Understanding Load Balancing
– Load balancing is a technique for distributing incoming network traffic across multiple servers. By evenly distributing the workload, load balancing enhances the performance, scalability, and reliability of web applications. Whether it’s a high-traffic e-commerce website or a complex cloud-based system, load balancing plays a vital role in ensuring a seamless user experience.
– Load balancing is not only about distributing traffic; it also enhances application availability and scalability. By implementing load balancing, organizations can achieve high availability by eliminating single points of failure. In a server failure, load balancers can seamlessly redirect traffic to healthy servers, ensuring uninterrupted service.
– Additionally, load balancing facilitates scalability by allowing organizations to add or remove servers quickly based on demand. This elasticity ensures that applications can handle sudden spikes in traffic without compromising performance.
Several techniques are employed for load balancing, each with its advantages and use cases. Let’s explore a few popular ones:
1. Round Robin: The Round Robin algorithm evenly distributes incoming requests among servers in a cyclical manner. This technique is simple and effective, ensuring all servers get an equal share of the traffic.
2. Weighted Round Robin: Unlike the traditional Round Robin approach, Weighted Round Robin assigns different server weights based on their capabilities. This allows administrators to allocate more traffic to high-performance servers, optimizing resource utilization.
3. Least Connection: The algorithm directs incoming requests to the server with the fewest active connections. This technique ensures that heavily loaded servers are not overwhelmed and distributes traffic intelligently.
4. IP Hash Load Balancing: Here, the client’s IP address is used to determine which server receives the request. This technique is beneficial for applications requiring session persistence, like shopping carts or user profiles.
5. Weighted Load Balancing: Servers are assigned a weight based on their capacity. More robust servers handle a larger proportion of the load, ensuring an efficient distribution of traffic.
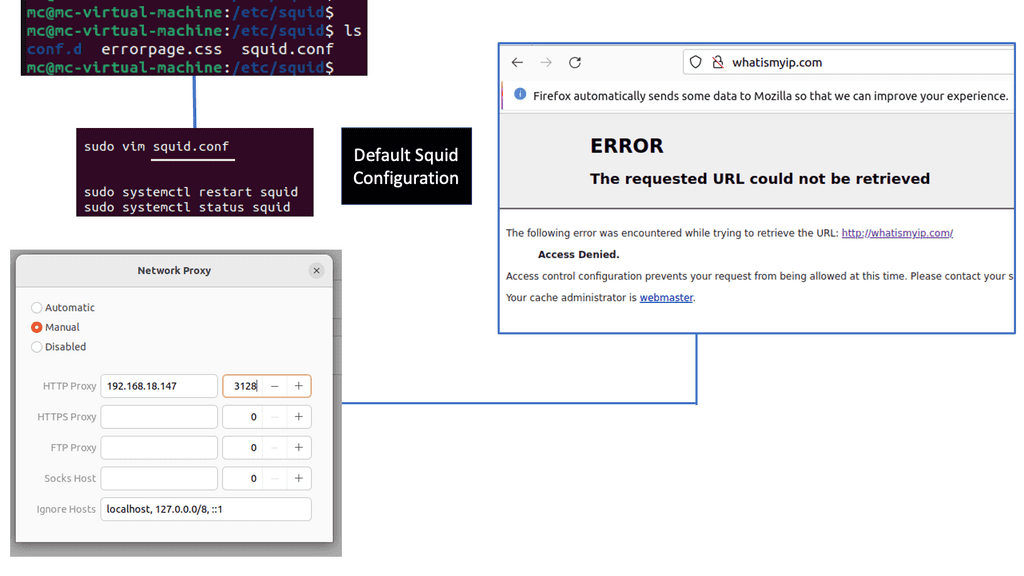
Example: What is Squid Proxy?
Squid Proxy is a widely-used caching proxy server that acts as an intermediary between clients and web servers. It caches commonly requested web content, allowing subsequent requests to be served faster, reducing bandwidth usage, and improving overall performance. Its flexibility and robustness make it a preferred choice for individuals and organizations alike.
Squid Proxy offers a plethora of features that enhance browsing efficiency and security. From content caching and access control to SSL decryption and transparent proxying, Squid Proxy can be customized to suit diverse requirements. Its comprehensive logging and monitoring capabilities provide valuable insights into network traffic, aiding in troubleshooting and performance optimization.
Implementing Squid Proxy brings several benefits to the table. Firstly, it significantly reduces bandwidth consumption by caching frequently accessed content, resulting in faster response times and reduced network costs. Additionally, Squid Proxy allows for granular control over web access, enabling administrators to define access policies, block malicious websites, and enforce content filtering. This improves security and ensures a safe browsing experience.

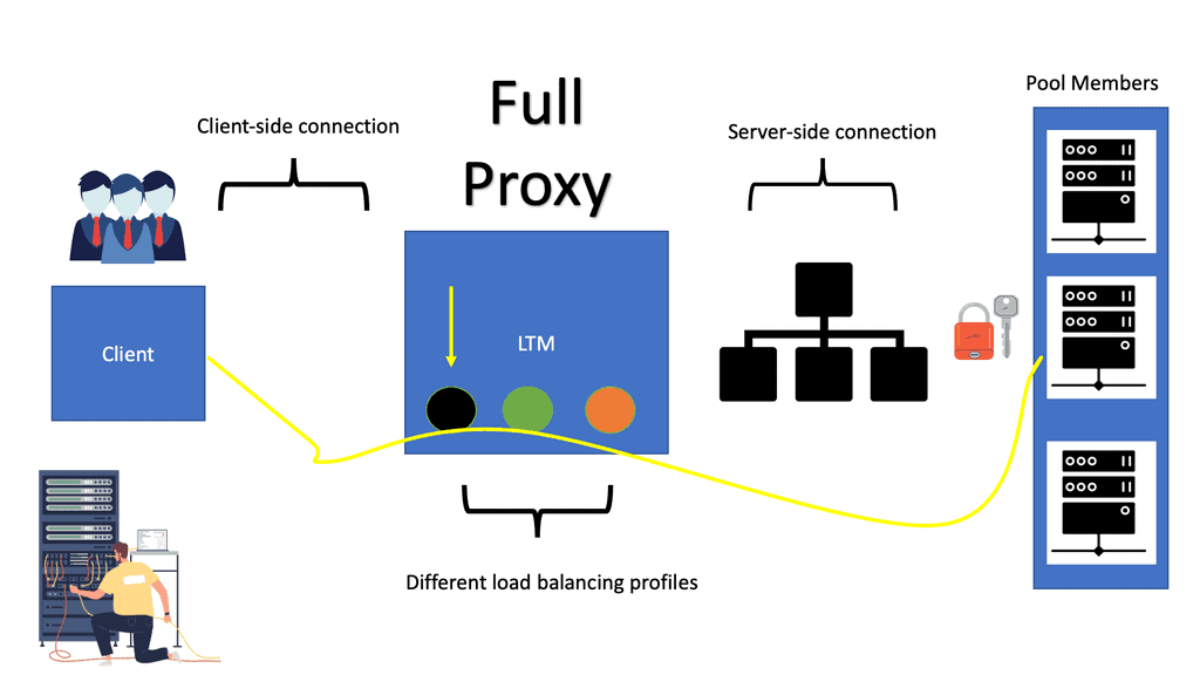
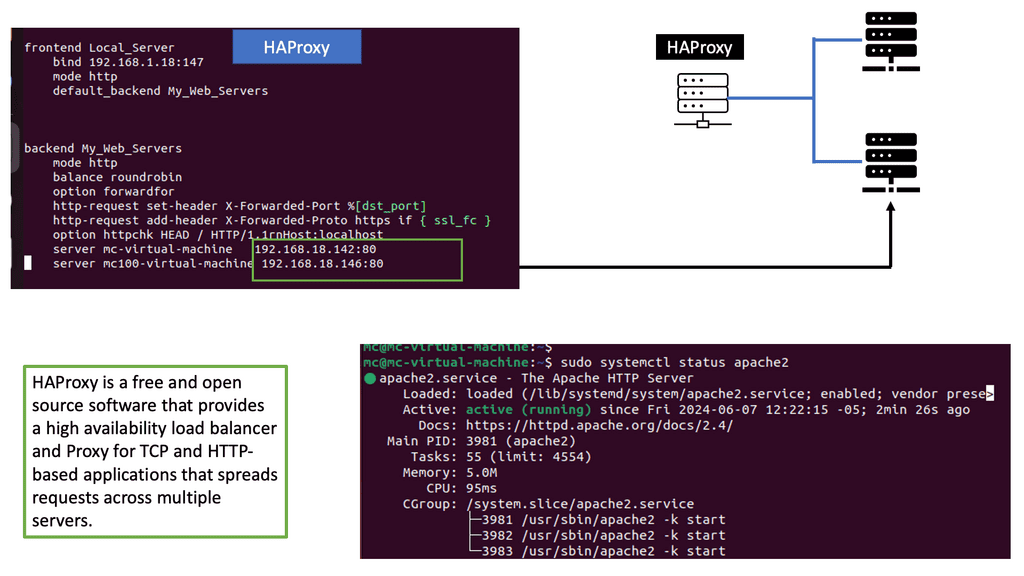
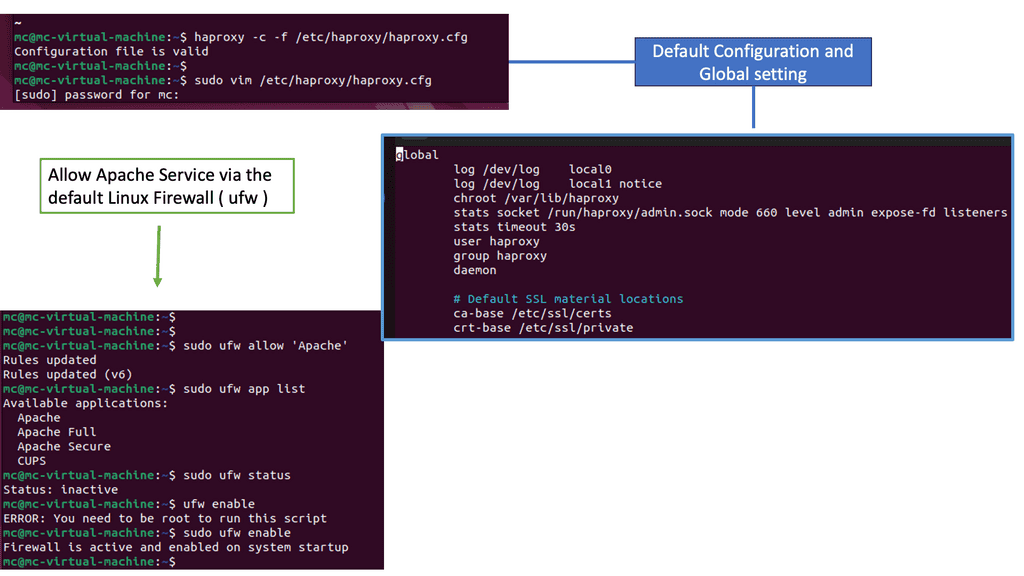
Example: Understanding HA Proxy
HA Proxy, short for High Availability Proxy, is an open-source load balancer and proxy server software. It operates at the application layer of the TCP/IP stack, making it a powerful tool for managing traffic between clients and servers. Its primary function is to distribute incoming requests across multiple backend servers based on various algorithms, such as round-robin, least connections, or source IP affinity.
HA Proxy offers a plethora of features that make it an indispensable tool for businesses seeking high performance and scalability. Firstly, its ability to perform health checks on backend servers ensures that only healthy servers receive traffic, ensuring optimal performance. Additionally, it supports SSL/TLS termination, allowing for secure connections between clients and servers. HA Proxy also provides session persistence, enabling sticky sessions for specific clients, which is crucial for applications that require stateful communication.
The Mechanics of Scale-Out Architectures
Scale-out architecture, unlike scale-up, involves adding more servers to an existing pool rather than upgrading a single server’s hardware. This horizontal scaling approach is preferred by many enterprises because it offers flexibility, cost-effectiveness, and the ability to seamlessly increase capacity as demand grows. By distributing the load across multiple machines, businesses can enhance performance, reduce downtime, and ensure a better user experience.
**The Benefits of Scale-Out Architectures**
One of the primary advantages of scale-out architectures is their inherent scalability. Businesses can easily accommodate growth by simply adding more servers to their network, thus avoiding the costly and complex upgrades associated with scale-up approaches. This flexibility allows companies to respond swiftly to changing demands, ensuring that their IT infrastructure can handle increased traffic without a hitch. Moreover, scale-out architectures often lead to cost savings, as organizations can opt for commodity hardware and open-source software to build their systems.
**Challenges and Considerations**
While scale-out architectures offer numerous benefits, they are not without challenges. Managing a distributed system can be complex, requiring robust monitoring and management tools to ensure optimal performance. Additionally, as the number of servers increases, so does the potential for network latency and data consistency issues. It’s crucial for businesses to carefully plan and design their scale-out strategies, taking into account factors such as data replication, network bandwidth, and fault tolerance to mitigate these challenges effectively.
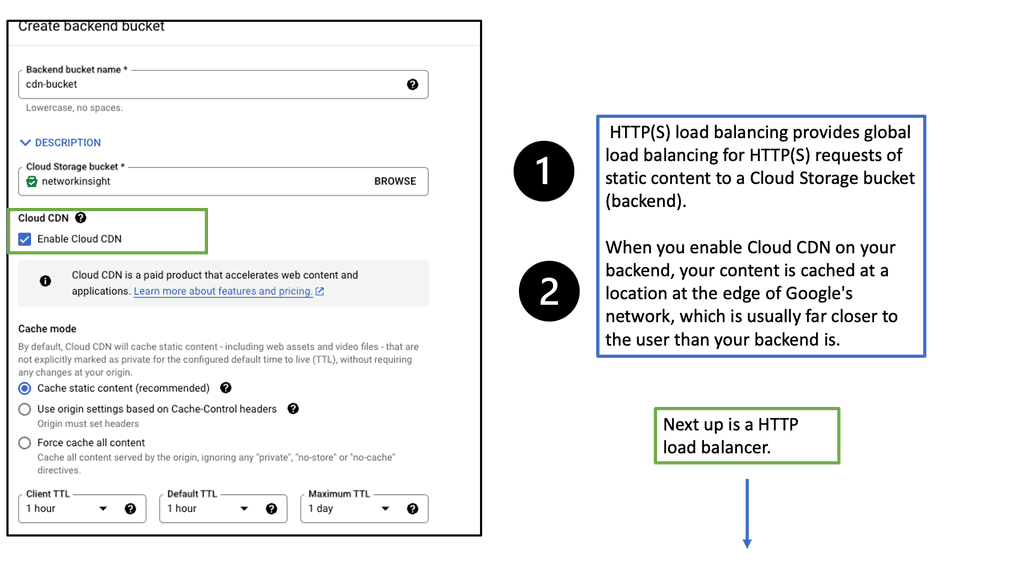
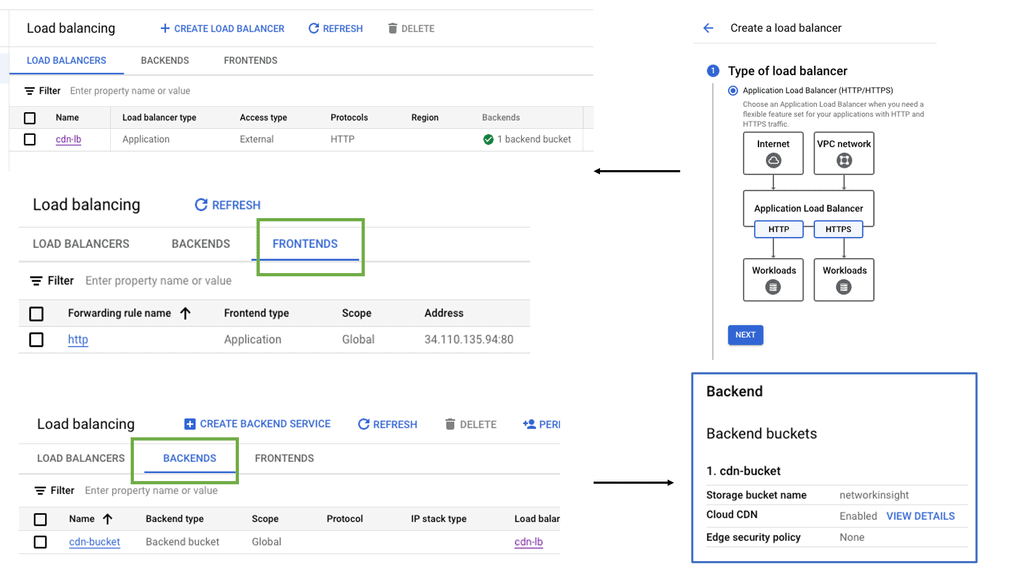
Google Cloud Load Balancing
Load balancing plays a vital role in distributing incoming network traffic across multiple servers, ensuring optimal performance and preventing server overload. Google Cloud’s Network and HTTP Load Balancers are powerful tools that enable efficient traffic distribution, enhanced scalability, and improved reliability.
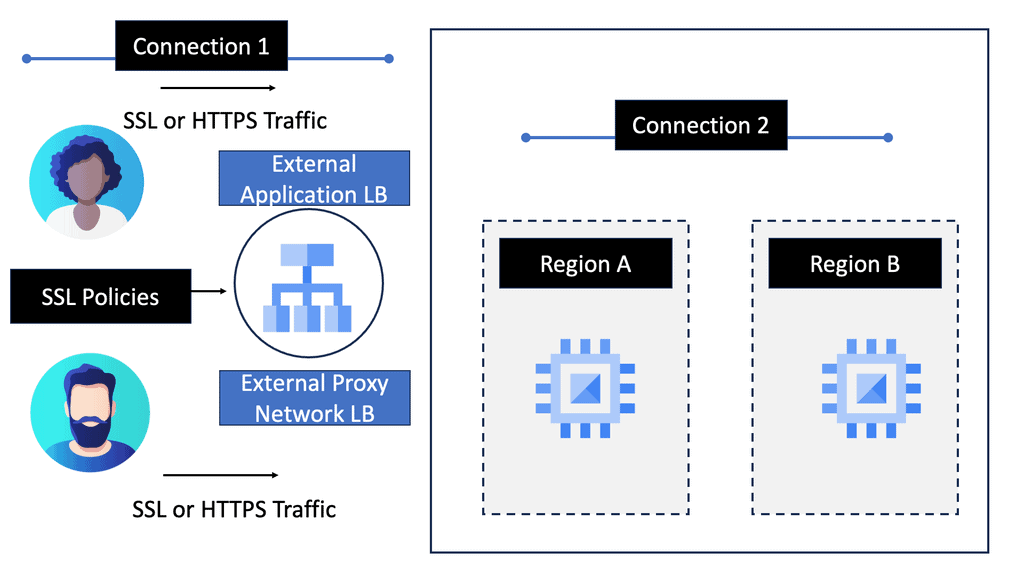
Network Load Balancer: Google Cloud’s Network Load Balancer operates at the transport layer (Layer 4) of the OSI model, making it ideal for TCP/UDP-based traffic. It offers regional load balancing, allowing you to distribute traffic across multiple instances within a region. With features like connection draining, session affinity, and health checks, Network Load Balancer provides robust and customizable load balancing capabilities.
HTTP Load Balancer: For web applications that rely on HTTP/HTTPS traffic, Google Cloud’s HTTP Load Balancer is the go-to solution. Operating at the application layer (Layer 7), it offers advanced features like URL mapping, SSL termination, and content-based routing. HTTP Load Balancer also integrates seamlessly with other Google Cloud services like Cloud CDN and Cloud Armor, further enhancing security and performance.
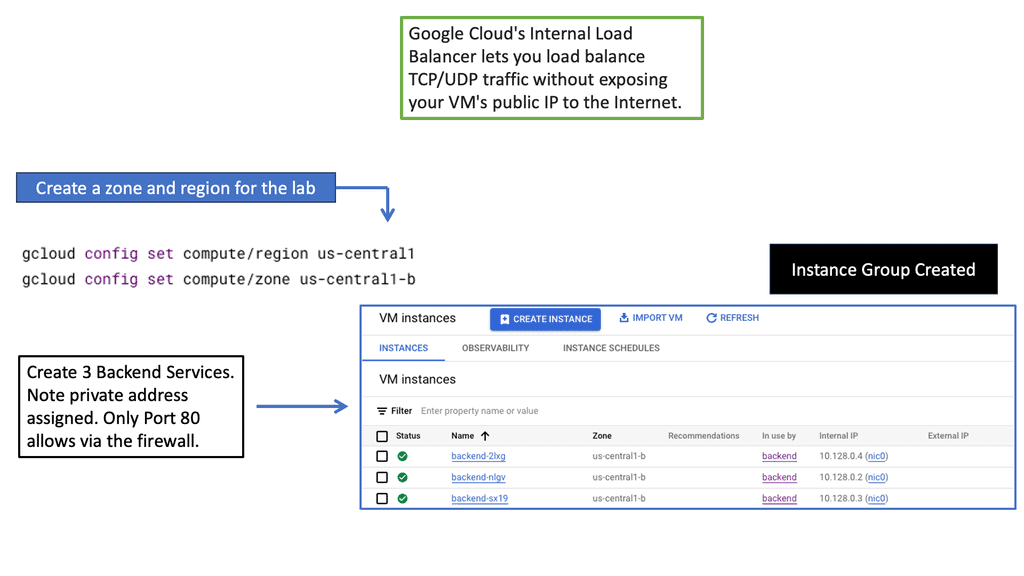
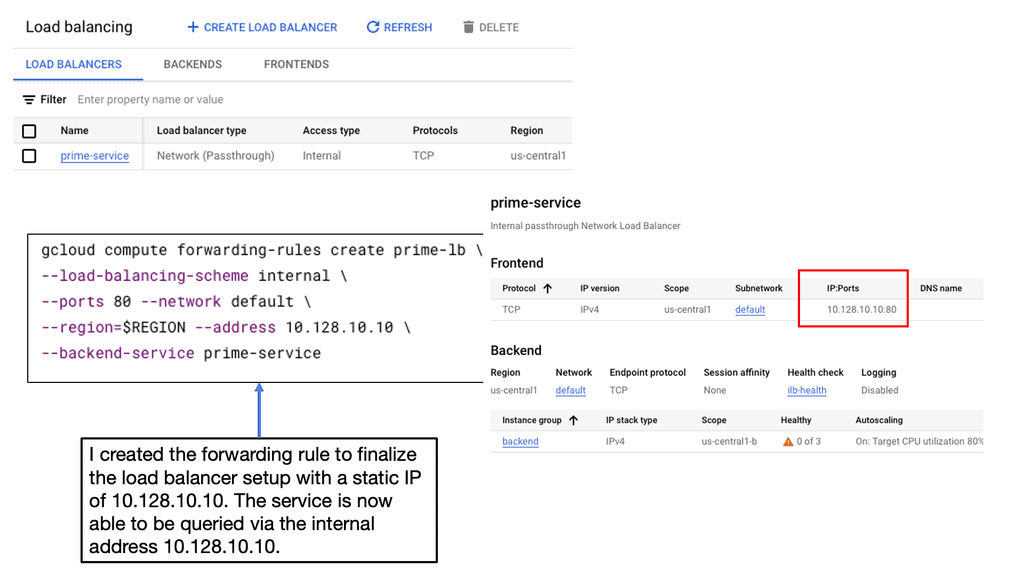
Setting Up Network and HTTP Load Balancers: Configuring Network and HTTP Load Balancers in Google Cloud is a straightforward process. From the Cloud Console, you can create a new load balancer instance, define backend services, set up health checks, and configure routing rules. Google Cloud’s intuitive interface and documentation provide step-by-step guidance, making the setup process hassle-free.
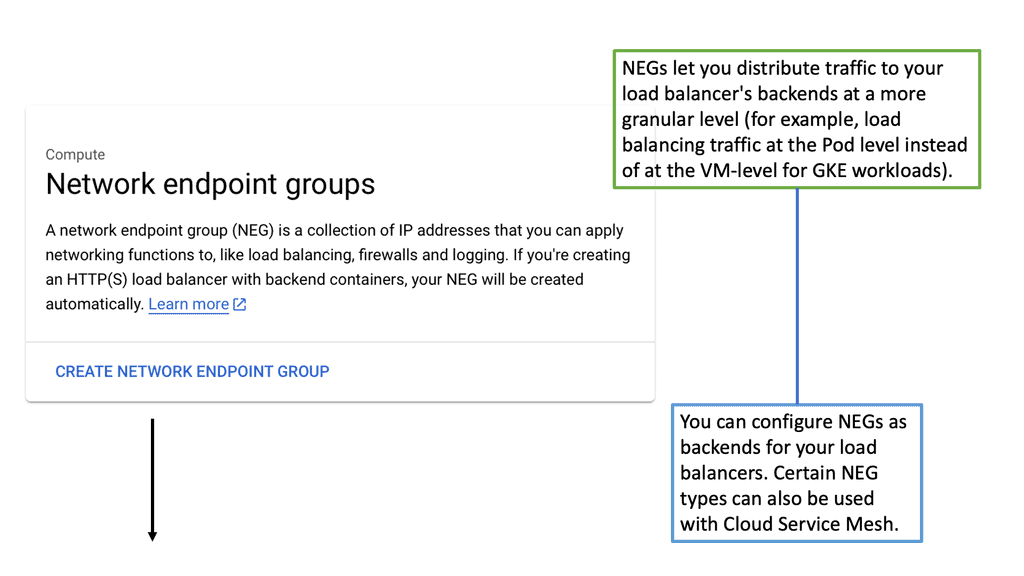
Google Cloud NEGs
### The Role of Network Endpoint Groups in Load Balancing
Load balancing is crucial for ensuring high availability and reliability of applications. NEGs play a significant role in this by enabling precise traffic distribution. By grouping network endpoints, you can ensure that your load balancer directs traffic to the most appropriate instances, thereby optimizing performance and reducing latency. This granular control is particularly beneficial for applications with complex network requirements.
### Types of Network Endpoint Groups
Google Cloud offers different types of NEGs to cater to various use cases. Zonal NEGs are used for VM instances within the same zone, ideal for scenarios where low latency is required. Internet NEGs, on the other hand, are perfect for external endpoints, such as Google Cloud Storage buckets or third-party services. Understanding these types allows you to choose the best option based on your specific needs and infrastructure setup.
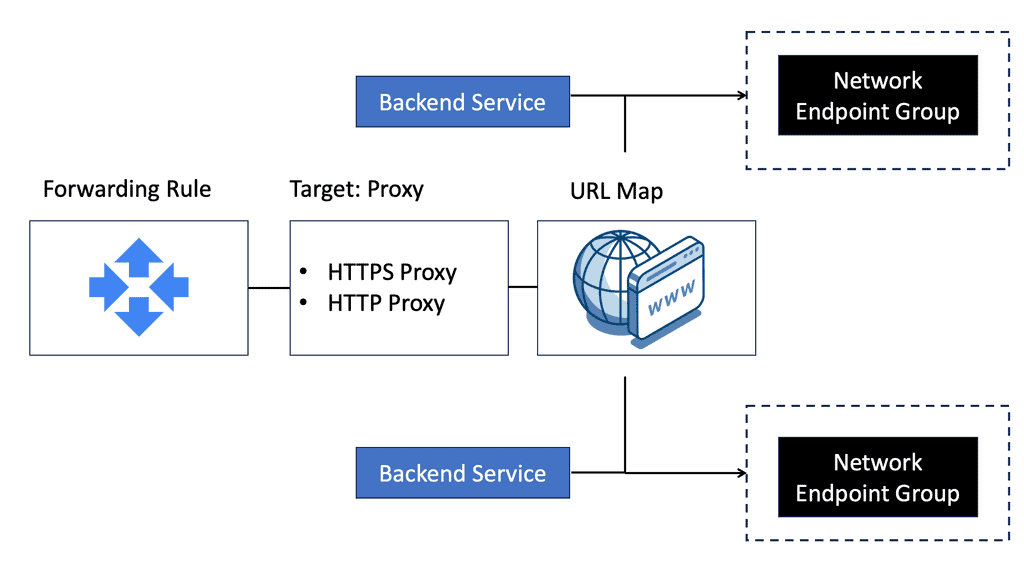
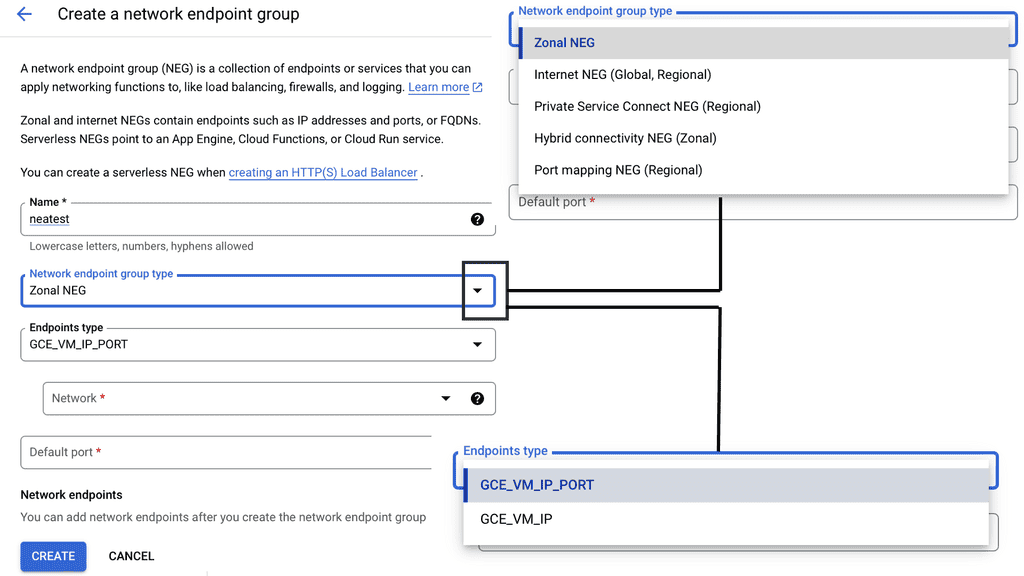
### Configuring Network Endpoint Groups
Configuring NEGs in Google Cloud is a straightforward process. Start by identifying your endpoints and the type of NEG you need. Then, create the NEG through the Google Cloud Console or using cloud commands. Assign the NEG to a load balancer, and configure the routing rules. This flexibility in configuration ensures that you can tailor your network setup to match your application’s demands.
### Best Practices for Using Network Endpoint Groups
To maximize the benefits of NEGs, adhere to best practices such as regularly monitoring traffic patterns and adjusting configurations as needed. This proactive approach helps in anticipating changes in demand and ensures optimal resource utilization. Additionally, leveraging Google Cloud’s monitoring tools can provide insights into the performance of your network endpoints, aiding in making informed decisions.
Load Balancing with MIGs
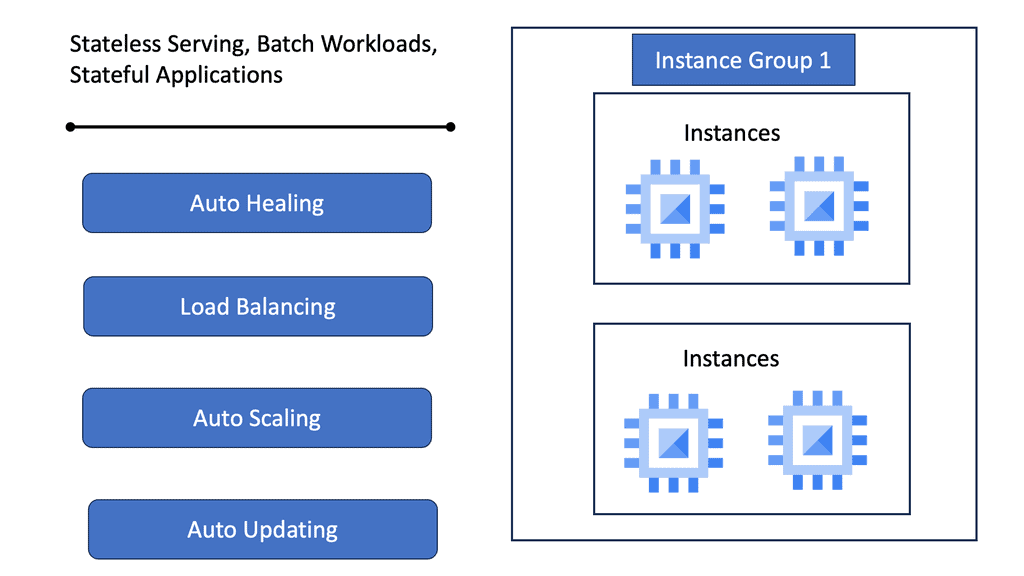
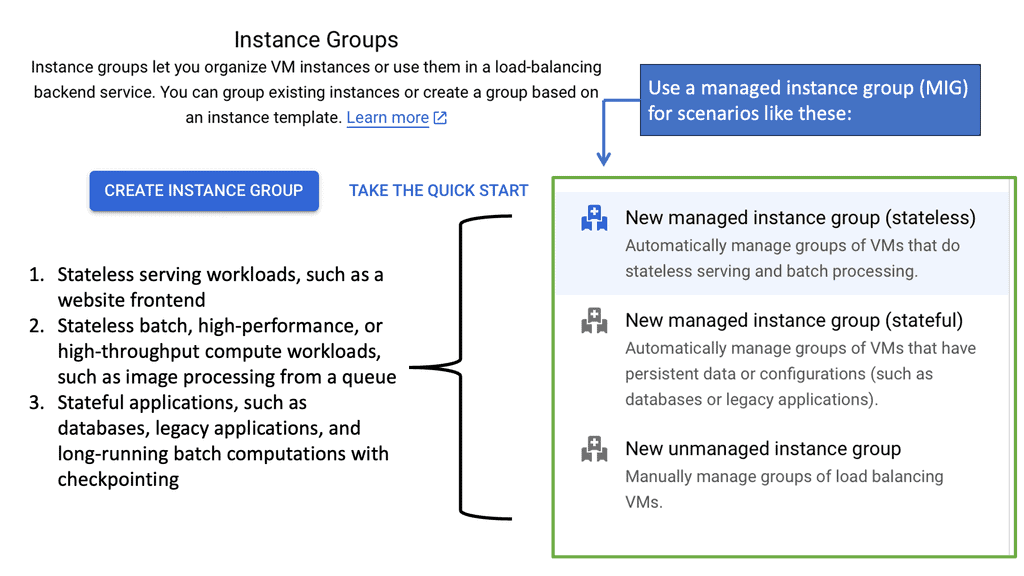
Google Cloud’s Managed Instance Groups (MIGs)
Google Cloud’s Managed Instance Groups (MIGs) offer a seamless way to manage large numbers of identical virtual machine instances, enabling businesses to efficiently scale their applications while maintaining high availability. Whether you’re running a web application, a backend service, or handling batch processing, MIGs provide a robust framework to meet your needs.
**Understanding the Benefits of Managed Instance Groups**
Managed Instance Groups automate the process of managing VM instances by ensuring that your applications are always running the desired number of instances. This automation not only reduces the operational overhead but also ensures your applications can handle varying loads with ease. With features like automatic healing, load balancing, and integrated monitoring, MIGs provide a comprehensive solution to manage your cloud resources efficiently. Moreover, they support rolling updates, allowing you to deploy new application versions with minimal downtime.
**Scaling with Confidence**
One of the standout features of Managed Instance Groups is their ability to scale your applications automatically. By setting up autoscaling policies based on CPU usage, HTTP load, or custom metrics, MIGs can dynamically adjust the number of running instances to match the current demand. This elasticity ensures that your applications remain responsive and cost-effective, as you only pay for the resources you actually need. Additionally, by distributing instances across multiple zones, MIGs enhance the resilience of your applications against potential failures.
**Best Practices for Using Managed Instance Groups**
To get the most out of Managed Instance Groups, it’s essential to follow best practices. Start by defining clear scaling policies that align with your application’s performance and cost objectives. Regularly monitor the performance of your MIGs using Google Cloud’s integrated monitoring tools to gain insights into resource utilization and potential bottlenecks. Additionally, consider leveraging instance templates to standardize configurations and simplify the deployment of new instances.
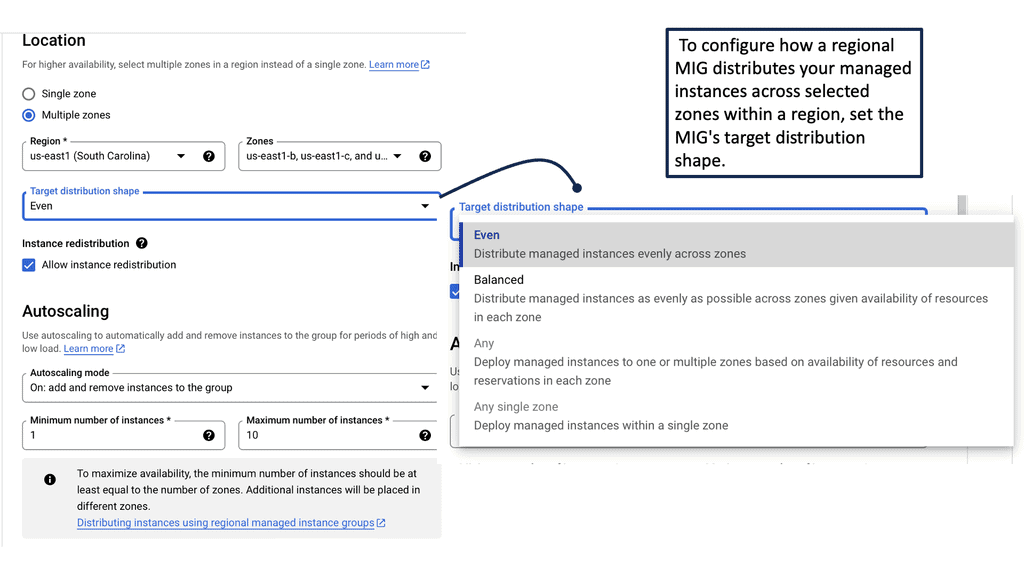
**What Are Health Checks and Why Do They Matter?**
Health checks are periodic tests run by load balancers to monitor the status of backend servers. They determine whether servers are available to handle requests and ensure that traffic is only directed to those that are healthy. Without health checks, a load balancer might continue to send traffic to an unresponsive or overloaded server, leading to potential downtime and poor user experiences. Health checks help maintain system resilience by redirecting traffic away from failing servers and restoring it once they are back online.
—
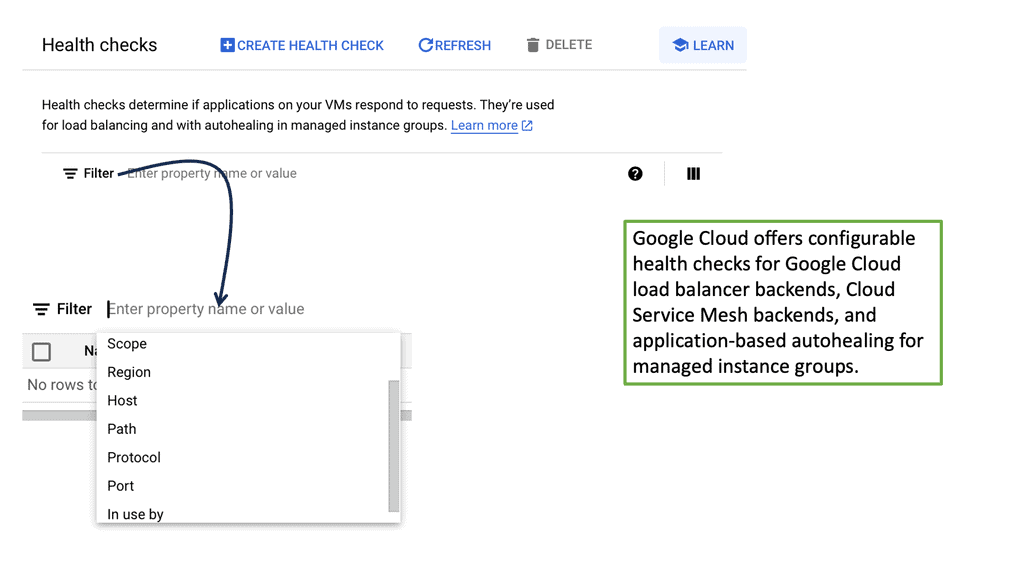
**Google Cloud’s Approach to Load Balancing Health Checks**
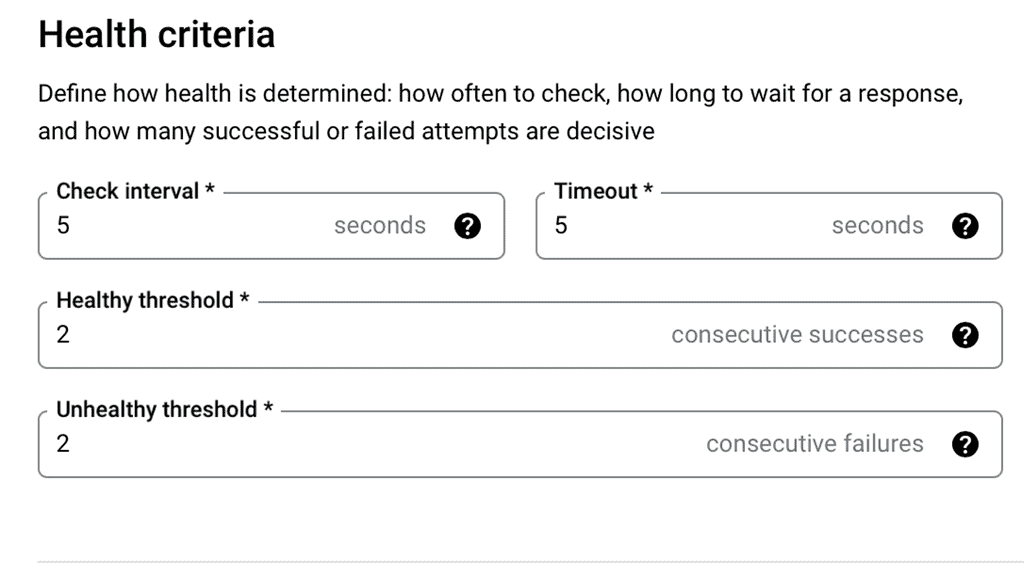
Google Cloud offers a comprehensive suite of load balancing options, each with customizable health check configurations. These health checks can be set up to monitor different aspects of server health, such as HTTP/HTTPS responses, TCP connections, and SSL handshakes. Google Cloud’s platform allows users to configure parameters like the frequency of health checks, timeout durations, and the criteria for considering a server healthy or unhealthy. By leveraging these features, businesses can tailor their health checks to meet their specific needs and ensure reliable application performance.
—
**Best Practices for Configuring Health Checks**
To make the most out of cloud load balancing health checks, consider implementing the following best practices:
1. **Set Appropriate Intervals and Timeouts:** Balance the frequency of health checks with network overhead. Frequent checks might catch issues faster but can increase load on your servers.
2. **Define Clear Success and Failure Criteria:** Establish what constitutes a successful health check and at what point a server is considered unhealthy. This might include response codes or specific message content.
3. **Monitor and Adjust:** Regularly review health check logs and performance metrics to identify patterns or recurring issues. Adjust configurations as necessary to address these findings.

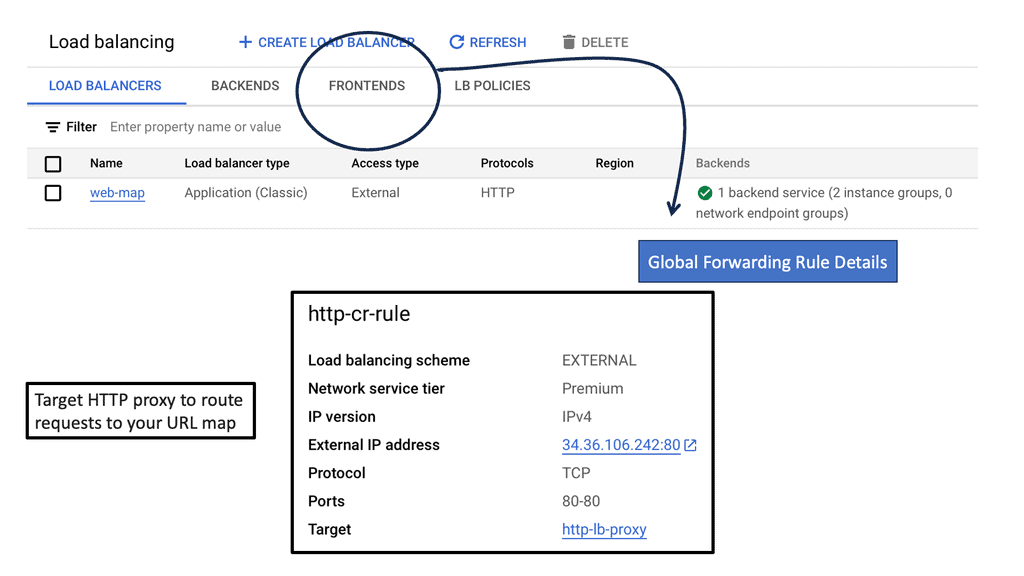
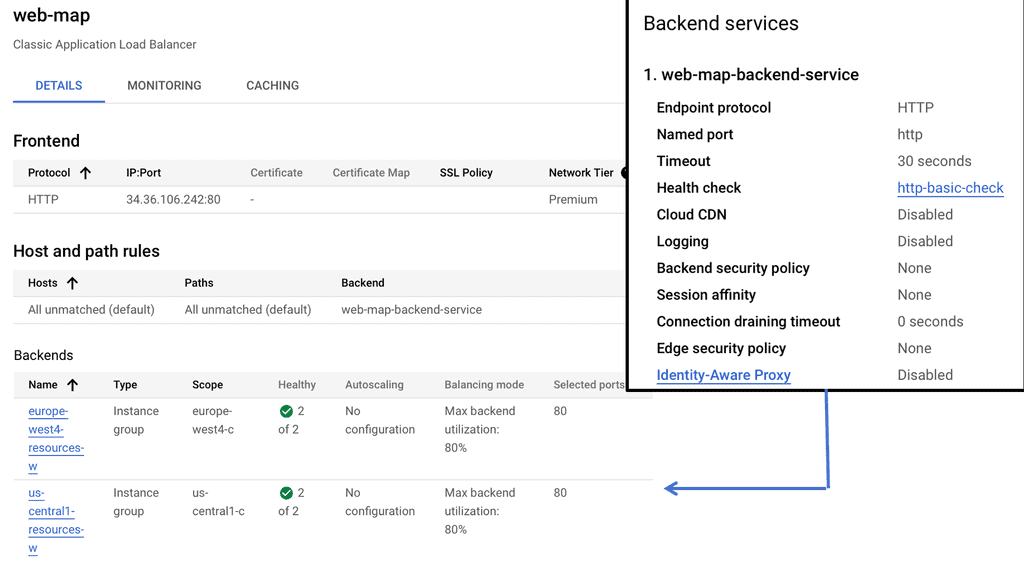
Understanding Cross-Region HTTP Load Balancing
Cross-region HTTP load balancing is a technique used to distribute incoming HTTP traffic across multiple servers located in different regions. This approach not only enhances the availability and reliability of your applications but also significantly reduces latency by directing users to the nearest server. On Google Cloud, this is achieved through the Global HTTP(S) Load Balancer, which intelligently routes traffic to optimize user experience based on various factors such as proximity, server health, and current load.
### Benefits of Cross-Region Load Balancing on Google Cloud
One of the primary benefits of using Google Cloud’s cross-region HTTP load balancing is its global reach. With data centers spread across the globe, you can ensure that your users always connect to the nearest available server, resulting in faster load times and improved performance. Additionally, Google Cloud’s load balancing solution comes with built-in security features, such as SSL offloading, DDoS protection, and IPv6 support, providing a robust shield against potential threats.
Another advantage is the seamless scalability. As your user base grows, Google Cloud’s load balancer can effortlessly accommodate increased traffic without manual intervention. This scalability ensures that your services remain available and responsive, even during peak times.
### Setting Up Cross-Region Load Balancing on Google Cloud
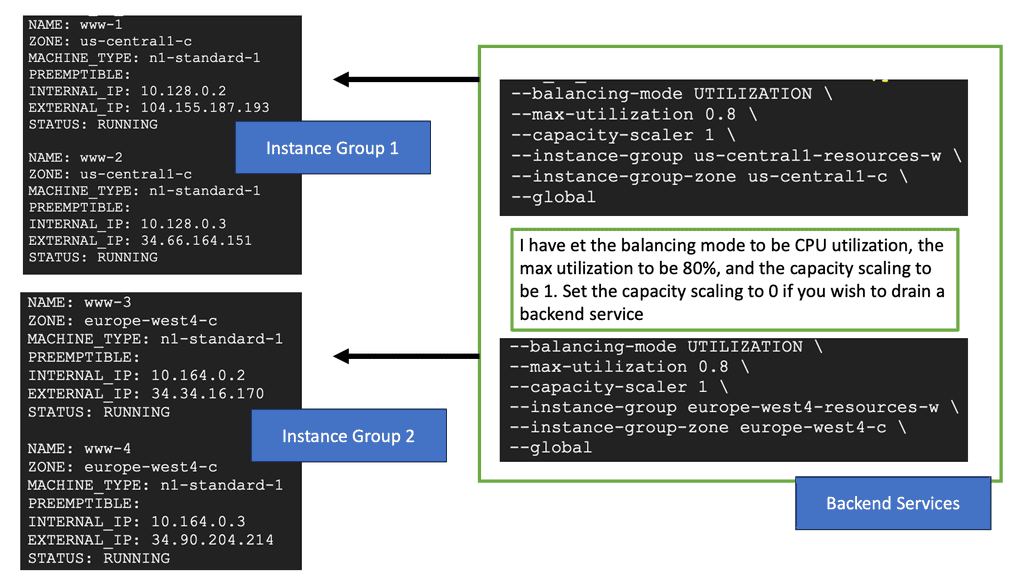
To set up cross-region HTTP load balancing on Google Cloud, you need to follow a series of steps. First, create backend services and associate them with your virtual machine instances located in different regions. Next, configure the load balancer by defining the URL map, which dictates how traffic is distributed across these backends. Finally, set up health checks to monitor the status of your instances and ensure that traffic is only directed to healthy servers. Google Cloud’s intuitive interface and comprehensive documentation make this process straightforward, even for those new to cloud infrastructure.
Distributing Load with Service Mesh
The Importance of Load Balancing
One of the primary functions of a cloud service mesh is load balancing. Load balancing is essential for distributing network traffic evenly across multiple servers, ensuring no single server becomes overwhelmed. This not only enhances the performance and reliability of applications but also contributes to the overall efficiency of the cloud infrastructure. With a well-implemented service mesh, load balancing becomes dynamic and intelligent, automatically adjusting to traffic patterns and server health.
### Enhancing Security with a Service Mesh
Security is a paramount concern in cloud computing. A cloud service mesh enhances security by providing built-in features such as mutual TLS (mTLS) for service-to-service encryption, authorization, and authentication policies. This ensures that all communications between services are secure and that only authorized services can communicate with each other. By centralizing security management within the service mesh, organizations can simplify their security protocols and reduce the risk of vulnerabilities.


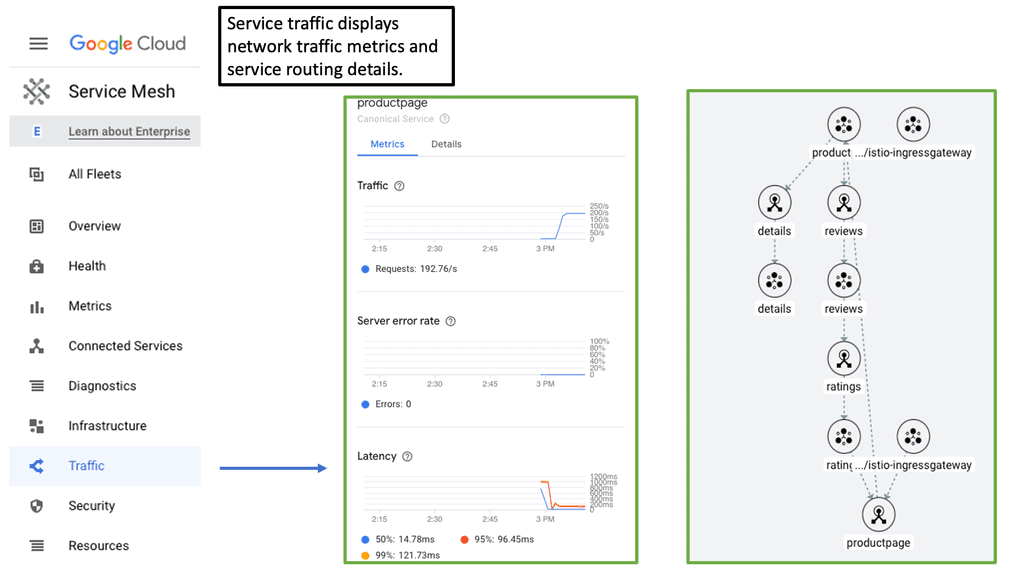
### Observability and Monitoring
Another significant advantage of using a cloud service mesh is the enhanced observability and monitoring it provides. With a service mesh, organizations gain insights into the behavior of their microservices, including traffic patterns, error rates, and latencies. This granular visibility allows for proactive troubleshooting and performance optimization. Tools integrated within the service mesh can visualize complex service interactions, making it easier to identify and address issues before they impact end-users.
### Simplifying Operations and DevOps
Managing microservices in a cloud environment can be complex and challenging. A cloud service mesh simplifies these operations by offering a consistent and unified approach to service management. It abstracts the complexities of service-to-service communication, allowing developers and operations teams to focus on building and deploying features rather than managing infrastructure. This leads to faster development cycles and more robust, resilient applications.

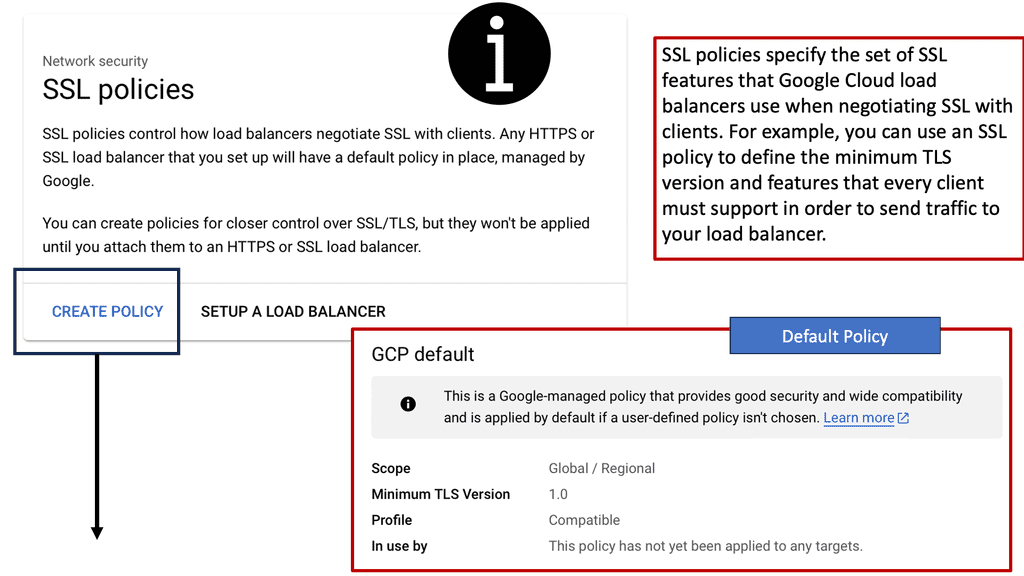
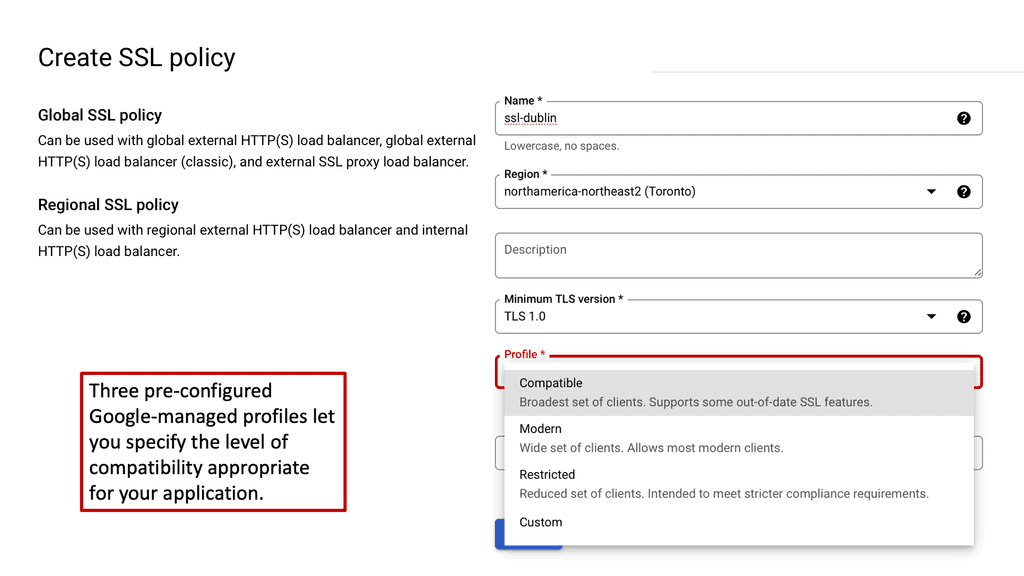 Google Cloud CDN
Google Cloud CDN
What is Cloud CDN?
Cloud CDN, short for Cloud Content Delivery Network, is a globally distributed network of servers that deliver web content to users with increased speed and reliability. By storing cached copies of content at strategically located edge servers, Cloud CDN significantly reduces latency and minimizes the distance data needs to travel, resulting in faster page load times and improved user experience.
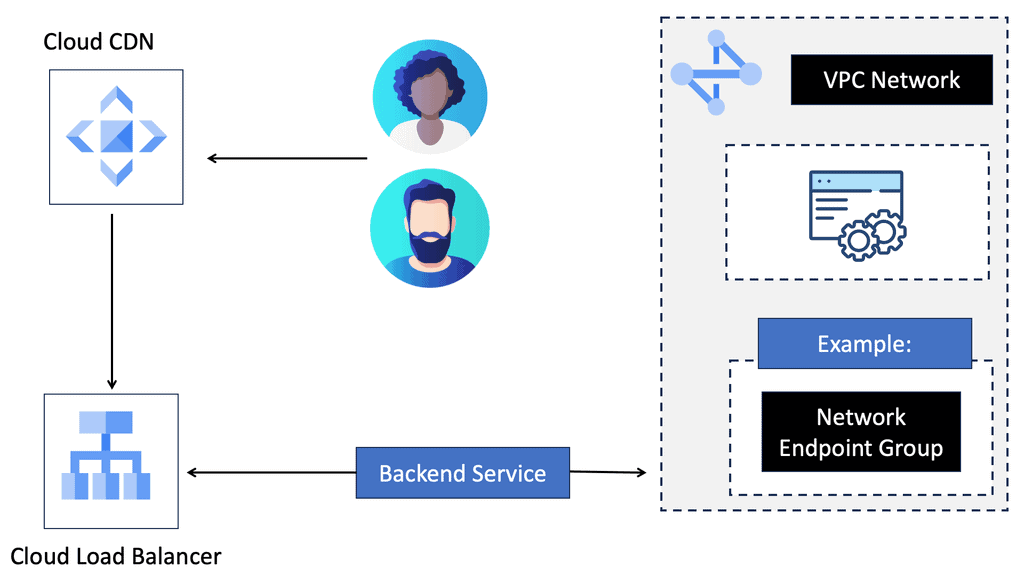
When a user requests content from a website, Cloud CDN intelligently routes the request to the nearest edge server to the user. If the requested content is already cached at that edge server, it is delivered instantly, eliminating the need to fetch it from the origin server. However, if the content is not cached, Cloud CDN retrieves it from the origin server and stores a cached copy for future requests, making subsequent delivery lightning-fast.
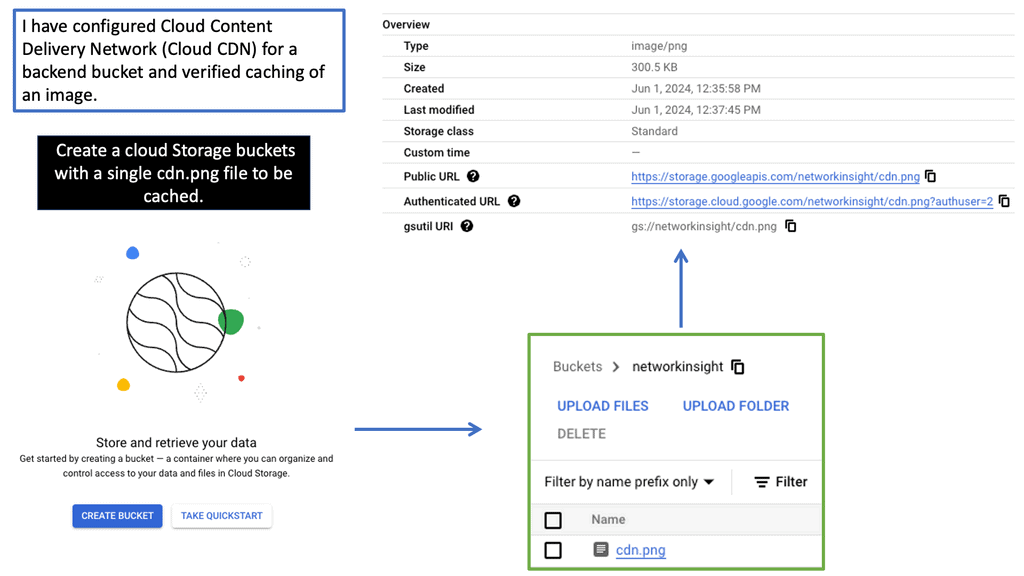
Load Balancer Scaling
How to scale the load balancer? When considering load balancer scaling and scalability, we need to recap the basics of scaling load balancers. A load balancer is a device that distributes network traffic across multiple servers. It provides an even distribution of traffic across multiple servers, so no single server is overloaded with requests. This helps to improve overall system performance and reliability. Load balancers can balance traffic between multiple web servers, application servers, and databases.
- Geographic Locations:
They can also be used to balance traffic between different geographic locations. Load balancers are typically configured to use round-robin, least connection, or source-IP affinity algorithms to determine how to distribute traffic. They can also be configured to use health checks to ensure that only healthy servers receive traffic. By distributing the load across multiple servers, the load balancer helps reduce the risk of server failure and improve overall system performance.
- Load Balancers and the OSI Model:
Load balancers operate at different Open Systems Interconnection ( OSI ) Layers from one data center to another; joint operation is between Layer 4 and Layer 7. The load balance function becomes the virtual representation of the application. Internal applications are represented by a virtual IP address ( VIP ). VIP acts as a front-end service to external clients’ requests. Data centers host unique applications with different requirements. Therefore, load balancing and scalability will vary depending on the housed applications.
- Understanding the Application:
For example, every application is unique regarding the number of sockets, TCP connections ( short-lived or long-lived ), idle time-out, and activities in each session regarding packets per second. Therefore, understanding the application structure and protocols is one of the most critical elements in determining how to scale the load balancer and design an effective load-balancing solution.
Techniques for Scaling Load Balancers
There are several strategies for scaling load balancers, each with its own benefits and ideal use cases:
1. **Vertical Scaling**: This involves increasing the capacity of your existing load balancer by upgrading its resources. While it is a straightforward approach, it has limitations in terms of cost and scalability.
2. **Horizontal Scaling**: This technique involves adding more load balancers to distribute the traffic effectively across a broader range of resources. It offers better redundancy and can accommodate larger loads but requires careful coordination between load balancers.
3. **Auto-scaling**: Implementing auto-scaling allows your infrastructure to dynamically adjust capacity based on real-time demand. This ensures that you only use the resources you need, thereby optimizing costs while maintaining performance.
**Scaling Up**
Scaling up is quite common for applications that need more power. Perhaps the database has grown so large that it no longer fits in memory, the disks may be full, or the database may be handling more requests and requiring more processing power than it used to.
Databases have traditionally been difficult to run on multiple machines, making them an excellent example of scaling up. When you try to make something work on two or more machines, many things that work on a single machine don’t. Do you know how to share tables efficiently across machines, for example? MongoDB and CouchDB are two new databases designed to work entirely differently since this is a challenging problem to solve.
**Scaling Out**
It’s here that things start to get interesting, which is why you picked up this book in the first place. In scaling out, you have multiple machines rather than a single one. The problem with scaling up is that you eventually reach a point where you can’t go any further. The capability of a single machine limits memory and processing power. If you need more than that, what should you do?
A single machine can’t handle so many visitors that people will tell you you’re in an envious position. You wouldn’t believe how nice it is to have such a problem! One of the great things about scaling out is that you can keep adding machines. Scaling out will certainly result in more compute power than scaling up, but you will run into space and power issues at some point.
Best Practices for Load Balancer Scaling
To successfully scale your load balancers, consider these best practices:
– **Monitor Traffic Patterns**: Analyze traffic trends to anticipate spikes and prepare your infrastructure accordingly.
– **Implement Robust Failover Strategies**: Ensure that your load balancers can handle failures gracefully without impacting the user experience.
– **Optimize Load Balancer Configurations**: Regularly review and optimize configurations to ensure that they align with current traffic demands.
Before you proceed, you may find the following post helpful:
Availability:
Load balancing plays a significant role in maintaining high availability for websites and applications. By distributing traffic across multiple servers, load balancers ensure that even if one server fails, others can continue handling incoming requests. This redundancy helps to minimize downtime and ensures uninterrupted service for users. In addition, load balancers can also perform health checks on servers, automatically detecting and redirecting traffic away from malfunctioning or overloaded servers, further enhancing availability.
Efficiency:
Load balancers optimize the utilization of computing resources by intelligently distributing incoming requests based on predefined algorithms. This even distribution prevents any single server from being overwhelmed, improving overall system performance. By utilizing load balancing, businesses can ensure that their servers operate optimally, using available resources and minimizing the risk of performance degradation or system failures.
Scale up and scale out:
How is this like load balancing in the computing world? It all comes down to having finite resources and attempting to make the best potential use of them. For example, you may have the goal of making your websites fast; to do that, you must route your requests to the machines best capable of handling them. To get around this, you need more resources.
For example, you can buy a giant machine to replace your current server, known as scale-up and pricey, or another small device that works alongside your existing server, known as scale-out. As noted, the biggest challenge in load balancing is trying to make many resources appear as one. So we can have load balancing with DNS, content delivery networks, and HTTP load balancing. We also need to balance our database and network connections.
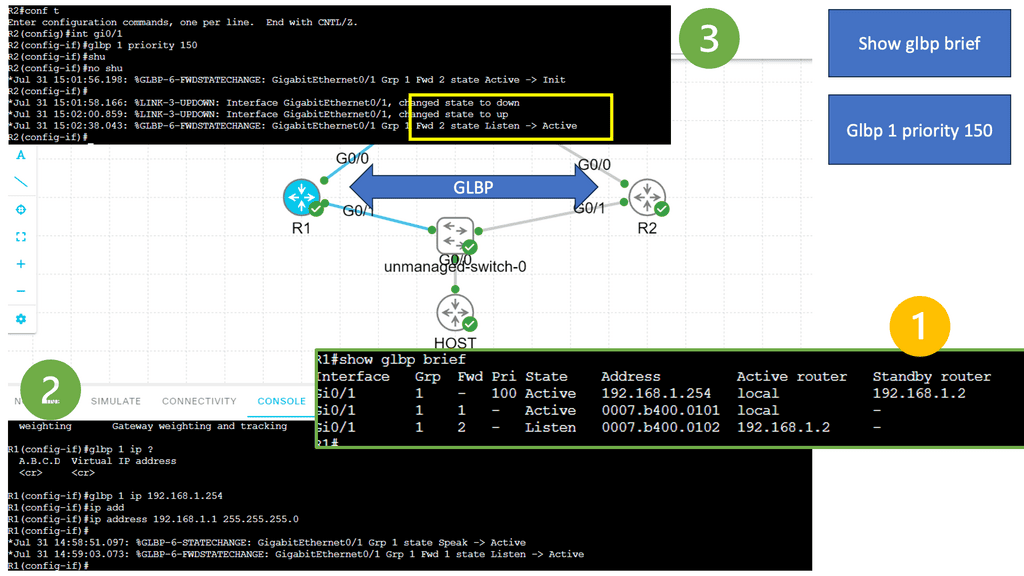
Guide on Gateway Load Balancing Protocol (GLBP)
GLBP is running between R1 and R2. The switch is not running GLPB and is used as an interconnection point. GLBP is often used internally between access layer switches and outside the data center. It is similar in operation to HSRP and VRRP. Notice that when we changed the priority of R2, its role changed to Active instead of Standby.
What is Load Balancer Scaling?
Load balancer scaling refers to the process of dynamically adjusting the resources allocated to a load balancer to meet the changing demands of an application. As the number of users accessing an application increases, load balancer scaling ensures that the incoming traffic is distributed evenly across multiple servers, preventing any single server from becoming overwhelmed.
**The Benefits of Load Balancer Scaling**
1. Enhanced Performance: Load balancers distribute incoming traffic among multiple servers, improving resource utilization and response times. By preventing any single server from overloading, load balancer scaling ensures a smooth user experience even during peak traffic.
2. High Availability: Load balancers play a crucial role in maintaining high availability by intelligently distributing traffic to healthy servers. If one server fails, the load balancer automatically redirects the traffic to the remaining servers, preventing service disruption.
3. Scalability: Load balancer scaling allows applications to quickly accommodate increased traffic without manual intervention. As the server load increases, additional resources are automatically allocated to handle the extra load, ensuring that the application can scale seamlessly as per the demands.
**Load Balancer Scaling Strategies**
1. Vertical Scaling: This strategy involves increasing individual servers’ resources (CPU, RAM, etc.) to handle higher traffic. While vertical scaling can provide immediate relief, it has limitations in terms of scalability and cost-effectiveness.
2. Horizontal Scaling: Horizontal scaling involves adding more servers to the application infrastructure to distribute the incoming traffic. Load balancers are critical in effectively distributing the load across multiple servers, ensuring optimal resource utilization and scalability.
3. Auto Scaling: Auto-scaling automatically adjusts the number of application instances based on predefined conditions. By monitoring various metrics like CPU utilization, network traffic, and response times, auto-scaling ensures that the application can handle increased traffic loads without manual intervention.
**Best Practices for Load Balancer Scaling**
1. Monitor and Analyze: Regularly monitor your application’s and load balancer’s performance metrics to identify any bottlenecks or areas of improvement. Analyzing the data will help you make informed decisions regarding load balancer scaling.
2. Implement Redundancy: To ensure high availability, deploy multiple load balancers in different availability zones. This redundancy ensures that even if one load balancer fails, the application remains accessible through the remaining ones.
3. Regularly Test and Optimize: Conduct load testing to simulate heavy traffic scenarios and verify the performance of your load balancer scaling setup. Optimize the configuration based on the test results to ensure optimal performance.
Example: Direct Server Return.
Direct server return (DSR) is an advanced networking technology that allows servers to send data directly to a client computer without going through an intermediary. This provides a more efficient and secure data transmission between the two, leading to faster speeds and better security.
DSR is also known as loopback, direct routing, or reverse path forwarding. It is essential in various applications, such as online gaming, streaming video, voice-over-IP (VoIP) services, and virtual private networks (VPNs).
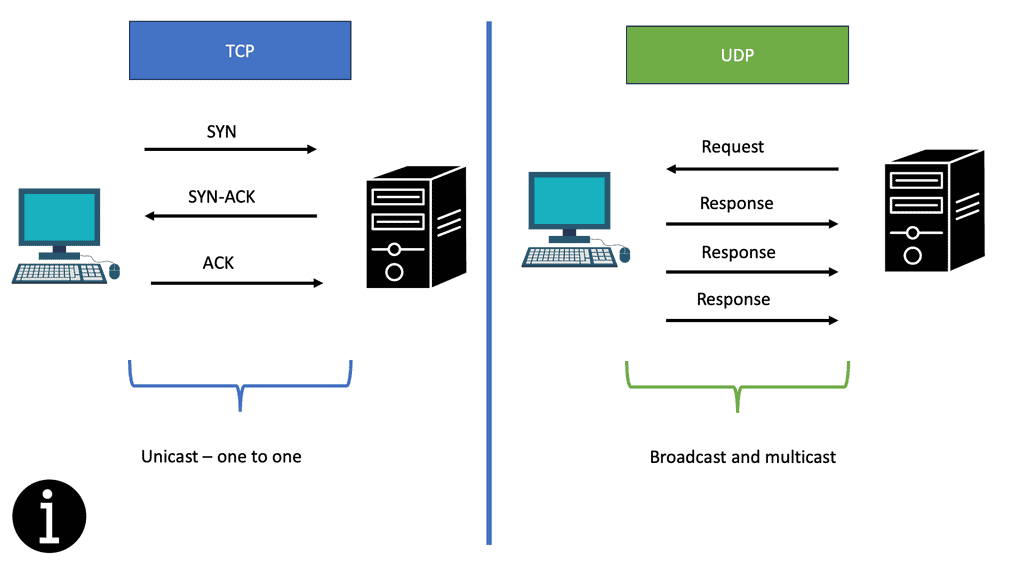
For example, the Real-Time Streaming Protocol ( RTSP ) is an application-level network protocol for multimedia transport streams. It is used in entertainment and communications systems to control streaming media servers. With this application requirement case, the initial client connects with TCP; however, return traffic from the server can be UDP, bypassing the load balancer. For this scenario, the load-balancing method of Direct Server Return is a viable option.
DSR is an excellent choice for high-speed, secure data transmission applications. It can also help reduce latency and improve reliability. For example, DSR can help reduce lag and improve online gaming performance.
How to scale load balancer
This post will first address the different load balancer scalability options: scale-up and scale-out. Scale-out is generally the path of scaling load balancers we see today, mainly as the traffic load, control, and data plane are spread across VMs or containers that are easy to spin up and down, commonly seen for absorbing DDoS attacks.
We will then discuss how to scale load balancer and the scalability options in the application and at a network load balancing level. We will finally address the different design options for load balancing, such as user session persistence, destination-only NAT, and persistent HTTP sessions.
Scaling a load balancer lets you adjust its performance to its workload by changing the number of nodes it contains. You can scale the load balancer up or down at any time to meet your traffic needs. So, when considering how to scale a load balancer, you must first look at the application requirements and work it out from there. What load do you expect?
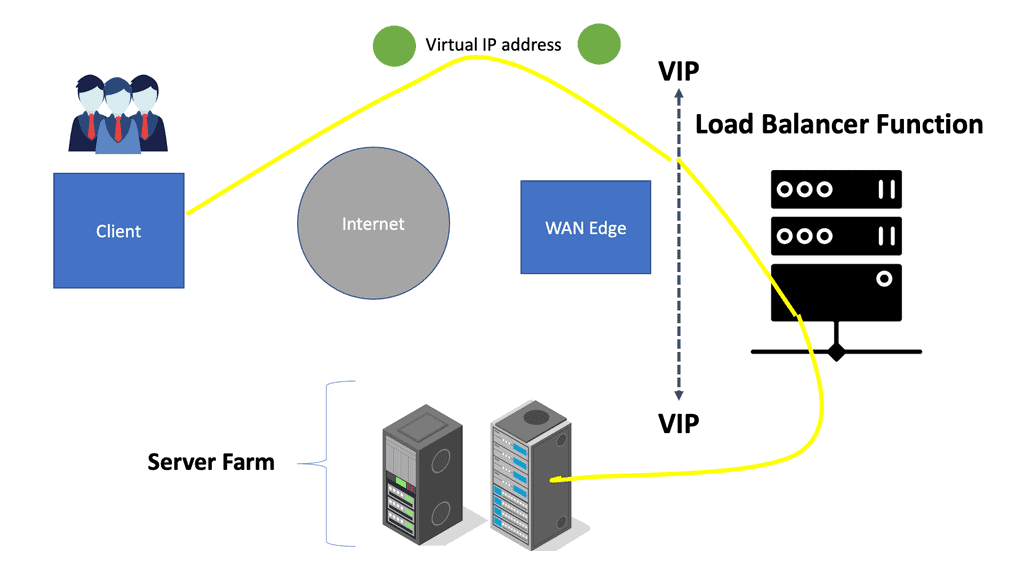
In the diagram below, we see the following.
- Virtual IP address: A virtual IP address is an IP address that is used to virtualize a computer’s identity on a local area network (LAN). The network address translation (NAT) form allows multiple devices to share a public IP address.
- Load Balancer Function: The load balancer is configured to receive client requests and route them to the most appropriate server based on a defined algorithm.
The primary benefit of load balancer scaling is that it provides scalability. Scalability is the ability of a networking device or application to handle organic and planned network growth. Scalability is the main advantage of load balancing, and in terms of application capacity, it increases the number of concurrent requests data centers can support. So, in summary, load balancing is the ability to distribute incoming workloads to multiple end stations based on an algorithm.
Load balancers also provide several additional features. For example, they can be configured to detect and remove unhealthy servers from the pool of available servers. They also offer SSL encryption, which can help to protect sensitive data being passed between clients and servers. Finally, they can perform other tasks like URL rewriting and content caching.
Load Balancing | Load Balancing Algorithm |
Load Balancing Method 1 | Round Robin Load Balancing |
Load Balancing Method 2 | Weighted Round Robin Load Balancing |
Load Balancing Method 3 | URL Hash Load Balancing |
Load Balancing Method 4 | Least Connection Method |
Load Balancing Method 5 | Weighted Least Connection Method |
Load Balancing Method 6 | Least Response Time Method |
Load Balancing with Routers
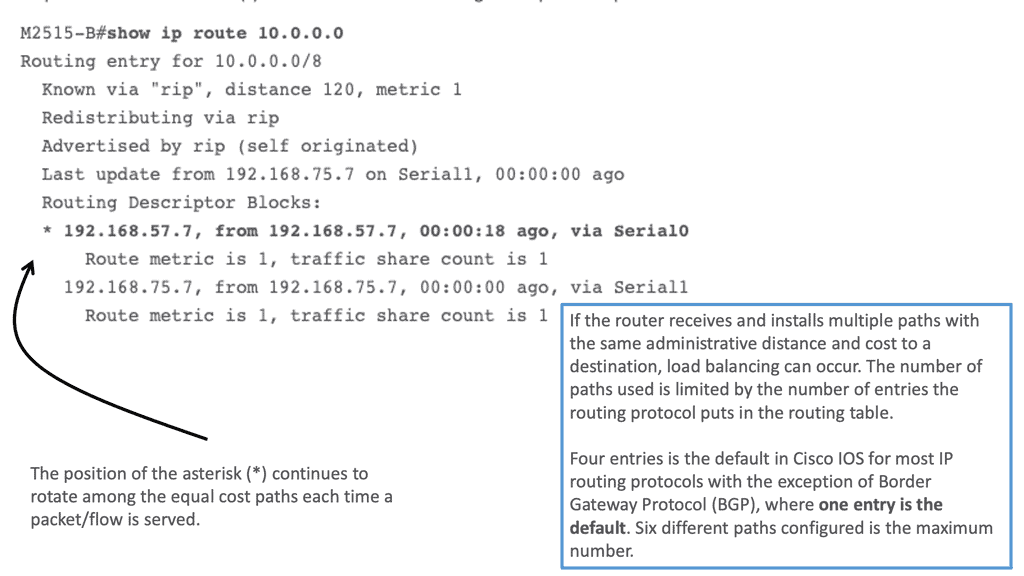
Load Balancing is not limited to load balancer devices. Routers also perform load balancing with routing. Across all Cisco IOS® router platforms, load balancing is a standard feature. The router automatically activates this feature when multiple routes to a destination are in the routing table.
Routing Information Protocol (RIP), RIPv2, Enhanced Interior Gateway Routing Protocol (EIGRP), Open Shortest Path First (OSPF), and Interior Gateway Routing Protocol (IGRP) are standard routing protocols or derived from static routing and packet forwarding protocols. When forwarding packets, RIP allows a router to use multiple paths.
- For process-switching — load balancing is on a per-packet basis, and the asterisk (*) points to the interface over which the next packet is sent.
- For fast-switching — load balancing is on a per-destination basis, and the asterisk (*) points to the interface over which the next destination-based flow is sent.
Load Balancer Scalability
Scaling load balancers with Scale-Up or Scale-Out
a) Scale-up—Expand linearly by buying more servers, adding CPU and memory, etc. Scale-up is usually done on transaction database servers as these servers are difficult to scale out. Scaling up is a simple approach but the most expensive and nonlinear. Old applications were upgraded by scaling up ( vertical scaling )—a rigid approach that is not elastic. In a virtualized environment, applications are scaled linearly in a scale-out fashion.
b) Scale-out—Add more parallel servers, i.e., scale linearly. Scaling out is more accessible on web servers; add additional web servers as needed. Netflix is an example of a company that designs by scale-out. It spins up Virtual Machines ( VM ) on-demand due to daily changes in network load. Scaling out is elastic and requires a load-balancing component. It is an agile approach to load balancing.
Shared states limit the scalability of scale-out architectures, so try to share and lock as few states as possible. An example of server locking is Amazon’s eventual consistency approach, which limits the amount of transaction locking—shopping cards are not checked until you click “buy.”
Scale up load balancing
A load balancer scale-up is the process of increasing the capacity of a load balancer by adding more computing resources. This can increase the system’s scalability or provide redundancy in case of system failure. The primary goal of scaling up a load balancer is to ensure the system can handle the increased workload without compromising performance.
Scaling up a load balancer involves adding more hardware and software resources, such as CPUs, RAM, and hard disks. These resources will enable the system to process requests more quickly and efficiently. When scaling up a load balancer, consider its architecture and the types of requests it will handle.
Different types of requests require different computing resources. For example, if the load balancer handles high-volume requests, it is essential to ensure that the system has enough CPUs and RAM to handle them.
Considering the network topology when scaling up a load balancer is also essential. The network topology defines how the load balancer will communicate with other systems, such as web servers and databases. If the network topology is not configured correctly, the system may be unable to handle the increased load. Finally, monitoring the system after scaling up a load balancer is essential. This will ensure that the system performs as expected and that the increased capacity is used effectively. Monitoring the system can also help detect potential issues or performance bottlenecks.
By scaling up a load balancer, organizations can increase the scalability and redundancy of their system. However, it is essential to consider the architecture, types of requests, network topology, and monitoring when scaling up a load balancer. This will ensure the system can handle the increased workload without compromising performance.
Additional information: Scale-out load balancing
Scaling out a load balancer adds additional load balancers to distribute incoming requests evenly across multiple nodes. The process of scaling out a load balancer can be achieved in various ways. Organizations can use virtualization or cloud-based solutions to add additional load balancers to their existing systems. Some organizations prefer to deploy their servers or use their existing hardware to scale the load balancer.
Regardless of the chosen method, the primary goal should be to create a reliable and efficient system that can handle increasing requests. This can be done by evenly distributing the load across multiple nodes, ensuring that every node is manageable and manageable. Additionally, organizations should consider deploying additional load balancer resources, such as memory, disk space, or CPU cores.
Finally, organizations should constantly monitor the load balancer’s performance to ensure the system runs optimally. This can be done by tracking the load-balancing performance, analyzing the response time of requests, and providing that the system can handle unexpected spikes in traffic.
Load Balancer Scalability: The Operations
The virtual IP address and load balancing control plane
Outside is a VIP, and inside is a pool of servers. A load balancer scaling device is configured for rules associating outside IP and port numbers with an inside pool of servers. Clients only know the outside IP address through, for example, DNS replies. The load-balancing control plane monitors the servers’ health and determines which can accept requests.
The client sends a TCP SYN packet, which the load balancer device intercepts. The load balancer performs a load-balancing algorithm and sends it to the best server destination. To get the request to the server, you can use Tunnelling, NAT, or two TCP sessions. In some cases, the load balancer will have to rewrite the content. Whatever the case, the load balancer has to create a session to know that this client is associated with a particular inside server.
Local and global load balancing
Local server selection occurs within the data center based on server load and application response times. Any application that uses TCP or UDP protocols can be load-balanced. Whereas local load balancing determines the best device within a data center, global load balancing chooses the best data center to service client requests.
Global load balancing is supported through redirection based on DNS and HTTP. HTTP mechanism provides better control, while DNS is fast and scalable. Both local and global appliances work hand-in-hand; the local device feeds information to the global device, enabling it to make better load-balancing decisions.
Load Balancer Scaling Types
Application-Level Load Balancer Scalability: Load balancing is implemented between tiers in the applications stack and carried out within the application. It is used in scenarios where applications are coded correctly, making it possible to configure load balancing in the application. Designers can use open-source tools with DNS or another method to track flows between tiers of the application stack.
Network-Level Load Balancer Scalability: Network-level load balancing includes DNS round-robin, Anycast, and Layer 4 – Layer 7 load balancers. Web browser clients do not usually have built-in application layer redundancy, which pushes designers to look at the network layer for load-balancing services. If applications were designed correctly, load balancing would not be a network-layer function.
Application-level load balancing
Application-level load balancer scaling concerns what we can do inside the application to provide load-balancing services. The first thing you can do is scale up—add a more worker process. Clients issue requests that block some significant worker processes and that resource is tied to TCP sessions. If your application requires session persistence ( long-lived TCP sessions ), you block worker processes even if the client is not sending data. The solution is FastCGI or changing the webserver to Nginx.
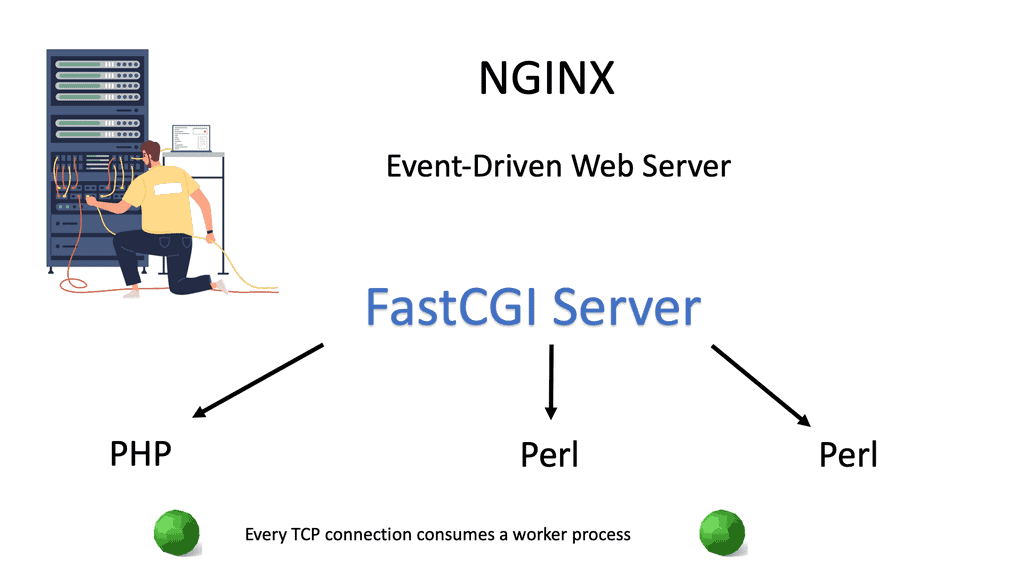
- A key point: Nginx
Nginx is event-based. On Apache ( not event-based), every TCP connection consumes a worker process, but with Nginx, a client connection takes no processes unless you are processing an actual request. Generally, Linux is poor at processing many simultaneous requests.
Nginx does not use threads and can easily have 100,000 connections. With Apache, you lose 50% of the performance, and adding CPU doesn’t help. With around 80,000 connections, you will experience severe performance problems no matter how many CPUs you add. Nginx is by far a better solution if you expect a lot of simultaneous connections.
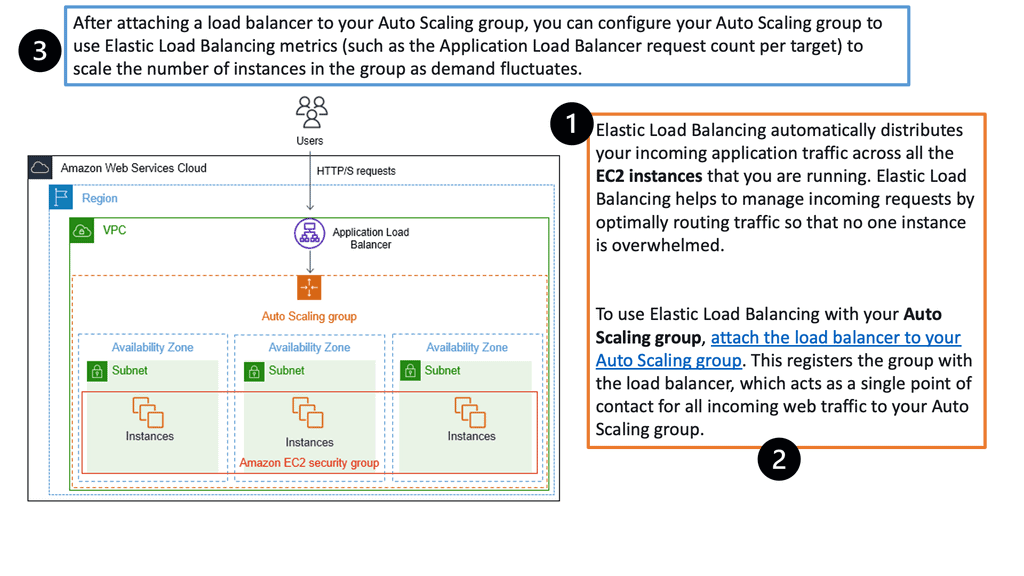
Example: Load Balancing with Auto Scaling groups on AWS.
The following looks at an example of load balancing in AWS. Registering your Auto Scaling group with an Elastic Load Balancing load balancer helps you set up a load-balanced application. Elastic Load Balancing works with Amazon EC2 Auto Scaling to distribute incoming traffic across your healthy Amazon EC2 instances.
This increases your application’s scalability and availability. In addition, you can enable Elastic Load Balancing within multiple Availability Zones to increase your application’s fault tolerance. Elastic Load Balancing supports different types of load balancers. A recommended load balancer is the Application Load Balancer.
Network-based load balancing
First, try to solve the load balancer scaling in the application. When you cannot load balance solely using applications, turn to the network for load-balancing services.
DNS round-robin load balancing
The most accessible type of network-level load balancing is DNS round robin. DNS server that keeps track of application server availability. The DNS control plane distributes user traffic over multiple servers round-robin. However, it does come with caveats:
- DNS does not know server health.
- DNS caching problems.
- No measures are available to prevent DoS attacks against servers.
Clients ask for the IP of the web server, and the DNS server replies with an IP address in random order. This works well if the application uses DNS. However, some applications use hard-coded IP addresses; you can’t rely on DNS-based load balancing in these scenarios.
DNS load balancing also requires low TTL times, so the client will often ask the servers. Generally, DNS-based load balancing works well, but not with web browsers. Why? DNS pinning.
DNS pinning
This is because there have been so many attacks on web browsers, and browsers now implement a security feature called DNS pinning. DNS pinning is a method whereby you get the server’s IP address, and even though the TTL has expired, you ignore the DNS TTL and continue to use the URL.
It prevents people from spoofing DNS records and is usually built-in to browsers. DNS load balancing is perfect if the application uses DNS and listens to DNS TTL times. But unfortunately, web browsers are not in that category.
IP Anycast load balancing
IP Anycast provides geographic server load balancing. The idea is to use the same IP address on multiple POPs. Routing in the core will choose the closest POP, routing the client to the nearest POP. All servers have the same IP address configured on loopback.
Address Resolution Protocol (ARP) replies would clash if the same IP address were configured on the LAN interface. Use any routing mechanism to generate an Equal Cost Multi-Path (ECMP) for loopback addresses. For example, static routes are based on IP SLA, or you can use OSPF between the server and router.
Best for UDP traffic
The router will load balance based on a 5-tuple as requests come in. Do not load the balance on destination addresses /ports, as they are always the same. It is usually done using the source client’s IP address/port number. The process takes the 5-tuple and creates a hash value, which makes independent paths based on that value. This works well for UDP traffic and how root servers work. It is also good for DNS server load balancing.
It works well for UDP as every request from the client is independent. TCP does not work like this, as TCP has sessions. It recommended not to use Anycast load balancing for TCP traffic. You need an actual load balancer if you want to load-balance TCP traffic. This could be a software package, Open Source ( HAproxy ), or a dedicated appliance.
**Scaling load balancers at Layer 2**
Layer 2 designs refer to the load balancer in bridged mode. As a result, all load-balanced and non-load-balanced traffic to and from the servers goes through the load-balancing device. The device bridges two VLANs together in the same IP subnet. Essentially, the load balancer acts as a crossover cable, merging two VLANs.
The critical point is that the client and server sides are in the same subnet. As a result, layer 2 implementations are much more accessible than layer 3 implementations, as there are no changes to IP addresses, netmasks, and default gateway settings on servers. However, with a bridged design, be careful about introducing loops and implementing spanning tree protocol ( STP ).
**Scaling load balancers at Layer 3**
With layer 3 designs, the load-balancing device acts in routed mode. Therefore, all load-balanced and non-load-balanced traffic to and from the server goes through the load-balancing device. The device routes between two different VLANs that are in two different subnets.
The critical point and significant difference between layer 3 and layer 2 designs are client-side VLANs and server-side VLANs in different subnets. Therefore, the VLANs are not merged, and the load-balancing device routes between VLANs. Layer 3 designs may be more complex to implement but will eventually be more scalable in the long run.
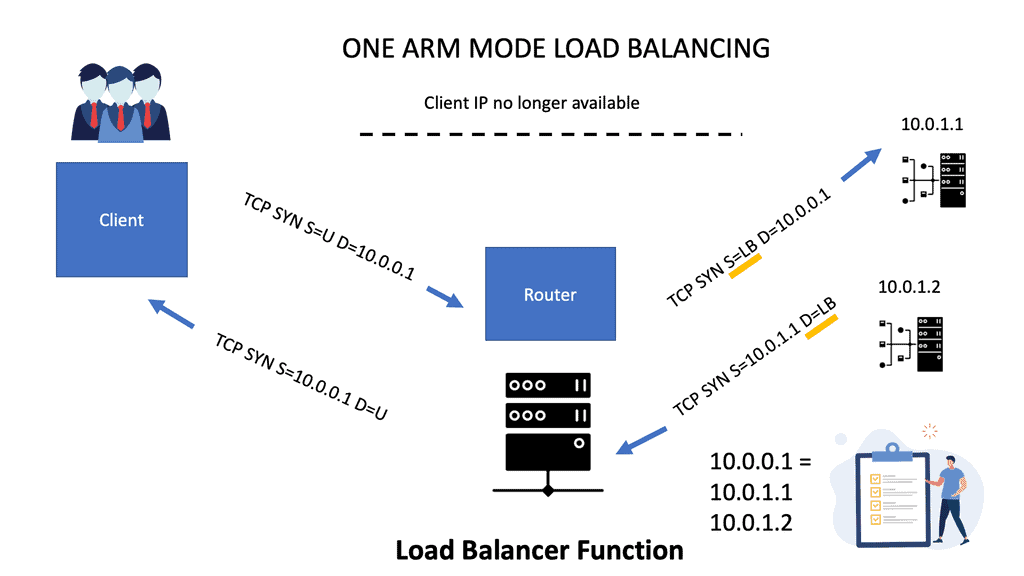
Scaling load balancers with One-ARM mode
One-armed mode refers to a load-balancing device, not in the forwarding path. The critical point is that the load balancer resides on its subnet and has no direct connectivity with server-side VLAN. A vital advantage of this model is that only load-balanced traffic goes through the device.
Server-initiated traffic bypasses the load balancer and changes both source and destination IP addresses. The load balancer terminates outside TCP sessions and initiates new inside TCP sessions. When the client connection comes in, you take the source IP and port number, put them in connection tables, and associate them with the load balancer’s TCP port number and IP.
As everything comes from the load balance IP address, the servers can no longer see the original client. On the right-hand side of the diagram below, the source and destination traffic flow on the server side is the load balancer. The VIP addresses 10.0.0.1, and that is what the client connects to.
The use of X-forwarder-for HTTP header
We use the X-forwarder-for HTTP header to indicate to the server which the original client is. The client’s IP address is replaced with the load balancer’s IP address. The load balancer can insert the X-Forwarders-for HTTP header, where they copy the client’s original IP address into the extra HTTP header—“X-forward-for header.” Apache has a standard that copies the value of this header into the standard CGI variable so all the scripts can pretend no load balancer exists.
The load balancer inserts data into the TCP session; in other words, it has to take ownership of the TCP sessions, so it needs to take control of TCP activities, including buffering, fragmentation, and reassembling. Modifying HTTP requests is hard. F5 has an accelerated mode of TCP load balancing.
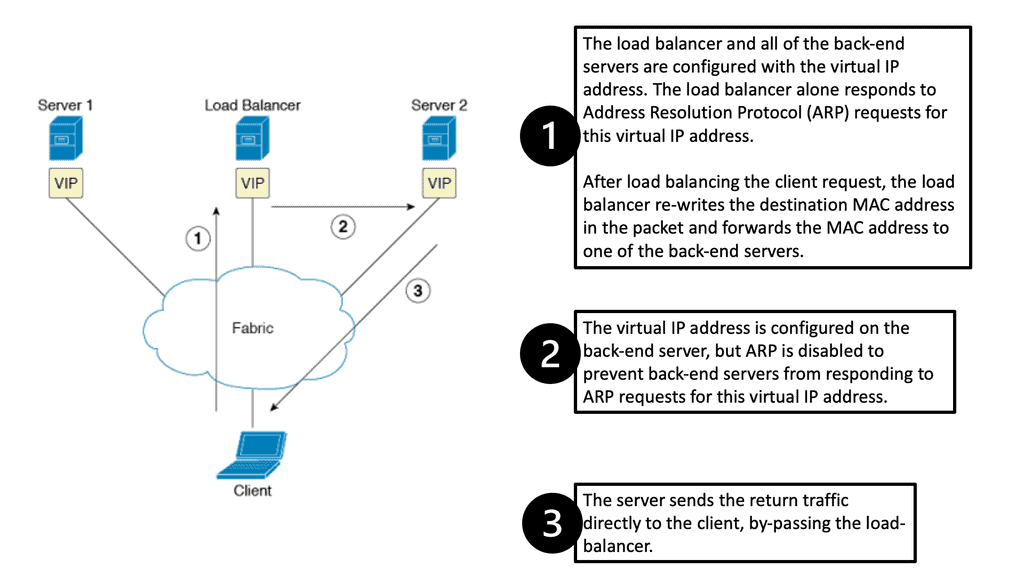
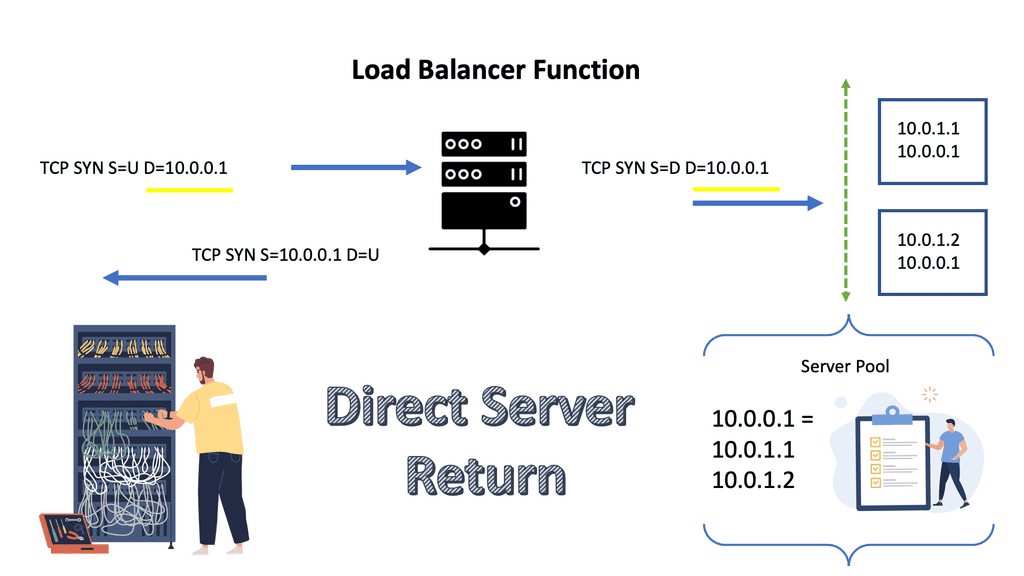
Scaling load balancers with Direct Server Return
Direct Server Return is when the same IP address is configured on all hosts. The same IP is configured on the loopback interface, not the LAN interface. The LAN IP address is only used for ARP, so the load balancer would send ARP requests only for the LAN IP address, rewrite the MAC header ( not TCP or HTTP alterations ), and send the unmodified IP packet to the selected server.
The server sends the reply to the client and does not involve the load balancer. As load balancing is done on the MAC address, it requires layer 2 connectivity between the load balancer and servers ( example: Linux Virtual Server ). Also, a tunneling method that uses Layer 3 between the load balancer and servers is available.
- A key point: MTU issues
If you do not have layer 2 connectivity, you can use tunnels, but be aware of MTU issues. Make sure the Maximum Segment Size ( MSS ) on the server is reduced so you do not have a PMTU issue between the client and server.
With direct server return, how do you ensure the reply is from the loopback, not the LAN address? If you are using TCP, the TCP session’s IP address is dictated by the original TCP SYN packet, so this is automatic.
However, UDP is different as UDP leaving is different from UDP coming in. So, in UDP cases, you need to set the IP address manually with the application or with iptables. But for TCP, the source in the reply is always copied from the destination IP address in the original TCP SYN request.
Scaling load balancers with Microsoft network load balancing
Microsoft load balancing is the ability to implement load balancing without load balancers. Instead, create a cluster IP address for the server and then use the flooding behavior to send it to all servers.
Clients send a packet to the shared cluster IP address associated with a client’s MAC address. This cluster MAC does not exist anywhere. When the request arrives at the last Layer 3 switch, it sends an ARP request: “Who has this IP address?”?.
ARP requests arrive at all the servers. So, when the client packet arrives, it is sent to the cluster’s bogus MAC address. Because the MAC address has never been associated with any source, all the traffic is flooded from the Layer 2 switch to the servers. The performance of the Layer 2 switch falls massively as unicast flooding is done in software.
The use of Multicast
Microsoft then changed this to use Multicast. This does not work, and packets are dropped as an illegal source of MAC when using a multicast MAC address. Cisco routers drop ARP packets with the source MAC address as multicast. To overcome this, configure static ARP entries. Microsoft also implements IGMP to reduce flooding.
Load Balancing Options
User session persistence ( Stickiness )
The load balancer must keep all session states, even for inactive sessions. Session persistence creates much more state than just the connection table. Some web applications store client session data on the servers, so sessions from the same client must go to the same server. This is particularly important when SSL is deployed for encryption or where shopping carts are used.
The client establishes an HTTP session with the webserver and logs in. After login, the HTTPS session from the same client should land on the same web server to which the client logged in using the initial HTTP request. The following are ways load balancers can determine who the source client is.

- Source IP address – > Problem may arise with large-scale NAT designs.
- Extra HTTP cookies – > May require the load balancer to take ownership of the TCP session.
- SSL session ID -> The session Will remain persistent even if the client is roaming and the client’s IP address changes.
Data path programming
F5 uses scripts that act on packets, triggering the load-balancing mechanism. You can select the server, manipulate HTTP headers, or even manipulate content. For example, the load balancer can add caching headers in MediaWiki (which does not change content / caching headers ). The load balancer adds the headers that allow the content to be cached.
Persistent HTTP sessions
The client has a long-lived HTTP session to eliminate one RTT and congestion window problem; then, we have a short-lived session from the load balancer to the server. SPDY is a next-generation HTTP with multiple HTTP sessions over one TCP session. This is useful in high-latency environments such as mobile devices. F5 has a SPDY-to-HTTP gateway.
Destination-only NAT
The server rewrites the destination IP address to the actual server’s destination IP and then forwards the packet. The reply packet has to hit the load balancer, as the load balancer has to replace the server’s source IP with the load balancer’s source IP. The client IP does not change, so the server talks directly with the client. This allows the server to do address-based access control or GEO location based on the source address.
Understanding Browser Caching
Browser caching is the process of storing static files locally on a user’s device to reduce load times when revisiting a website. By leveraging browser caching, web developers can instruct browsers to store certain resource files, such as images, CSS, and JavaScript, for a specified period. This way, subsequent visits to the website become faster as the browser doesn’t need to fetch those files again.
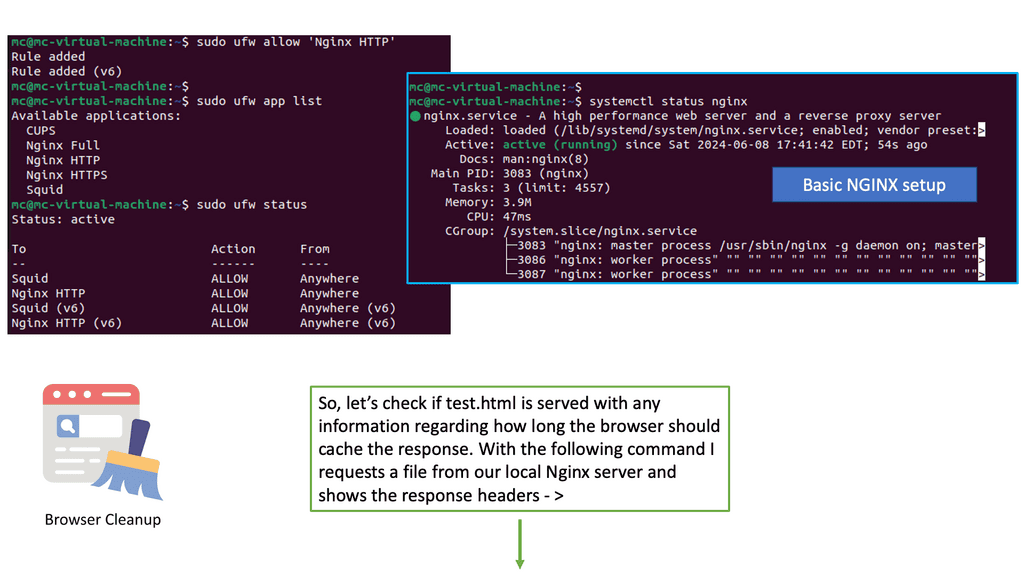
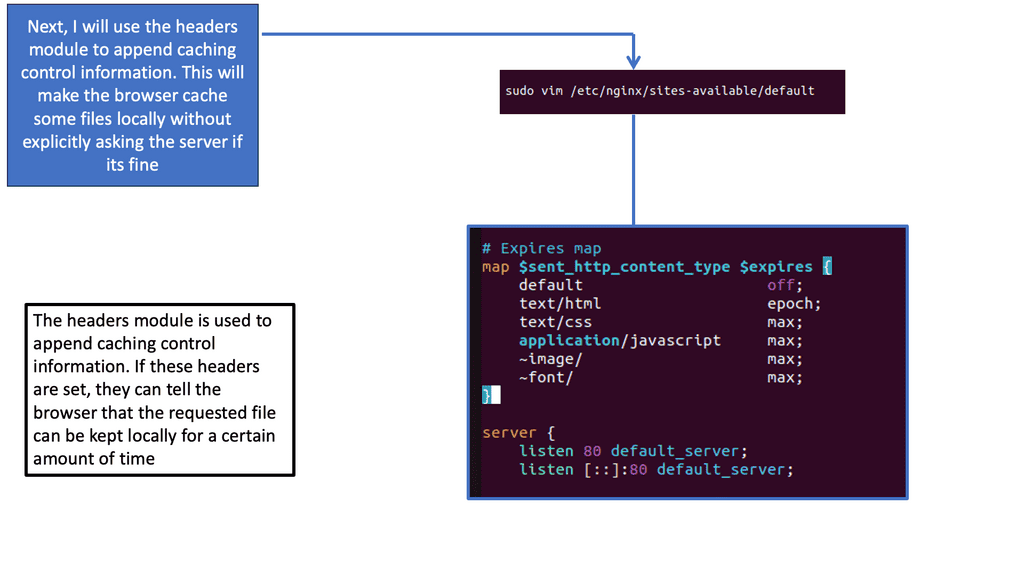
Nginx, a popular web server and reverse proxy server, offers a powerful module called “header” that enables fine-grained control over HTTP response headers. With this module, web developers can easily configure caching directives and optimize how browsers cache static resources. By setting appropriate cache-control headers and expiration times, you can dictate how long a browser should cache specific files.
To leverage the browser caching capabilities of Nginx’s header module, you need to configure your server block or virtual host file. First, ensure that the module is installed and enabled. Then, within the server block, you can use the “add_header” directive to set the cache-control headers for different file types. For example, you can instruct the browser to cache images for a month, CSS files for a week, and JavaScript files for a day.
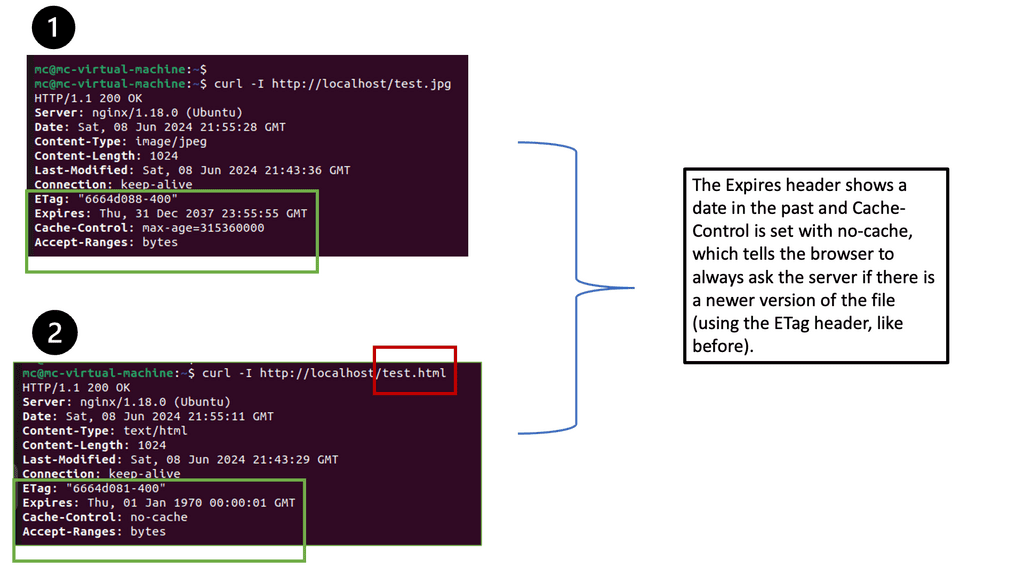
After configuring the caching directives, it’s crucial to verify if the changes are properly applied. There are various tools available, such as browser developer tools and online caching checkers, that can help you inspect the response headers and check if the caching settings are working as intended. By ensuring the correct headers are present, you can confirm that browsers will cache the specified resources.

Final Point: Scaling Load Balancing
As your user base grows, so does the demand on your servers. Without proper scaling, you risk overloading your systems, leading to slowdowns or even crashes. Load balancer scaling helps manage this growth seamlessly. By dynamically adjusting to traffic demands, scaling ensures that resources are used efficiently, providing users with a smooth experience regardless of traffic spikes.
There are primarily two types of load balancer scaling: vertical and horizontal. Vertical scaling involves adding more power to an existing server, such as increasing CPU or RAM. While effective, there’s a limit to how much you can scale vertically. Horizontal scaling, on the other hand, involves adding more servers to distribute the load. This approach is more flexible and can handle larger traffic volumes more effectively.
Implementing load balancer scaling requires careful planning and consideration of your infrastructure needs. It’s important to choose the right tools and technologies that align with your application requirements. Solutions like AWS Elastic Load Balancing or Google Cloud Load Balancing offer robust scaling options that can be tailored to your specific needs. Monitoring and analytics tools are also essential to predict traffic patterns and scale resources proactively.
To get the most out of load balancer scaling, consider these best practices:
1. **Monitor Performance Metrics:** Continuously track key performance indicators to identify when scaling is necessary.
2. **Automate Scaling Processes:** Implement automation to respond quickly to traffic changes, reducing the risk of manual errors.
3. **Test Scaling Strategies:** Regularly test your scaling strategies in a controlled environment to ensure they work as expected.
4. **Optimize Resource Allocation:** Use analytics to allocate resources efficiently, minimizing costs while maximizing performance.

- DMVPN - May 20, 2023
- Computer Networking: Building a Strong Foundation for Success - April 7, 2023
- eBOOK – SASE Capabilities - April 6, 2023