Rise of Distributed Computing
Several megatrends have driven the move to an Ansible architecture. Firstly, the rise of distributed computing made the manual approach to almost anything in the IT environment obsolete. This was not only because it caused many errors and mistakes but also because the configuration drift from the desired to the actual state was considerable.
This is not only an operational burden but also a considerable security risk. Today, deploying applications by combining multiple services that run on a distributed set of resources is expected. As a result, configuration and maintenance are more complex than in the past.
Two Options:
– You have two options to implement all of this. First, you can connect these services by manually spinning up the servers, installing the necessary packages, and SSHing to each one, or you can go down the path of automation, in particular, automation with Ansible.
– So, with Ansible deployment architecture, we have the Automation Engine, the CLI, and Ansible Tower, which is more of an automation platform for enterprise-grade automation. This post focuses on Ansible Engine.
– As a quick note, if you have environments with more than a few teams automating, I recommend Ansible Tower or the open-source version of AWX. Ansible Tower has a 60-day trial license, while AWX is fully open-sourced and does not require a license. The open-source version of AWX could be a valuable tool for your open networking journey.
A Key Point: Risky: The Manual Way.
Let me put it this way: If you configure manually, you will likely maintain all the settings. What about mitigating vulnerabilities and determining what patches or packages are installed in a large environment?
How can you ensure all your servers are patched and secured manually? Manipulating configuration files by hand is tedious, error-prone, and time-consuming. Equally, performing pattern matching to make changes to existing files is risky.
A Key Point: The issue of Configuration Drift
The manual approach will result in configuration drift, where some servers will drift from the desired state. Configuration drift is caused by inconsistent configuration items across devices, usually due to manual changes and updates and not following the automation path. Ansible is all about maintaining the desired state and eliminating configuration drift.
Components: Ansible Deployment Architecture
Configuration management
The Ansible architecture is based on a configuration management tool that can help alleviate these challenges. Ansible replaces the need for an operator to tune configuration files manually and does an excellent job in application deployment and orchestrating multi-deployment scenarios. It can also be integrated into CI/CD pipelines.
In reality, Ansible is relatively easy to install and operate. However, it is not a single entity. Instead, it comprises tools, modules, and software-defined infrastructure that form the ansible toolset configured from a single host that can manage multiple hosts.
We will discuss the value of idempotency with Ansible modules later. Even with modules’ idempotency, you can still have users of Ansible automate over each other. Ansible Tower or AWS is the recommended solution for multi-team automation efforts.
Pre-deployed infrastructure: Terraform
Ansible does not deploy the infrastructure; you could use other solutions like Terraform that are best suited for this. Terraform is infrastructure as a code tool. Ansible Engine is more of a configuration as code. The physical or virtual infrastructure needs to be there for Ansible to automate, compared to Terraform, which does all of this for you.
Ansible is an easy-to-use DevOps tool that manages configuration as code has in the same design through any sized environment. Therefore, the size of the domain is irrelevant to Ansible.
As Ansible Connectivity uses SSH that runs over TCP, there are multiple optimizations you can use to increase performance and optimize connectivity, which we will discuss shortly. Ansible is often described as a configuration management tool and is typically mentioned along the same lines as Puppet, Chef, and Salt. However, there is a considerable difference in how they operate. Most notably, the installation of agents.
Ansible architecture: Agentless
The Ansible architecture is agentless and requires nothing to be installed on the managed systems. It is also serverless and agentless, so it has a minimal footprint. Some configuration management systems, such as Chef and Puppet, are “pull-based” by default.
Where agents are installed, periodically check in with the central service and pull-down configuration. Ansible is agentless and does not require the installation of an agent on the target to communicate with the target host.
However, it requires connectivity from the control host to the target inventory ( which contains a list of hosts that Ansible manages) with a trusted relationship. For convenience, we can have passwordless sudo connectivity between our hosts. This allows you to log in without a password and can be a security risk if someone gets to your machines; they could have escalated privileges on all the Ansible-managed hosts.
Key Ansible features:
Easy-to-Read Syntax: Ansible uses the YAML file format and Jinja2 templating. Jinja2 is the template engine for the Python programming language. Ansible uses Jinja2 templating to access variables and facts and extends the defaults of Ansible for more advanced use cases.
Not a full programming language: Although Ansible is not a full-fledged programming language, it has several good features. One of the most important is a variable substitution, or using the values of variables in strings or other variables.
In addition, the variables in Ansible make the Ansible playbooks, which are like executable documents, very flexible. Variables are a powerful construct within Ansible and can be used in various ways. Nearly every single thing done in Ansible can include a variable reference. We also have dynamic variables known as facts.
Jinja2 templating language: Ansible’s defaults are extended using the Jinja2 templating language. In addition, Ansible’s use of Jinja2 templating adds more advanced use cases. One great benefit is that it is self-documenting, so when someone looks at your playbook, it’s easy to understand, unlike Python code or a Bash script.
So, not only is Ansible easy to understand, but with just a few lines of YAML, the language used for Ansible, you can install, let’s say, web servers on as many hosts as you like.
Ansible Architecture: Scalability: Ansible can scale. For example, Ansible uses advanced features like SSH multiplexing to optimize SSH performance. Some use cases manage thousands of nodes with Ansible from a single machine.
SSH Connection: Parallel connections: We have three managed hosts: web1, web2, and web3. Ansible will make SSH connections parallel to web1, web2, and web3. It will then execute the first task on the list on all three hosts simultaneously. In this example, the first task is installing the Nginx package, so the task in the playbook would look like this. Ansible uses the SSH protocol to communicate with hosts except Windows hosts.
This SSH service is usually integrated with the operating system authentication stack, enabling you to use Kerberos to improve authentication security. Ansible uses the same authentication methods that you are already familiar with. SSH keys are typically the easiest way to proceed as they remove the need for users to input the authentication password every time a playbook is run.
Optimizing SSH
Ansible uses SSH to manage hosts, and establishing an SSH connection takes time. However, you can optimize SSH with several features. Because the SSH protocol runs on top of the TCP protocol, you need to create a new TCP connection when you connect to a remote host with SSH.
You don’t want to open a new SSH connection for every activity. Here, you can use Control Master, which allows multiple simultaneous SSH connections with a remote host using one network connection. Control Persists, or multiplexing keeps a connection option for xx seconds. The pipeline allows more commands to use simultaneous SSH connections. If you recall how Ansible executes a task?
- It generates a Python script based on the module being invoked
- It then copies the Python script to the host
- Finally, it executes the Python script
The pipelining optimization will execute the Python scripts by piping it to the SSH sessions instead of copying git. Here, we are using one SSH session instead of two. These options can be configured in Ansible.cfg, and we use the SSH_connecton section. Then, you can specify how these connections are used.
A note on scalability: Ansible and modularity
Ansible scales down well because simple tasks are easy to implement and understand in playbooks. Ansible scales well because it allows decomposing of complex jobs into smaller pieces. So, we can bring the concept of modularity into playbooks as the playbook becomes more difficult. I like using Tags for playbook developments that can save time and effect to test different parts of the playbook when you know certain parts are 100% working.
Security wins! No daemons and no listening agents
Once Ansible is installed, it will not add a database, and there will be no daemons to start or keep running. You only need to install it on one machine (which could easily be a laptop), and it can manage an entire fleet of remote machines from that central point. No Ansible agent is listening on a port. Therefore, when you use Ansible, there is no extra attack surface for a bad actor to play with.
This is a big win for security following one of the leading security principles of reducing the attack surface. When you run the Ansible-playbook command, Ansible connects to the remote servers and does what you want. By its defaults, Ansible is pretty streamlined out of the box, but you can enhance it by configuring Ansible.cfg file, to be even more automated.
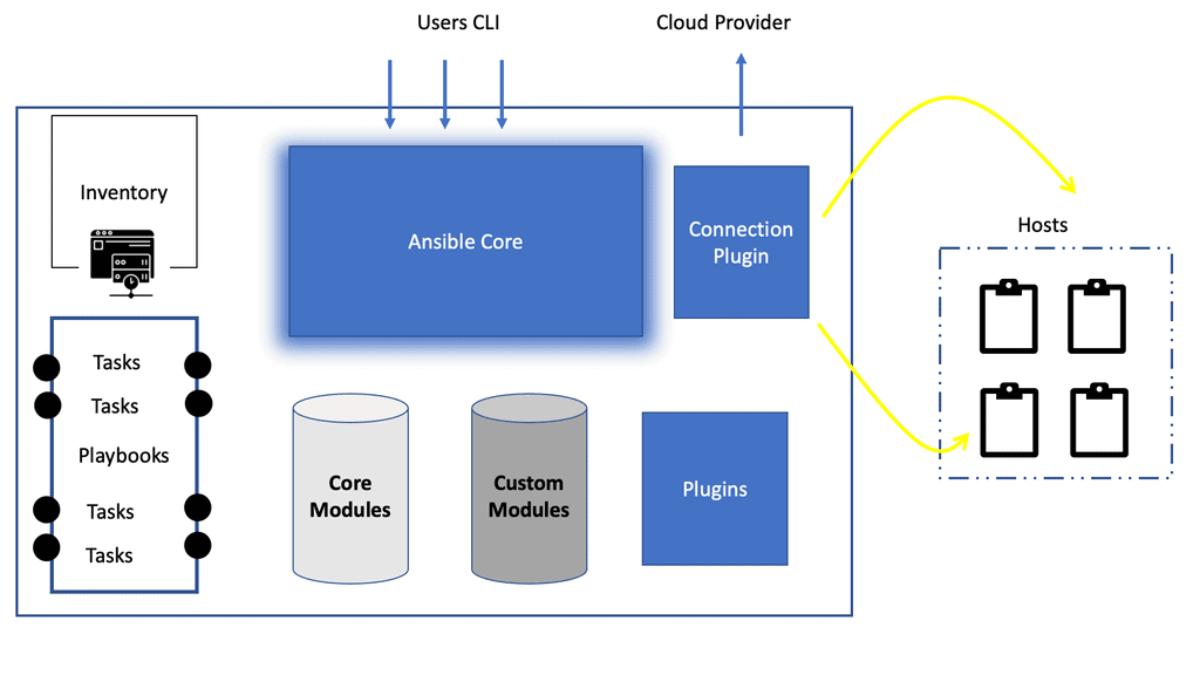
Ansible Architecture: Ansible Architecture diagram
Ansible Inventory: Telling Ansible About Your Servers
The Ansible architecture diagram has several critical components. First, the Ansible inventory is all about telling Ansible about your servers. Ansible can manage only the servers it explicitly knows about. Ansible comes with one default server of the local host, the control host.
You provide Ansible with information about servers by specifying them in an inventory. We usually create a directory called “inventory” to hold this information.
Example: For example, a straightforward inventory file might contain a list of hostnames. The Ansible Inventory is the system against which a playbook runs. It is a list of systems in your infrastructure against which the automaton is executed. The following Ansible architecture diagram shows all the Ansible components, including modules, playbooks, and plugins.
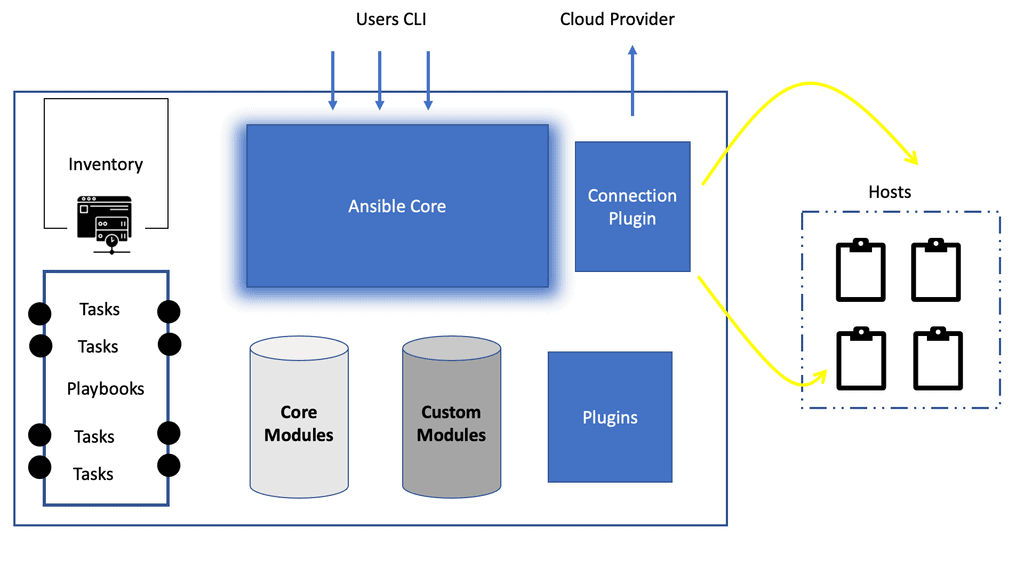
Ansible architecture diagram: Inventory highlights
These hosts commonly have hosts but can comprise other components such as network devices, storage arrays, and other physical and virtual appliances. It also has valuable information that can be used alongside our target using the execution.
The Inventory can be as simple as a text file or more dynamic, where it is an executable where the data is sourced dynamically. This way, we can store data externally and use it during runtime. So, we can have a dynamic inventory via Amazon Web Service or create our own dynamic.
Example: AWS EC2 External inventory script
The above Ansible architecture diagram shows a connection to the cloud. If you use Amazon Web Services EC2, maintaining an inventory file might not be the best approach because hosts may come and go over time, be managed by external applications, or be affected by AWS autoscaling.
For this reason, you can use the EC2 external inventory script. In addition, if your hosts run on Amazon EC2, then EC2 tracks information about your hosts for you. Ansible inventory is flexible; you can use multiple inventory sources simultaneously. Mix dynamic and statically managed inventory sources in the same ansible run is possible. Many are referring to this as an instant hybrid cloud.

Ansible deployment architecture and Ansible modules
Next, within the Ansible deployment architecture, we have the Ansible modules, which are considered Ansible’s main workhorse. You use modules to perform various tasks, such as installing a package, restarting a service, or copying a configuration file. Ansible modules cater to a wide range of system administration tasks.
This list has categories of the kinds of modules that you can use. There are over 3000 modules. So you may be thinking, who is looking after these modules? That’s where collections in the more recent versions of Ansible are doing it.
**Extending Ansible Modules**
The modules are the scripts (written in Python) that come with packages with Ansible and Perform some action on the managed host. Ansible has extensive modules covering many areas, including networking, cloud computing, server configuration, containerization, and virtualization.
In addition, many modules support your automation requirements. If no modules exist, you can create a custom module with the extensive framework of Ansible. Each task is correlated with the module one-to-one. For example, a template task will use the template module.
**A key point: Idempotency**
Modules strive to be idempotent, allowing the module to run repeatedly without a negative impact. In Ansible, the input is in the form of command-line arguments to the module, and the output is delivered as JSON to STDOUT. Input is generally provided in the space-separated key=value syntax, and it’s up to the module to deconstruct these into usable data.
Most Ansible modules are also idempotent, which means running an Ansible playbook multiple times against a server is safe. For example, if the deploy user does not exist, Ansible will create it. If it does exist, Ansible will not do anything. This is a significant improvement over the shell script approach, where running the script a second time might have different and potentially unintended effects.
**The Use of Ansible Ad Hoc Commands**
For instance, if you wanted to power off all of your labs for the weekend, you could execute a quick one-liner in Ansible without writing a playbook. With an Ad Hoc command, we can be suitable for running one command on a host, and it uses the modules. They are used to check configuring on the host and are also good for learning Ansible.
Note that Ansible is the executable for ad hoc one-task executions, and ansible-playbook is the executable for processing playbooks to orchestrate multiple tasks.
The opposable side of the puzzle is the playbook commands are used for more complex tasks and are better for use cases where the dependencies have to be managed. The playbook can take care of all application deployments and dependencies.

Ansible Plays
1.Ansible playbooks
An Ansible Playbook can have multiple plays that can exist within an Ansible playbook that can execute on different managed assets. So, an Ansible Play is all about “what am I automating.” Then, it connects to the hosts to perform the actions. Each playbook comprises one or more ‘plays’ in a list. The goal of a play is to map a group of hosts to some well-defined roles, represented by things Ansible calls tasks.
At a basic level, a task is just a call to an Ansible module. By composing a playbook of multiple ‘plays’, it is possible to orchestrate multi-machine deployments, running specific steps on all machines in the web servers group. For example, particular actions are on the database server group; then more commands are returned on the web servers group, etc.
2.Ansible tasks
Ansible is ready to execute a task once a playbook is parsed and the hosts are determined. Tasks include a name, a module reference, module arguments, and task control directives. Task execution By default, Ansible executes each task in order, one at a time, against all machines matched by the host pattern. Each task executes a module with specific arguments. You can also use the “–start-at-task <task name> flag to tell the Ansible playbook to start a playbook in the middle of a task.
3.Task execution
Each play contains a list of tasks. Tasks are executed in order, one at a time, against all machines matched by the host pattern before moving on to the next task. It is essential to understand that, within a play, all hosts will get the same task directives. This is because the purpose of a play is to map a selection of hosts to tasks.

- Fortinet’s new FortiOS 7.4 enhances SASE - April 5, 2023
- Comcast SD-WAN Expansion to SMBs - April 4, 2023
- Cisco CloudLock - April 4, 2023