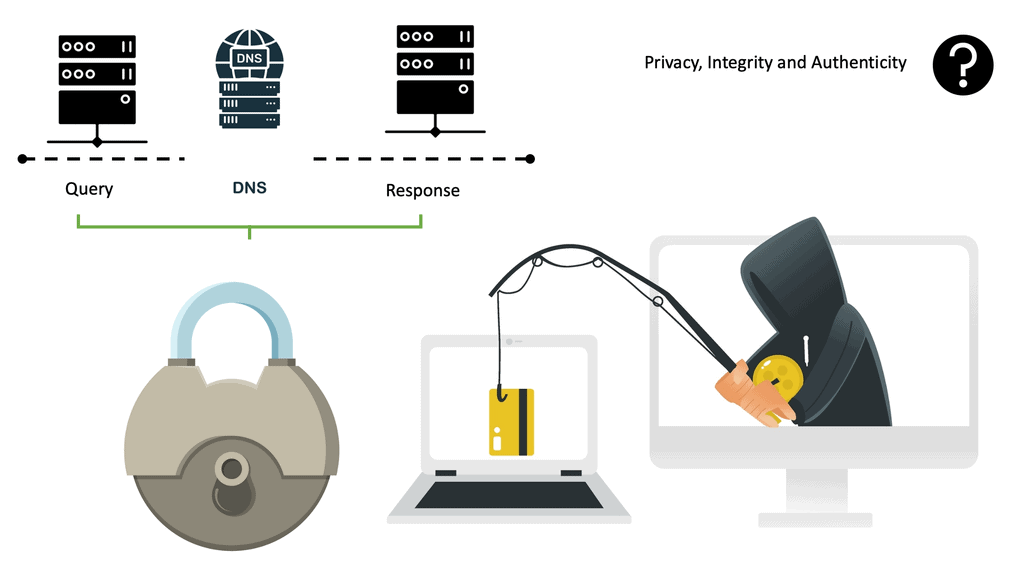
DNS Security Solutions In today’s interconnected digital world, ensuring the security of your online presence is of paramount importance. One crucial aspect often overlooked is Domain Name System (DNS) security. In this blog post, we will delve into the world of DNS security solutions, exploring their significance, benefits, and implementation. …
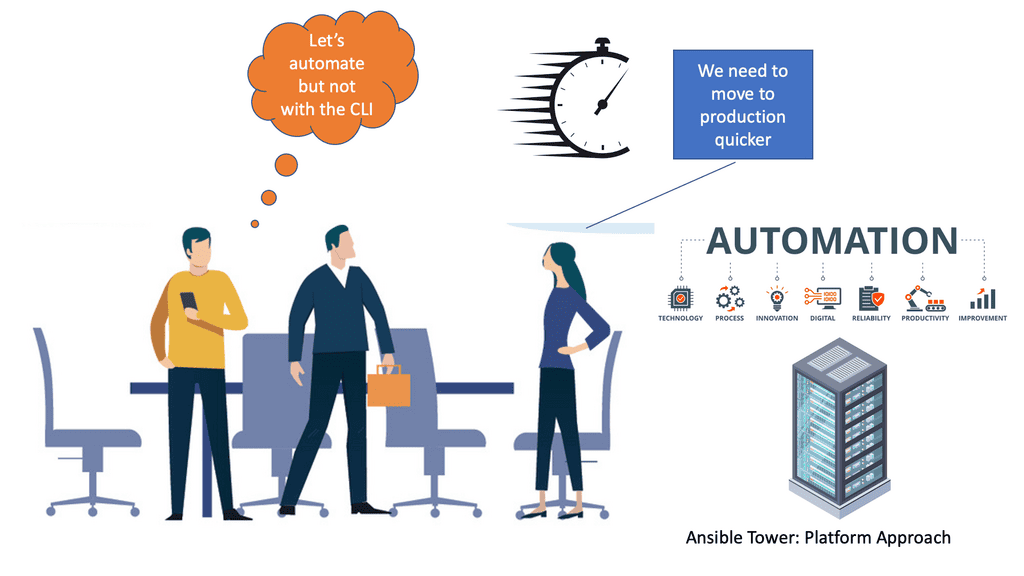
Ansible Tower In today’s fast-paced world, businesses rely heavily on efficient IT operations to stay competitive and meet customer demands. Manual and repetitive tasks can slow the workflow, leading to inefficiencies and increased costs. This is where Ansible Tower comes in – a powerful automation platform that empowers organizations to …
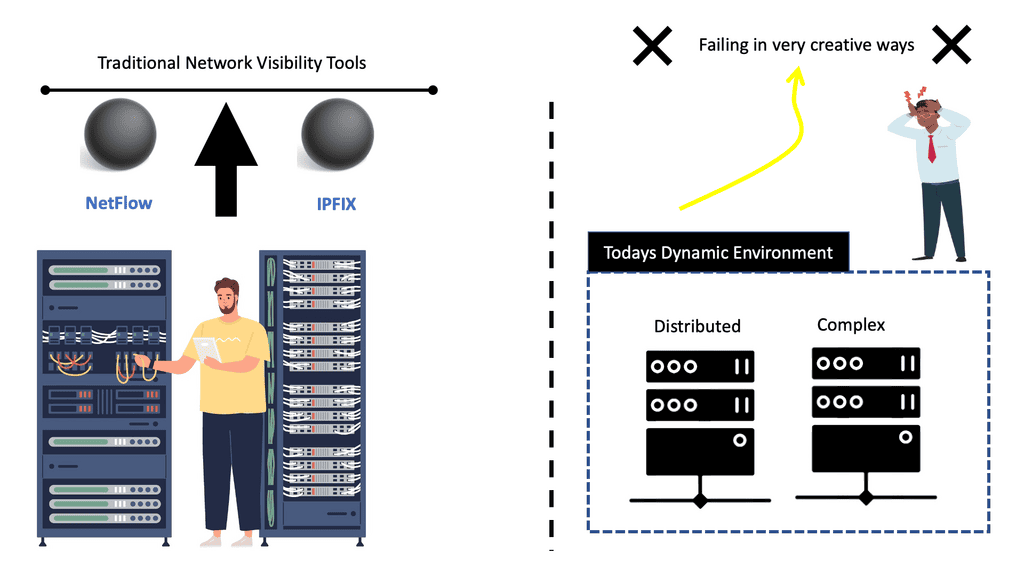
Network Visibility In today’s interconnected world, where digital operations are the backbone of businesses, network visibility plays a crucial role in ensuring seamless connectivity, robust security, and optimal performance. This blog explores the significance of network visibility and how it empowers organizations to stay ahead in the ever-evolving technological landscape. …
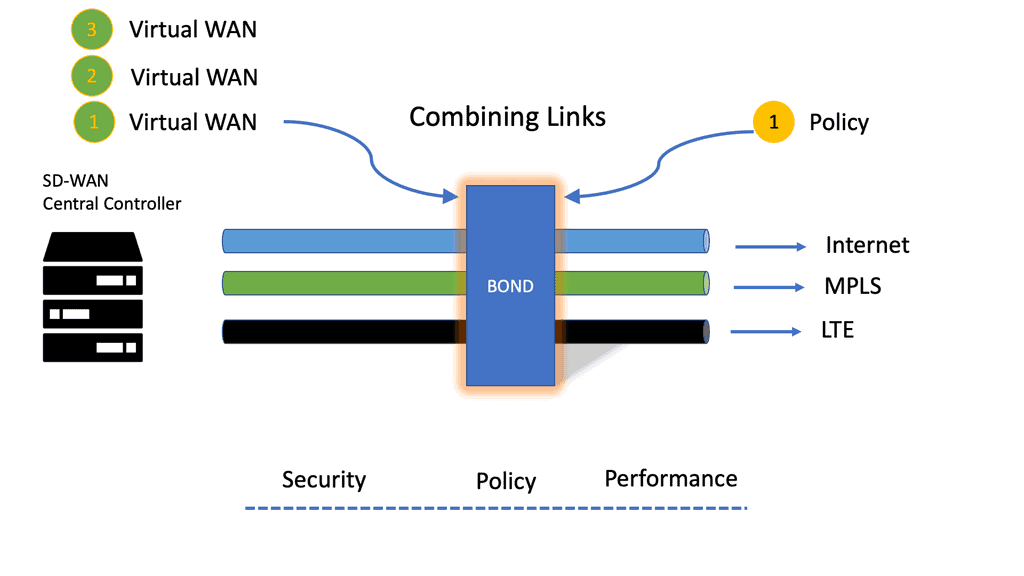
WAN Monitoring In today’s digital landscape, the demand for seamless and reliable network connectivity is paramount. This is where Software-Defined Wide Area Networking (SD-WAN) comes into play. SD-WAN offers enhanced agility, cost savings, and improved application performance. However, to truly leverage the benefits of SD-WAN, effective monitoring is crucial. In …

Implementing Network Security In today’s interconnected world, where technology reigns supreme, the need for robust network security measures has become paramount. This blog post aims to provide a detailed and engaging guide to implementing network security. By following these steps and best practices, individuals and organizations can fortify their digital …
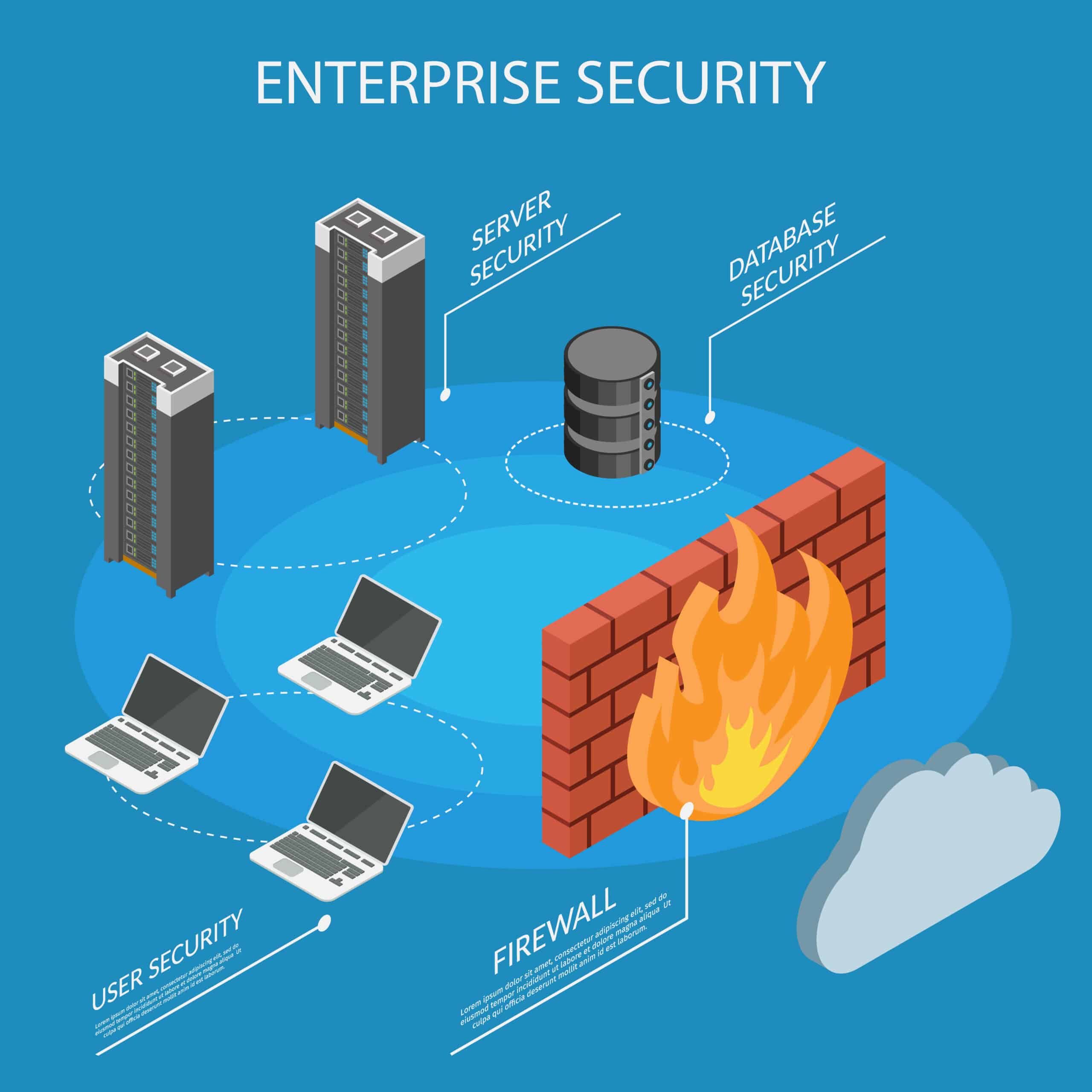
Network Security Components In today’s interconnected world, network security plays a crucial role in protecting sensitive data and ensuring the smooth functioning of digital systems. A strong network security framework consists of various components that work together to mitigate risks and safeguard valuable information. In this blog post, we will …

Open Networking In today’s digital age, where connectivity is the lifeline of businesses and individuals alike, open networking has emerged as a transformative approach. This blogpost delves into the concept of open networking, its benefits, and its potential to revolutionize the way we connect and communicate. Open networking refers to …
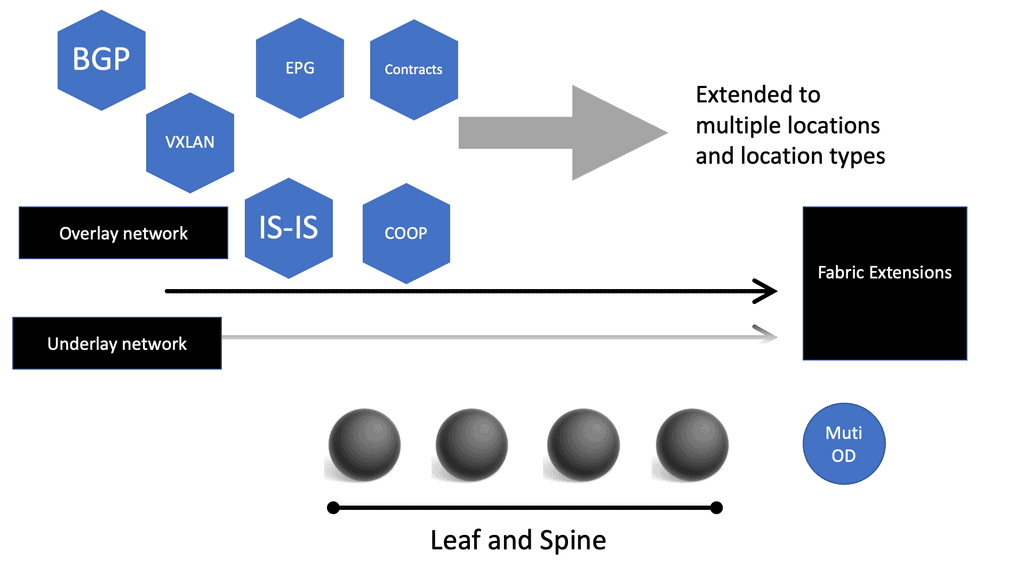
Cisco ACI Components In today’s rapidly evolving technological landscape, organizations are constantly seeking innovative solutions to streamline their network infrastructure. Enter Cisco ACI Networks, a game-changing technology that promises to redefine networking as we know it. In this blog post, we will explore the key features and benefits of Cisco …
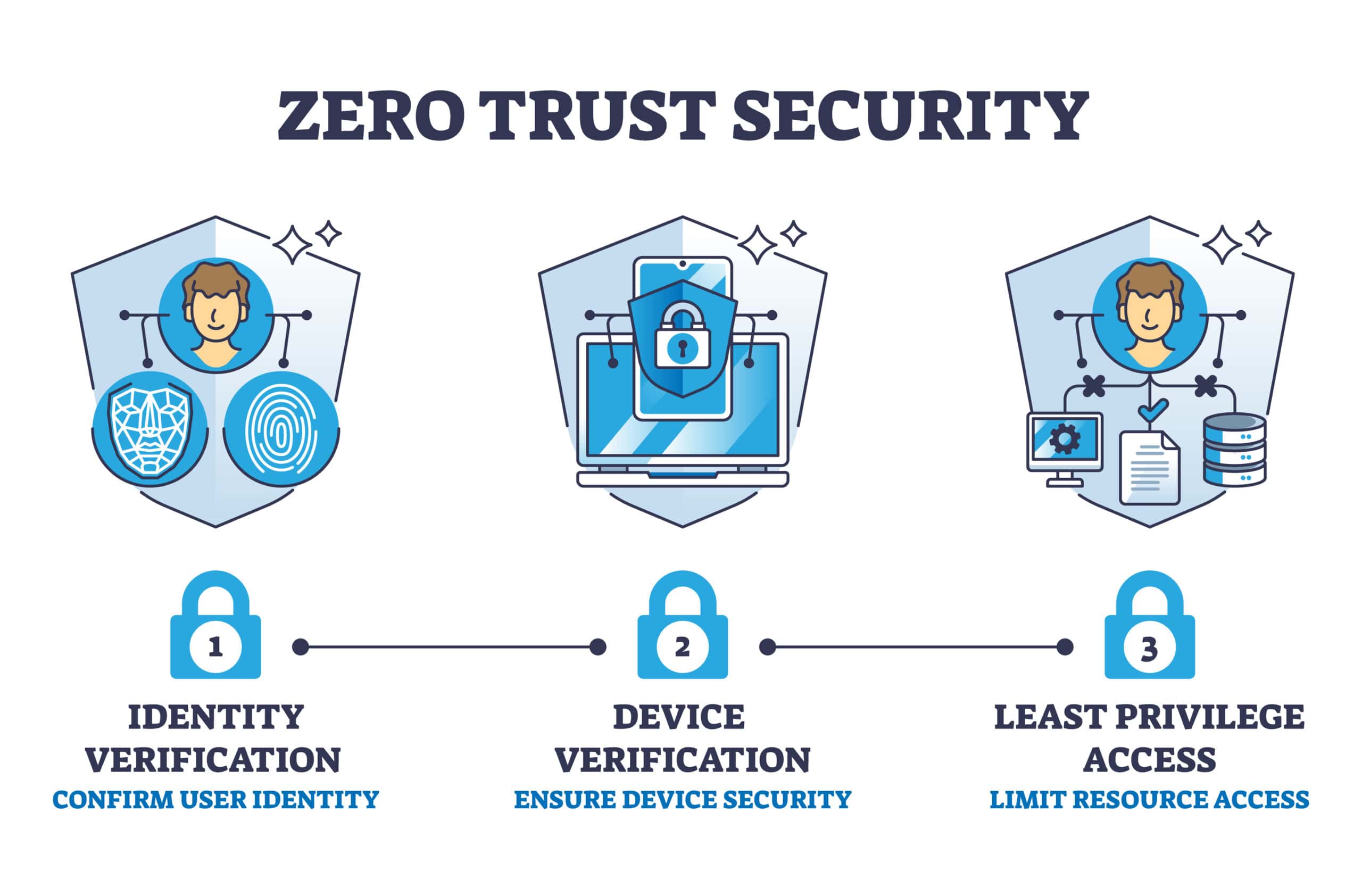
Zero Trust SASE In today’s digital age, where remote work and cloud-based applications are becoming the norm, traditional network security measures are no longer sufficient to protect sensitive data. Enter Zero Trust Secure Access Service Edge (SASE), a revolutionary approach that combines the principles of Zero Trust security with the …
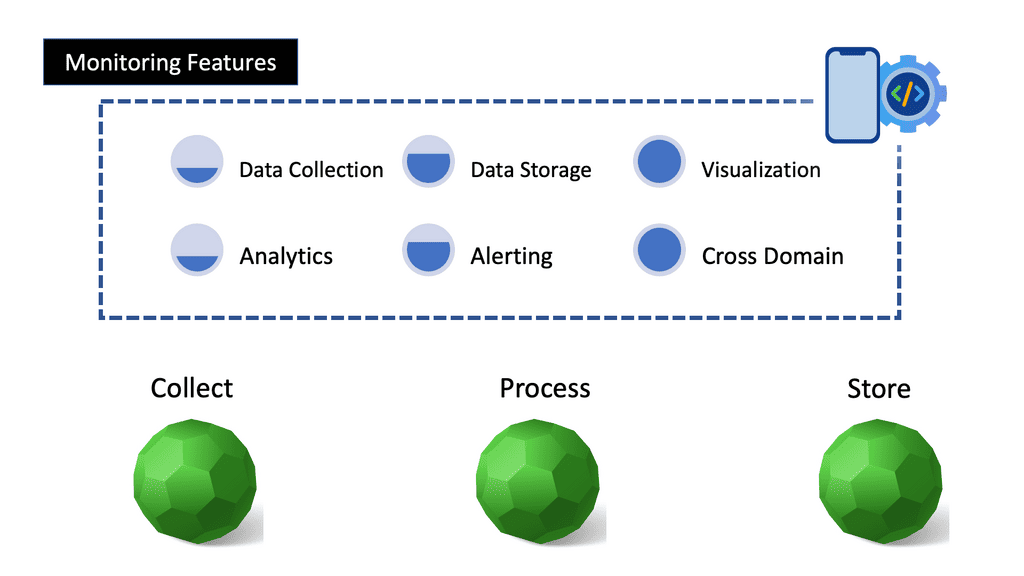
Monitoring Microservices In the world of software development, microservices have gained significant popularity due to their scalability, flexibility, and ease of deployment. However, as the complexity of microservices architectures grows, so does the need for robust observability practices. In this blog post, we will delve into the realm of microservices …
Cisco ACI | ACI Infrastructure In the ever-evolving landscape of network infrastructure, Cisco ACI (Application Centric Infrastructure) stands out as a game-changer. This innovative solution brings a new level of agility, scalability, and security to modern networks. In this blog post, we will delve into the world of Cisco ACI, …

SASE Definition In today’s ever-evolving digital landscape, businesses are seeking agile and secure networking solutions. Enter SASE (Secure Access Service Edge), a revolutionary concept that combines network and security functionalities into a unified cloud-based architecture. In this blog post, we will delve into the definition of SASE, its components, implementation …