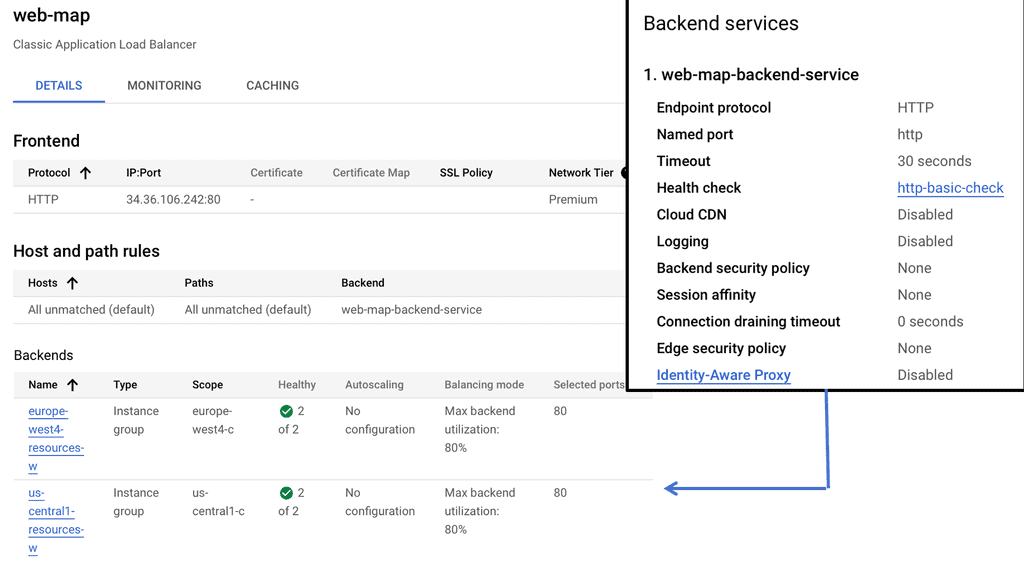
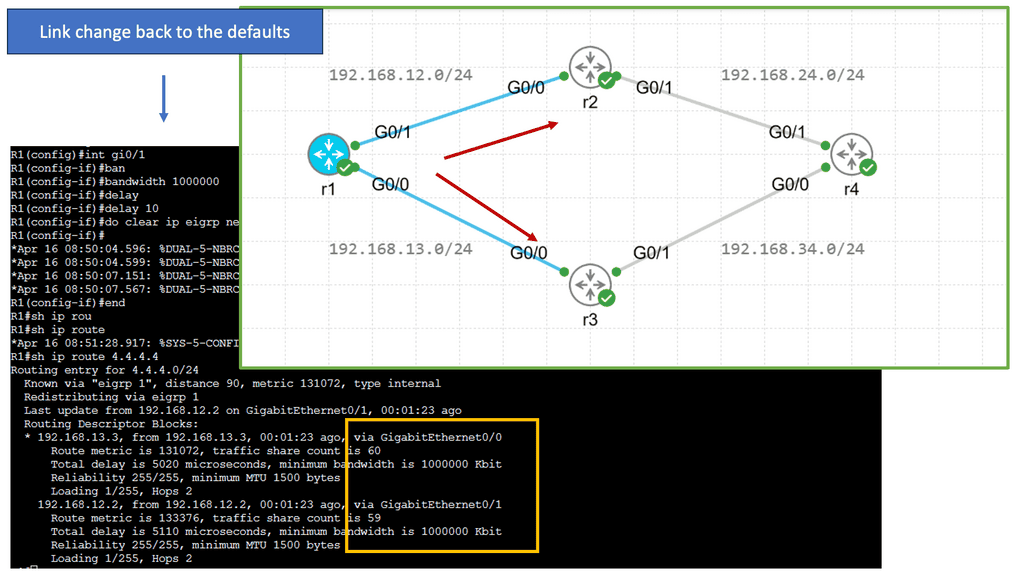
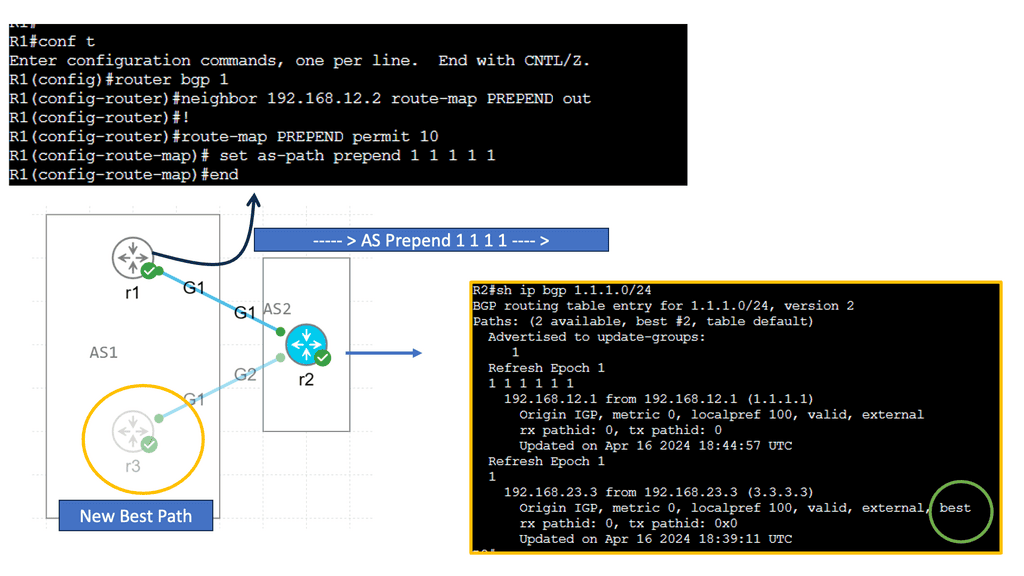
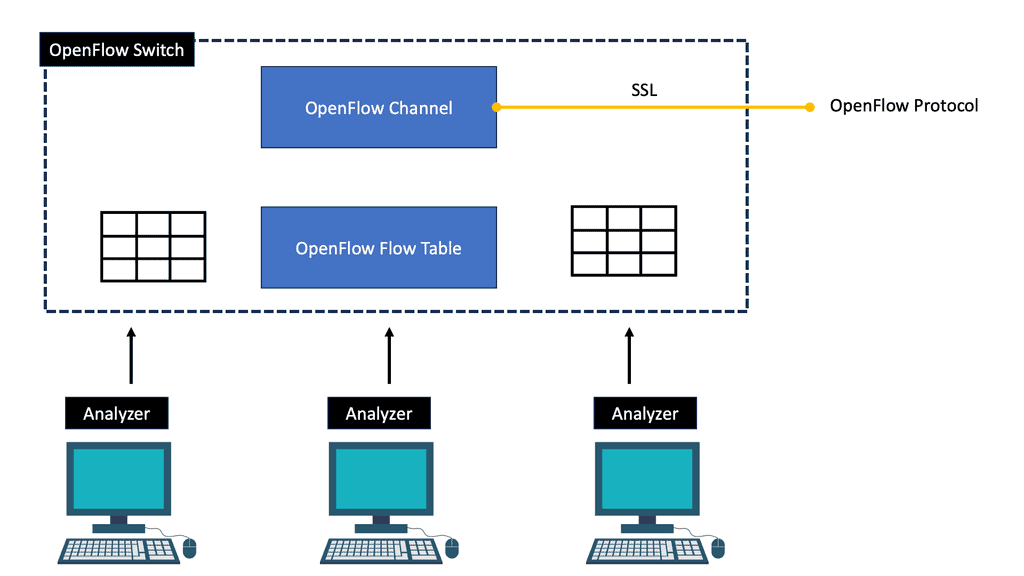
Understanding Service Chaining
A: ) – Service chaining is a technique for connecting multiple network services in a specific order to create a chain of services. It enables the smooth flow of data packets through interconnected services, such as firewalls, load balancers, and deep packet inspection tools. By directing traffic through this predefined service chain, organizations can enhance security, optimize performance, and streamline network management.
B : ) – Service chaining, in simple terms, refers to the process of linking multiple services together to create a streamlined and automated workflow. It involves the sequential execution of various services, where the output of one service becomes the input for the next, forming a chain. By orchestrating these services, businesses can achieve complex tasks with minimal manual intervention, resulting in improved efficiency and reduced operational costs.
Service Chaining Considerations:
Improved Performance: Service chaining efficiently distributes network traffic, reducing latency and improving overall performance. Organizations can strategically place services within the chain to ensure critical applications receive the necessary resources and bandwidth.
Enhanced Security: Service chaining enables the seamless integration of security services, such as intrusion detection systems (IDS) and data loss prevention (DLP) tools. Routing traffic through these services in a specific order can detect, mitigate, and prevent potential threats from reaching critical systems.
Simplified Network Management: With service chaining, managing and configuring network services becomes more streamlined. Changes and updates can be made at the service chain level, eliminating the need for extensive reconfiguration of individual services. This simplification reduces complexity and saves valuable time for network administrators.
Flexibility and Scalability: With service chaining, organizations can easily adapt to changing business requirements. By adding or modifying services within the chain, businesses can quickly scale their operations and meet evolving customer demands.
Applications of Service Chaining:
– Cloud Computing: Service chaining is particularly beneficial in cloud computing environments. Cloud providers can efficiently direct traffic through various service functions by leveraging service chaining, ensuring optimal performance, scalability, and security for cloud-based applications.
– Data Centers: Service chaining is crucial in managing network traffic in large-scale data center environments. Using service chaining techniques, data centers can prioritize traffic, allocate resources efficiently, and enforce security policies, enhancing performance and protection for critical applications.
– Telecommunications: Service chaining is also prevalent in telecommunications networks. Telecom operators can easily optimize traffic routing, implement advanced security measures, and deliver value-added services by employing service chaining.
Implementing Service Chaining
1 Identifying Service Dependencies: The first step in implementing service chaining is identifying the services involved and their dependencies. This requires a thorough understanding of the business processes and the interactions between different services.
2 Defining Workflow and Orchestration: Once the dependencies are identified, businesses need to design the workflow and orchestration logic. This involves determining the sequence of services, their inputs and outputs, and the conditions for triggering each service.
3 Leveraging Automation Tools: To implement service chaining efficiently, organizations can leverage automation tools and platforms. These tools provide visual interfaces for designing, managing, and monitorin
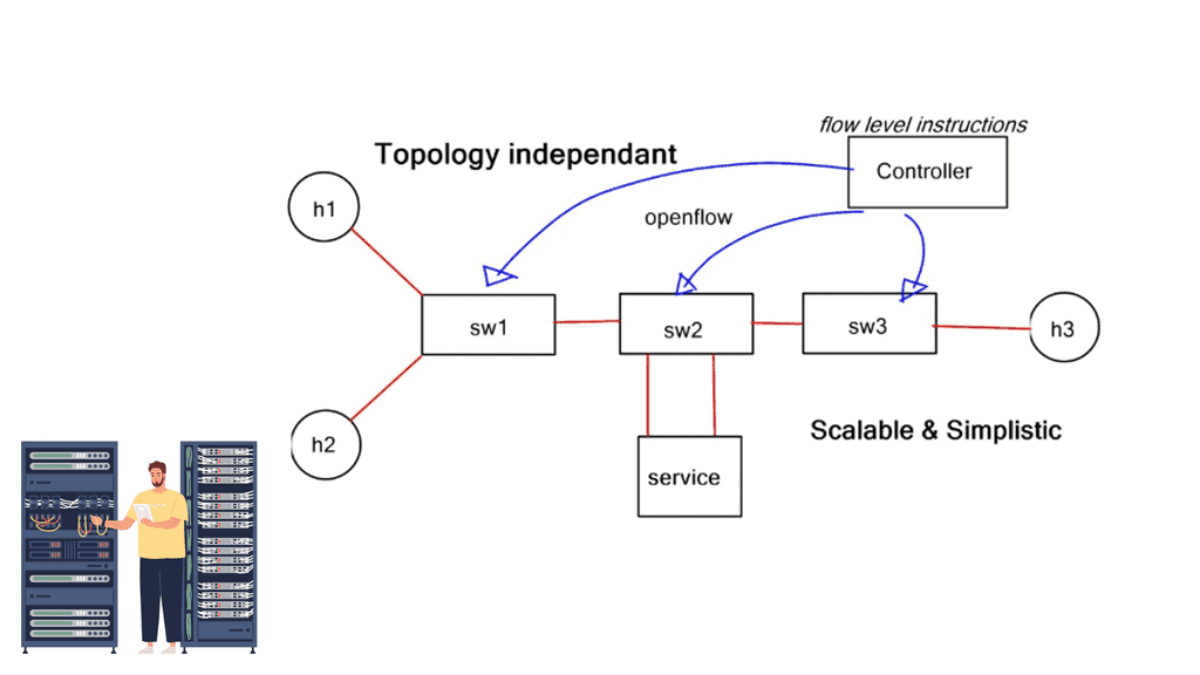
**Service Chaining & SDN**
This capability uses software-defined networking (SDN) capabilities to connect network services, such as firewalls, network address translation (NAT), and intrusion protection, using network service chaining, also known as service function chaining (SFC).
Network operators can create a catalog of pathways through which traffic can travel by chaining network services. Depending on the traffic’s requirements, a route can consist of any combination of connected services. More security, lower latency, or a high quality of service (QoS) may be necessary for different types of traffic.
Chaining network services has the primary advantage of automating how virtual network connections can be set up to handle traffic flows between connected services. Based on the source, destination, or type of traffic, an SDN controller could apply a chain of services to different traffic flows. By chaining L4-7 devices, traditional network administrators can automate connecting incoming and outgoing traffic, which requires several manual steps in the past.
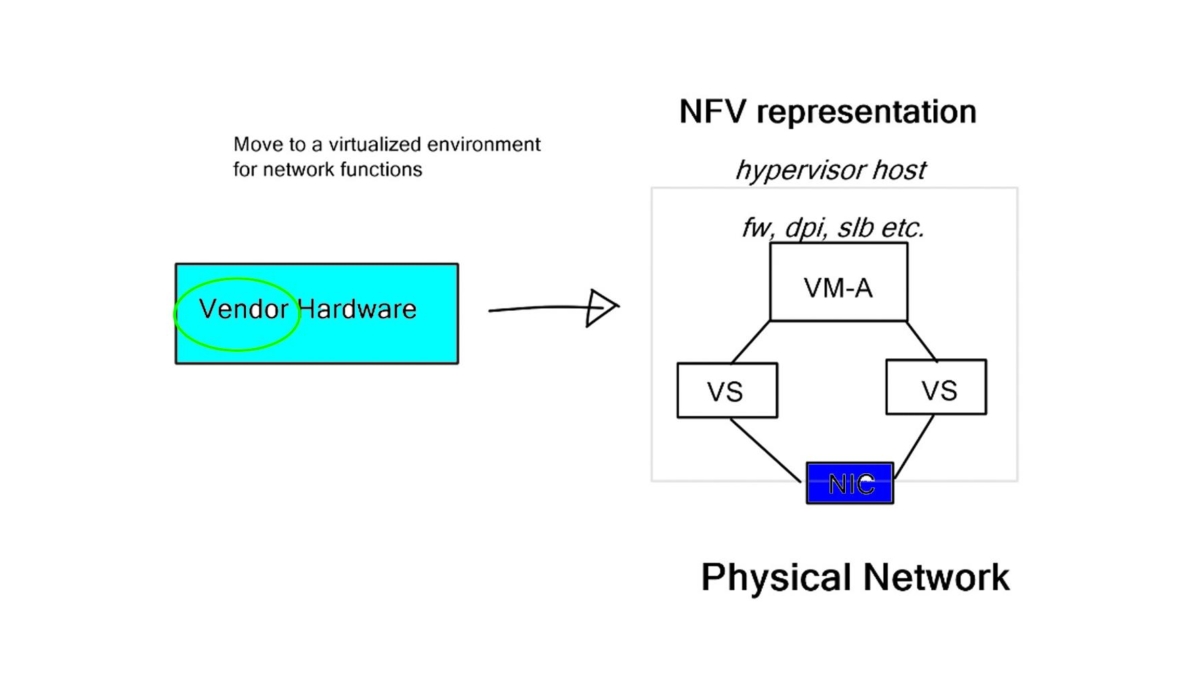
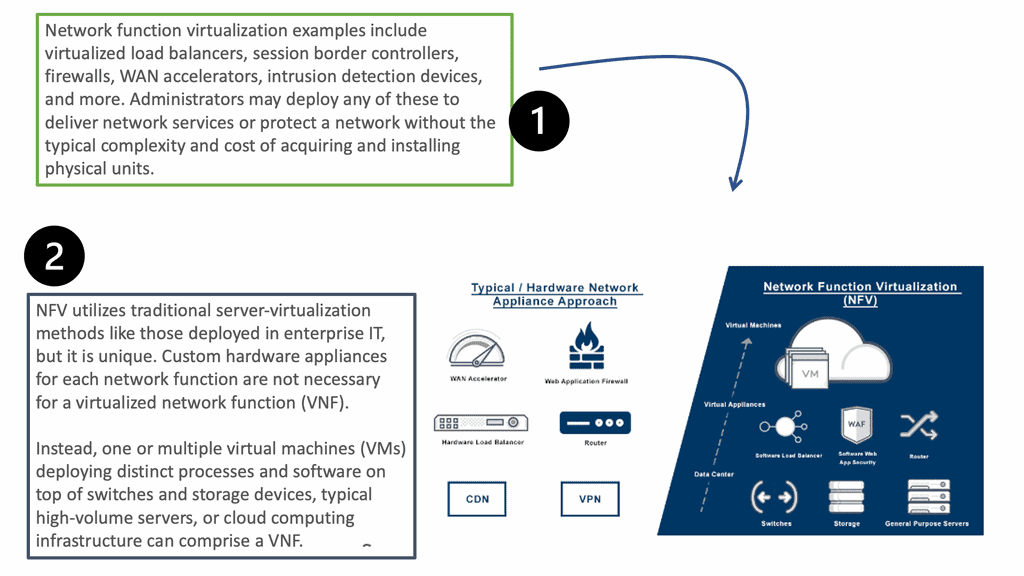
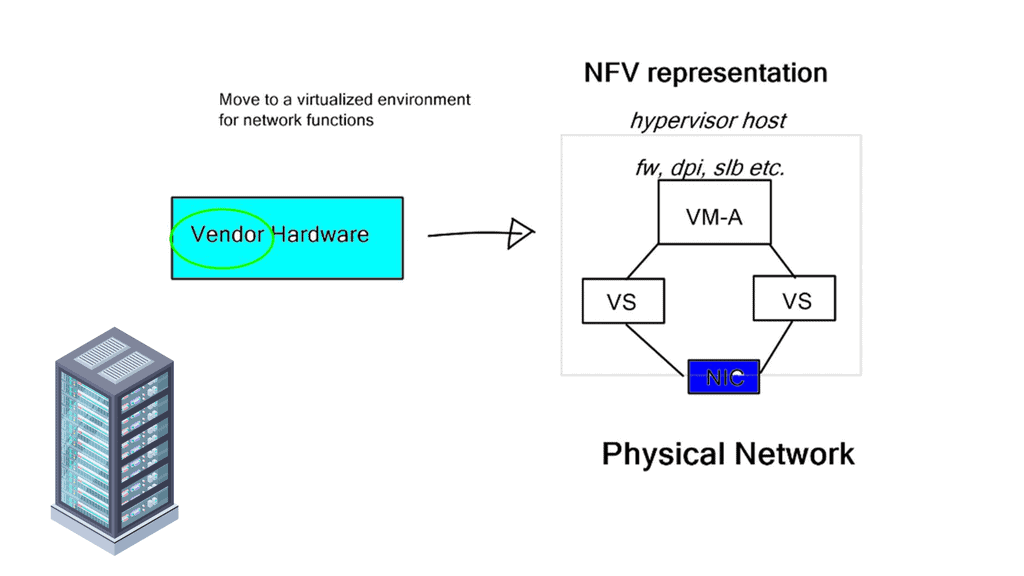
By using software provisioning, the chain in service chaining represents the services that can be connected across the network. Software-only services can be instantiated on commodity hardware in the NFV world.
Due to the technology’s capabilities, many virtual network functions can be connected in an NFV environment. Through the NFV orchestration layer, these connections can be set up and torn down as needed as NFV is implemented through software using virtual circuits.
Service chaining via overlays
Service chaining ensures the network operator’s policies are enforced by channeling traffic through a network overlay or tunneled path in a virtual topology.
As traffic arrives from the host, Router A passes through a tunnel to one of the packet inspection processes in that pool. Encapsulated packets are sent to NAT, spam filtering, and finally, the mail server after being encapsulated. At each stage, rather than routing the packet directly to the mail server, the final destination, the packet is forwarded to the next service in the chain.
How can this be accomplished? Three basic models can be used to form a service chain:
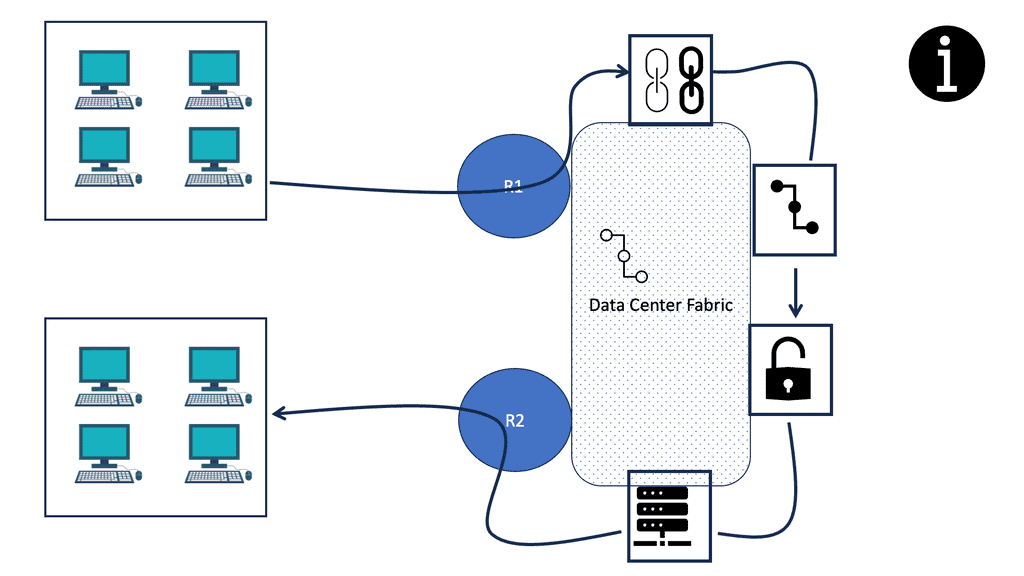
An ingress device, in this case, Router 1, usually imposes the initial service on a chain. When the packet reaches the first service (or the hypervisor’s virtual switch), it is encapsulated correctly for the next service. The following service to be imposed on the chain is determined by local policies within the service. After handling each packet, the final service forwards it based on its destination address.
In the fabric, switching devices can impose the initial and subsequent services. The chain segments are imposed by network devices (such as Top-of-Rack switches) rather than by service processes.
An initial service and all subsequent services may be imposed on a packet when it encounters a DC edge switch, for example, in a cloud deployment. The edge switch receives information about every service through which packets destined for a particular service must pass and a way to stack headers on each packet.
**The Role of NFV**
Many perspectives exist on Network Function Virtualization (NFV) and Software-Defined Networking (SDN). It depends on who you ask and what side they lay on – server or network departments in the service provider, data center, or branch. I view SDN in the data center/WAN and NFV anywhere at the network edge. While the NFV use cases vary from enterprise, service provider, and branch requirements, it’s about simplifying management and orchestration.
**NFV Enables Service Chaining**
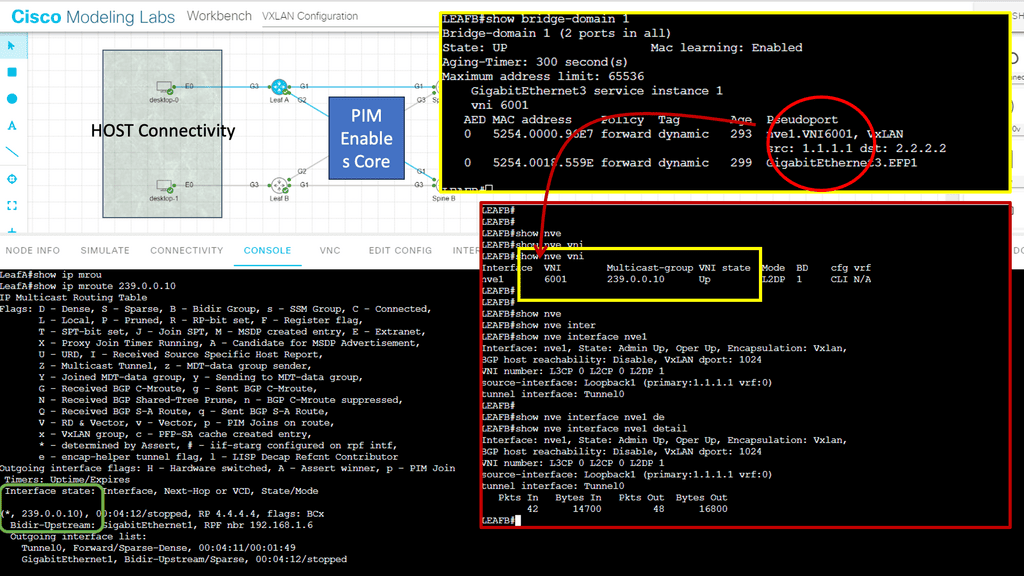
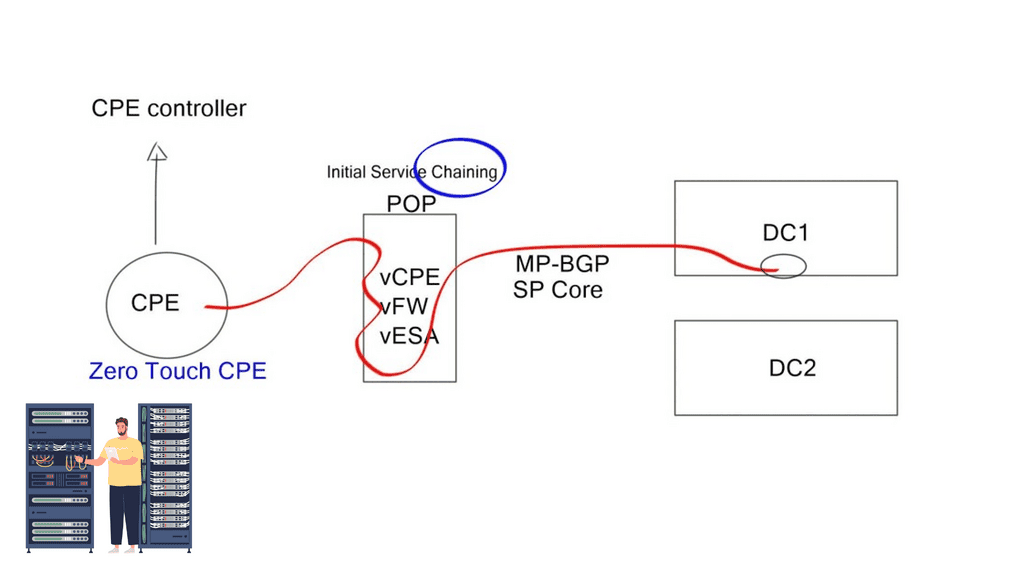
NFV with network service chaining enables you to bring network services that used to be at the customer edge to the nearest POP or data center to run on a virtualization environment. For example, a newly installed CPE obtains its configuration from a PnP server, and a tunnel (VXLAN, GRE, LISP, IPSec, or Layer 2) can be created to local POP consisting of, for example, vCPE, vFW, or vESE virtual services. MP-BGP is then used across the SP WAN for route propagation to the data center.
Before you proceed, you may find the following posts helpful:
Service chaining is a networking technique that involves the sequential connection of multiple network services to form a chain. Rather than sending data packets directly from the source to the destination, they are routed through a series of services, each performing a specific function. This enables the customization and optimization of network traffic, leading to improved performance, security, and scalability.
Service chaining is required to move traffic to these virtualized services. Therefore, its role is to help automate traffic flow between services in a virtual network. It also optimizes network resources to improve application performance using the best routing path. An example sequence is passing through the firewall, encryption, and software-defined WAN.
Network Service Chaining
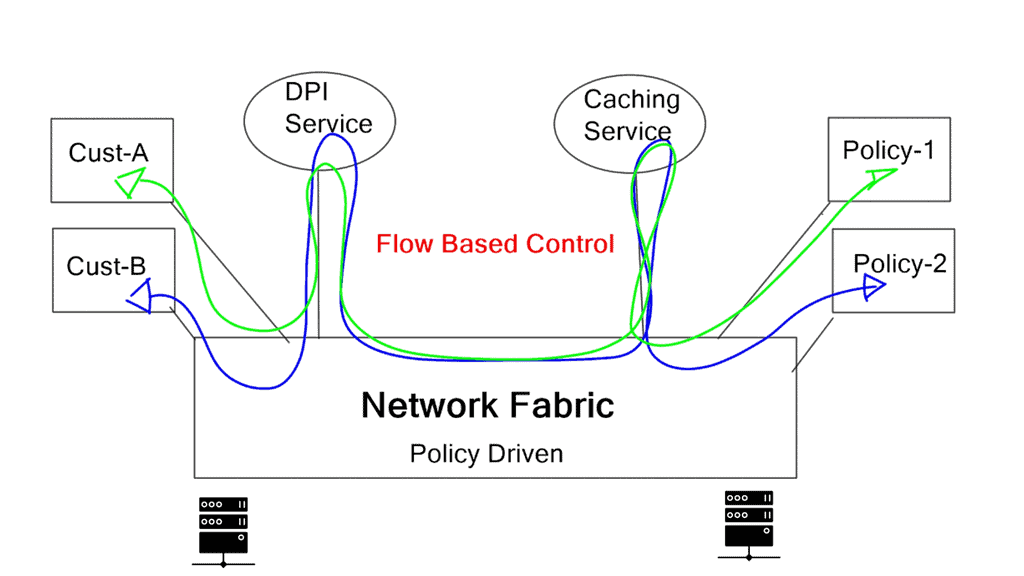
Service chains are policy constructs that can steer application traffic through a series of service nodes. These nodes may include firewalls, load balancers, intrusion detection devices, and virtual email security agents.
For example, we want to add a stateful packet engine to an application flow. In a classic case, we usually implement a physical or virtual firewall as the default gateway. All traffic leaving the host will follow its default gateway, and traffic gets inspected.
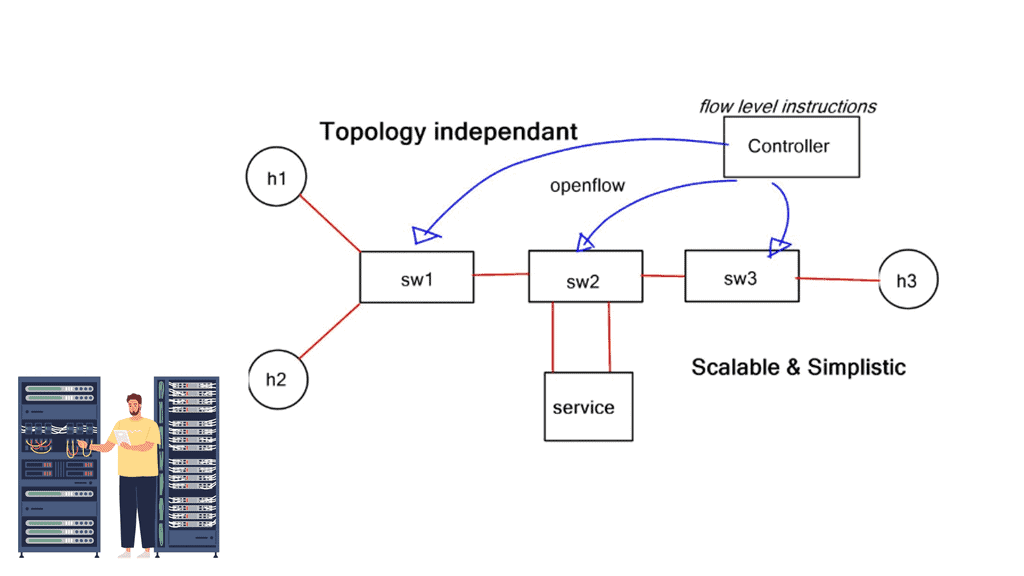
This design is a typical topology-dependent service chain. What if you need to go one step further and add several service devices to the chain, such as an IPS or load balancer? This will soon become a complicated design, and complexity comes at a cost in troubleshooting and maintenance.
The lack of end-to-end service visibility
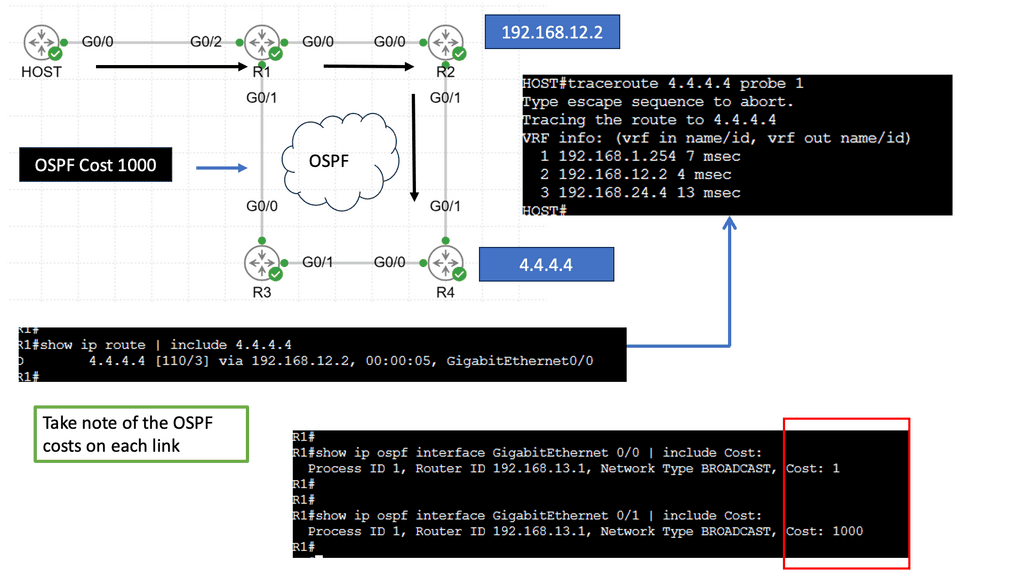
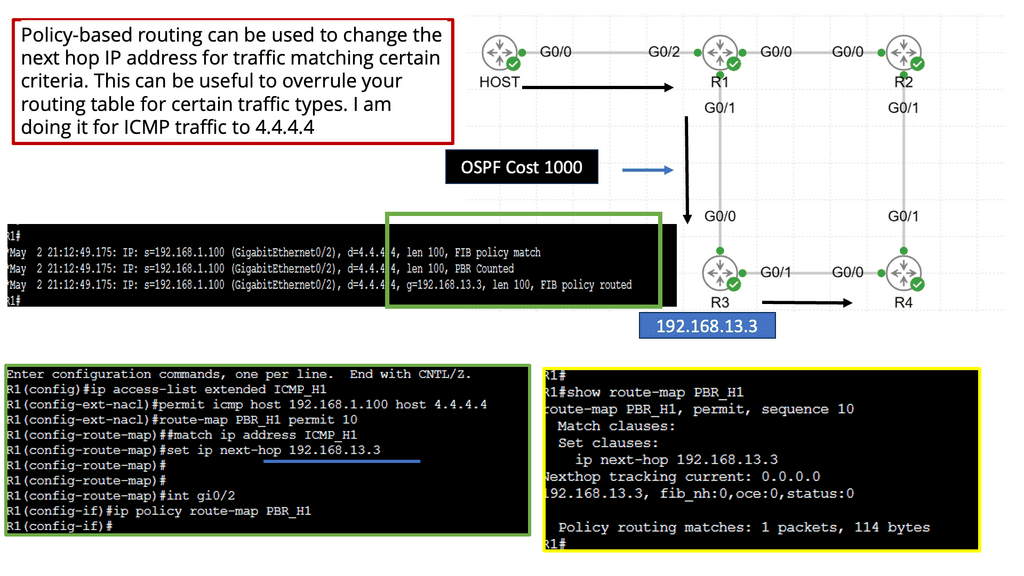
Service chaining is static and bound to the insertion and policy selection topology. One major drawback is that network service deployments are tightly coupled to the network topology. This limits network agility, especially in a virtual environment. They are typically built through manual configuration and are prone to human error. Policy-based routing (PBR) and VLAN stitching are existing technologies used for service chaining. They lack end-to-end service visibility, and troubleshooting is complicated.
**Policy-Based Routing**
PBR is configured per box, per flow, and autonomous routing protocols do not understand it. PBR breaks routing. You usually build that chain statically if you have to run traffic through some network service. Still, in a data center that uses a lot of multi-tenancy and is highly segmented, you need to route traffic in a much more flexible way.
Implementing network services and security policies into an application network has traditionally been complex. Implementing service nodes into an application path, independent of location, has challenged many data centers and cloud providers.
Example Policy Based Routing:
### Introduction to Policy-Based Routing
In the ever-evolving landscape of digital networks, ensuring the efficient flow of data is more crucial than ever. Policy-Based Routing (PBR) emerges as an innovative solution to manage and direct data traffic based on predefined policies. Unlike traditional routing, which relies solely on destination addresses, PBR allows network administrators to dictate routing decisions based on various criteria, including source address, protocol type, and application. This approach not only enhances traffic management but also ensures optimal resource utilization.
### The Mechanics of Policy-Based Routing
Understanding the mechanics of PBR is essential for implementing it effectively. At its core, PBR involves creating routing policies that act as rules for directing traffic. These policies can be configured based on multiple parameters, such as the type of service or the time of day, offering a level of customization that traditional routing lacks. By applying these policies at the network’s edge, administrators can influence the path that data packets take through the network, optimizing performance and security.
### Benefits of Implementing Policy-Based Routing
The advantages of PBR extend beyond mere traffic management. One of its primary benefits is the ability to prioritize critical applications, ensuring that essential services receive the bandwidth they need. This is particularly valuable in environments with limited resources, where congestion can lead to performance bottlenecks. Additionally, PBR enhances security by allowing administrators to route sensitive data through secure paths, mitigating the risk of interception or unauthorized access.
Example: Service chaining and the virtual switch
The Nexus 1000V virtual switch initially introduced the concept of service chaining. It implements a service-chaining technology called vPath, which provides traffic interception and reroutes to the required service node. However, it initially lacked because it could only service chain one service at a time and for one type of device: the Virtual Security Gateway (VSG).
It was later expanded to service multiple workloads between multiple service hops. While vPath was a success, it could only work with virtual nodes. A solution was needed to enable physical and virtual nodes to be in the virtual chaining path.
Network Service Header (NSH)
Cisco has developed the Network Service Header (NSH). It creates a dedicated service plane independent of the underlying transport networks. A node inserts it into encapsulated packets or frames, usually at ingress, and describes a series of service nodes to which a packet should be routed. It also adds additional metadata about the packet. The packets are then encapsulated in an outer header for transport.
Service Function Forwarder (SFF)
The traffic is sent via an overlay to the Service Function Forwarder (SFF), which looks at the service path header and tells it what service needs to be applied at the particular chain. NSH requires NSH-aware nodes, i.e., front-end service nodes, but it doesn’t require any change to the transport network. The SFF is an NSH-aware forwarder in front of the service node.
The SFF only needs to know how to do a simple lookup and ask for a location. The locator can be delivered via SDN controller ODL, LISP, and BGP. Because the control and data plane are decoupled, it is simplified. The abstraction between the control and data plane allows you to build more complicated (scale and topology) service chains with NSH rather than using flows.
Closing Points on Service Chaining
Service chaining is crucial in today’s complex network environments where data packets need to traverse through various services such as firewalls, intrusion detection systems, and load balancers. Traditional network setups often require manual configuration and management of these services, leading to increased complexity and potential for errors. By implementing service chaining, organizations can automate the flow of data across these services, ensuring a more efficient and error-free network operation.
The process of service chaining involves a series of steps that automatically direct network traffic through the required services. This is typically achieved through the use of network functions virtualization (NFV) and software-defined networking (SDN) technologies. NFV allows for the virtualization of network services, while SDN provides a centralized control mechanism to manage the flow of traffic. Together, they enable the dynamic creation of service chains that can be easily modified and optimized to meet the specific needs of the network.
There are several benefits to implementing service chaining in a network environment. One of the most significant advantages is the increased agility it provides. Organizations can quickly adapt to changing network demands by reconfiguring service chains on the fly. Additionally, service chaining enhances network security by ensuring that data passes through all necessary security services before reaching its destination. This reduces the risk of data breaches and ensures compliance with security policies.
While service chaining offers numerous benefits, there are also challenges to consider. One of the primary challenges is the complexity involved in designing and managing service chains. Organizations need to have a clear understanding of their network architecture and the specific requirements of each service within the chain. Additionally, there may be compatibility issues between different network services, which can complicate the implementation process.