Hello,
I have created an “Enterprise Networking Tech Brief” Series. Kindly click on the link to view the video. I’m trying out a few videos styles.
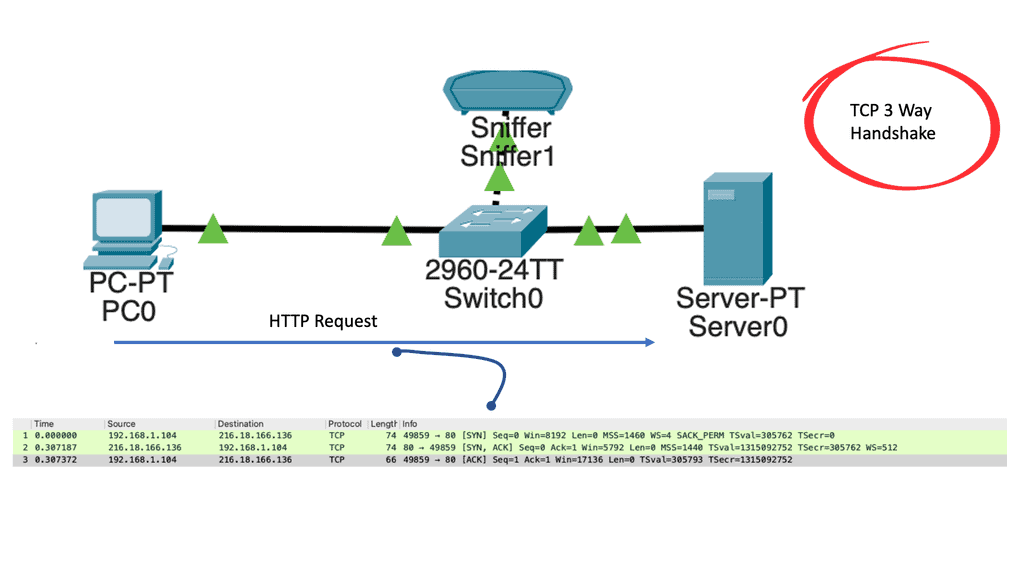
Enterprise Networking A – LISP Components & DEMO – > https://youtu.be/PBYvIhxwrSc
Enterprise Networking B – SD-Access & Intent-based networking – > https://youtu.be/WKoGSBw5_tc
” In campus networking, there are a number of different trends that are impacting the way networks will be built in the future. Mobility, pretty much every user that is getting onto the campus is a mobile device. It used to be only company-owned devices, nows it is about BYOD and wearables. It is believed that the average user will bring about 2.7 devices to the workplace – a watch, and intelligent wearables. This aspect access to printers or collaboration systems. They also expect the same type of access to cloud workloads and application workloads in private DC.
All this to be seamless across all devices. Iot – the corporate IoT within a campus network-connected light, card readers, all the things you would like to find in an office building. How do you make sure these cannot compromise your networks. Every attack we have seen in 12 – 19 has involved an insecure IoT device that is not managed or produced by I.T., In some cases, this IoT Device has access to the Internet, and the company network cause issues with malware and hacks. The source from Matt Conran Network World
Enterprise Networking C – Hands-on configuration for LISP introduction – > https://youtu.be/T1AZKK5p9PY
Enterprise Networking D – Introducing load balancing – > https://youtu.be/znhdUOFzEoM
” Load balancers operate at different Open Systems Interconnection ( OSI ) Layers from one data center to another; common operation is between Layer 4 and Layer 7. This is because each data centers hosts-unique applications with different requirements. Every application is unique with respect to the number of sockets, TCP connections ( short-lived or long-lived ), idle time-out, and activities in each session in terms of packets per second. One of the most important elements of designing a load-balancing solution is to understand fully the application structure and protocols”
Enterprise Networking E – Hand-on configuration for LISP Debugging – > https://youtu.be/h7axIhyu1Bs
Enterprise Networking F – Types of load balancing – > https://youtu.be/ThCX03JYoL8
“Application-Level Load Balancing: Load balancing is implemented between tiers in the applications stack and is carried out within the application. Used in scenarios where applications are coded correctly making it possible to configure load balancing in the application. Designers can use open source tools with DNS or some other method to track flows between tiers of the application stack. Network-Level Load Balancing: Network-level load balancing includes DNS round-robin, Anycast, and L4 – L7 load balancers. Web browser clients do not usually have built-in application layer redundancy, which pushes designers to look at the network layer for load balancing services. If applications were designed correctly, load balancing would not be a network-layer function.”
Enterprise Networking H – Introducing application performance and buffer sizes – > https://youtu.be/d36fPso1rZg
“Today’s data centers have a mixture of applications and workloads all with different consistency requirements. Some applications require predictable latency while others sustained throughput. It’s usually the case that the slowest flow is the ultimate determining factor affecting the end-to-end performance. So to try to satisfy varied conditions and achieve predictable application performance we must focus on consistent bandwidth and unified latency for ALL flows types and workloads.”
Enterprise Networking I – Application performance: small vs large buffer sizes – > https://youtu.be/JJxjlWTJbQU
“Both small and large buffer sizes have different effects on application flow types. Some sources claim that small buffers sizes optimize performance, while other claims that larger buffers are better. Many of the web giants including Facebook, Amazon, and Microsoft use small buffer switches. It depends on your environment. Understanding your application traffic pattern and testing optimizations techniques are essential to finding the sweet spot. Most out-of-the-box applications are not going to be fine-tuned for your environment, and the only rule of thumb is to lab test.
Complications arise when the congestion control behavior of TCP interacts with the network device buffer. The two have different purposes. TCP congestion control continuously monitors available network bandwidth by using packet drops as the metric. On the other hand buffering is used to avoid packet loss. In a congestion scenario, the TCP is buffered, but the sender and receiver have no way of knowing that there is congestion and the TCP congestion behavior is never initiated. So the two mechanisms that are used to improve application performance don’t compliment each other and require careful testing for your environment.”
Enterprise Networking J – TCP Congestion Control – > https://youtu.be/ycPTlTksszs
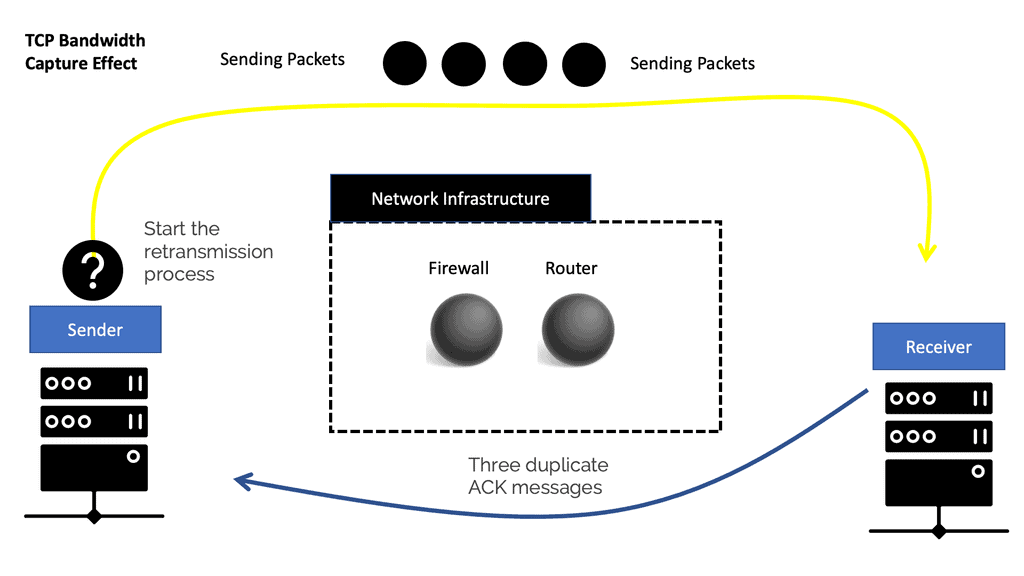
“The discrepancy and uneven bandwidth allocation for flow boil down to the natural behavior of how TCP reacts and interacts with insufficient packet buffers and the resulting packet drops. The behavior is known as the TCP/IP bandwidth capture effect. The TCP/IP bandwidth capture effect does not affect the overall bandwidth but more individual Query Completion Times and Flow Completion Times (FCT) for applications. The QCT and FCT are prime metrics for measuring TCP-based application performance. A TCP stream’s pace of transmission is based on a built-in feedback mechanism. The ACK packets from the receiver adjust the sender’s bandwidth to match the available network bandwidth. With each ACK received, the sender’s TCP starts to incrementally increase the pace of sending packets to use all available bandwidth. On the other hand, it takes 3 duplicate ACK messages for TCP to conclude packet loss on the connection and start the process of retransmission.”
Enterprise Networking K – Mice and Elephant flows – > https://youtu.be/vCB_JH2o1nk
” There are two types of flows in data center environments. We have a large, elephant and smaller mice flow. Elephant flows might only represent a low proportion of the number of flows but consume most of the total data volume. Mice flows are, for example, control and alarm/control messages and usually pretty significant. As a result, they should be given priority over larger elephant flows, but this is sometimes not the case with simple buffer types that don’t distinguish between flow types. Priority can be given by somehow regulating the elephant flows with intelligent switch buffers. Mice flows are often bursty flows where one query is sent to many servers. This results in many small queries getting sent back to the single originating host. These messages are often small only requiring 3 to 5 TCP packets. As a result, the TCP congestion control mechanism may not even be evoked as the congestion mechanisms take 3 duplicate ACK messages. Due to the size of elephant flows they will invoke the TCP congestion control mechanism (mice flows don’t as they are too small).
Enterprise Networking L – Multipath TCP – > https://youtu.be/Dfykc40oWzI
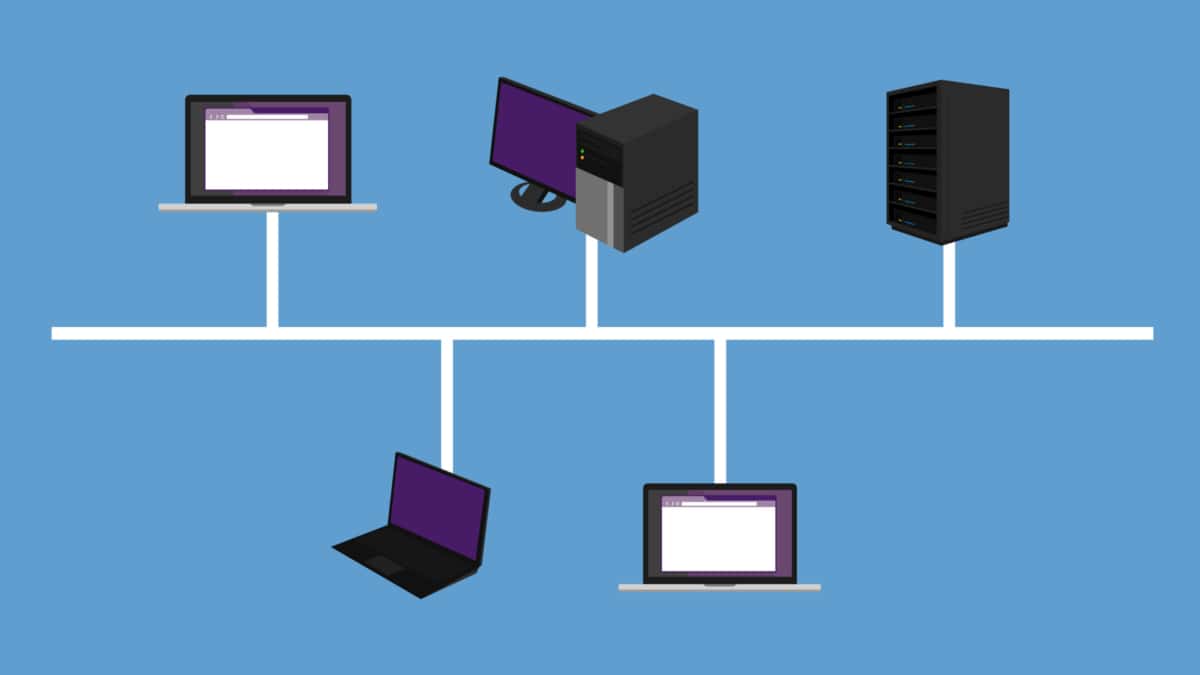
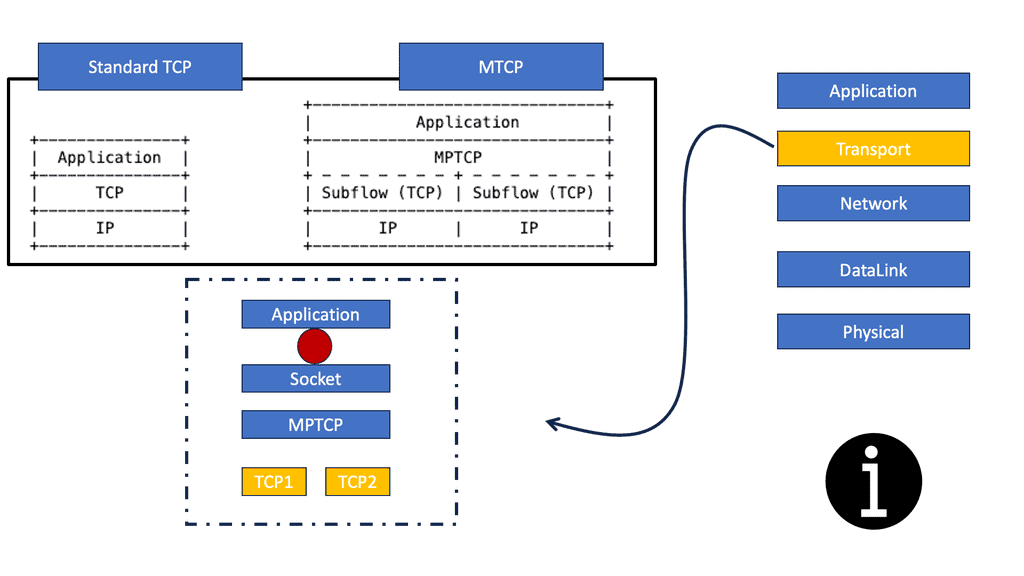
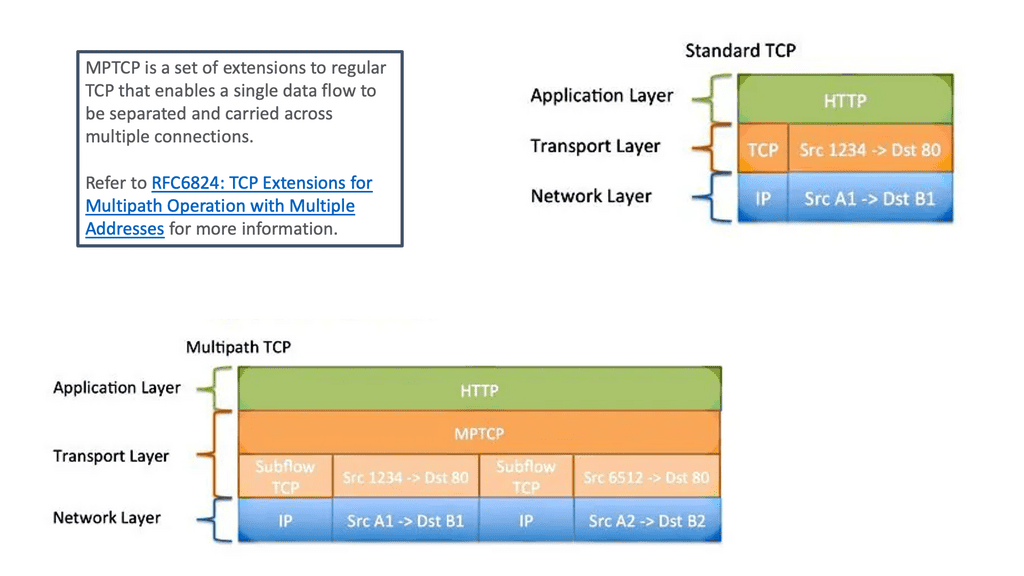
“Transmission Control Protocol (TCP) applications offer reliable byte stream with congestion control mechanisms adjusting flows to current network load. Designed in the 70s, TCP is the most widely used protocol and remains largely unchanged, unlike the networks it operates within. Back in those days the designers understood there could be link failure and decided to decouple the network layer (IP) from the transport layer (TCP). This enables the routing with IP around link failures without breaking the end-to-end TCP connection. Dynamic routing protocols do this automatically without the need for transport layer knowledge. Even Though it has wide adoption, it does not fully align with the multipath characteristics of today’s networks. TCP’s main drawback is that it’s a single path per connection protocol. A single path means once the stream is placed on a path ( endpoints of the connection) it can not be moved to another path even though multiple paths may exist between peers. This characteristic is suboptimal as the majority of today’s networks, and end hosts have multipath characteristics for better performance and robustness.”
Enterprise Networking M – Multipath TCP use cases – > https://youtu.be/KkL_yLNhK_E
“Multipath TCP is particularly useful in the multipath data center and mobile phone environments. All mobiles allow you to connect via WiFi and a 3G network. MPTCP enables either the combined throughput and the switching of interfaces ( Wifi / 3G ) without disrupting the end-to-end TCP connection. For example, if you are currently on a 3G network with an active TCP stream, the TCP stream is bound to that interface. If you want to move to the Wifi network you need to reset the connection and all ongoing TCP connections will, therefore, get reset. With MPTCP the swapping of interfaces is transparent. Next-generation leaf and spine data center networks are built with Equal-Cost Multipath (ECMP). Within the data center, any two endpoints are equidistant. For one endpoint to communicate to another, a TCP flow is placed on a single link, not spread over multiple links. As a result, single-path TCP collisions may occur, reducing the throughput available to that flow. This is commonly seen for large flows and not small mice flow.”
Enterprise Networking N – > Multipath TCP connection setup – > https://youtu.be/ALAPKcOouAA
“The aim of the connection is to have a single TCP connection with many subflows. The two endpoints using MPTCP are synchronized and have connection identifiers for each of the subflows. MPTCP starts the same as regular TCP. If additional paths are available additional TCP subflow sessions are combined into the existing TCP session. The original TCP session and other subflow sessions appear as one to the application, and the main Multipath TCP connection seems like a regular TCP connection. The identification of additional paths boils down to the number of IP addresses on the hosts. The TCP handshake starts as normal, but within the first SYN, there is a new MP_CAPABLE option ( value 0x0 ) and a unique connection identifier. This allows the client to indicate they want to do MPTCP. At this stage, the application layer just creates a standard TCP socket with additional variables indicating that it wants to do MPTCP. If the receiving server end is MP_CAPABLE it will reply with the SYN/ACK MP_CAPABLE along with its connection identifier. Once the connection is agreed the client and server will set upstate. Inside the kernel, this creates a Meta socket acting as the layer between the application and all the TCP subflows.”
More Videos to come!
Additional Enterprise Networking information can be found at the following: