How Cloud Data Centers Transform Businesses**
For businesses, cloud data centers offer unparalleled flexibility and scalability. They allow companies to scale their IT resources on demand, reducing the need for costly physical infrastructure. This flexibility enables businesses to respond quickly to changing market conditions and customer demands. Additionally, cloud data centers offer enhanced security measures, including encryption and multi-factor authentication, ensuring that sensitive information is protected from cyber threats.
**Section 3: Environmental Impact and Sustainability**
While cloud data centers are technological marvels, they also consume significant energy. However, many companies are committed to reducing their environmental impact. Innovations in energy-efficient technologies and renewable energy sources are being implemented to power these centers sustainably. By optimizing cooling systems and utilizing solar, wind, or hydroelectric power, cloud providers are taking significant steps towards greener operations, minimizing their carbon footprint.
**Section 4: The Future of Cloud Data Centers**
The evolution of cloud data centers is far from over. With advancements in artificial intelligence, edge computing, and quantum computing, the future holds exciting possibilities. These technologies promise to improve data processing speeds, reduce latency, and enhance overall efficiency. As the demand for data storage and processing continues to rise, cloud data centers will play an increasingly vital role in shaping the technological landscape.
Components of a Cloud Data Center
Servers and Hardware: At the heart of every data center are numerous high-performance servers, meticulously organized into racks. These servers handle the processing and storage of data, working in tandem to cater to the demands of cloud services.
Networking Infrastructure: To facilitate seamless communication between servers and with external networks, robust networking infrastructure is deployed. This includes routers, switches, load balancers, and firewalls, all working together to ensure efficient data transfer and secure connectivity.
Storage Systems: Data centers incorporate diverse storage systems, ranging from traditional hard drives to cutting-edge solid-state drives (SSDs) and even advanced storage area networks (SANs). These systems provide the immense capacity needed to store and retrieve vast amounts of data on-demand.
**Data is distributed**
Data and applications are being accessed by a multidimensional world of data and applications as our workforce shifts from home offices to centralized campuses to work-from-anywhere setups. Data is widely distributed across on-premises, edge clouds, and public clouds, and business-critical applications are becoming containerized microservices. Agile and resilient networks are essential for providing the best experience for customers and employees.
The IT department faces a multifaceted challenge in synchronizing applications with networks. An automation tool set is essential to securely manage and support hybrid and multi-cloud data center operations. Automation toolsets are also necessary with the growing scope of NetOps and DevOps roles.
Understanding Pod Data Centers
Pod data centers are modular and self-contained units that house all the necessary data processing and storage components. Unlike traditional data centers requiring extensive construction and physical expansion, pod data centers are designed to be easily deployed and scaled as needed. These prefabricated units consist of server racks, power distribution systems, cooling mechanisms, and network connectivity, all enclosed within a secure and compact structure.
The adoption of pod data centers offers several advantages. Firstly, their modular nature allows for rapid deployment and easy scalability. Organizations can quickly add or remove pods based on their computing needs, resulting in cost savings and flexibility. Additionally, pod data centers are highly energy-efficient, incorporating advanced cooling techniques and power management systems to optimize resource consumption. This not only reduces operational costs but also minimizes the environmental impact.

Enhanced Reliability and Redundancy
Pod data centers are designed with redundancy in mind. Organizations can ensure high availability and fault tolerance by housing multiple pods within a facility. In the event of a hardware failure or maintenance, the workload can be seamlessly shifted to other functioning pods, minimizing downtime and ensuring uninterrupted service. This enhanced reliability is crucial for industries where downtime can lead to significant financial losses or compromised data integrity.
The rise of pod data centers has paved the way for further innovations in computing infrastructure. As the demand for data processing continues to grow, pod data centers will likely become more compact, efficient, and capable of handling massive workloads. Additionally, advancements in edge computing and the Internet of Things (IoT) can further leverage the benefits of pod data centers, bringing computing resources closer to the source of data generation and reducing latency.
Data center network virtualization
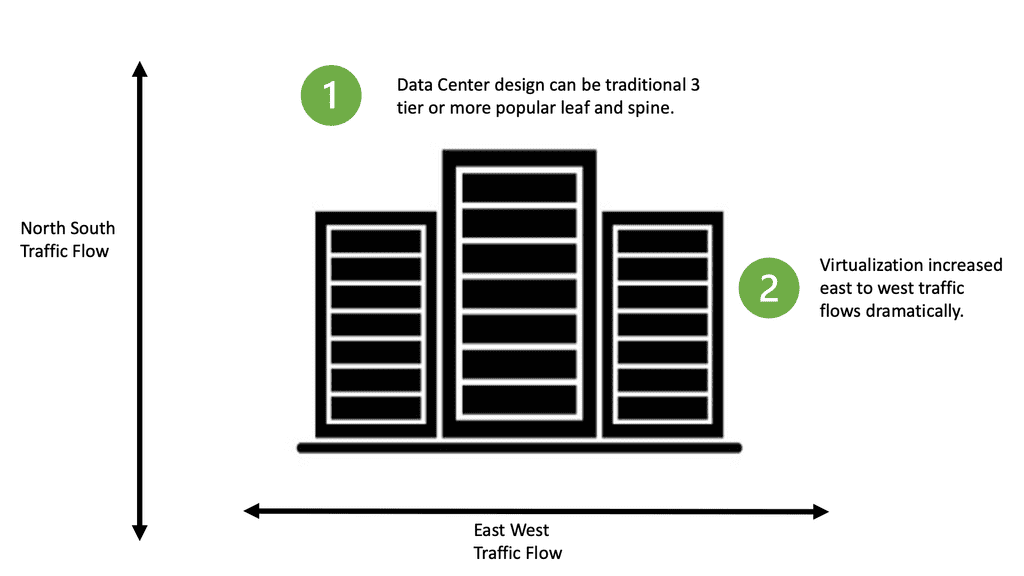
Network Virtualization of networks plays a significant role in designing data centers, especially those for use in the cloud space. There is not enough space here to survey every virtualization solution proposed or deployed (such as VXLAN, nvGRE, MPLS, and many others); a general outline of why network virtualization is essential will be considered in this section.
A primary goal of these technologies is to move the control plane state from the core to the network’s edges. With VXLAN, a Layer 3 fabric can be used to build Layer 2 broadcast domains. For each ToR, spine switches only know a few addresses, reducing the state carried in the IP routing control plane to a minimum.
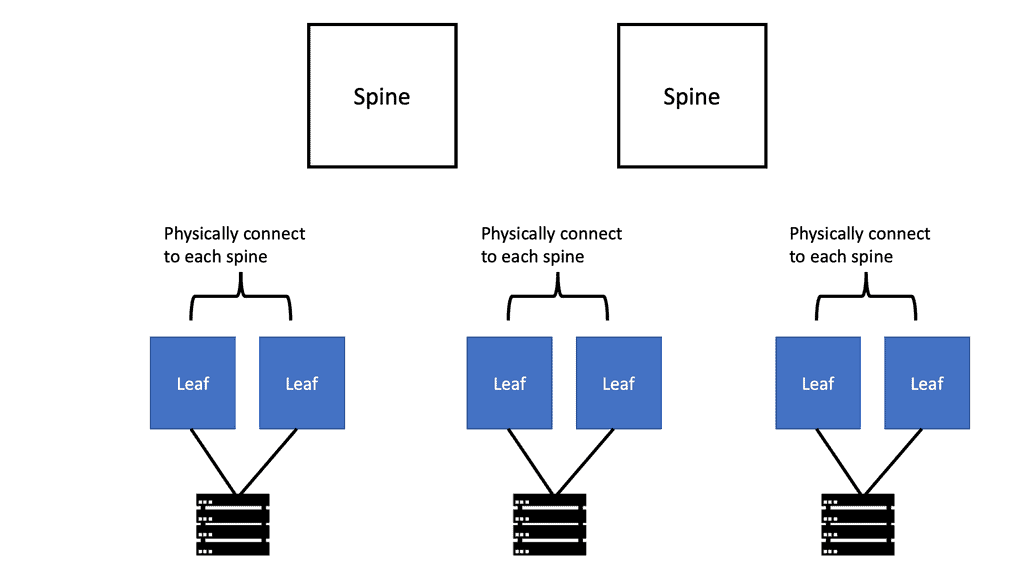
Tunneling will affect visibility to quality of service and other traffic segregation mechanisms within the spine or the data center core, which is the first question relating to these technologies. In theory, tunneling traffic edge-to-edge could significantly reduce the state held at spine switches (and perhaps even at ToR switches). Still, it could sacrifice fine-grained control over packet handling.
Tunnel Termination
In addition, where should these tunnels be terminated? The traffic flows across the fabric can be pretty exciting if they are terminated in software running on the data center’s compute resources (such as in a user VM space, the software control space, or hypervisor space). In this case, traffic is threaded from one VLAN to another through various software tunnels and virtual routing devices. However, the problem of maintaining and managing hardware designed to support these tunnels can still exist if these tunnels terminate on either the ToR or in the border leaf nodes.
Modular Data Center Design
A modular data center design consists of several prefabricated modules or a deployment method for delivering data center infrastructure in a modular, quick, and flexible process. The modular building block design approach is necessary for large data centers as “Hugh domains fail for a reason” – “Russ White.” For the virtual data center, these modular building blocks can be referred to as “Points of Delivery,” also known as pods, and “Integrated Compute Stacks,” also known as ICSs, such as VCE Vblock and FlexPod.
Example: Cisco ACI
You could define a pod as a modular unit of data center components ( pod data center ) that supports incremental build-out of the data center. They are the basis for modularity within the cloud data center and are the basis of design in the ACI network. Based on spine-leaf architecture, pods can be scaled and expanded incrementally by designers adding Integrated Compute Stacks ( ICS ) within a pod. ICS is a second, smaller unit added as a repeatable unit.
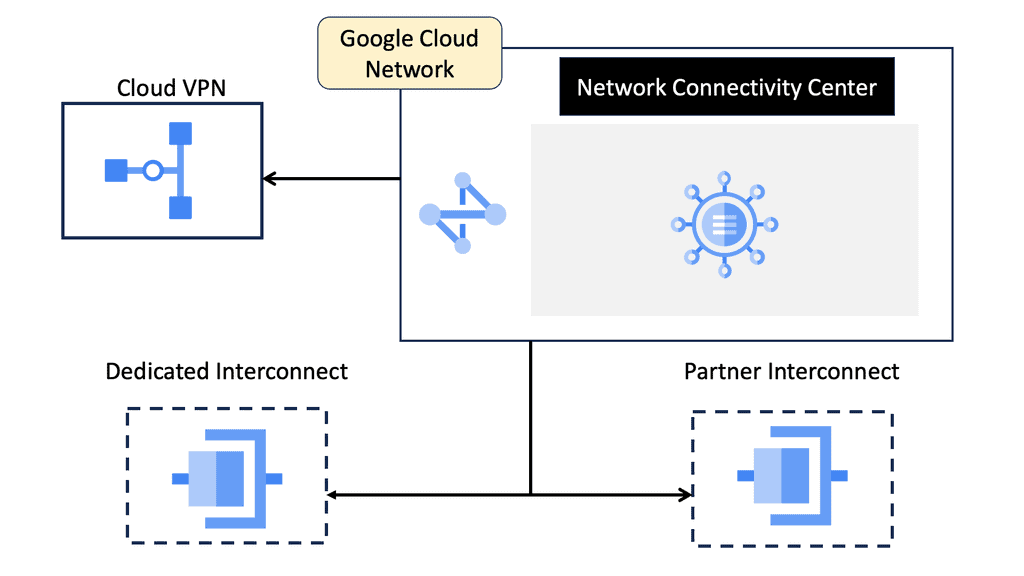
Google Cloud Data Centers
Understanding Network Tiers
Network tiers are a fundamental concept within the infrastructure of cloud computing platforms. Google Cloud offers multiple network tiers that cater to different needs and budget requirements. These tiers include Premium Tier, Standard Tier, and Internet Tier. Each tier offers varying levels of performance, reliability, and cost. Understanding the characteristics of each network tier is essential for optimizing network spend.
The Premium Tier is designed for businesses that prioritize high performance and global connectivity. With this tier, organizations can benefit from Google’s extensive network infrastructure, ensuring fast and reliable connections across regions. While the Premium Tier may come at a higher cost compared to other tiers, its robustness and scalability make it an ideal choice for enterprises with demanding networking requirements.


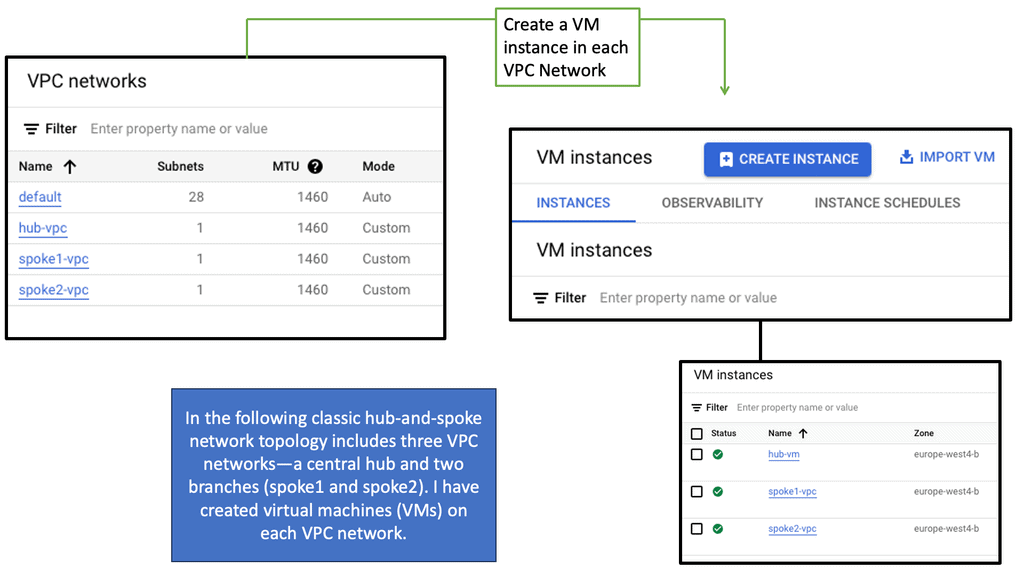
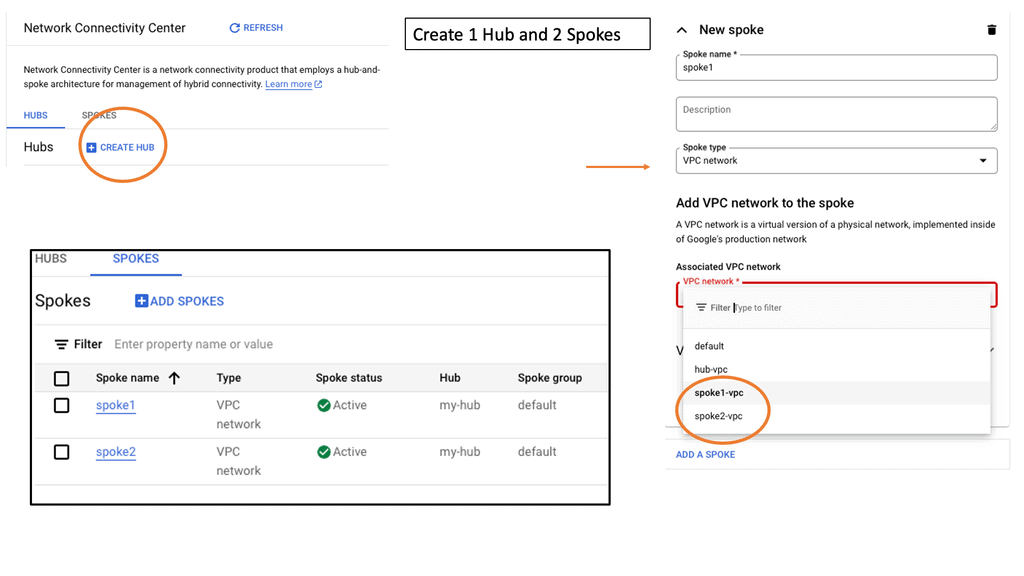
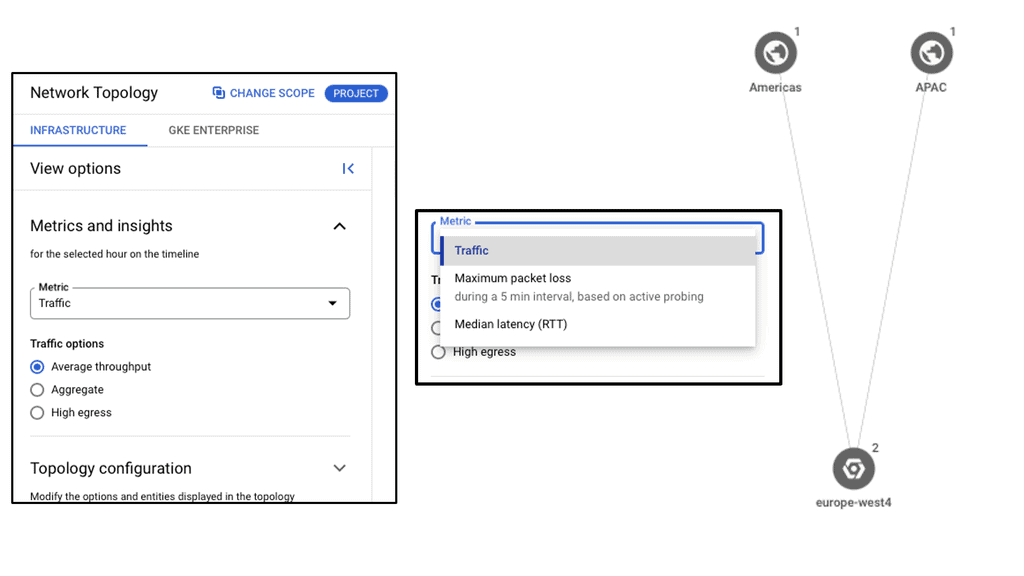
Understanding VPC Networking
VPC Networking forms the backbone of a cloud infrastructure, providing secure and isolated communication between resources within a virtual network. It allows you to define and customize your network environment, ensuring seamless connectivity while maintaining data privacy and security.

Google Cloud’s VPC Networking offers a range of impressive features that empower businesses to design and manage their network infrastructure effectively. Some notable features include subnet creation, firewall rules, VPN connectivity, and load balancing capabilities. These features provide flexibility, scalability, and robust security measures for your applications and services.


Example: What is VPC Peering?
VPC Peering is a networking arrangement that enables direct communication between VPC networks within the same region or across different regions. It establishes a secure and private connection, allowing resources in different VPC networks to interact as if they were within the same network.

VPC Peering offers several key benefits, making it an essential tool for network architects and administrators. First, it simplifies network management by eliminating the need for complex VPN configurations or public IP addresses. Second, it enables low-latency and high-bandwidth communication, enhancing the performance of distributed applications. Third, it provides secure communication between VPC networks without exposing resources to the public Internet.
VPC Peering unlocks various use cases and scenarios for businesses leveraging Google Cloud. One everyday use case is multi-region deployments, where organizations can distribute their resources across different regions and establish VPC Peering connections to facilitate cross-region communication. Additionally, VPC Peering benefits organizations with multiple projects or departments, allowing them to share resources and collaborate efficiently and securely.

Before you proceed, you may find the following posts helpful:
Data centers were significantly dissimilar from those just a short time ago. Infrastructure has moved from traditional on-premises physical servers to virtual networks. These virtual networks must seamlessly support applications and workloads across physical infrastructure pools and multi-cloud environments. Generally, a data center consists of the following core infrastructure components: network infrastructure, storage infrastructure, and compute infrastructure.
Modular Data Center Design
Scalability:
One key advantage of cloud data centers is their scalability. Unlike traditional data centers, which require physical infrastructure upgrades to accommodate increased storage or processing needs, cloud data centers can quickly scale up or down based on demand. This flexibility allows businesses to adapt rapidly to changing requirements without incurring significant costs or disruptions to their operations.
Efficiency:
Cloud data centers are designed to maximize energy consumption and hardware utilization efficiency. By consolidating multiple servers and storage devices into a centralized location, cloud data centers reduce the physical footprint required to store and process data. This minimizes the environmental impact and helps businesses save on space, power, and cooling costs.
Reliability:
Cloud data centers are built with redundancy in mind. They have multiple power sources, network connections, and backup systems to ensure uninterrupted service availability. This high level of reliability helps businesses avoid costly downtime and ensures that their data is always accessible, even in the event of hardware failures or natural disasters.
Security:
Data security is a top priority for businesses, and cloud data centers offer robust security measures to protect sensitive information. These facilities employ various security protocols such as encryption, firewalls, and intrusion detection systems to safeguard data from unauthorized access or breaches. Cloud data centers often comply with industry-specific regulations and standards to ensure data privacy and compliance.
Cost Savings:
Cloud data centers offer significant cost savings compared to maintaining an on-premises data center. With cloud-based infrastructure, businesses can avoid upfront capital expenditures on hardware and maintenance costs. Instead, they can opt for a pay-as-you-go model, where they only pay for the resources they use. This scalability and cost efficiency make cloud data centers attractive for businesses looking to reduce IT infrastructure expenses.
The general idea behind these two forms of modularity is to have consistent, predictable configurations with supporting implementation plans that can be rolled out when a predefined performance limit is reached. For example, if pod-A reaches 70% capacity, a new pod called pod-B is implemented precisely. The critical point is that the modular architecture provides a predictable set of resource characteristics that can be added as needed. This adds numerous benefits to fault isolation, capacity planning, and ease of new technology adoption. Special service pods can be used for specific security and management functions.
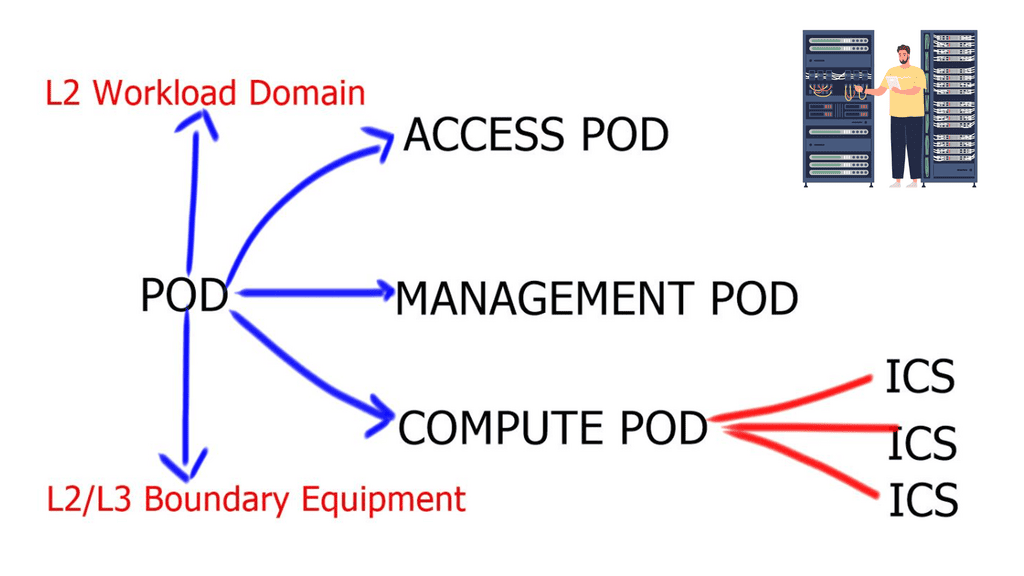
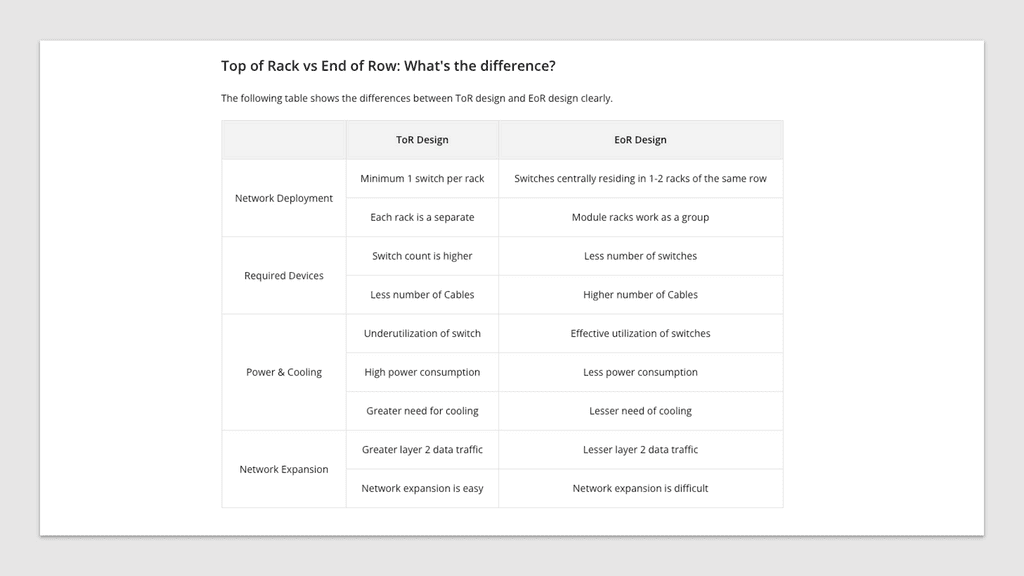
**Pod Data Center**
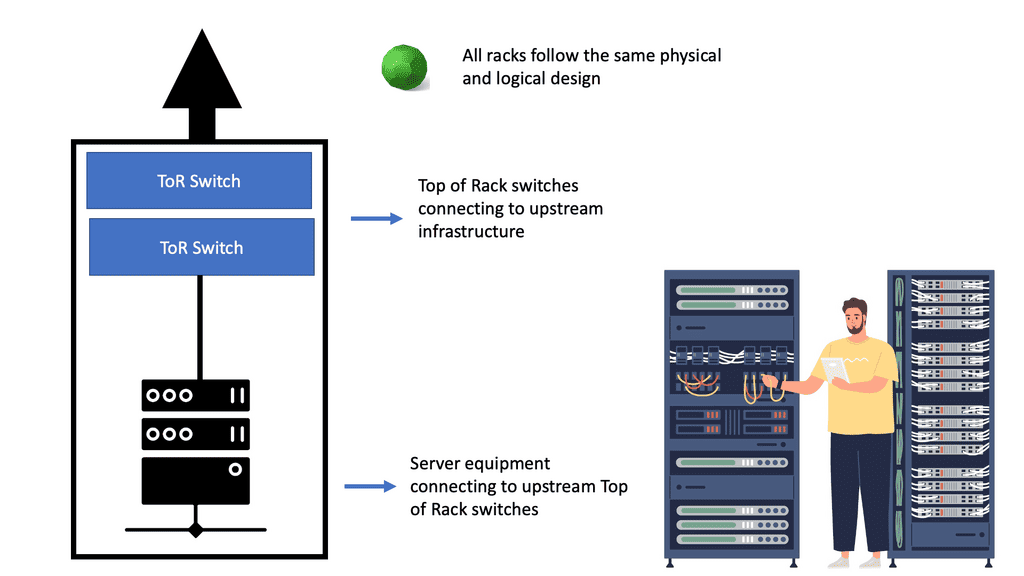
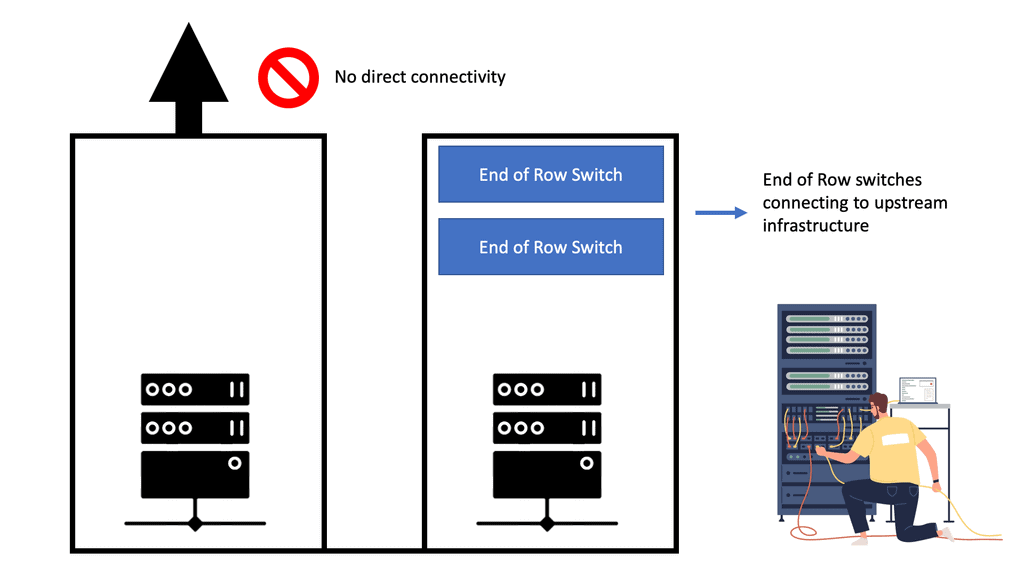
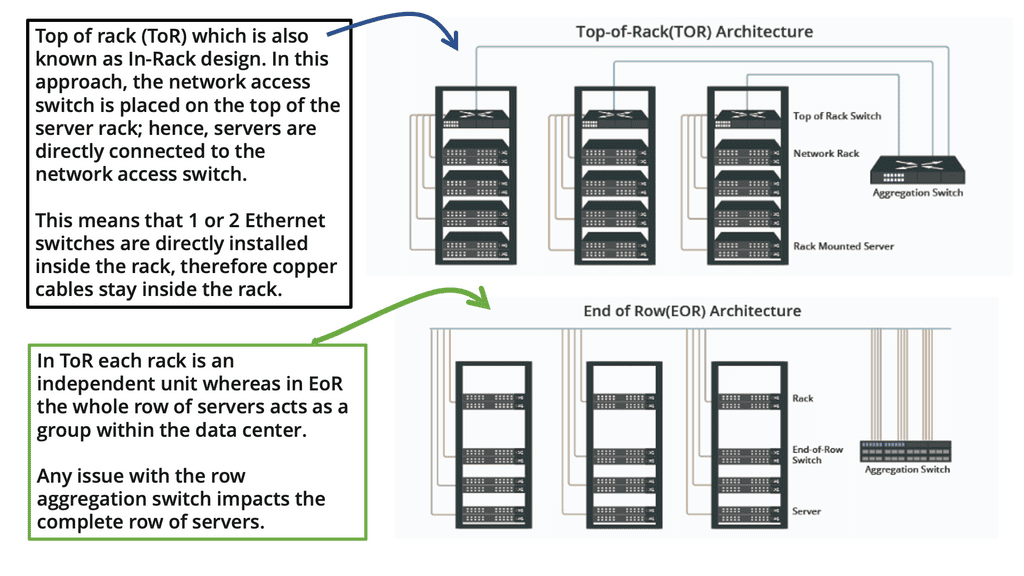
No two data centers will be the same with all the different components. However, a large-scale data center will include key elements: applications, servers, storage, networking such as load balancers, and other infrastructure. These can be separated into different pods. A pod is short for Performance Optimized Datacenter and has been used to describe several different data center enclosures. Most commonly, these pods are modular data center solutions with a single-aisle, multi-rack enclosure with built-in hot- or cold-aisle containment.
A key point: Pod size
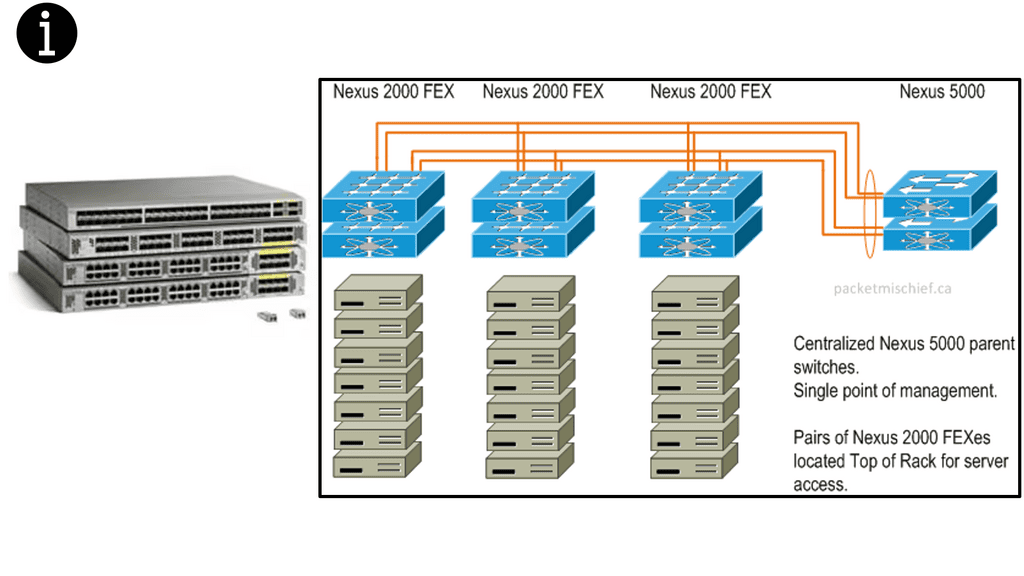
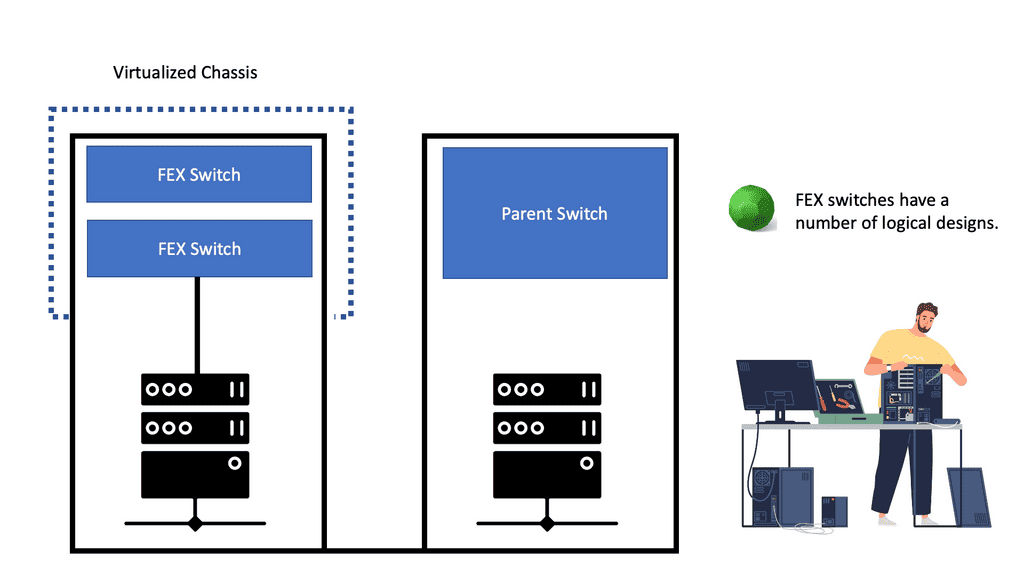
The pod size is relative to the MAC addresses supported at the aggregation layer. Different vNICs require unique MAC addresses, usually 4 MAC addresses per VM. For example, the Nexus 7000 series supports up to 128,000 MAC addresses, so in a large POD design, 11,472 workloads can be enabled, translating to 11,472 VM – 45,888 MAC addresses. Sharing VLANS among different pods is not recommended, and you should try to filter VLANs on trunk ports to stop unnecessary MAC address flooding. In addition, spanning VLANs among PODs would result in an end-to-end spanning tree, which should be avoided at all costs.
Pod data center and muti-tenancy
Within these pods and ICS stacks, multi-tenancy and tenant separation is critical. A tenant is an entity subscribing to cloud services and can be defined in two ways. First, a tenant’s definition depends on its location in the networking world. For example, a tenant in the private enterprise cloud could be a department or business unit. However, a tenant in the public world could be an individual customer or an organization.
Each tenant can have differentiating levels of resource allocation within the cloud. Cloud services can range from IaaS to PaaS, ERP, SaaS, and more depending on the requirements. Standard service offerings fall into four tiers: Premium, Gold, Silver, and Bronze. In addition, recent tiers, such as Copper and Palladium, will be discussed in later posts.
It does this by selecting a network container that provides them with a virtual dedicated network ( within a shared infrastructure ). The customer then goes through a VM sizing model, storage allocation/protection, and the disaster recovery tier.

Example of a tiered service model
Component | Gold | Silver | Bronze |
Segmentation | Single VRF | Single VRF | Single VRF |
Data recovery | Remote replication | Remote replicaton | None |
VLAN | Mulit VLAN | Multi VLAN | Single VLAN |
Service | FW and LB service | LB service | None |
Data protection | Clone | Snap | None |
Bandwidth | 40% | 30% | 20% |
Modular building blocks: Network container
The type of service selected in the network container will vary depending on application requirements. In some cases, applications may require several tiers. For example, a Gold tier could require a three-tier application layout ( front end, application, and database ). Each tier is placed on a separate VLAN, requiring stateful services ( dedicated virtual firewall and load balancing instances). Other tiers may require a shared VLAN with front-end firewalling to restrict inbound traffic flows.
Usually, a tier will use a single individual VRF ( VRF-lite ), but the number of VLANs will vary depending on the service level. For example, a cloud provider offering simple web hosting will provide a single VRF and VLAN. On the other hand, an enterprise customer with a multi-layer architecture may want multiple VLANs and services ( load balancer, Firewall, Security groups, cache ) for its application stack.
Modular building blocks: Compute layer
The compute layer is related to the virtual servers and the resources available to the virtual machines. Service profiles can vary depending on the size of the VM attributes, CPU, memory, and storage capacity. Service tiers usually have three compute workload sizes at a compute layer, as depicted in the table below.
Pod data center: Example of computing resources
Component | Large | Medium | Small |
vCPU per VM | 1 vCPU | 0.5 vCPU | 0.25 vCPU |
Cores per CPU | 4 | 4 | 4 |
VM per CPU | 4 VM | 16 VM | 32 VM |
VM per vCPU oversubscription | 1:1 ( 1 ) | 2:1 ( 0.5 ) | 4:1 ( 0.25 ) |
RAM allocation | 16 GB dedicated | 8 GB dedicated | 4 GB shared |
Compute profiles can also be associated with VMware Distributed Resource Scheduling ( DRS ) profiles to prioritize specific classes of VMs.
Modular building blocks: Storage Layer
This layer relates to storage allocation and the type of storage protection. For example, a GOLD tier could offer three tiers of RAID-10 storage using 15K rpm FC, 10K rpm FC, and SATA drives. While a BRONZE tier could offer just a single RAID-5 with SATA drives
Google Cloud Security
Understanding Google Compute Resources
Before diving into the importance of securing Google Compute resources, let’s first gain a clear understanding of what they entail. Google Compute Engine (GCE) allows users to create and manage virtual machines (VMs) on Google’s infrastructure. These VMs serve as the backbone of various applications and services hosted on the cloud platform.
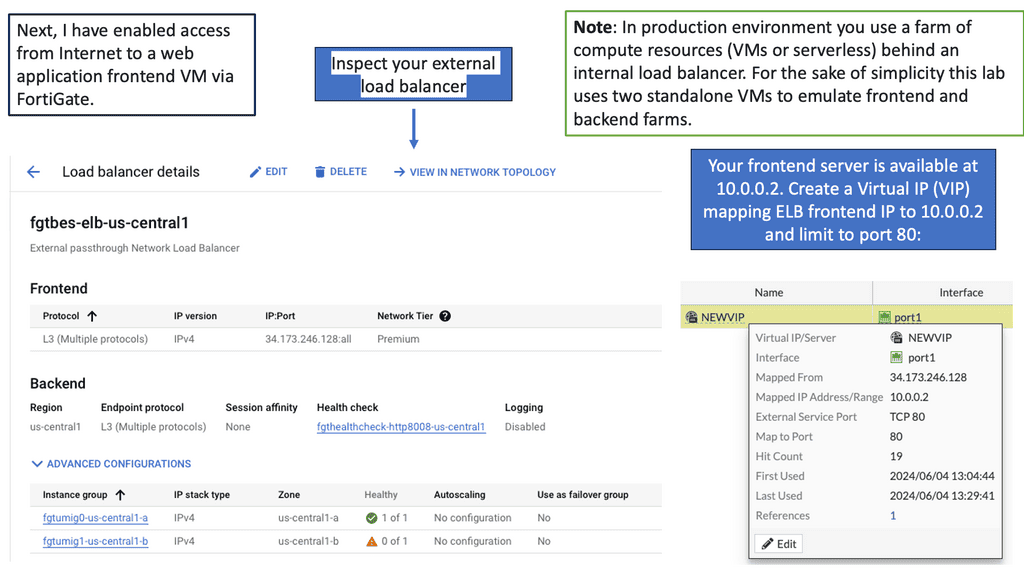
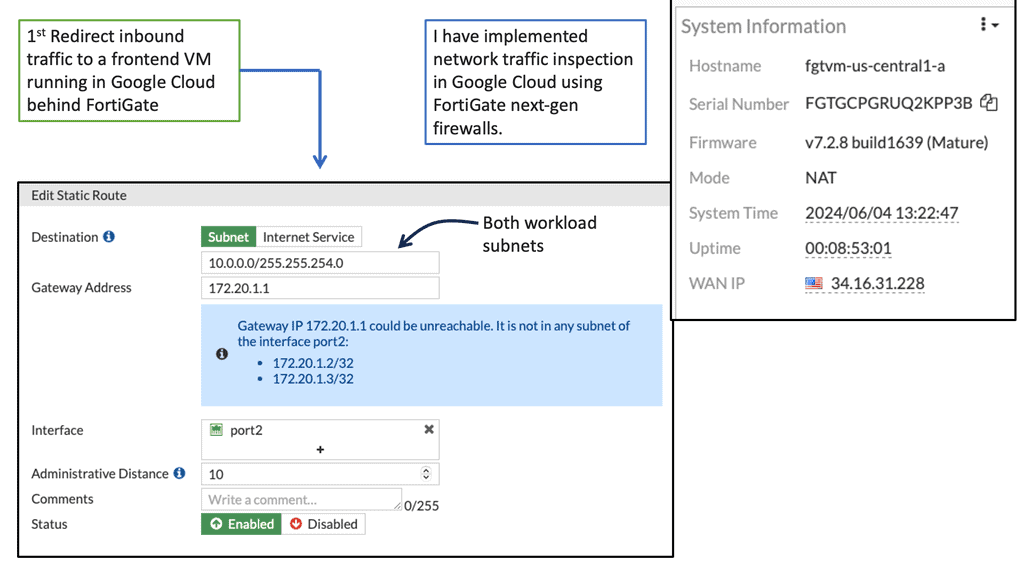
As organizations increasingly rely on cloud-based infrastructure, the need for robust security measures becomes paramount. Google Compute resources may contain sensitive data, intellectual property, or even customer information. Without proper protection, these valuable assets are at risk of unauthorized access, data breaches, and other cyber threats. FortiGate provides a comprehensive security solution to mitigate these risks effectively.
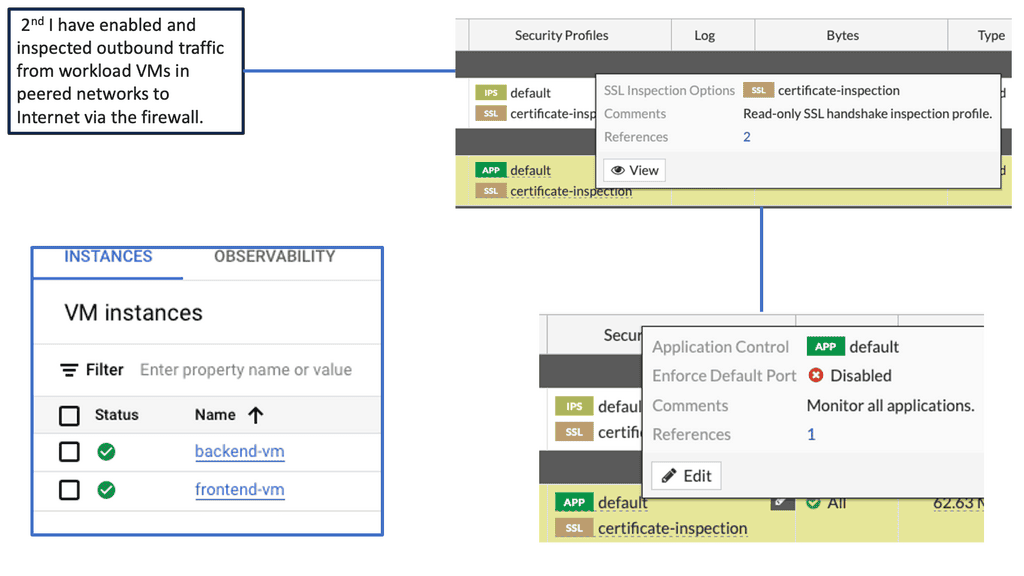
FortiGate offers a wide range of features tailored to secure Google Compute resources. Its robust firewall capabilities ensure that only authorized traffic enters and exits the VMs, protecting against malicious attacks and unauthorized access attempts. Additionally, FortiGate’s intrusion prevention system (IPS) actively scans network traffic, detecting and blocking any potential threats in real-time.
Beyond traditional security measures, FortiGate leverages advanced threat prevention techniques to safeguard Google Compute resources. Its integrated antivirus and antimalware solutions continuously monitor the VMs, scanning for any malicious files or activities. FortiGate’s threat intelligence feeds and machine learning algorithms further enhance its ability to detect and prevent sophisticated cyber threats.