**The Anatomy of a Data Center Failure**
Data center failures can occur due to a myriad of reasons, ranging from power outages and hardware malfunctions to software glitches and natural disasters. Each failure can have a ripple effect, impacting business continuity and data integrity. Recognizing the common causes of failures allows organizations to develop robust strategies to mitigate risks and ensure stability.
**Storage High Availability: The Shield Against Disruption**
At the core of mitigating data center failures is the concept of storage high availability (HA). This involves designing storage systems that are resilient to failures, ensuring data is always accessible, even when components fail. Techniques such as data replication, clustering, and failover mechanisms are employed to achieve high availability. By implementing these strategies, organizations can minimize downtime and protect their critical data assets.
**Implementing Proactive Measures**
Organizations must adopt a proactive approach to safeguard their data centers. Regular maintenance, monitoring, and testing of systems are essential to identify potential points of failure before they escalate. Investing in advanced technologies like predictive analytics and artificial intelligence can provide insights into system health and preemptively address issues. Additionally, having a well-documented disaster recovery plan ensures a swift response in the event of a failure.
Data Center Storage Protocols
Protocols for communicating between storage and the outside world include iSCSI, SAS, SATA, and Fibre Channel (FC). It defines connections between HDDs, cables, backplanes, storage switches, or servers from one manufacturer connected to stuff from another manufacturer. Connectors must fit reliably, and there are a variety of them.
It seemed trivial at the time, but a specification lacking a definition of connector tolerances was a critical obstacle to SATA adoption (it seemed trivial at the time). This resulted in loose connectors, which resulted in a lot of bad press over a situation that could have been fixed with an errata note to fix the industry interoperability problem.
Transport Layer
Having established the physical, electrical, and digital connections, the transport layer creates, delivers, and confirms the delivery of the payloads, called frames information structures (FISs). The transport layer also handles addressing.
Storage protocols often connect multiple devices on a single wire; they include a global address so data sent down the wire gets to the right place. You can think of FIS packets as having a start and end of frames and a payload. Payloads can be either data or commands; here are the SATA FIS types (SAS and FC are similar but not identical):
Summary of storage protocols: they are simultaneously simple yet incredibly robust and complex. Error handling is the real merit of a storage protocol. When a connection is abruptly established or dropped, what happens? In the event of delays or non-acknowledgments, what happens? There is a lot of magic going on when it comes to handling errors. Each has different price tags and capabilities; choose the right tool based on your needs.
**Recap on blog series**
This blog is the third in a series discussing the tail of active-active data centers and data center failure. The first blog focuses on GTM DNS-based load balancing and introduces failover challenges. The second discusses databases and Data Center Failover. This post addresses storage challenges, and finally, the fourth will focus on ingress and egress traffic flows.
There are many factors to consider, such as the type of storage solution, synchronous or asynchronous replication, latency, and bandwidth restrictions between data centers. All of these are compounded by the complexity of microservices observability. And provide redundancy for these containerized environments.
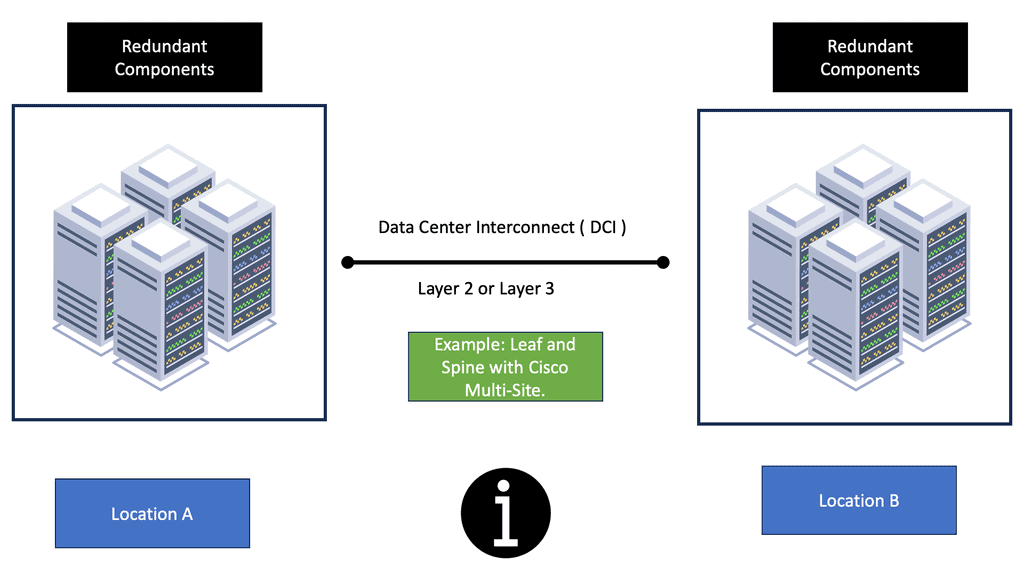
Data Center Design
Nowadays, most SDN data center designs are based on the spine leaf architecture. However, even though the switching architecture may be the same for data center failure, every solution will have different requirements. For example, latency can drastically affect synchronous replications as a round trip time (RTT) is added to every write action. Still, this may not be as much of an issue for asynchronous replications. Design errors may also become apparent from specific failure scenarios, such as data center interconnect failure.
This potentially results in split-brain scenarios, so be careful when you try to over-automate and over-engineer things that should be kept simple in the first place. Split-brain occurs when both are active at the same time. Everything becomes out of sync, which may result in full tap storage restores.
Before you proceed, you may find the following helpful pre-information:
History of Storage
Small Computer System Interface (SCSI) was one of the first open storage standards. It was developed by the American National Standards Institute (ANSI) for attaching peripherals, such as storage, to computers. Initially, it wasn’t very flexible and could connect only 15 devices over a flat copper ribbon cable of 20 meters.
So, the fiber channel replaced the flat cable with a fiber cable. Now, we have a fiber infrastructure that overcomes the 20-meter restriction. However, it still uses the same SCSI protocol over fiber, commonly known as SCSI. Fibre Channel is used to transport SCSI information units over optical fiber.
Storage devices
We then started to put disks into enclosures, known as storage arrays. Storage arrays increase resilience and availability by eliminating single failure points (SPOFs). Applications would not write or own a physical disk but instead write to what is known as a LUN (Logical disk). A LUN is a unit that logically supports read/write operations. LUNs allow multi-access support by permitting numerous hosts to access the same storage array.
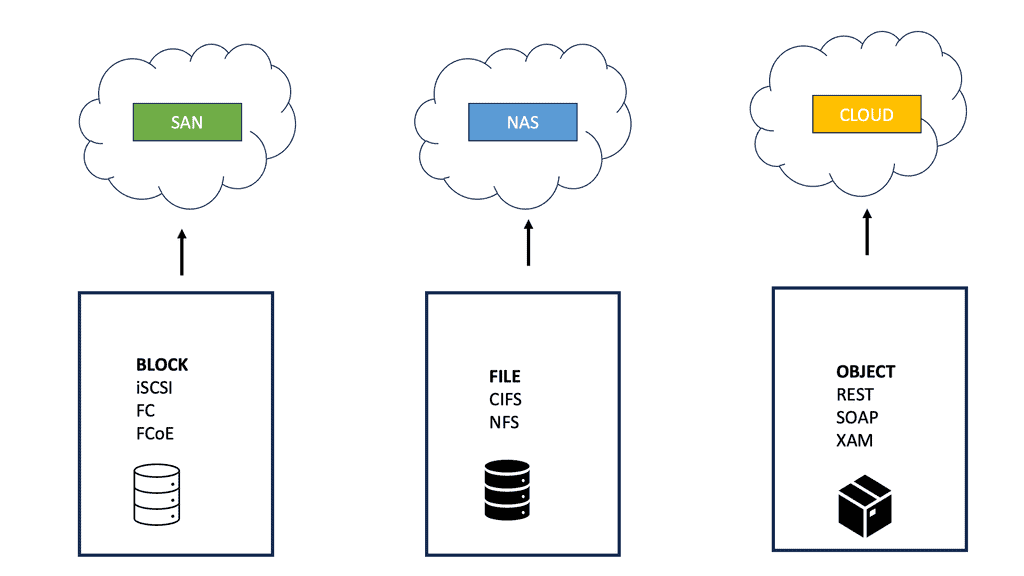
Eventually, vendors designed storage area networks (SAN). SAN networks provide access to block-level data storage. Block-level storage is used for SAN access, while file-level storage is used for network-attached storage (NAS) access. They no longer used SCSI and invented their routing protocol, FSPF routing.
Brocade invented FSPF, which is conceptually similar to OSPF for IP networks. They also implemented VSAN, similar to VLANs on Layer 2 networks, but used it for storage. VSAN is a collection of ports that represent a virtual fabric.
Remote disk access
Traditionally, servers would have a Host Bus Adapter (HBA) and run FC/ FCoE/iSCSI protocols to communicate with the remote storage array. Another method is sending individual file system calls to a remote file system, a NAS. The protocols used for this are CIFS and NFS. Microsoft developed CIFS, an open variation of the Server Message Block Protocol (SMB). NFS, developed by Sun Microsystems, runs over TCP and gives you access to shared files instead of SCSI, providing you access to remote disks.
The speed of file access depends on your application. Slow performances are generally not related to the protocols NFS or CIF. If your application is well-written and can read vast chunks of data, it will be refined over NFS. On the other hand, if your application is poorly written, it is best to use iSCSI. Then, the host will do most of the buffering.
Why not use LAN instead of a fiber channel?
Initially, there was a wide variety of different operating systems. Most of these operating systems already used SCSI and the device drivers that implemented connectivity to load SCSI host adapters. The storage industry decided to offer the same SCSI protocol to the same device driver but over a fiber channel physical infrastructure.
Everything above the fiber channel was not changed. This allowed backward compatibility with old adapters, so they continued using the old SCSI protocols.
Fiber channels have their own set of requirements and terminology. The host still thinks they write to a disk 20m away, requiring tight timings. It must have low latency and a minimum distance of around 100 km. Nothing can be lost, so it must be lossless, and packets are critical.
FC requires lossless networks, which usually result in a costly dedicated network. With this approach, you have one network for LAN and one for storage.
Fiber channels over Ethernet eliminated fiber-only networks by offering I/O consultations between servers and switches. They took the entire fiber frame and put it into an Ethernet frame. FCoE requires lossless Ethernet (DCB) between the servers and the first switch, i.e., VN and VF ports. It is mainly used to reduce the amount of cabling between servers and switches. It is an access-tier solution. On the Ethernet side, we must have lossless Ethernet. There are several standards IEEE formed for this.
The first limited the sending device by issuing a PAUSE frame, known as 802.3x, which stops the server from sending data. As a result of the PAUSE frame, the server stops ALL transmissions. But we need a way to stop only the lossless part of the traffic, i.e., the FCoE traffic. This is 802.1qbb and allows you to stop a single class of services. There is also QCN (Congestion notification 802.1Qua), an end-to-end mechanism telling the sending device to slow down. All the servers, switches, and storage arrays negotiate the class parameters, deciding what will be lossless.
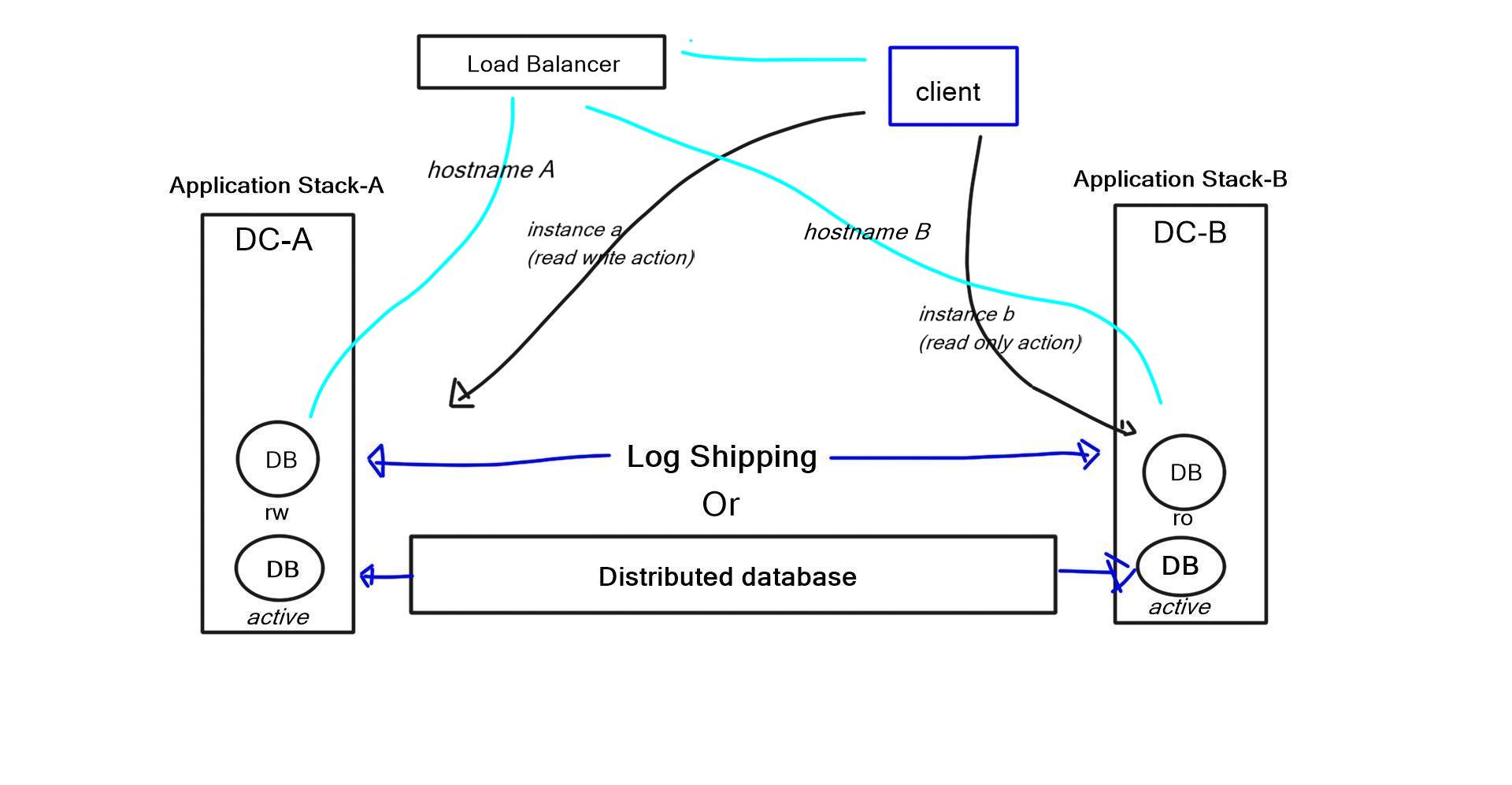
Data center failure: Storage replication for disaster recovery
The primary reasons for storage replication are disaster recovery and fulfilling service level agreements (SLA). How accurate will your data be when data center services fail from one DC to another? The level of data consistency depends on the solution in place and how you replicate your data. There are two types of storage replication: synchronous and asynchronous.
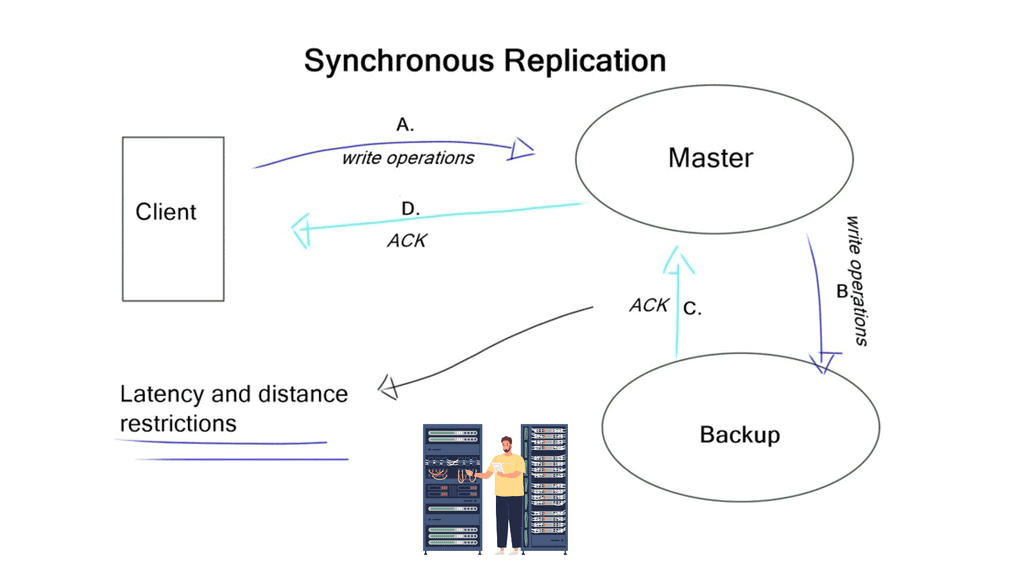
Synchronous has several steps.
The host writes to the disk, and the disk writes to the other disk in the remote location. Only when the other disk says, OK will an OK be returned to the host. Synchronous replication guarantees that the data is ideally in sync. However, it requires tight timeouts, severely limiting the distance between the two data centers. You need to implement asynchronous replication if there are long distances between data centers.
The host writes to the local disk, and the local disk immediately says OK without writing or receiving notifications from the remote disk. The local disk sends a written request to the remote disk in the background. If you use traditional LUN-based replication between two data centers, most solutions make one of these disks read-only and the other read-write.
Problems with latency occur when a VM is spawned in the data center with only the read-only copy, resulting in replication back to the writable copy. One major influential design factor is how much bandwidth storage replication consumes between data centers.
Data center failure: Distributed file systems
A better storage architecture is to use a system with distributed file systems—both ends are writable. Replication is not done at the disk level but at a file level. Your replication type is down to the recovery point objective (RPO), which is the terminology used for business continuity objectives. You must use synchronous replication if you require an RPO of zero. As discussed, it requires several steps before it is acknowledged to the application.
Synchronous also has distance and latency restrictions, which vary depending on the chosen storage solution. For example, VMware VSAN supports RTT of 5 ms. It is a distributed file system, so the replication is not done on a traditional LUN level but at a file level. It employs synchronous replication between data centers, adding RTT to every write.
Most storage solutions eventually become consistent. You write to a file, the file locks, and the file is copied to the other end. This offers much better performance, but obviously, RPO is non-zero.
Closing Points: Data Center Failure Storage
Downtime in a data center doesn’t just mean a temporary loss of access to information; it can lead to significant financial losses, damage to brand reputation, and a loss of customer trust. For industries such as finance, healthcare, and e-commerce, even a few minutes of downtime can result in catastrophic consequences. Thus, ensuring high availability is not just an IT concern but a business imperative.
One of the most effective ways to combat data center failures is through high availability (HA) storage solutions. These systems are designed to provide continuous access to data, even when parts of the system fail. High availability storage ensures that there are multiple pathways for data access, meaning if one path fails, another can take over seamlessly. This redundancy is critical for maintaining service during unexpected disruptions.
To implement a high availability storage solution, businesses must first assess their current infrastructure and identify potential weak points. This often involves deploying redundant hardware, such as servers and storage devices, and ensuring that they are strategically located to avoid a single point of failure. Additionally, leveraging cloud technologies can provide an extra layer of resilience, offering offsite backups and alternative processing capabilities.