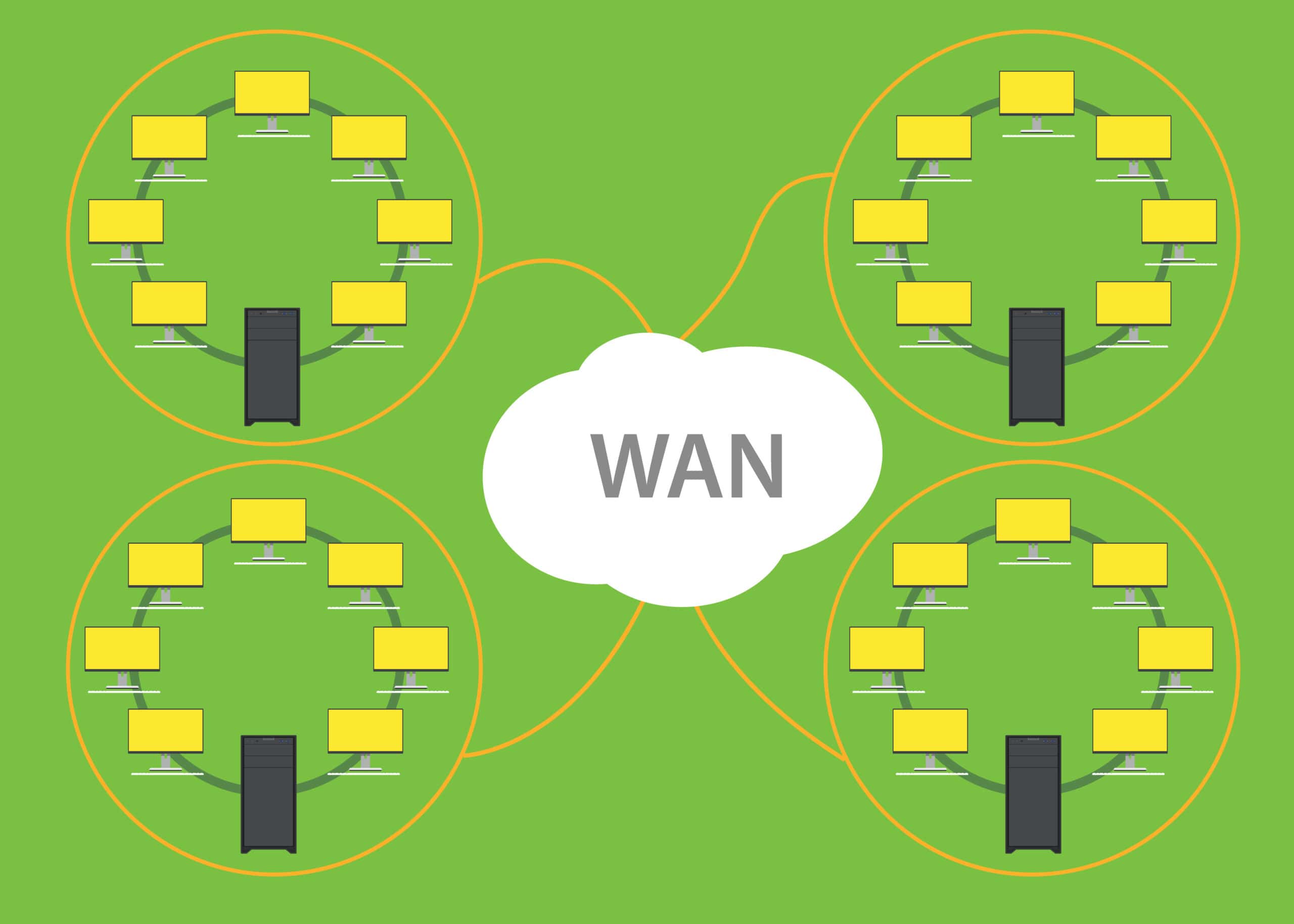
DMVPN Cisco DMVPN is based on a virtual private network (VPN), which provides private connectivity over a public network like the Internet. Furthermore, the DMVPN network takes this VPN concept further by allowing multiple VPNs to be deployed over a shared infrastructure in a manageable and scalable way. This shared …
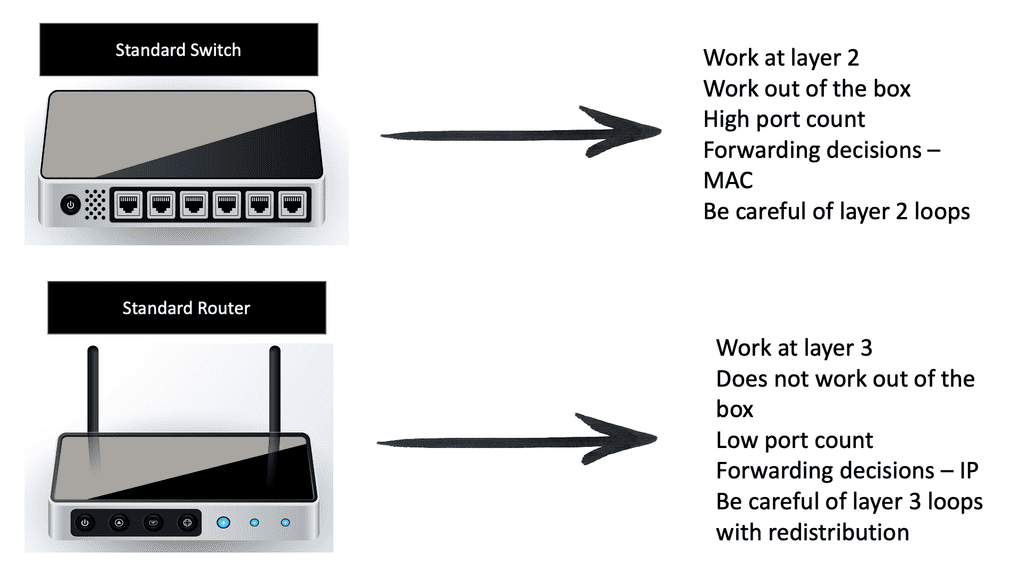
Computer Networking Computer networking has revolutionized how we communicate and share information in today’s digital age. Computer networking offers many possibilities and opportunities, from the Internet to local area networks. This blog post will delve into the fascinating world of computer networking and discover its key components, benefits, and prospects. …
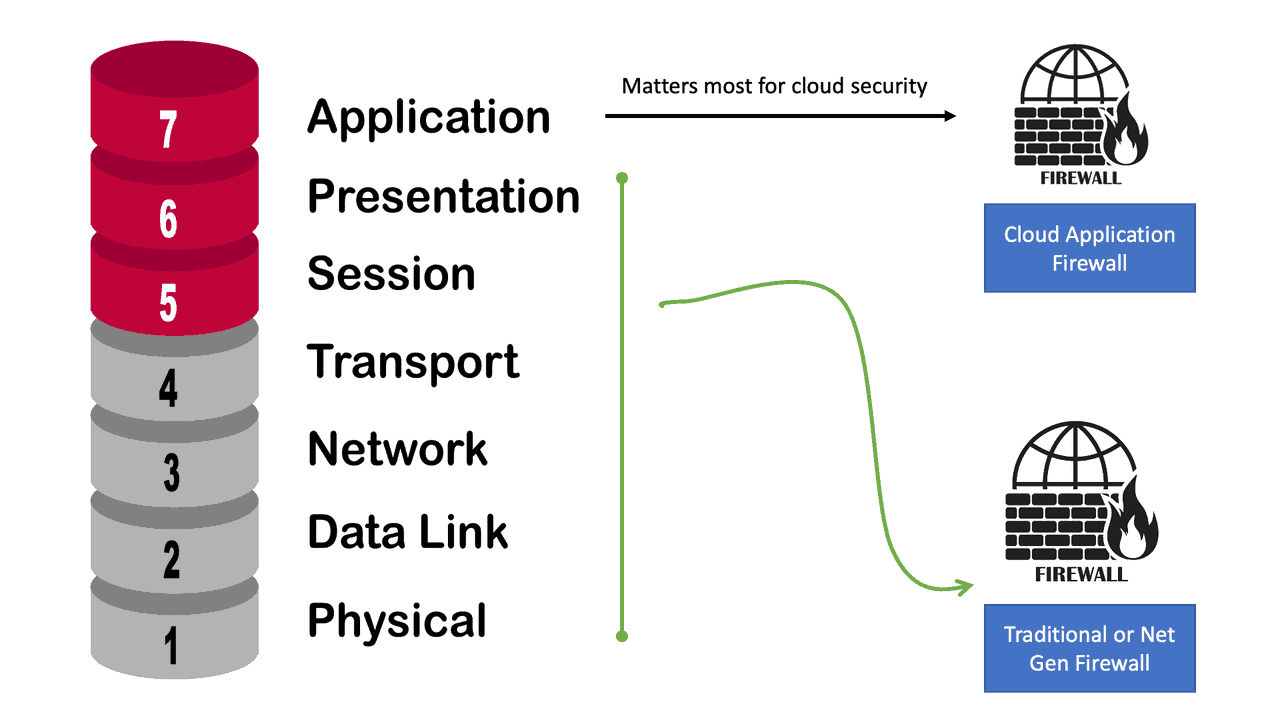
In the following ebook, we will address the key points: Challenging Landscape The rise of SASE based on new requirements SASE definition Core SASE capabilities Final recommendations For pre-information, you may find the following links useful: SD WAN SASE Zero Trust SASE SASE Model SASE Solution Cisco Secure …
Cisco CloudLock In today’s digital age, data security is of utmost importance. With the increasing number of cloud-based applications and the growing risk of data breaches, organizations need robust solutions to protect their sensitive information. One such solution is Cisco Cloudlock, a powerful cloud security platform. In this blog post, …
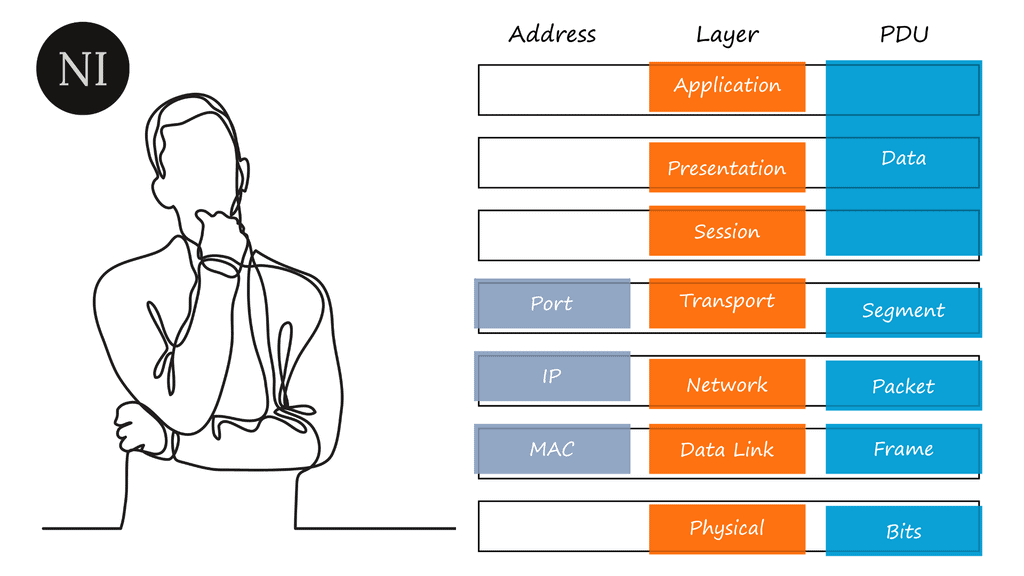
Network Connectivity Network connectivity has become integral to our lives in today’s digital age. A reliable and efficient network is crucial, from staying connected with loved ones to conducting business operations. In this blog post, we will explore the significance of network connectivity and how it has shaped our world. …
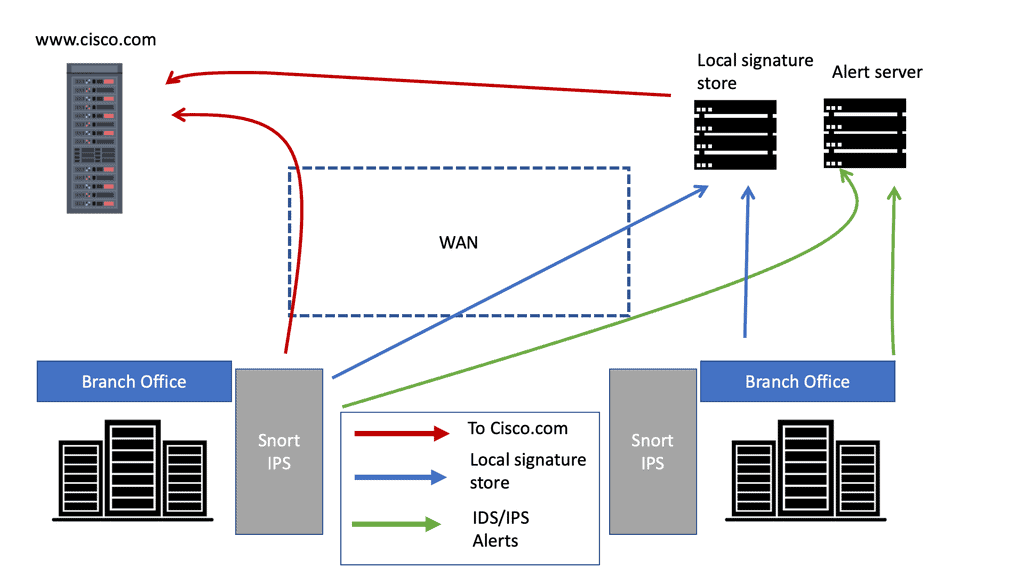
Cisco Firewall with IPS In today’s digital landscape, the need for robust network security has never been more critical. With the increasing prevalence of cyber threats, businesses must invest in reliable firewall solutions to safeguard their sensitive data and systems. One such solution that stands out is the Cisco Firewall. …
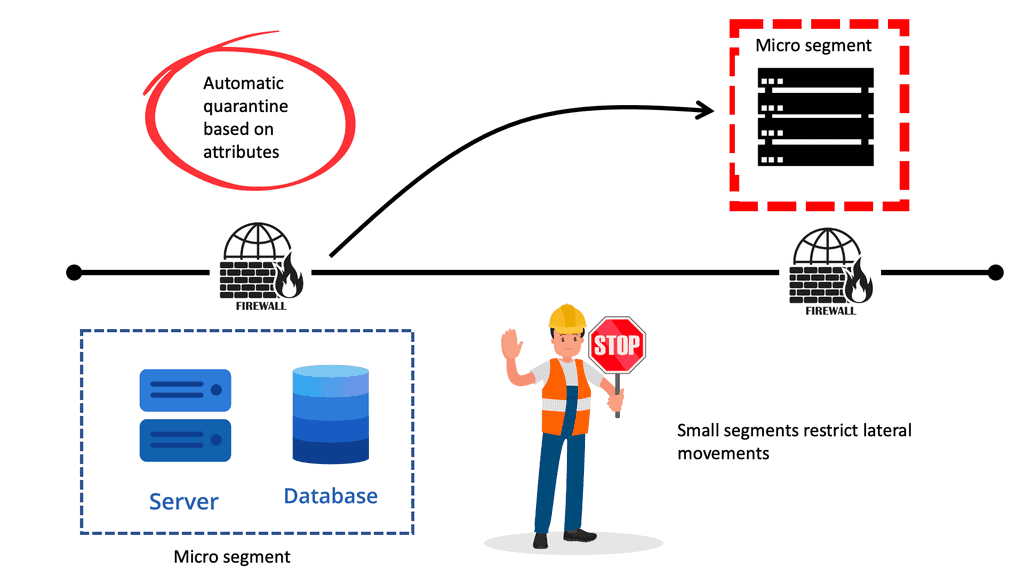
Data Center Security Data centers are crucial in storing and managing vast information in today’s digital age. However, with increasing cyber threats, ensuring robust security measures within data centers has become more critical. This blog post will explore how Cisco Application Centric Infrastructure (ACI) can enhance data center security, providing …
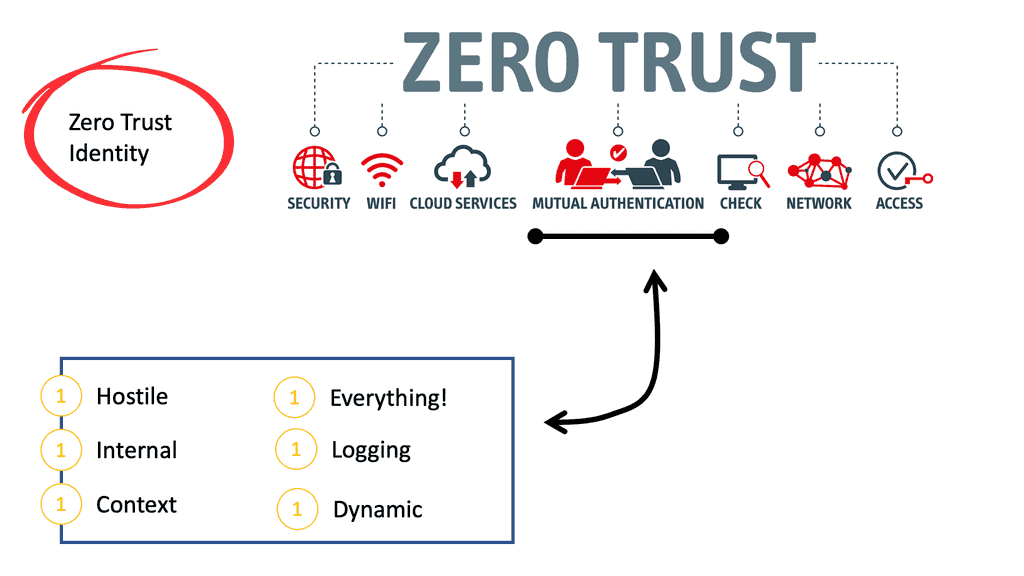
Identity Security In today’s interconnected world, protecting our personal information has become more crucial than ever. With the rise of cybercrime and data breaches, ensuring identity security has become a paramount concern for individuals and organizations alike. In this blog post, we will explore the importance of identity security, common …
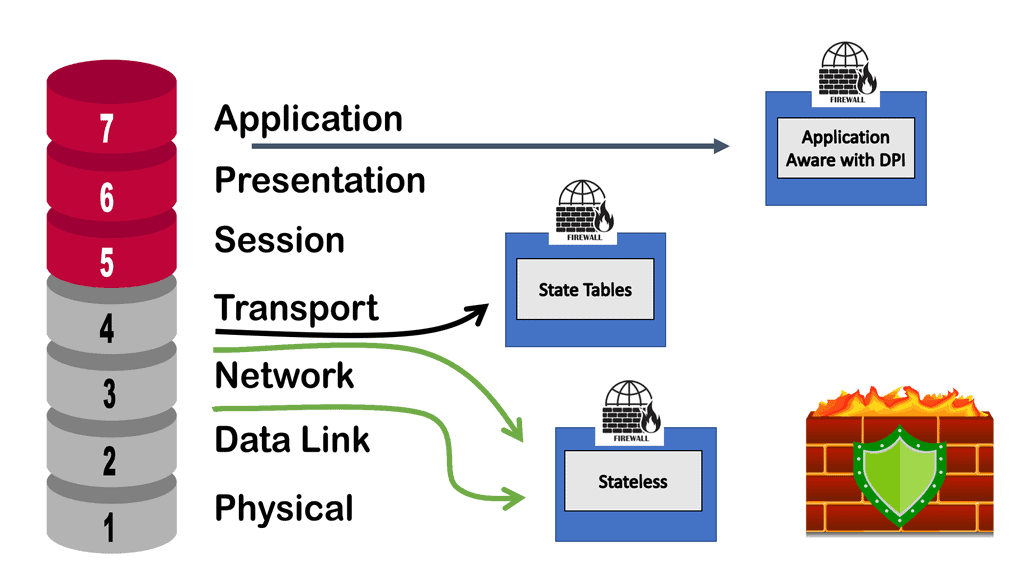
Cisco Secure Firewall with SASE Cloud In today’s digital era, network security is of paramount importance. With the rise of cloud-based services and remote work, businesses require a comprehensive security solution that not only protects their network but also ensures scalability and flexibility. Cisco Secure Firewall with SASE (Secure Access …
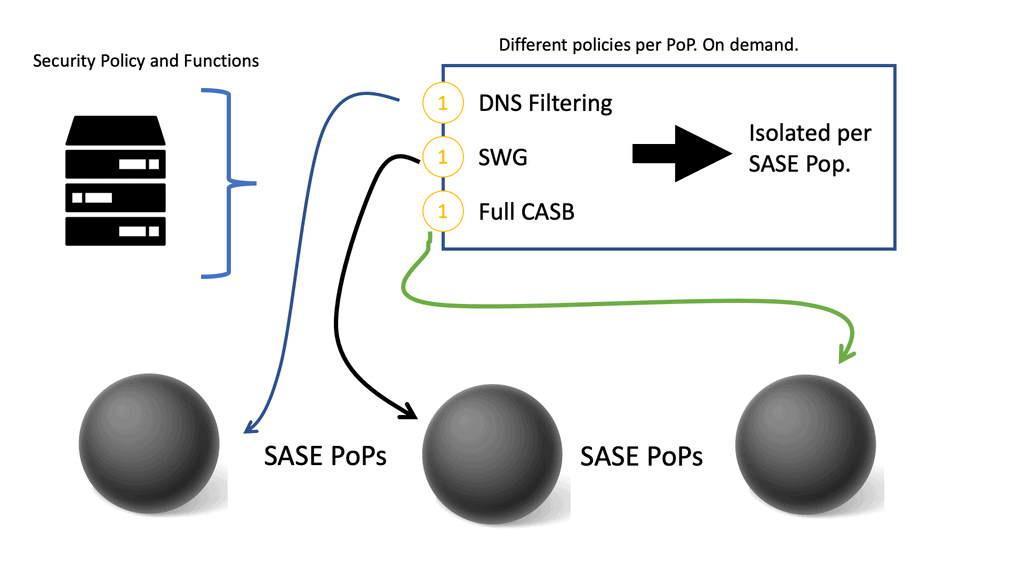
SASE Model | Zero Trust Identity In today’s ever-evolving digital landscape, the need for robust cybersecurity measures is more critical than ever. Traditional security models are being challenged by the growing complexity of threats and the increasing demand for remote work capabilities. This blog post delves into the SASE (Secure …
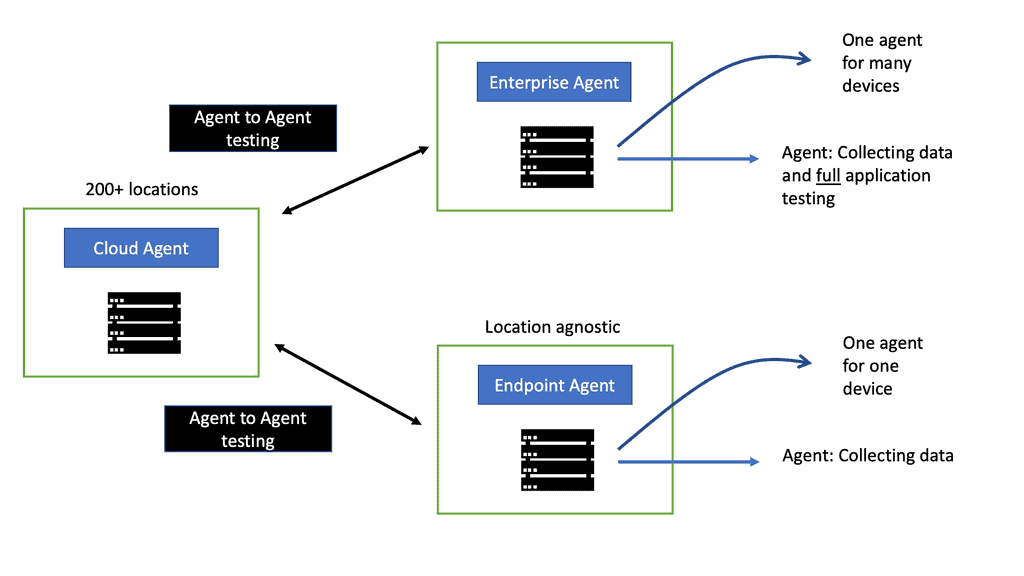
SASE Visibility with Cisco ThousandEyes In today’s interconnected digital landscape, enterprises are increasingly adopting Secure Access Service Edge (SASE) solutions to streamline their network and security infrastructure. One key aspect of SASE implementation is ensuring comprehensive visibility into the network performance and security posture. In this blog post, we will …
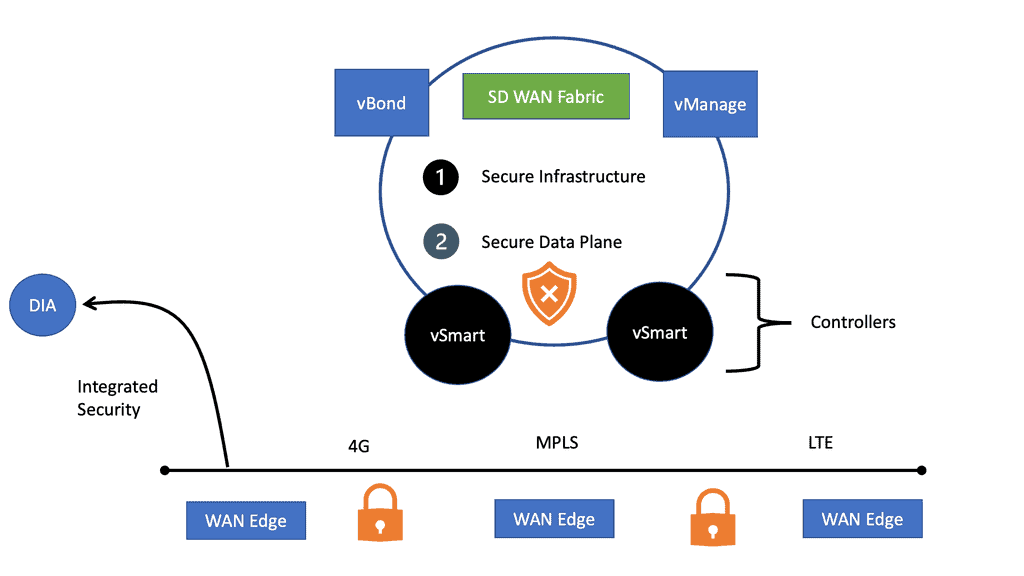
SD WAN Security In today’s interconnected world, where businesses rely heavily on networks for their daily operations, ensuring the security of Wide Area Networks (WANs) has become paramount. WANs are at the heart of data transmission, connecting geographically dispersed locations and enabling seamless communication. However, with the rise of cyber …