Nexus OS Software Release
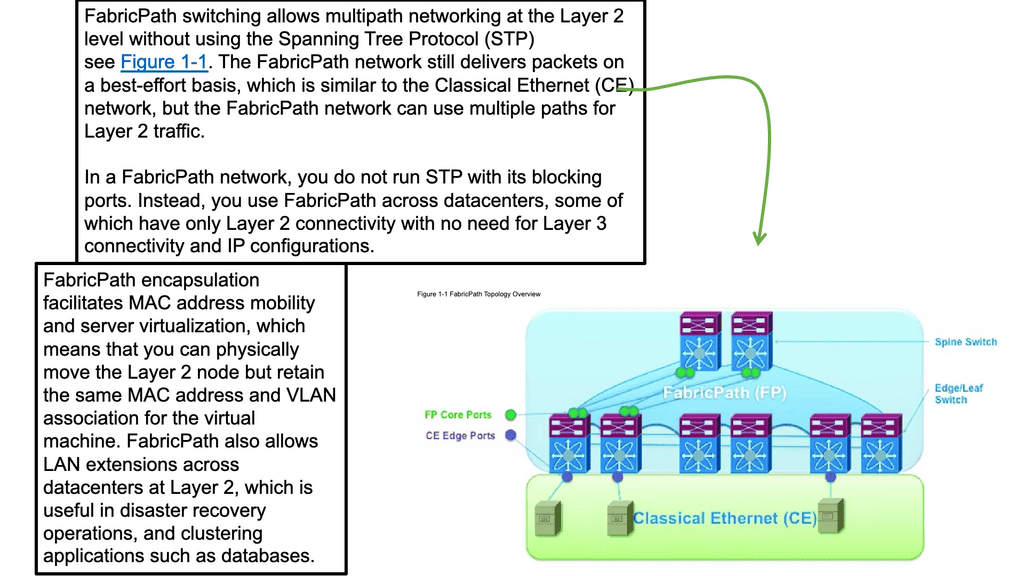
Introduced by Cisco in Nexus OS software Release 5.1(3), FabricPath Nexus allows architects to design highly scalable actual Layer 2 fabrics. Similar to the spanning tree, it provides an almost plug-and-play deployment model with the benefits of Layer 3 routing, allowing FabricPath networks to scale at an unprecedented level.
In addition to its simplicity, Fabric Path enables faster, simpler, and flatter data center networks. Cisco FabricPath uses routing principles to allow Layer 2 scaling, bringing the stability of Layer 3 routing to Layer 2. Fabric path traffic is no longer forwarded along a spanning tree design. As a result, we now have a more scalable design that is not limited by bisectional bandwidth.
**Understanding the Core Concepts of FabricPath**
At its core, FabricPath combines the best aspects of Layer 2 and Layer 3 networking, creating a unified fabric that simplifies data center operations. Unlike traditional Spanning Tree Protocol (STP), FabricPath employs a routing protocol that ensures optimal path selection and loop prevention. This results in a more efficient and robust network design, capable of handling the demands of modern applications. Key to this is the use of Intermediate System to Intermediate System (IS-IS) protocol, which facilitates dynamic path calculation and enhances network resilience.
**Advantages of Implementing FabricPath**
Cisco FabricPath offers a multitude of benefits that address common network challenges. One of its primary advantages is the elimination of STP-related issues, such as blocked links and inefficient bandwidth utilization. With FabricPath, all available paths are active, leading to increased throughput and reduced latency. Additionally, the protocol supports seamless scalability, allowing networks to grow without significant reconfiguration. This makes it an ideal choice for businesses looking to future-proof their infrastructure.
**Deploying FabricPath in Your Network**
Deploying Cisco FabricPath in your network involves several considerations to ensure optimal performance. First, it’s crucial to assess your current network architecture and identify areas that would benefit from FabricPath integration. Once identified, the implementation process involves configuring FabricPath on compatible Cisco Nexus switches and ensuring proper interoperability with existing network protocols. Proper planning and execution are essential to reap the full benefits of this innovative technology.
Key FabricPath Notes:
– Understanding the Basics: Fabric Path is a layer 2 network technology that provides the advantages of traditional Ethernet and routing protocols. By leveraging multiprotocol label switching (MPLS) techniques, it enables the creation of scalable, efficient, and resilient networks. Fabric Path ensures optimal traffic flow and minimizes congestion by utilizing a loop-free topology and distributing forwarding information across the network.
– Key Features and Benefits: Fabric Path offers several compelling features, making it a highly desirable solution for modern network architectures. Firstly, its ability to support large Layer 2 domains without the limitations of Spanning Tree Protocol (STP) enables efficient utilization of network resources.
Additionally, Fabric Path provides increased bandwidth and redundancy, leading to enhanced performance and reliability. With its support for Equal-Cost Multipath (ECMP) load balancing, the technology allows for efficient distribution of traffic across multiple paths, further optimizing network utilization.
– Seamless Migration and Interoperability: One of the significant advantages of Fabric Path is its seamless integration with existing network infrastructures. It enables organizations to migrate from conventional Ethernet-based networks to Fabric Path gradually, without disrupting their ongoing operations. This interoperability ensures a smooth transition and allows businesses to leverage the benefits of Fabric Path without compromising their existing investments.
– Real-World Applications: Fabric Path has found extensive applications in various industries and network environments. In data centers, it provides a highly scalable and flexible solution for building large Layer 2 domains, enabling seamless virtual machine mobility and workload distribution.
Similarly, Fabric Path offers simplified network design, reduced complexity, and improved performance in campus networks. Furthermore, it has proven to be an effective solution for service providers, facilitating the delivery of bandwidth-intensive services with high availability and resiliency.
**The need for layer 2**
In the past, data centers were designed primarily to provide high availability. Layer 2 is crucial for modern data centers. Today’s networks must be agile and flexible, just like the organizations they serve since switching allows devices to be moved and infrastructure to be modified transparently, expanding the Layer 2 domain would satisfy this additional requirement. On the other hand, existing switching technologies rely on inefficient forwarding schemes based on spanning trees that cannot be extended to the entire network. The flexibility of Layer 2 compromises the scalability of Layer 3.
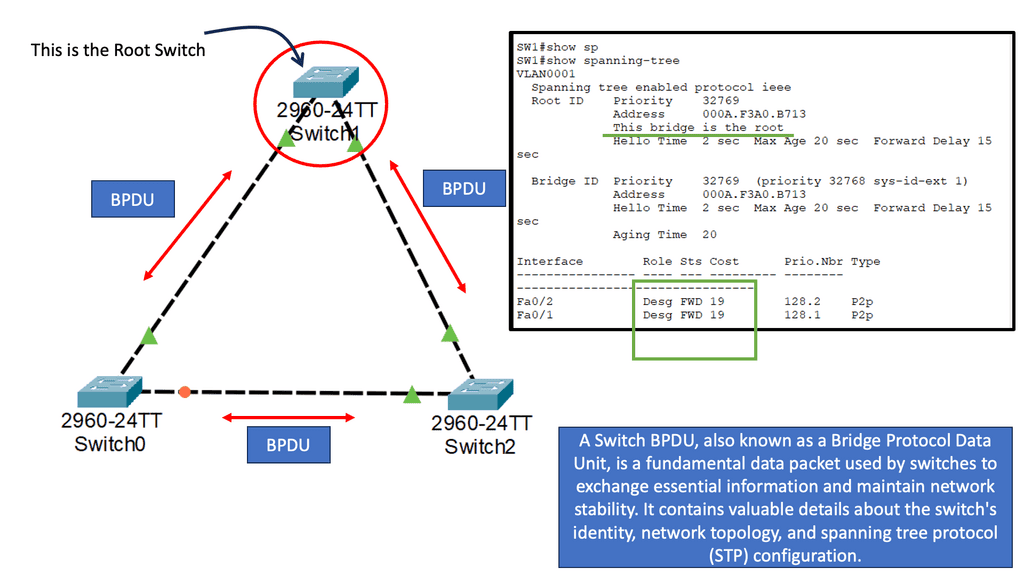
**Routing concepts at layer 2**
Cisco FabricPath: Expanding Routing Concepts to Layer 2 Cisco® FabricPath extends routing stability and scalability to Layer 2 of Cisco NX-OS. Workloads can be moved across the entire data center by eliminating the need to segment the switched domain. As a result, the bisectional bandwidth of the network is no longer limited by a spanning tree, allowing for massive scalability.
An entirely new Layer 2 data plane is created with Cisco FabricPath, where frames enter the fabric with routable source and destination addresses. The source address of a frame is its receiving switch’s address, and its destination address is its destination switch’s address. As soon as the frame reaches the remote switch, it is de-encapsulated and delivered in its original Ethernet format.
The role of Fabric Path
In large data centers, virtualization of physical servers began a few years ago. Due to server virtualization and economies of scale, “mega data centers” containing tens of thousands of servers emerged due to server virtualization.
As a result, distributed applications had to be supported on a large scale and provisioned in different data center zones. A scalable and resilient Layer 2 fabric was required to enable any-to-any communication. FabricPath was developed by Cisco to meet these new demands. Providing scalability, resilience, and flexibility, FabricPath is a highly scalable Layer 2 fabric.
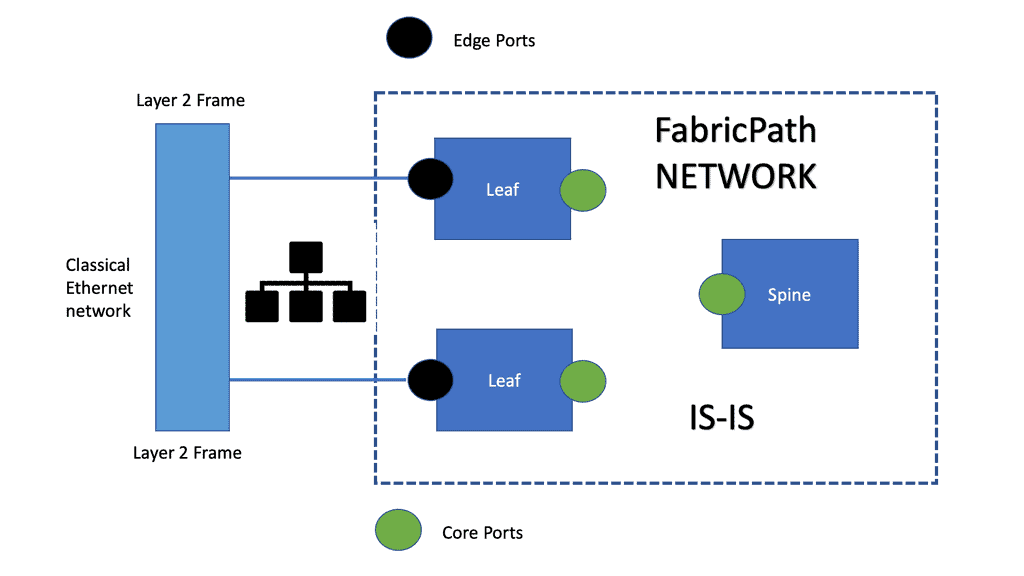
Fabric Path Requirements
– Massive Scalable Data Centers (MSDCs) and virtualization technologies have led to the development of large Layer 2 domains in data centers with more than 1000 servers and a design for scalability. Due to the limitations of Spanning Tree Protocol (STP), Layer 2 switching has evolved into technologies such as TRILL and FabricPath. To understand FabricPath’s limitations, you need to consider the limitations of current Layer 2 networks based on STP:
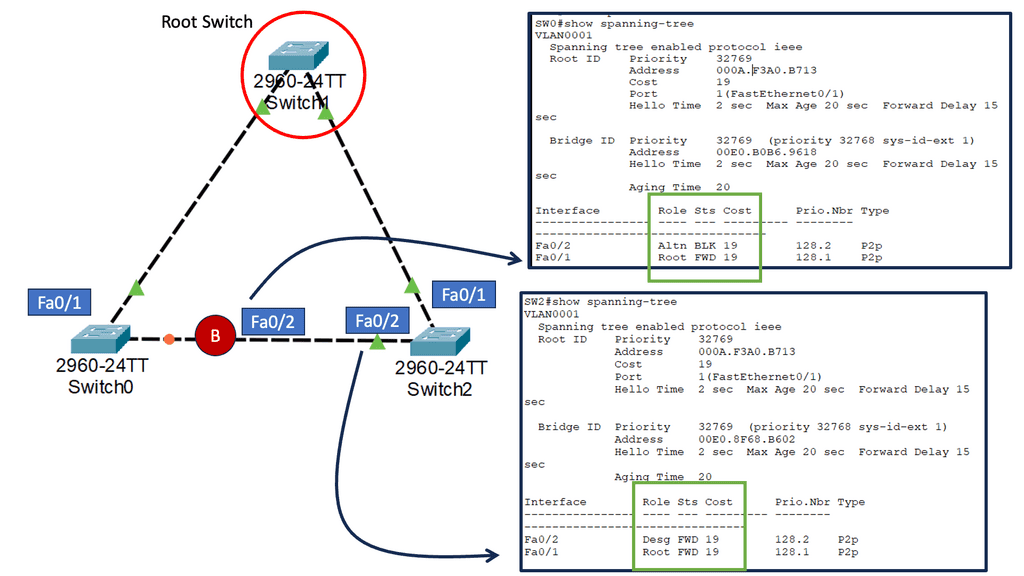
– By blocking redundant paths, STP creates loop-free topologies in Layer 2 networks. STP uses the root selection process to accomplish this. To build shortest paths to the root switch, all the other switches block the other ports while building shortest paths to the root switch. The result is a Layer 2 network topology that is loop-free.
– This blocks layer 2 networks because all redundant paths are blocked. PVST, which enables per-VLAN load balancing, also has limitations in multipathing support, although some enhancements were made using the per-VLAN Spanning Tree Protocol (PVSTP).
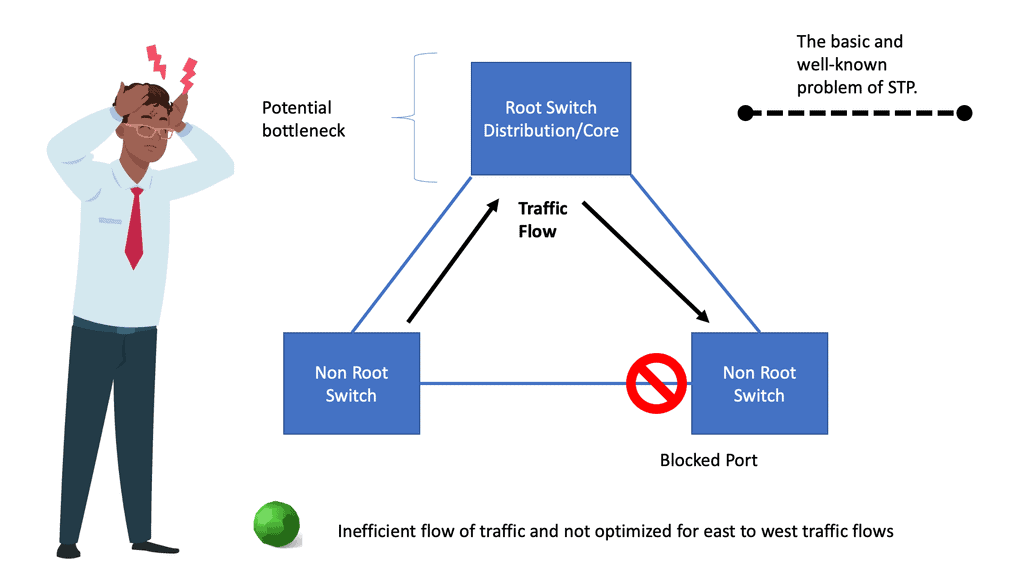
– The root bridge is selected based on the shortest path, which results in inefficient path selection between switches. So, selecting a path between switches doesn’t necessarily mean choosing the shortest path. Take two access switches as an example connected to distribution and each other. If the distribution switch serves as the root bridge for STP, the link between the two access switches is blocked. All traffic flows through the distribution switch.
– Unavailability of Time-To-Live (TTL): The Layer 2 packet header doesn’t have a TTL field. This can lead to network meltdowns in switched networks. This is because a forwarding loop can cause a broadcast packet to duplicate, consuming excessive network resources exponentially.
MAC address scalability: Nonhierarchical flat addressing of Ethernet MAC addresses leads to limited scalability since MAC address summarization is impossible. Additionally, all the MAC addresses are essentially assigned to every switch in the Layer 2 network, increasing the size of Layer 2 tables.
As a result, Layer 3 routing protocols provide multipathing and efficient shortest paths between all nodes in the network, which resolve the shortcomings of Layer 2 networks. Layer 3 solves these issues, but the network design becomes static. Static network design limits Layer 2 domain size, so virtualization cannot be used. Thanks to FabricPath’s combination of the two technologies, a Layer 2 network can be flexible and scaled with Layer 3 networks.
Fabric Path Benefits
With FabricPath, data center architects and administrators can design and implement scalable Layer 2 fabrics. Benefits of FabricPath include:
Maintains the plug-and-play features of classical Ethernet: Due to the minimal configuration requirements and the fact that the administrator must include the FabricPath core network interfaces, configuration effort is significantly reduced.
Unicast forwarding, multicast forwarding, and VLAN pruning are also controlled by a single protocol (IS-IS). FabricPath operations, administration, and management (OAM) now support ping and trace routes, allowing network administrators to troubleshoot Layer 2 FabricPath networks similarly to Layer 3 networks.
**Multipathing**
Multipathing allows data center network architects to build large, scalable networks using N-way (more than one path) multipathing. A network administrator can also incrementally add new devices as needed to the existing topology. Using flat topologies, MSDC networks can be connected by only one hop between nodes. A single node failure in N-way multipathing results in a reduction in fabric bandwidth of 1/Nth.
With the enhanced Layer 2 network capabilities combined with Layer 3 capabilities, multiple paths can be created between endpoints instead of just one, replacing STP. It allows network administrators to increase bandwidth as bandwidth requirements increase incrementally.The FabricPath protocol enables traffic to be forwarded over the shortest path to the destination, reducing network latency. This is more efficient than Layer 2 forwarding based on STP.
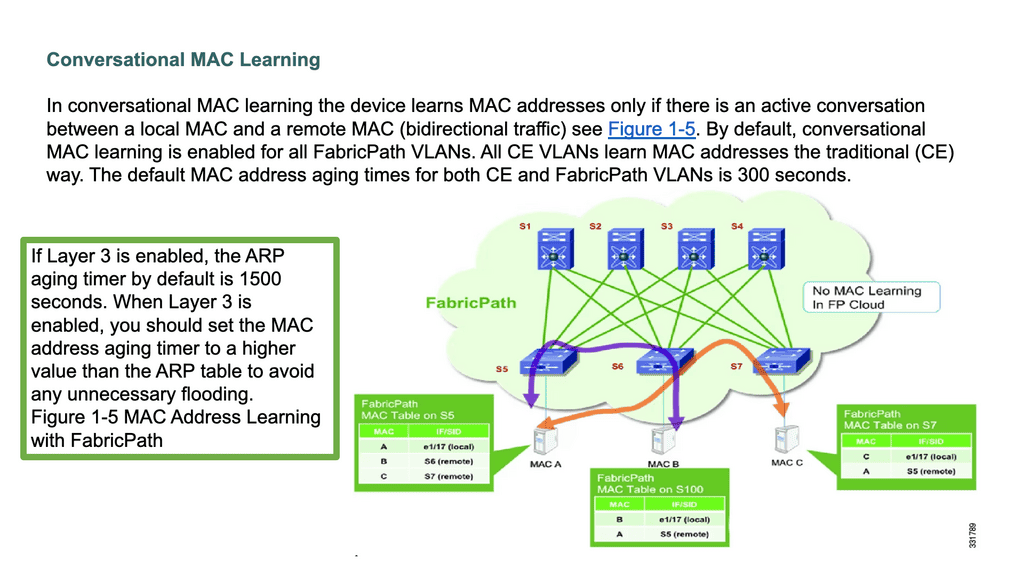
With FabricPath, MAC addresses are learned selectively based on active flows with conversational MAC learning. As a result, the need for large MAC tables is reduced.
Related: Before you proceed, you may find the following posts helpful:
Scalable Layer 2
We must support distributed applications at a considerable scale and have the flexibility to provision them in different zones of data center topologies. This necessitated creating a scalable and resilient Layer 2 fabric enabling any-to-any communication without workload placement restrictions—Cisco developed FabricPath to meet these new demands.
FabricPath is a powerful network technology from Cisco Systems that provides a unified, programmable fabric to connect, manage, and optimize data center networks. It is based on a distributed Layer 2 network protocol that enables the creation of multi-tenant, multi-domain, and multi-site networks with a single, unified control plane. FabricPath operates on a flat, non-hierarchical topology designed to simplify network virtualization and automation.
FabricPath delivers a highly scalable Layer 2 fabric
FabricPath delivers a highly scalable Layer 2 fabric. It uses a single control protocol (IS-IS) for unicast forwarding, multicast forwarding, and VLAN pruning. FabricPath also enables traffic to be forwarded across the shortest path to the destination, thus reducing latency in the Layer 2 network. This is more efficient than Layer 2 forwarding based on the STP.
FabricPath includes several features that make it ideal for large enterprise networks and data centers. It uses a distributed control plane to provide a unified view of the network and reduce network complexity. In addition, FabricPath supports virtualization, allowing the creation of multiple virtual networks within the same physical infrastructure. It also allows the creation of multiple forwarding instances and provides fast convergence times.
The Challenges Of Inefficient Forwarding Schemes
1: The challenge is that existing switching technologies have inefficient IP forwarding schemes based on spanning trees and cannot be extended to the network. Therefore, current designs compromise the flexibility of Layer 2 and the scaling offered by Layer 3. On the other hand, Fabric Path introduces a new method of forwarding.
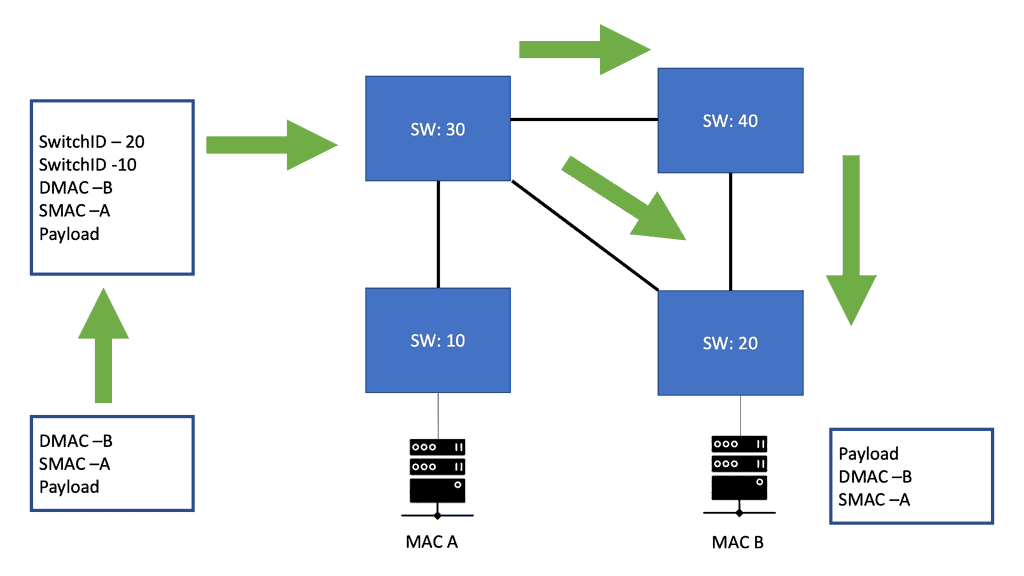
2: The data design can stay the same as a leaf and spine. Still, we have a new Layer 2 data plane with fabric paths that encapsulate the frames entering the fabric with a header consisting of routable source and destination addresses.
3: These addresses are the address of the switch on which the frame was received and the address of the destination switch to which the frame is heading. From there, the frame is routed until it reaches the remote switch, where it is de-encapsulated and delivered in its original Ethernet format. FabricPath Nexus also uses a Shortest Path First (SPF) routing protocol to determine reachability and path selection in the FabricPath domain.
4: With Fabric Path, we have a simple and flexible behavior of Layer 2 while using the routing mechanisms that make IP reliable and scalable. So you may ask, what about the Layer 2 and 3 boundaries? The Layer 2 and 3 boundary still exists in a data center based on Cisco FabricPath. However, there is little difference in how traffic is forwarded in those two distinct areas of the network. The following sections discuss the drivers for FabricPath and what you may opt for in its design.
**Why Cisco Fabricpath?**
1) No Multipathing support at Layer 2: Spanning Tree Protocol ( STP ) lacks any good Layer 2 multipathing features for large data centers. The protocol has been enhanced with PVST per VLAN load balancing, but this feature can only load balance on VLANs.
2) MAC address scalability: Layer 2 end hosts are discovered by their MAC address, and this type of host addressing cannot be hierarchical and summarized. For example, one MAC address cannot represent a stub of networks. Traditional Layer 3 networks overcome this by introducing ABRs in OSPF or summarization/filtering in EIGRP. Also, in the Layer 2 network, all the MAC addresses are populated in ALL switches, leading to large requirements in the Layer 2 table sizes.
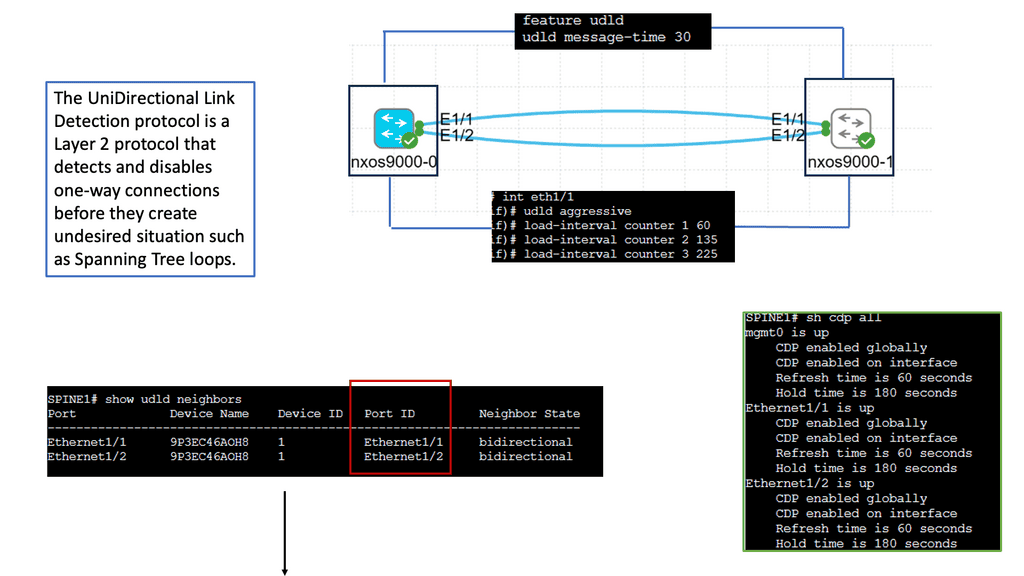
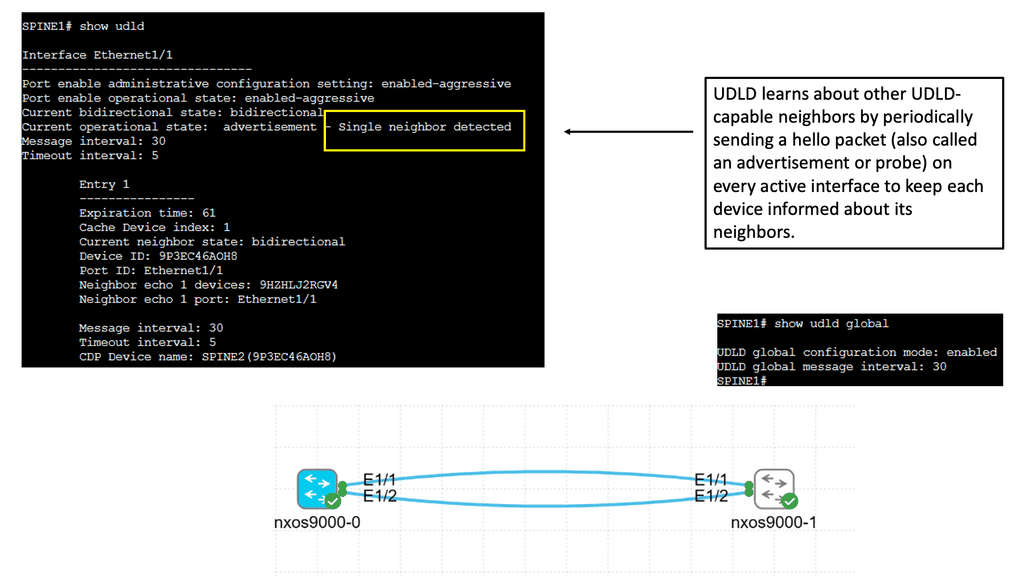
3) Instability of Layer 2 networks: Layer 3 networks have an eight-bit Time to Live ( TTL ) field that prevents datagrams from persisting (e.g., going in circles ) on the internet. However, compared to Layer 3 headers, the Layer 2 packet header does not have a TTL field. The lack of a TTL field will cause Layer 2 packets to loop infinitely, causing a network meltdown.
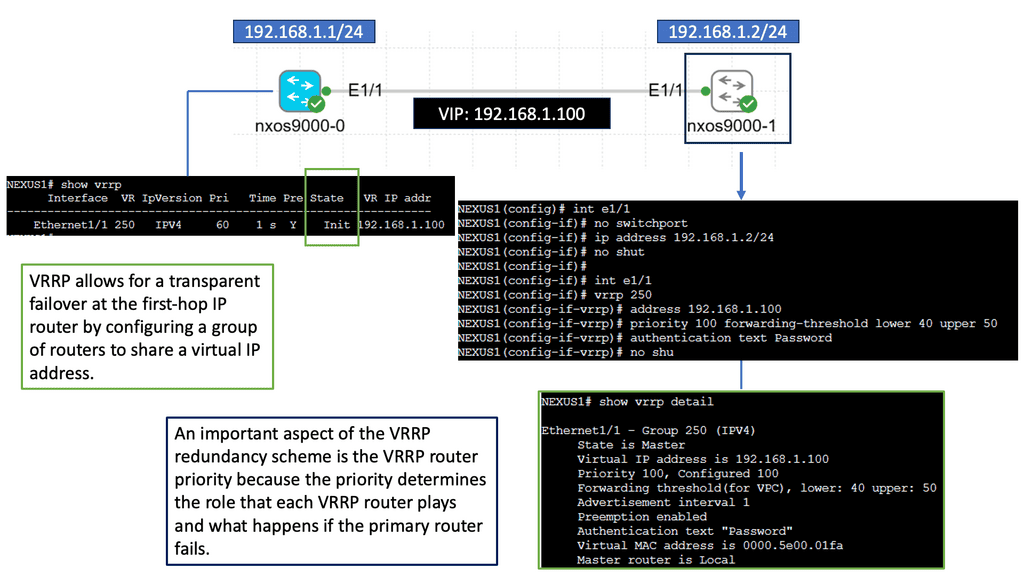
4) Incompetent path selection: The shortest path for a Layer 2 network depends on the placement of the Root switch. Depending on costs and port priorities, you can influence the root port selection ( forwarding port ), but the root switch’s placement is how the forwarding path is built.
For example, in the diagram below, the most optimum traffic for the server-to-server flows would be via the inter-switch link, but as you can see, spanning tree blocks, this port, and traffic takes the sub-optimal path through the distribution switch.
Issues with Spanning Tree: Vendors’ responses.
A Spanning Tree allows only one path to be active between any two nodes and blocks the rest, making it unsuitable for low-latency data centers and cloud environments. Every vendor addressing the data center market proposes augmenting or replacing a Spanning Tree with a link-state protocol.
For example, Brocade uses TRILL in the data plane, while the control plane is based on Fabric Shortest Path First, an ANSI standard used by all Fibre Channel SAN fabrics as the link-state routing protocol.
On the other hand, Juniper implemented a tagging mechanism in the Broadcom silicon in its QFabric switches rather than a link-state protocol. Cisco FabricPath is considered a “superset” of TRILL, bringing scale to the data center and improving application performance.
Fabric Path typical use cases
Fabric Path can support any new protocol that can be done elegantly in IS-IS by adding new extensions without modifying the base infrastructure. Each IS-IS Intermediate router advertises one or more IS-IS Link State Protocol Data Units (LSPs) with routing information.
The LSP comprises a fixed header and several tuples, each consisting of a Type, a Length, and a Value. Such tuples are commonly known as TLVs and are a good way of encoding information in a flexible and extensible format. These make IS-IS a very extensible routing protocol, and FabricPath takes advantage of this extensibility.
This allows FarbicPath to support the following prominent use cases.
- Large flat data centers that need Layer 2 multipathing and equidistant endpoints.
- DC requires a reduction of Layer 2 table sizes ( done via MAC conversational learning ).
Cisco FabricPath control plane
FabricPath is a Layer 2 overlay network with an IS-IS control plane. Using FabricPath IS-IS, the switches build their forwarding tables, similar to building the forwarding table in Layer 3 networks. The extensions used in IS-IS to support Fabricpath allow this Layer 2 overlay to take advantage of all the scalable and load balancing ( ECMP, up to 16 routes ) benefits of a Layer 3 network while retaining the benefits of a plug-and-play Layer 2 network.
The FabricPath Header
The FabricPath header has a hop count in one of the fields, which mitigates temporary loops in FabricPath networks. This header uses locally assigned hierarchical MAC addresses for forwarding frames within the network. The original Layer 2 frames are encapsulated with a FabricPath header, and a new CRC is appended to the existing packet. One of the main elements of the FabricPath header is the SwitchID, and the core switches forward Fabricpath traffic by examining this field. The switch ID is the field used in the FabricPath domain to forward packets to the correct destination switch.
Why use IS-IS as the FabricPath Nexus control plane?
We touched on this just a moment ago. Its control protocol is built on top of the Intermediate System–to Intermediate System (IS-IS) routing protocol, which provides fast convergence and has been proven to scale up to the largest service provider environments.
- IS-IS is flexible and can be extended to support other functions with new type-length values (TLVs).
- TLV is also known as tag-length value and encodes optional information.IS-IS runs directly over the link layer, thereby preventing the need for any underlying Layer 3 protocol like IP to work.
Virtual PortChannel
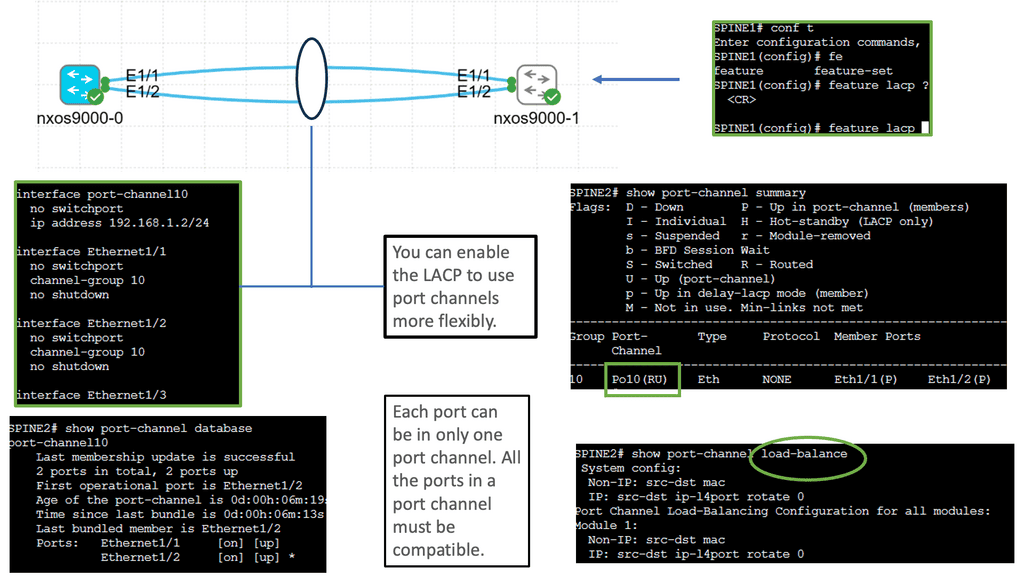
Fabricpath Nexus uses Virtual PortChannel. Now, we have multiple active link capabilities, resulting in active-active forwarding paths. The vPC allows a more granular design over standard port channeling, which only allows you to terminate on one switch. In addition, Cisco vPC enables a more flexible triangular design. Both aggregation technologies can use LACP for the control plane to negotiate the links.
Virtual Device Context
Fabricpath Nexus also uses Virtual Device Contexts (VDC), which allows each FabricPath control-plane protocol and functional block to run in its own protected memory space as individual processes for stability and fault isolation. A VDC design enables modular building blocks to improve security and performance.
**FabricPath Nexus and conversational MAC learning**
FabricPath Nexus performs conversational MAC learning, enabling a switch to learn only those MACs involved in active bidirectional communication. Similar to a three-way handshake, this new technique leads to the population of only the interested host’s MAC addresses rather than all MAC addresses in the domain. This dramatically reduces the need for large table sizes as each switch only learns the MAC addresses that the hosts under its interface are actively communicating with. As a result, edge nodes only know the MAC addresses of local nodes or nodes that want to speak with local nodes directly.
FabricPath Nexus benefits and drawbacks
Benefits | Drawbacks |
Plug-and-play features like Classical Ethernet | Cisco proprietary |
The single control plane for ALL types of traffic and good troubleshooting features to debug problems at Layer 2 | Fabric interfaces carry only FabricPath encapsulated traffic |
High performance and high availability using multipathing** | Useful as a DCI solution only over short distances |
Easy to add new devices to an existing FabricPath domain | NA |
Small Layer 2 table sizes result in better performance | NA |
** This enables the MSDC networks to have flat topologies, separating the nodes by a single hop.
Although IS-IS forms the basis of Cisco FabricPath, you don’t need to be an IS-IS expert. You can enable FabricPath interfaces and begin forwarding FabricPath encapsulated frames in the same way they can activate Spanning Tree and interconnect switches.
The only necessary configuration is distinguishing the core ports, which link the switches, from the edge ports, where end devices are attached. No other parameters need to be tuned to achieve an optimal configuration, and the switch addresses are assigned automatically for you.
Closing Points on FabricPath
Cisco FabricPath is an innovative technology that combines the best of both Layer 2 and Layer 3 architectures. By leveraging the Intermediate System to Intermediate System (IS-IS) protocol, it simplifies network topology and enhances scalability. Unlike traditional spanning tree protocols, FabricPath eliminates loop issues and provides multipath capabilities, ensuring optimal data flow across the network. This section will explore how FabricPath works and why it’s a game-changer for modern networks.
One of the standout features of Cisco FabricPath is its ability to create a flat, scalable network fabric that supports large-scale data center environments. It offers seamless mobility, allowing for the efficient movement of virtual machines across the network without impacting performance. Additionally, FabricPath supports equal-cost multipathing (ECMP), which optimizes bandwidth usage and enhances network resiliency. This section will break down these features and explain how they contribute to a more efficient and reliable networking environment.
Successfully deploying Cisco FabricPath requires a strategic approach. This section will provide best practices for implementation, including considerations for network design, hardware compatibility, and performance optimization. We’ll also discuss common challenges and how to overcome them, ensuring a smooth transition to a FabricPath-enabled network. By following these guidelines, organizations can maximize the benefits of FabricPath and future-proof their network infrastructure.