At its core, MPTCP is an extension of the conventional Transmission Control Protocol (TCP), designed to improve network resource utilization and increase resilience by allowing multiple paths for data transmission. This means data packets can be sent over several network interfaces simultaneously, optimizing speed and reliability.
The traditional TCP protocol uses a single network path for communication, which can lead to bottlenecks and inefficiencies, especially in environments with fluctuating network conditions. Multipath TCP, on the other hand, breaks away from this limitation by enabling a session to split across multiple paths. This is particularly useful in mobile environments, where devices often switch between different networks such as Wi-Fi and cellular data. By leveraging multiple paths, MPTCP ensures that if one path fails or becomes congested, others can take over seamlessly, maintaining a stable connection.
Adopting MPTCP
– MPTCP is an extension of the traditional Transmission Control Protocol (TCP) that enables the establishment of multiple sub-flows within a single TCP connection. This means that data can be simultaneously transmitted over different network paths, such as Wi-Fi and cellular networks, providing increased throughput and improved resilience against network failures.
– One of the primary advantages of MPTCP is its ability to utilize the combined bandwidth of multiple network paths, resulting in faster data transfer rates. Additionally, MPTCP offers enhanced reliability by dynamically adapting to network conditions and rerouting data if a path becomes congested or fails. This makes it particularly useful in scenarios with a stable and high-bandwidth connection, such as streaming multimedia content or real-time applications, which is crucial.
How Multipath TCP Works:
A) MPTCP operates by establishing a regular TCP connection between two endpoints, known as the initial subflow. It then negotiates with the remote endpoint to create additional subflows over different network paths.
B) These subflows are managed by a central entity called the MPTCP scheduler, which ensures efficient data distribution across the available paths. By splitting the data into smaller chunks and assigning them to different subflows, MPTCP enables parallel transmission and optimal resource utilization.
C) The versatility of MPTCP opens up exciting possibilities for various applications. MPTCP can seamlessly switch between different networks in mobile devices, providing uninterrupted connectivity and improved user experience. It also holds great potential in cloud computing, where it can enable efficient data transfers across multiple data centers, reducing latency and enhancing overall performance.
Critical Benefits of Multipath TCP:
1. Improved Performance: MPTCP can distribute the data traffic using multiple paths, enabling faster transmission rates and reducing latency. This enhanced performance is particularly beneficial for bandwidth-intensive applications such as streaming, file transfers, and video conferencing, where higher throughput and reduced latency are crucial.
2. Increased Resilience: MPTCP enhances network resilience by providing seamless failover capabilities. In traditional TCP, if a network path fails, the connection is disrupted, resulting in a delay or even a complete loss of service. However, with MPTCP, if one path becomes unavailable, the connection can automatically switch to an alternative path, ensuring uninterrupted communication.
3. Efficient Resource Utilization: MPTCP allows for better utilization of available network resources. Distributing traffic across multiple paths prevents congestion on a single path and optimizes the usage of available bandwidth. This results in more efficient utilization of network resources and improved overall performance.
4. Seamless Transition between Networks: MPTCP is particularly useful in scenarios where devices need to switch between different networks seamlessly. For example, when a mobile device moves from a Wi-Fi network to a cellular network, MPTCP can maintain the connection and seamlessly transfer the ongoing data traffic to the new network without interruption.
5. Compatibility with Existing Infrastructure: MPTCP is designed to be backward compatible with traditional TCP, making it easy to deploy and integrate into existing network infrastructure. It can coexist with legacy TCP connections and gradually adapt to MPTCP capabilities as more devices and networks support the protocol.
**TCP restricts communication**
Multiple paths connect hosts, but TCP restricts communications to a single path per transport connection. Multiple paths could be used concurrently within the network to maximize resource usage. Improved resilience to network failures and higher throughput should enhance the user experience.
Due to protocol constraints both on the end systems and within the network, Internet resources (particularly bandwidth) are often not fully utilized as the Internet evolves. The end-user experience could be significantly improved if these resources were used simultaneously.
A similar improvement in user experience could also be achieved without as much expenditure on network infrastructure. In resource pooling, these available resources are ‘pooled’ into one logical resource for the user.
**The goal of resource pooling**
As part of multipath transport, disjoint (or partially disjoint) paths across a network are simultaneously used to achieve some of the goals of resource pooling. In addition to increasing resilience, multipath transport protects end hosts from failures on one path. As a result, network capacity can be increased by improving resource utilization efficiency. In a multipath TCP connection, multiple paths are pooled transparently within a transport connection to achieve multipath TCP goals.
When one or both hosts are multihomed, multipath TCP uses multiple paths end-to-end. A host can also manipulate the network path by changing port numbers with Equal Cost MultiPath (ECMP), for example, to create multiple paths within the network.
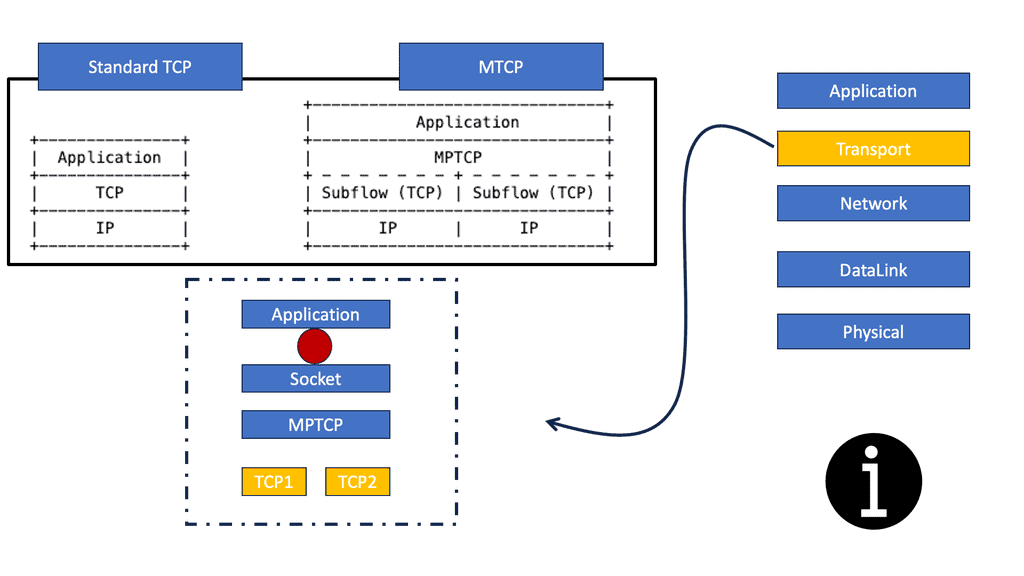
**Multipath TCP and TCP**
Multipath TCP (MPTCP) is a protocol extension that allows for the simultaneous use of multiple network paths between two endpoints. Traditionally, TCP (Transmission Control Protocol) relies on a single path for data transmission, which can limit performance and reliability. With MPTCP, multiple paths can be established between the sender and receiver, enabling the distribution of traffic across these paths. This offers several advantages, including increased throughput, better load balancing, and improved resilience against network failures.
**Automatically Set Up Multiple Paths**
It is designed to automatically set up multiple paths between two endpoints and use those paths to send and receive data efficiently. It also provides a mechanism for detecting and recovering from packet loss and for providing low-latency communication. MPTCP is used in applications that require high throughput and low latency, such as streaming media, virtual private networks (VPNs), and networked gaming. MPTCP is an extension to the standard TCP protocol and is supported by most modern operating systems, including Windows, macOS, iOS, and Linux.
**High Throughput & Low Latency**
MPTCP is an attractive option for applications that require high throughput and low latency, as it can provide both. Additionally, it can provide fault tolerance and redundancy, allowing an application to remain operational even if one or more of its paths fail. This makes it useful for applications such as streaming media, where high throughput and low latency are essential, and reliability is critical.
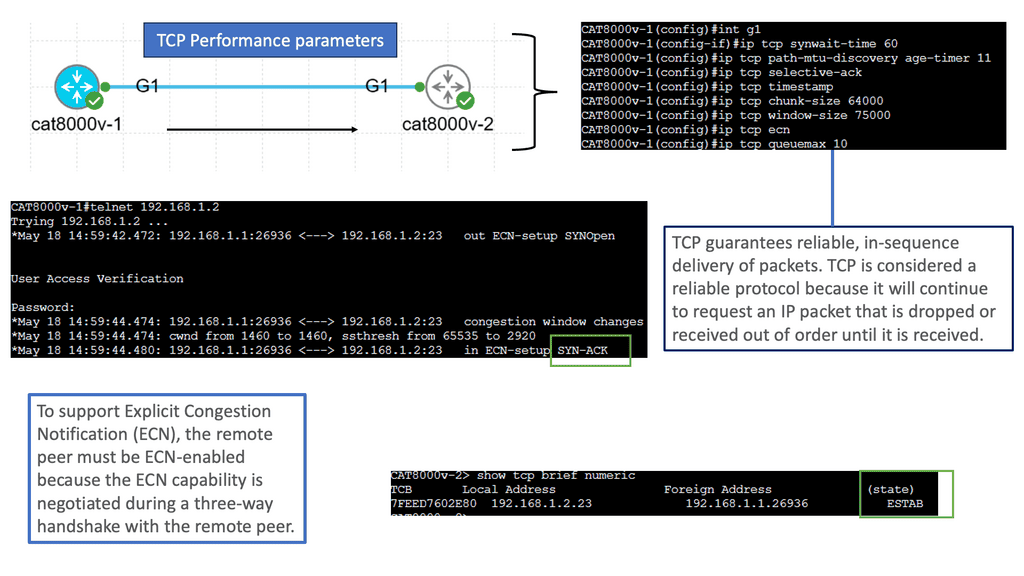
Understanding TCP Performance Parameters
TCP performance parameters are settings that can be tweaked to fine-tune the behavior of the TCP protocol. These parameters dictate how TCP handles congestion control, window size, retransmission, and more. By understanding the impact of each parameter, network administrators can optimize TCP for specific use cases and network conditions.
Congestion Control and Window Size: Congestion control is vital to TCP performance. It ensures that the network does not become overwhelmed with excessive data. Network engineers can balance throughput and network utilization by adjusting TCP congestion control algorithms and window sizes.
Retransmission and Timeout: TCP retransmission and timeout mechanisms ensure reliable data delivery. By fine-tuning retransmission parameters such as RTO (Retransmission Timeout), SRTT (Smoothed Round Trip Time), and RTO Min/Max, network administrators can optimize TCP’s ability to recover from lost packets efficiently. There are a number of trade-offs between aggressive and conservative retransmission strategies and examine how different timeout values impact overall performance.
Buffer Sizes and Burstiness: Buffers are temporary storage areas that hold data during transmission. Properly sizing TCP buffers is essential for maximizing performance. Oversized buffers can lead to increased latency and buffer bloat, while undersized buffers can cause packet loss. There are a number of intricacies of buffer sizing and techniques like Active Queue Management (AQM) to mitigate buffer-related issues.
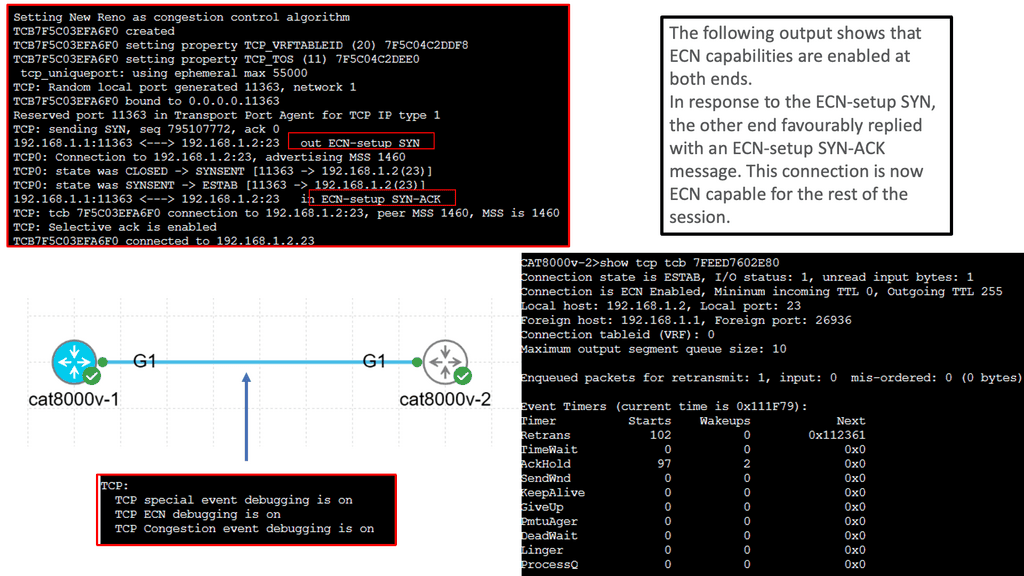
What is TCP MSS?
TCP MSS, or Maximum Segment Size, refers to the maximum amount of data encapsulated in a single TCP segment. It determines the payload size sent within a TCP packet, excluding the TCP header. The MSS value is negotiated during the TCP handshake process, allowing both the sender and receiver to agree upon an optimal segment size for communication.
The TCP MSS value directly affects network performance and efficiency. It impacts the amount of data that can be transmitted in a single packet, affecting a network connection’s overall throughput and latency. Understanding and optimizing the TCP MSS value can significantly improve application performance and reduce unnecessary overhead.
Several factors can influence the TCP MSS value used in a network connection. One primary factor is the underlying network infrastructure’s Maximum Transmission Unit (MTU). The TCP MSS is typically set to match the MTU to avoid fragmentation and improve efficiency. Additionally, network devices, such as routers and firewalls, can enforce specific MSS values, leading to further variations.
It is crucial to consider the network environment and characteristics to optimize TCP MSS for better performance. Understanding the MTU limitations and adjusting the MSS value accordingly can prevent fragmentation and enhance data transmission. Network administrators can also employ Path MTU Discovery techniques to dynamically adjust the MSS value based on the path characteristics between the communicating devices.

Before you proceed, you may find the following helpful:
Reliable byte streams
To start the discussion on multipath TCP, we must understand the basics of Transmission Control Protocol (TCP) and its effect on IP Forwarding. TCP applications offer reliable byte streams with congestion control mechanisms that adjust flows to the current network load. Designed in the 1970s, TCP is the most widely used protocol and remains unchanged, unlike the networks it operates within. In those days, the designers understood there could be link failure and decided to decouple the network layer (IP) from the transport layer (TCP).
Required: Multipath Routing
This enables the routing with IP around link failures without breaking the end-to-end TCP connection. Dynamic routing protocols such as BGP Multipath do this automatically without the need for transport layer knowledge. Even though it has wide adoption, it does not fully align with the multipath networking requirements of today’s networks, driving the need for MP-TCP.
Challenge: Default TCP Operation
TCP delivers reliability using distinct variations of the techniques. Because it provides a byte stream interface, TCP must convert a sending application’s stream of bytes into a set of packets that IP can carry. This is called packetization. These packets contain sequence numbers, which in TCP represent the byte offsets of the first byte in each packet in the overall data stream rather than packet numbers. This allows packets to be of variable size during a transfer and may also allow them to be combined, called repacketization.
Challenge: Single Path Connection Protocol
TCP’s main drawback is that it’s a single path per connection protocol. A single path means once the stream is placed on a path ( endpoints of the connection), it can not be moved to another path even though multiple paths may exist between peers. This characteristic is suboptimal as most of today’s networks and end hosts have multipath characteristics for better performance and robustness.
What is Multipath TCP?
A) Multipath TCP, also known as MPTCP, is an extension to the traditional TCP protocol that allows a single TCP connection to utilize multiple network paths simultaneously. Unlike conventional TCP, which operates on a single path, MPTCP offers the ability to distribute the traffic across multiple paths, enabling more efficient resource utilization and increased overall network capacity.
Multiple Paths for a Single TCP Session
B) Using multiple paths for a single TCP session increases resource usage and resilience for TCP optimization. Additional extensions added to regular TCP simultaneously enable connection transport across multiple links.
C) The core aim of Multipath TCP (MP-TCP) is to allow a single TCP connection to use multiple paths simultaneously by using abstractions at the transport layer. As it operates at the transport layer, the upper and lower layers are transparent to its operation. No network or link-layer modifications are needed.
D) There is no need to change the network or the end hosts. The end hosts use the same socket API call, and the network continues to operate as before. No unique configurations are required as it’s a capability exchange between hosts. Multipath TCP enabling multipath networking is 100% backward compatible with regular TCP.
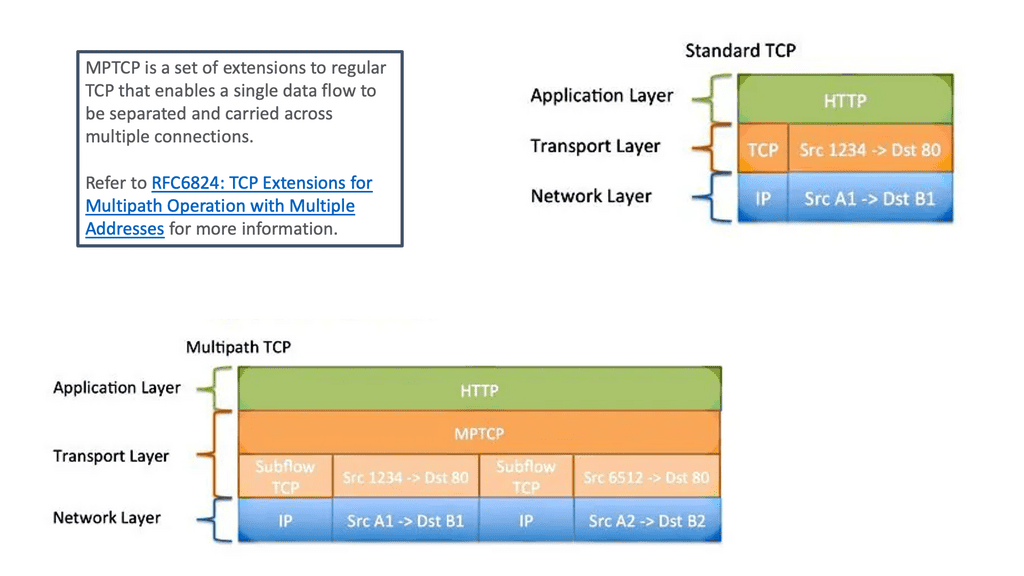
TCP sub flows
MPTCP achieves its goals through sub-flows of individual TCP connections forming an MPTCP session. These sub-flows can be established over different network paths, allowing for parallel data transmission. MPTCP also includes mechanisms for congestion control and data sequencing across the sub-flows, ensuring reliable packet delivery.
MP-TCP binds a TCP connection between two hosts, not two interfaces, like regular TCP. Regular TCP connects two IP endpoints by establishing a source/destination by IP address and port number. The application has to choose a single link for the connection. However, MPTCP creates new TCP connections known as sub-flows, allowing the application to take different links for each subflow.
Subflows are set up the same as regular TCP connections. They consist of a flow of TCP segments operating over individual paths but are still part of the overall MPTCP connection. Subflows are never fixed and may fluctuate in number during the lifetime of the parent Multipath TCP connection.
Multipath TCP uses cases.
The deployment of MPTCP has the potential to benefit various applications and use cases. For example, MPTCP can enable seamless handovers between cellular towers or Wi-Fi access points in mobile networks, providing uninterrupted connectivity. MPTCP can improve server-to-server communications in data centers by utilizing multiple links and avoiding congestion.
Multipath TCP is beneficial in multipath data centers and mobile phone environments. All mobiles allow you to connect via wifi and a 3G network. MP-TCP enables the combined throughput and the switching of interfaces (wifi / 3G ) without disrupting the end-to-end TCP connection.
For example, if you are currently on a 3G network with an active TCP stream, the TCP stream is bound to that interface. If you want to move to the wifi network, you need to reset the connection, and all ongoing TCP connections will reset. With MP-TCP, the swapping of interfaces is transparent.
Multipath networking: leaf-spine data center
Leaf and spine data centers are a revolutionary networking architecture that has revolutionized connectivity in modern data centers. Unlike traditional hierarchical designs, leaf and spine networks are based on a non-blocking, fully meshed structure. The leaf switches act as access points, connecting directly to the spine switches, creating a flat network topology.
Critical Characteristics of Leaf and Spine Data Centers
One key characteristic of leaf and spine data centers is their scalability. With their non-blocking architecture, leaf and spine networks can easily accommodate the increasing demands of modern data centers without sacrificing performance. Additionally, they offer low latency, high bandwidth, and improved resiliency compared to traditional designs.
Next-generation leaf and spine data center networks are built with Equal-Cost Multipath (ECMP). Within the data center, any two endpoints are equidistant. For one endpoint to communicate with another, a TCP flow is placed on a single link, not spread over multiple links. As a result, single-path TCP collisions may occur, reducing the throughput available to that flow.
This is commonly seen for large flows and not small mice flows. When a server starts a TCP connection in a data center, it gets placed on a path and stays there. With MP-TCP, you could use many sub-flows per connection instead of a single path per connection. Then, if some of those sub-flows get congested, you don’t send over that subflow, improving traffic fairness and bandwidth optimizations.
Hash-based distribution
The default behavior of spreading traffic through a LAG or ECMP next hops is based on the hash-based distribution of packets. First, an array of buckets is created, and each outbound link is assigned to one or more. Next, fields such as source-destination IP address / MAC address are taken from the outgoing packet header and hashed based on this endpoint identification. Finally, the hash selects a bucket, and the packet is queued to the interface assigned to that bucket.
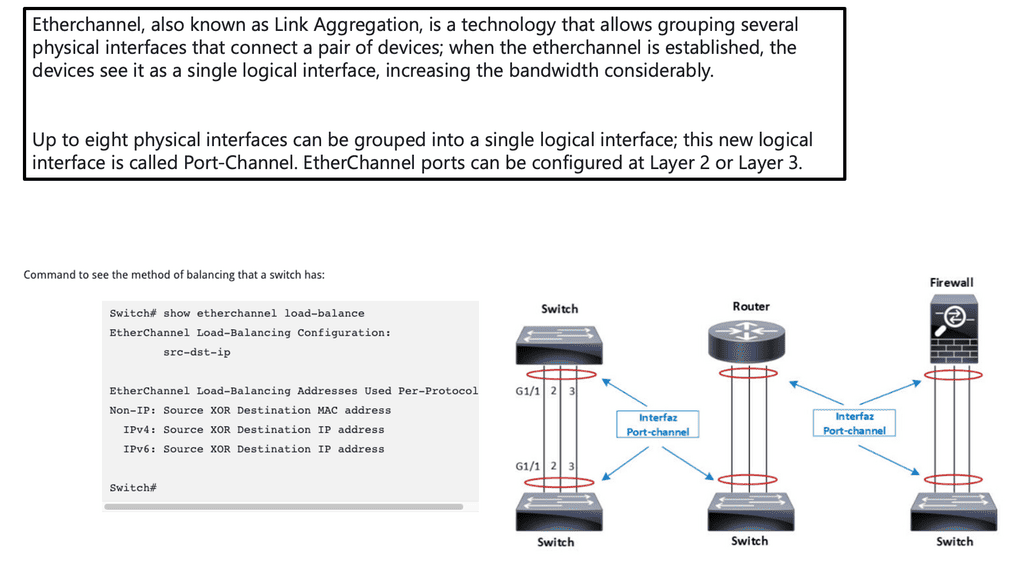
The issue is that the load-balancing algorithm does not consider interface congestions or packet drops. With all mice flows, this is fine, but once you mix mice and elephant flows together, your performance will suffer. An algorithm is needed to identify congested links and then reshuffle the traffic.
A good use for MPTCP is a mix of mice and elephant flows. Generally, MP-TCP does not improve performance for environments with only mice flows.
Small files, say 50 KB, perform similarly to regular TCP. Multipath networking usually has the same results as link bonding as the file size increases. The benefits of MP-TCP come into play when files are enormous (300 KB ). MP-TCP outperforms link bonding at this level as the congestion control can better balance the load over the links.
MP-TCP connection setup
The connection aims to have a single TCP connection with many sub-flows. The two endpoints using MPTCP are synchronized and have connection identifiers for each sub-flow. MPTCP starts the same as regular TCP. Additional TCP subflow sessions are combined into the existing TCP session if different paths are available. The original TCP and other subflow sessions appear as one to the application, and the primary Multipath TCP connection seems like a regular TCP connection. Identifying additional paths boils down to the number of IP addresses on the hosts.
The TCP handshake starts as expected, but within the first SYN is a new MP_CAPABLE option ( value 0x0 ) and a unique connection identifier. This allows the client to indicate that they want to do MPTCP. At this stage, the application layer creates a standard TCP socket with additional variables telling it intends to do MPTCP.
If the receiving server end is MP_CAPABLE, it will reply with the SYN/ACK MP_CAPABLE and its connection identifier. Once the connection is agreed upon, the client and server will set up the upstate. Inside the kernel, a Meta socket is the layer between the application and all the TCP sub-flows.
Under a multipath condition and when multiple paths are detected (based on IP addresses), the client starts a regular TCP handshake with the MP_JOIN option (value 0x1) and uses the connection identifier for the server. The server then replies with a subflow setup. New sub-flows are created, and the scheduler will schedule over each sub-flow as the data is sent from the application to the meta socket.
TCP sequence numbers
Regular TCP uses sequence numbers, enabling the receiving side to return packets in the correct order before sending them to the application. The sender can determine which packets are lost by looking at the ACK.
For MP-TCP, packets must travel multiple paths, so sequence numbers are needed to restore packet order before they are passed to the application. The sequence numbers also inform the sender of any packet loss on a path. When an application sends a packet, the segment is assigned a data sequence number.
TCP looks at the sub-flows to see where to send this segment. When it ships on a subflow, it uses a sequence number and puts it in the TCP header, and the other data sequence number gets set in the TCP options.
The sequence number on the TCP header informs the client of any packet loss. The recipient also uses the data sequence number to reorder packets before sending them to the application.
Congestion control
Congestion control was never a problem in circuit switching. Resources are reserved at call setup to prevent congestion during data transfer, resulting in a lot of bandwidth underutilization due to the reservation of circuits. We then moved to packet switching, where we had a single link with no reservation, but the flows could use as much of the link as they wanted. This increases the utilization of the link and also the possibility of congestion.
To help this situation, congestion control mechanisms were added to TCP. Similar TCP congestion control mechanisms are employed for MP-TCP. Standard TCP congestion control maintains a congestion window for each connection, and you increase the window size on each ACK. With a drop, you half the window.
MP-TCP operates similarly. You maintain one congestion window for each subflow path. Similar to standard TCP, when you have a drop on a subflow, you have half the window for that subflow. However, the increased rules are different from expected TCP behavior.
It gives more of an increase for sub-flows with a larger window. A larger window means it has a lower loss. As a result, traffic moves from congested to uncongested links dynamically.
Closing Points on MP-TCP
At its core, Multipath TCP operates by distributing data packets across multiple paths between a client and server. This process, known as multipath routing, allows for simultaneous use of various network interfaces, such as Wi-Fi and cellular data. By dynamically managing these paths, MPTCP can reroute traffic in response to network congestion or failures, ensuring a seamless and uninterrupted connection. This section delves into the technical intricacies of MPTCP, exploring how it negotiates paths, manages data packets, and maintains connection stability.
The adoption of Multipath TCP brings a plethora of benefits to both consumers and enterprises. For end-users, it means faster download speeds and a more stable internet connection, even in challenging environments. Businesses can leverage MPTCP to enhance the performance of their network applications, ensuring high availability and improved user experiences. Additionally, MPTCP contributes to better load balancing and resource utilization across network infrastructures. This section highlights the key advantages of integrating MPTCP into modern networking solutions.
Multipath TCP is not just a theoretical concept; it has practical applications in various fields. From enhancing mobile networks to optimizing cloud services, MPTCP is making its mark. In mobile devices, MPTCP allows for the simultaneous use of Wi-Fi and cellular networks, providing a more robust connection. In cloud computing, it facilitates efficient resource distribution and redundancy. This section explores real-world use cases, demonstrating how MPTCP is transforming networking across industries.

- DMVPN - May 20, 2023
- Computer Networking: Building a Strong Foundation for Success - April 7, 2023
- eBOOK – SASE Capabilities - April 6, 2023