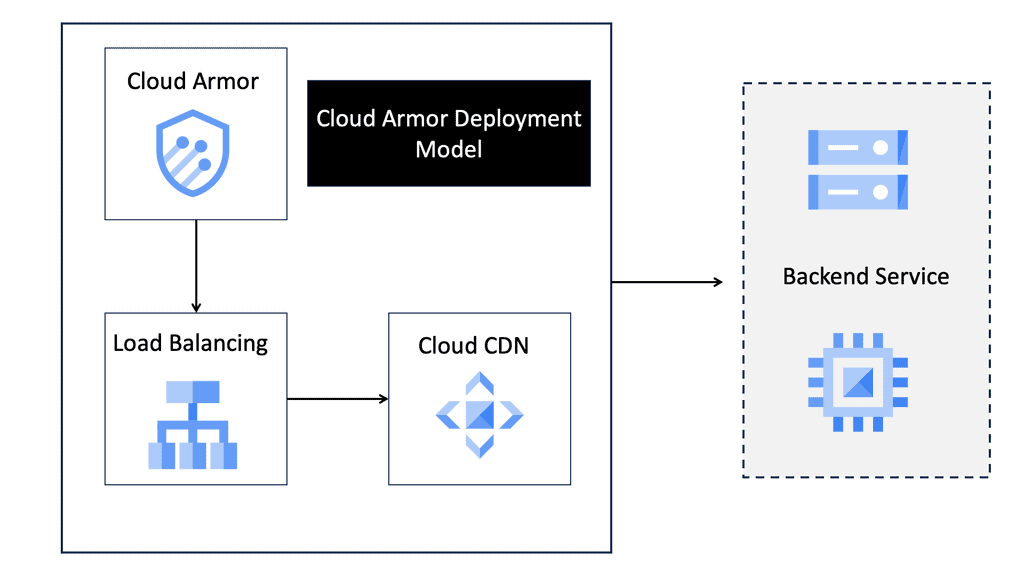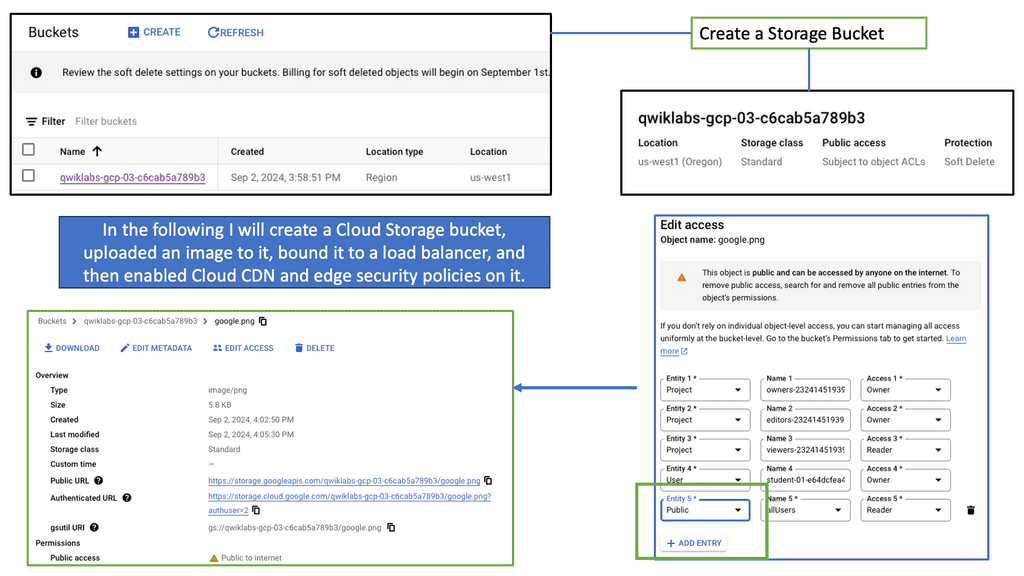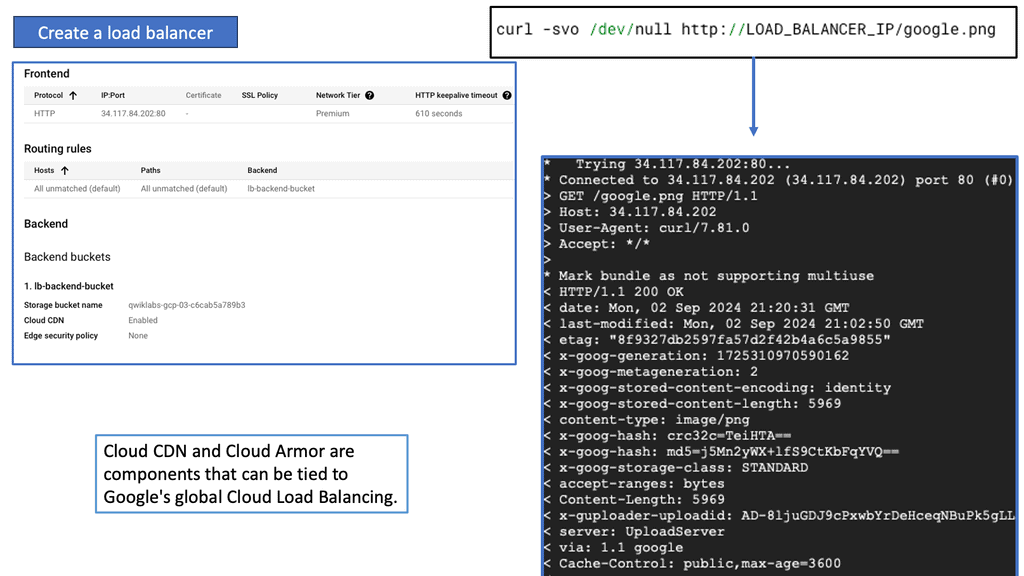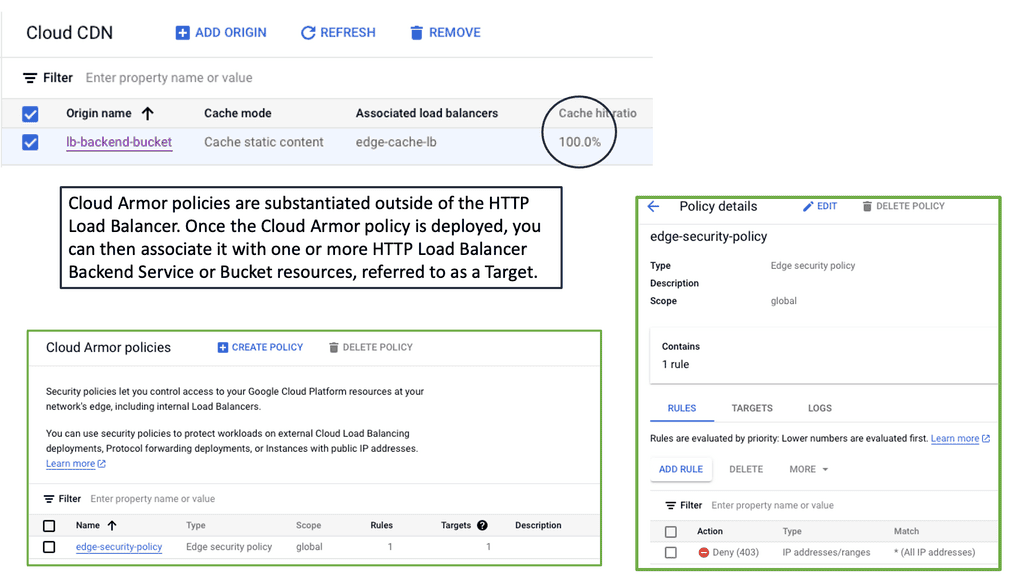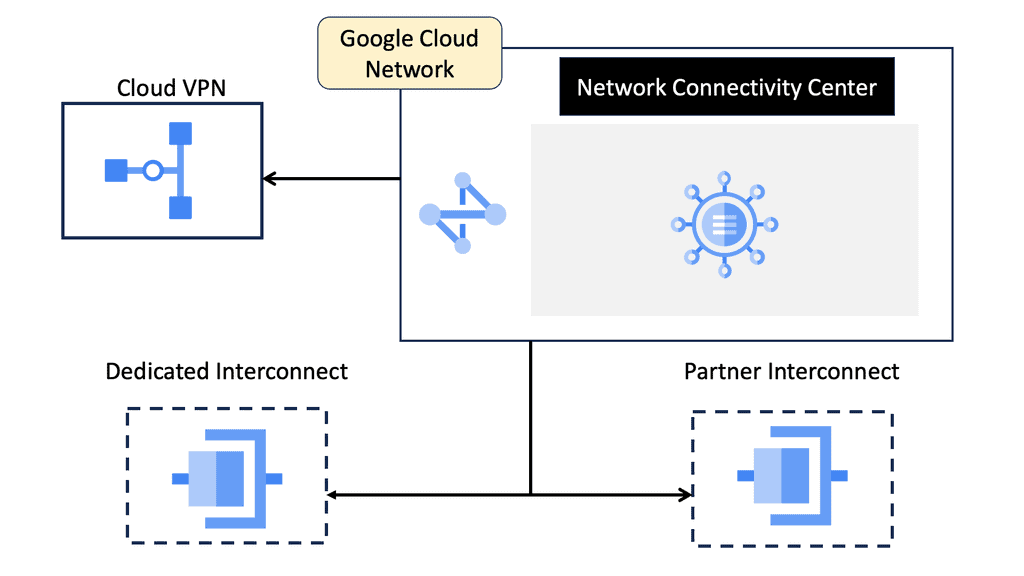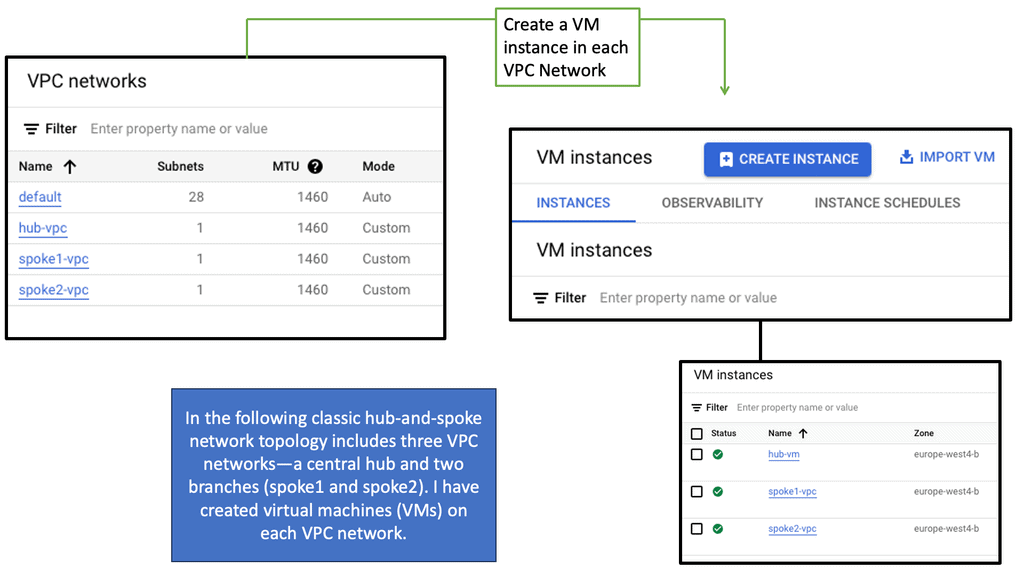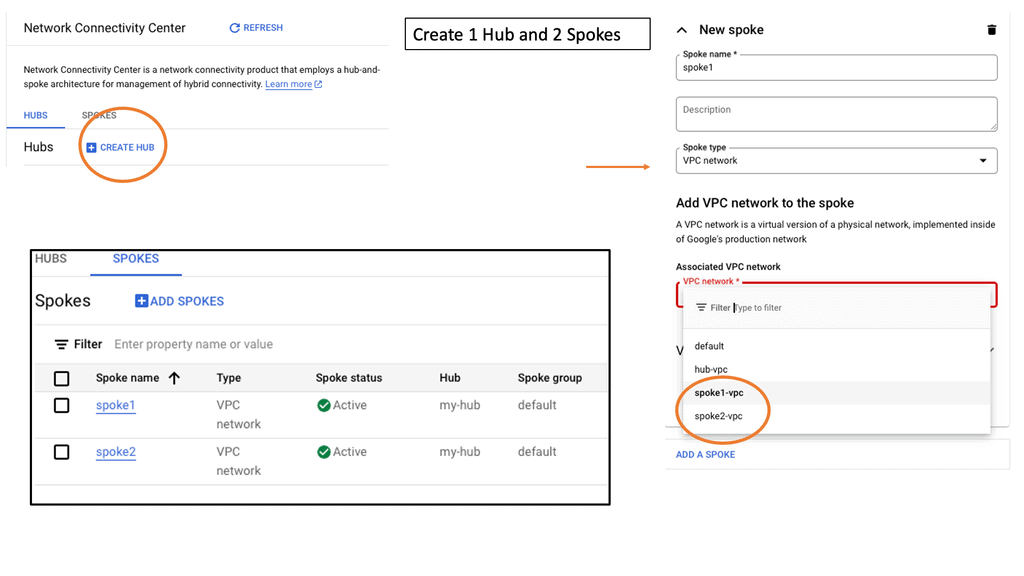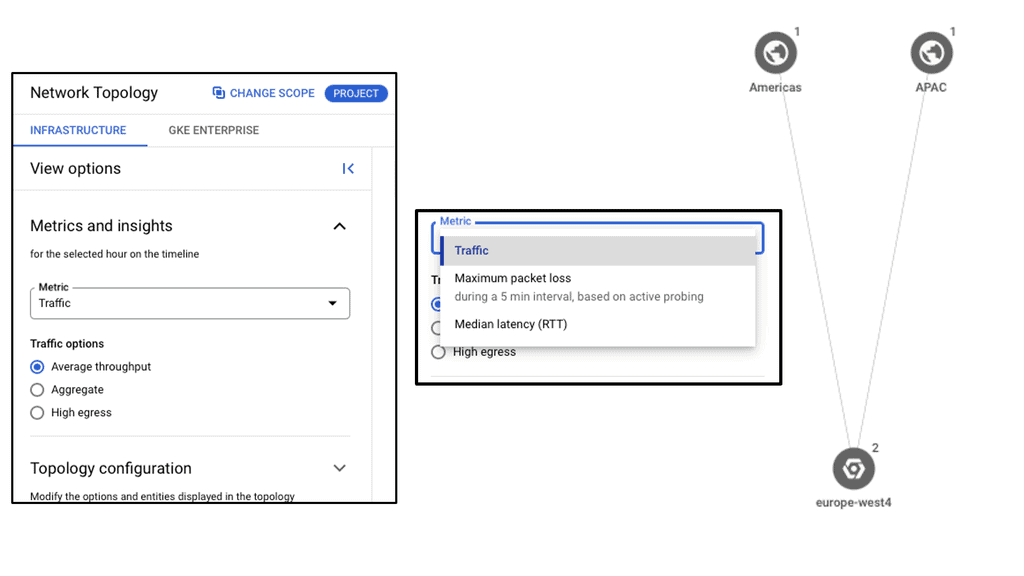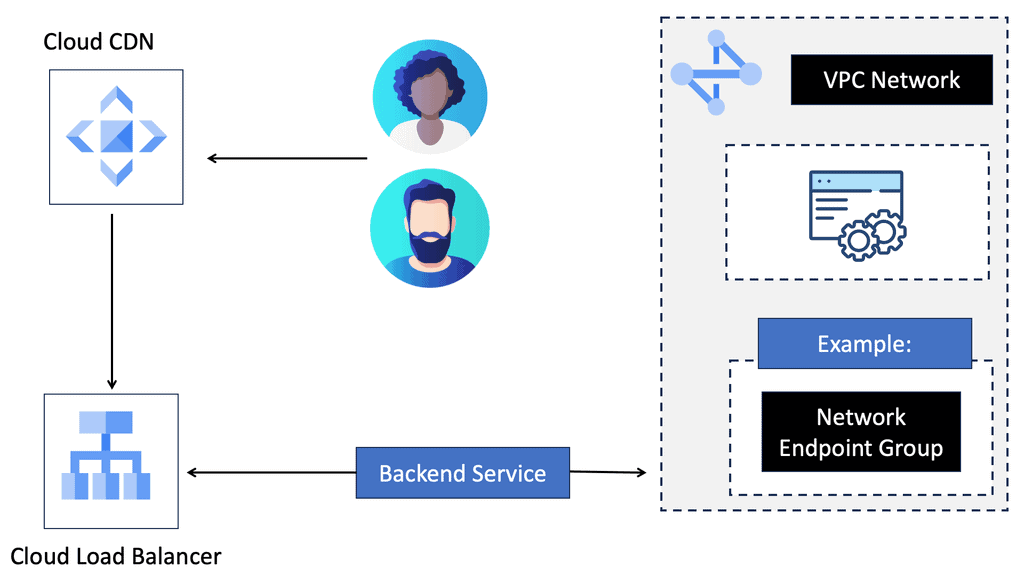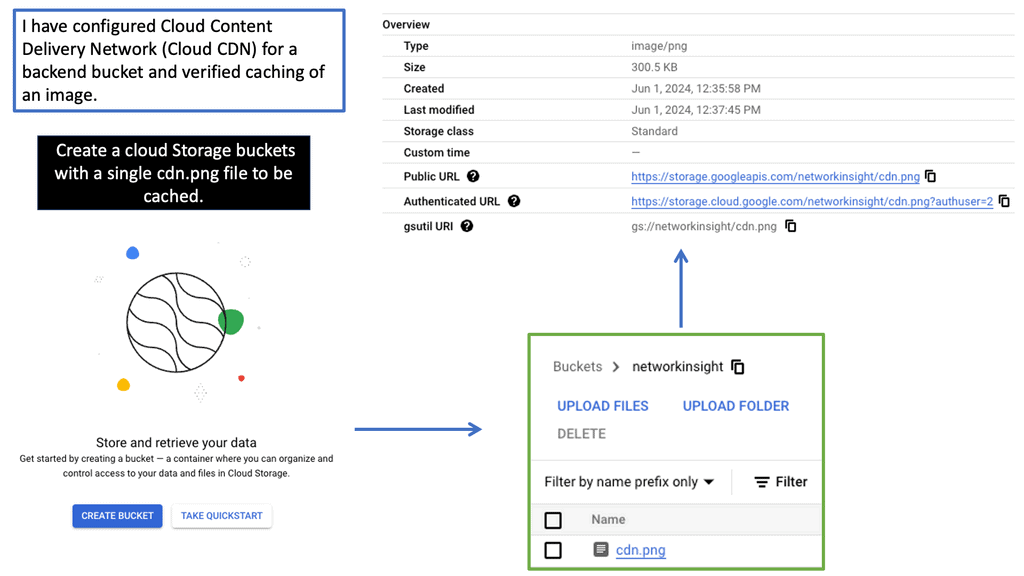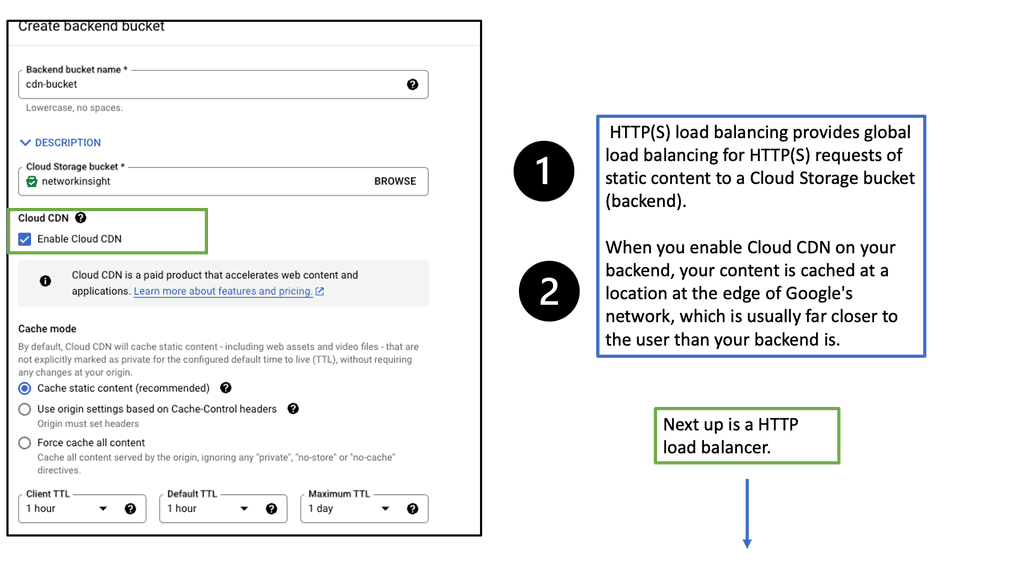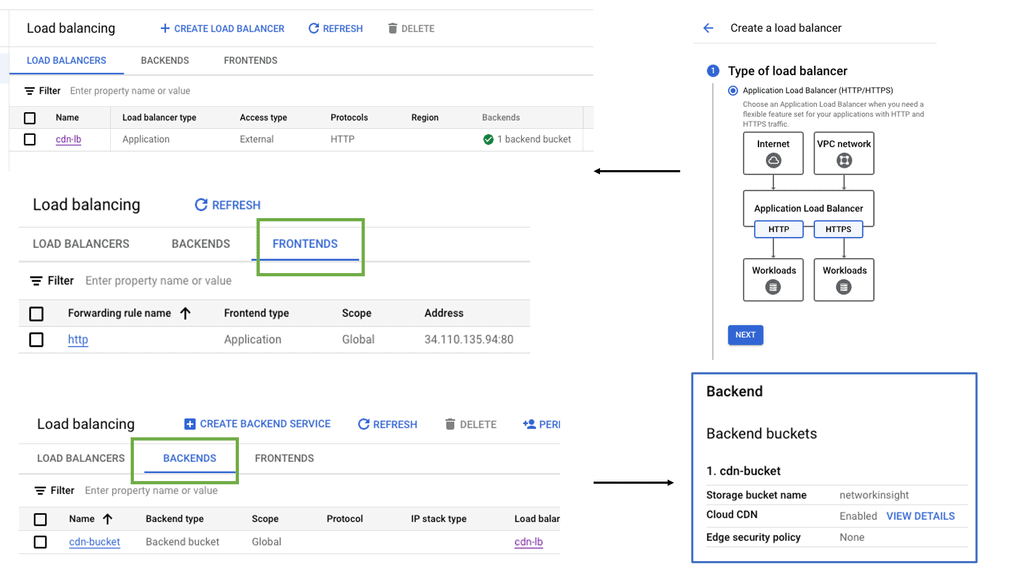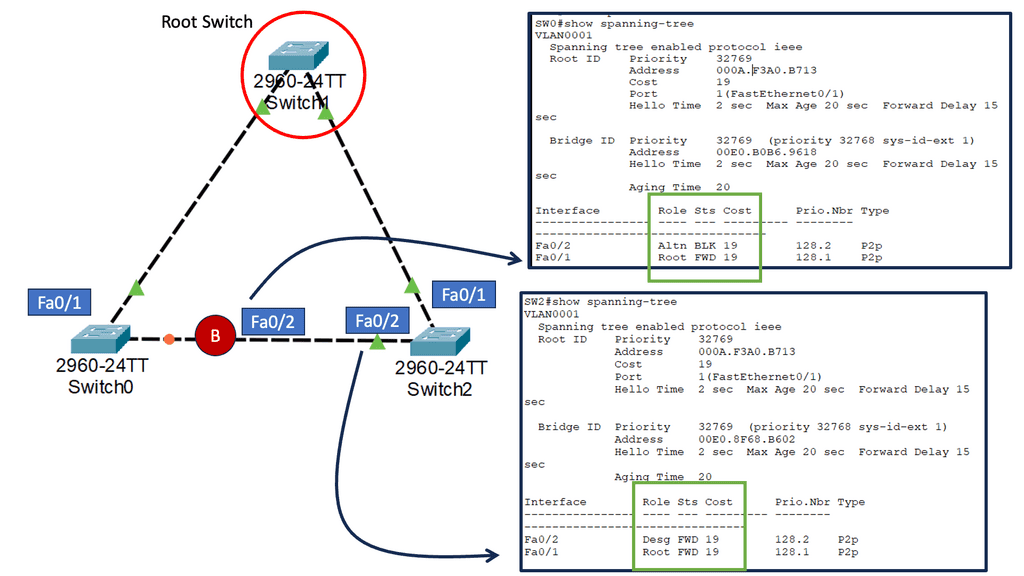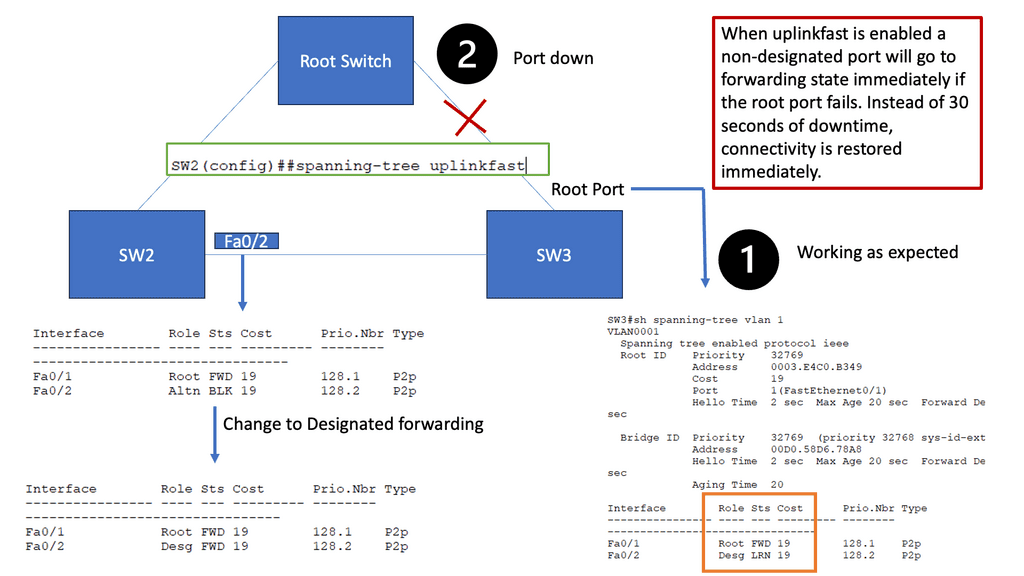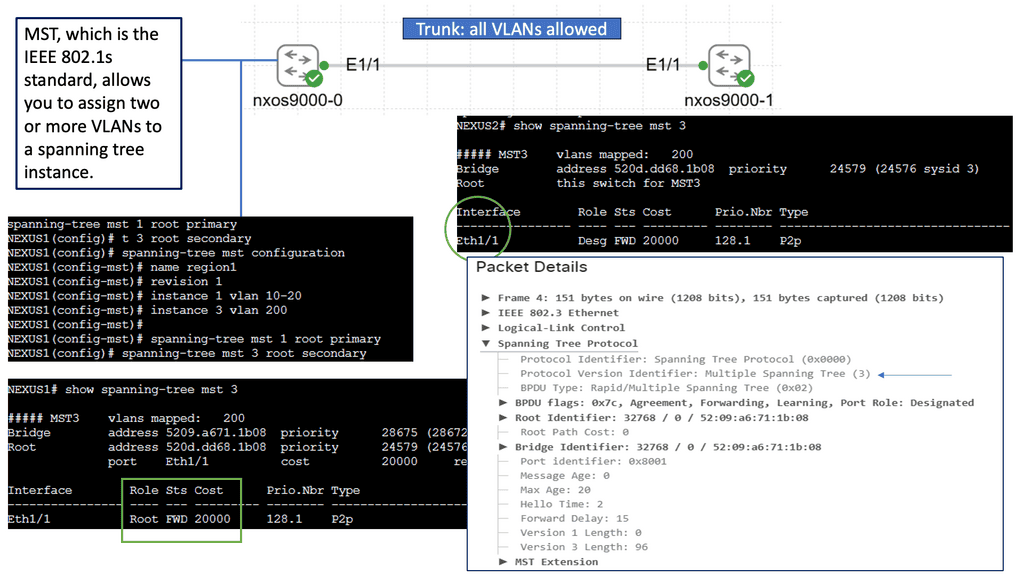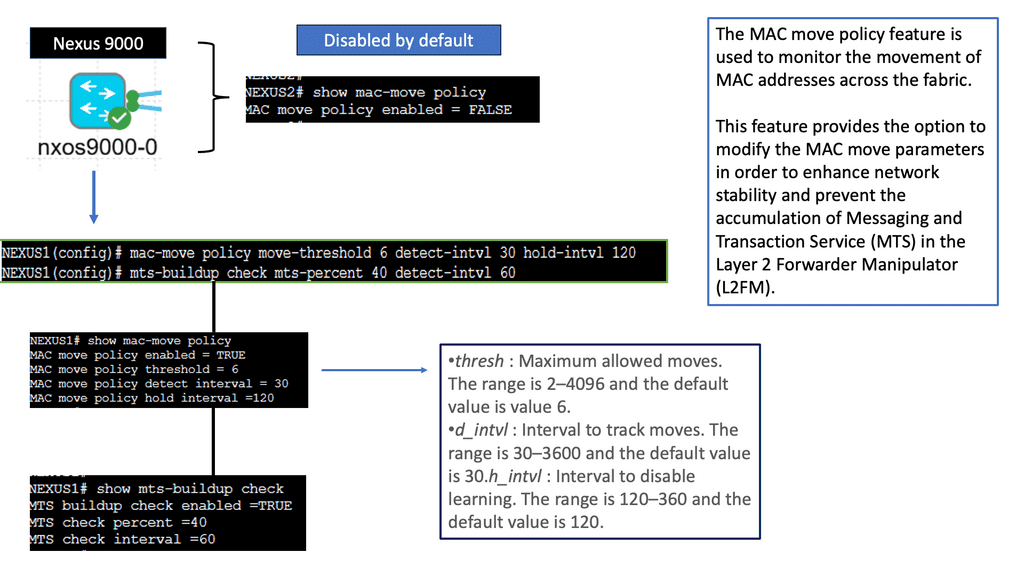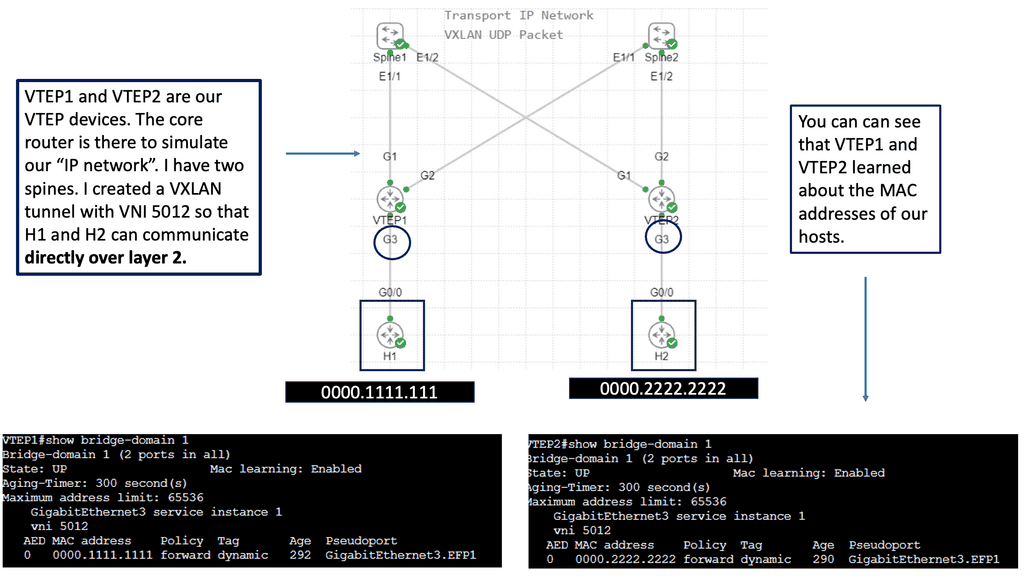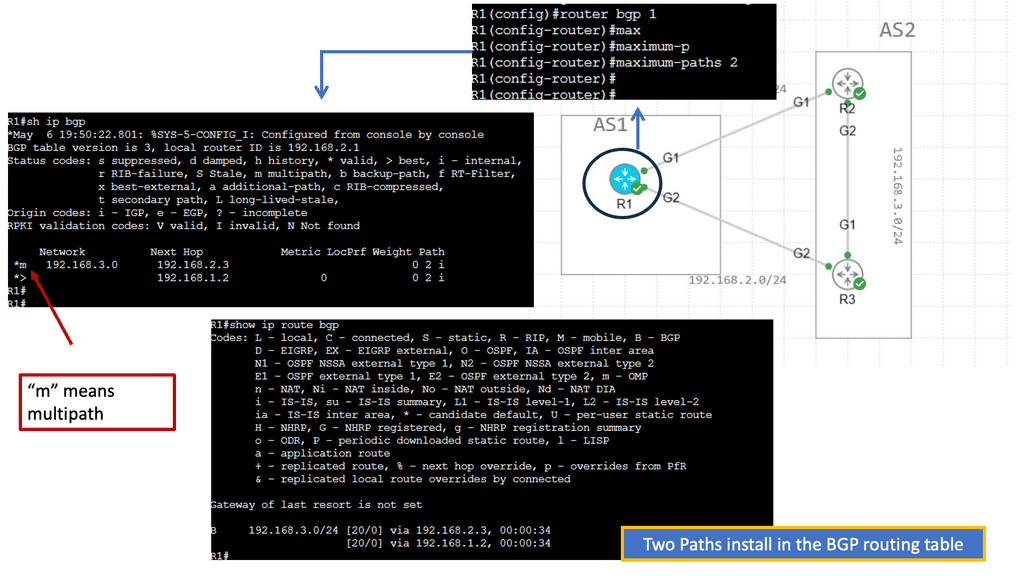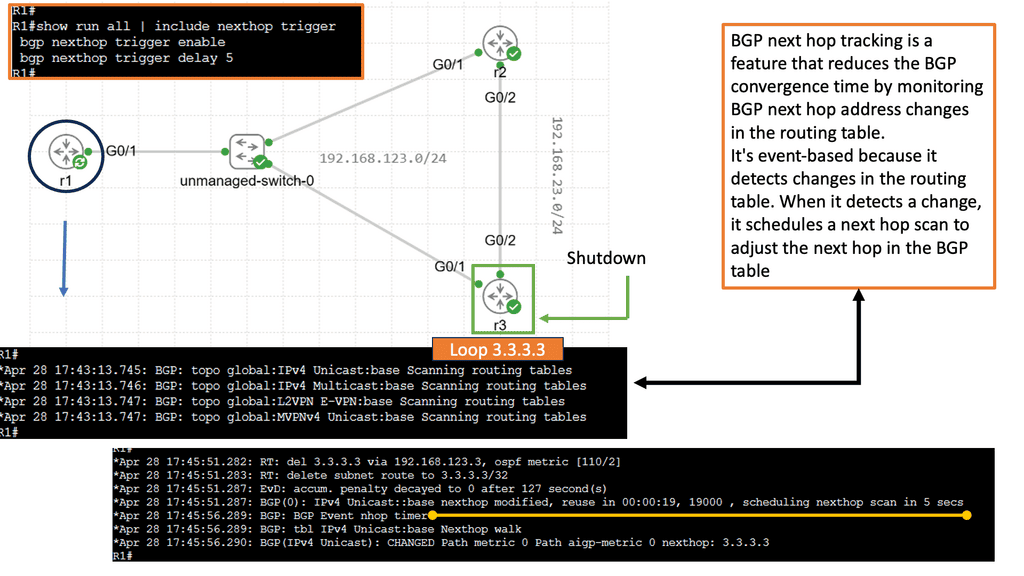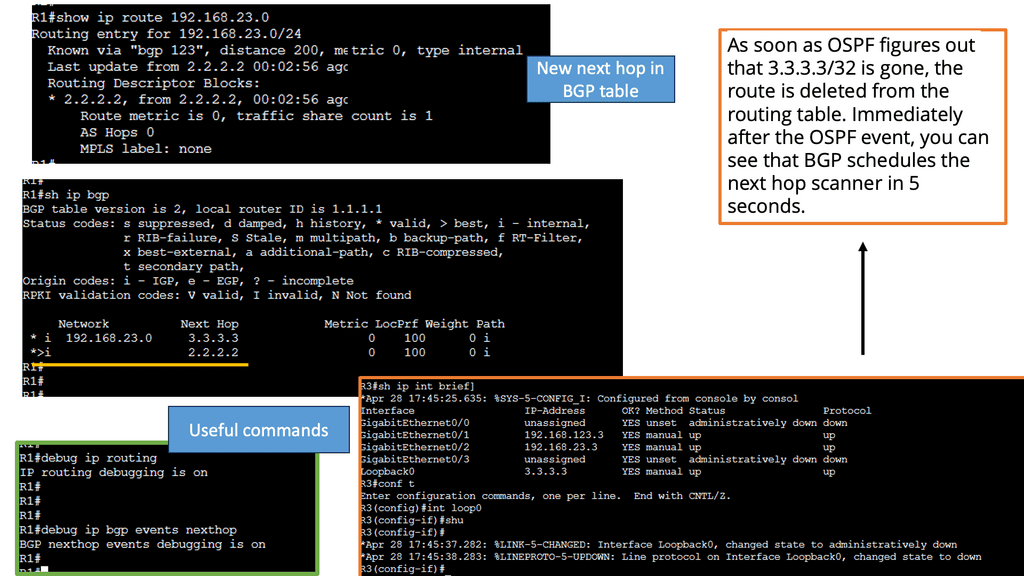
Discussing WAN SDN
1: – ) Traditional WANs have long been plagued by various limitations, such as complexity, lack of agility, and high operational costs. These legacy networks typically rely on manual configurations and proprietary hardware, making them inflexible and time-consuming. SDN brings a paradigm shift to WANs by decoupling the network control plane from the underlying infrastructure. With centralized control and programmability, SDN enables network administrators to manage and orchestrate their WANs through a single interface, simplifying network operations and promoting agility.
2: – ) At its core, WAN SDN separates the control plane from the data plane, allowing network administrators to manage network traffic dynamically and programmatically. This separation leads to more efficient network management, reducing the complexity associated with traditional network infrastructures. With WAN SDN, businesses can optimize traffic flow, enhance security, and reduce operational costs by leveraging centralized control and automation.
3: – ) One of the key advantages of SDN in WANs is its inherent flexibility and scalability. With SDN, network administrators can dynamically allocate bandwidth, reroute traffic, and prioritize applications based on real-time needs. This level of granular control allows organizations to optimize their network resources efficiently and adapt to changing demands.
4: – ) SDN brings enhanced security features to WANs through centralized policy enforcement and monitoring. By abstracting network control, SDN allows for consistent security policies across the entire network, minimizing vulnerabilities and ensuring better threat detection and mitigation. Additionally, SDN enables rapid network recovery and failover mechanisms, enhancing overall resilience.
**Key Benefits of WAN SDN**
1. **Scalability and Flexibility**: WAN SDN enables networks to adapt quickly to changing demands without the need for significant hardware investments. This flexibility is crucial for organizations looking to scale their operations efficiently.
2. **Improved Network Performance**: By optimizing traffic routing and prioritizing critical applications, WAN SDN ensures that networks operate at peak performance levels. This capability is particularly beneficial for businesses with high bandwidth demands.
3. **Enhanced Security**: WAN SDN allows for the implementation of robust security measures, including automated threat detection and response. This proactive approach to security helps protect sensitive data and maintain compliance with industry regulations.
**Application Challenges**
Compared to a network-centric model, business intent-based WAN networks have great potential. By using a WAN architecture, applications can be deployed and managed more efficiently. However, application services topologies must replace network topologies. Supporting new and existing applications on the WAN is a common challenge for network operations staff. Applications such as these consume large amounts of bandwidth and are extremely sensitive to variations in bandwidth quality. Improving the WAN environment for these applications is more critical due to jitter, loss, and delay.
**WAN SLA**
In addition, cloud-based applications such as Enterprise Resource Planning (ERP) and Customer Relationship Management (CRM) are increasing bandwidth demands on the WAN. As cloud applications require increasing bandwidth, provisioning new applications and services is becoming increasingly complex and expensive. In today’s business environment, WAN routing and network SLAs are controlled by MPLS L3VPN service providers. As a result, they are less able to adapt to new delivery methods, such as cloud-based and SaaS-based applications.
These applications could take months to implement in service providers’ environments. These changes can also be expensive for some service providers, and some may not be made at all. There is no way to instantiate VPNs independent of underlying transport since service providers control the WAN core. Implementing differentiated service levels for different applications becomes challenging, if not impossible.
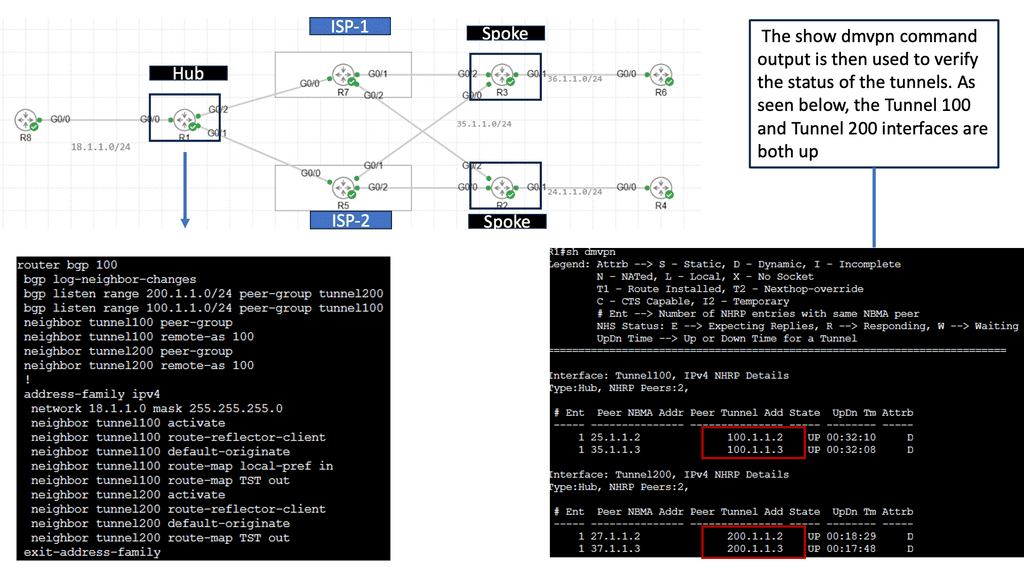
WAN SDN Technology: DMVPN
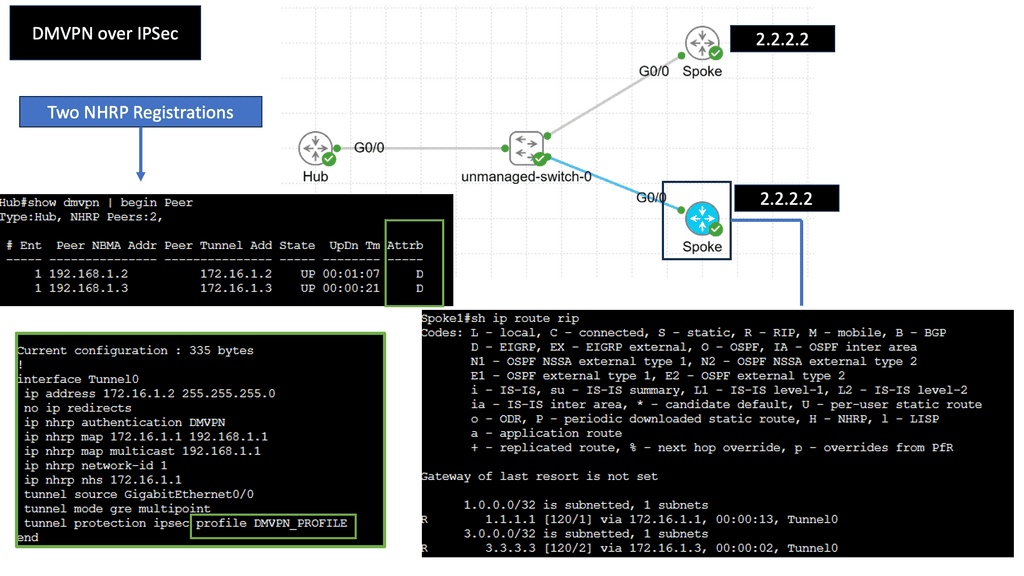
DMVPN is a Cisco-developed solution that enables the creation of virtual private networks over public or private networks. Unlike traditional VPNs that require point-to-point connections, DMVPN utilizes a hub-and-spoke architecture, allowing for dynamic and scalable network deployments. DMVPN simplifies network management and reduces administrative overhead by leveraging multipoint GRE tunnels.
– Multipoint GRE Tunnels: At the core of DMVPN lies the concept of multipoint GRE tunnels. These tunnels create a virtual network, connecting multiple sites while encapsulating packets in GRE headers. This enables efficient traffic routing between sites, reducing the complexity and overhead associated with traditional point-to-point VPNs.
– Next-Hop Resolution Protocol (NHRP): NHRP plays a crucial role in DMVPN by dynamically mapping tunnel IP addresses to physical addresses. It allows for the efficient resolution of next-hop information, eliminating the need for static routes. NHRP also enables on-demand tunnel establishment, improving scalability and reducing administrative overhead.
– IPsec Encryption: DMVPN utilizes IPsec encryption to ensure secure communication over the VPN. IPsec provides confidentiality, integrity, and authentication of data, making it ideal for protecting sensitive information transmitted over the network. With DMVPN, IPsec is applied dynamically per-tunnelly, enhancing flexibility and scalability.



DMVPN over IPSec
Understanding DMVPN & IPSec
IPsec, a widely adopted security protocol, is integral to DMVPN deployments. It provides the cryptographic framework necessary for securing data transmitted over the network. By leveraging IPsec, DMVPN ensures the transmitted information’s confidentiality, integrity, and authenticity, protecting sensitive data from unauthorized access and tampering.
Firstly, the dynamic mesh topology eliminates the need for complex hub-and-spoke configurations, simplifying network management and reducing administrative overhead. Additionally, DMVPN’s scalability enables seamless integration of new sites and facilitates rapid expansion without compromising performance. Furthermore, the inherent flexibility ensures optimal routing, load balancing, and efficient bandwidth utilization.

Example WAN Techniques:
Understanding Virtual Routing and Forwarding
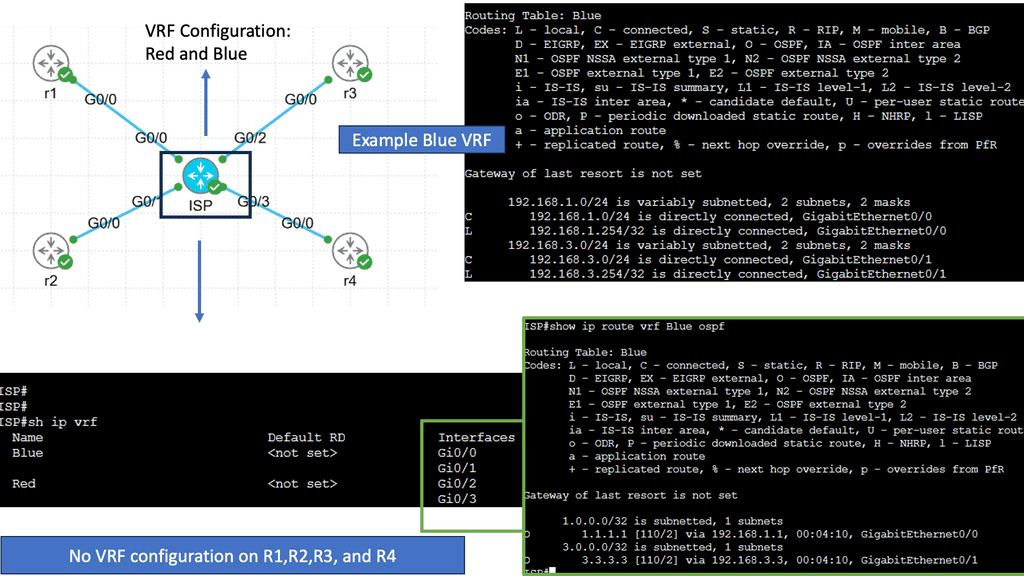
VRF is a technology that enables the creation of multiple virtual routing tables within a single physical router. Each VRF instance acts as an independent router with its routing table, interfaces, and forwarding decisions. This separation allows different networks or customers to coexist on the same physical infrastructure while maintaining complete isolation.
One critical advantage of VRF is its ability to provide network segmentation. By dividing a physical router into multiple VRF instances, organizations can isolate their networks, ensuring that traffic from one VRF does not leak into another. This enhances security and provides a robust framework for multi-tenancy scenarios.
Use Cases for VRF
VRF finds application in various scenarios, including:
1. Service Providers: VRF allows providers to offer their customers virtual private network (VPN) services. Each customer can have their own VRF, ensuring their traffic remains separate and secure.
2. Enterprise Networks: VRF can segregate different organizational departments, creating independent virtual networks.
3. Internet of Things (IoT): With the proliferation of IoT devices, VRF can create separate routing domains for different IoT deployments, improving scalability and security.

Understanding Policy-Based Routing
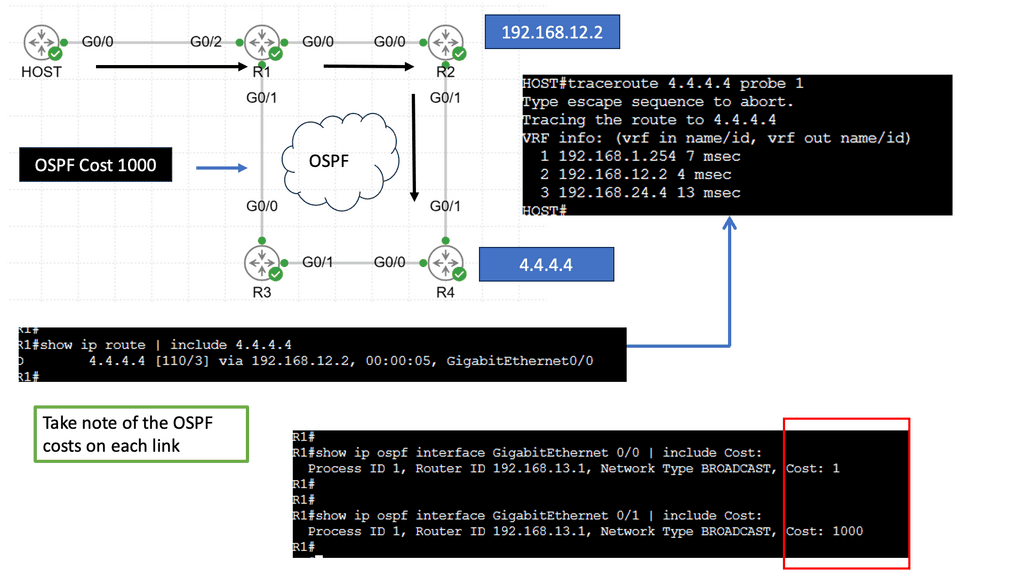
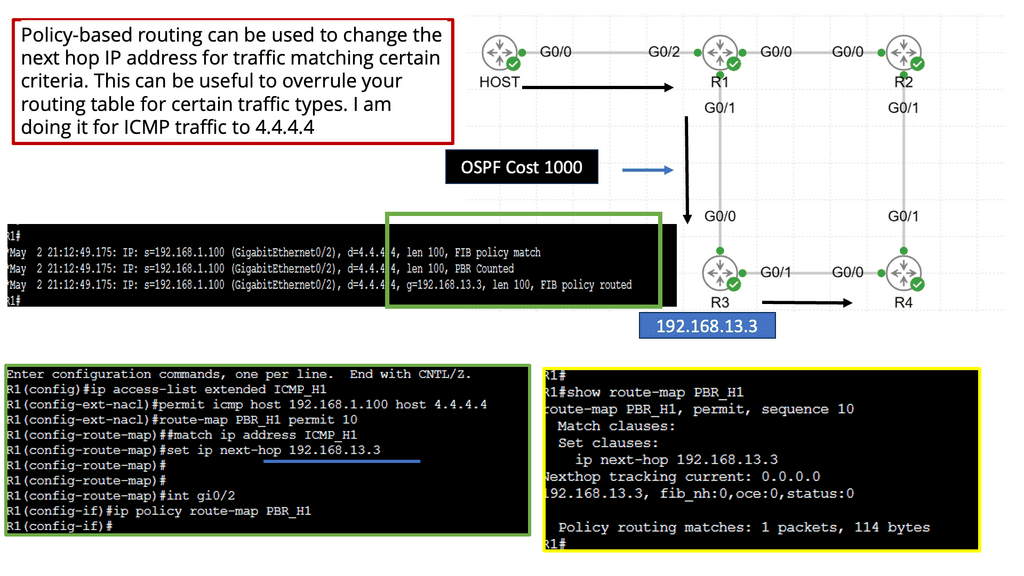
Policy-based Routing, at its core, involves manipulating routing decisions based on predefined policies. Unlike traditional routing protocols that rely solely on destination addresses, PBR considers additional factors such as source IP, ports, protocols, and even time of day. By implementing PBR, network administrators gain flexibility in directing traffic flows to specific paths based on specified conditions.
The adoption of Policy Based Routing brings forth a multitude of benefits. Firstly, it enables efficient utilization of network resources by allowing administrators to prioritize or allocate bandwidth for specific applications or user groups. Additionally, PBR enhances security by allowing traffic redirection to dedicated firewalls or intrusion detection systems. Furthermore, PBR facilitates load balancing and traffic engineering, ensuring optimal performance across the network.
Implementing Policy-Based Routing
To implement PBR, network administrators must follow a series of steps. Firstly, the traffic classification criteria are defined by specifying the match criteria based on desired conditions. Secondly, create route maps that outline the actions for matched traffic. These actions may include altering the next-hop address, setting specific Quality of Service (QoS) parameters, or redirecting traffic to a different interface. Lastly, the route maps should be applied to the appropriate interfaces or specific traffic flows.
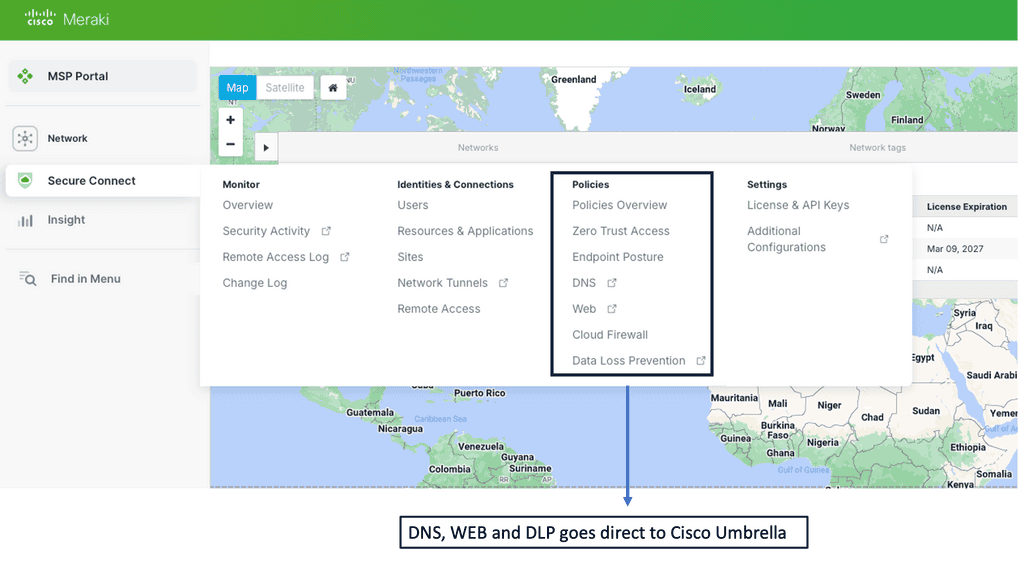
Example SD WAN Product: Cisco Meraki
**Seamless Cloud Management**
One of the standout features of Cisco Meraki is its seamless cloud management. Unlike traditional network systems, Meraki’s cloud-based platform allows IT administrators to manage their entire network from a single, intuitive dashboard. This centralization not only simplifies network management but also provides real-time visibility and control over all connected devices. With automatic updates and zero-touch provisioning, businesses can ensure their network is always up-to-date and secure without the need for extensive manual intervention.
 **Cutting-Edge Security Features**
**Cutting-Edge Security Features**
Security is at the core of Cisco Meraki’s suite of products. With cyber threats becoming more sophisticated, Meraki offers a multi-layered security approach to protect sensitive data. Features such as Advanced Malware Protection (AMP), Intrusion Prevention System (IPS), and secure VPNs ensure that the network is safeguarded against intrusions and malware. Additionally, Meraki’s security appliances are designed to detect and mitigate threats in real-time, providing businesses with peace of mind knowing their data is secure.
**Scalability and Flexibility**
As businesses grow, so do their networking needs. Cisco Meraki’s scalable solutions are designed to grow with your organization. Whether you are expanding your office space, adding new branches, or integrating more IoT devices, Meraki’s flexible infrastructure can easily adapt to these changes. The platform supports a wide range of devices, from access points and switches to security cameras and mobile device management, making it a comprehensive solution for various networking requirements.
**Enhanced User Experience**
Beyond security and management, Cisco Meraki enhances the user experience by ensuring reliable and high-performance network connectivity. Features such as intelligent traffic shaping, load balancing, and seamless roaming between access points ensure that users enjoy consistent and fast internet access. Furthermore, Meraki’s analytics tools provide insights into network usage and performance, allowing businesses to optimize their network for better efficiency and user satisfaction.
Performance at the WAN Edge
Understanding Performance-Based Routing
Performance-based routing is a dynamic approach to network traffic management that prioritizes route selection based on real-time performance metrics. Instead of relying on traditional static routing protocols, performance-based routing algorithms assess the current conditions of network paths, such as latency, packet loss, and available bandwidth, to make informed routing decisions. By dynamically adapting to changing network conditions, performance-based routing aims to optimize traffic flow and enhance overall network performance.
The adoption of performance-based routing brings forth a multitude of benefits for businesses.
1- Firstly, it enhances network reliability by automatically rerouting traffic away from congested or underperforming paths, minimizing the chances of bottlenecks and service disruptions.
2- Secondly, it optimizes application performance by intelligently selecting the best path based on real-time network conditions, thus reducing latency and improving end-user experience. A
3- Additionally, performance-based routing allows for efficient utilization of available network resources, maximizing bandwidth utilization and cost-effectiveness.
Implementation Details:
Implementing performance-based routing requires a thoughtful approach. Firstly, businesses must invest in monitoring tools that provide real-time insights into network performance metrics. These tools can range from simple latency monitoring to more advanced solutions that analyze packet loss and bandwidth availability.
Once the necessary monitoring infrastructure is in place, configuring performance-based routing algorithms within network devices becomes the next step. This involves setting up rules and policies that dictate how traffic should be routed based on specific performance metrics.
Lastly, regular monitoring and fine-tuning performance-based routing configurations are essential to ensure optimal network performance.
WAN Performance Parameters
TCP Performance Parameters
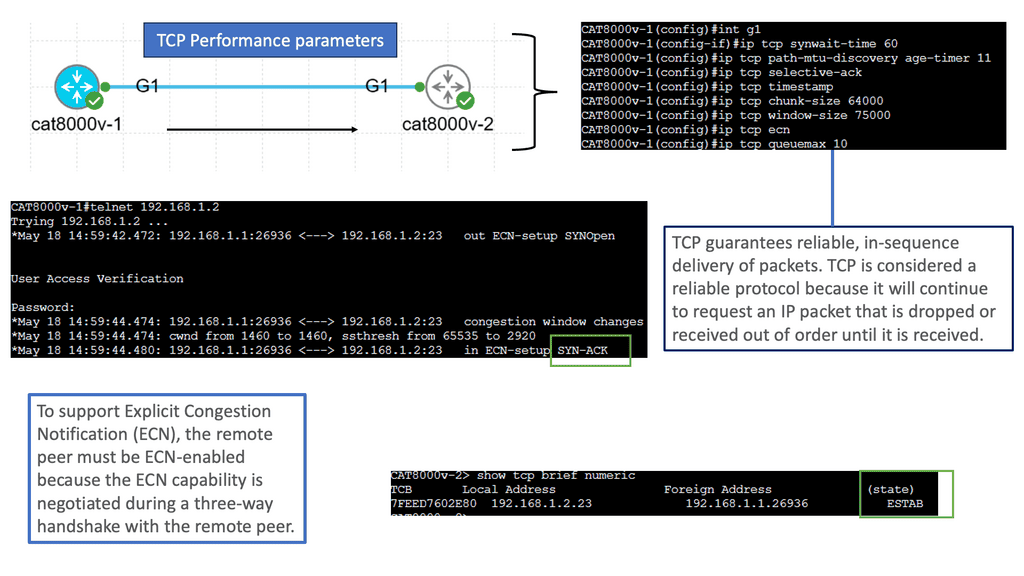
TCP (Transmission Control Protocol) is the backbone of modern Internet communication, ensuring reliable data transmission across networks. Behind the scenes, TCP performance is influenced by several key parameters that can significantly impact network efficiency.
TCP performance parameters govern how TCP behaves in various network conditions. These parameters can be fine-tuned to adapt TCP’s behavior to specific network characteristics, such as latency, bandwidth, and congestion. By adjusting these parameters, network administrators and system engineers can optimize TCP performance for better throughput, reduced latency, and improved overall network efficiency.
Congestion Control Algorithms: Congestion control algorithms are crucial in TCP performance. They monitor network conditions, detect congestion, and adjust TCP’s sending rate accordingly. Popular algorithms like Reno, Cubic, and BBR implement different strategies to handle congestion, balancing fairness and efficiency. Understanding these algorithms and their impact on TCP behavior is essential for maintaining a stable and responsive network.
Window Size and Bandwidth Delay Product: The window size parameter, often called the congestion window, determines the amount of data that can be sent before receiving an acknowledgment. The bandwidth-delay product should set the window size, a value calculated by multiplying the available bandwidth with the round-trip time (RTT). Adjusting the window size to match the bandwidth-delay product ensures optimal data transfer and prevents underutilization or overutilization of network resources.
Maximum Segment Size (MSS): The Maximum Segment Size is another TCP performance parameter defining the maximum amount of data encapsulated within a single TCP segment. By carefully configuring the MSS, it is possible to reduce packet fragmentation, enhance data transmission efficiency, and mitigate issues related to network overhead.
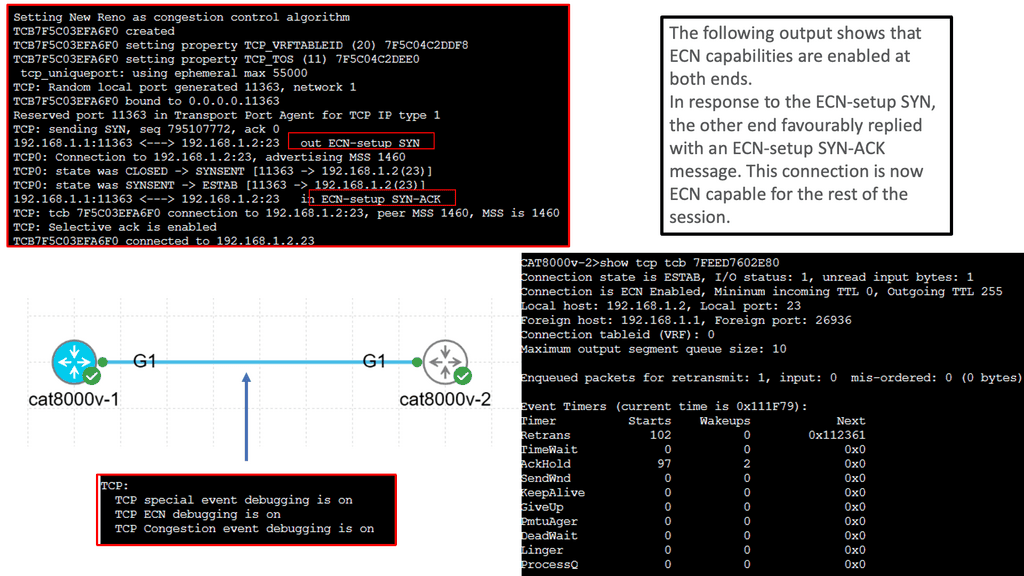
Selective Acknowledgment (SACK): Selective Acknowledgment is a TCP extension that allows the receiver to acknowledge out-of-order segments and provide more precise information about the received data. Enabling SACK can improve TCP performance by reducing retransmissions and enhancing the overall reliability of data transmission.
Understanding TCP MSS
TCP MSS refers to the maximum amount of data encapsulated within a single TCP segment. It represents the most significant data payload that can be transmitted without fragmentation. By limiting the segment size, TCP aims to prevent excessive overhead and ensure efficient data transmission across networks.
Several factors influence the determination of TCP MSS. One crucial aspect is the underlying network infrastructure’s Maximum Transmission Unit (MTU). The MTU represents the maximum packet size that can be transmitted over the network without fragmentation. TCP MSS must be set to a value equal to or lower than the MTU to avoid fragmentation and subsequent performance degradation.
Path MTU Discovery (PMTUD) is a mechanism TCP employs to dynamically determine the optimal MSS value for a given network path. By exchanging ICMP messages with routers along the path, TCP can ascertain the MTU and adjust the MSS accordingly. PMTUD helps prevent packet fragmentation and ensures efficient data transmission across network segments.
The TCP MSS value directly affects network performance. A smaller MSS can increase overhead due to more segments and headers, potentially reducing overall throughput. On the other hand, a larger MSS can increase the risk of fragmentation and subsequent retransmissions, impacting latency and overall network efficiency. Striking the right balance is crucial for optimal performance.

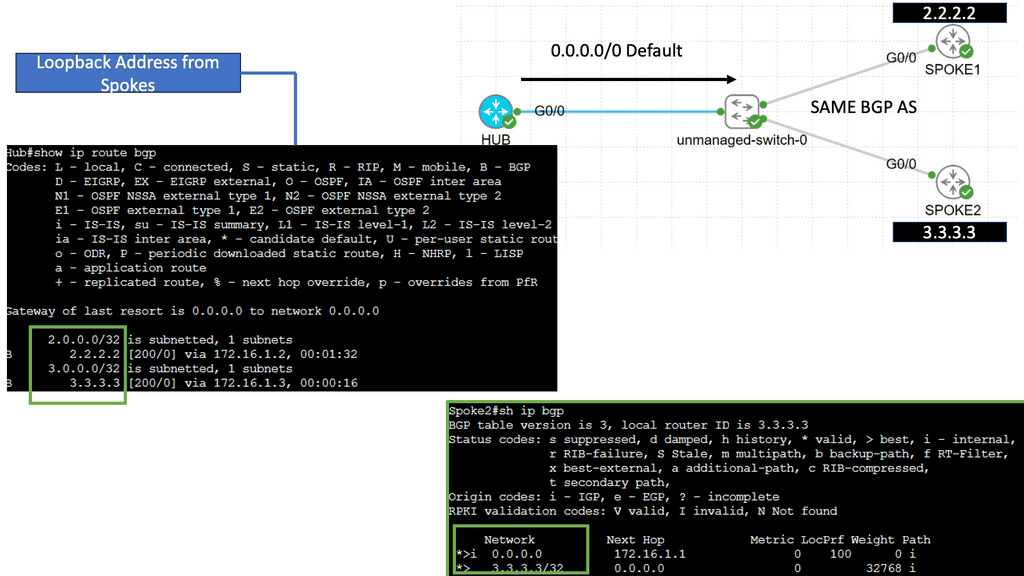
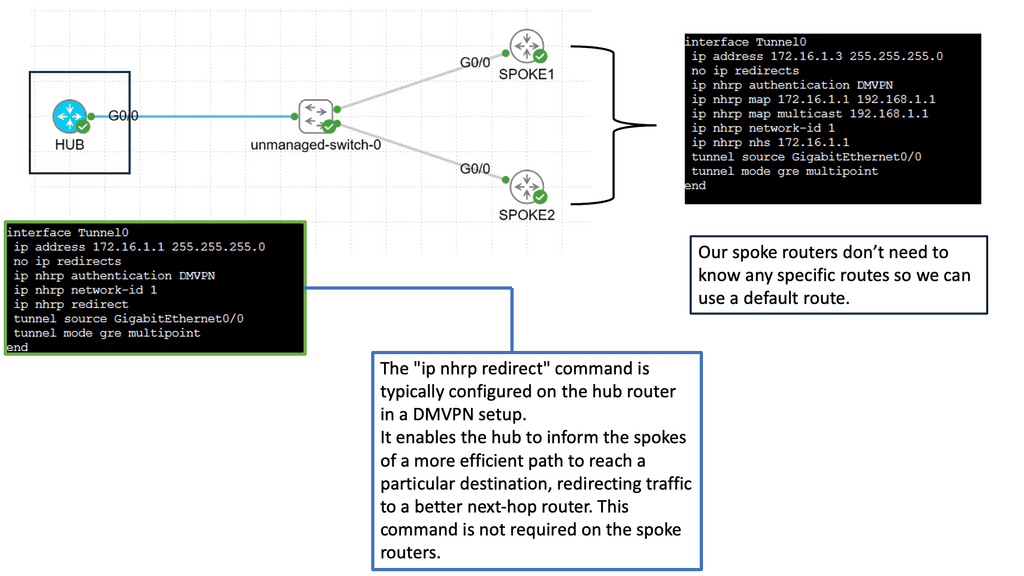
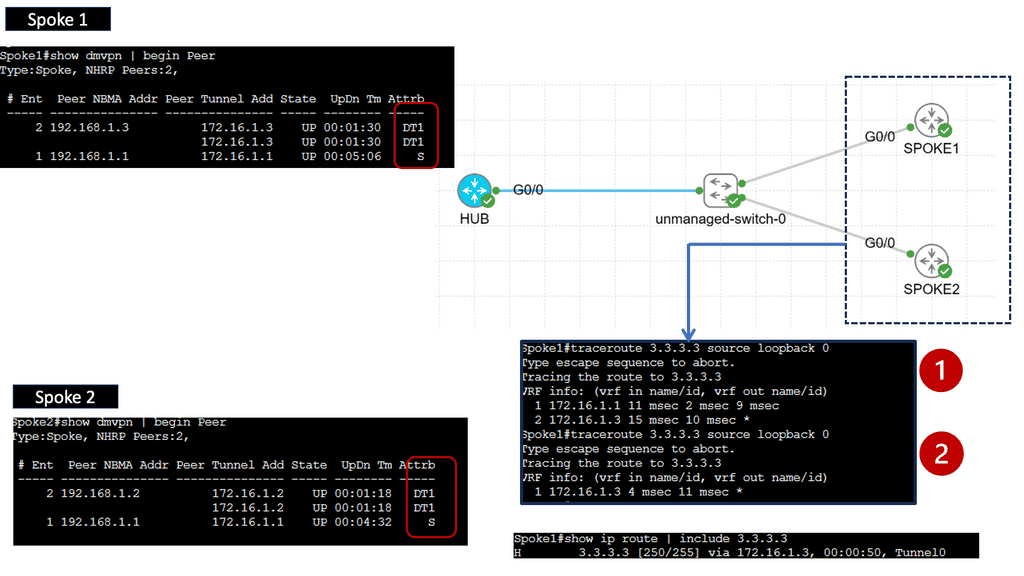
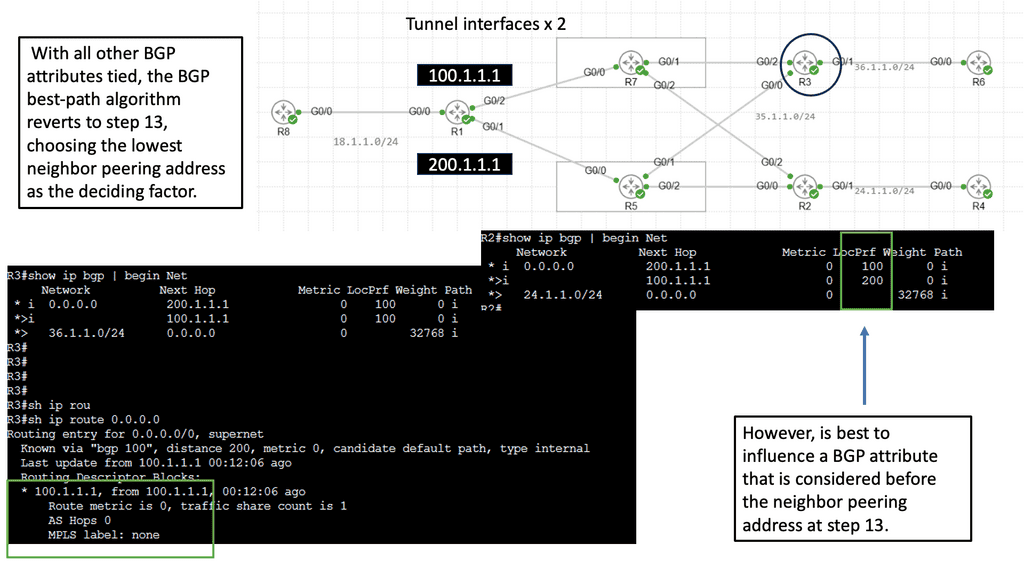
Example WAN Technology: DMVPN Phase 3
Understanding DMVPN Phase 3
DMVPN Phase 3 builds upon the foundation of its predecessors, bringing forth even more advanced features. This section will provide an overview of DMVPN Phase 3, highlighting its main enhancements, such as increased scalability, simplified configuration, and enhanced security protocols.
One of the standout features of DMVPN Phase 3 is its scalability. This section will explain how DMVPN Phase 3 allows organizations to effortlessly add new sites to the network without complex manual configurations. By leveraging multipoint GRE tunnels, DMVPN Phase 3 offers a dynamic and flexible solution that can easily accommodate growing networks.
Example WAN Technology: FlexVPN Site-to-Site Smart Defaults
Understanding FlexVPN Site-to-Site Smart Defaults
FlexVPN Site-to-Site Smart Defaults is a powerful feature that simplifies site-to-site VPN configuration and deployment process. Providing pre-defined templates and configurations eliminates the need for manual configuration, reducing the chances of misconfigurations or human errors. This feature ensures a secure and reliable VPN connection between sites, enabling organizations to establish a robust network infrastructure.
FlexVPN Site-to-Site Smart Defaults offers several key features and benefits that contribute to improved network security. Firstly, it provides secure cryptographic algorithms that protect data transmission, ensuring the confidentiality and integrity of sensitive information. Additionally, it supports various authentication methods, such as digital certificates and pre-shared keys, further enhancing the overall security of the VPN connection. The feature also allows for easy scalability, enabling organizations to expand their network infrastructure without compromising security.
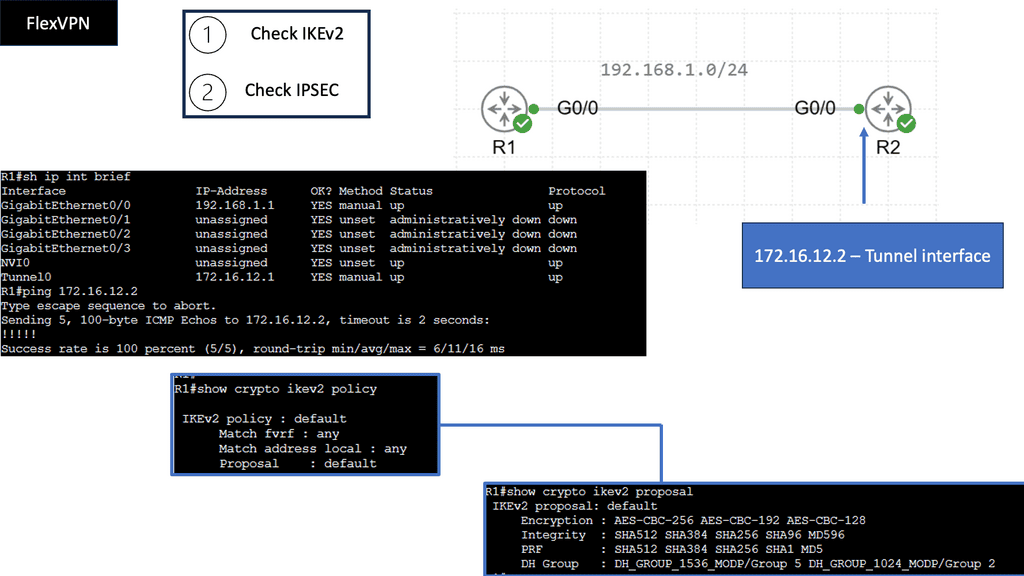
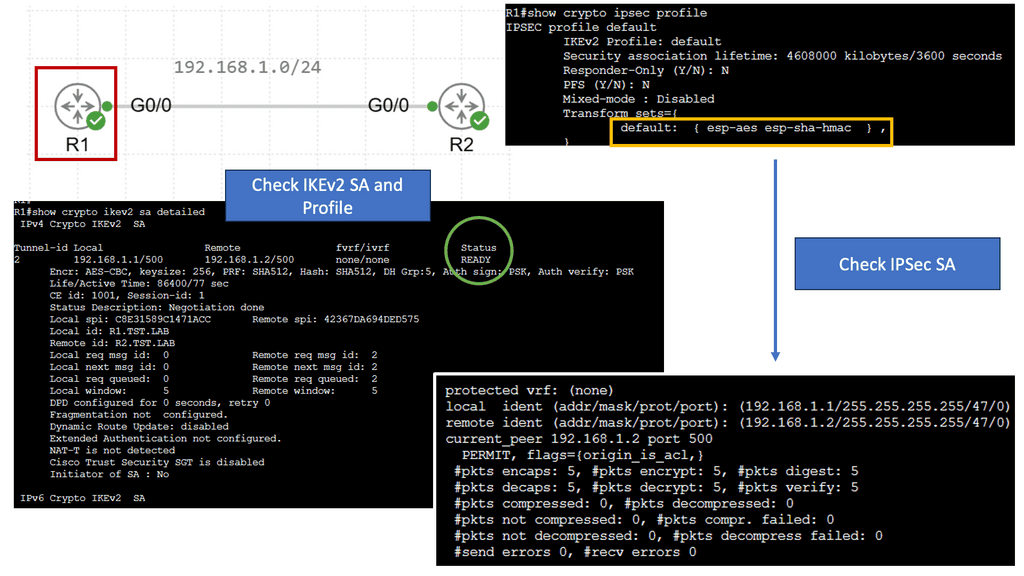
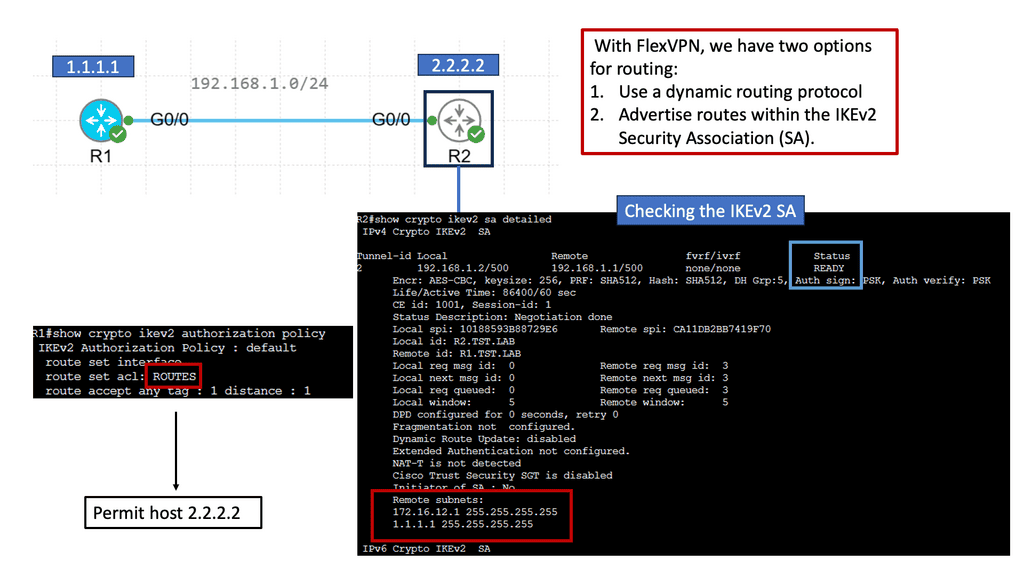
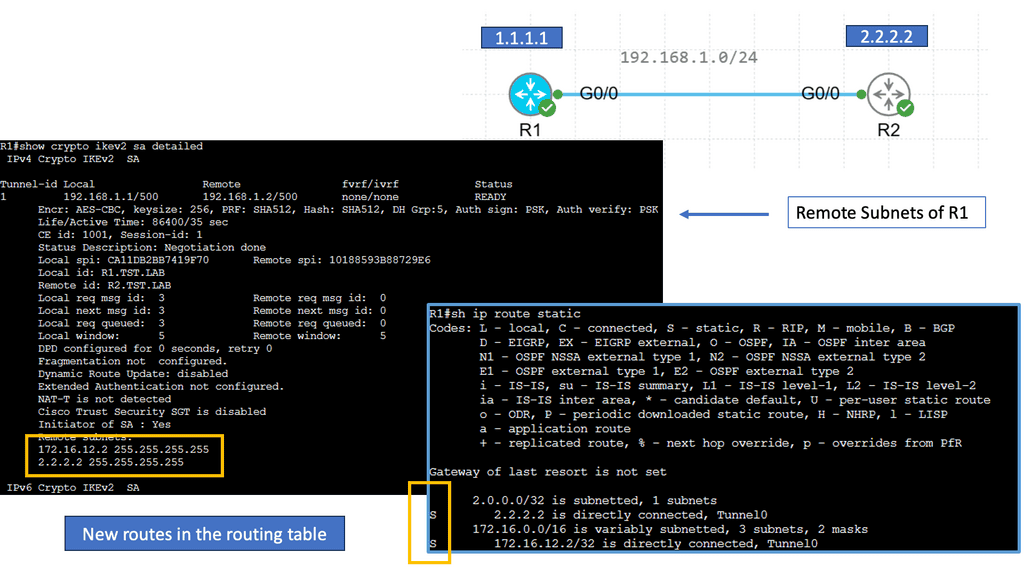
Example WAN Technology: FlexVPN IKEv2 Routing
Understanding FlexVPN
FlexVPN, short for Flexible VPN, is a versatile framework offering various VPN solutions. It provides a secure and scalable approach to establishing Virtual Private Networks (VPNs) over various network infrastructures. With its flexibility, it allows for seamless integration and interoperability across different platforms and devices.
IKEv2, or Internet Key Exchange version 2, is a secure and efficient protocol for establishing and managing VPN connections. It boasts numerous advantages, including its robust security features, ability to handle network disruptions, and support for rapid reconnection. IKEv2 is highly regarded for its ability to maintain stable and uninterrupted VPN connections, making it an ideal choice for FlexVPN.
a. Enhanced Security: FlexVPN IKEv2 Routing offers advanced encryption algorithms and authentication methods, ensuring the confidentiality and integrity of data transmitted over the VPN.
b. Scalability: With its flexible architecture, FlexVPN IKEv2 Routing effortlessly scales to accommodate growing network demands, making it suitable for small—to large-scale deployments.
c. Dynamic Routing: One of FlexVPN IKEv2 Routing’s standout features is its support for dynamic routing protocols, such as OSPF and EIGRP. This enables efficient and dynamic routing of traffic within the VPN network.
d. Seamless Failover: FlexVPN IKEv2 Routing provides automatic failover capabilities, ensuring uninterrupted connectivity even during network disruptions or hardware failures.
Understanding MPLS (Multi-Protocol Label Switching)
MPLS serves as the foundation for MPLS VPNs. It is a versatile and efficient routing technique that uses labels to forward data packets through a network. By assigning labels to packets, MPLS routers can make fast-forwarding decisions based on the labels, reducing the need for complex and time-consuming lookups in routing tables. This results in improved network performance and scalability.
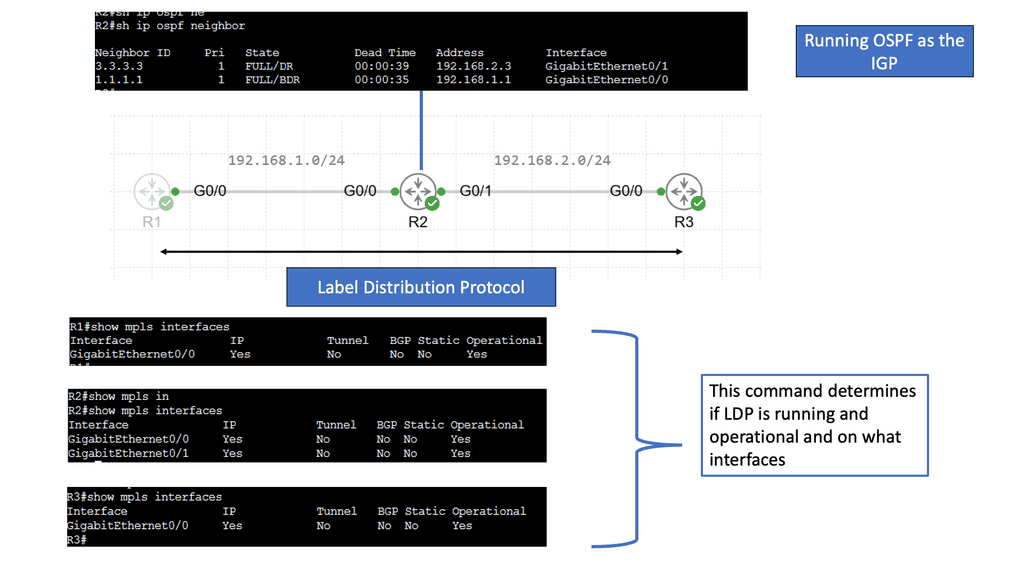
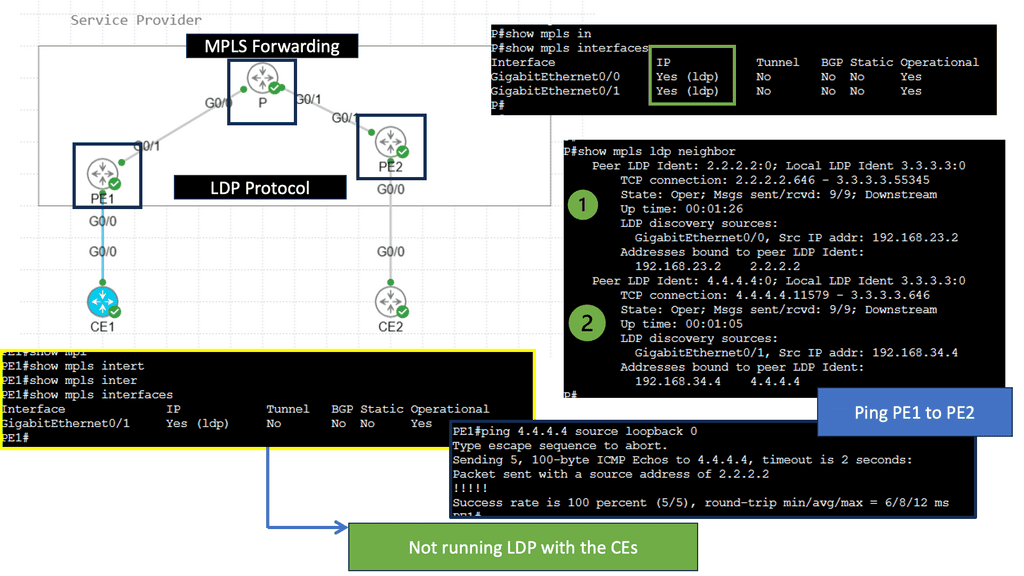
Understanding MPLS LDP
MPLS LDP is a crucial component in establishing label-switched paths within MPLS networks. MPLS LDP facilitates efficient packet forwarding and routing by enabling the distribution of labels and creating forwarding equivalency classes. Let’s take a closer look at how MPLS LDP operates.
One of the fundamental aspects of MPLS LDP is label distribution. Through signaling protocols, MPLS LDP ensures that labels are assigned and distributed across network nodes. This enables routers to make forwarding decisions based on labels, resulting in streamlined and efficient data transmission.
In MPLS LDP, labels serve as the building blocks of label-switched paths. These paths allow routers to forward packets based on labels rather than traditional IP routing. Additionally, MPLS LDP employs forwarding equivalency classes (FECs) to group packets with similar characteristics, further enhancing network performance.
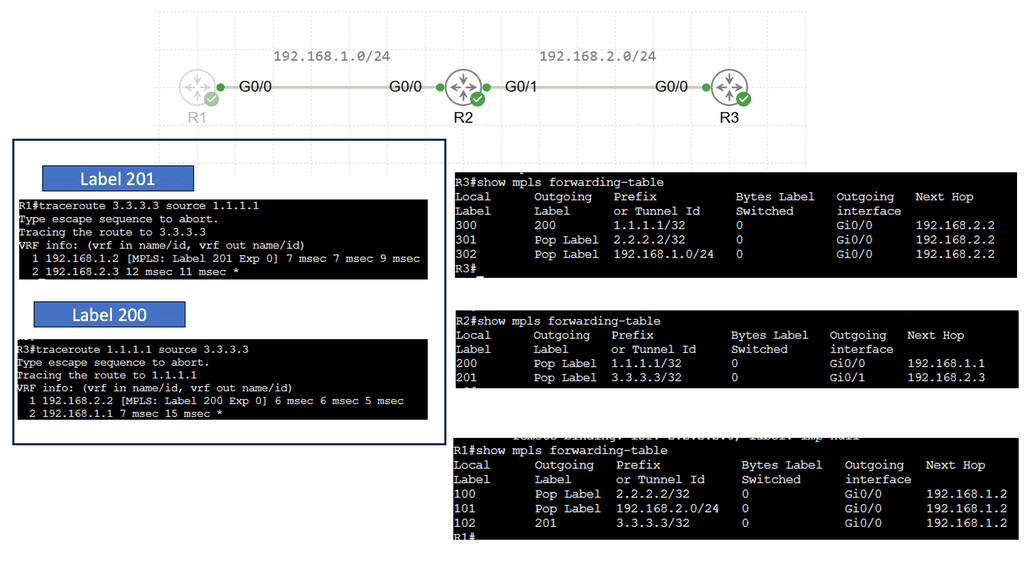
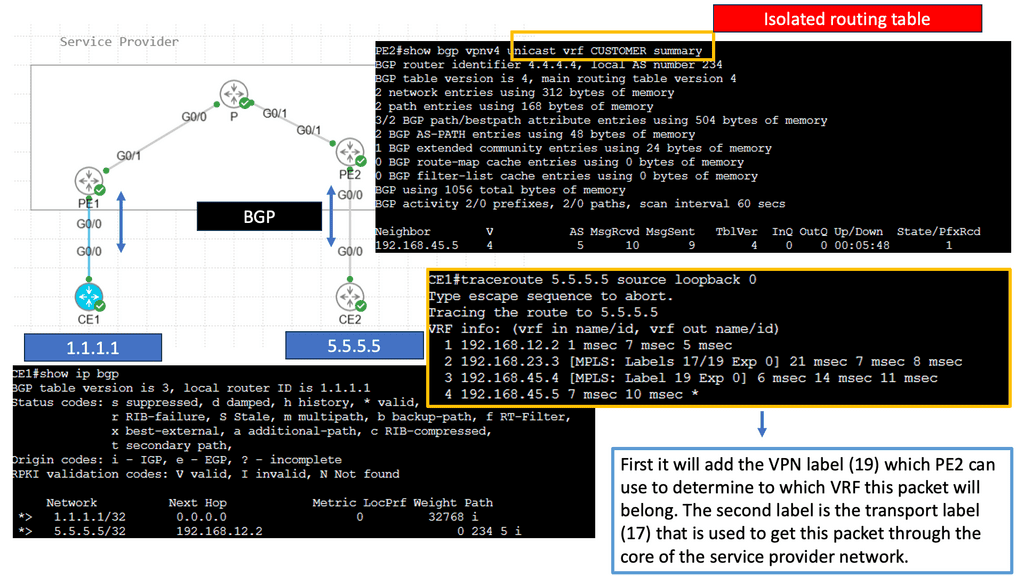
MPLS Virtual Private Networks (VPNs) Explained
VPNs provide secure communication over public networks by creating a private tunnel through which data can travel. They employ encryption and tunneling protocols to protect data from eavesdropping and unauthorized access. MPLS VPNs utilize this VPN concept to establish secure connections between geographically dispersed sites or remote users.
MPLS VPN Components
Customer Edge (CE) Router: The CE router acts as the entry and exit point for customer networks. It connects to the provider network and exchanges routing information. It encapsulates customer data into MPLS packets and forwards them to the provider network.
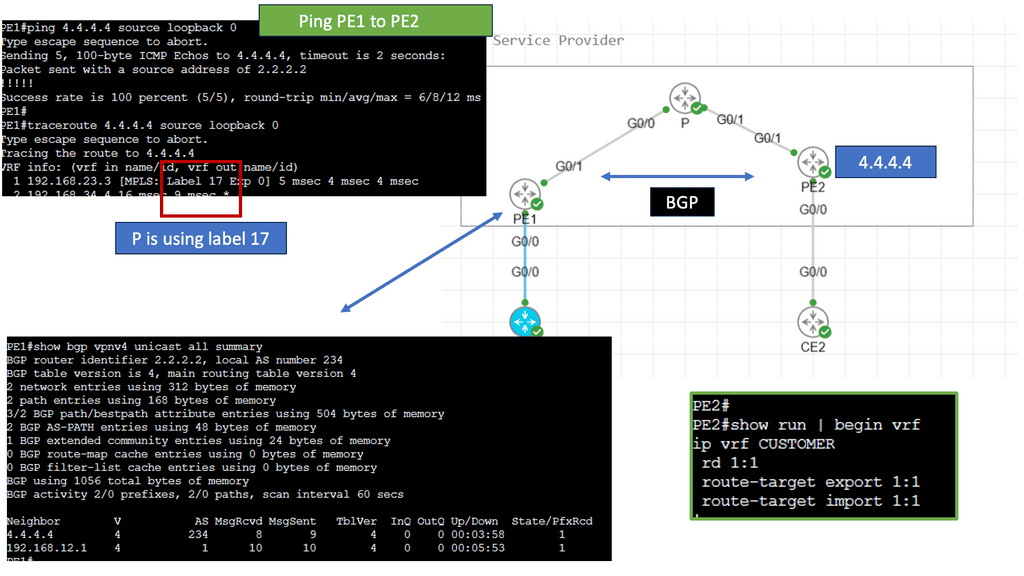
Provider Edge (PE) Router: The PE router sits at the edge of the service provider’s network and connects to the CE routers. It acts as a bridge between the customer and provider networks and handles the MPLS label switching. The PE router assigns labels to incoming packets and forwards them based on the labels’ instructions.
Provider (P) Router: P routers form the backbone of the service provider’s network. They forward MPLS packets based on the labels without inspecting the packet’s content, ensuring efficient data transmission within the provider’s network.
Virtual Routing and Forwarding (VRF) Tables: VRF tables maintain separate routing instances within a single PE router. Each VRF table represents a unique VPN and keeps the customer’s routing information isolated from other VPNs. VRF tables enable the PE router to handle multiple VPNs concurrently, providing secure and independent communication channels.
Use Case – DMVPN Single Hub, Dual Cloud
Single Hub, Dual Cloud is a specific configuration within the DMVPN architecture. In this setup, a central hub device acts as the primary connection point for branch offices while utilizing two separate cloud providers for redundancy and load balancing. This configuration offers several advantages, including improved availability, increased bandwidth, and enhanced failover capabilities.
1. Enhanced Redundancy: By leveraging two cloud providers, organizations can achieve high availability and minimize downtime. If one cloud provider experiences an issue or outage, the traffic can seamlessly be redirected to the alternate provider, ensuring uninterrupted connectivity.
2. Load Balancing: Distributing network traffic across two cloud providers allows for better resource utilization and improved performance. Organizations can optimize their bandwidth usage and mitigate potential bottlenecks.
3. Scalability: Single Hub, Dual Cloud DMVPN allows organizations to easily scale their network infrastructure by adding more branch offices or cloud providers as needed. This flexibility ensures that the network can adapt to changing business requirements.
4. Cost Efficiency: Utilizing multiple cloud providers can lead to cost savings through competitive pricing and the ability to negotiate better service level agreements (SLAs). Organizations can choose the most cost-effective options while maintaining the desired level of performance and reliability.


The role of SDN
With software-defined networking (SDN), network configurations can be dynamic and programmatically optimized, improving network performance and monitoring more like cloud computing than traditional network management. By disassociating the forwarding of network packets from routing (control plane), SDN can be used to centralize network intelligence within a single network component by improving the static architecture of traditional networks.
Controllers make up the control plane of an SDN network, which contains all of the network’s intelligence. They are considered the brains of the network. Security, scalability, and elasticity are some of the drawbacks of centralization.
Since OpenFlow’s emergence in 2011, SDN was commonly associated with remote communication with network plane elements to determine the path of network packets across network switches. Additionally, proprietary network virtualization platforms, such as Cisco Systems’ Open Network Environment and Nicira’s, use the term.
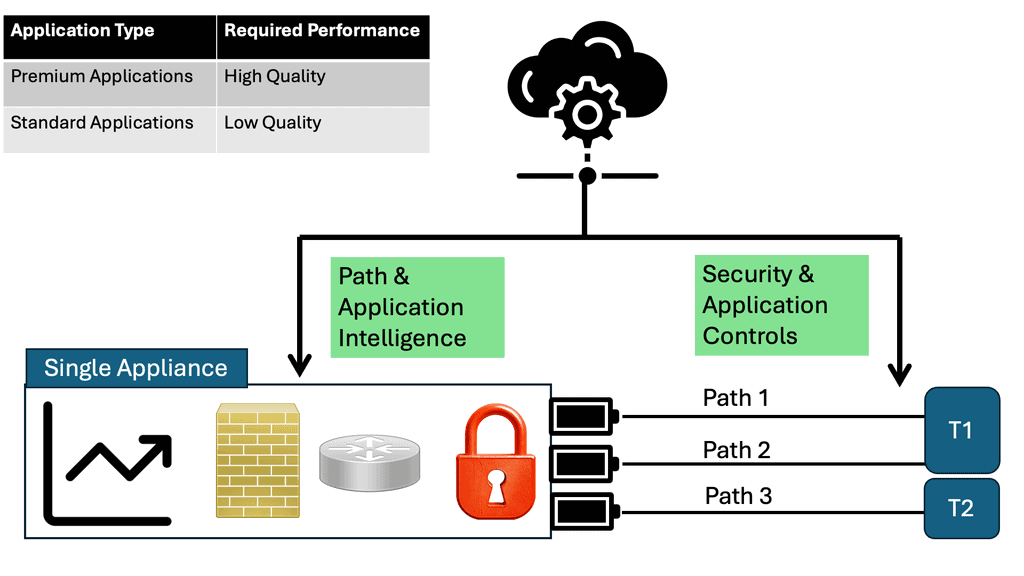
The SD-WAN technology is used in wide area networks (WANs)
SD-WAN, short for Software-Defined Wide Area Networking, is a transformative approach to network connectivity. Unlike traditional WAN, which relies on hardware-based infrastructure, SD-WAN utilizes software and cloud-based technologies to connect networks over large geographic areas securely. By separating the control plane from the data plane, SD-WAN provides centralized management and enhanced flexibility, enabling businesses to optimize their network performance.
Transport Independance: Hybrid WAN
The hybrid WAN concept was born out of this need. An alternative path that applications can take across a WAN environment is provided by hybrid WAN, which involves businesses acquiring non-MPLS networks and adding them to their LANs. Business enterprises can control these circuits, including routing and application performance. VPN tunnels are typically created over the top of these circuits to provide secure transport over any link. 4G/LTE, L2VPN, commodity broadband Internet, and L2VPN are all examples of these types of links.
As a result, transport independence is achieved. In this way, any transport type can be used under the VPN, and deterministic routing and application performance can be achieved. These commodity links can transmit some applications rather than the traditionally controlled L3VPN MPLS links provided by service providers.
SDN and APIs
WAN SDN is a modern approach to network management that uses a centralized control model to manage, configure, and monitor large and complex networks. It allows network administrators to use software to configure, monitor, and manage network elements from a single, centralized system. This enables the network to be managed more efficiently and cost-effectively than traditional networks.
SDN uses an application programming interface (API) to abstract the underlying physical network infrastructure, allowing for more agile network control and easier management. It also enables network administrators to rapidly configure and deploy services from a centralized location. This enables network administrators to respond quickly to changes in traffic patterns or network conditions, allowing for more efficient use of resources.
Scalability and Automation
SDN also allows for improved scalability and automation. Network administrators can quickly scale up or down the network by leveraging automated scripts depending on its current needs. Automation also enables the network to be maintained more rapidly and efficiently, saving time and resources.
Before you proceed, you may find the following posts helpful:
A Deterministic Solution
Technology typically starts as a highly engineered, expensive, deterministic solution. As the marketplace evolves and competition rises, the need for a non-deterministic, inexpensive solution comes into play. We see this throughout history. First, mainframes were/are expensive, and with the arrival of a microprocessor personal computer, the client/server model was born. The Static RAM ( SRAM ) technology was replaced with cheaper Dynamic RAM ( DRAM ). These patterns consistently apply to all areas of technology.
Finally, deterministic and costly technology is replaced with intelligent technology using redundancy and optimization techniques. This process is now appearing in Wide Area Networks (WAN). Now, we are witnessing changes to routing space with the incorporation of Software Defined Networking (SDN) and BGP (Border Gateway Protocol). By combining these two technologies, companies can now perform intelligent routing, aka SD-WAN path selection, with an SD WAN Overlay
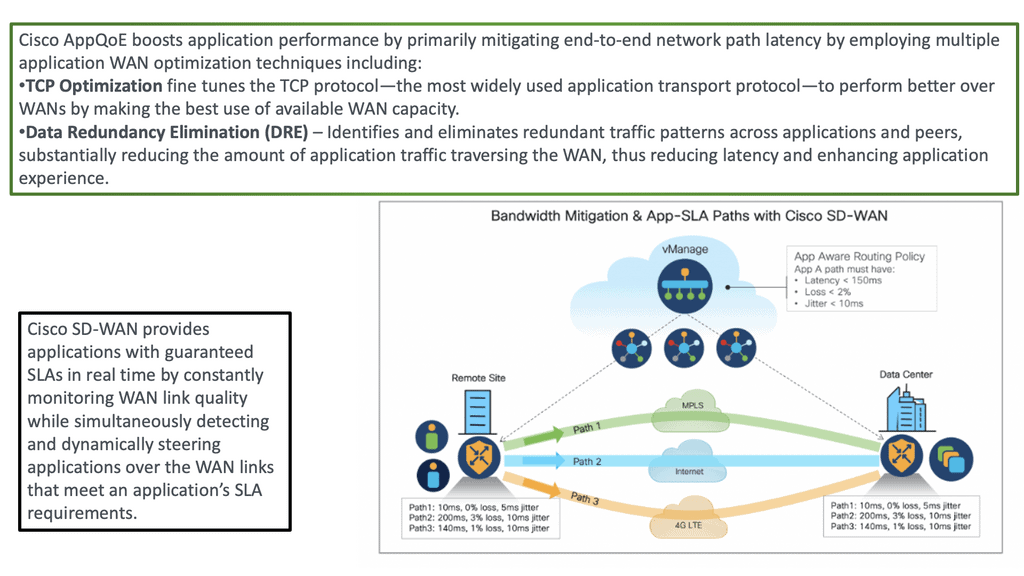
**SD-WAN Path Selection**
SD-WAN path selection is essential to a Software-Defined Wide Area Network (SD-WAN) architecture. SD-WAN path selection selects the most optimal network path for a given application or user. This process is automated and based on user-defined criteria, such as latency, jitter, cost, availability, and security. As a result, SD-WAN can ensure that applications and users experience the best possible performance by making intelligent decisions on which network path to use.
When selecting the best path for a given application or user, SD-WAN looks at the quality of the connection and the available bandwidth. It then looks at the cost associated with each path. Cost can be a significant factor when selecting a path, especially for large enterprises or organizations with multiple sites.
SD-WAN can also prioritize certain types of traffic over others. This is done by assigning different weights or priorities for various kinds of traffic. For example, an organization may prioritize voice traffic over other types of traffic. This ensures that voice traffic has the best possible chance of completing its journey without interruption.
Critical Considerations for Implementation:
Network Security:
When adopting WAN SDN, organizations must consider the potential security risks associated with software-defined networks. Robust security measures, including authentication, encryption, and access controls, should be implemented to protect against unauthorized access and potential vulnerabilities.
Staff Training and Expertise:
Implementing WAN SDN requires skilled network administrators proficient in configuring and managing the software-defined network infrastructure. Organizations must train and upskill their IT teams to ensure successful implementation and ongoing management.
Real-World Use Cases:
Multi-Site Connectivity:
WAN SDN enables organizations with multiple geographically dispersed locations to connect their sites seamlessly. Administrators can prioritize traffic, optimize bandwidth utilization, and ensure consistent network performance across all locations by centrally controlling the network.
Cloud Connectivity:
With the increasing adoption of cloud services, WAN SDN allows organizations to connect their data centers to public and private clouds securely and efficiently. This facilitates smooth data transfers, supports workload mobility, and enhances cloud performance.
Disaster Recovery:
WAN SDN simplifies disaster recovery planning by allowing organizations to reroute network traffic dynamically during a network failure. This ensures business continuity and minimizes downtime, as the network can automatically adapt to changing conditions and reroute traffic through alternative paths.
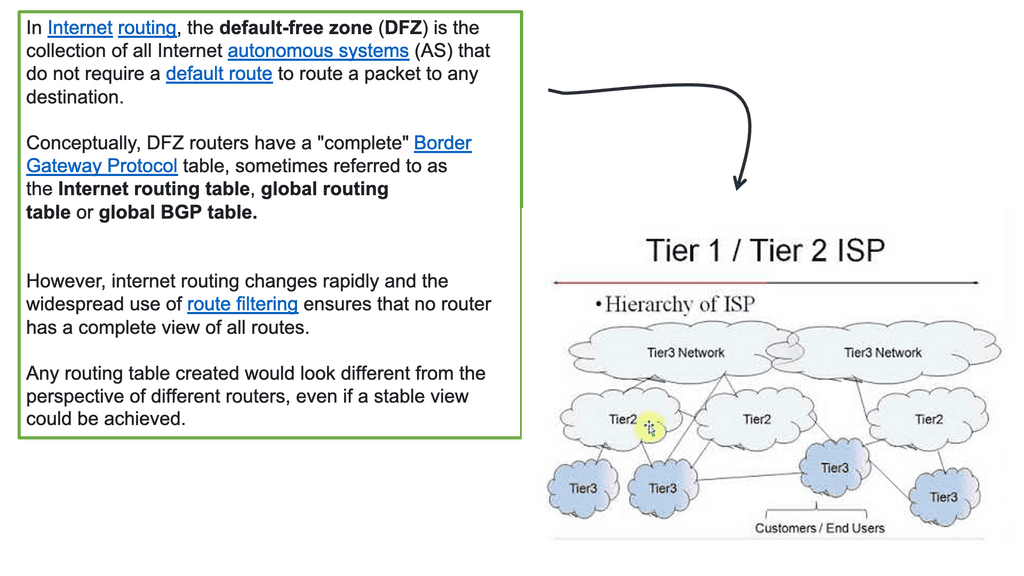
The Rise of WAN SDN
The foundation for business and cloud services are crucial elements of business operations. The transport network used for these services is best efforts, weak, and offers no guarantee of an acceptable delay. More services are being brought to the Internet, yet the Internet is managed inefficiently and cheaply.
Every Autonomous System (AS) acts independently, and there is a price war between transit providers, leading to poor quality of transit services. Operating over this flawed network, customers must find ways to guarantee applications receive the expected level of quality.
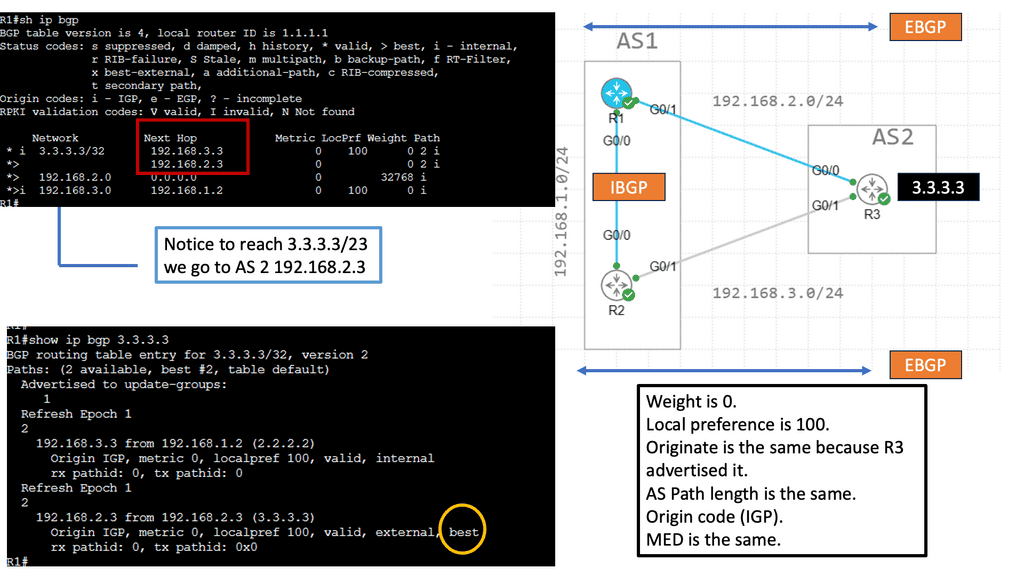
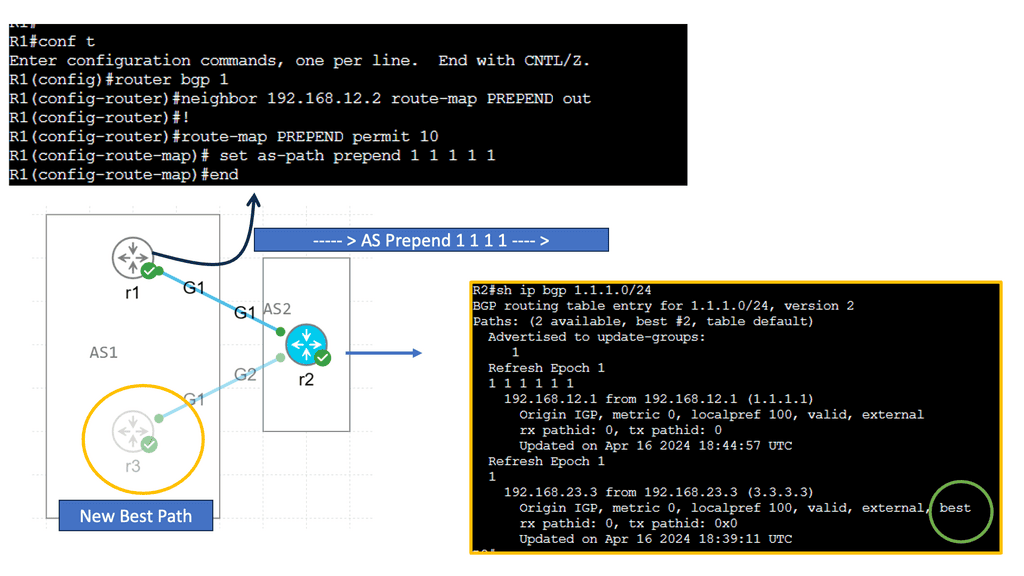
Border Gateway Protocol (BGP), the Internet’s glue, has several path selection flaws. The main drawback of BGP is the routing paradigm relating to the path-selection process. BGP default path selection is based on Autonomous System (AS) Path length; prefer the path with the shortest AS_PATH. It misses the shape of the network with its current path selection process. It does not care if propagation delay, packet loss, or link congestion exists. It resulted in long path selection and utilizing paths potentially experiencing packet loss.
Example: WAN SDN with Border6
Border6 is a French company that started in 2012. It offers non-stop internet and an integrated WAN SDN solution, influencing BGP to perform optimum routing. It’s not a replacement for BGP but a complementary tool to enhance routing decisions. For example, it automates changes in routing in cases of link congestion/blackouts.
“The agile way of improving BGP paths by the Border 6 tool improves network stability” Brandon Wade, iCastCenter Owner.
As the Internet became more popular, customers wanted to add additional intelligence to routing. Additionally, businesses require SDN traffic optimizations, as many run their entire service offerings on top of it.
What is non-stop internet?
Border6 offers an integrated WAN SDN solution with BGP that adds intelligence to outbound routing. A common approach when designing SDN in real-world networks is to prefer that SDN solutions incorporate existing field testing mechanisms (BGP) and not reinvent all the wheels ever invented. Therefore, the border6 approach to influence BGP with SDN is a welcomed and less risky approach to implementing a greenfield startup. In addition, Microsoft and Viptela use the SDN solution to control BGP behavior.
Border6 uses BGP to guide what might be reachable. Based on various performance metrics, they measure how well paths perform. They use BGP to learn the structure of the Internet and then run their algorithms to determine what is essential for individual customers. Every customer has different needs to reach different subnets. Some prefer costs; others prefer performance.
They elect several interesting “best” performing prefixes, and the most critical prefixes are selected. Next, they find probing locations and measure the source with automatic probes to determine the best path. All these tools combined enhance the behavior of BGP. Their mechanism can detect if an ISP has hardware/software problems, drops packets, or rerouting packets worldwide.
Thousands of tests per minute
The Solution offers the best path by executing thousands of tests per minute and enabling results to include the best paths for packet delivery. Outputs from the live probing of path delays and packet loss inform BGP on which path to route traffic. The “best path” is different for each customer. It depends on the routing policy the customer wants to take. Some customers prefer paths without packet loss; others wish to cheap costs or paths under 100ms. It comes down to customer requirements and the applications they serve.
**BGP – Unrelated to Performance**
Traditionally, BGP gets its information to make decisions based on data unrelated to performance. Broder 6 tries to correlate your packet’s path to the Internet by choosing the fastest or cheapest link, depending on your requirements.
They are taking BGP data service providers and sending them as a baseline. Based on that broad connectivity picture, they have their measurements – lowest latency, packets lost, etc.- and adjust the data from BGP to consider these other measures. They were, eventually, performing optimum packet traffic forwarding. They first look at Netflow or Sflow data to determine what is essential and use their tool to collect and aggregate the data. From this data, they know what destinations are critical to that customer.
BGP for outbound | Locator/ID Separation Protocol (LISP) for inbound
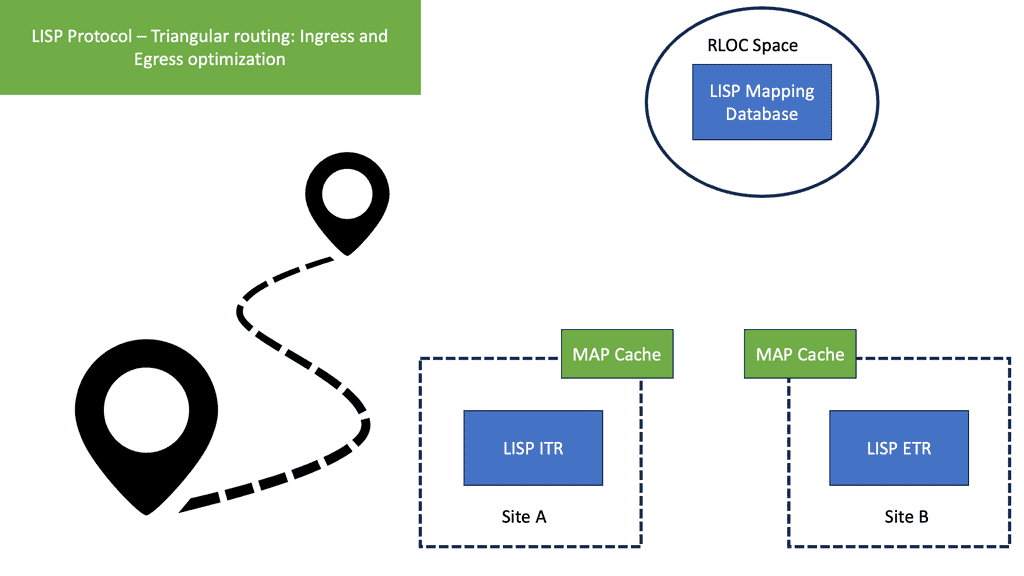
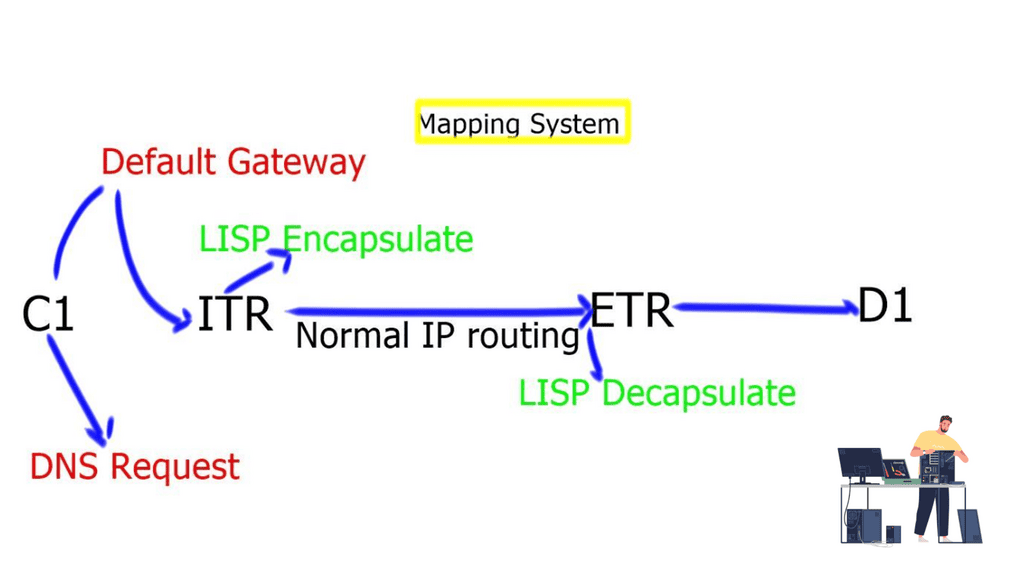
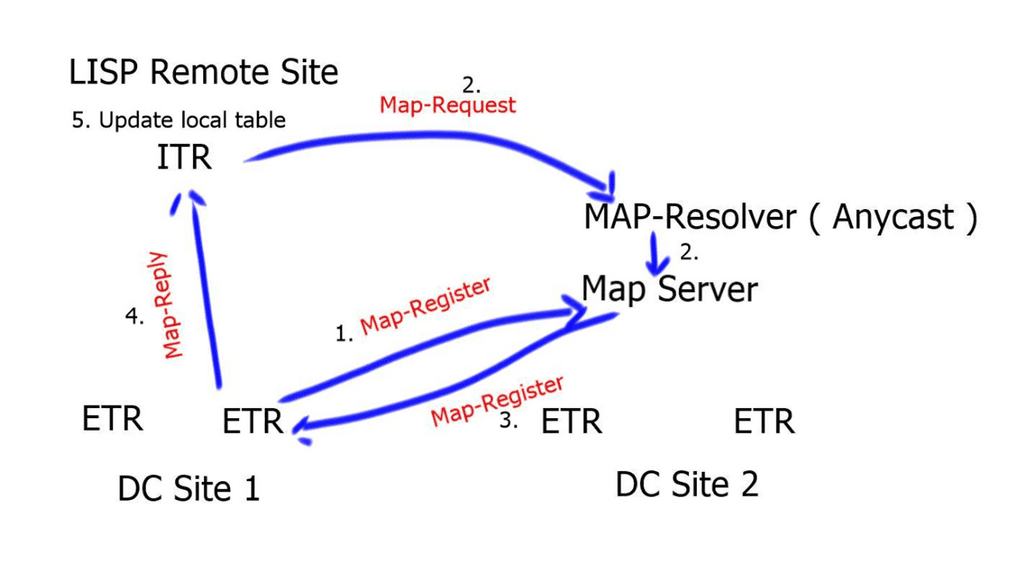
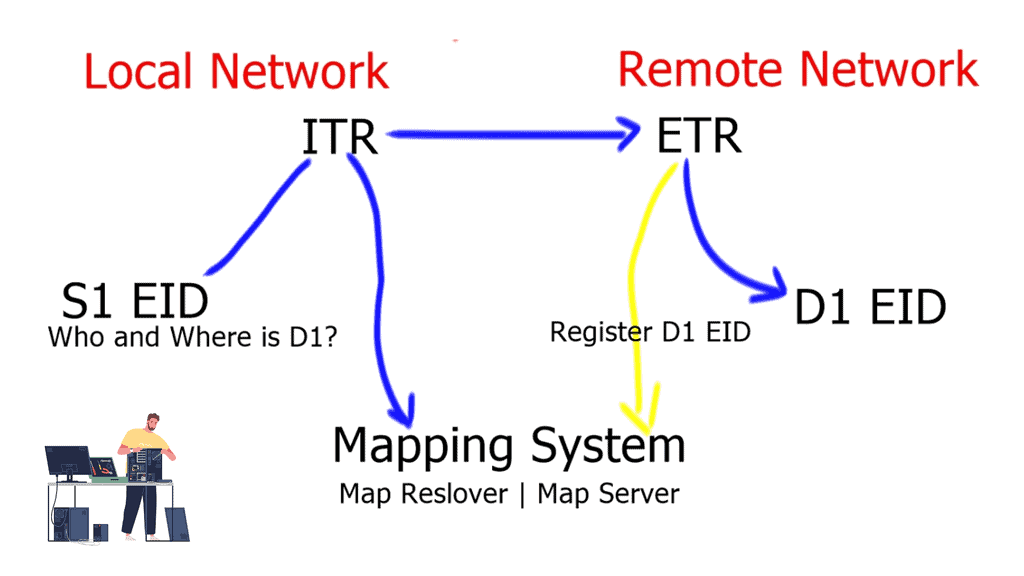
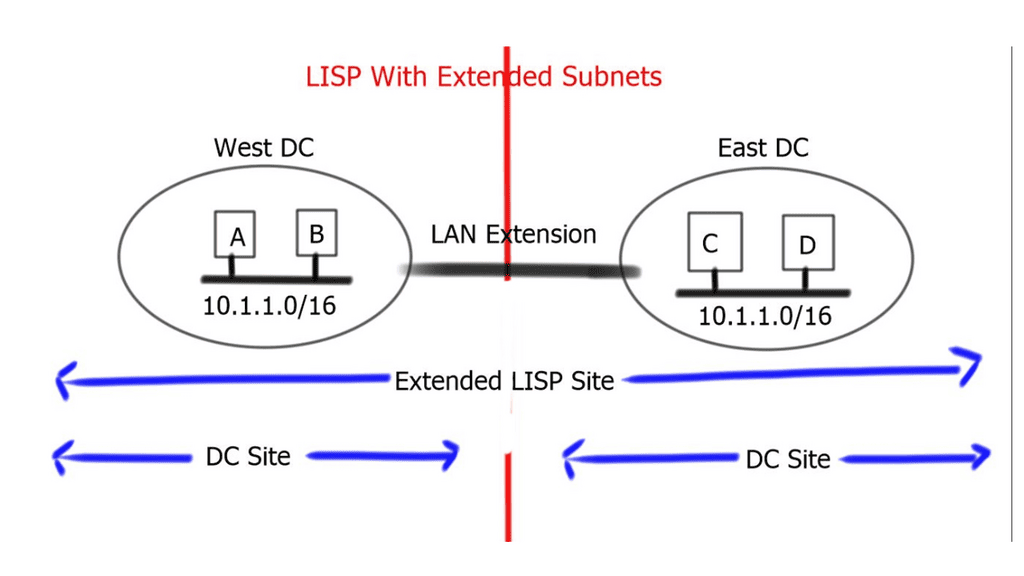
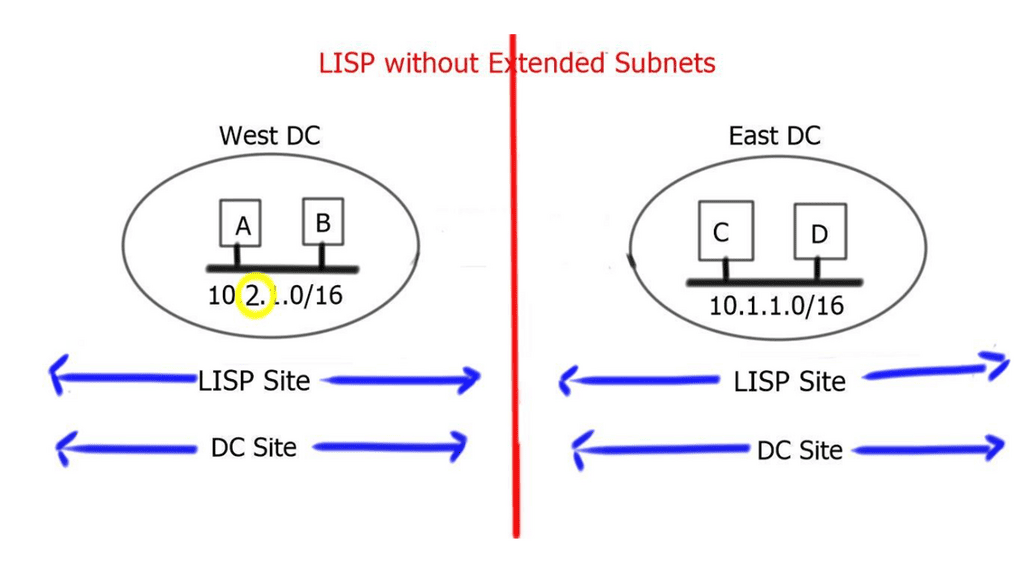
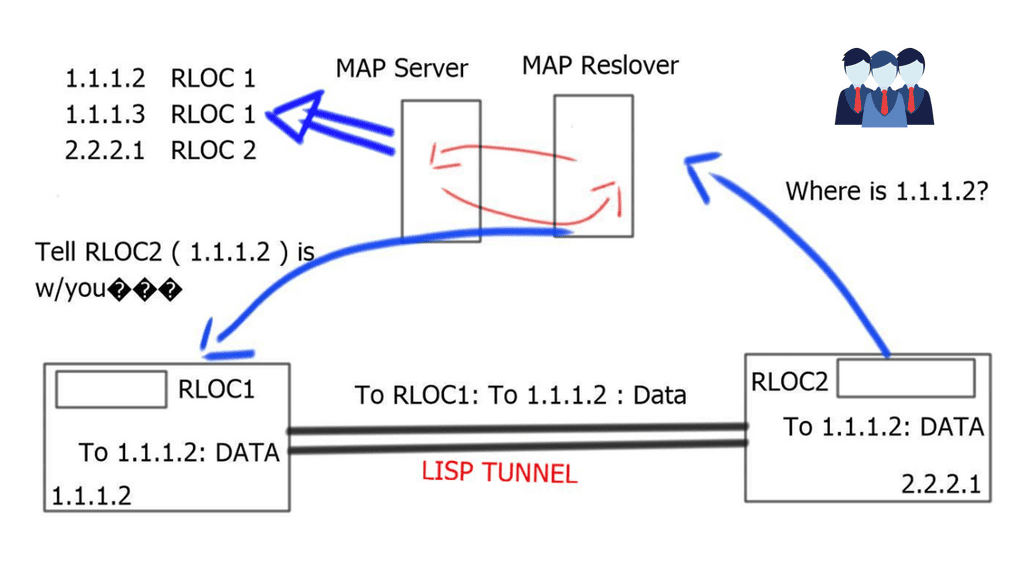
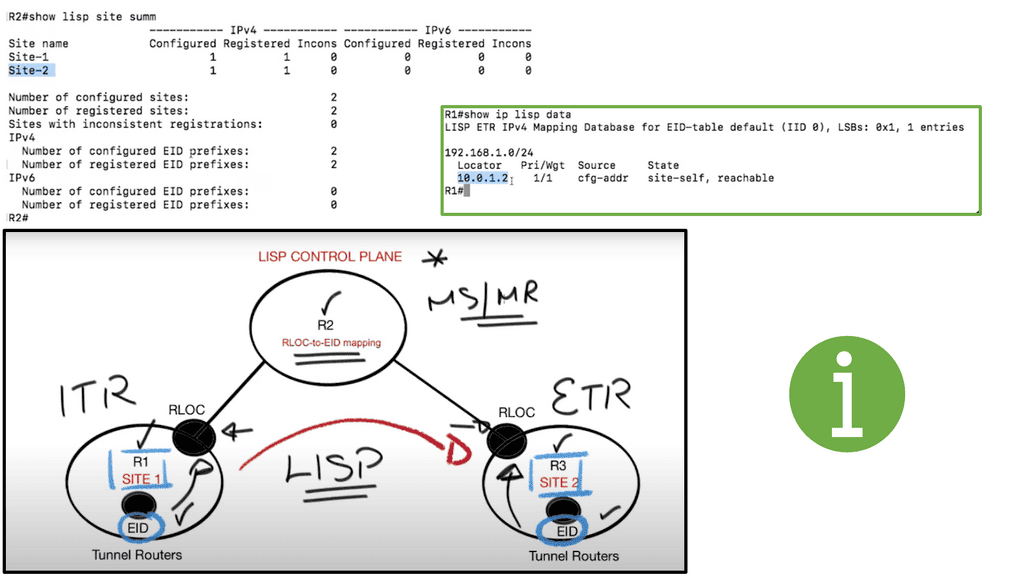
Border6 products relate to outbound traffic optimizations. It can be hard to influence inbound traffic optimization with BGP. Most AS behave selfishly and optimize the traffic in their interest. They are trying to provide tools that help AS optimize inbound flows by integrating their product set with the Locator/ID Separation Protocol (LISP). The diagram below displays generic LISP components. It’s not necessarily related to Border6 LISP design.
LISP decouples the address space so you can optimize inbound traffic flows. Many LISP uses cases are seen with active-active data centers and VM mobility. It decouples the “who” and the “where,” which allows end-host addressing not to correlate with the actual host location. The drawback is that LISP requires endpoints that can build LISP tunnels.
Currently, they are trying to provide a solution using LISP as a signaling protocol between Border6 devices. They are also working on performing statistical analysis for data received to mitigate potential denial-of-service (DDoS) events. More DDoS algorithms are coming in future releases.
Closing Points: On WAN SDN
At its core, WAN SDN separates the control plane from the data plane, facilitating centralized network management. This separation allows for dynamic adjustments to network configurations, providing businesses with the agility to respond to changing conditions and demands. By leveraging software to control network resources, organizations can achieve significant improvements in performance and cost-effectiveness.
One of the primary advantages of WAN SDN is its ability to optimize network traffic and improve bandwidth utilization. By intelligently routing data, WAN SDN minimizes latency and enhances the overall user experience. Additionally, it simplifies network management by providing a single, centralized platform to control and configure network policies, reducing the complexity and time required for network maintenance.