Securing containerized environments
Securing containerized environments is considerably different from securing the traditional monolithic application because of the inherent nature of the microservices architecture. We went from one to many, and there is a clear difference in attack surface and entry points. So, there is much to consider for OpenShift network security and OpenShift security best practices, including many Docker security options.
The application stack previously had very few components, maybe just a cache, web server, and database separated and protected by a context firewall. The most common network service allows a source to reach an application, and the sole purpose of the network is to provide endpoint reachability.
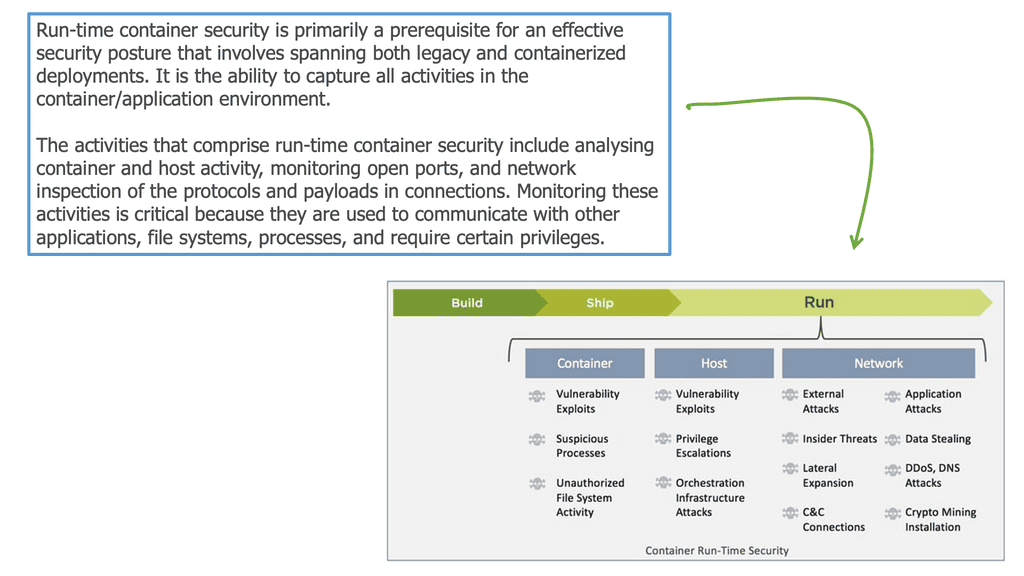
As a result, the monolithic application has few entry points, such as ports 80 and 443. Not every monolithic component is exposed to external access and must accept requests directly, so we designed our networks around these facts. The following diagram provides information on the threats you must consider for container security.
Container Security Best Practices
1. Secure Authentication and Authorization: One of the fundamental aspects of OpenShift security is ensuring that only authorized users have access to the platform. Implementing robust authentication mechanisms, such as multifactor authentication (MFA) or integrating with existing identity management systems, is crucial to prevent unauthorized access. Additionally, defining fine-grained access controls and role-based access control (RBAC) policies will help enforce the principle of least privilege.
2. Container Image Security: OpenShift leverages containerization technology, which brings its security considerations. It is essential to use trusted container images from reputable sources and regularly update them to include the latest security patches. Implementing image scanning tools to detect vulnerabilities and malware within container images is also recommended. Furthermore, restricting privileged containers and enforcing resource limits will help mitigate potential security risks.
3. Network Security: OpenShift supports network isolation through software-defined networking (SDN). It is crucial to configure network policies to restrict communication between different components and namespaces, thus preventing lateral movement and unauthorized access. Implementing secure communication protocols, such as Transport Layer Security (TLS), between services and enforcing encryption for data in transit will further enhance network security.
4. Monitoring and Logging: A robust monitoring and logging strategy is essential for promptly detecting and responding to security incidents. OpenShift provides built-in monitoring capabilities, such as Prometheus and Grafana, which can be leveraged to monitor system health, resource usage, and potential security threats. Additionally, enabling centralized logging and auditing of OpenShift components will help identify and investigate security events.
5. Regular Vulnerability Assessments and Penetration Testing: To ensure the ongoing security of your OpenShift environment, it is crucial to conduct regular vulnerability assessments and penetration testing. These activities will help identify any weaknesses or vulnerabilities within the platform and its associated applications. Addressing these vulnerabilities promptly will minimize the risk of potential attacks and data breaches.
**OpenShift Security**
OpenShift delivers all the tools you need to run software on top of it with SRE paradigms, from a monitoring platform to an integrated CI/CD system that you can use to monitor and run both the software deployed to the OpenShift cluster and the cluster itself. So, the cluster and the workload that runs in it need to be secured.
From a security standpoint, OpenShift provides robust encryption controls to protect sensitive data, including platform secrets and application configuration data. In addition, OpenShift optionally utilizes FIPS 140-2 Level 1 compliant encryption modules to meet security standards for U.S. federal departments.
This post highlights OpenShift security and provides security best practices and considerations when planning and operating your OpenShift cluster. These will give you a starting point. However, as clusters and bad actors are ever-evolving, it is important to revise the steps you took.
**Central security architecture**
Therefore, we often see security enforcement in a fixed central place in the network infrastructure. This could be, for example, a significant security stack consisting of several security appliances. We are often referred to as a kludge of devices. As a result, the individual components within the application need not worry about carrying out any security checks as they occur centrally for them.
On the other hand, with the common microservices architecture, those internal components are specifically designed to operate independently and accept requests alone, which brings considerable benefits to scaling and deploying pipelines.
However, each component may now have entry points and accept external connections. Therefore, they need to be concerned with security individually and not rely on a central security stack to do this for them.
**The different container attack vectors**
These changes have considerable consequences for security and how you approach your OpenShift security best practices. The security principles still apply, and we still are concerned with reducing the blast radius, least privileges, etc. Still, they must be used from a different perspective and to multiple new components in a layered approach. Security is never done in isolation.
So, as the number of entry points to the system increases, the attack surface broadens, leading us to several docker container security attack vectors not seen with the monolithic. We have, for example, attacks on the Host, images, supply chain, and container runtime. There is also a considerable increase in the rate of change for these types of environments; an old joke says that a secure application is an application stack with no changes.
Open The Door To Bad Actors
So when you change, you can open the door to a bad actor. Today’s application varies considerably a few times daily for an agile stack. We have unit and security tests and other safety tests that can reduce mistakes, but no matter how much preparation you do, there is a chance of a breach whenever there is a change.
So, environmental changes affect security and some alarming technical challenges to how containers run as default, such as running as root by default and with a disturbing amount of capabilities and privileges. The following image displays attack vectors that are linked explicitly to containers.
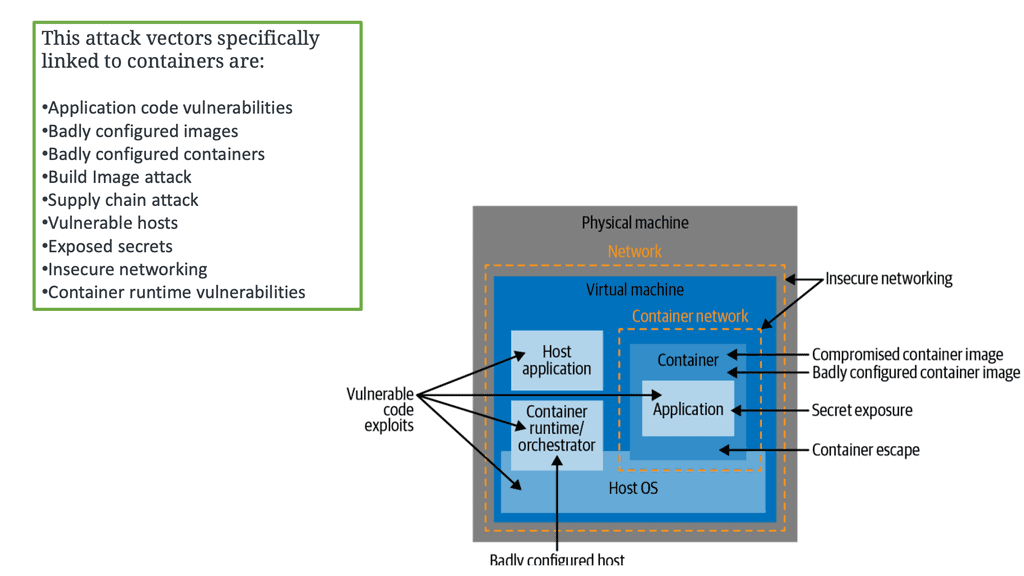
Challenges with Securing Containers
Containers running as root
As you know, containers run as root by default and share the Kernel of the Host OS. The container process is visible from the Host, which is a considerable security risk when a container compromise occurs. When a security vulnerability in the container runtime arose, and a container escape was performed, as the application ran as root, it could become root on the underlying Host.
Therefore, if a bad actor gets access to the Host and has the correct privileges, it can compromise all the hosts’ containers.
Risky Configuration
Containers often run with excessive privileges and capabilities—much more than they need to do their job efficiently. As a result, we need to consider what privileges the container has and whether it runs with any unnecessary capabilities it does not need.
Some of a container’s capabilities may be defaults that fall under risky configurations and should be avoided. You should keep an eye on the CAP_SYS_ADMIN flag, which grants access to an extensive range of privileged activities.
Excessive container isolation
The container has isolation boundaries by default with namespace and control groups ( when configured correctly). However, granting excessive container capabilities will weaken the isolation between the container, this Host, and other containers on the same Host. This is essentially removing or dissolving the container’s ring-fence capabilities.
Starting OpenShift Security Best Practices
Then, we have security with OpenShift, which overcomes many of the default security risks you have with running containers. And OpenShift does much of this out of the box. If you want further information on securing an OpenShift cluster, kindly check out my course for Pluralsight on OpenShift Security and OpenShift Network Security.
OpenShift Container Platform (formerly known as OpenShift Enterprise) or OCP is Red Hat’s offering for the on-premises private platform (PaaS). OpenShift is based on the Origin open-source project and is a Kubernetes distribution.
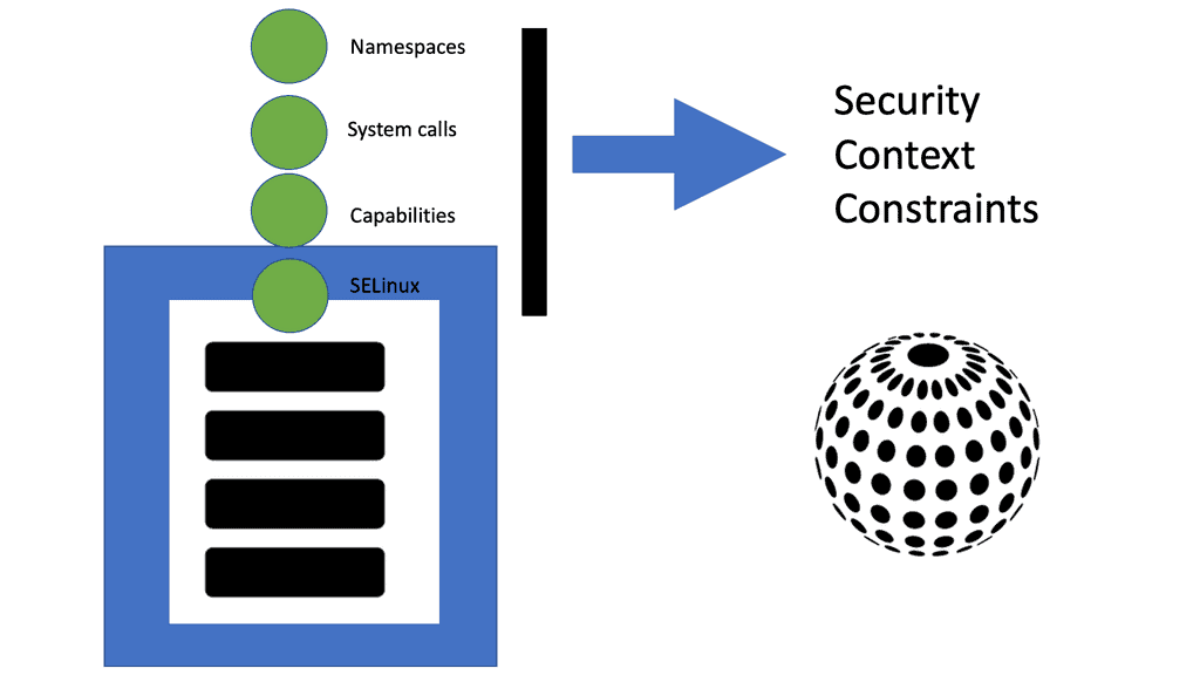
The foundation of the OpenShift Container Platform and OpenShift Network Security is based on Kubernetes and, therefore, shares some of the same networking technology and some enhancements. However, as you know, Kubernetes is a complex beast and can be utilized by itself when trying to secure clusters. OpenShift does an excellent job of wrapping Kubernetes in a layer of security, such as using Security Context Constraints (SCCs) that give your cluster a good security base.
**Security Context Constraints**
By default, OpenShift prevents the cluster container from accessing protected functions. These functions—Linux features such as shared file systems, root access, and some core capabilities such as the KILL command—can affect other containers running in the same Linux kernel, so the cluster limits access.
Most cloud-native applications work fine with these limitations, but some (especially stateful workloads) need greater access. Applications that require these functions can still use them but need the cluster’s permission.
The application’s security context specifies the permissions that the application needs, while the cluster’s security context constraints specify the permissions that the cluster allows. An SC with an SCC enables an application to request access while limiting the access that the cluster will grant.
What are security contexts and security context constraints?
A pod configures a container’s access with permissions requested in the pod’s security context and approved by the cluster’s security context constraints:
-A security context (SC), defined in a pod, enables a deployer to specify a container’s permissions to access protected functions. When the pod creates the container, it configures it to allow these permissions and block all others. The cluster will only deploy the pod if the permissions it requests are permitted by a corresponding SCC.
-A security context constraint (SCC), defined in a cluster, enables an administrator to control pod permissions, which manage containers’ access to protected Linux functions. Similarly to how role-based access control (RBAC) manages users’ access to a cluster’s resources, an SCC manages pods’ access to Linux functions.
By default, a pod is assigned an SCC named restricted that blocks access to protected functions in OpenShift v4.10 or earlier. Instead, in OpenShift v4.11 and later, the restricted-v2 SCC is used by default. For an application to access protected functions, the cluster must make an SCC that allows it to be available to the pod.
SCC grants access to protection functions
While an SCC grants access to protected functions, each pod needing access must request it. To request access to the functions its application needs, a pod specifies those permissions in the security context field of the pod manifest. The manifest also specifies the service account that should be able to grant this access.
When the manifest is deployed, the cluster associates the pod with the service account associated with the SCC. For the cluster to deploy the pod, the SCC must grant the permissions that the pod requests.
One way to envision this relationship is to think of the SCC as a lock that protects Linux functions, while the manifest is the key. The pod is allowed to deploy only if the key fits.
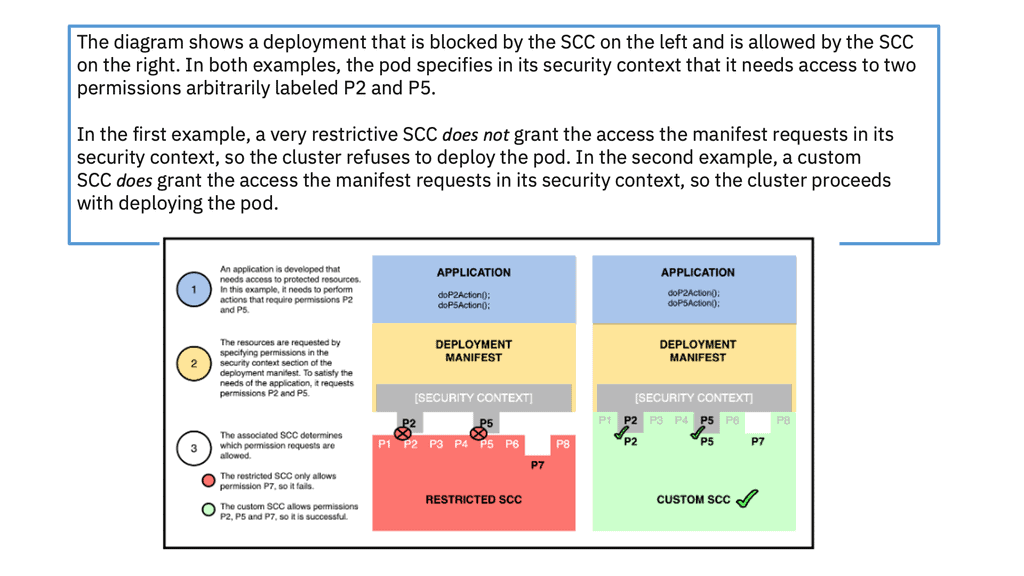
A final note: Security context constraint
When your application is deployed to OpenShift in a virtual data center design, the default security model will enforce that it is run using an assigned Unix user ID unique to the project for which you are deploying it. Now, we can prevent images from being run as the Unix root user. When hosting an application using OpenShift, the user ID that a container runs as will be assigned based on which project it is running in.
Containers cannot run as the root user by default—a big win for security. SCC also allows you to set different restrictions and security configurations for PODs.
So, instead of allowing your image to run as the root, which is a considerable security risk, you should run as an arbitrary user by specifying an unprivileged USER, setting the appropriate permissions on files and directories, and configuring your application to listen on unprivileged ports.
OpenShift Network Security
SCC defaults access:
Security context constraints let you drop privileges by default, which is essential and still the best practice. Red Hat OpenShift security context constraints (SCCs) ensure that no privileged containers run on OpenShift worker nodes by default—another big win for security. Access to the host network and host process IDs are denied by default. Users with the required permissions can adjust the default SCC policies to be more permissive.
So, when considering SCC, consider SCC admission controllers as restricting POD access, similar to how RBAC restricts user access. To control the behavior of pods, we have security context constraints (SCCs). These cluster-level resources define what resources pods can access and provide additional control.
Security context constraints let you drop privileges by default, which is a critical best practice. With Red Hat OpenShift SCCs, no privileged containers run on OpenShift worker nodes. Access to the host network and host process IDs is denied by default, a big win for OpenShift security.
Restricted security context constraints (SCCs):
A few SCCs are available by default, and you may have the head of the restricted SCC. By default, all pods, except those for builds and deployments, use a default service account assigned by the restricted SCC, which doesn’t allow privileged containers – that is, those running under the root user and listening on privileged ports are ports under <1024. SCC can be used to manage the following:
- Privilege Mode: This setting allows or denies a container from running in privilege mode. As you know, privilege mode bypasses any restriction such as control groups, Linux capabilities, secure computing profiles,
- Privilege Escalation: This setting enables or disables privilege escalation inside the container ( all privilege escalation flags)
- Linux Capabilities: This setting allows the addition or removal of specific Linux capabilities
- Seccomp profile – this setting shows which secure computing profiles are used in a pod.
- Root-only file system: this makes the root file system read-only
The goal is to assign the fewest possible capabilities for a pod to function fully. This least-privileged model ensures that pods can’t perform tasks on the system that aren’t related to their application’s proper function. The default value for the privileged option is False; setting the privileged option to True is the same as giving the pod the capabilities of the root user on the system. Although doing so shouldn’t be common practice, privileged pods can be helpful under certain circumstances.
OpenShift Network Security: Authentication
Authentication refers to the process of validating one’s identity. Usually, users aren’t created in OpenShift but are provided by an external entity, such as the LDAP server or GitHub. The only part where OpenShift steps in is authorization—determining roles and permissions for a user.
OpenShift supports integration with various identity management solutions in corporate environments, such as FreeIPA/Identity Management, Active Directory, GitHub, Gitlab, OpenStack Keystone, and OpenID.
OpenShift Network Security: Users and identities
A user is any human actor who can request the OpenShift API to access resources and perform actions. Users are typically created in an external identity provider, usually a corporate identity management solution such as Lightweight Directory Access Protocol (LDAP) or Active Directory.
To support multiple identity providers, OpenShift relies on the concept of identities as a bridge between users and identity providers. A new user and identity are created upon the first login by default. There are four ways to map users to identities:
OpenShift Network Security: Service accounts
Service accounts allow us to control API access without sharing users’ credentials. Pods and other non-human actors use them to perform various actions and are a central vehicle by which their access to resources is managed. By default, three service accounts are created in each project:
OpenShift Network Security: Authorization and role-based access control
Authorization in OpenShift is built around the following concepts:
Rules: Sets of actions allowed to be performed on specific resources.
Roles are collections of rules that allow them to be applied to a user according to a specific user profile. They can be used either at the cluster or project level.
Role bindings are associations between users or groups and roles. A given user or group can be associated with multiple roles.
If pre-defined roles aren’t sufficient, you can always create custom roles with just the specific rules you need.