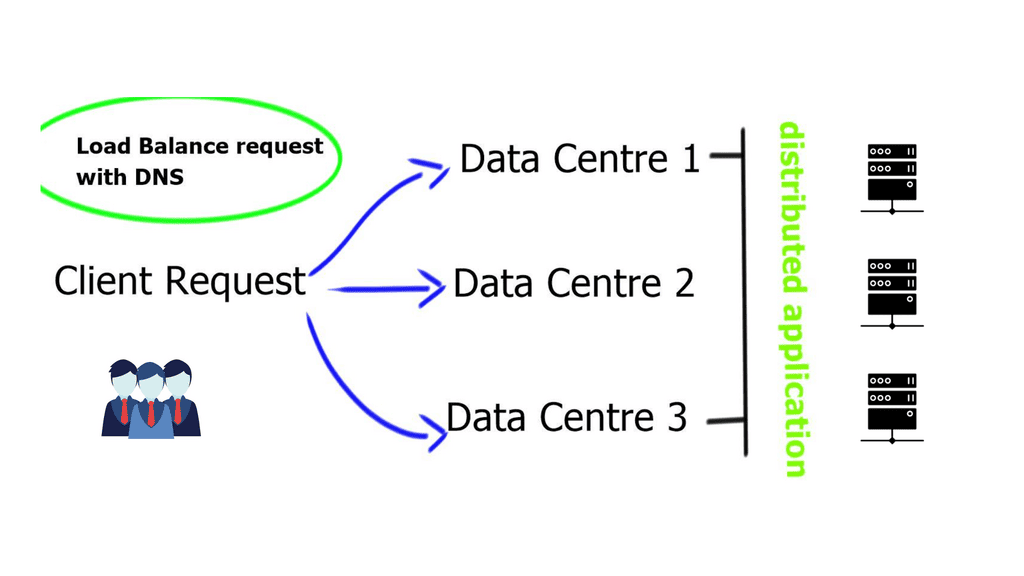
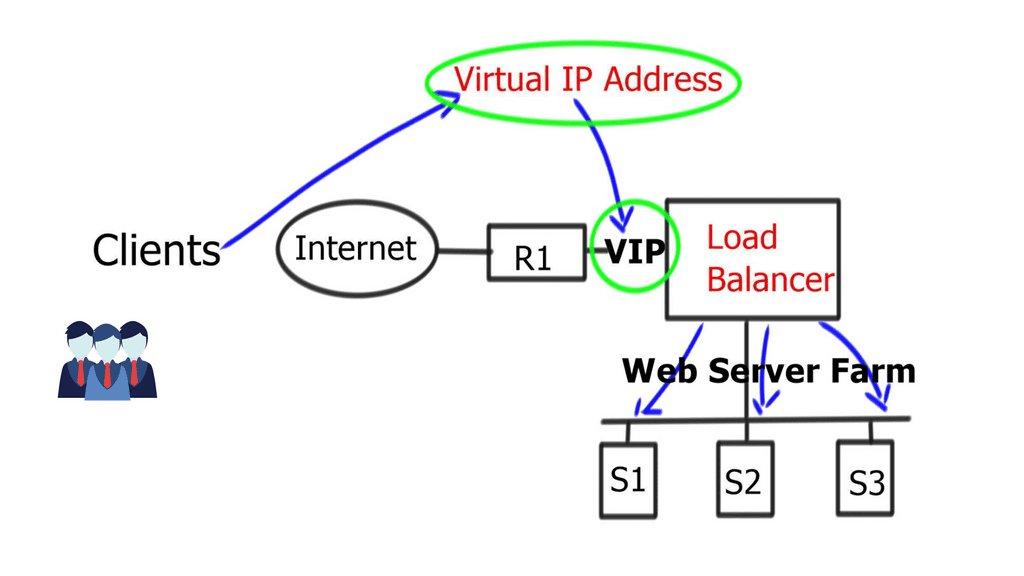
In today's digital age, ensuring online security has become paramount. One crucial aspect of protecting sensitive information is SSL (Secure Sockets Layer) encryption. In this blog post, we will explore what SSL is, how it works, and its significance in safeguarding online transactions and data.
SSL, or Secure Sockets Layer, is a standard security protocol that establishes encrypted links between a web server and a browser. It ensures that all data transmitted between these two points remains private and integral. By employing a combination of encryption algorithms and digital certificates, SSL provides a secure channel for information exchange.
SSL plays a vital role in maintaining online security in several ways. Firstly, it encrypts sensitive data, such as credit card details, login credentials, and personal information. This encryption makes it extremely difficult for hackers to intercept and decipher the transmitted data. Secondly, SSL verifies the identity of websites, ensuring users can trust the authenticity of the platform they are interacting with. Lastly, SSL protects against data tampering during transmission, guaranteeing the integrity and reliability of the information.
Implementing SSL on your website offers numerous benefits. Firstly, it instills trust in your visitors, as they see the padlock icon or the HTTPS prefix in their browser's address bar, indicating a secure connection. This trust can lead to increased user engagement, longer browsing sessions, and higher conversion rates. Additionally, SSL is crucial for e-commerce websites, as it enables secure online transactions, protecting both the customer's financial information and the business's reputation.
There are different types of SSL certificates available, each catering to specific needs. These include Domain Validated (DV) certificates, Organization Validated (OV) certificates, and Extended Validation (EV) certificates. DV certificates are suitable for personal websites and blogs, while OV certificates are recommended for small to medium-sized businesses. EV certificates offer the highest level of validation and are commonly used by large corporations and financial institutions.
SSL security is an indispensable aspect of the online world. It not only protects sensitive data but also builds trust among users and enhances the overall security of websites. By implementing SSL encryption and obtaining the appropriate SSL certificate, businesses and individuals can ensure a safer online experience for their users and themselves.
Highlights: SSL Security
Understanding SSL Security
**What is SSL Security?**
SSL, or Secure Socket Layer, is a standard security protocol that establishes encrypted links between a web server and a browser. This ensures that all data passed between them remains private and integral. SSL is the backbone of secure internet transactions, providing privacy, authentication, and data integrity. When you see a padlock icon in your browser’s address bar, it signifies that the website is SSL-secured, giving users peace of mind that their data is protected from prying eyes.
**The Importance of SSL Certificates**
An SSL certificate is a digital certificate that authenticates a website’s identity and enables an encrypted connection. Businesses and website owners must prioritize obtaining an SSL certificate to protect their users’ data and build trust. Not only does it prevent hackers from intercepting sensitive information such as credit card details and login credentials, but it also enhances your website’s reputation. In fact, search engines like Google give preference to SSL-secured sites, potentially boosting your site’s ranking in search results.
1: – ) SSL, which stands for Secure Sockets Layer, is a cryptographic protocol that provides secure communication over the Internet. It establishes an encrypted link between a web server and a user’s browser, ensuring that all data transmitted remains private and confidential.
2: – ) SSL certificates, websites can protect sensitive information such as login credentials, credit card details, and personal data from falling into the wrong hands.
3: – ) SSL certificates play a pivotal role in the implementation of SSL security. These certificates are issued by trusted third-party certificate authorities (CAs) and are digital website passports.
4: – ) When a user visits an SSL-enabled website, their browser checks the validity and authenticity of the SSL certificate, establishing a secure connection if everything checks out.
How SSL Encryption Works
– SSL encryption involves a complex process that ensures data confidentiality, integrity, and authenticity. When users access an SSL-enabled website, their browser initiates a handshake process with the web server.
– This handshake involves the exchange of encryption keys, establishing a secure connection. Once the connection is established, all data transmitted between the user’s browser and the web server is encrypted and can only be decrypted by the intended recipient.
– The implementation of SSL security offers numerous benefits for website owners and users alike. Firstly, it provides a secure environment for online transactions, protecting sensitive customer information and instilling trust.
– Additionally, SSL-enabled websites often experience improved rankings as search engines prioritize secure websites. Furthermore, SSL security helps prevent unauthorized access and data tampering, ensuring the integrity of data transmission.
**Benefits of SSL Security**
1. Data Protection: SSL encryption ensures the privacy and confidentiality of sensitive information transmitted over the internet, making it extremely difficult for hackers to decrypt and misuse the data.
2. Authentication: SSL certificates authenticate websites’ identities, assuring users that they interact with legitimate and trustworthy entities. This helps prevent phishing attacks and protects users from submitting personal information to malicious websites.
3. Search Engine Ranking: Search engines like Google consider SSL security as a ranking factor to promote secure web browsing. Websites with an SSL certificate enjoy a higher search engine ranking, thus driving more organic traffic and increasing credibility.
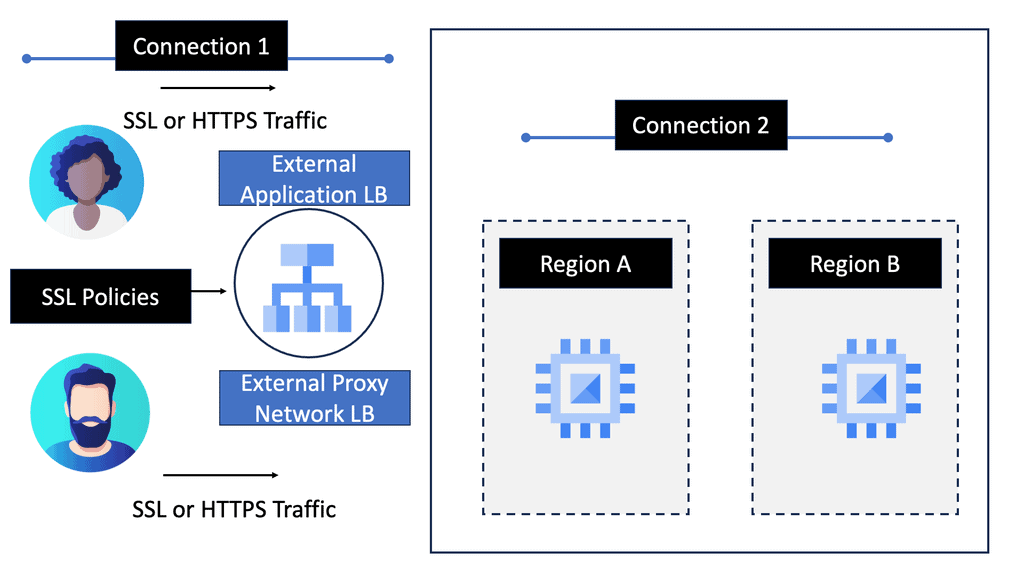
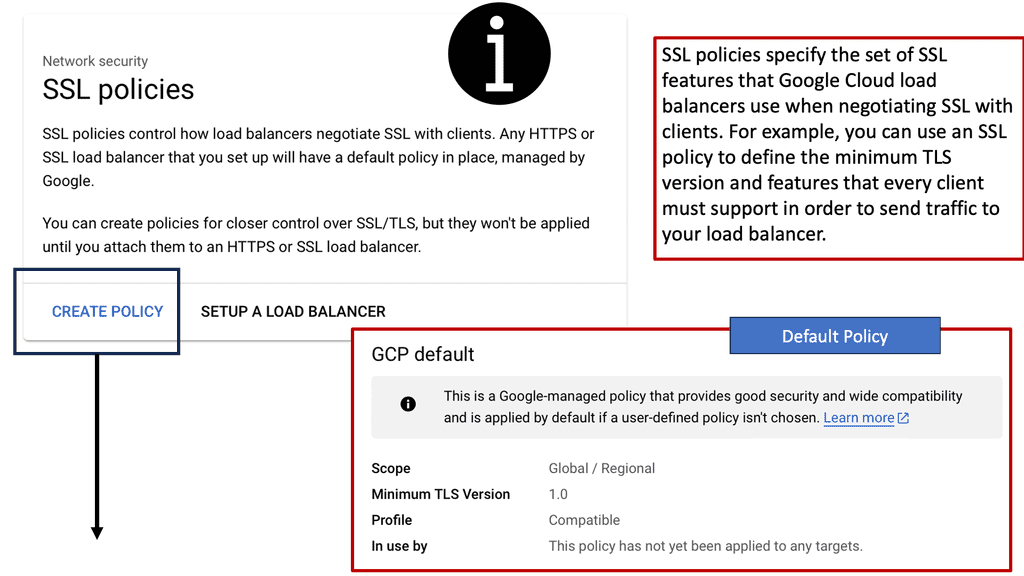
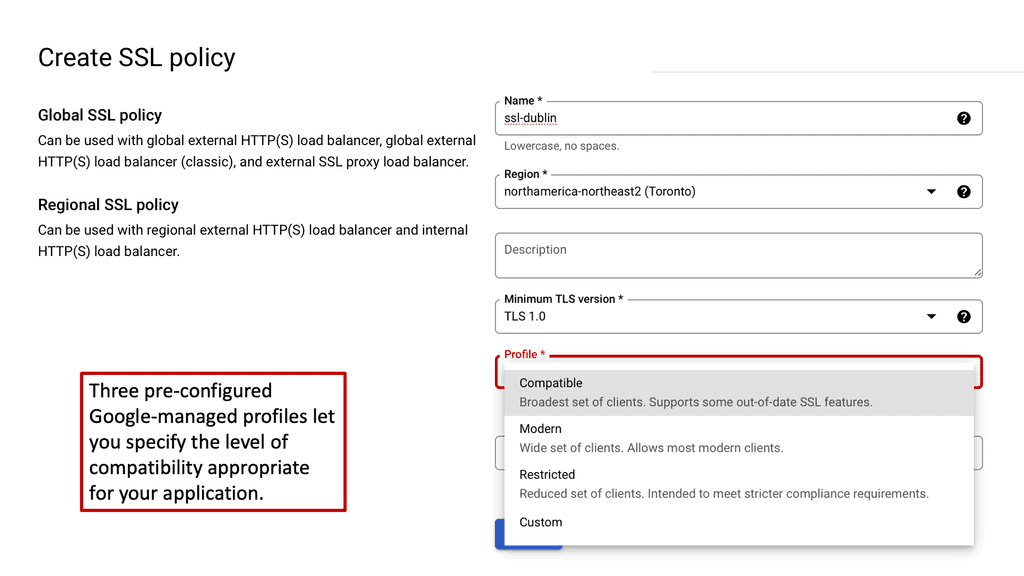
Example SSL Technology: SSL Policies
### Implementing SSL Policies on Google Cloud
Google Cloud offers robust tools and services to implement SSL policies, ensuring secure data transmission. One of the primary tools is the Cloud Load Balancing service, which provides SSL offloading. This service allows you to manage SSL certificates, ensuring encrypted connections without burdening your servers. Additionally, Google Cloud offers the Certificate Manager, a user-friendly tool to obtain, manage, and deploy SSL certificates across your cloud infrastructure seamlessly.
### Best Practices for SSL Policies on Google Cloud
To maximize the efficacy of SSL policies on Google Cloud, consider the following best practices:
1. **Regularly Update Certificates**: Ensure that SSL certificates are up to date to maintain secure connections and avoid potential security vulnerabilities.
2. **Use Strong Encryption Algorithms**: Opt for robust encryption algorithms, such as AES-256, to safeguard data effectively.
3. **Implement Automated Certificate Management**: Utilize Google Cloud’s automated tools to manage SSL certificates, reducing the risk of human error and ensuring timely renewals.
4. **Monitor and Audit SSL Traffic**: Regularly monitor SSL traffic to detect and mitigate any unusual activities or potential threats.
Example Product: Cisco Umbrella
#### What is Cisco Umbrella?
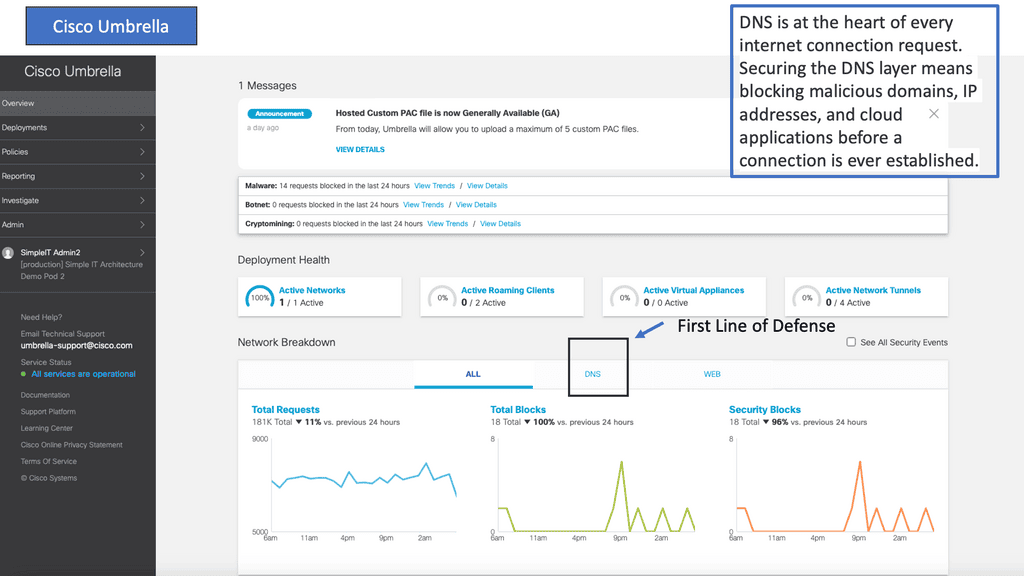
Cisco Umbrella is a cloud-delivered security service that provides enterprises with a first line of defense against internet threats. It uses the power of DNS (Domain Name System) to block malicious domains, IP addresses, and cloud applications before a connection is ever established. By leveraging Cisco Umbrella, businesses can ensure that their network is safeguarded against a wide range of cyber threats, including malware, phishing, and ransomware.
#### The Importance of SSL Security
Secure Sockets Layer (SSL) is a standard security technology for establishing an encrypted link between a server and a client. This technology ensures that all data passed between the web server and browsers remain private and integral. SSL security is crucial because it protects sensitive information such as credit card numbers, usernames, passwords, and other personal data. Without SSL security, data can be intercepted and accessed by malicious actors, leading to significant breaches and financial loss.
#### How Cisco Umbrella Enhances SSL Security
Cisco Umbrella plays a pivotal role in bolstering SSL security by providing several key benefits:
1. **Automated Threat Detection**: Cisco Umbrella continuously monitors web traffic, identifying and blocking suspicious activities before they can cause harm. This proactive approach ensures that threats are neutralized at the DNS layer, providing an additional layer of security.
2. **Encrypted Traffic Analysis**: With the rise of encrypted traffic, traditional security measures often fall short. Cisco Umbrella’s advanced analytics can inspect encrypted traffic, ensuring that SSL/TLS connections are secure and free from malicious content.
3. **Global Threat Intelligence**: Cisco Umbrella leverages global threat intelligence from Cisco Talos, one of the largest commercial threat intelligence teams in the world. This wealth of data ensures that Cisco Umbrella can quickly identify and respond to emerging threats, keeping SSL connections secure.
4. **User and Application Visibility**: Cisco Umbrella provides comprehensive visibility into user and application activities. This insight helps in identifying risky behaviors and potential vulnerabilities, allowing IT teams to take corrective actions promptly.
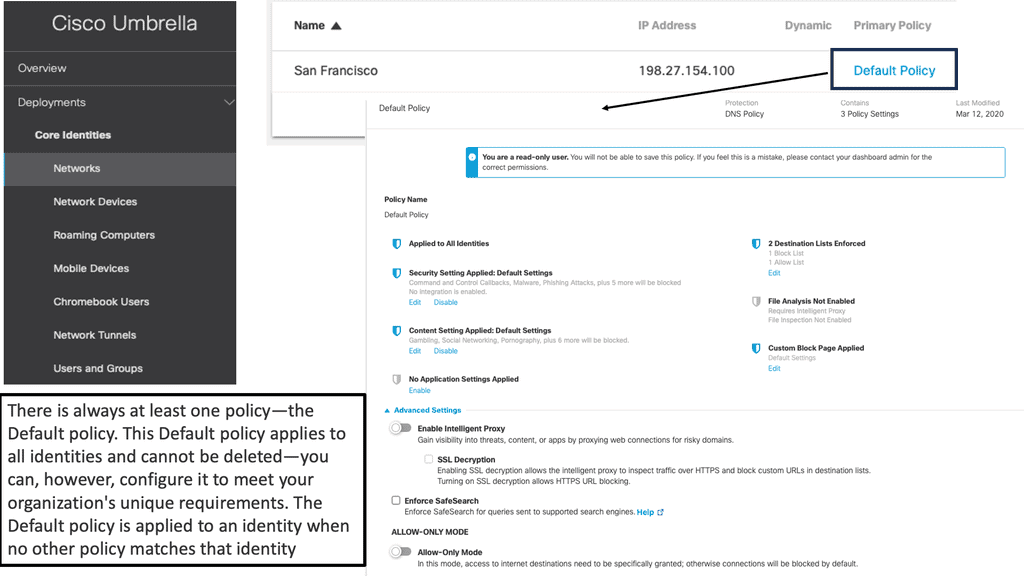
#### Implementation of Cisco Umbrella
Implementing Cisco Umbrella is straightforward and can be integrated with existing security frameworks. It involves a simple change in the DNS settings, pointing them to Cisco Umbrella’s servers. Once configured, Cisco Umbrella starts offering protection immediately, with minimal impact on network performance. Businesses can also customize policies to align with their specific security needs, ensuring a tailored security posture.
Motivation for SSL
SSL was also primarily motivated by HTTP. It was initially designed as an add-on to HTTP, called HTTPS, but it is not a standalone protocol. Additionally, HTTP has improved from a security perspective. With HTTP, data traveling over the network is encrypted using SSL and TLS protocols. As a result, man-in-the-middle attacks are complicated to execute.
The Role of HTTP
Hypertext Transfer Protocol (HTTP) is an application-based protocol used for communications over the Internet. It is the foundation for Internet communication. Of course, as time has passed, there are new ways to communicate over the Internet. Due to its connectionless and stateless features, HTTP has numerous security limitations at the application layer and exposure to various TCP control plane attacks.
Challenges: Attack Variations
It is vulnerable to many attacks, including file and name-based attacks, DNS Spoofing, location headers and spoofing, SSL decryption attacks, and HTTP proxy man-in-the-middle attacks. In addition, it carries crucial personal information, such as usernames/passwords, email addresses, and potentially encryption keys, making it inherently open to personal information leakage. All of which are driving you to SSL security.
For additional pre-information, you may find the following helpful information:
– All our applications require security, and cryptography is one of the primary tools used to provide that security. The primary goals of cryptography, data confidentiality, data integrity, authentication, and non-repudiation (accountability) can be used to prevent multiple types of network-based attacks. These attacks may include eavesdropping, IP spoofing, connection hijacking, and tampering.
– We have an open-source version of SSL, a cryptographic library known as OpenSSL. It implements the industry’s best-regarded algorithms, including encryption algorithms such as 3DES (“Triple DES”), AES, and RSA, as well as message digest algorithms and message authentication codes.
– SSL security is essential for maintaining trust and confidence in online transactions and communications. With increasing cyber threats, SSL encryption helps protect sensitive information such as credit card details, login credentials, and personal data from falling into the wrong hands. By encrypting data, SSL security ensures that the information remains unreadable and unusable to unauthorized individuals even if intercepted.
How SSL Security Works:
When users access a website secured with SSL, their browser initiates a secure connection with the web server. The server sends its SSL certificate, containing its public key, to the browser. The browser then verifies the authenticity of the SSL certificate and uses the server’s public key to encrypt data before sending it back to the server. Only the server, possessing the corresponding private key, can decrypt the encrypted data and process it securely.
SSL Operations
A: – SSL was introduced to provide security for client-to-server communications by a) encrypting the data transfer and b) ensuring the authenticity of the connection. Encryption means that a 3rd party cannot read the data.
B: – They are essential, hiding what is sent from one computer to another by changing the content. Codes encrypt traffic, and SSL puts a barrier around the data. Authenticity means that you can trust the other end of the connection.
SSL uses TCP for transport:
SSL uses TCP as the transport protocol, enabling security services for other application-based protocols that ride on TCP, including FTP and SMTP. Some well-known TCP ports for SSL are 443 HTTPS, 636 LDAP, 989 FTPS-DATA, 990 FTPS, 992 TELNET, 993 IMAPS, 994 IRCS, 995 POP3, and 5061 SIPS. It relies on cryptography; shared keys encrypt and decrypt the data. SSL certificates, assigned by certificate authorities (CA), issue public keys, creating trusted 3rd parties on the Internet.
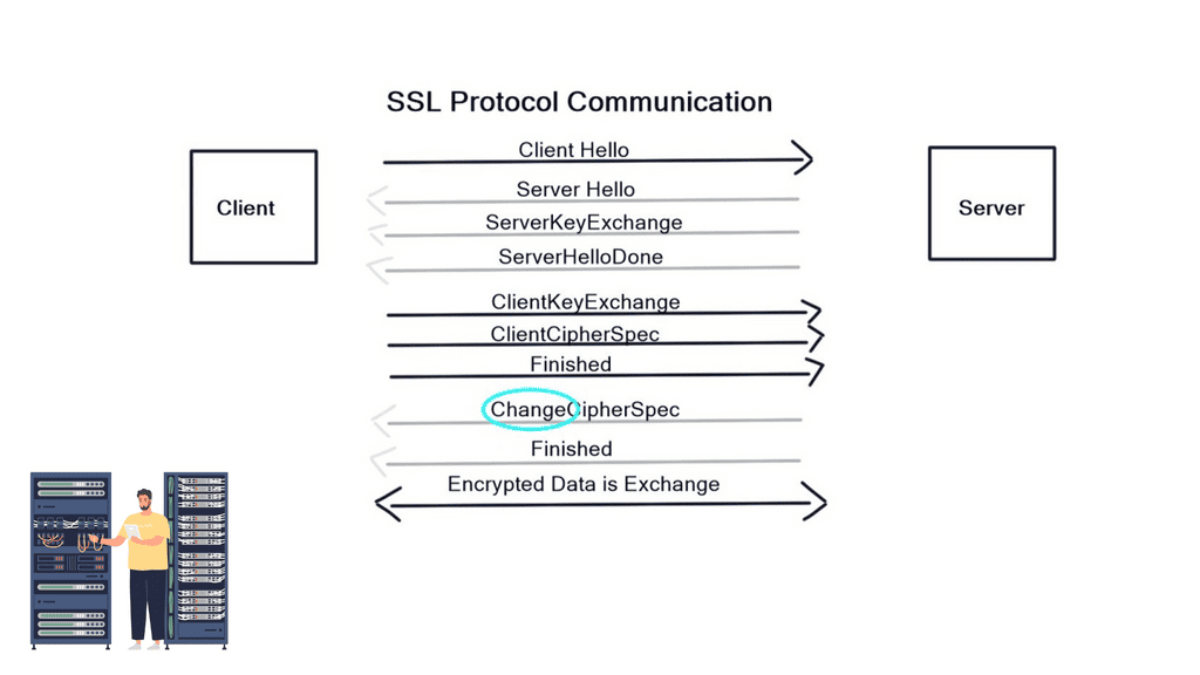
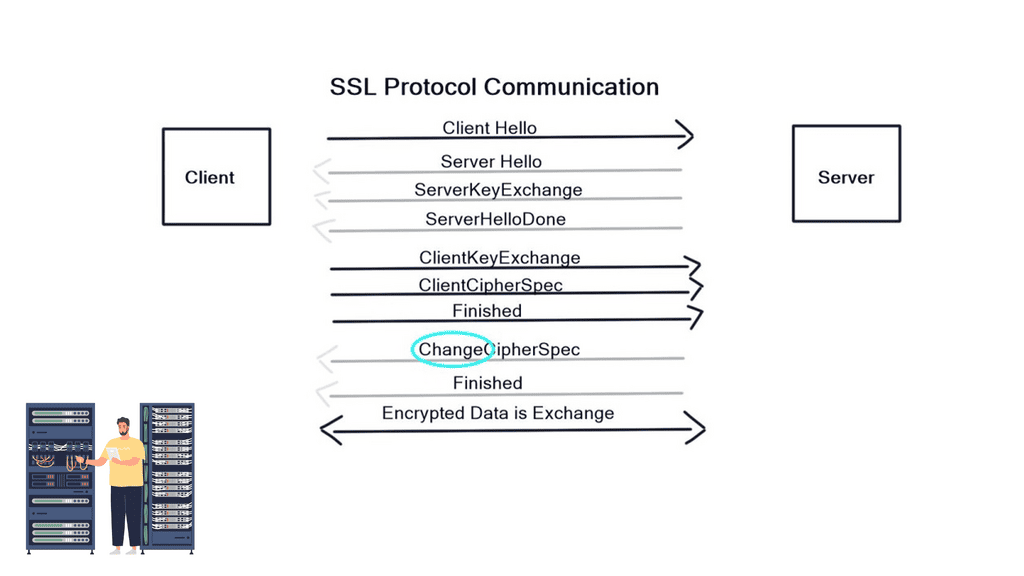
Firstly, the client and server agree on “how” to encrypt data by sending HELLO messages containing Key Exchange Message, Cipher, version of SSL, and the Hash. The server replies with a HELLO message with the chosen parameters (The client offers what it can do, and the server replies with what it will do). In the next stage, the server sends a certificate to the client containing its public key.
Next, a client key exchange message is used, and once this message is sent, both computers calculate a master secret code, which is used to encrypt communications. The computer then changes to the Cipher Spec agreed in the previous HELLO messages. Encryption then starts.
Diagram: SSL Security.
Certificates are used for identification and are signed by a trusted Certificate Authority (CA). Firstly, you need to apply for a certificate via a CA (Similar to the analogy of a passport application). Then, the CA creates the certificate and signs it. The signature is created by condensing all the company details into a number through a Hash function. The CA encrypts with the private keys, so anyone holding the public key can encrypt. For example, the certificate is installed on a web server at the customer’s site and used in the handshake process.
1: SSL security and forward secrecy
Most sites supporting HTTPS operate in a non-forward secret mode, exposing themselves to retrospective decryption. Forward secrecy is a feature that prevents the compromise of a long-term secret key. It allows today’s information to be kept secret even if the private key gets compromised in the future. For example, if someone tries to sniff client-to-server communications but can’t, as the server uses a 128-bit key, they can record the entire transmission for the next five years.
When the server is decommissioned, they attempt to get the key and decrypt the traffic. Forward secrecy solves this problem by double-encrypting every connection. So even if someone gets the key in the future, they can’t decrypt the traffic. Google supports forward secrecy on many of its HTTPS websites, such as Gmail, Google Docs, and Google+. Around the world? The Internet uses forward secrecy.
2: Strict transport security (HSTS)
In 2009, a computer security researcher named Moxie Marlinspike introduced the concept of SSL stripping. He released a tool called “sslstrip,” which could prevent a browser from upgrading to SSL in a way that would go unnoticed by the end user. Strict Transport Security is a security feature that lets a website inform browsers it should be communicating with HTTPS and not HTTP to prevent man-in-the-middle attacks. Although the deployment of HSTS has been slow, around 1% of the Internet uses it.
3: POODLE Attack – Flaw in SSLv3
In October 2014, Google’s security team uncovered the POODLE attack (Padding Oracle On Downgraded Legacy Encryption) and released a paper called “POODLE bites.” They revealed a flaw in SSLv3 that allowed an attacker to decrypt HTTP cookies and hijack your browser session—essentially another man-in-the-middle attack.
Many browsers will revert to SSL 3.0 when a TLS connection is unavailable, and an attacker may force a server to default to SSL v3.0 to exploit the vulnerability. One way to overcome this is to permanently disable SSL ver 3.0 on the client and server. However, there are variants of POODLE for TLSv1 and TLS v2. Before the poodle attack, a large proportion of the Internet supported SSL Ver 3.0, but this has considerably dropped in response to the attack.
4: SSL Decryption Attack
Assaults on trust through SSL-encrypted traffic are common and growing in frequency and sophistication. The low-risk, high-reward nature of SSL/TLS vulnerability ensures that these trends will continue, leading to various SSL decryption attacks.
An SSL decryption attack is a DoS attack that targets the SSL handshake protocol either by sending worthless data to the SSL server, which will result in connection issues for legitimate users, or by abusing the SSL handshake protocol itself.
5: 2048-bit keys SSL certificate
Strong recommendations exist for using 2048-bit certificates. The NIST and other companies feel the encryption of 1048-bit keys is insufficient. Computers are getting faster, and 1048-bit keys will not protect you for the lifetime of the secret. On the other hand, 2048-bit certificates will give you about 30 years of security.
The impact of a larger key length is a reduction in performance. 2048-bit keys will reduce transactions per second (TPS) by five times. There are options to configure a “Session Reuse” feature that lets you reuse the session ID negotiated asymmetrically. Session Reuse is a mechanism that allows you to do fewer asymmetric key exchanges.
SSL to the server can cripple the application. Generic hardware is not optimized for this type of handling, and 2048-bit keys don’t work well on generic software and processors. Consolidating the SSL with an appliance that handles the SSL load is better for TPS and performance. Additionally, the driver for SSL offload on optimized hardware is more compelling with 2048-bit keys.
SSL Security – Closing Points
SSL works by using encryption algorithms to scramble data in transit, preventing hackers from reading it as it is sent over the connection. When a browser attempts to connect to a secured website, the server and browser engage in an “SSL handshake.” During this process, they establish a secure connection by generating unique session keys. This ensures that the information exchanged remains confidential and is only accessible to the intended parties.
Having an SSL certificate is crucial for any website, especially if it involves handling sensitive information like credit card details or personal data. SSL certificates serve multiple purposes: they authenticate the identity of the website, ensure data integrity, and provide encryption. Websites with SSL certificates are marked with a padlock icon in the browser’s address bar, which builds trust and credibility with users. Moreover, search engines like Google favor SSL-secured websites, giving them a higher ranking in search results.
There are several types of SSL certificates, each catering to different levels of security needs. The most common types include:
1. **Domain Validated (DV) SSL Certificates**: These provide a basic level of encryption and are usually the quickest to obtain.
2. **Organization Validated (OV) SSL Certificates**: These offer a higher level of security, requiring verification of the organization’s identity.
3. **Extended Validation (EV) SSL Certificates**: These provide the highest level of security and trust, involving a thorough vetting process. Websites with EV SSL certificates display a green address bar in the browser.
Choosing the right type of SSL certificate depends on the specific security requirements of your website.
Despite its widespread use, there are several misconceptions about SSL security. Some believe that SSL is only necessary for e-commerce websites, but it is essential for any site that collects user data. Others assume that SSL encryption slows down website performance, but modern technologies have optimized SSL to ensure minimal impact on speed.
Summary: SSL Security
In today’s digital age, where online security is paramount, understanding SSL (Secure Sockets Layer) security is crucial. In this blog post, we will delve into the world of SSL, exploring its significance, how it works, and why it is essential for safeguarding sensitive information online.
What is SSL?
SSL, or Secure Sockets Layer, is a cryptographic protocol that provides secure communication over the internet. It establishes an encrypted link between a web server and a user’s web browser, ensuring that all data transmitted between them remains private and secure.
The Importance of SSL Security
With cyber threats constantly evolving, SSL security plays a vital role in protecting sensitive information. It prevents unauthorized access, data breaches, and man-in-the-middle attacks. By encrypting data, SSL ensures that it cannot be intercepted or tampered with during transmission, providing users with peace of mind while sharing personal or financial details online.
How Does SSL Work?
SSL works through a process known as the SSL handshake. When a user attempts to establish a secure connection with a website, the web server presents its SSL certificate, which contains a public key. The user’s browser then verifies the certificate’s authenticity and generates a session key. This session key encrypts and decrypts data during the communication between the browser and server.
Types of SSL Certificates
Various types of SSL certificates are available, each catering to different needs and requirements. These include Domain-Validated (DV) certificates, Organization-Validated (OV) certificates, and Extended Validation (EV) certificates. Each type offers different validation and trust indicators, allowing users to make informed decisions when interacting with websites.
SSL and SEO
In addition to security benefits, SSL has implications for search engine optimization (SEO). In recent years, major search engines have prioritized secure websites, giving them a slight ranking boost. By implementing SSL security, website owners can enhance their security and improve their visibility and credibility in search engine results.
Conclusion:
In conclusion, SSL security is a fundamental component of a safe and trustworthy online experience. It protects sensitive data, prevents unauthorized access, and instills confidence in users. With the increasing prevalence of cyber threats, understanding SSL and its importance is crucial for both website owners and internet users alike.
In today's interconnected world, cyber threats continue to evolve, posing significant risks to individuals, organizations, and even nations. One such threat, the DNS Reflection Attack, has gained notoriety for its potential to disrupt online services and cause significant damage. In this blog post, we will delve into the intricacies of this attack, exploring its mechanics, impact, and how organizations can protect themselves from its devastating consequences.
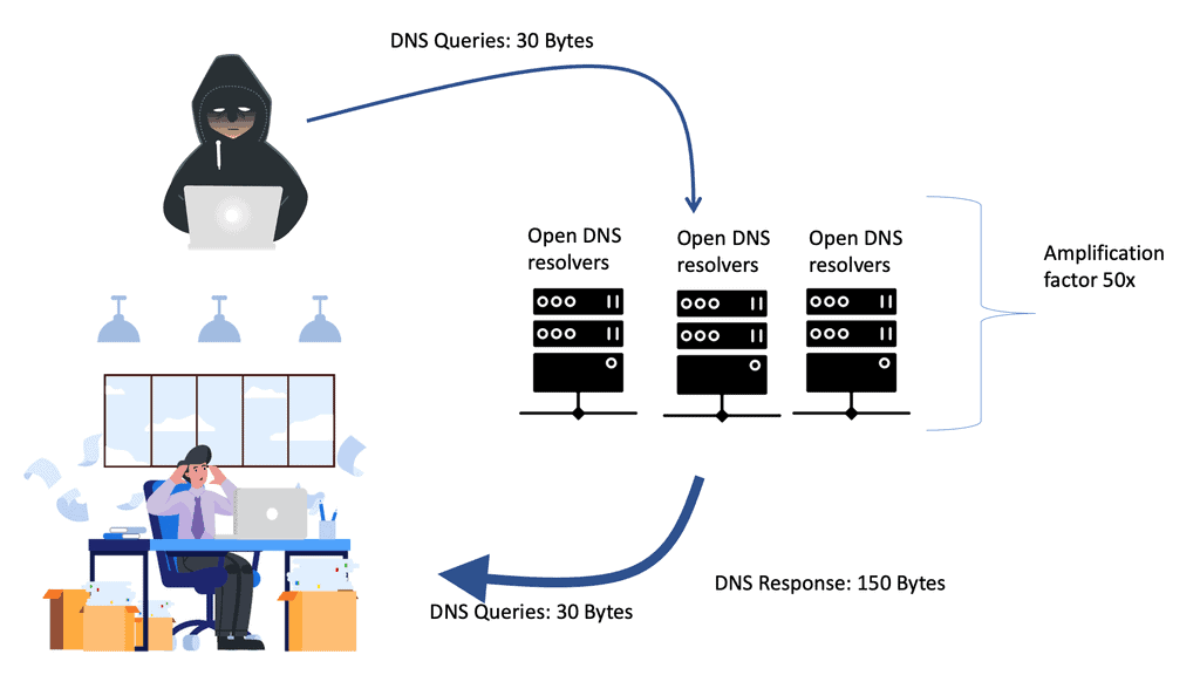
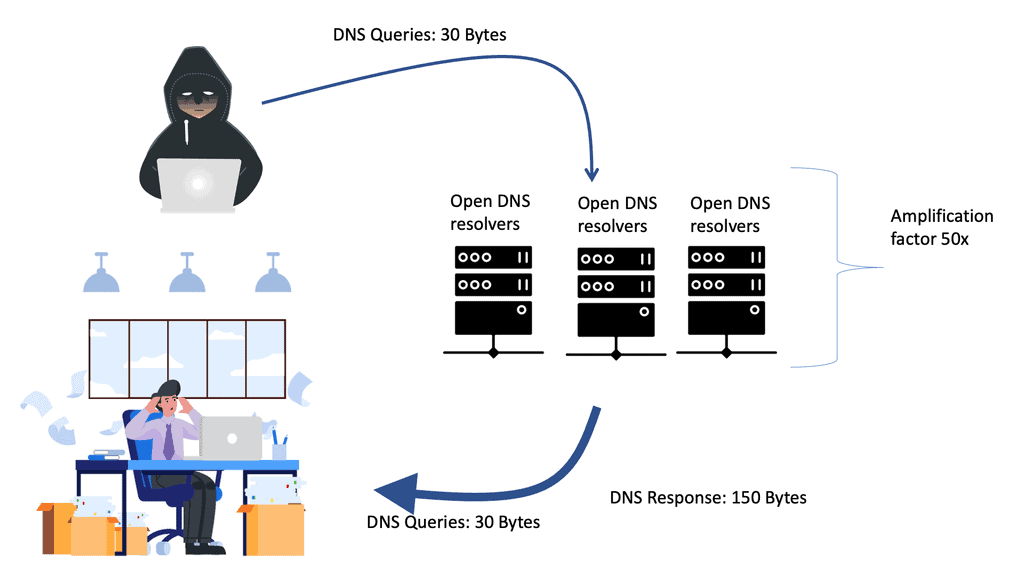
A DNS Reflection Attack, or a DNS amplification attack, is a type of Distributed Denial of Service (DDoS) attack. It exploits the inherent design of the Domain Name System (DNS) to overwhelm a target's network infrastructure. The attacker spoofs the victim's IP address and sends multiple DNS queries to open DNS resolvers, requesting significant DNS responses. The amplification factor of these responses can be several times larger than the original request, leading to a massive influx of traffic directed at the victim's network.
DNS reflection attacks exploit the inherent design of the Domain Name System (DNS) to amplify the impact of an attack. By sending a DNS query with a forged source IP address, the attacker tricks the DNS server into sending a larger response to the targeted victim.
One of the primary dangers of DNS reflection attacks lies in the amplification factor they possess. With the ability to multiply the size of the response by a significant factor, attackers can overwhelm the victim's network infrastructure, leading to service disruption, downtime, and potential data breaches.
DNS reflection attacks can target various sectors, including but not limited to e-commerce platforms, financial institutions, online gaming servers, and government organizations. The vulnerability lies in misconfigured DNS servers or those that haven't implemented necessary security measures.
To mitigate the risk of DNS reflection attacks, organizations must implement a multi-layered security approach. This includes regularly patching and updating DNS servers, implementing ingress and egress filtering to prevent IP address spoofing, and implementing rate-limiting or response rate limiting (RRL) techniques to minimize amplification.
Addressing the DNS reflection attack threat requires collaboration among industry stakeholders. Organizations should actively participate in industry forums, share threat intelligence, and adhere to recommended security standards such as the BCP38 Best Current Practice for preventing IP spoofing.
DNS reflection attacks pose a significant threat to the stability and security of network infrastructures. By understanding the nature of these attacks and implementing preventive measures, organizations can fortify their defenses and minimize the risk of falling victim to such malicious activities.
Highlights: DNS Reflection attack
Understanding DNS Reflection
1: -) The Domain Name System (DNS) serves as the backbone of the internet, translating human-readable domain names into IP addresses. However, cybercriminals have found a way to exploit this system by leveraging reflection attacks. DNS reflection attacks involve the perpetrator sending a DNS query to a vulnerable server, with the source IP address spoofed to appear as the victim’s IP address. The server then responds with a much larger response, overwhelming the victim’s network and causing disruption and loss of service.
**Distributed Attacks**
2: -) Attackers often use botnets to distribute the attack traffic across multiple sources to execute a DNS reflection attack, making it harder to trace back to the source. This is known as distributed attacks. By exploiting open DNS resolvers, which respond to queries from any IP address, attackers can amplify the data sent to the victim. This amplification factor significantly magnifies the attack’s impact as the victim’s network becomes flooded with incoming data.
**Attacking the Design of DNS**
3: -) DNS reflection attacks leverage the inherent design of the DNS protocol, capitalizing on the ability to send DNS queries with spoofed source IP addresses. This allows attackers to amplify the volume of traffic directed towards unsuspecting victims, overwhelming their network resources. By exploiting open DNS resolvers, attackers can create massive botnets and launch devastating distributed denial-of-service (DDoS) attacks.
**The Amplification Factor**
4: -) One of the most alarming aspects of DNS reflection attacks is the amplification factor they possess. Through carefully crafted queries, attackers can achieve amplification ratios of several hundred times, magnifying the impact of their assault. This means that even with a relatively low amount of bandwidth at their disposal, attackers can generate an overwhelming flood of traffic, rendering targeted systems and networks inaccessible.
Consequences of DNS reflection attack
– DNS reflection attacks can have severe consequences for both individuals and organizations. The vast amount of traffic generated by these attacks can saturate network bandwidth, leading to service disruptions, website downtime, and unavailability of critical resources.
– Moreover, these attacks can be used as a smokescreen to divert attention from other malicious activities, such as data breaches or unauthorized access attempts.
– While DNS reflection attacks can be challenging to prevent entirely, several measures organizations can take to mitigate their impact can help. Implementing network ingress filtering and rate-limiting DNS responses can help prevent IP spoofing and reduce the effectiveness of amplification techniques.
– Furthermore, regularly patching and updating DNS server software and monitoring DNS traffic for suspicious patterns can aid in detecting and mitigating potential attacks.
Google Cloud DNS
**Understanding the Core Features of Google Cloud DNS**
Google Cloud DNS is a high-performance, resilient DNS service powered by Google’s infrastructure. Some of its core features include high availability, low latency, and automatic scaling. It supports both public and private DNS zones, allowing you to manage your internal and external domain resources seamlessly. Additionally, Google Cloud DNS offers advanced features such as DNSSEC for enhanced security, ensuring that your DNS data is protected from attacks.
**Setting Up Your Google Cloud DNS**
Getting started with Google Cloud DNS is straightforward. First, you’ll need to create a DNS zone, which acts as a container for your DNS records. This can be done through the Google Cloud Console or using the Cloud SDK. Once your zone is set up, you can start adding DNS records such as A, CNAME, MX, and TXT records, depending on your needs. Google Cloud DNS also provides an easy-to-use interface to manage these records, making updates and changes a breeze.
Google Cloud Security Command Center
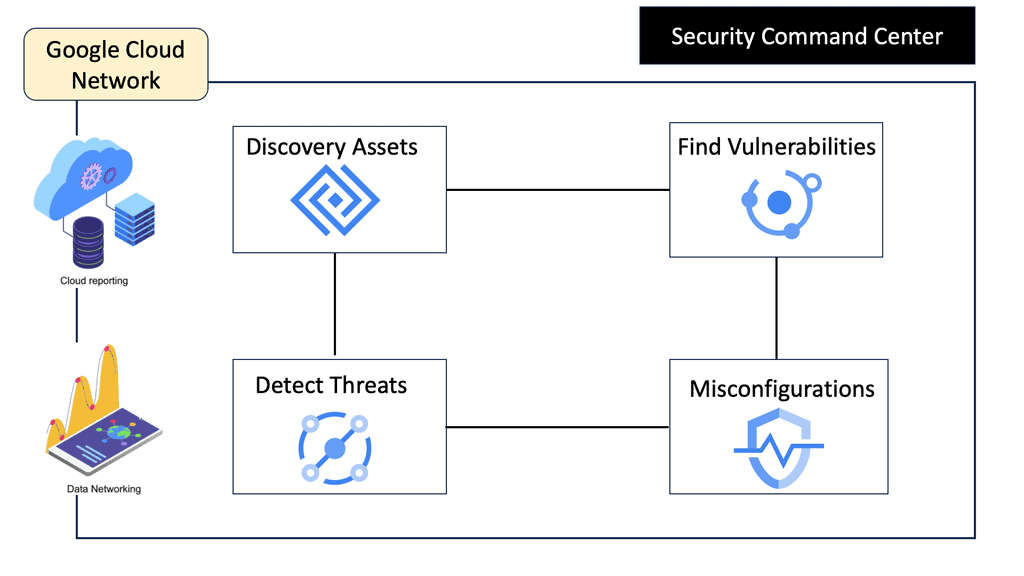
**Understanding Security Command Center**
Security Command Center is Google’s unified security and risk management platform for Google Cloud. It provides centralized visibility and control over your cloud assets, allowing you to identify and mitigate potential vulnerabilities. SCC offers a suite of tools that help detect threats, manage security configurations, and ensure compliance with industry standards. By leveraging SCC, organizations can maintain a proactive security posture, minimizing the risk of data breaches and other cyber threats.
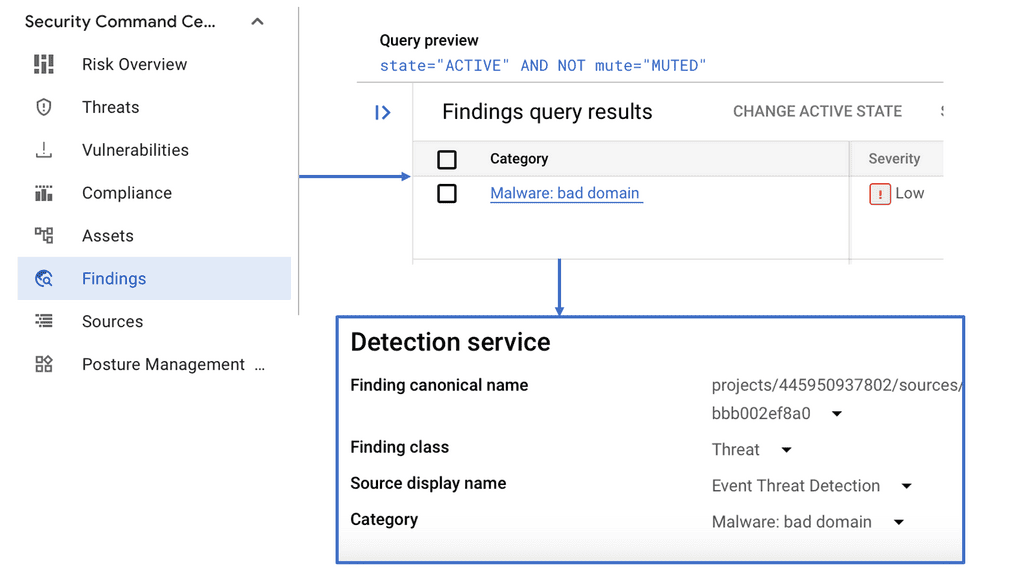
**The Anatomy of a DNS Reflection Attack**
One of the many threats that SCC can help mitigate is a DNS reflection attack. This type of attack involves exploiting publicly accessible DNS servers to flood a target with traffic, overwhelming its resources and disrupting services. Attackers send forged requests to DNS servers, which then send large responses to the victim’s IP address. Understanding the nature of DNS reflection attacks is crucial for implementing effective security measures. SCC’s threat detection capabilities can help identify unusual patterns and alert administrators to potential attacks.
**Leveraging SCC for Enhanced Security**
Utilizing Security Command Center involves more than just monitoring; it requires strategically configuring its features to suit your organization’s needs. SCC provides comprehensive threat detection, asset inventory, and security health analytics. By setting up custom alerts, organizations can receive real-time notifications about suspicious activities. Additionally, SCC’s integration with other Google Cloud services ensures a seamless security management experience. Regularly updating security policies and conducting audits through SCC can significantly enhance your cloud security strategy.
**Best Practices for Using Security Command Center**
To maximize the benefits of SCC, organizations should follow best practices tailored to their specific environments. Regularly review asset inventories to ensure all resources are accounted for and properly configured. Implement automated response strategies to quickly address threats as they arise. Keep abreast of new features and updates from Google to leverage the latest advancements in cloud security. Training your team to effectively utilize SCC’s tools is also critical in maintaining a secure cloud infrastructure.
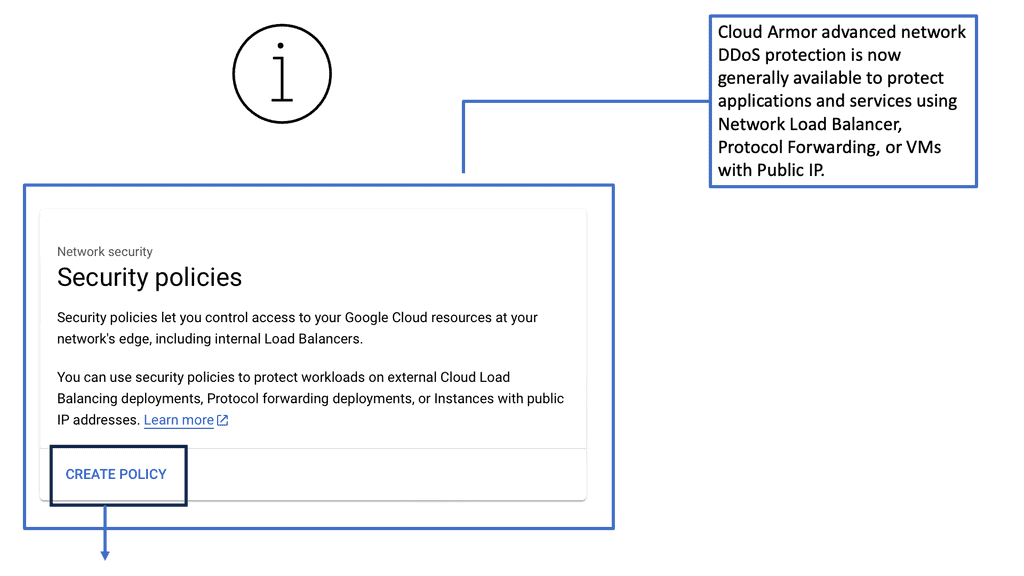
Cloud Armor – Enabling DDoS Protection
*Cloud Armor: The Ultimate Defender**
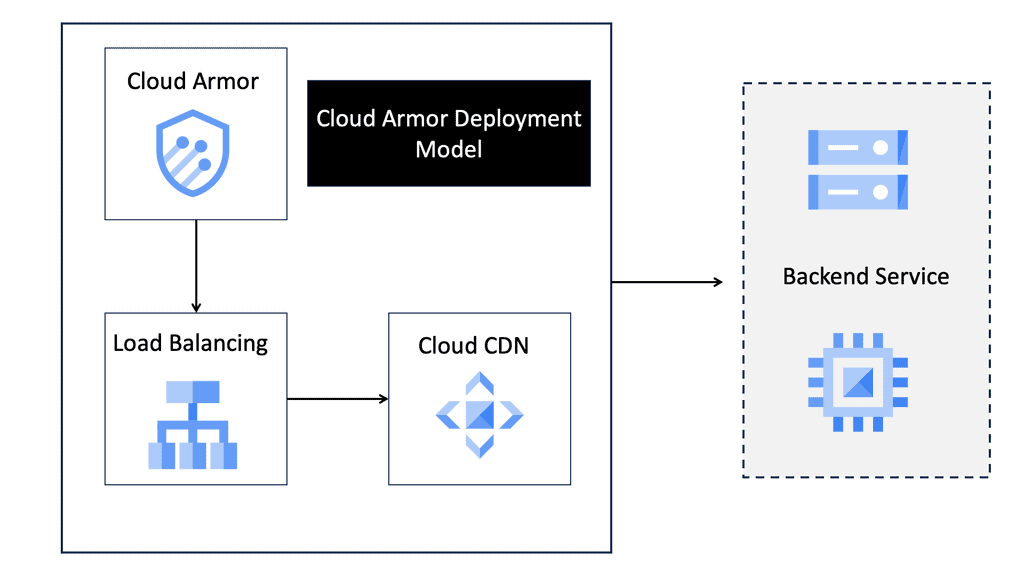
Enter Cloud Armor, a powerful line of defense in the realm of DDoS protection. Cloud Armor is designed to safeguard applications and websites from the barrage of malicious traffic, ensuring uninterrupted service availability. At its core, Cloud Armor leverages Google’s global infrastructure to absorb and mitigate attack traffic at the edge of the network. This not only prevents traffic from reaching and compromising your systems but also ensures that legitimate users experience no disruption.
**How Cloud Armor Mitigates DNS Reflection Attacks**
DNS reflection attacks, a common DDoS attack vector, capitalize on the amplification effect of DNS servers. Cloud Armor, however, is adept at countering this threat. By analyzing traffic patterns and employing advanced filtering techniques, Cloud Armor can distinguish between legitimate and malicious requests. Its adaptive algorithms learn from each attack attempt, continuously improving its ability to thwart DNS-based threats without impacting the performance for genuine users.
**Implementing Cloud Armor: A Step-by-Step Guide**
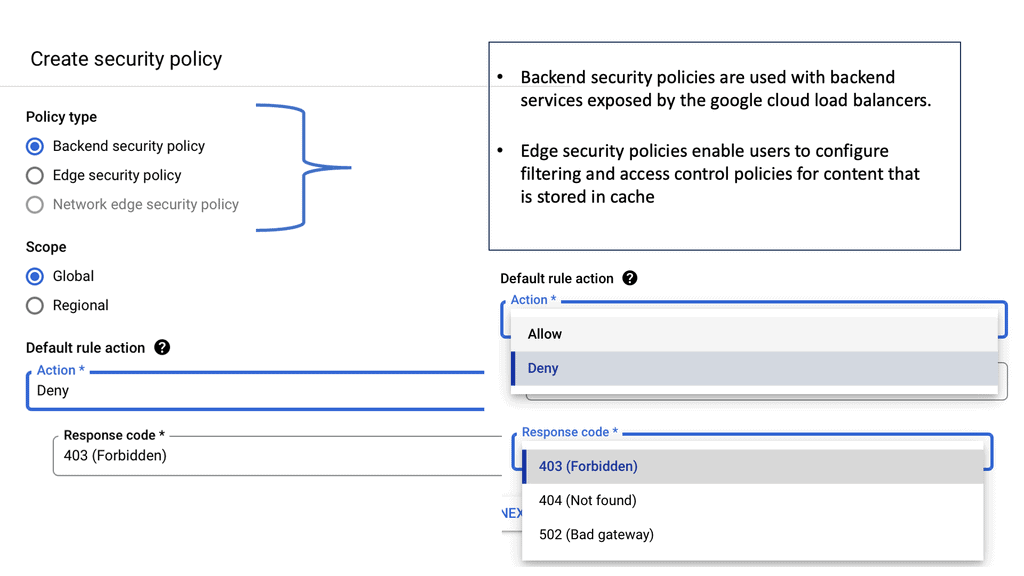
Deploying Cloud Armor to protect your digital assets is a strategic decision that involves several key steps:
1. **Assessment**: Begin by evaluating your current infrastructure to identify vulnerabilities and potential entry points for DDoS attacks.
2. **Configuration**: Set up Cloud Armor policies tailored to your specific needs, focusing on rules that address known attack vectors like DNS reflection.
3. **Monitoring**: Utilize Cloud Armor’s monitoring tools to keep an eye on traffic patterns and detect anomalies in real time.
4. **Optimization**: Regularly update your Cloud Armor configurations to adapt to emerging threats and ensure optimal protection.
Example DDoS Technology: BGP FlowSpec:
Understanding BGP Flowspec
BGP Flowspec, or Border Gateway Protocol Flowspec, is an extension to BGP that allows for distributing traffic flow specification rules across network routers. It enables network administrators to define granular traffic filtering policies based on various criteria such as source/destination IP addresses, transport protocols, ports, packet length, DSCP markings, etc. By leveraging BGP Flowspec, network administrators can have fine-grained control over traffic filtering and mitigation of DDoS attacks.
Enhanced Network Security: One of the primary advantages of BGP Flowspec is its ability to improve network security. Organizations can effectively block malicious traffic or mitigate the impact of DDoS attacks in real-time by defining specific traffic filtering rules. This proactive approach to network security helps safeguard critical resources and minimize downtime
DDoS Mitigation: BGP Flowspec plays a crucial role in mitigating DDoS attacks. Organizations can quickly identify and drop malicious traffic at the network’s edge to prevent attacks from overwhelming their network resources. BGP Flowspec allows rapidly deploying traffic filtering policies, providing immediate protection against DDoS threats.
**Combating DNS Reflection Attacks with BGP FlowSpec**
Several measures can be implemented to protect networks from BGP Flowspec and DNS reflection attacks. First, network administrators should ensure that BGP Flowspec is enabled and properly configured on their network devices. This allows for granular traffic filtering and the ability to drop or rate-limit specific traffic patterns associated with attacks.
In addition, implementing robust ingress and egress filtering mechanisms at the network edge is crucial. Organizations can significantly reduce the risk of DNS reflection attacks by filtering out spoofed or illegitimate traffic. Deploying DNS reflection attack mitigation techniques, such as rate limiting or deploying DNSSEC (Domain Name System Security Extensions), can also enhance network security.
Understanding DNS Amplification
Domain names are stored and mapped into IP addresses in the Domain Name System (DNS). As part of a two-step distributed denial-of-service attack (DDoS), DNS reflection/amplification is used to manipulate open DNS servers. Cybercriminals use a spoofed IP address to send massive requests to DNS servers.
Therefore, the DNS server responds to the request and attacks the target victim. Many traffic is sent to the victim server since these attacks are more significant than the spoofed request. An attack can render data entirely inaccessible to a company or organization.
Even though DNS reflection/amplification DDoS attacks are common, they pose a severe threat to an organization’s servers. Massive amounts of traffic pushed into the victim server consume company resources, slowing and paralyzing systems to prevent real traffic from accessing the DNS server.
Diagram: Attacking DNS.
Combat DNS Reflection/Amplification
1: – DNS Reflectors:
Despite the difficulty of mitigating these attacks, network operators can implement several strategies to combat them. DNS servers should be hosted locally and internally within the organization to reduce the possibility of their own DNS servers being used as reflectors. Additionally, this allows organisations to separate internal DNS traffic from external DNS traffic. Therefore segregating DNS traffic. Therefore allowing them to block unwanted DNS traffic.
2: – Block Unsolicited DNS Replies:
Organizations should block unsolicited DNS replies, allowing only responses requested by internal clients, to protect themselves against DNS reflection/amplification attacks. When DDoS attacks are reflected in DNS Reply sections, detection tools can detect and remove unwanted DNS replies.
Strengthening Your Network Defenses
Several proactive measures can be implemented to protect your network against DNS reflection attacks.
3: – Implement DNS Response Rate Limiting (DNS RRL): DNS RRL is an effective technique that limits the number of responses sent to a specific source IP address, mitigating the amplification effect of DNS reflection attacks.
4: – Employing Access Control Lists (ACLs): By configuring ACLs on your network devices, you can restrict access to open DNS resolvers, allowing only authorized clients to make DNS queries and reducing the potential for abuse by attackers.
5: – Enabling DNSSEC (Domain Name System Security Extensions): DNSSEC adds an extra layer of security to the DNS infrastructure by digitally signing DNS records. Implementing DNSSEC ensures the authenticity and integrity of DNS responses, making it harder for attackers to manipulate the system.
Additionally, deploying firewalls, intrusion prevention systems (IPS), and DDoS mitigation solutions can provide an added layer of defense.
Example IDS Technology: Suricata
### Understanding Suricata IPS
In the rapidly evolving world of cybersecurity, intrusion detection and prevention systems (IDPS) are crucial for safeguarding networks against threats. Suricata, an open-source engine, stands out as a versatile tool for network security. Developed by the Open Information Security Foundation (OISF), Suricata offers robust intrusion prevention system (IPS) capabilities that help organizations detect and block malicious activities effectively. Unlike traditional systems, Suricata provides multi-threaded architecture, enabling it to handle high throughput and complex network environments with ease.
### Key Features of Suricata IPS
Suricata boasts a range of features that make it a powerful ally in network security. One of its standout capabilities is deep packet inspection, which allows it to scrutinize data packets for any suspicious content. Additionally, Suricata supports a wide array of protocols, making it adaptable to various network architectures. Its rule-based language, compatible with Snort rules, provides flexibility in defining security policies tailored to specific organizational needs. Moreover, Suricata’s ability to generate alerts and logs in multiple formats ensures seamless integration with existing security information and event management (SIEM) systems.
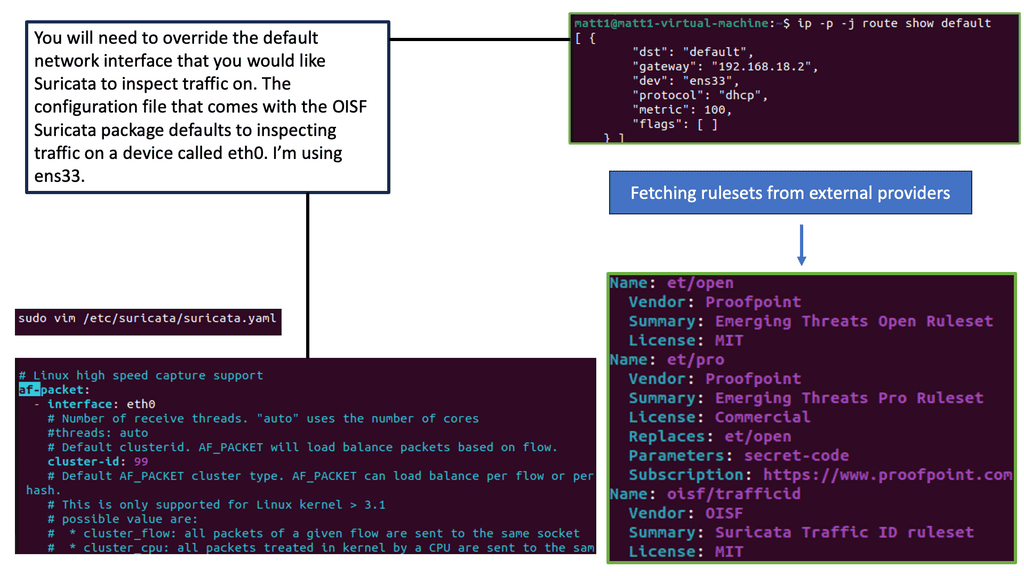
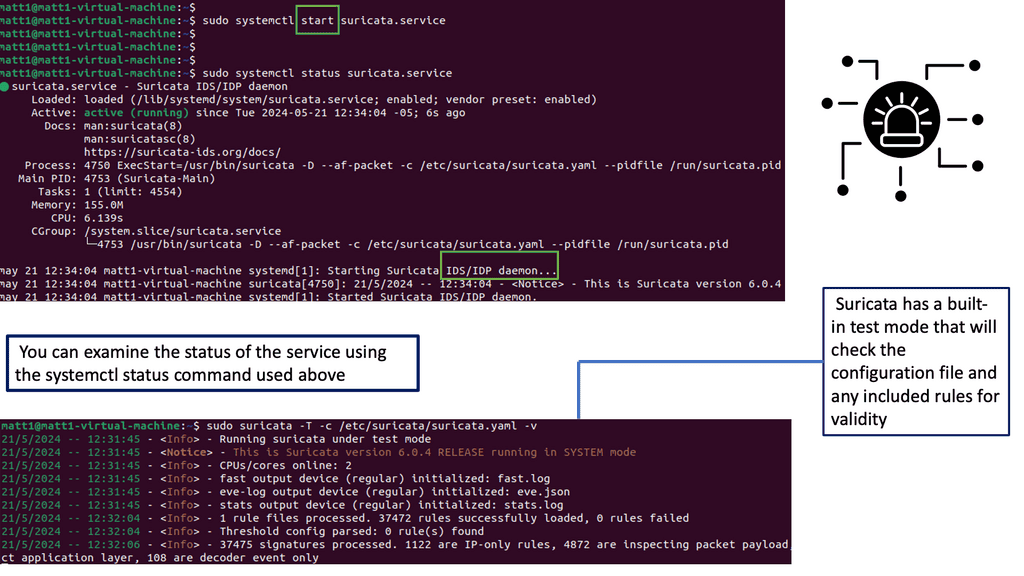
### Implementing Suricata in Your Network
Deploying Suricata IPS in your network involves several key steps. First, assess your network infrastructure to determine the optimal placement of the Suricata engine for maximum effectiveness. Typically, it is positioned at strategic points within the network to monitor traffic flow comprehensively. Next, configure Suricata with appropriate rulesets, either by utilizing available community rules or customizing them to address specific threats pertinent to your organization. Regular updates and fine-tuning of these rules are essential to maintain the system’s efficacy in detecting emerging threats.
The Role of DNS
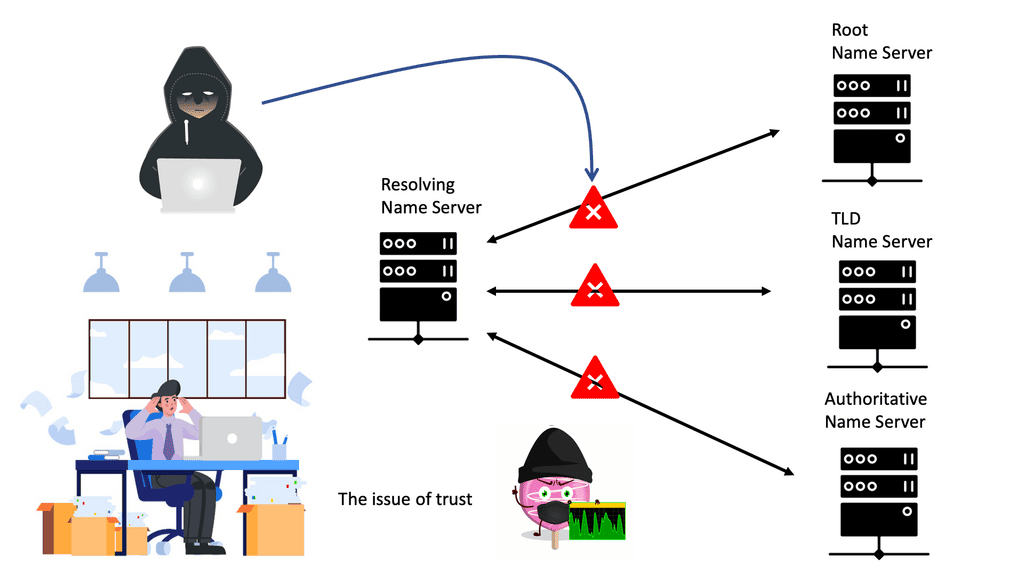
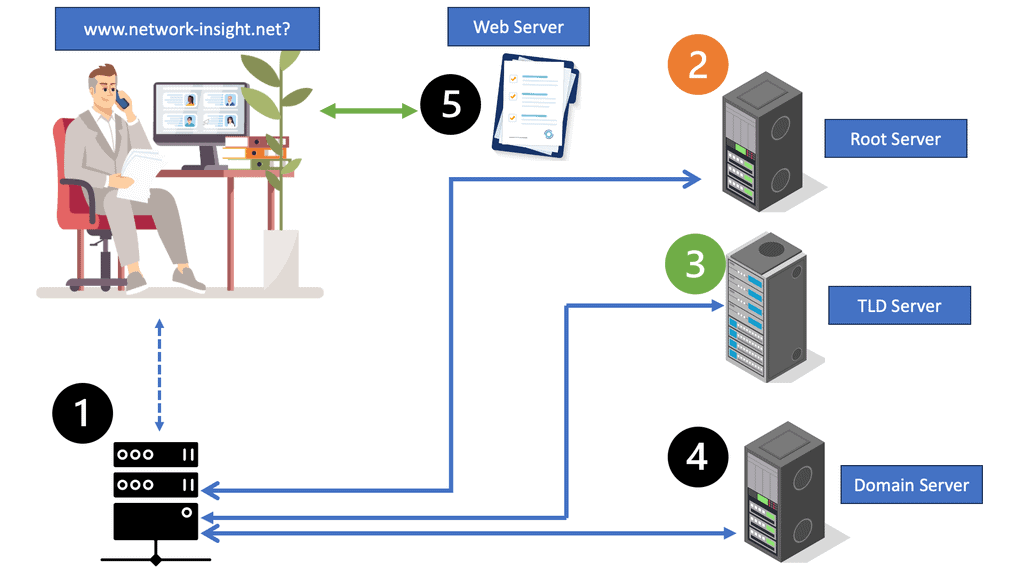
Firstly, the basics. DNS (Domain Name System) is a host-distributed database that converts domain names to IP addresses. Most clients rely on DNS for communicating services such as Telnet, file transfer, and HTTP web browsing. It goes through a chain of events, usually only taking milliseconds for the client to receive a reply. Quick does not often mean secure. First, let us examine the DNS structure and DNS operations.
The DNS Process
The clients send a DNS query to a local DNS server (LDNS), a Resolver. Then, the LDNS relays the request to a Root server with the required information to service the request. Root servers are a critical part of Internet architecture.
They are authoritative name servers that serve the DNS root zone by directly answering requests or returning a list of authoritative nameservers for the appropriate top-level domain (TLD). Unfortunately, this chain of events is the base of DNS-based DDoS attacks such as the DNS Recursion attack.
Guide on the DNS Process.
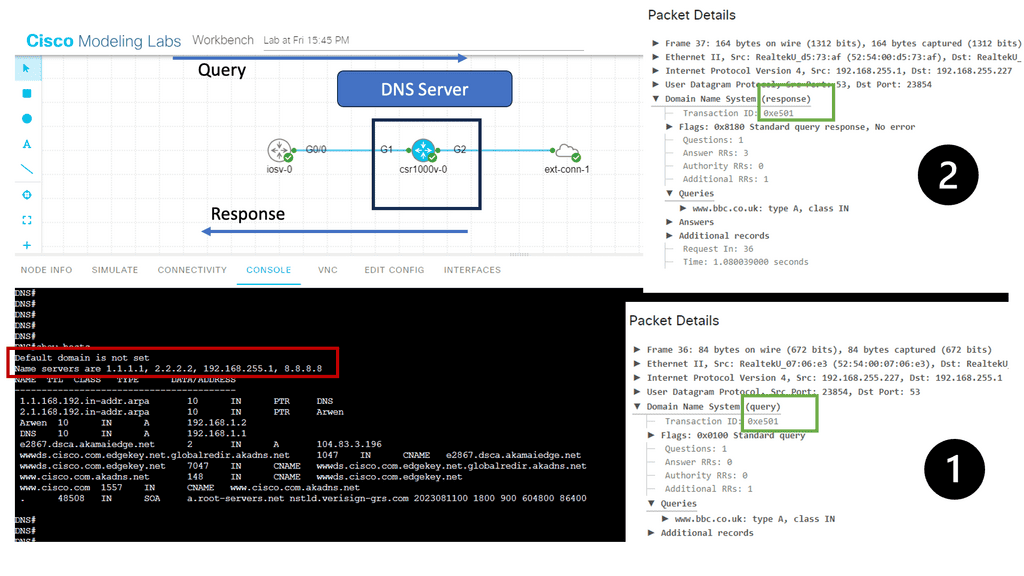
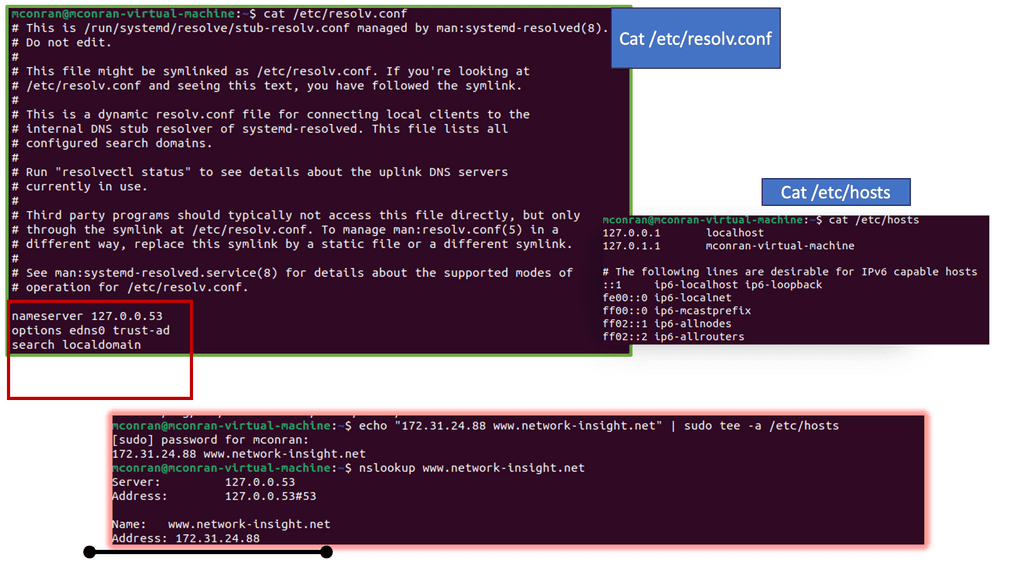
The DNS resolution process begins when a user enters a domain name in their browser. It involves several steps to translate the domain name into an IP address. In the example below, I have a CSR1000v configured as a DNS server and several name servers. I also have an external connector configured with NAT for external connectivity outside of Cisco Modelling Labs.
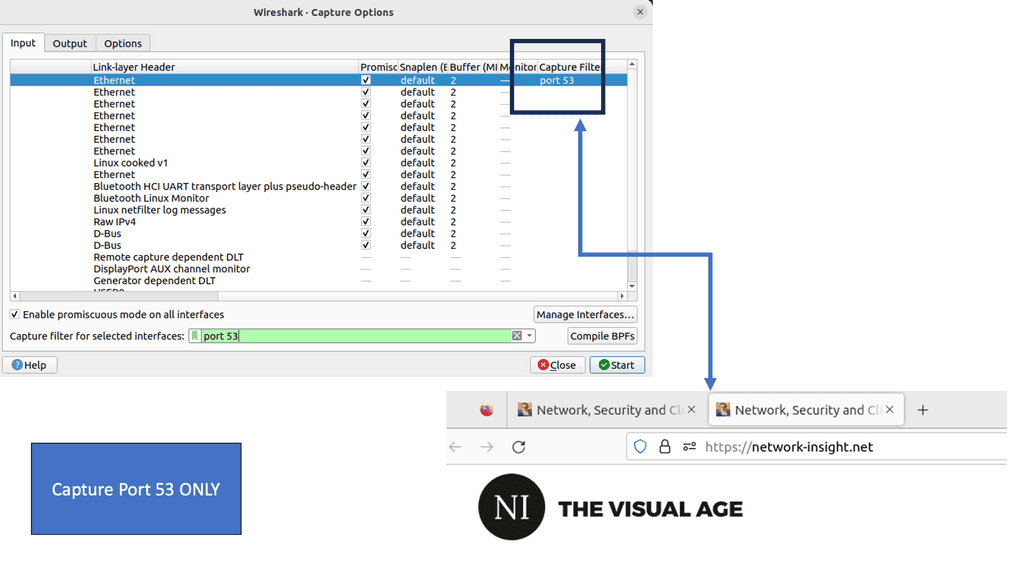
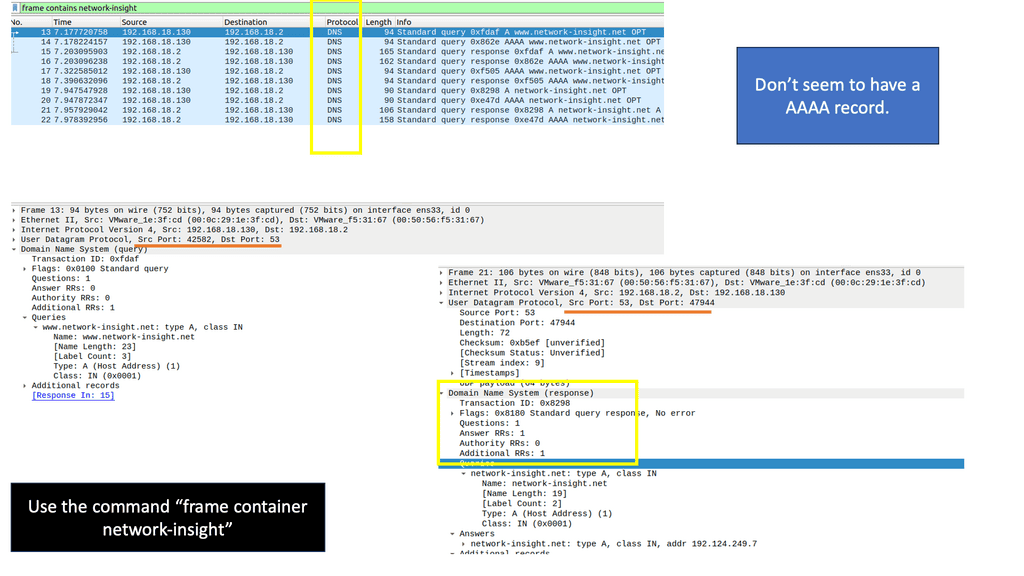
Notice the DNS Query and the DNS Response from the Packet Capture. Keep in mind this is UDP and, by default, insecure.
Before you proceed, you may find the following posts useful for pre-information:
So, we have domain names that index DNS’s distributed database. Each domain name is a path in a large inverted tree called the domain namespace. So, when you think about the tree’s hierarchical structure, it is similar to the design of the Unix filesystem.
The tree has a single root at the top. So, the Unix filesystem represents the root directory by a slash (/). So, we have DNS that calls and refers to it as “the root.” But it’s a similar structure that, too, has limits. The DNS’s tree can branch any number of ways at each intersection point or node. However, the depth of the tree is limited to 127 levels, which you are not likely to reach.
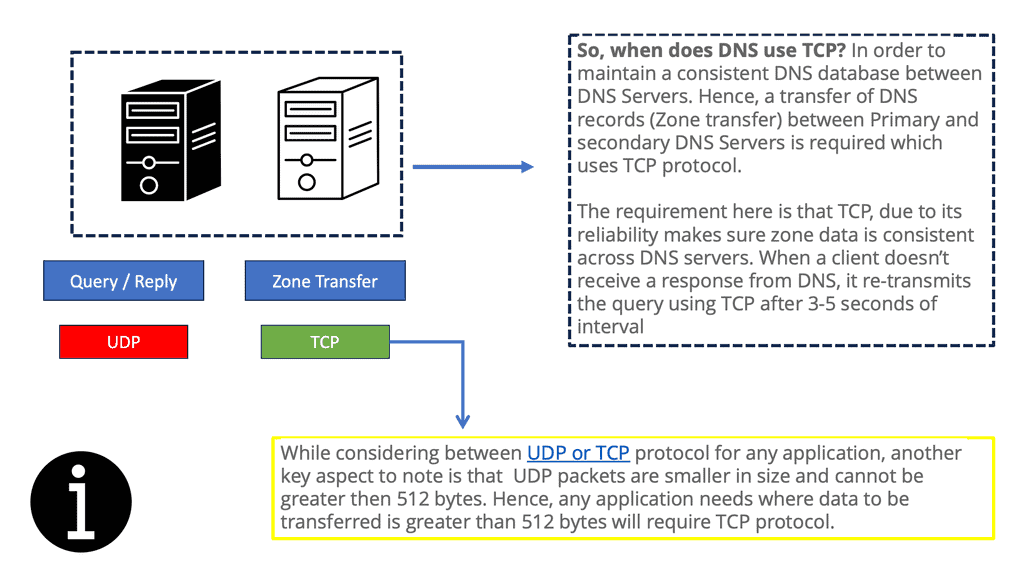
DNS and its use of UDP
DNS uses User Datagram Protocol (UDP) as the transport protocol. UDP is a lot faster than TCP due to its stateless operation. Stateless means no connection state is maintained between UDP peers. It has no connection information, just a query/response process.
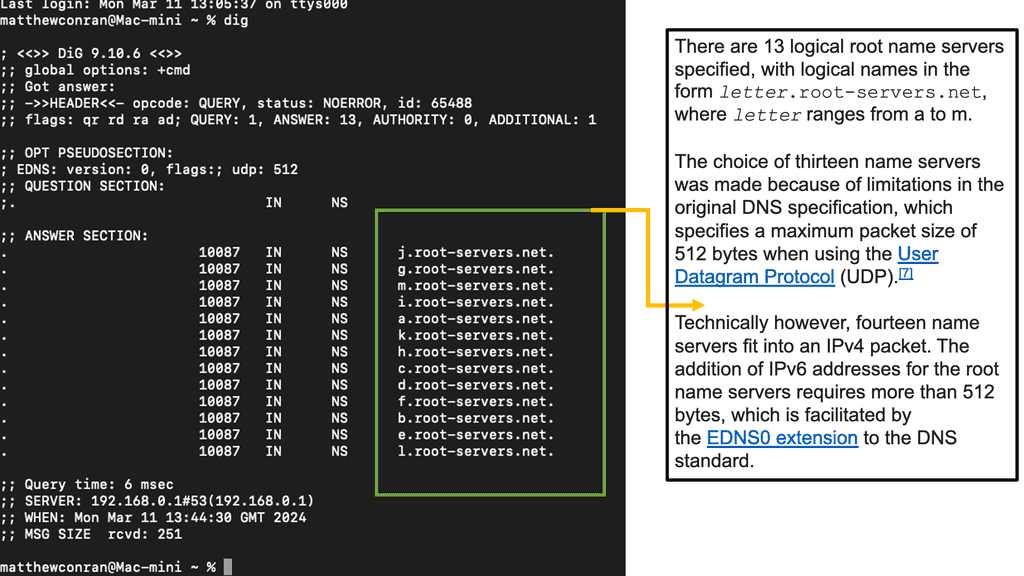
**Size of unfragmented UDP packets
One problem with using UDP as the transport protocol is that the size of unfragmented UDP packets has limited the number of root server addresses to 13. To alleviate this problem, root server IP addressing is based on Anycast, permitting the number of root servers to be larger than 500. Anycast permits the same IP address to be advertised from multiple locations.
Understanding DNS Reflection Attack
The attacker identifies vulnerable DNS resolvers that can be abused to amplify the attack. These resolvers respond to DNS queries from any source without proper source IP address validation. By sending a small DNS request with the victim’s IP address as the source, the attacker tricks the resolver into sending a much larger response to the victim’s network. This amplification effect allows attackers to generate a significant traffic volume, overwhelming the victim’s infrastructure and rendering it inaccessible.
DNS Reflection Attacks can have severe consequences, both for individuals and organizations. Some of the critical impacts include:
Disruption of Online Services:
The attack can destroy websites, online services, and other critical infrastructure by flooding the victim’s network with massive amplified traffic. This can result in financial losses, reputational damage, and significant user inconvenience.
Collateral Damage:
In many cases, DNS Reflection Attacks can have collateral damage, affecting the intended target and other systems sharing the same network infrastructure. This can lead to a ripple effect, causing cascading failures and disrupting multiple online services simultaneously.
Loss of Confidentiality:
During a DNS Reflection Attack, attackers exploit chaos and confusion to gain unauthorized access to sensitive data. This can include stealing user credentials, financial information, or other valuable data, further exacerbating the damage caused by the attack.
To mitigate the risk of DNS Reflection Attacks, organizations should consider implementing the following measures:
Source IP Address Validation:
DNS resolvers should be configured to only respond to queries from authorized sources, preventing the use of open resolvers for amplification attacks.
Rate Limiting:
By implementing rate-limiting mechanisms, organizations can restrict the number of DNS responses sent to a particular IP address within a given time frame. This can help mitigate the impact of DNS Reflection Attacks.
Network Monitoring and Traffic Analysis:
Organizations should regularly monitor their network traffic to identify suspicious patterns or abnormal spikes in DNS traffic. Advanced traffic analysis tools can help detect and mitigate DNS Reflection Attacks in real-time.
DDoS Mitigation Services:
Engaging with reputable DDoS mitigation service providers can offer additional protection against DNS Reflection Attacks. These services employ sophisticated techniques to identify and filter malicious traffic, ensuring the availability and integrity of online services.
Exploiting DNS-Based DDoS Attacks
Attacking UDP
Mainly, denial of service (DoS) mechanisms disrupt activity and prevent upper-layer communication between hosts. Attacking UDP is often harder to detect than general DoS resource saturation attacks. Attacking UDP is not as complex as attacking TCP because UDP has no authentication and is connectionless.
This makes it easier to attack than some application protocols, which usually require authentication and integrity checks before accepting data. The potential threat against DNS is that it relies on UDP and is subject to UDP control plane threats. Launching an attack on a UDP session can be achieved without application awareness.
1: **DNS query attack**
One DNS-based DDoS attack method is carrying out a DNS query attack. The attacker uses a tap client and sends a query to a remote DNS server to overload it with numerous clients, sending queries to the same DNS server. The capacity of a standard DNS server is about 150,000 queries. If the remote server does not have the capacity, it will drop and ignore the legitimate request and be unable to send responses. The DNS server cannot tell which query is good or bad. A query attack is a relatively simple attack.
2: **DNS Recursion attack**
The recursive nature of DNS servers enables them to query one another to locate a DNS server with the correct IP address or to find an authoritative DNS server that holds the canonical mapping of the domain name to its IP address. The very nature of this operation opens up DNS to a DNS Recursion Attack.
A DNS Recursion Attack is also known as a DNS cache poisoning attack. DNS attacks occur when a recursive DNS server requests an IP address from another; an attacker intercepts the request and gives a fake response, often the IP address for a malicious website.
3: **DNS reflection attack**
A more advanced form of DNS-based DDoS attacks is a technique called a DNS reflection attack. The attackers take advantage of the underlying vulnerability in the DNS protocol. The return address (source IP address in the query) is tricked into being someone else. This is known as DNS Spoofing or DNS cache poisoning.
The attackers send out a DNS request and set the IP address as their target for the source IP. The natural source gets overwhelmed with return traffic, and the source IP address is known to be spoofed.
The main reason for carrying out reflection attacks is an amplification. The advertisement of spoofed DNS name records enables the attacker to carry out many other attacks. As discussed, they can redirect flows to a destination of choice, which opens up other sophisticated attacks that facilitate eavesdropping, MiTM attacks, the injection of false data, and the distribution of Malware and Trojans.
Diagram: DNS Reflection Attack.
DNS and unequal sizes
IPv4 & IPv6 Amplification Attacks
The nature of the DNS system is that it has unequal sizes. The query messages are tiny, and the response is typically double the query size. However, there are certain record types that you can ask for that are much more significant. Attackers may concentrate their attack using DNS security extension (DNSSEC) cryptographic or EDNS0 extensions. If you add DNSsec, it combines a lot of keys and makes the packet much larger.
These requests can increase packet size from around 40 bytes to above the maximum Ethernet packet size of 4000. They potentially require fragmentation, further targeting network resources. This is the essence of any IPv4 and IPv6 attack amplification: a small query with a significant response. Many load balancing products have built-in DoS protection, enabling you to set limits for packets per second on specific DNS queries.
Amplified with DNS Open Resolvers
The attack can be amplified even more with DNS Open Resolvers, enabling the least number of Bots with maximum damage. A Bot is a type of Malware that allows the attacker to control it. Generally, a security mechanism should be in place so resolvers only answer requests from a list of clients. These are called locked or secured DNS resolvers.
Unfortunately, many resolvers lack best-practice security mechanisms. Unfortunately, Open Resolvers amplify the amplification attack surface even further. DNS amplification is a variation of an old-school attack called an SMURF attack.
At a fundamental level, ensure you have an automated list to accept only known clients. Set up ingress filtering to ensure you don’t have an illegal address leaving your network. Ingress filtering prevents any spoofing-style attacks. This will weed it down and thin it out a bit.
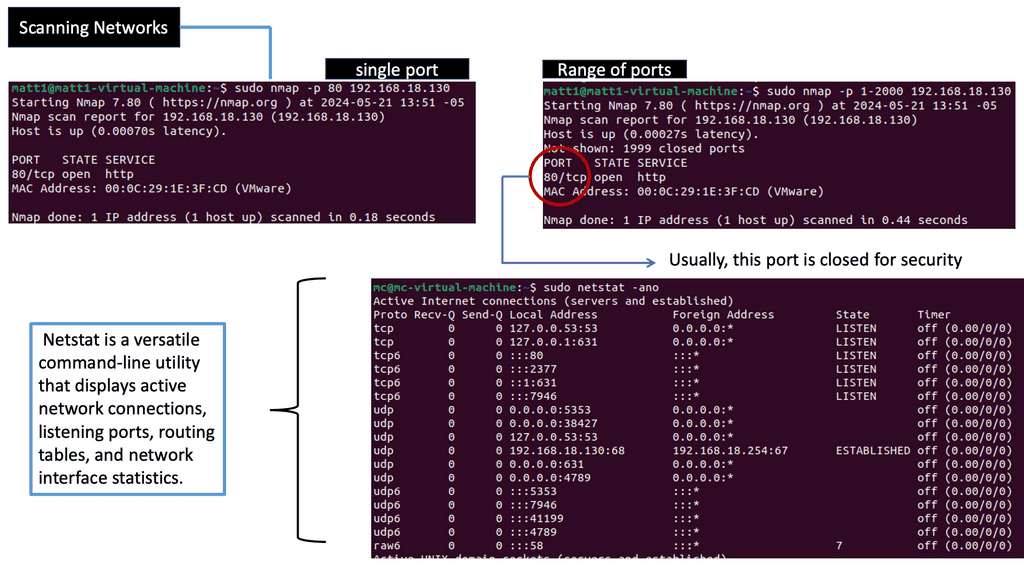
Next, test your network and make sure you don’t have any Open Resolvers. NMAP (Network Mapper) is a tool with a script to test recursion. This will test whether your local DNS servers are open to recursion attacks.
Example DDOS Protection: GTM Load Balancer
At a more expensive level, F5 offers a product called DNS Express. It allows you to withstand DoS attacks by adding an F5 GTM Load Balancer to your DNS servers. DNS Express handles the request on behalf of the DNS server. It works from high-speed RAM and, on average, handles about 2 million requests per second.
This is about 12 times more than a regular DNS server, which should be enough to withstand a sophisticated DNS DoS attack. Later posts deal with mitigation techniques, including stateful firewalls and other devices.
Closing Points on DNS Reflection Attack
A DNS Reflection Attack is a type of Distributed Denial of Service (DDoS) attack that leverages the Domain Name System (DNS) to overwhelm a target with traffic. The attacker sends a small query to a DNS server, spoofing the IP address of the victim. The server, in turn, responds with a much larger packet, sending it to the victim’s address. By exploiting numerous DNS servers, an attacker can amplify the volume of data directed at the target, effectively crippling their services.
The mechanics of a DNS Reflection Attack are both clever and destructive. At its core, the attack relies on two primary components: spoofing and amplification. Here’s a step-by-step breakdown of the process:
1. **Spoofing**: The attacker sends DNS requests to multiple open DNS resolvers, using the victim’s IP address as the source address.
2. **Amplification**: These DNS requests are crafted to trigger large responses. A small request can generate a response that is several times larger, due to the nature of DNS queries and responses.
3. **Reflection**: The DNS servers send the amplified responses to the victim’s IP address, inundating their network with data and leading to service disruption.
The consequences of a successful DNS Reflection Attack can be severe, affecting not only the direct victim but also the broader network infrastructure. Some of the notable impacts include:
– **Service Downtime**: The primary goal of a DNS Reflection Attack is to render services unavailable. This can lead to significant financial losses and damage to reputation for businesses.
– **Network Congestion**: The flood of traffic can cause congestion on the network, affecting legitimate users and potentially leading to further delays and outages.
– **Collateral Damage**: Open DNS resolvers used in the attack can also face repercussions, as they become unwitting participants in the attack, consuming resources and bandwidth.
Protecting against DNS Reflection Attacks requires a multi-layered approach, combining best practices and technological solutions. Here are some effective strategies:
– **Implement Rate Limiting**: Configure DNS servers to limit the number of responses sent to a single IP address within a specific timeframe, reducing the potential for amplification.
– **Use DNSSEC**: DNS Security Extensions (DNSSEC) add a layer of authentication to DNS responses, making it more difficult for attackers to spoof source IP addresses.
– **Deploy Firewalls and Intrusion Detection Systems (IDS)**: These tools can help identify and filter out malicious traffic, preventing it from reaching the intended target.
– **Close Open Resolvers**: Ensure that DNS servers are not open to the public, limiting their use to authorized users only.
Summary: DNS Reflection attack
In the vast realm of the internet, a fascinating phenomenon known as DNS reflection exists. This intriguing occurrence has captured the curiosity of tech enthusiasts and cybersecurity experts alike. In this blog post, we embarked on a journey to unravel the mysteries of DNS reflection and shed light on its inner workings.
Understanding DNS
Before diving into the intricacies of DNS reflection, it is essential to grasp the basics of DNS (Domain Name System). DNS serves as the backbone of the internet, translating human-readable domain names into IP addresses that computers can understand. It acts as a directory, facilitating seamless communication between devices across the web.
The Concept of Reflection
Reflection, in the context of DNS, refers to the bouncing back of packets between different systems. It occurs when a DNS server receives a query and responds by sending a more significant response to an unintended target. This amplification effect can lead to potentially devastating consequences if exploited by malicious actors.
Amplification Attacks
One of the most significant threats associated with DNS reflection is the potential for amplification attacks. Cybercriminals can leverage this vulnerability to launch large-scale distributed denial of service (DDoS) attacks. By spoofing the source IP address and sending a small query to multiple DNS servers, they can provoke a deluge of amplified responses to the targeted victim, overwhelming their network infrastructure.
Mitigation Strategies
Given the potential havoc that DNS reflection can wreak, it is crucial to implement robust mitigation strategies. Network administrators and cybersecurity professionals can take several proactive steps to protect their networks. These include implementing source IP verification, deploying rate-limiting measures, and utilizing specialized DDoS protection services.
Conclusion
In conclusion, DNS reflection poses a significant challenge in cybersecurity. By understanding its intricacies and implementing appropriate mitigation strategies, we can fortify our networks against potential threats. As technology evolves, staying vigilant and proactive is paramount in safeguarding our digital ecosystems.
In the vast world of the internet, the Domain Name System (DNS) plays a crucial role in translating human-readable domain names into machine-readable IP addresses. It is a fundamental component of the Internet infrastructure, enabling users to access websites and other online resources effortlessly. This blog post aims to comprehensively understand the DNS structure and its significance in the digital realm.
At its core, the Domain Name System is a decentralized system that translates human-readable domain names (e.g., www.example.com) into IP addresses, which computers understand. It acts as a directory for the internet, enabling us to access websites without memorizing complex strings of numbers.
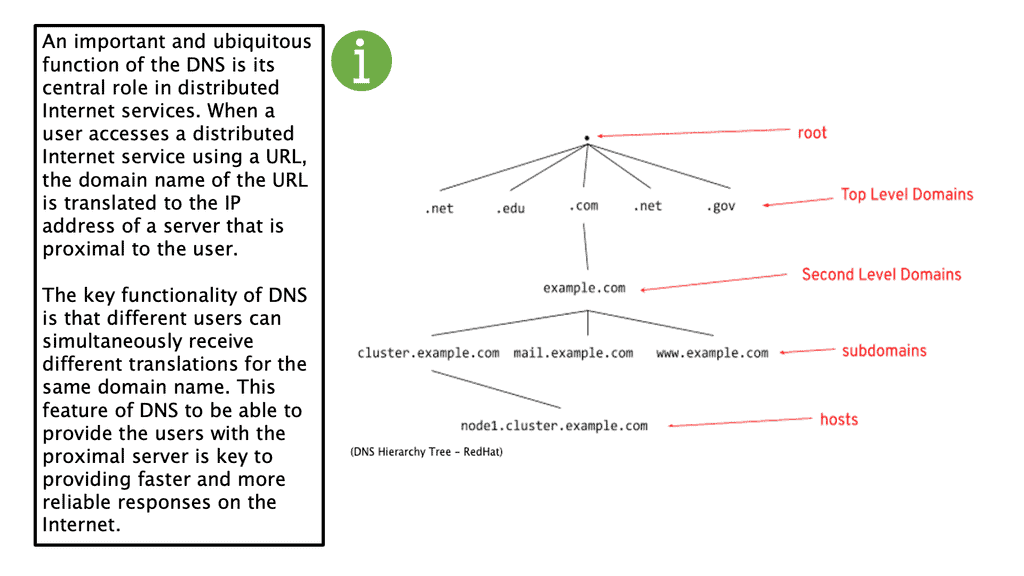
The DNS structure follows a hierarchical system, resembling an upside-down tree. The DNS tree structure consists of several levels. At the top level, we have the root domain, represented by a single dot (.). Below the root are top-level domains (TLDs), such as .com and .org, or country-specific ones, like .us or .uk.
Further, down the DNS hierarchy, we encounter second-level domains (SLDs) unique to a particular organization or entity. For instance, in the domain name “example.com,” “example” is the SLD.
Highlights: DNS Structure
The Basics of DNS
Turning Names into Numbers
At its core, DNS functions like a phone book for the internet. When you type a domain name into your browser, DNS translates this name into an IP address, enabling your browser to locate the server that hosts the website. This process is seamless and happens in milliseconds, allowing you to access websites from anywhere in the world without needing to remember complex numerical addresses.
When you enter a web address in your browser, the DNS system kicks into action. First, your computer checks its local DNS cache to see if it already knows the corresponding IP address. If it doesn’t, the request is sent to a DNS server, which begins the process of resolving the domain name by querying other servers. This usually involves several steps, including checking through root servers, TLD (Top-Level Domain) servers, and authoritative DNS servers until it finds the correct IP address. This entire process happens in mere milliseconds, allowing you to access your desired web page almost instantly.
DNS is a fundamental component of the internet’s infrastructure. Without it, navigating the web would be much more complex and cumbersome, requiring users to remember strings of numbers instead of simple, memorable names. Beyond convenience, DNS also plays a critical role in the performance and security of internet communications. A well-functioning DNS ensures that users are quickly and accurately directed to their intended destinations, while DNS security measures protect against threats like DNS spoofing and cache poisoning.
Components of DNS: The Building Blocks
The DNS structure is composed of several key components:
1. **Domain Names**: These are the user-friendly names like “example.com” that we use to navigate the web.
2. **DNS Servers**: These include the root name servers, TLD (Top-Level Domain) servers, and authoritative servers. Each plays a distinct role in the hierarchy of DNS resolution.
3. **Resolvers**: These are intermediaries that handle the user’s request and query the DNS servers to find the corresponding IP address.
Understanding these components is crucial, as they work in harmony to ensure a smooth internet browsing experience.
The DNS Resolution Process: A Step-by-Step Journey
When you enter a domain name, a process unfolds behind the scenes:
1. **Querying the Resolver**: Your request first reaches a DNS resolver, typically managed by your Internet Service Provider (ISP).
2. **Contacting the Root Server**: The resolver contacts a root server, which directs it to the appropriate TLD server based on the domain extension (.com, .org, etc.).
3. **Reaching the Authoritative Server**: The TLD server points the resolver to the authoritative name server specific to the domain, where the IP address is finally retrieved.
This multi-step process, though complex, is executed in mere moments, highlighting the efficiency of the DNS system.
DNS Security: Protecting the Web’s Address Book
As a critical component of internet infrastructure, DNS is a target for cyber threats such as DNS spoofing and cache poisoning. To combat these threats, DNS security measures like DNSSEC (Domain Name System Security Extensions) have been implemented. DNSSEC adds a layer of security by ensuring that the responses to DNS queries are authentic, protecting users from malicious redirections.
Endpoint Selection
Network designers are challenged with endpoint selection. How do you get eyeballs to the correct endpoint in multi-datacenter environments? Consider Domain Name System (DNS) “air traffic control” for your site. Some DNS servers should offer probing mechanisms that extract real-time data from your infrastructure for automatic traffic management—as a result, optimizing traffic management to and from the data center with efficient DNS structure, optimizing with DNS solution from GTM load balancer. Before we delve into the details of the DNS structure and the DNS hierarchy, let’s start with the basics of DNS hierarchy with DNS records and formats.
**DNS Records and Formats**
When you browse a webpage like network-insight.com, the computer needs to convert the domain name into an IP address. DNS is the protocol that accomplishes this. DNS involves queries and answers. You will make a query to resolve a web address. In response, your DNS server, typically the Active Directory server in an enterprise environment, will respond with an answer called a resource record. There are many types of DNS records and formats.
DNS happens in the background. By simply browsing www.network-insight.com, you will initiate a DNS query to resolve the IP. For example, the “A” query requests an IPv4 address for www.network-insight.com. This is the most common form of DNS request.
**DNS Hierarchy**
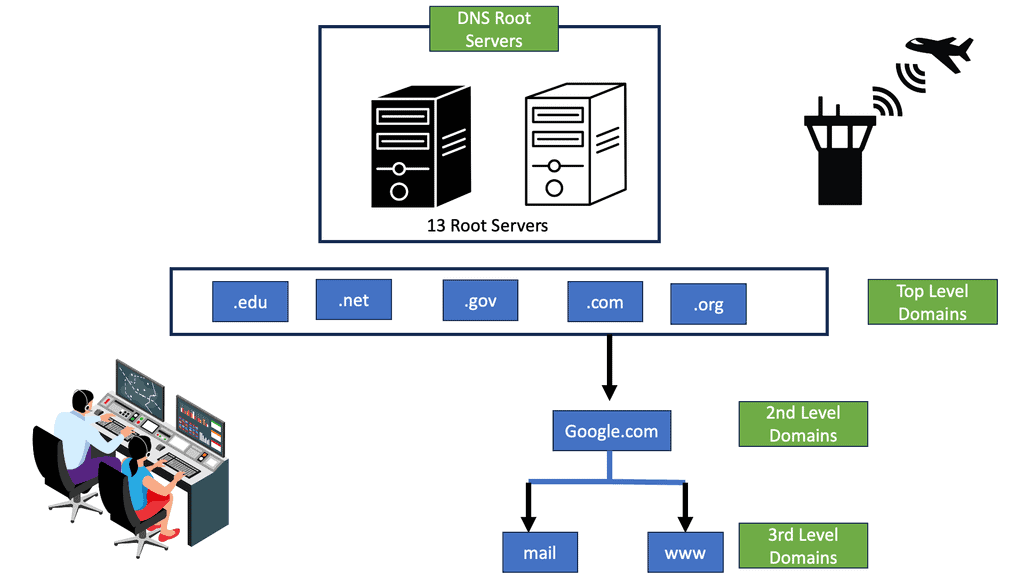
– Considering the DNS and DNS tree structures, we have a hierarchy to manage its distributed database system. So, the DNS hierarchy, also called the domain name space, is an inverted tree structure, much like eDirectory. The DNS tree structure has a single domain at the top called the root domain.
– So, we have a decentralized system without any built-in security mechanism that, by default, runs over a UDP transport. Some of these called for the immediate need for DNS security solutions. Therefore, you need to keep in mind the security risks. The DNS tree structure is a large attack surface extensible and is open to many attacks, such as the DNS reflection attack.
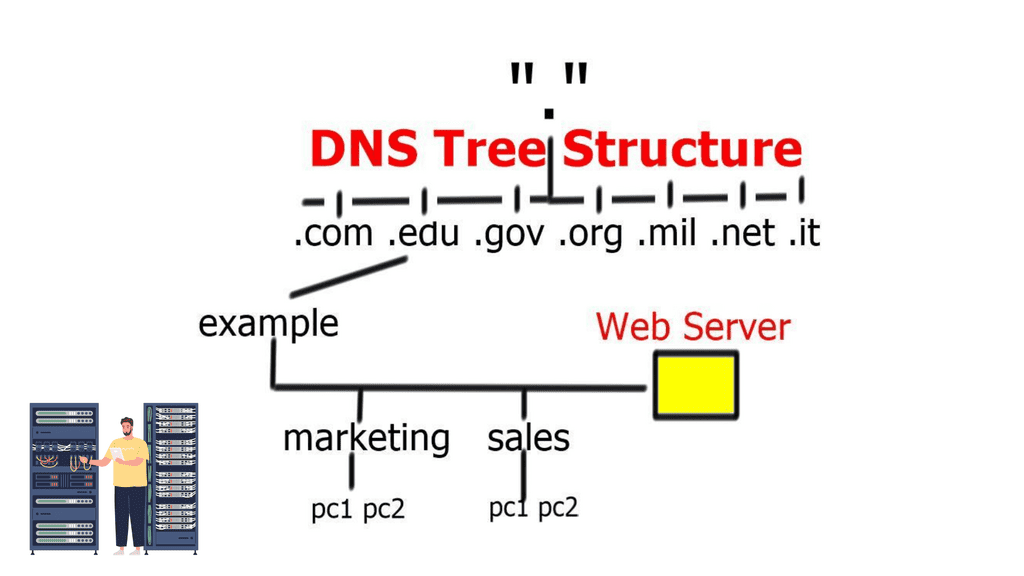
DNS Tree Structure
The structure of the DNS is hierarchical, consisting of five distinct components.
The root domain is at the apex of the domain name hierarchy. Above it are the top-level domains, further divided into second-level domains, third-level domains, and so on.
The top-level domains include generic domains, such as .com, .net, and .org, and country code top-level domains, such as .uk and .us. The second-level domains are typically used to identify an organization or business. For example, the domain name google.com consists of the second-level domain Google and the top-level domain .com.
Third-level domains identify a specific host or service associated with a domain name. For example, the domain name www.google.com consists of the third-level domain www, the second-level domain google, and the top-level domain .com.
The fourth-level domains provide additional information about a particular host or service on the Internet. An example of a fourth-level domain is mail.google.com, which is used to access Google’s Gmail service.
Finally, the fifth-level domains are typically used to identify a particular resource within a domain. An example of a fifth-level domain is docs.google.com, which is used to access Google’s online document storage service.
Key Technology: Network Scanning
Network scanning is the systematic process of identifying active hosts, open ports, and services running on a network. Security experts gain insights into the network’s infrastructure, potential weaknesses, and attack vectors by employing scanning tools and techniques.
Port Scanning: Port scanning involves probing a host for open ports, which serve as communication endpoints. Through port scanning, security professionals can identify accessible services, potential vulnerabilities, and the overall attack surface.
IP Scanning: IP scanning entails examining a range of IP addresses to identify active hosts within a network. By discovering live hosts, security teams can map the network’s layout, identify potential entry points, and prioritize security measures accordingly.
Related: Before you proceed, you may find the following posts of interest:
Most of us take Internet surfing for granted. However, much is happening to make this work for you. We must consider the technology behind our simple ability to type a domain universal resource locator, aka URL, in our browsers and arrive at the landing page. TheDNS structure is based on a DNS hierarchy, which makes reaching the landing page possible in seconds.
The DNS architecture consists of a hierarchical and decentralized name resolution system for resources connected to the Internet. It stores the associated information of the domain names assigned to each resource.
Thousands of DNS servers are distributed and hierarchical, but they need a complete database of all hostnames, domain names, and IP addresses. If a DNS server does not have information for a specific domain, it may have to ask other DNS servers for help. A total of 13 root name servers contain information for top-level domains such as com, net, org, biz, edu, or country-specific domains such as uk, nl, de, be, au, ca, etc.
That allows them to be reachable via the DNS resolution process. DNS queries for a resource pass through the DNS – with the URLs as parameters. Then, the DNS takes the URLs, translates them into the target IP addresses, and sends the queries to the correct resource.
Guide: DNS Process
Domain Name System
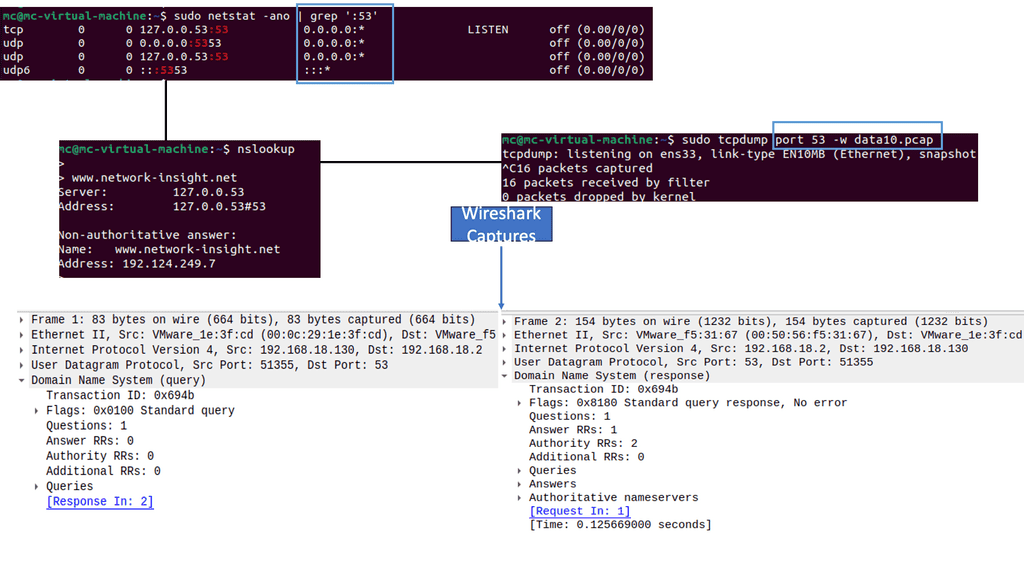
Now that you have an idea of DNS, let’s look at an example of a host that wants to find the IP address of a hostname. The host will send a DNS request and receive a DNS reply from the server. The following example shows I have a Cisco Router set up as a DNS server. I also have several public name servers configured with an external connector.
With Cisco Modelling Labs, getting external access with NAT is relatively easy. Set your connecting interface to DHCP, and the external connecter does the rest.
Note:
In the example below, the host will now send a DNS request to find the IP address of bbc.co.uk. Notice the packet capture output. Below, you can see that the DNS query uses UDP port 53. The host wants to know the IP address for bbc.co.uk. Here’s what the DNS server returns:
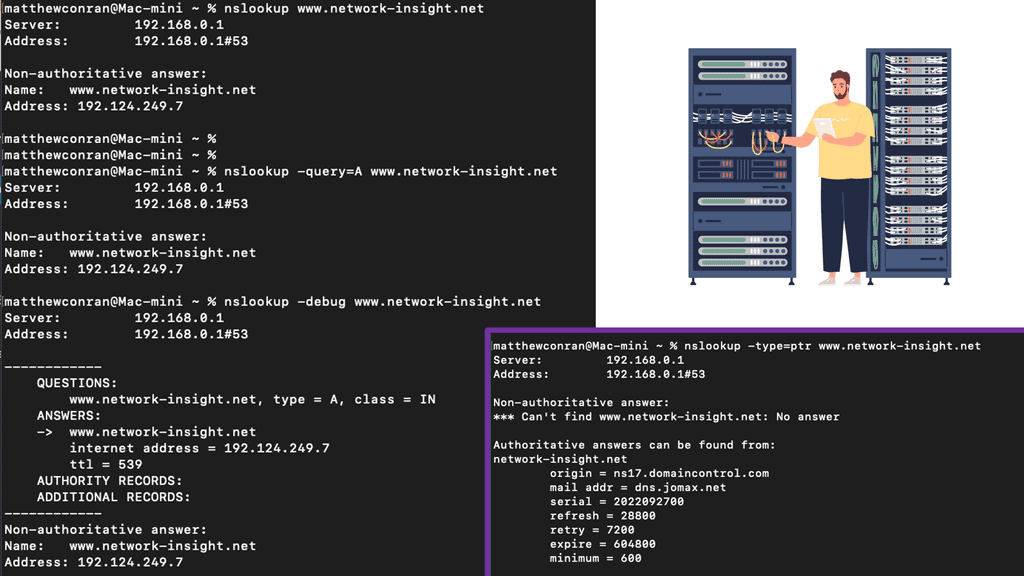
An administrator can query DNS name servers using TCP/IP utilities called nslookup, host, and dig. These utilities can be used for many purposes, including manually determining a host’s IP address, checking DNS resource records, and verifying name resolution.
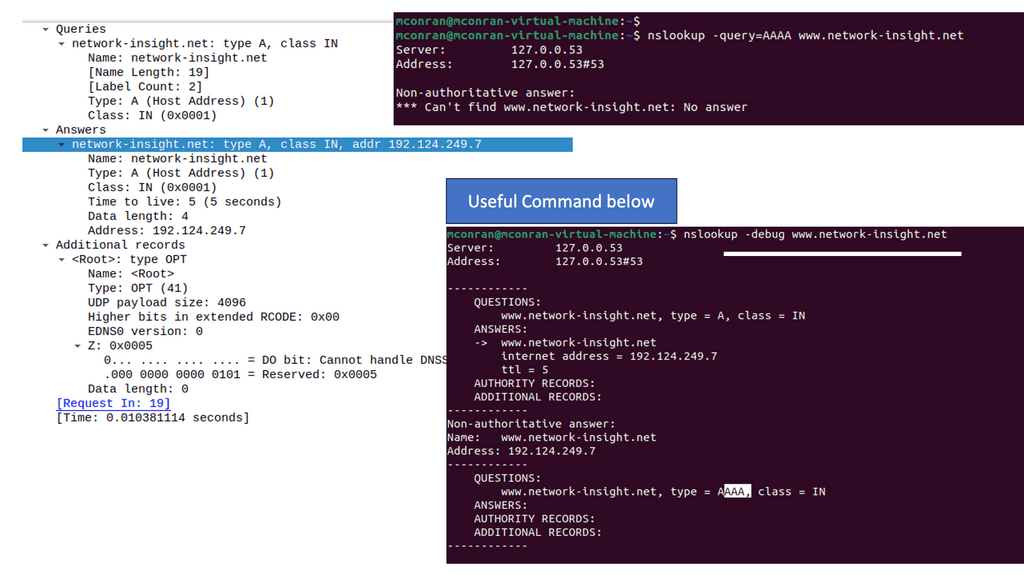
One of Dig’s primary uses is retrieving DNS records. By querying a specific domain, Dig can provide information such as the IP address associated with the domain, mail server details, and even the DNS records’ time-to-live (TTL) value. We will explore the types of DNS records that can be queried using Dig, including A, AAAA, MX, and NS records.
Advanced Dig Techniques
Dig goes beyond simple DNS queries. It offers advanced techniques to extract more detailed information. We will uncover how to perform reverse DNS lookups, trace the DNS delegation path, and gather information about DNSSEC (Domain Name System Security Extensions). These advanced techniques can be invaluable for network administrators and security professionals.
Using Dig for Troubleshooting
Dig is a powerful troubleshooting tool that can help diagnose and resolve network-related issues. We will cover common scenarios where Dig can rescue, such as identifying DNS resolution problems, checking DNS propagation, and verifying DNSSEC signatures.
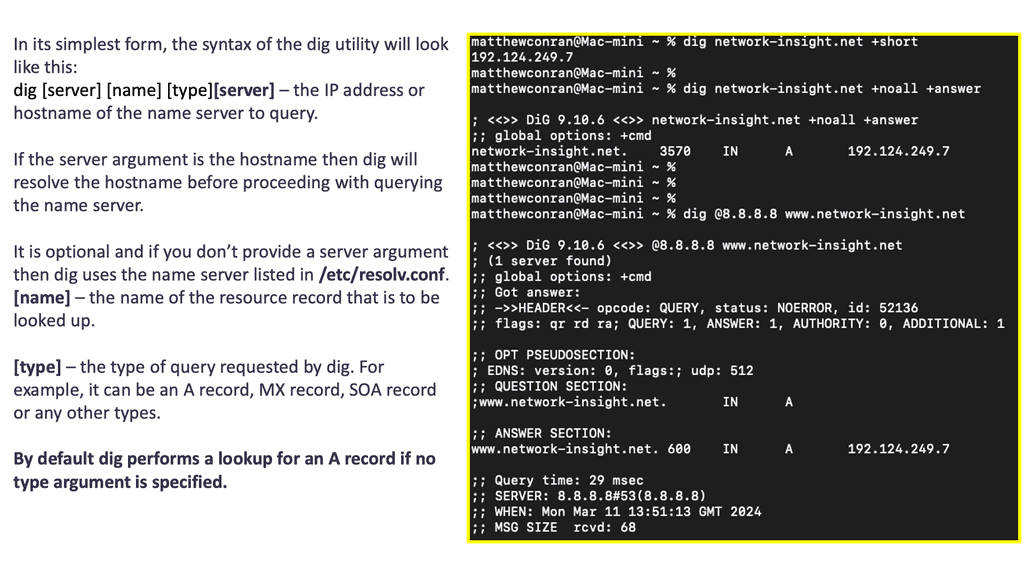
Understanding the Basic Syntax
Dig command follows a straightforward syntax: `dig [options] [domain] [type]`. Let’s break it down:
Options: Dig offers a range of options to customize your query. For example, the “+short” option provides only concise output, while the “+trace” option traces the DNS delegation path.
Domain: Specify the domain name you want to query. It can be a fully qualified domain name (FQDN) or an IP address.
Type: The type parameter defines the type of DNS record to retrieve. It can be A, AAAA, MX, NS, and more.
Exploring Advanced Functionality
Dig offers more advanced features that can enhance your troubleshooting and analysis capabilities.
Querying Specific DNS Servers: The “@server” option lets you query a specific DNS server directly. This can be useful for testing DNS configurations or diagnosing issues with a particular server.
Reverse DNS Lookup: Dig can perform reverse DNS lookups using the “-x” option followed by the IP address. This lets you obtain the domain name associated with a given IP address.
Analyzing DNSSEC Information
DNSSEC (Domain Name System Security Extensions) provides a layer of security to DNS. Dig can assist in retrieving and verifying DNSSEC-related information.
Checking DNSSEC Validation: The “+dnssec” option enables DNSSEC validation. Dig will fetch the DNSSEC signatures for the queried domain, allowing you to ensure the integrity and authenticity of the DNS responses.
Troubleshooting DNS Issues
Dig proves to be a valuable tool for troubleshooting DNS-related problems.
Checking DNS Resolution: By omitting the “type” parameter, Dig retrieves the default A record for the specified domain. This can help identify if the DNS resolution is functioning correctly.
Analyzing Response Times: Dig provides valuable information about response times, including the time DNS servers take to respond to queries. This can aid in identifying latency or performance issues.
DNS Architecture
DNS is a hierarchical system, with the root at the top and various levels of domains, subdomains, and records below. The Internet root server manages top-level domains such as .com, .net, and .org at the root level. These top-level domains are responsible for managing their subdomains and records.
Below the top-level domains are the authoritative nameservers, which are responsible for managing the records of the domains they are responsible for. These authoritative nameservers are the source of truth for the DNS records and are responsible for responding to DNS queries from clients.
At the DNS record level, there are various types of records, such as A (address) records, MX (mail exchange) records, and CNAME (canonical name) records. Each record type serves a different purpose and provides information about the domain or subdomain.
Name servers are the backbone of the DNS structure. They store and distribute DNS records, including IP addresses associated with domain names. When a user enters a domain name in their web browser, the browser queries the nearest name server to retrieve the corresponding IP address. Name servers are distributed globally, ensuring efficient and reliable DNS resolution.
Primary name servers, also known as master servers, are responsible for storing the original zone data for a domain. Secondary name servers, or slave servers, obtain zone data from primary servers and act as backups, ensuring redundancy and improved performance. Additionally, caching name servers, often operated by internet service providers (ISPs), store recently resolved domain information, reducing the need for repetitive queries.
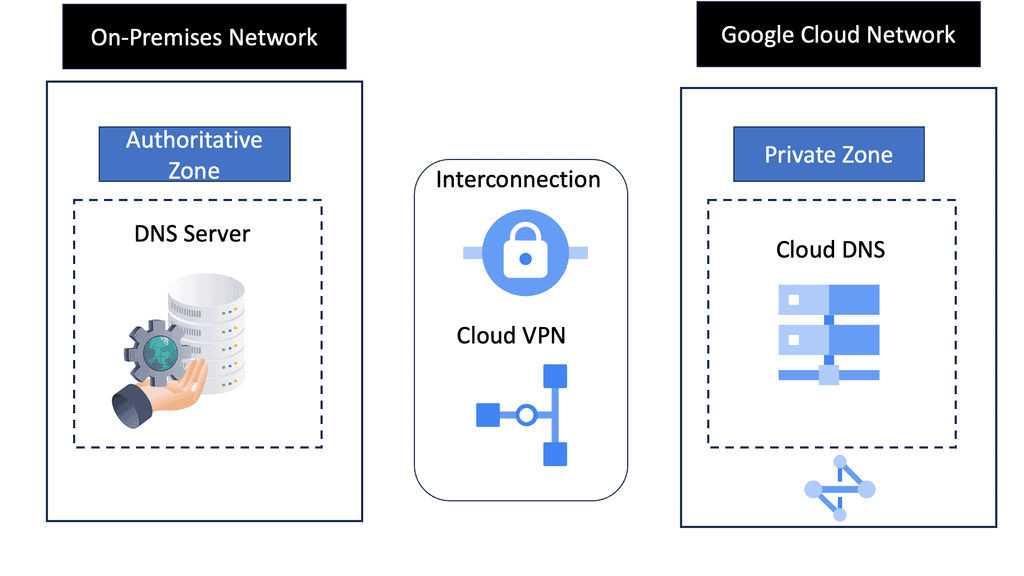
DNS Zones:
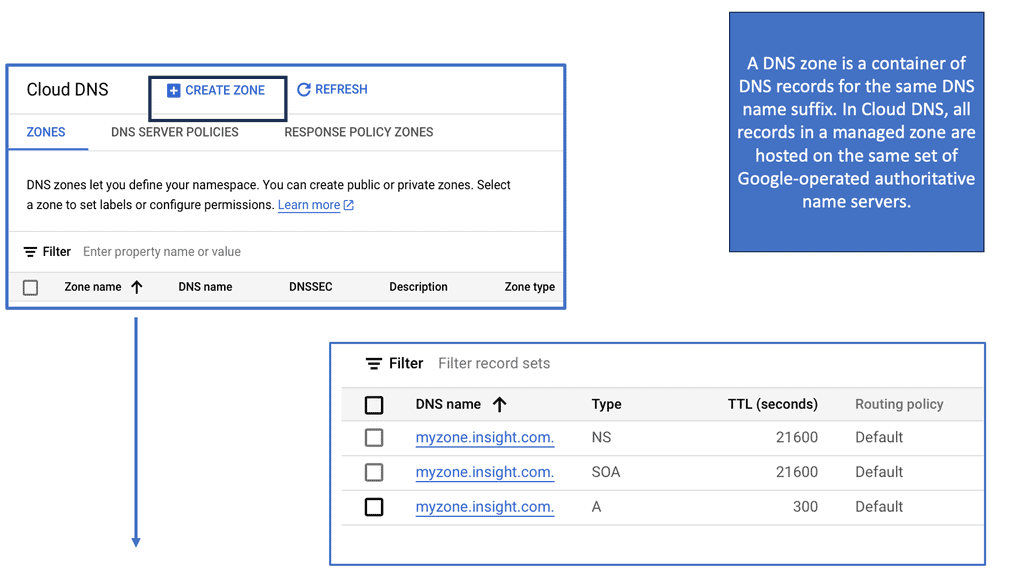
A DNS zone refers to a specific portion of the DNS namespace managed by an authoritative name server. Zones allow administrators to control and maintain DNS records for a particular domain or subdomain. Each zone consists of resource records (RRs) that hold various types of information, such as A records (IP addresses), MX records (mail servers), CNAME records (aliases), and more.
Google Cloud DNS
**Understanding DNS Zones: The Building Blocks of Google Cloud DNS**
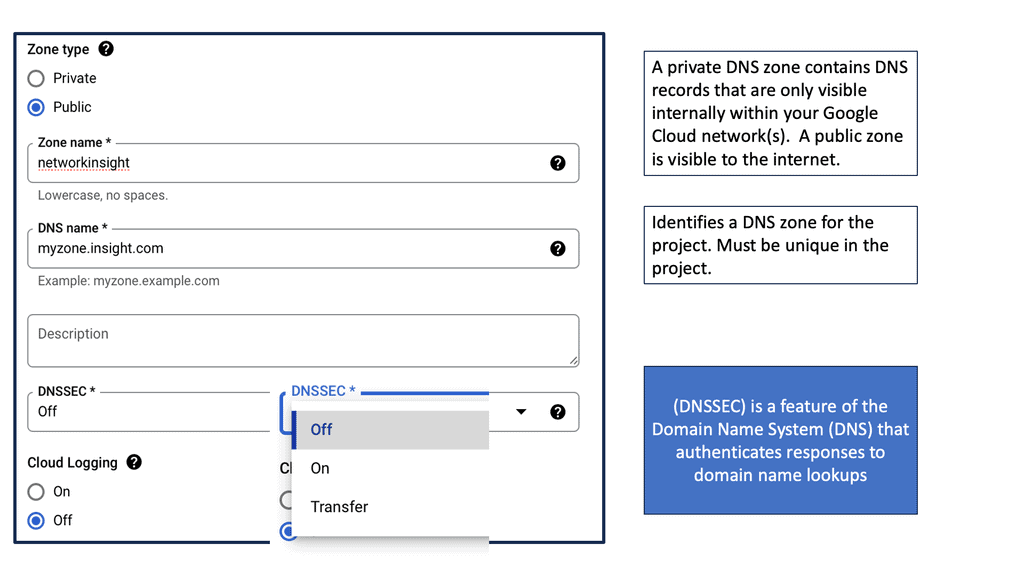
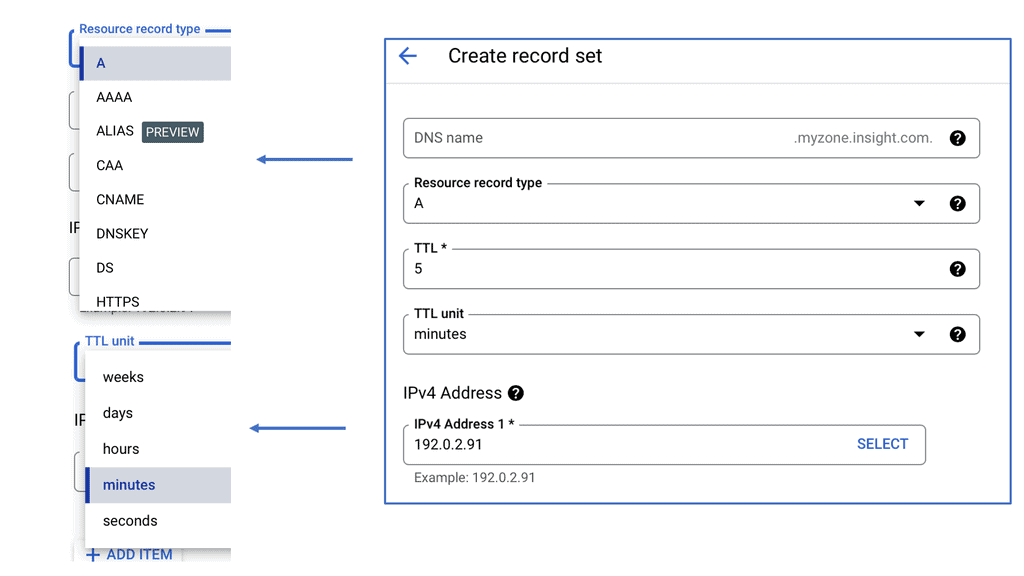
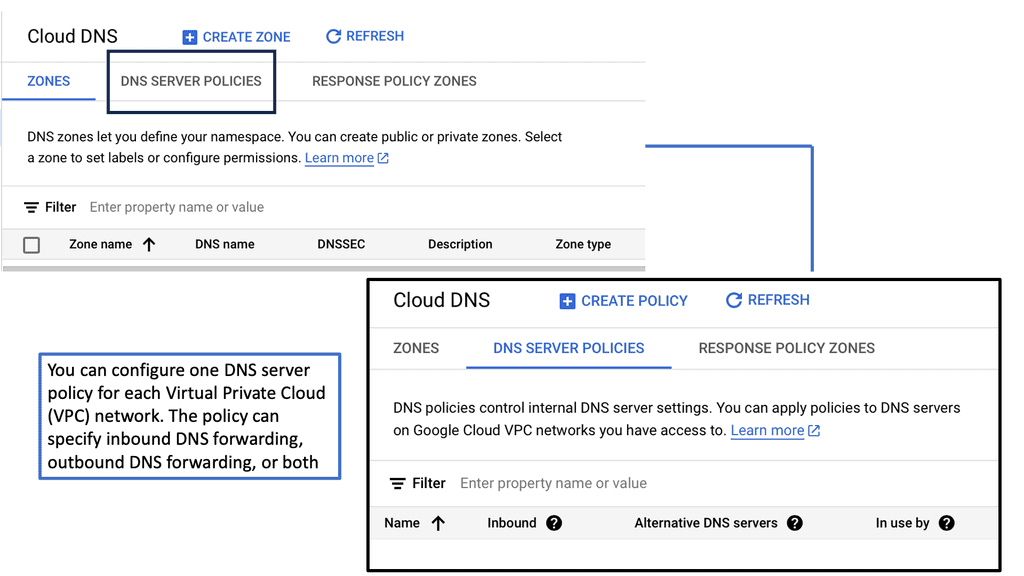
At the heart of Google Cloud DNS are DNS zones. A zone represents a distinct portion of the DNS namespace within the Google Cloud DNS service. There are two types of zones: public and private. Public zones are accessible over the internet, while private zones are accessible only within a specific Virtual Private Cloud (VPC) network. Understanding these zones is critical as they determine how your domain names are resolved, affecting how users access your services.
**Creating and Managing Zones: Your Blueprint to Success**
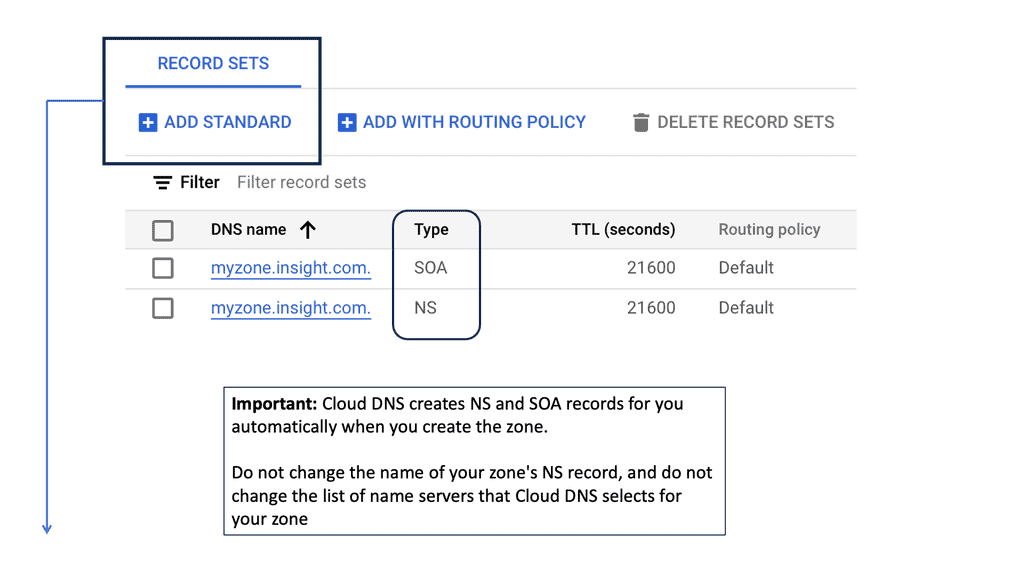
Creating a DNS zone in Google Cloud is a straightforward process. Begin by accessing the Google Cloud Console, navigate to the Cloud DNS section, and click on “Create Zone.” Here, you’ll need to specify a name, DNS name, and whether it’s a public or private zone. Once created, managing zones involves adding, editing, or deleting DNS records, which dictate the behavior of your domain and subdomains. This flexibility allows for precise control over your domain’s DNS settings, ensuring optimal performance and reliability.
**Integrating Zones with Other Google Cloud Services**
One of the standout features of Google Cloud DNS is its seamless integration with other Google Cloud services. For instance, when using Google Kubernetes Engine (GKE), you can automatically create DNS records for services within your clusters. Similarly, integrating with Cloud Load Balancing allows for automatic updates to DNS records, ensuring your applications remain highly available and responsive. These integrations exemplify the power and versatility of managing zones within Google Cloud DNS, enhancing your infrastructure’s scalability and efficiency.
**DNS Resolution Process**
When a user requests a domain name, the DNS resolution occurs behind the scenes. The resolver, usually provided by the Internet Service Provider (ISP), starts by checking its cache for the requested domain’s IP address. If the information is not cached or has expired, the resolver sends a query to the root name servers. The root name servers respond by directing the resolver to the appropriate TLD name servers. Finally, the resolver queries the authoritative name server for the specific domain and receives the IP address.
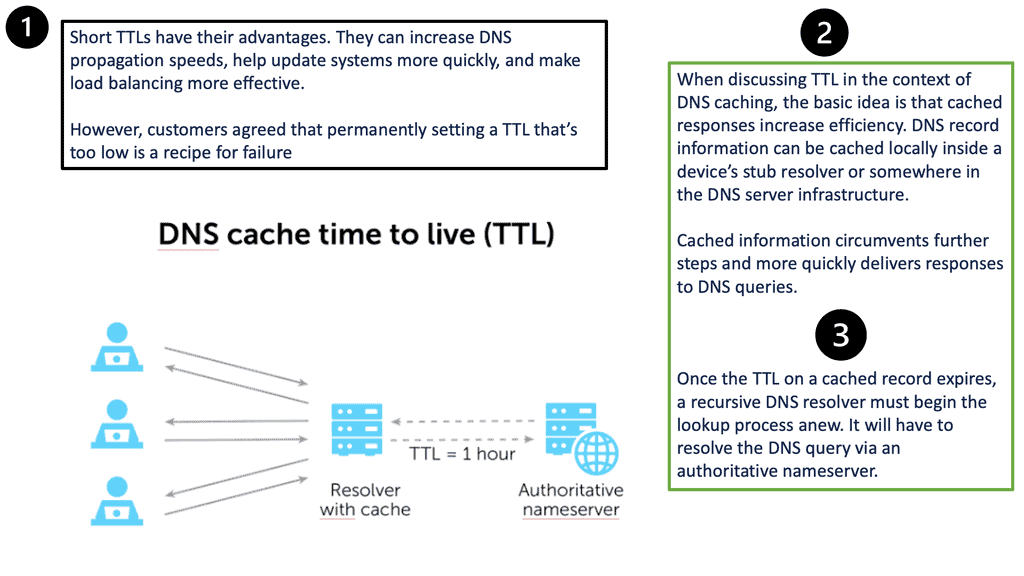
DNS Caching:
Caching is implemented at various levels to optimize the DNS resolution process and reduce the load on name servers. Caching allows resolvers to store DNS records temporarily, speeding up subsequent requests for the same domain. However, caching introduces the challenge of ensuring timely updates to DNS records when changes occur, as outdated information may persist until the cache expires.
DNS Traffic Flow:
First, two concepts are essential to understand. Every client within an enterprise network won’t be making external DNS queries. Instead, they make requests to the local DNS server or DNS resolver, which makes the external queries on their behalf. The communication chain for DNS resolve can involve up to three other DNS servers to fully resolve any hostname. The other concept to consider is caching. Before a client requests a DNS server, it will check the local browser and system cache.
DNS records are cached in three locations
In general, DNS records are cached in three locations, and keeping these locations secured is essential. First is the browser cache, which is usually stored for a very short period. If you’ve ever had a problem with a website fixed by closing and reopening or browsing with an incognito tab, the root issue probably had something to do with the page being cached. Next is the operating system cache. It doesn’t make sense for a server to make hundreds of requests when multiple users visit the same page, so this efficiency is beneficial. However, it still presents a security risk.
Role of UDP and DNS:
Regarding DNS, UDP is crucial in facilitating fast and lightweight communication. Unlike TCP (Transmission Control Protocol), which guarantees reliability but adds additional overhead, UDP operates in a connectionless manner. This means that UDP packets can be sent without establishing a formal connection, making it ideal for time-sensitive applications like DNS. UDP’s simplicity enables faster communication, eliminating the need for acknowledgments and other mechanisms present in TCP.
**The DNS Query Process**
Let’s explore the typical DNS query process to understand how DNS and UDP work together. When a user enters a domain name in their browser, the DNS resolver initiates a query to find the corresponding IP address. The resolver sends a DNS query packet, typically UDP, to the configured DNS server. The server then processes the query, searching its database for the requested information. Once found, the server sends a DNS response packet back to the resolver, enabling the user’s browser to establish a connection with the website.
**Ensuring Reliability in DNS with UDP**
While UDP’s connectionless nature provides speed advantages, it also introduces challenges in terms of reliability. Since UDP does not guarantee packet delivery or order, there is a risk of lost or corrupted packets during transmission. DNS implements various mechanisms to address this, such as retrying queries, caching responses, and even falling back to TCP when necessary. These measures ensure that DNS remains a reliable and robust system despite utilizing UDP as its underlying protocol.
Introducing DNS TCP
TCP, or Transmission Control Protocol, is another DNS protocol employed for specific scenarios. Unlike UDP, TCP provides reliable, connection-oriented communication. It ensures that all data packets are received in the correct order, making it suitable for scenarios where accuracy and reliability are paramount.
Use Cases for DNS TCP
While DNS UDP is the default choice for most DNS queries and responses, DNS TCP comes into play in specific situations. Large DNS responses that exceed the maximum UDP packet size can be transmitted using TCP. Additionally, DNS zone transfers, which involve the replication of DNS data between servers, rely on TCP due to its reliability.
In conclusion, DNS relies on UDP and TCP protocols to cater to various scenarios and requirements. UDP offers speed and efficiency, making it ideal for most DNS queries and responses. On the other hand, TCP ensures reliability and accuracy, making it suitable for large data transfers and zone transfers.
Guide: Delving into DNS data
DNS Capture
In the lab guide, we will delve more into DNS data. Before digging into the data, it’s essential to understand some general concepts of DNS:
To browse a webpage (www.network-insight.net), the computer must convert the web address to an IP address. DNS is the protocol that accomplishes this
DNS involves queries and answers. You will make a query to resolve a web address. In response, your DNS Server (typically the Active Directory Server for an enterprise environment) will respond with an answer called a resource record. There are many types of DNS records. Notice below in the Wireshark capture, I am filtering only for DNS traffic.
In this section, you will generate some sample DNS traffic. By simply browsing www.network-insight.net, you will initiate a DNS query to resolve the IP. I have an Ubuntu host running on a VM. Notice that your first query is an “A” query, requesting an IPv4 address for www.network-insight.net. This is the most common form of DNS request.
As part of your web request, this automatically initiated two DNS queries. The second (shown here) is an “AAAA” query requesting an IPv6 address.
Note: In most instances, the “A” record response will be returned first; however, in some cases, you will see the “AAAA” response first. In either instance, these should be the 3rd and 4th packets.
Analysis:
The IP header contains IPv4 information. This is the communication between the host making the request (192.168.18.130) and the DNS Server (192.168.18.2). Typical DNS operates over UDP, but sometimes it works over TCP. DNS over UDP can open up some security concerns.
This means there’s no error checking or tracking in the network communication. Because of this, the DNS server will return a copy of the original query in the response to ensure they stay matched up.
Next are two A records containing the IPv4 answers. It’s pervasive for popular domains to have multiple IPs for load-balancing purposes.
Nslookup stands for “name server lookup.” It is a command-line tool for querying the Domain Name System (DNS) and obtaining information about domain names, IP addresses, and other DNS records. Nslookup is available on most operating systems and provides a simple yet powerful way to investigate DNS-related issues.
Nslookup offers a range of commands that allow users to interact with DNS servers and retrieve specific information. Some of the most commonly used commands include querying for IP addresses, performing reverse lookups, checking DNS records, and troubleshooting DNS configuration problems.
Use the -query option to request only an ‘A’ record: nslookup -query=A www.network-insight.net
Use the -debug option to display the full response information: nslookup -debug www.network-insight.net: This provides a much more detailed response, including the Time-to-Live (TTL) values and any additional record information returned.
You can also perform a reverse DNS lookup by sending a Pointer Record (PTR) and the IP address: nslookup -type=ptr xx.xx.xx.xx
Analysis:
The result is localhost, despite us knowing that the IP given belongs to www.network-insight.net. This is a security strategy to bypass source address checks and prevent individuals from performing PTR lookups for some domains.
DNS Scalability and Redundancy
Scalability refers to the ability of a system to handle increasing amounts of traffic and data without compromising performance. In the context of DNS, scalability is crucial to ensure that the system can efficiently handle the ever-growing number of domain name resolutions. Various techniques, such as load balancing, caching, and distributed architecture, are employed to achieve scalability.
Load Balancing for Scalability
Load balancing is vital in distributing incoming DNS queries across multiple servers. By evenly distributing the workload, load balancers prevent any server from overloading, ensuring optimal performance. Techniques like round-robin or dynamic load-balancing algorithms help achieve scalability by efficiently managing traffic.
Caching for Improved Performance
Caching is another crucial aspect of DNS scalability. By storing recently resolved domain names and their corresponding IP addresses, caching servers can respond to queries without the need for recursive lookups, significantly reducing response times. Implementing caching effectively reduces the load on authoritative DNS servers, improving overall scalability.
Achieving Redundancy with DNS
Redundancy is vital to ensure high availability and fault tolerance in DNS. It involves duplicating critical components of the DNS infrastructure to eliminate single points of failure. Redundancy can be achieved by implementing multiple authoritative DNS servers, using secondary DNS servers, and employing DNS anycast.
Secondary DNS Servers
Secondary DNS servers act as backups to primary authoritative servers. They replicate zone data from the primary server, allowing them to respond to queries if the primary server becomes unavailable. By distributing the workload and ensuring redundancy, secondary DNS servers enhance the scalability and reliability of the DNS system.
DNS Anycast for Improved Resilience
DNS anycast is a technique that allows multiple servers to advertise the same IP address. When a DNS query is received, the network routes it to the nearest anycast server, improving response times and redundancy. This distributed approach ensures that even if some anycast servers fail, the overall DNS service remains operational.
Knowledge Check: Authoritative Name Server
Understanding the Basics
Before we dive deeper, let’s start with the fundamentals. An authoritative name server is responsible for providing the official DNS records of a domain name. When a user types a website address into their browser, the browser sends a DNS query to the authoritative name server to retrieve the corresponding IP address. These servers hold the authoritative information for specific domain names, making them an essential component of the DNS hierarchy.
The Functioning of Authoritative Name Servers
Now that we have a basic understanding, let’s explore how authoritative name servers function. When a domain is registered, the registrar collects the necessary information and updates the top-level domain’s (TLD) authoritative name servers with the domain’s DNS records. These authoritative name servers act as the primary source of information for the domain, serving as the go-to reference for any DNS queries related to that domain.
Caching and Zone Transfers
Caching plays a crucial role in the efficient operation of authoritative name servers. Caching allows these servers to store previously resolved DNS queries, reducing the overall response time for subsequent queries. Additionally, authoritative name servers employ zone transfers to synchronize DNS records with secondary name servers. This redundancy ensures reliability and fault tolerance in case of primary server failures.
Load Distribution and Load Balancing
In the modern landscape of high-traffic websites, load distribution and load balancing are vital considerations. Authoritative name servers can employ various techniques to distribute the load evenly across multiple servers, such as round-robin DNS or geographic load balancing. These strategies help maintain optimal performance and prevent overwhelming any single server with excessive requests.
Domain Name System Fundamentals
DNS Tree
The domain name system (DNS) is a naming database in which Internet domain names are located and translated into Internet Protocol (IP) addresses. It uses a hierarchy to manage its distributed database system. The DNS hierarchy, also called the domain name space, consists of a DNS tree with a single domain at the top of the structure called the root domain.
Consider DNS a naming system that is both hierarchical and distributed. Because of the hierarchical structure, you can assign the same “label” to multiple machines (for example, www.abc.com maps to 10.10.10.10 and 10.10.10.20).
Diagram: DNS structure
Domain Name System and its Operations
DNS servers are machines that respond to DNS queries sent by clients. Servers can translate names and IP addresses. There are differences between an authoritative DNS server and a caching server. A caching-only server is a name server with no zone files. It is not authoritative for any domain.
Caching speeds up the name-resolution process. This server can help improve a network’s performance by reducing the time it takes to resolve a hostname to its IP address. This can minimize web browsing latency, as the DNS server can quickly resolve the hostname and connect you to the website. A DNS caching server can also reduce the network’s data traffic, as DNS queries are sent only once, and the cached results are used for subsequent requests.
It can be viewed as a positive and negative element of DNS. Caching reduces the delay and number of DNS packets transmitted. On the negative side, it can produce stale records, resulting in applications connecting to invalid IP addresses and increasing the time applications failover to secondary services.
Ensuring that the DNS caching server is configured correctly is essential, as it can cause issues if the settings are incorrect. Additionally, it is crucial to ensure that the server is secure and not vulnerable to malicious attacks.
The Time-to-Live (TTL) fields play an essential role in DNS. It controls how long a record should be stored in the cache. Choosing the suitable TTL timer per application is an important task. A short TTL can send too many queries, while a long TTL can’t capture any changes in the records.
DNS proxies and DNS resolvers respect the TTL setting for the form and usually honor TTL values as they should be. However, applications do not necessarily keep the TTL, which becomes problematic with failover events.
DNS Main Components
Main DNS Components
DNS Structure and DNS Hierarchy
The DNS structure follows a hierarchical system, resembling an upside-down tree.
We have a decentralized system without any built-in security mechanism.
There are various types of records at the DNS record level, such as A (address) records.
Name servers are the backbone of the DNS structure. They store and distribute DNS records.
Caching speeds up the name-resolution process. It can be viewed as a positive and negative element of DNS.
Site-selection considerations: Load balance data centers?
DNS is used to perform site selection. Multi-data centers use different IP endpoints in each data center, and DNS-based load balancing is used to send clients to one of the data centers. The design is to start using random DNS responses and slowly migrate to geo-location-based DNS load balancing. There are many load-balancing strategies, and different methods match different requirements.
Google Cloud DNS Routing Policy
Google Cloud DNS
DNS routing policies steer traffic based on query (for example, round robin or geolocation). You can configure routing policies by creating special ResourceRecordSets (in the collection sense) with particular routing policy values.
We will examine Cloud DNS routing policies in this lab. Users can configure DNS-based traffic steering using cloud DNS routing policies. Routing policies can be divided into two types.
Note:
There are two types of routing policies: Weighted Round Robin (WRR) and Geolocation (GEO). Creating ResourceRecordSets with particular routing policy values can be used to configure routing policies.
When resolving domain names, use WRR to specify different weights per ResourceRecordSet. By resolving DNS requests according to the configured weights, cloud DNS routing policies ensure traffic is distributed across multiple IP addresses.
I have configured the Geolocation routing policy in this lab. Provide DNS answers corresponding to source geo locations using GEO. The geolocation routing policy applies to the nearest match if the traffic source location does not match any policy items exactly.
Here, we have a Cloud DNS routing policy, create ResourceRecordSets for geo.example.com, and configure the Geolocation policy to help ensure a client request is routed to a server in the client’s closest region.
Above, we have three client VMs in the same default VPC but in different regions. There is a Europe, USA, and Asia region. There is a web server in the European region and one in the USA region. There is no web server in Asia.
I have created a firewall to allow access to the VMs. I have permitted SSH to the client VM for testing and HTTP for the webservers to accept CURL commands when we try the geolocation.
Analysis:
It’s time to test the configuration; I SSH into all the client VMs. Since all of the web server VMs are behind the geo.example.com domain, you will use cURL command to access this endpoint.
Since you are using a Geolocation policy, the expected result is that:
Clients in the US should always get a response from the US-East1 region.
The client in Europe should always get a response from the Europe-West2 region.
Since the TTL on the DNS record is set to 5 seconds, a sleep timer of 6 seconds has been added. The sleep timer will ensure you get an uncached DNS response for each cURL request. This command will take approximately one minute to complete.
When we run this test multiple times and analyze the output to see which server is responding to the request, the client should always receive a response from a server in the client’s region.
**The Power of DNS Security**
DNS Security is a critical component of cloud security, and the Security Command Center excels in this area. DNS, or Domain Name System, is like the internet’s phone book, translating domain names into IP addresses. Unfortunately, it is also a common target for cyber attacks. SCC’s DNS Security features help identify and mitigate threats like DNS spoofing and cache poisoning. By continuously monitoring DNS traffic, SCC alerts users to suspicious activities, ensuring that your cloud infrastructure remains secure from DNS-based attacks.
**Maximizing Visibility with Google Cloud’s SCC**
One of the standout features of the Security Command Center is its ability to provide a unified view of security across all Google Cloud assets. With SCC, users can effortlessly track security metrics, detect vulnerabilities, and receive real-time alerts about potential threats. This centralized visibility means that security teams can respond swiftly to incidents, minimizing potential damage. Additionally, SCC’s integration with other Google Cloud services ensures a seamless security experience.
**Leveraging SCC for Threat Detection and Response**
Threat detection and response are crucial elements of any robust security strategy. The Security Command Center enhances these capabilities by employing advanced analytics and machine learning to identify and respond to threats. By analyzing patterns and anomalies in cloud activities, SCC can predict potential security incidents and provide actionable insights. This proactive approach not only protects your cloud environment but also empowers your security team to stay ahead of evolving threats.
Knowledge Check: DNS-based load balancing
DNS-based load balancing is an approach to distributing traffic across multiple hosts by using DNS to map requests to the appropriate host. It is a cost-effective way of scaling and balancing a web application or website load across multiple servers.
With DNS-based load balancing, each request is routed to the appropriate server based on DNS resolution. The DNS server is configured to provide multiple responses pointing to different servers hosting the same service.
The client then chooses one of the responses and sends its request to that server. The subsequent requests from the same client are sent to the same server unless the server becomes unavailable; in this case, the client will receive a different response from the DNS server and send its request to a different server.
DNS: Asynchronous Process
This approach has many advantages, such as improved reliability, scalability, and performance. It also allows for faster failover if one of the servers is down since the DNS server can quickly redirect clients to another server. Additionally, since DNS resolution is an asynchronous process, clients can receive near real-time responses and updates as servers are added or removed from the system.
Diagram: DNS requests
Route Health Injection (RHI)
Try to combine the site selector ( the device that monitors the data centers) with routing, such as Route Health Injection ( RHI ), to overcome the limitation of cached DNS entries. DNS is used outside of performing load distribution among data centers, and Interior Gateway Protocol (IGP) is used to reroute internal traffic to the data center.
Avoid false positives by tuning the site selector accordingly. DNS is not always the best way to fail the data center. DNS failover can quickly influence 90 % of incoming data center traffic within the first few minutes.
If you want 100% of traffic, you will probably need additional routing tricks and advertising the IP of the secondary data center with conditional route advertisements or some other form of route injection.
Diagram: Load balancing
Zone File Presentation
The application has changed, and the domain name system and DNS structure must be more intelligent. Users look up an “A” record for www.XYX.com, and there are two answers. When you have more than one answer, you have to think more about zone file presentation, what you offer, and based on what criteria/metrics.
Previously, the DNS structure was a viable solution with BIND. You had a primary/secondary server redundancy model with an exceedingly static configuration. People weren’t building applications with distributed data center requirements. Application requirements started to change in early 2000 with anycast DNS. DNS with anycast became more reliable and offered faster failover. Nowadays, performance is more of an issue. How quickly can you spit out an answer?
Ten years ago, to have the same application in two geographically dispersed data centers was a big deal. Now, you can spin up active-active applications in dispersed MS Azure and Amazon locations in seconds. Tapping new markets in different geographic areas takes seconds. The barriers to deploying applications in multi-data centers have changed, and we can now deploy multiple environments quickly.
Geographic routing and smarter routing decisions
Geographic routing is where you try to figure out where a user is coming from based on the Geo IP database. From this information, you can direct requests to the closest data center. Unfortunately, this doesn’t always work, and you may experience performance problems.
To make intelligent decisions, you need to take in all kinds of network telemetry about customers’ infrastructure and what is happening on the Internet now. Then, they can make more intelligent routing decisions. For this, you can analyze information about the end-user application to get an idea about what’s going on – where are you / how fast are your pipes, and what speed do you have?
The more they know, the more granular routing decisions are made. For example, are your servers overloaded, and at what point of saturation are your Internet or WAN pipes? They get this information using an API-driven approach, not dropping agents on servers.
Geographical location – Solution
The first problem with geographical location is network performance. Geographical location is not relevant to how close things are. Second, you are looking at resolving the DNS server, not the client. You receive the IP address of the DNS resolver, not the end client’s IP address. Also, the user sometimes uses a DNS server that is not located where they are.
The first solution is an extension to DNS protocol – “EDNS client subnets.” This gets the DNS server to forward end-user information, including IP addresses. Google and OpenDNS will deliver the first three octets of the IP address, attempting to provide geographic routing based on the IP address of the actual end-user and not the DNS Resolver. To optimize response times or minimize packet loss, you should measure the metrics you are trying to optimize and then make a routing decision. Capture all information and then turn it into routing data.
Trying to send users to the “BEST” server varies from application to application. The word “best” really depends on the application. Some application performance depends heavily on response times. For example, streaming companies don’t care about RTT returning the first MPEG file. It depends on the application and what route you want.
DNS pinning is a technique to ensure that the IP address associated with a domain name remains consistent. It involves creating an association between a domain name and the IP address of the domain’s authoritative nameserver. This association is a DNS record and is stored in a DNS database.
When DNS pinning is enabled, an organization can ensure that the IP address associated with a domain name remains the same. This is beneficial in several ways. First, it helps ensure that users are directed to the correct server when accessing a domain name. Second, it helps prevent malicious actors from hijacking a domain name and redirecting traffic to a malicious server.
DNS Spoofing
So, the main reason for DNS pinning in browsers is enabled due to security problems with DNS spoofing. Browsers that don’t honor the TTL get stuck with the same IP for up to 15 minutes. Applications should always keep the TTL for reasons mentioned at the start of the post—no notion of session stickiness with DNS. DNS has no sessions, but you can have consistent routing hashing; the same clients go to the same data center.
Route hashing optimizes cache locality. It’s like stickiness for DNS and is used for data cache locality. However, most users use the same data center based on “source IP address” or other “EDNS client subnet” information.
Guide: Advanced DNS
DNS Advanced Configuration
Every client within a network won’t be making external DNS queries. Instead, they make requests to the local DNS Server or DNS Resolver, and it makes the external queries on their behalf. The communication chain for DNS Resolve can involve up to three other DNS servers to resolve any hostname fully. All of which need to be secured.
Note: The other concept to consider is caching. Before a client event requests the DNS Server, it will first check the local browser and system cache. DNS records are generally cached in three locations, and keeping these locations secured is essential.
First is the browser cache, which is usually stored for a very short period. If you’ve ever had a problem with a website fixed by closing/reopening or browsing with an incognito tab, the root issue probably had something to do with the page being cached.
Next is the Operating System (OS) cache. We will view this in the screenshot below.
Finally, we have the DNS Server’s cache. It doesn’t make sense for a Server to make hundreds of requests when multiple users visit the same page, so this efficiency is beneficial. However, it still presents a security risk.
Take a look at your endpoint’s DNS Server configuration. In most Unix-based systems, this is found in the resolv.conf file
Configuration options:
The resolv.conf file comprises various configuration options determining how the DNS resolver library operates. Let’s take a closer look at some of the essential options:
1. nameserver: This option specifies the IP address of the DNS server that the resolver should use for name resolution. Multiple nameserver lines can be included to provide backup DNS servers if the primary server is unavailable.
2. domain: This option sets the default domain for the resolver. When a domain name is entered without a fully qualified (FQDN), the resolver appends the domain option to complete the FQDN.
3. search: Similar to the domain option, the search option defines a list of domains that the resolver appends to incomplete domain names. This allows for easier access to resources without specifying the complete domain name.
4. options: The options option provides additional settings such as timeout values, the order in which the resolver queries DNS servers, and other resolver behaviors.
Analysis:
The nameserver is the IP address of the DNS server. In this case, 127.0.0.53 is listed because the “system-resolved” service is running. This service manages the DNS routing and local cache for this endpoint, which is typical for cloud-hosted endpoints. You can also have multiple nameservers listed here.
Options allow for certain modifications. In our example, edns0 allows for larger replies, and trust-ad is a configuration for DNSSEC and validating responses.
Now, look at your endpoint’s host file. This is a static mapping of domain names with IP addresses. Per the notice above, I have issued the command cat /etc/hosts. This file has not been modified and shows a typical configuration. If you were to send a request to localhost, an external DNS request is not necessary because a match already exists in the host’s file and will translate to 127.0.0.1.
The etc/hosts file, found in the root directory of Unix-based operating systems, is a simple text file that maps hostnames to IP addresses. It serves as a local DNS (Domain Name System) resolver, allowing the computer to bypass DNS lookup and directly associate IP addresses with specific domain names. Maintaining a record of these associations, the etc/hosts file expedites resolving domain names, improving network performance.
Finally, I modified the host’s file to redirect DNS to a fake IP address. This IP address does not exist. Notice that with the NSLookup command, DNS has been redirected to the fake IP.
**Final Points on DNS Tree Structure**
The DNS tree structure is a hierarchical organization of domain names, starting from the root domain and branching out into top-level domains (TLDs), second-level domains, and subdomains. It resembles an inverted tree, where each node represents a domain or subdomain, and the branches represent their relationship.
Components of the DNS Tree Structure:
a) Root Domain:
The root domain is at the top of the DNS tree structure, denoted by a single dot (.). It signifies the beginning of the hierarchy and is the starting point for all DNS resolutions.
b) Top-Level Domains (TLDs):
Below the root domain are the TLDs, such as .com, .org, .net, and country-specific TLDs like .uk or .de. Different organizations manage TLDs and are responsible for specific types of websites.
c) Second-Level Domains:
After the TLDs, we have second-level domains, the primary domains individuals or organizations register. Examples of second-level domains include google.com, apple.com, or microsoft.com.
d) Subdomains:
Subdomains are additional levels within a domain. They can be used to create distinct website sections or serve specific purposes. For instance, blog.google.com or support.microsoft.com are subdomains of their respective second-level domains.
A Distributed and Hierarchical database
The DNS system is distributed and hierarchical. Although there are thousands of DNS servers, none has a complete database of all hostnames/domain names / IP addresses. DNS servers can have information for specific domains, but they may have to query other DNS servers if they do not. Thirteen root name servers store information for generic top-level domains, such as com, net, org, biz, edu, or country-specific domains, such as UK, nl, de, be, au, ca.
13 root name servers at the top of the DNS hierarchy handle top-level domain extensions. For example, a name server for .com will have information on cisco.com, but it won’t know anything about cisco.org. It will have to query a name server responsible for the org domain extension to get an answer.
For the top-level domain extensions, you will find the second-level domains. Here’s where you can find domain names like Cisco, Microsoft, etc.
Further down the tree, you can find hostnames or subdomains. For example, tools.cisco.com is the hostname of the VPS (virtual private server) that runs this website. An example of a subdomain is tools.cisco.com, where vps.tools.cisco.com could be the hostname of a server in that subdomain.
How the DNS Tree Structure Works:
When a user enters a domain name in their web browser, the DNS resolver follows a specific sequence to resolve the domain to its corresponding IP address. Here’s a simplified explanation of the process:
– The DNS resolver starts at the root domain and queries the root name servers to identify the authoritative name servers for the specific TLD.
– The resolver then queries the TLD’s name server to find the authoritative name servers for the second-level domain.
– Finally, the resolver queries the authoritative name server of the second-level domain to obtain the IP address associated with the domain.
The DNS tree structure ensures the scalability and efficient functioning of the DNS. Organizing domains hierarchically allows for easy management and delegation of authority for different parts of the DNS. Moreover, it enables faster DNS resolutions by distributing the workload across multiple name servers.
The DNS structure serves as the backbone of the internet, enabling seamless and efficient communication between users and online resources. Understanding the hierarchical nature of domain names, the role of name servers, and the DNS resolution process empowers individuals and organizations to navigate the digital landscape easily. By grasping the underlying structure of DNS, we can appreciate its significance in enabling the interconnectedness of the modern world.
Summary: DNS Structure
In today’s interconnected digital world, the Domain Name System (DNS) plays a vital role in translating domain names into IP addresses, enabling seamless communication over the internet. Understanding the intricacies of DNS structure is key to comprehending the functioning of this fundamental technology.
Section 1: What is DNS?
DNS, or the Domain Name System, is a distributed database system that converts user-friendly domain names into machine-readable IP addresses. It acts as the backbone of the internet, facilitating the efficient routing of data packets across the network.
Section 2: Components of DNS Structure
The DNS structure consists of various components working harmoniously to ensure smooth domain name resolution. These components include the root zone, top-level domains (TLDs), second-level domains (SLDs), and authoritative name servers. Each component has a specific role in the hierarchy.
Section 3: The Root Zone
At the very top of the DNS hierarchy lies the root zone. It is the starting point for all DNS queries, containing information about the authoritative name servers for each top-level domain.
Section 4: Top-Level Domains (TLDs)
Below the root zone, we find the top-level domains (TLDs). They represent the highest level in the DNS hierarchy and are classified into generic TLDs (gTLDs) and country-code TLDs (ccTLDs). Examples of gTLDs include .com, .org, and .net, while ccTLDs represent specific countries like .us, .uk, and .de.
Section 5: Second-Level Domains (SLDs)
Next in line are the second-level domains (SLDs). These are the names chosen by individuals, organizations, or businesses to create unique web addresses under a specific TLD. SLDs customize and personalize the domain name, making it more memorable for users.
Section 6: Authoritative Name Servers
Authoritative name servers store and provide DNS records for a specific domain. When a DNS query is made, the authoritative name server provides the corresponding IP address, allowing the user’s device to connect with the desired website.
Conclusion:
In conclusion, the DNS structure serves as the backbone of the internet, enabling seamless communication between devices using user-friendly domain names. Understanding the various components, such as the root zone, TLDs, SLDs, and authoritative name servers, helps demystify the functioning of DNS. By grasping the intricacies of DNS structure, we gain a deeper appreciation for the technology that powers our online experiences.
Shopping Basket
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.