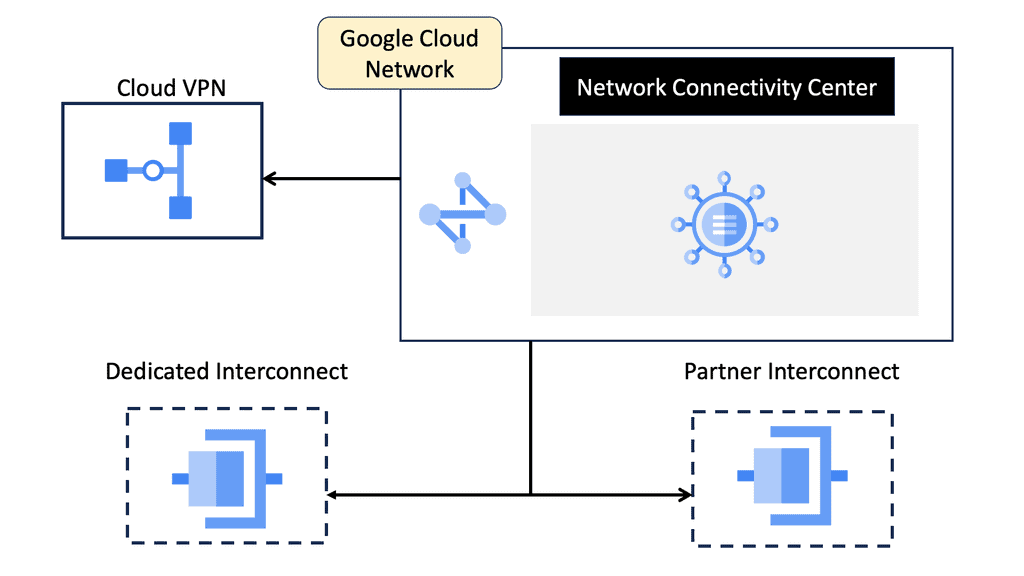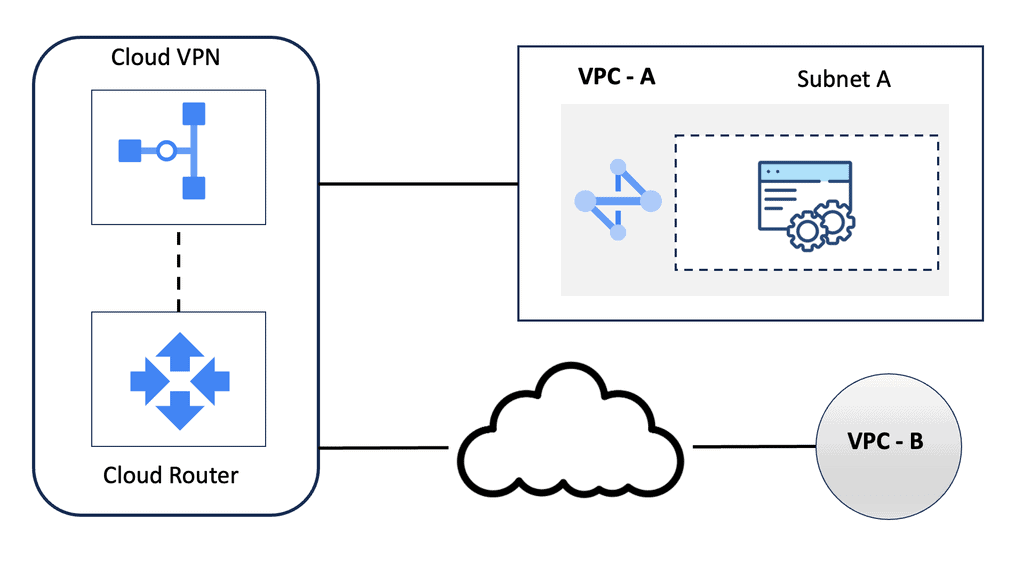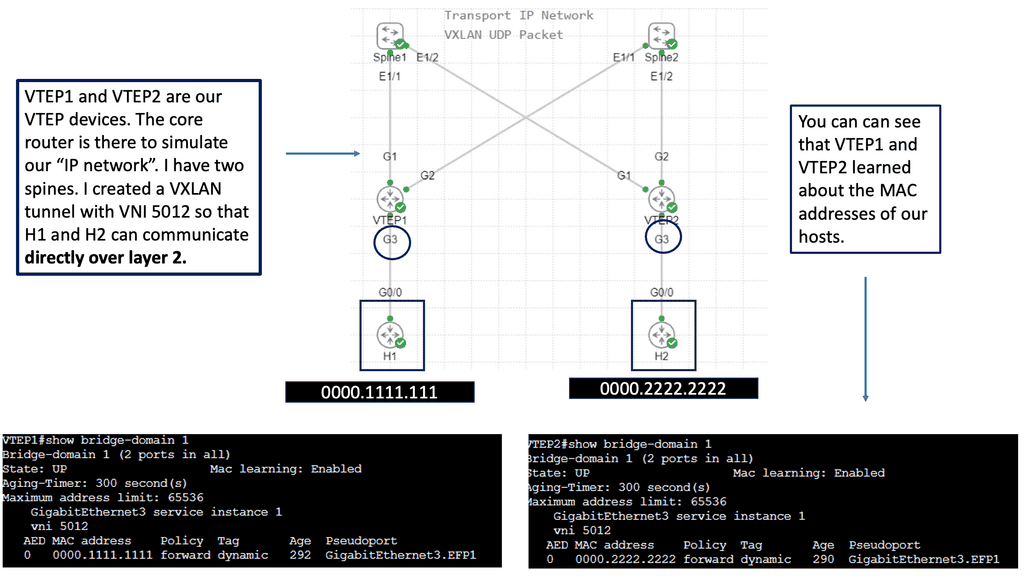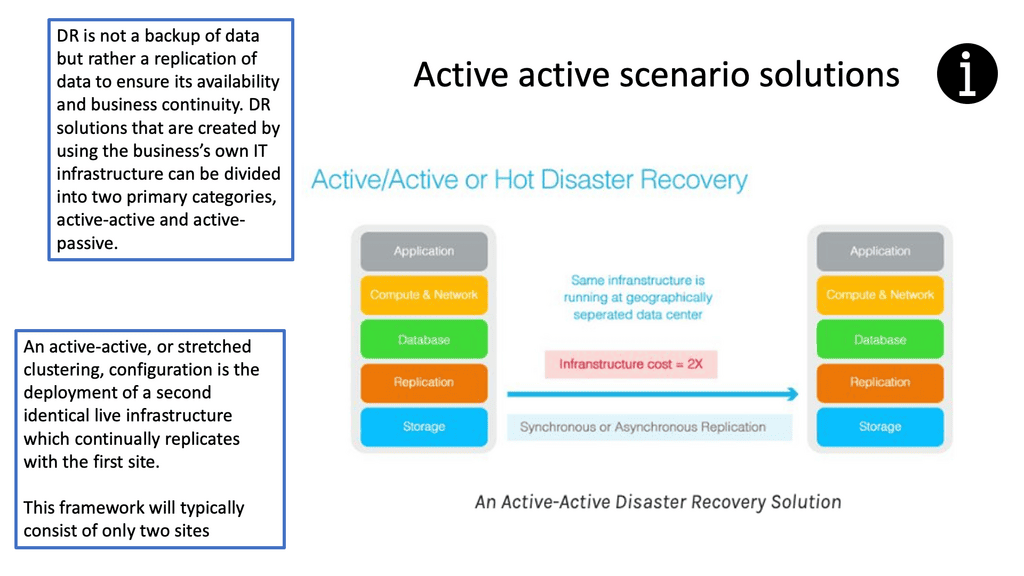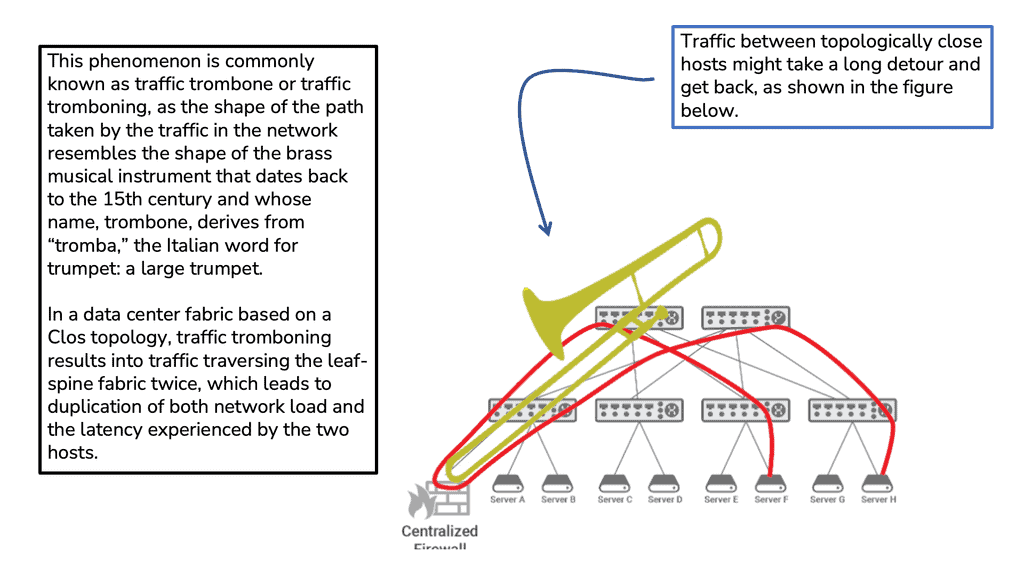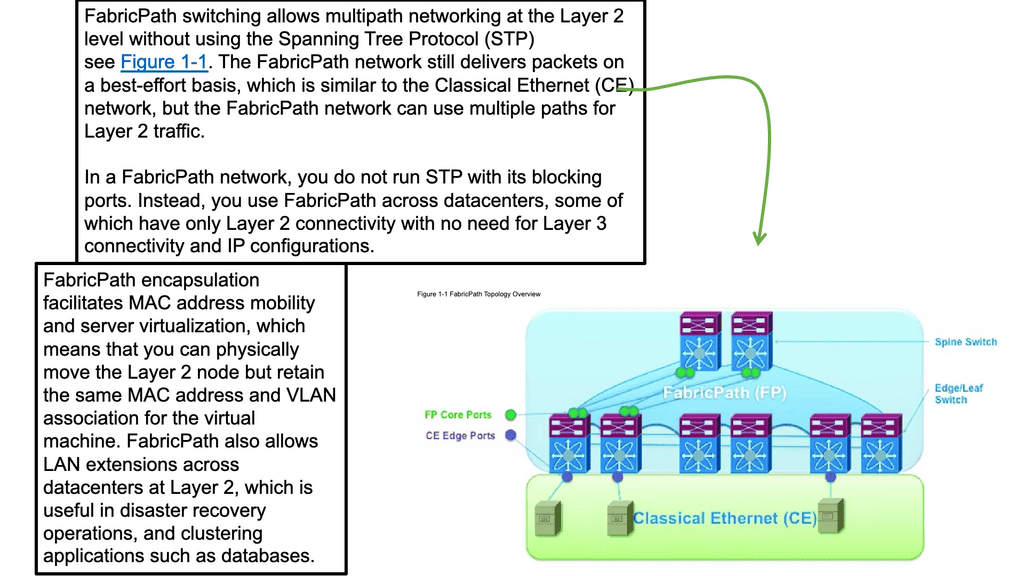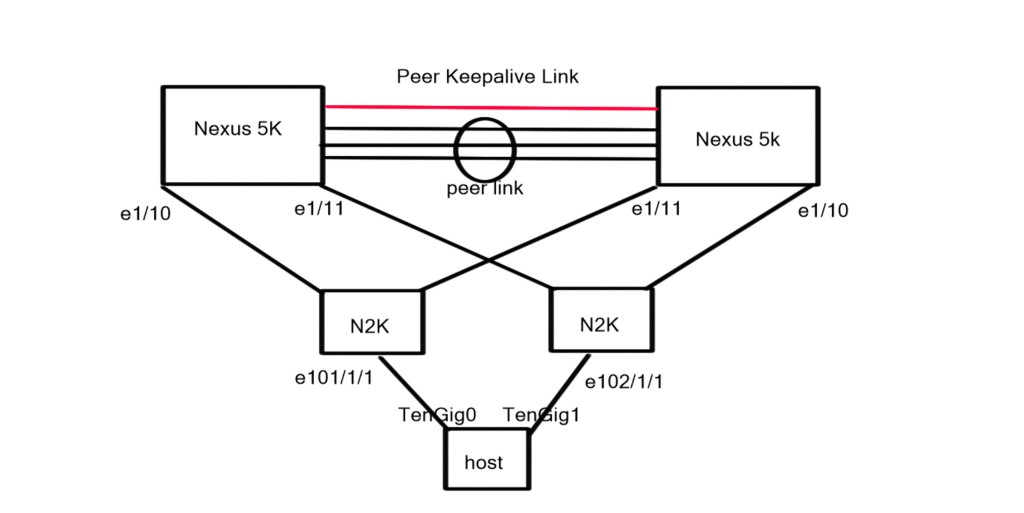
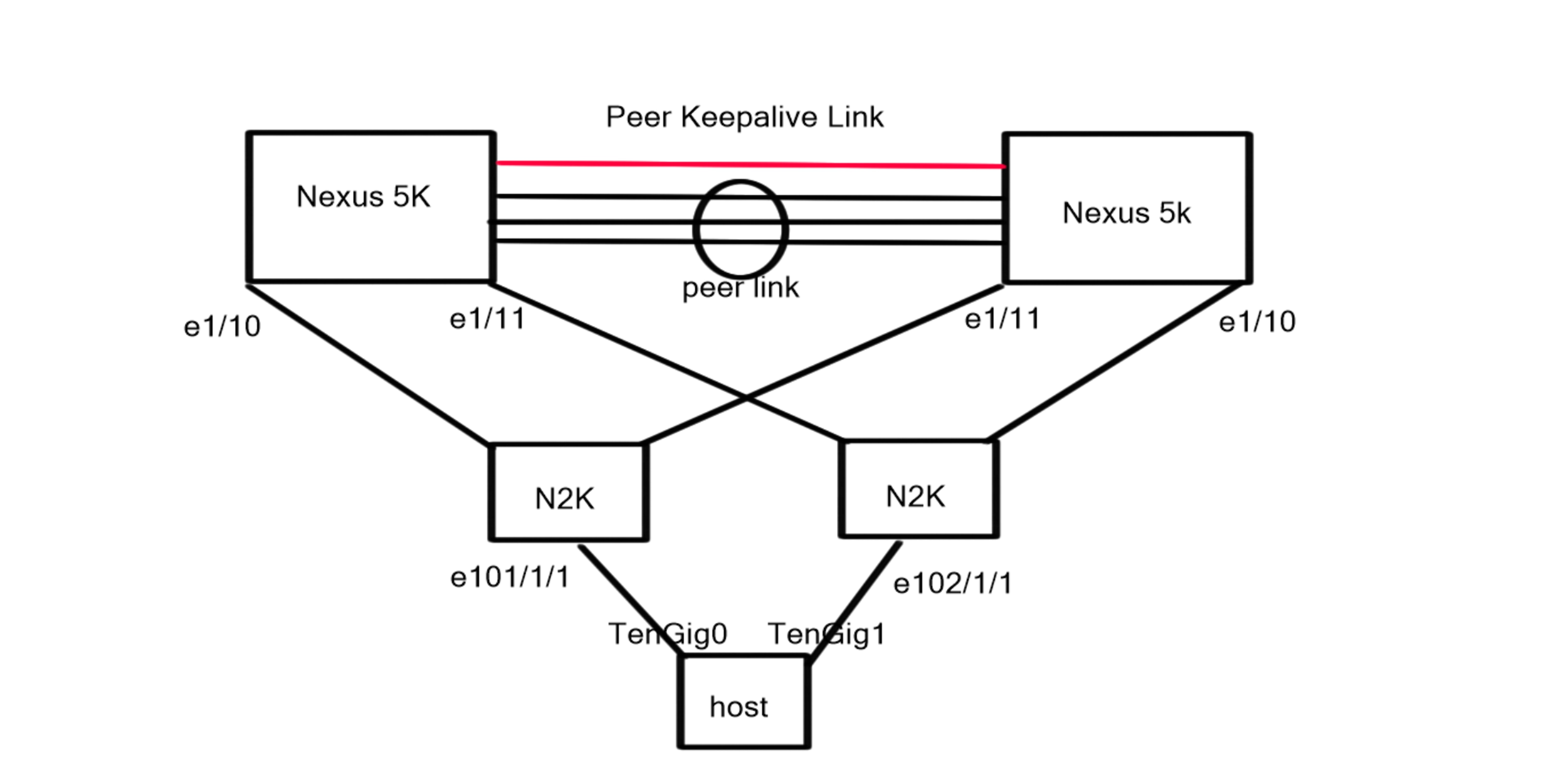
Topology Diagram
The topology diagram depicts two Nexus 5K acting as parent switches with physical connections to two downstream Nexus 2k (FEX) acting as the 10G physical termination points for the connected server.
Part1. Connecting the FEX to the Parent switch:
The FEX and the parent switch use Satellite Discovery Protocol (SDP) periodic messages to discovery and register with one another.
When you initially log on to the Nexus 5K you can see that the OS does not recognise the FEX even though there are two FEXs that are cabled correctly to parent switch. As the FEX is recognised as a remote line card you would expect to see it with a “show module” command.
| N5K3# sh module Mod Ports Module-Type Model Status — —– ——————————– ———————- ———— 1 40 40x10GE/Supervisor N5K-C5020P-BF-SUP active * 2 8 8×1/2/4G FC Module N5K-M1008 ok Mod Sw Hw World-Wide-Name(s) (WWN) — ————– —— ————————————————– 1 5.1(3)N2(1c) 1.3 — 2 5.1(3)N2(1c) 1.0 93:59:41:08:5a:0c:08:08 to 00:00:00:00:00:00:00:00 Mod MAC-Address(es) Serial-Num — ————————————– ———- 1 0005.9b1e.82c8 to 0005.9b1e.82ef JAF1419BLMA 2 0005.9b1e.82f0 to 0005.9b1e.82f7 JAF1411AQBJ |
We issue the “feature fex” command we observe the FEX sending SDP messages to the parent switch i.e. RX but we don’t see the parent switch sending SDP messages to the FEX i.e. TX.
Notice in the output below there is only “fex:Sdp-Rx” messages.
| N5K3# debug fex pkt-trace N5K3# 2014 Aug 21 09:51:57.410701 fex: Sdp-Rx: Interface: Eth1/11, Fex Id: 0, Ctrl Vntag: -1, Ctrl Vlan: 1 2014 Aug 21 09:51:57.410729 fex: Sdp-Rx: Refresh Intvl: 3000ms, Uid: 0x4000ff2929f0, device: Fex, Remote link: 0x20000080 2014 Aug 21 09:51:57.410742 fex: Sdp-Rx: Vendor: Cisco Systems Model: N2K-C2232PP-10GE Serial: FOC17100NHX 2014 Aug 21 09:51:57.821776 fex: Sdp-Rx: Interface: Eth1/10, Fex Id: 0, Ctrl Vntag: -1, Ctrl Vlan: 1 2014 Aug 21 09:51:57.821804 fex: Sdp-Rx: Refresh Intvl: 3000ms, Uid: 0x2ff2929f0, device: Fex, Remote link: 0x20000080 2014 Aug 21 09:51:57.821817 fex: Sdp-Rx: Vendor: Cisco Systems Model: N2K-C2232PP-10GE Serial: FOC17100NHU |
The FEX appears as “DISCOVERED” but no additional FEX host interfaces appear when you issue a “show interface brief“.
Command: show fex [chassid_id [detail]]: Displays information about a specific Fabric Extender Chassis ID
Command: show interface brief: Display interface information and connection status for each interface.
| N5K3# sh fex FEX FEX FEX FEX Number Description State Model Serial ———————————————————————— — ——– Discovered N2K-C2232PP-10GE SSI16510AWF — ——– Discovered N2K-C2232PP-10GE SSI165204YC N5K3# N5K3# show interface brief ——————————————————————————– Ethernet VLAN Type Mode Status Reason Speed Port Interface Ch # ——————————————————————————– Eth1/1 1 eth access down SFP validation failed 10G(D) — Eth1/2 1 eth access down SFP validation failed 10G(D) — Eth1/3 1 eth access up none 10G(D) — Eth1/4 1 eth access up none 10G(D) — Eth1/5 1 eth access up none 10G(D) — Eth1/6 1 eth access down Link not connected 10G(D) — Eth1/7 1 eth access down Link not connected 10G(D) — Eth1/8 1 eth access down Link not connected 10G(D) — Eth1/9 1 eth access down Link not connected 10G(D) — Eth1/10 1 eth fabric down FEX not configured 10G(D) — Eth1/11 1 eth fabric down FEX not configured 10G(D) — Eth1/12 1 eth access down Link not connected 10G(D) — snippet removed |
The Fabric interface Ethernet1/10 show as DOWN with a “FEX not configured” statement.
| N5K3# sh int Ethernet1/10 Ethernet1/10 is down (FEX not configured) Hardware: 1000/10000 Ethernet, address: 0005.9b1e.82d1 (bia 0005.9b1e.82d1) MTU 1500 bytes, BW 10000000 Kbit, DLY 10 usec reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA Port mode is fex-fabric auto-duplex, 10 Gb/s, media type is 10G Beacon is turned off Input flow-control is off, output flow-control is off Rate mode is dedicated Switchport monitor is off EtherType is 0x8100 snippet removed |
To enable the parent switch to fully discover the FEX we need to issue the “switchport mode fex-fabric” under the connected interface. As you can see we are still not sending any SDP messages but we are discovering the FEX.
The next step is to enable the FEX logical numbering under the interface so we can start to configure the FEX host interfaces. Once this is complete we run the “debug fex pkt-trace” and we are not sending TX and receiving RX SDP messages.
Command:”fex associate chassis_id“: Associates a Fabric Extender (FEX) to a fabric interface. To disassociate the Fabric Extender, use the “no” form of this command.
From the “debug fexpkt-race” you can see the parent switch is now sending TX SDP messages to the fully discovered FEX.
| N5K3(config)# int Ethernet1/10 N5K3(config-if)# fex associate 101 N5K3# debug fex pkt-trace N5K3# 2014 Aug 21 10:00:33.674605 fex: Sdp-Tx: Interface: Eth1/10, Fex Id: 101, Ctrl Vntag: 0, Ctrl Vlan: 4042 2014 Aug 21 10:00:33.674633 fex: Sdp-Tx: Refresh Intvl: 3000ms, Uid: 0xc0821e9b0500, device: Switch, Remote link: 0x1a009000 2014 Aug 21 10:00:33.674646 fex: Sdp-Tx: Vendor: Model: Serial: ———- 2014 Aug 21 10:00:33.674718 fex: Sdp-Rx: Interface: Eth1/10, Fex Id: 0, Ctrl Vntag: 0, Ctrl Vlan: 4042 2014 Aug 21 10:00:33.674733 fex: Sdp-Rx: Refresh Intvl: 3000ms, Uid: 0x2ff2929f0, device: Fex, Remote link: 0x20000080 2014 Aug 21 10:00:33.674746 fex: Sdp-Rx: Vendor: Cisco Systems Model: N2K-C2232PP-10GE Serial: FOC17100NHU 2014 Aug 21 10:00:33.836774 fex: Sdp-Rx: Interface: Eth1/11, Fex Id: 0, Ctrl Vntag: -1, Ctrl Vlan: 1 2014 Aug 21 10:00:33.836803 fex: Sdp-Rx: Refresh Intvl: 3000ms, Uid: 0x4000ff2929f0, device: Fex, Remote link: 0x20000080 2014 Aug 21 10:00:33.836816 fex: Sdp-Rx: Vendor: Cisco Systems Model: N2K-C2232PP-10GE Serial: FOC17100NHX 2014 Aug 21 10:00:36.678624 fex: Sdp-Tx: Interface: Eth1/10, Fex Id: 101, Ctrl Vntag: 0, Ctrl Vlan: 4042 2014 Aug 21 10:00:36.678664 fex: Sdp-Tx: Refresh Intvl: 3000ms, Uid: 0xc0821e9b0500, device: Switch, Remote snippet removed |
Now the 101 FEX status changes from “DISCOVERED” to “ONLINE”. You may also see an additional FEX with serial number SSI165204YC as “DISCOVERED” and not “ONLINE”. This is due to the fact that we have not explicitly configured it under the other Fabric interface.
| N5K3# sh fex FEX FEX FEX FEX Number Description State Model Serial ———————————————————————— 101 FEX0101 Online N2K-C2232PP-10GE SSI16510AWF — ——– Discovered N2K-C2232PP-10GE SSI165204YC N5K3# N5K3# show module fex 101 FEX Mod Ports Card Type Model Status. — — —– ———————————- —————— ———– 101 1 32 Fabric Extender 32x10GE + 8x10G Module N2K-C2232PP-10GE present FEX Mod Sw Hw World-Wide-Name(s) (WWN) — — ————– —— ———————————————– 101 1 5.1(3)N2(1c) 4.4 — FEX Mod MAC-Address(es) Serial-Num — — ————————————– ———- 101 1 f029.29ff.0200 to f029.29ff.021f SSI16510AWF |
Issuing the “show interface brief” we see new interfaces, specifically host interfaces for the FEX. The syntax below shows that only one interface is up; interface labelled Eth101/1/1. Reason for this is that only one end host (server) is connected to the FEX
| N5K3# show interface brief ——————————————————————————– Ethernet VLAN Type Mode Status Reason Speed Port Interface Ch # ——————————————————————————– Eth1/1 1 eth access down SFP validation failed 10G(D) — Eth1/2 1 eth access down SFP validation failed 10G(D) — snipped removed ——————————————————————————– Port VRF Status IP Address Speed MTU ——————————————————————————– mgmt0 — up 192.168.0.53 100 1500 ——————————————————————————– Ethernet VLAN Type Mode Status Reason Speed Port Interface Ch # ——————————————————————————– Eth101/1/1 1 eth access up none 10G(D) — Eth101/1/2 1 eth access down SFP not inserted 10G(D) — Eth101/1/3 1 eth access down SFP not inserted 10G(D) — Eth101/1/4 1 eth access down SFP not inserted 10G(D) — Eth101/1/5 1 eth access down SFP not inserted 10G(D) — Eth101/1/6 1 eth access down SFP not inserted 10G(D) — snipped removed |
| N5K3# sh run int eth1/10 interface Ethernet1/10 switchport mode fex-fabric fex associate 101 |
The Fabric Interfaces do not run a Spanning tree instance while the host interfaces do run BPDU guard and BPDU filter by default. The reason why the fabric interfaces do not run spanning tree is because they are backplane point to point interfaces.
By default, the FEX interfaces will send out a couple of BPDU’s on start-up.
| N5K3# sh spanning-tree interface Ethernet1/10 No spanning tree information available for Ethernet1/10 N5K3# N5K3# N5K3# sh spanning-tree interface Eth101/1/1Vlan Role Sts Cost Prio.Nbr Type —————- —- — ——— ——– ——————————– VLAN0001 Desg FWD 2 128.1153 Edge P2p N5K3# N5K3# sh spanning-tree interface Eth101/1/1 detail Port 1153 (Ethernet101/1/1) of VLAN0001 is designated forwarding Port path cost 2, Port priority 128, Port Identifier 128.1153 Designated root has priority 32769, address 0005.9b1e.82fc Designated bridge has priority 32769, address 0005.9b1e.82fc Designated port id is 128.1153, designated path cost 0 Timers: message age 0, forward delay 0, hold 0 Number of transitions to forwarding state: 1 The port type is edge Link type is point-to-point by default Bpdu guard is enabled Bpdu filter is enabled by default BPDU: sent 11, received 0 |
| N5K3# sh spanning-tree interface Ethernet1/10 No spanning tree information available for Ethernet1/10 N5K3# N5K3# N5K3# sh spanning-tree interface Eth101/1/1Vlan Role Sts Cost Prio.Nbr Type—————- —- — ——— ——– ——————————– VLAN0001 Desg FWD 2 128.1153 Edge P2p N5K3# N5K3# sh spanning-tree interface Eth101/1/1 detail Port 1153 (Ethernet101/1/1) of VLAN0001 is designated forwarding Port path cost 2, Port priority 128, Port Identifier 128.1153 Designated root has priority 32769, address 0005.9b1e.82fc Designated bridge has priority 32769, address 0005.9b1e.82fc Designated port id is 128.1153, designated path cost 0 Timers: message age 0, forward delay 0, hold 0 Number of transitions to forwarding state: 1 The port type is edge Link type is point-to-point by default Bpdu guard is enabled Bpdu filter is enabled by default BPDU: sent 11, received 0 |
Issue the commands below to determine the transceiver type for the fabric ports and also the hosts ports for each fabric interface.
Command: “show interface fex-fabric“: displays all the Fabric Extender interfaces
Command: “show fex detail“: Shows detailed information about all FEXs. Including more recent log messages related to the FEX.
| N5K3# show interface fex-fabric Fabric Fabric Fex FEX Fex Port Port State Uplink Model Serial ————————————————————— 101 Eth1/10 Active 3 N2K-C2232PP-10GE SSI16510AWF — Eth1/11 Discovered 3 N2K-C2232PP-10GE SSI165204YC N5K3# N5K3# N5K3# show interface Ethernet1/10 fex-intf Fabric FEX Interface Interfaces ————————————————— Eth1/10 Eth101/1/1 N5K3# N5K3# show interface Ethernet1/10 transceiver Ethernet1/10 transceiver is present type is SFP-H10GB-CU3M name is CISCO-TYCO part number is 1-2053783-2 revision is N serial number is TED1530B11W nominal bitrate is 10300 MBit/sec Link length supported for copper is 3 m cisco id is — cisco extended id number is 4 N5K3# show fex detail FEX: 101 Description: FEX0101 state: Online FEX version: 5.1(3)N2(1c) [Switch version: 5.1(3)N2(1c)] FEX Interim version: 5.1(3)N2(1c) Switch Interim version: 5.1(3)N2(1c) Extender Serial: SSI16510AWF Extender Model: N2K-C2232PP-10GE, Part No: 73-12533-05 Card Id: 82, Mac Addr: f0:29:29:ff:02:02, Num Macs: 64 Module Sw Gen: 12594 [Switch Sw Gen: 21] post level: complete pinning-mode: static Max-links: 1 Fabric port for control traffic: Eth1/10 FCoE Admin: false FCoE Oper: true FCoE FEX AA Configured: false Fabric interface state: Eth1/10 – Interface Up. State: Active Fex Port State Fabric Port Eth101/1/1 Up Eth1/10 Eth101/1/2 Down None Eth101/1/3 Down None Eth101/1/4 Down None snippet removed Logs: 08/21/2014 10:00:06.107783: Module register received 08/21/2014 10:00:06.109935: Registration response sent 08/21/2014 10:00:06.239466: Module Online S |
Now we quickly enable the second FEX connected to fabric interface E1/11.
| N5K3(config)# int et1/11 N5K3(config-if)# switchport mode fex-fabric N5K3(config-if)# fex associate 102 N5K3(config-if)# end N5K3# sh fex FEX FEX FEX FEX Number Description State Model Serial ———————————————————————— 101 FEX0101 Online N2K-C2232PP-10GE SSI16510AWF 102 FEX0102 Online N2K-C2232PP-10GE SSI165204YC N5K3# show fex detail FEX: 101 Description: FEX0101 state: Online FEX version: 5.1(3)N2(1c) [Switch version: 5.1(3)N2(1c)] FEX Interim version: 5.1(3)N2(1c) Switch Interim version: 5.1(3)N2(1c) Extender Serial: SSI16510AWF Extender Model: N2K-C2232PP-10GE, Part No: 73-12533-05 Card Id: 82, Mac Addr: f0:29:29:ff:02:02, Num Macs: 64 Module Sw Gen: 12594 [Switch Sw Gen: 21] post level: complete pinning-mode: static Max-links: 1 Fabric port for control traffic: Eth1/10 FCoE Admin: false FCoE Oper: true FCoE FEX AA Configured: false Fabric interface state: Eth1/10 – Interface Up. State: Active Fex Port State Fabric Port Eth101/1/1 Up Eth1/10 Eth101/1/2 Down None Eth101/1/3 Down None Eth101/1/4 Down None Eth101/1/5 Down None Eth101/1/6 Down None snippet removed Logs: 08/21/2014 10:00:06.107783: Module register received 08/21/2014 10:00:06.109935: Registration response sent 08/21/2014 10:00:06.239466: Module Online Sequence 08/21/2014 10:00:09.621772: Module Online FEX: 102 Description: FEX0102 state: Online FEX version: 5.1(3)N2(1c) [Switch version: 5.1(3)N2(1c)] FEX Interim version: 5.1(3)N2(1c) Switch Interim version: 5.1(3)N2(1c) Extender Serial: SSI165204YC Extender Model: N2K-C2232PP-10GE, Part No: 73-12533-05 Card Id: 82, Mac Addr: f0:29:29:ff:00:42, Num Macs: 64 Module Sw Gen: 12594 [Switch Sw Gen: 21] post level: complete pinning-mode: static Max-links: 1 Fabric port for control traffic: Eth1/11 FCoE Admin: false FCoE Oper: true FCoE FEX AA Configured: false Fabric interface state: Eth1/11 – Interface Up. State: Active Fex Port State Fabric Port Eth102/1/1 Up Eth1/11 Eth102/1/2 Down None Eth102/1/3 Down None Eth102/1/4 Down None Eth102/1/5 Down None snippet removed Logs: 08/21/2014 10:12:13.281018: Module register received 08/21/2014 10:12:13.283215: Registration response sent 08/21/2014 10:12:13.421037: Module Online Sequence 08/21/2014 10:12:16.665624: Module Online |
Part 2. Fabric Interfaces redundancy
Static Pinning is when you pin a number of host ports to a fabric port. If the fabric port goes down so do the host ports that are pinned to it. This is useful when you want no oversubscription in the network.
Once the host port shut down due to a fabric port down event, the server if configured correctly should revert to the secondary NIC.
The “pinning max-link” divides the number specified in the command by the number of host interfaces to determine how many host interfaces go down if there is a fabric interface failure.
Now we shut down fabric interface E1/10, you can see that Eth101/1/1 has changed its operation mode to DOWN. The FEX has additional connectivity with E1/11 which remains up.
| Enter configuration commands, one per line. End with CNTL/Z. N5K3(config)# int et1/10 N5K3(config-if)# shu N5K3(config-if)# N5K3(config-if)# end N5K3# sh fex detail FEX: 101 Description: FEX0101 state: Offline FEX version: 5.1(3)N2(1c) [Switch version: 5.1(3)N2(1c)] FEX Interim version: 5.1(3)N2(1c) Switch Interim version: 5.1(3)N2(1c) Extender Serial: SSI16510AWF Extender Model: N2K-C2232PP-10GE, Part No: 73-12533-05 Card Id: 82, Mac Addr: f0:29:29:ff:02:02, Num Macs: 64 Module Sw Gen: 12594 [Switch Sw Gen: 21] post level: complete pinning-mode: static Max-links: 1 Fabric port for control traffic: FCoE Admin: false FCoE Oper: true FCoE FEX AA Configured: false Fabric interface state: Eth1/10 – Interface Down. State: Configured Fex Port State Fabric Port Eth101/1/1 Down Eth1/10 Eth101/1/2 Down None Eth101/1/3 Down None snippet removed Logs: 08/21/2014 10:00:06.107783: Module register received 08/21/2014 10:00:06.109935: Registration response sent 08/21/2014 10:00:06.239466: Module Online Sequence 08/21/2014 10:00:09.621772: Module Online 08/21/2014 10:13:20.50921: Deleting route to FEX 08/21/2014 10:13:20.58158: Module disconnected 08/21/2014 10:13:20.61591: Offlining Module 08/21/2014 10:13:20.62686: Module Offline Sequence 08/21/2014 10:13:20.797908: Module Offline FEX: 102 Description: FEX0102 state: Online FEX version: 5.1(3)N2(1c) [Switch version: 5.1(3)N2(1c)] FEX Interim version: 5.1(3)N2(1c) Switch Interim version: 5.1(3)N2(1c) Extender Serial: SSI165204YC Extender Model: N2K-C2232PP-10GE, Part No: 73-12533-05 Card Id: 82, Mac Addr: f0:29:29:ff:00:42, Num Macs: 64 Module Sw Gen: 12594 [Switch Sw Gen: 21] post level: complete pinning-mode: static Max-links: 1 Fabric port for control traffic: Eth1/11 FCoE Admin: false FCoE Oper: true FCoE FEX AA Configured: false Fabric interface state: Eth1/11 – Interface Up. State: Active Fex Port State Fabric Port Eth102/1/1 Up Eth1/11 Eth102/1/2 Down None Eth102/1/3 Down None Eth102/1/4 Down None snippet removed Logs: 08/21/2014 10:12:13.281018: Module register received 08/21/2014 10:12:13.283215: Registration response sent 08/21/2014 10:12:13.421037: Module Online Sequence 08/21/2014 10:12:16.665624: Module Online |
Port Channels can be used instead of static pinning between parent switch and FEX so in the event of a fabric interface failure all hosts ports remain active. However, the remaining bandwidth on the parent switch will be shared by all the host ports resulting in an increase in oversubscription.
Part 3. Fabric Extender Topologies
Straight-Through: The FEX is connected to a single parent switch. The servers connecting to the FEX can leverage active-active data plane by using host vPC.
Shutting down the Peer link results in ALL vPC member ports in the secondary peer become disabled. For this reason it is better to use a Dual Homed.
Dual Homed: Connecting a single FEX to two parent switches.
In active – active, a single parent switch failure does not affect the host’s interfaces because both vpc peers have separate control planes and manage the FEX separately.
For the remainder of the post we are going to look at Dual Homed FEX connectivity with host Vpc.
Full configuration:
| N5K1: feature lacp feature vpc feature fex ! vlan 10 ! vpc domain 1 peer-keepalive destination 192.168.0.52 ! interface port-channel1 switchport mode trunk spanning-tree port type network vpc peer-link ! interface port-channel10 switchport access vlan 10 vpc 10 ! interface Ethernet1/1 switchport access vlan 10 spanning-tree port type edge speed 1000 ! interface Ethernet1/3 – 5 switchport mode trunk spanning-tree port type network channel-group 1 mode active ! interface Ethernet1/10 switchport mode fex-fabric fex associate 101 ! interface Ethernet101/1/1 switchport access vlan 10 channel-group 10 mode on N5K2: feature lacp feature vpc feature fex ! vlan 10 ! vpc domain 1 peer-keepalive destination 192.168.0.51 ! interface port-channel1 switchport mode trunk spanning-tree port type network vpc peer-link ! interface port-channel10 switchport access vlan 10 vpc 10 ! interface Ethernet1/2 switchport access vlan 10 spanning-tree port type edge speed 1000 ! interface Ethernet1/3 – 5 switchport mode trunk spanning-tree port type network channel-group 1 mode active ! interface Ethernet1/11 switchport mode fex-fabric fex associate 102 ! interface Ethernet102/1/1 switchport access vlan 10 channel-group 10 mode on |
The FEX do not support LACP so configure the port-channel mode to “ON”
The first step is to check the VPC peer link and general VPC parameters.
Command: “show vpc brief“. Displays the vPC domain ID, the peer-link status, the keepalive message status, whether the configuration consistency is successful, and whether peer-link formed or the failure to form
Command: “show vpc peer-keepalive” Displays the destination IP of the peer keepalive message for the vPC. The command also displays the send and receives status as well as the last update from the peer in seconds and milliseconds
| N5K3# sh vpc brief Legend: (*) – local vPC is down, forwarding via vPC peer-link vPC domain id : 1 Peer status : peer adjacency formed ok vPC keep-alive status : peer is alive Configuration consistency status: success Per-vlan consistency status : success Type-2 consistency status : success vPC role : primary Number of vPCs configured : 1 Peer Gateway : Disabled Dual-active excluded VLANs : – Graceful Consistency Check : Enabled vPC Peer-link status ——————————————————————— id Port Status Active vlans — —- —— ————————————————– 1 Po1 up 1,10 vPC status —————————————————————————- id Port Status Consistency Reason Active vlans —— ———– —— ———– ————————– ———– 10 Po10 up success success 10 N5K3# show vpc peer-keepalive vPC keep-alive status : peer is alive –Peer is alive for : (1753) seconds, (536) msec –Send status : Success –Last send at : 2014.08.21 10:52:30 130 ms –Sent on interface : mgmt0 –Receive status : Success –Last receive at : 2014.08.21 10:52:29 925 ms –Received on interface : mgmt0 –Last update from peer : (0) seconds, (485) msec vPC Keep-alive parameters –Destination : 192.168.0.54 –Keepalive interval : 1000 msec –Keepalive timeout : 5 seconds –Keepalive hold timeout : 3 seconds –Keepalive vrf : management –Keepalive udp port : 3200 –Keepalive tos : 192 |
The trunk interface should be forwarding on the peer link and VLAN 10 must be forwarding and active on the trunk link. Take note if any vlans are on err-disable mode on the trunk.
| N5K3# sh interface trunk ——————————————————————————- Port Native Status Port Vlan Channel ——————————————————————————– Eth1/3 1 trnk-bndl Po1 Eth1/4 1 trnk-bndl Po1 Eth1/5 1 trnk-bndl Po1 Po1 1 trunking — ——————————————————————————– Port Vlans Allowed on Trunk ——————————————————————————– Eth1/3 1-3967,4048-4093 Eth1/4 1-3967,4048-4093 Eth1/5 1-3967,4048-4093 Po1 1-3967,4048-4093 ——————————————————————————– Port Vlans Err-disabled on Trunk ——————————————————————————– Eth1/3 none Eth1/4 none Eth1/5 none Po1 none ——————————————————————————– Port STP Forwarding ——————————————————————————– Eth1/3 none Eth1/4 none Eth1/5 none Po1 1,10 ——————————————————————————– Port Vlans in spanning tree forwarding state and not pruned ——————————————————————————– Eth1/3 — Eth1/4 — Eth1/5 — Po1 — ——————————————————————————– Port Vlans Forwarding on FabricPath ——————————————————————————– N5K3# sh spanning-tree vlan 10 VLAN0010 Spanning tree enabled protocol rstp Root ID Priority 32778 Address 0005.9b1e.82fc This bridge is the root Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Bridge ID Priority 32778 (priority 32768 sys-id-ext 10) Address 0005.9b1e.82fc Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Interface Role Sts Cost Prio.Nbr Type —————- —- — ——— ——– ——————————– Po1 Desg FWD 1 128.4096 (vPC peer-link) Network P2p Po10 Desg FWD 1 128.4105 (vPC) Edge P2p Eth1/1 Desg FWD 4 128.129 Edge P2p |
Check the Port Channel database and determine the status of the port channel
| N5K3# show port-channel database port-channel1 Last membership update is successful 3 ports in total, 3 ports up First operational port is Ethernet1/3 Age of the port-channel is 0d:00h:13m:22s Time since last bundle is 0d:00h:13m:18s Last bundled member is Ethernet1/5 Ports: Ethernet1/3 [active ] [up] * Ethernet1/4 [active ] [up] Ethernet1/5 [active ] [up] port-channel10 Last membership update is successful 1 ports in total, 1 ports up First operational port is Ethernet101/1/1 Age of the port-channel is 0d:00h:13m:20s Time since last bundle is 0d:00h:02m:42s Last bundled member is Ethernet101/1/1 Time since last unbundle is 0d:00h:02m:46s Last unbundled member is Ethernet101/1/1 Ports: Ethernet101/1/1 [on] [up] * |
To execute reachability tests, create an SVI on the first parent switch and run ping tests. You must first enable the feature set “feature interface-vlan”. The reason we create an SVI in VLAN 10 is because we need an interfaces to source our pings.
| N5K3# conf t Enter configuration commands, one per line. End with CNTL/Z. N5K3(config)# fea feature feature-set N5K3(config)# feature interface-vlan N5K3(config)# int vlan 10 N5K3(config-if)# ip address 10.0.0.3 255.255.255.0 N5K3(config-if)# no shu N5K3(config-if)# N5K3(config-if)# N5K3(config-if)# end N5K3# ping 10.0.0.3 PING 10.0.0.3 (10.0.0.3): 56 data bytes 64 bytes from 10.0.0.3: icmp_seq=0 ttl=255 time=0.776 ms 64 bytes from 10.0.0.3: icmp_seq=1 ttl=255 time=0.504 ms 64 bytes from 10.0.0.3: icmp_seq=2 ttl=255 time=0.471 ms 64 bytes from 10.0.0.3: icmp_seq=3 ttl=255 time=0.473 ms 64 bytes from 10.0.0.3: icmp_seq=4 ttl=255 time=0.467 ms — 10.0.0.3 ping statistics — 5 packets transmitted, 5 packets received, 0.00% packet loss round-trip min/avg/max = 0.467/0.538/0.776 ms N5K3# ping 10.0.0.10 PING 10.0.0.10 (10.0.0.10): 56 data bytes Request 0 timed out 64 bytes from 10.0.0.10: icmp_seq=1 ttl=127 time=1.874 ms 64 bytes from 10.0.0.10: icmp_seq=2 ttl=127 time=0.896 ms 64 bytes from 10.0.0.10: icmp_seq=3 ttl=127 time=1.023 ms 64 bytes from 10.0.0.10: icmp_seq=4 ttl=127 time=0.786 ms — 10.0.0.10 ping statistics — 5 packets transmitted, 4 packets received, 20.00% packet loss round-trip min/avg/max = 0.786/1.144/1.874 ms N5K3# |
Do the same tests on the second Nexus 5K.
| N5K4(config)# int vlan 10 N5K4(config-if)# ip address 10.0.0.4 255.255.255.0 N5K4(config-if)# no shu N5K4(config-if)# end N5K4# ping 10.0.0.10 PING 10.0.0.10 (10.0.0.10): 56 data bytes Request 0 timed out 64 bytes from 10.0.0.10: icmp_seq=1 ttl=127 time=1.49 ms 64 bytes from 10.0.0.10: icmp_seq=2 ttl=127 time=1.036 ms 64 bytes from 10.0.0.10: icmp_seq=3 ttl=127 time=0.904 ms 64 bytes from 10.0.0.10: icmp_seq=4 ttl=127 time=0.889 ms — 10.0.0.10 ping statistics — 5 packets transmitted, 4 packets received, 20.00% packet loss round-trip min/avg/max = 0.889/1.079/1.49 ms N5K4# ping 10.0.0.13 PING 10.0.0.13 (10.0.0.13): 56 data bytes Request 0 timed out Request 1 timed out Request 2 timed out Request 3 timed out Request 4 timed out — 10.0.0.13 ping statistics — 5 packets transmitted, 0 packets received, 100.00% packet loss N5K4# ping 10.0.0.3 PING 10.0.0.3 (10.0.0.3): 56 data bytes Request 0 timed out 64 bytes from 10.0.0.3: icmp_seq=1 ttl=254 time=1.647 ms 64 bytes from 10.0.0.3: icmp_seq=2 ttl=254 time=1.298 ms 64 bytes from 10.0.0.3: icmp_seq=3 ttl=254 time=1.332 ms 64 bytes from 10.0.0.3: icmp_seq=4 ttl=254 time=1.24 ms — 10.0.0.3 ping statistics — 5 packets transmitted, 4 packets received, 20.00% packet loss round-trip min/avg/max = 1.24/1.379/1.647 ms |
Shut down one of the FEX links to the parent and you see that the FEX is still reachable via the other link that is in the port channel bundle.
| N5K3# conf t Enter configuration commands, one per line. End with CNTL/Z. N5K3(config)# int Eth101/1/1 N5K3(config-if)# shu N5K3(config-if)# end N5K3# N5K3# N5K3# ping 10.0.0.3 PING 10.0.0.3 (10.0.0.3): 56 data bytes 64 bytes from 10.0.0.3: icmp_seq=0 ttl=255 time=0.659 ms 64 bytes from 10.0.0.3: icmp_seq=1 ttl=255 time=0.515 ms 64 bytes from 10.0.0.3: icmp_seq=2 ttl=255 time=0.471 ms 64 bytes from 10.0.0.3: icmp_seq=3 ttl=255 time=0.466 ms 64 bytes from 10.0.0.3: icmp_seq=4 ttl=255 time=0.465 ms — 10.0.0.3 ping statistics — 5 packets transmitted, 5 packets received, 0.00% packet loss round-trip min/avg/max = 0.465/0.515/0.659 ms |
If you would like to futher your knowlege on VPC and how it relates to Data Center toplogies and more specifically, Cisco’s Application Centric Infrastructure (ACI), you can check out my following training courses on Cisco ACI. Course 1: Design and Architect Cisco ACI, Course 2: Implement Cisco ACI, and Course 3: Troubleshooting Cisco ACI,