
Understanding Prometheus’ Pull-Based System
Prometheus operates on a pull-based model, meaning it actively fetches metrics from the targets it monitors. Instead of waiting for the targets to push metrics to it, Prometheus takes the initiative and pulls the data at regular intervals. This approach offers several advantages over traditional push-based systems.
1. Flexibility and Reliability: One of the key benefits of the pull-based system is its flexibility. Prometheus can quickly adapt to dynamic environments and handle changes in the configuration of monitored targets. It can automatically discover new targets and adjust the scraping frequency based on the importance of metrics. This flexibility ensures that Prometheus can keep up with the ever-changing nature of modern infrastructure.
2. Efficiency and Scalability: The pull-based system also provides efficiency and scalability. By fetching metrics directly from the targets, Prometheus reduces the resource overhead on each target. This is particularly beneficial in scenarios where the number of targets is large, or the resources on the targets are limited. Additionally, Prometheus can distribute the scraping workload across multiple instances, enabling horizontal scalability and ensuring smooth operations even under heavy loads.
3. Data Integrity and Consistency: Another advantage of the pull-based system is its ability to ensure data integrity and consistency. Since Prometheus fetches metrics directly from the targets, potential data loss in a push-based system is eliminated. By actively pulling the data, Prometheus guarantees that the most up-to-date and accurate metrics are available for analysis and alerting.
4. Alerting and Monitoring: Prometheus’ pull-based system seamlessly integrates with its powerful alerting and monitoring capabilities. By regularly fetching metrics, Prometheus can evaluate them against predefined rules and trigger alerts when certain thresholds are exceeded. This proactive approach to monitoring ensures that any potential issues or anomalies are promptly detected, allowing for timely remedial actions.
Example: Prometheus is Google Cloud
In the following example, I have set up a Google Kubernetes Engine cluster ad and then deployed the Managed Service for Prometheus to ingest metrics from a simple application. Remember that the Managed Service for Prometheus is Google Cloud’s fully managed storage and query service for Prometheus metrics. This service is built on Monarch, the same globally scalable data store as Cloud Monitoring.
Note: A thin fork of Prometheus replaces existing Prometheus deployments and sends data to the managed service with no user intervention. This data can then be queried using PromQL through the Prometheus Query API supported by the managed service and the existing Cloud Monitoring query mechanisms.
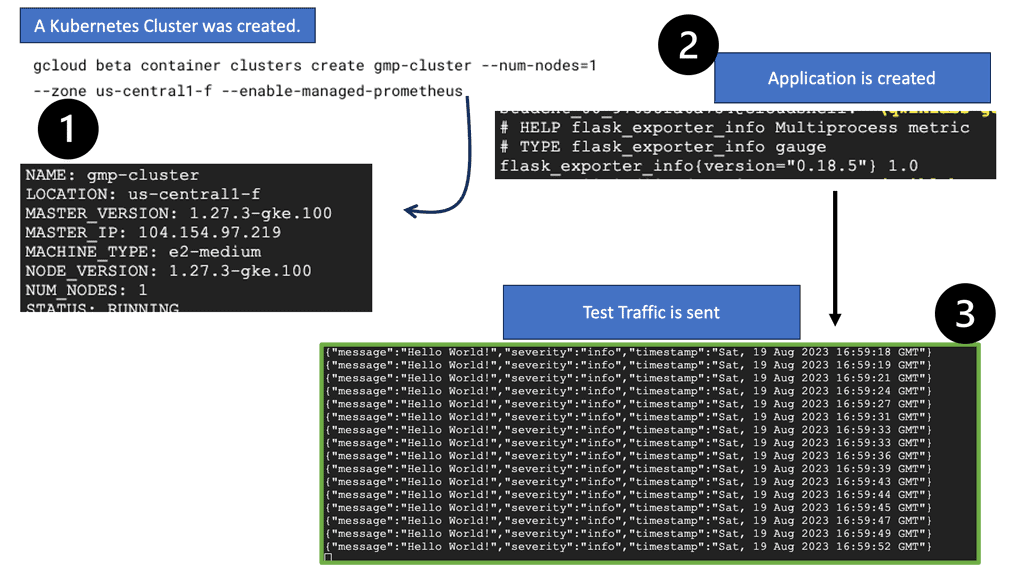
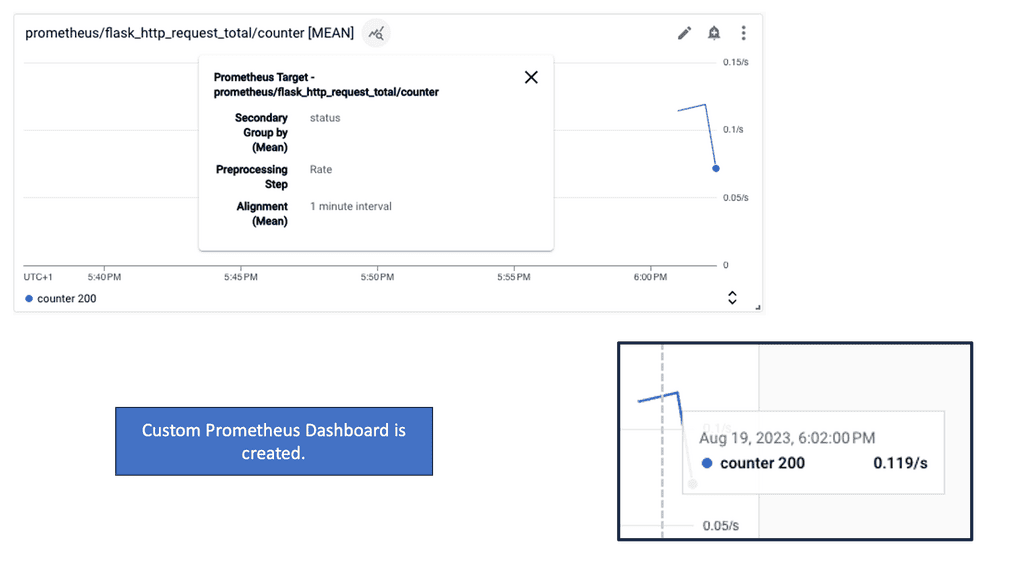
In this last section, quickly use gcloud to deploy a custom monitoring dashboard that shows the metrics from this application in a line chart. Once created, navigate to Monitoring > Dashboards to see the newly created
Prometheus Network Monitoring
Prometheus network monitoring is an open-source, metrics-based system. It includes a robust data model and a query language that lets you analyze how your applications and infrastructure are performing. It does not try to solve problems outside the metrics space and works solely in metric-based monitoring.
However, it can be augmented with tools and a platform for additional observability. For Prometheus to work, you need to instrument your code.
Available Client libraries
Client libraries are available in all the popular languages and runtimes for instrumenting your code, including Go, Java/JVM, C#/.Net, Python, Ruby, Node.js, Haskell, Erlang, and Rust. In addition, software like Kubernetes and Docker are already instrumented with Prometheus client libraries. So you say these are out of the box, so are you ready for Prometheus to scrap their metrics?
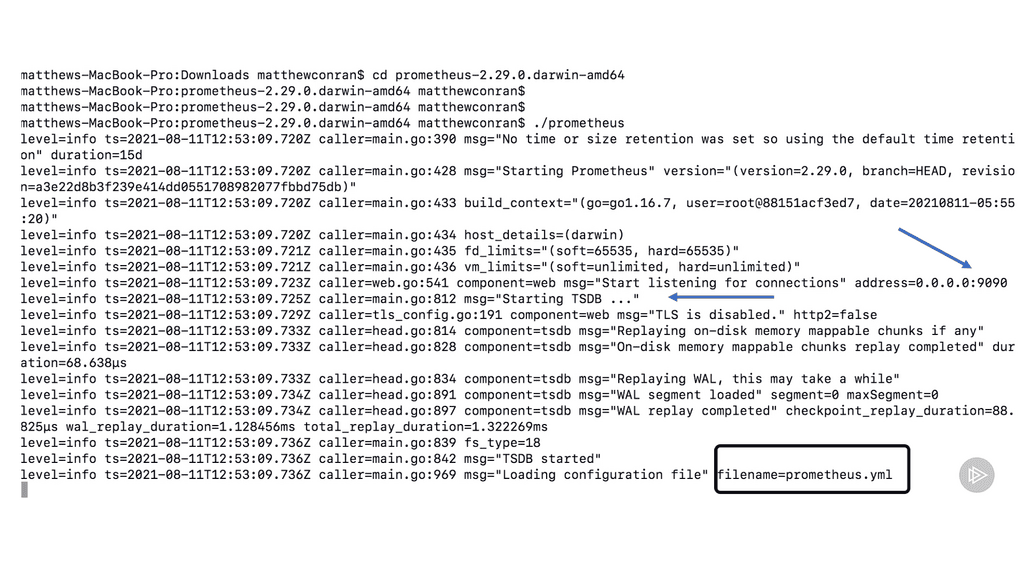
In the following diagram, you will see the Prometheus settings from a fresh install. I have downloaded Prometheus from the Prometheus website on my local machine. Prometheus, by default, listens on port 9090 and contains a highly optimized Time Series Database (TSDB), which you can see is started. Also displayed at the very end of the screenshot is the default name of the Prometheus configuration file.
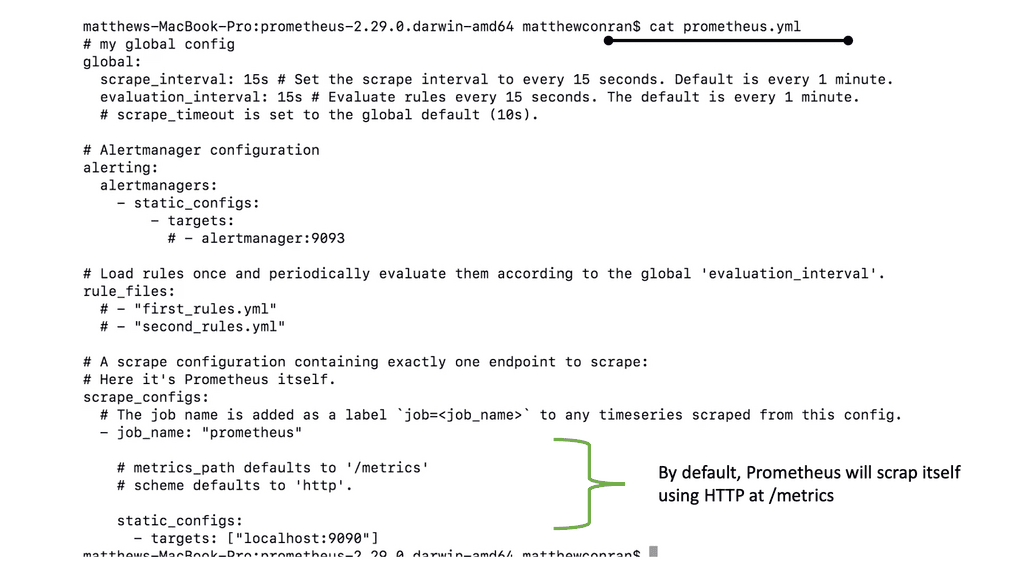
The Prometheus configuration file is written in YAML format and is defined by the scheme. I have done a CAT on the Prometheus configuration file to give you an idea of what it looks like. In the default configuration, a single job called Prometheus scrapes the time series data exposed by the Prometheus server. The job contains a single, statically configured target, the local host on port 9090.
The Transition to Prometheus network monitoring
Around eight years ago, Ganglia introduced SaaS-based monitoring solutions. These now solved some problems with alerting built-in and API to get to the data. However, now there are two systems, and this introduces complexity. The collector and the agents are pushing to the SaaS-based system along with an on-premises design.
These systems may need to be managed by two different teams. There can be cloud teams looking after the cloud-based SaaS solution and on-premises network or security teams looking at the on-premises monitoring. So, there is already a communication gap, not to mention the creation of a considerably siloed environment in one technology set—monitoring.
Also, questions arise about where to put the metrics in the SaaS-based product or Ganga. For example, we could have different metrics in the same place or the same metrics in only one spot. How can you keep track and ensure consistency?
Ideally, if you have a dispersed PoP design and expect your infrastructure to grow and plan for the future, you don’t want to have centralized collectors. But unfortunately, most on-premise solutions still have a push-based centralized model.
Prometheus Monitoring: Prometheus Pull
Then Prometheus Pull came around and offered a new approach to monitoring. It can handle millions of metrics on modest hardware. In general, rather than having external services push metrics to it, Prometheus uses a pull approach compared to a push approach.
Prometheus network monitoring is a server application written in GO. It is an open-source, decentralized monitoring tool that can be centralized using the federate option. Prometheus has a server component, which you run in each environment. You can also run a Prometheus container in each Kubernetes pod.
We use a time-series database for Prometheus monitoring, and every metric is recorded with a timestamp. Prometheus is not an SQL database; you need to use PromQL as its query language, which allows you to query the metrics.
Prometheus Monitoring: Legacy System
So, let us expand on this and look at two environments for monitoring. We have a legacy environment and a modern Kubernetes environment. We are running a private cloud for the legacy with many SQL, Windows, and Linux servers. There is nothing new here. Here, you would run Prometheus on the same subnet. A Prometheus agent would also be installed.
We would have Node Exporters for both Linux and Windows, extracting and creating a metric endpoint on your servers. The metric endpoint is needed on each server or host so Prometheus can scrap the metrics. So, a Daemon is running, collecting all of the metrics. These metrics are exposed on a page, for example, http://host:port/metrics, that allows Prometheus to scrape.
There is also a Prometheus federation feature. You can have a federated endpoint, allowing Prometheus to expose its metrics to other services. This will enable you to pull metrics around different subnets. So, we can have another Prometheus in a different subnet, scrapping the other Prometheus. The federate option will enable you to link these two Prometheus solutions quickly.
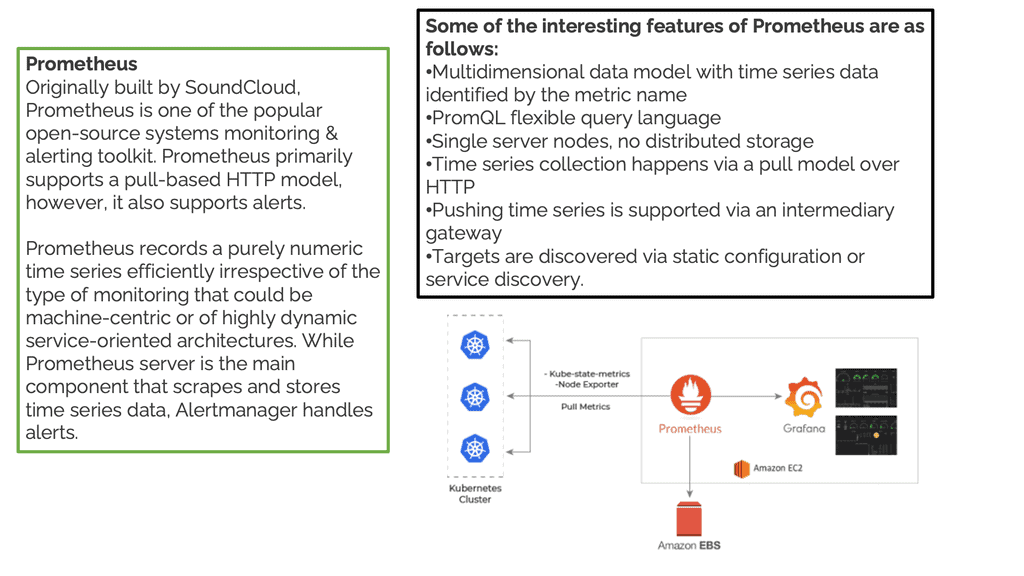
Prometheus Monitoring: Modern Kubernetes
Here, we have a microservices observability platform and a bunch of containers or VMs running in a Kubernetes cluster. In this environment, we usually create a namespace; for example, we could call the namespace monitoring. So, we deploy a Prometheus pod in our environments.
The Prometheus pod YAML file will point to the Kubernetes API. The Kubernetes API has a metric server that gets all metrics from your environments. So here we are, getting metrics for the container processes. You can deploy the library in your code if you want to instrument your application.
This can be done with Prometheus code libraries. We now have a metrics endpoint similar to before, and we can grab metrics specific to your application. We also have a metrics endpoint on each container that Prometheus can scrape.
**What is Prometheus Exporter**
Prometheus exporter is a specialized component that extracts and exposes metrics from third-party systems, applications, and services. It bridges Prometheus, an open-source monitoring and alerting toolkit, and the target system or application.
By implementing the Prometheus exporter, users can conveniently collect and monitor custom metrics, enabling them to gain valuable insights into their systems’ health and performance.
How Does Prometheus Exporter Work?
Prometheus exporter follows a simple and efficient architecture. It utilizes a built-in HTTP server to expose metrics in a format that Prometheus understands. The exporter periodically collects metrics from the target system or application and makes them available over HTTP endpoints. Prometheus then scrapes these endpoints, discovers and stores the metrics, and performs analysis and alerting based on the defined rules.
Benefits of Prometheus Exporter:
1. Flexibility: The Prometheus exporter provides flexibility in monitoring various metrics, making it suitable for multiple systems and applications. With its support for custom metrics, users can easily monitor specific aspects and gain insights into their systems’ behavior.
2. Compatibility: Due to its popularity, many systems and applications offer native support for Prometheus exporters. This compatibility allows users to effortlessly integrate the exporter into their existing monitoring infrastructure, eliminating the need for complex configurations or additional tools.
3. Extensibility: Prometheus exporter encourages extensibility by offering a straightforward mechanism to develop and expose custom metrics. This capability enables users to monitor specific application-level metrics critical to their unique monitoring requirements.
4. Scalability: With Prometheus exporter, users can scale their monitoring infrastructure as their systems grow. The exporter’s lightweight design and efficient data collection mechanism ensure that monitoring remains reliable and efficient, even in high-throughput environments.
Exposing Runtime Metrics: The Prometheus Exporter
- Exporter Types:
To enable Prometheus monitoring, you must add a metric API to the application containers to support this. For applications that don’t have their metric API, we use what is known as an Exporter. This utility reads the runtime metrics the app has already collected and exposes them on an HTTP endpoint.
Prometheus can then look at this HTTP endpoint. So we have different types of Exporters that collect metrics for other runtimes, such as a JAVA Exporter, which will give you a set of JVM statistics, and a .NET Exporter, which will provide you with a set of Windows performance metrics.
Essentially, we are adding a Prometheus endpoint to the application. In addition, we use an Exporter utility alongside the application. So, we will have two processes running in the container.
With this approach, you don’t need to change the application. This could be useful for some regulatory environments where you can’t change the application code. So now you have application runtime metrics without changing any code.
This is the operating system and application host data already collected in the containers. To make these metrics available to Prometheus, add an Exporter to the Docker Image. Many use the Exporters for legacy applications instead of changing the code to support Prometheus monitoring.
Essentially, we are exporting the statistics to a metric endpoint.

- Fortinet’s new FortiOS 7.4 enhances SASE - April 5, 2023
- Comcast SD-WAN Expansion to SMBs - April 4, 2023
- Cisco CloudLock - April 4, 2023