Understanding Distributed Systems
At their core, distributed systems consist of multiple interconnected nodes working together to achieve a common goal. These nodes can be geographically dispersed and communicate through various protocols. Understanding the structure and behavior of distributed systems is crucial before exploring reliability measures.
To grasp the inner workings of distributed systems, it’s essential to familiarize ourselves with their key components. These include communication protocols, consensus algorithms, fault tolerance mechanisms, and distributed data storage. Each component plays a crucial role in ensuring the reliability and efficiency of distributed systems.
– Challenges and Risks: Reliability in distributed systems faces several challenges and risks due to their inherent nature. Network failures, node crashes, message delays, and data inconsistency are common issues compromising system reliability. Furthermore, the complexity of these systems amplifies the difficulty of diagnosing and resolving failures promptly.
– Replication and Redundancy: To mitigate the risks associated with distributed systems, replication and redundancy techniques are employed. Replicating data and functionalities across multiple nodes ensures fault tolerance and enhances reliability. The system can continue to operate with redundant components even if specific nodes fail.
– Consistency and Coordination: Maintaining data consistency is crucial in distributed systems. Distributed consensus protocols, such as the Paxos or Raft consensus algorithms, ensure that all nodes agree on the same state despite failures or network partitions. Coordinating actions among distributed nodes is essential to prevent conflicts and ensure reliable system behavior.
– Monitoring and Failure Detection: Continuous monitoring and failure detection mechanisms are essential for identifying and resolving issues promptly. Various monitoring tools and techniques, such as heartbeat protocols and health checks, can help detect failures and initiate recovery processes. Proactive monitoring and regular maintenance significantly contribute to the overall reliability of distributed systems.
**Shift in Landscape**
When considering reliability in a distributed system, considerable shifts in our environmental landscape have caused us to examine how we operate and run our systems and networks. We have had a mega change with the introduction of various cloud platforms and their services and containers.
In addition, with the complexity of managing distributed systems observability and microservices observability that unveil significant gaps in current practices in our technologies. Not to mention the flaws with the operational practices around these technologies.
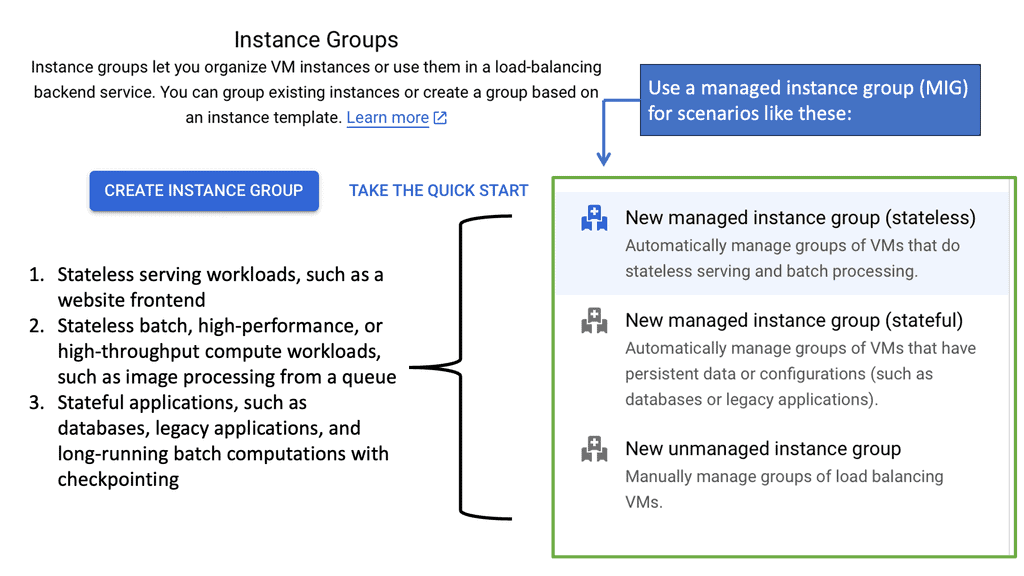
Managed Instance Groups (MIGs)
**Understanding the Basics of Managed Instance Groups**
Managed Instance Groups are collections of virtual machine (VM) instances that are treated as a single entity. They are designed to simplify the management of multiple instances by automating tasks like scaling, updating, and load balancing. With MIGs, you can ensure that your application has the right number of instances running at any given time, responding dynamically to changes in demand.
Google Cloud’s MIGs make it easy to deploy applications with high availability and reliability. By using templates, you can define the configuration for all instances in the group, ensuring consistency and reducing the potential for human error.
—
**Ensuring Reliability in Distributed Systems**
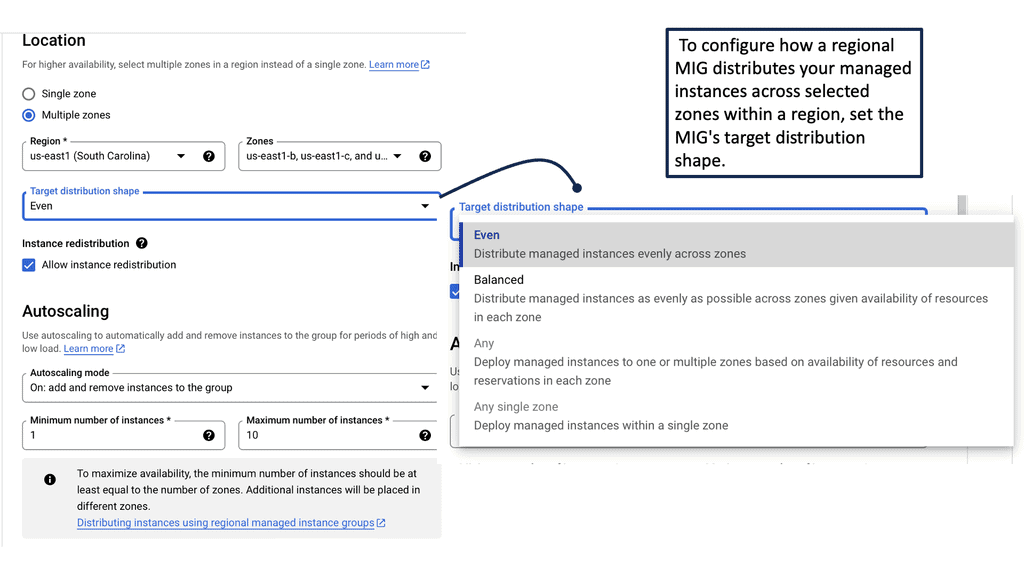
Reliability is a critical component of any distributed system, and Managed Instance Groups play a significant role in achieving it. By distributing workloads across multiple instances and regions, MIGs help prevent single points of failure. If an instance fails, the group automatically replaces it with a new one, minimizing downtime and ensuring continuous service availability.
Moreover, Google Cloud’s infrastructure ensures that your instances are backed by a robust network, providing low-latency access and high-speed connectivity. This further enhances the reliability of your applications and services, giving you peace of mind as you scale.
—
**Scaling with Ease and Flexibility**
One of the standout features of Managed Instance Groups is their ability to scale quickly and efficiently. Whether you’re dealing with sudden spikes in traffic or planning for steady growth, MIGs offer flexible scaling policies to meet your needs. You can scale based on CPU utilization, load balancing capacity, or even custom metrics, allowing for precise control over your application’s performance.
Google Cloud’s autoscaling capabilities mean you only pay for the resources you use, optimizing cost-efficiency while maintaining high performance. This flexibility makes MIGs an ideal choice for businesses looking to grow their cloud infrastructure without unnecessary expenditure.
—
**Integrating with Google Cloud Ecosystem**
Managed Instance Groups seamlessly integrate with other Google Cloud services, providing a cohesive ecosystem for your applications. They work in harmony with Cloud Load Balancing to distribute traffic efficiently and with Stackdriver for monitoring and logging, giving you comprehensive insights into your application’s performance.
By leveraging Google Cloud’s extensive suite of tools, you can build, deploy, and manage applications with greater agility and confidence. This integration streamlines operations and simplifies the complexities of managing a distributed system.
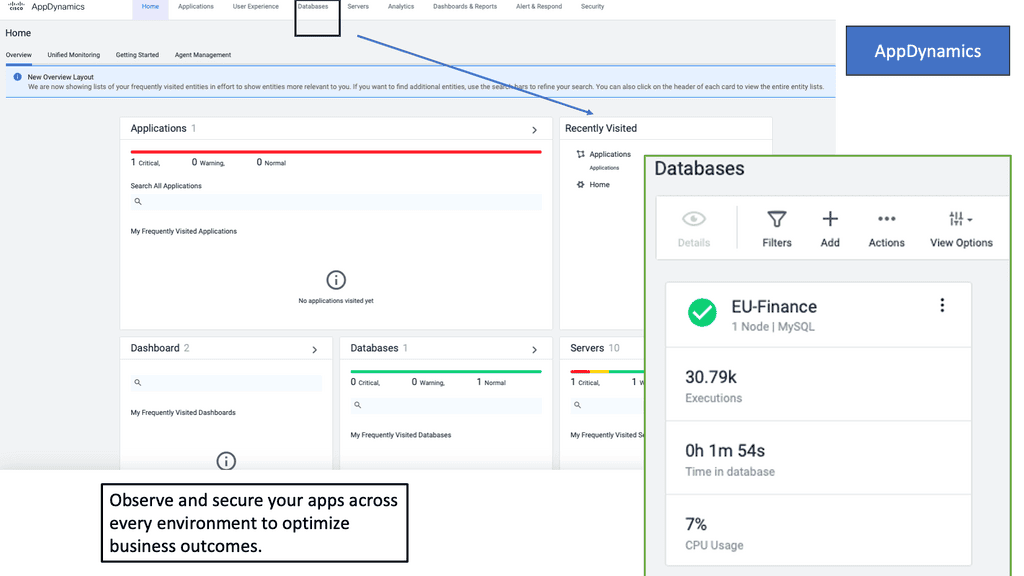
Example Product: Cisco AppDynamics
### What is Cisco AppDynamics?
Cisco AppDynamics is an application performance management (APM) solution that offers deep insights into your application’s performance, user experience, and business impact. It helps IT teams detect, diagnose, and resolve issues quickly, ensuring a seamless digital experience for end-users. By leveraging machine learning and artificial intelligence, AppDynamics provides actionable insights to optimize your applications.
### Key Features of Cisco AppDynamics
#### Real-Time Performance Monitoring
With Cisco AppDynamics, you can monitor the performance of your applications in real-time. This feature allows you to detect anomalies and performance issues as they happen, ensuring that you can address them before they impact your users.
#### End-User Monitoring
Understanding how your users interact with your applications is crucial. AppDynamics offers end-user monitoring, which provides visibility into the user journey, from the front-end user interface to the back-end services. This helps you identify and resolve issues that directly affect user experience.
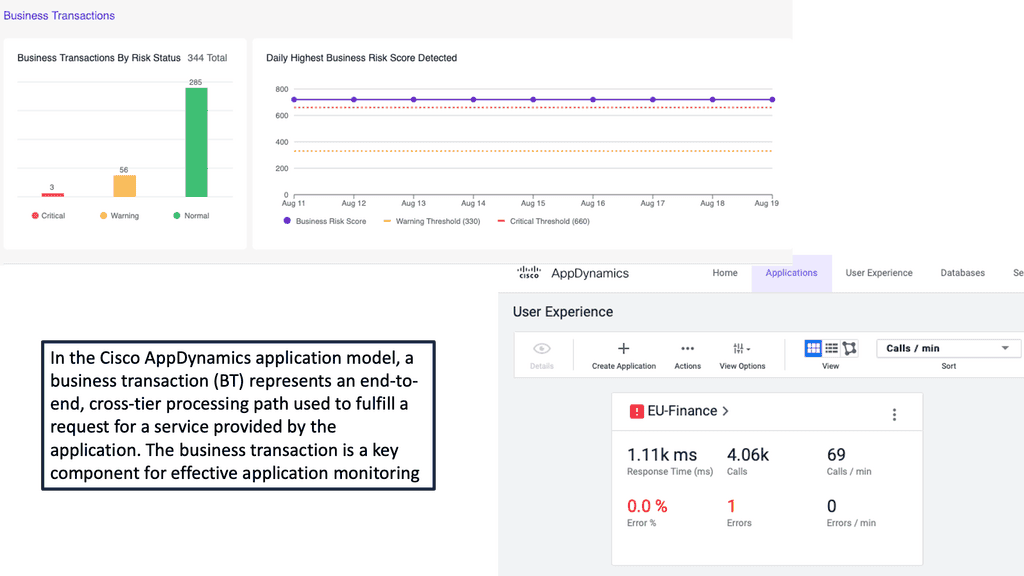
#### Business Transaction Monitoring
AppDynamics breaks down your application into business transactions, which are critical user interactions within your application. By monitoring these transactions, you can gain insights into how your application supports key business processes and identify areas for improvement.
#### AI-Powered Analytics
The platform’s AI-powered analytics enable you to predict and prevent performance issues before they occur. By analyzing historical data and identifying patterns, AppDynamics helps you proactively manage your application’s performance.
### Benefits of Using Cisco AppDynamics
#### Improved Application Performance
By continuously monitoring your application’s performance, AppDynamics helps you identify and resolve issues quickly, ensuring that your application runs smoothly and efficiently.
#### Enhanced User Experience
With end-user monitoring, you can gain insights into how users interact with your application and address any issues that may affect their experience. This leads to increased user satisfaction and retention.
#### Better Business Insights
Business transaction monitoring provides a clear understanding of how your application supports critical business processes. This helps you make data-driven decisions to optimize your application and drive business growth.
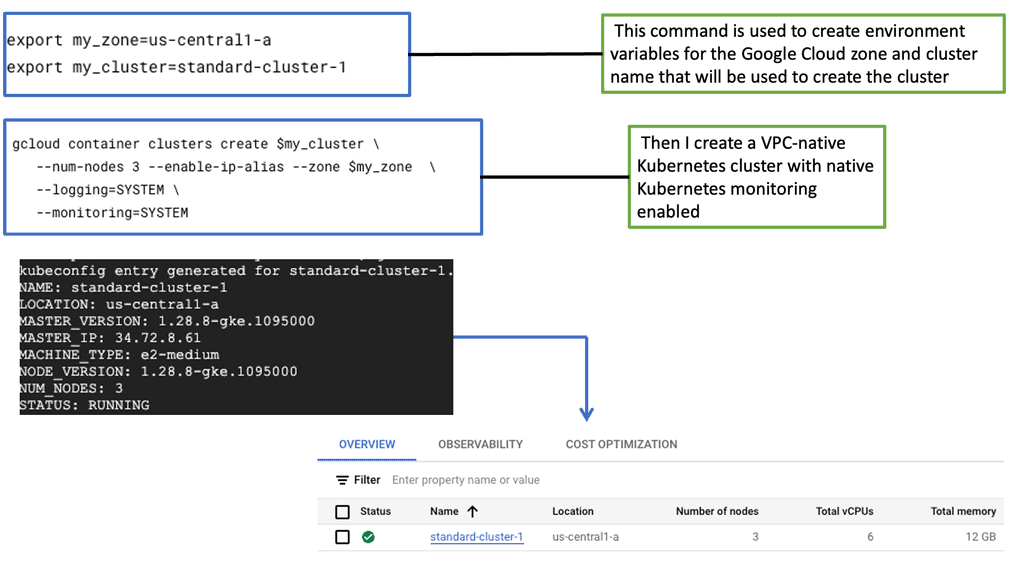
Monitoring GKE Environment
The Significance of Monitoring in GKE
Monitoring in GKE goes beyond simply monitoring resource utilization. It provides valuable insights into the health and performance of your Kubernetes clusters, nodes, and applications running within them. You gain a comprehensive understanding of your system’s behavior by closely monitoring key metrics such as CPU usage, memory utilization, and network traffic. You can proactively address issues before they escalate.
GKE-Native Monitoring has many powerful features that simplify the monitoring process. One notable feature is integrating with Stackdriver, Google Cloud’s monitoring and observability platform.
With this integration, you can access a rich set of monitoring tools, including customizable dashboards, alerts, and logging capabilities, all designed explicitly for GKE deployments. Additionally, GKE-Native Monitoring seamlessly integrates with other Google Cloud services, enabling you to leverage advanced analytics and machine learning capabilities.
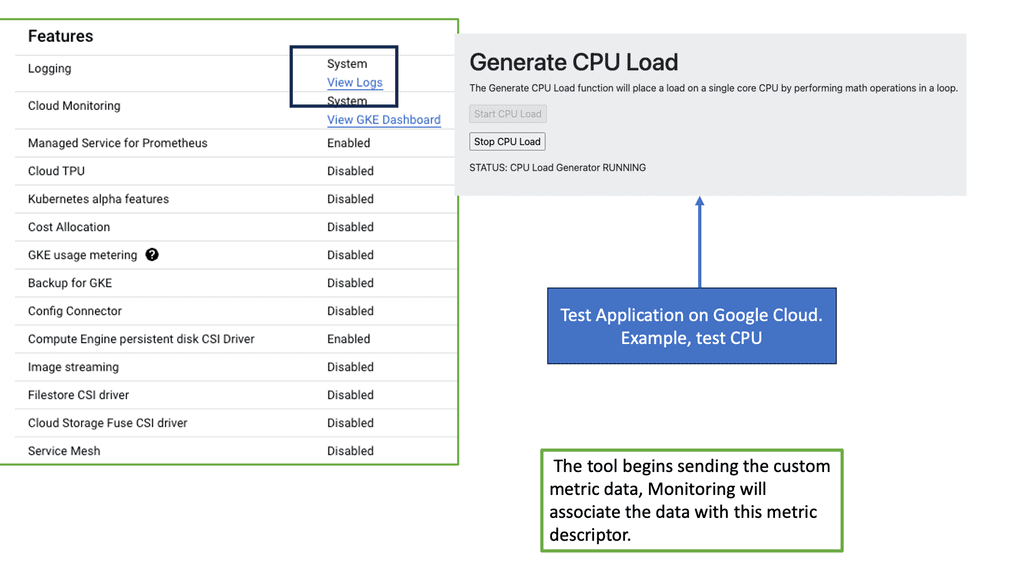
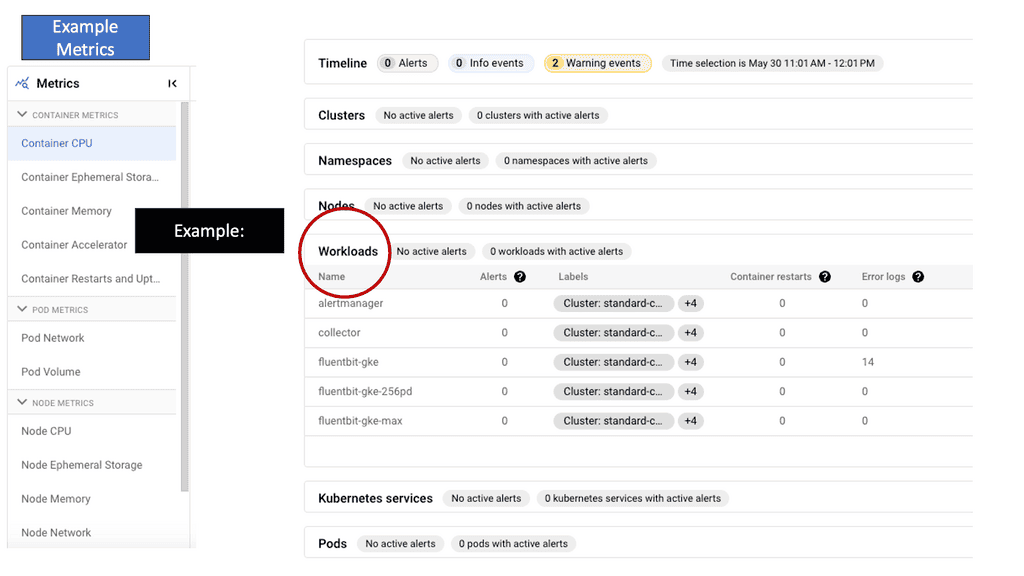
Challenges to Gaining Reliability
**Existing Static Tools**
This has caused a knee-jerk reaction to a welcomed drive-in innovation to system reliability. Yet, some technologies and tools used to manage these innovations do not align with the innovative events. Many of these tools have stayed relatively static in our dynamic environment. So, we have static tools used in a dynamic environment, which causes friction to reliability in distributed systems and the rise for more efficient network visibility.
**Understanding the Complexity**
Distributed systems are inherently complex, with multiple components across different machines or networks. This complexity introduces challenges like network latency, hardware failures, and communication bottlenecks. Understanding the intricate nature of distributed systems is crucial to devising reliable solutions.
Gaining Reliability
**Redundancy and Replication**
One critical approach to enhancing reliability in distributed systems is redundancy and replication. By duplicating critical components or data across multiple nodes, the system becomes more fault-tolerant. This ensures the system can function seamlessly even if one component fails, minimizing the risk of complete failure.
**Consistency and Consensus Algorithms**
Maintaining consistency in distributed systems is a significant challenge due to the possibility of concurrent updates and network delays. Consensus algorithms, such as the Paxos or Raft algorithms, are vital in achieving consistency by ensuring agreement among distributed nodes. These algorithms enable reliable decision-making and guarantee that all nodes reach a consensus state.
**Monitoring and Failure Detection**
To ensure reliability, robust monitoring mechanisms are essential. Monitoring tools can track system performance, resource utilization, and network health. Additionally, implementing efficient failure detection mechanisms allows for prompt identification of faulty components, enabling proactive measures to mitigate their impact on the overall system.
**Load Balancing and Scalability**
Load balancing is crucial in distributing the workload evenly across nodes in a distributed system. It ensures that no single node is overwhelmed, reducing the risk of system instability. Furthermore, designing systems with scalability in mind allows for seamless expansion as the workload grows, ensuring that reliability is maintained even during periods of high demand.
Required: Distributed Tracing
Using distributed tracing, you can profile or monitor the results of requests across a distributed system. Distributed systems can be challenging to monitor since each node generates its logs and metrics. To get a complete view of a distributed system, it is necessary to aggregate these separate node metrics holistically.
A distributed system generally doesn’t access its entire set of nodes but rather a path through those nodes. With distributed tracing, teams can analyze and monitor commonly accessed paths through a distributed system. The distributed tracing is installed on each system node, allowing teams to query the system for information on node health and performance.
Benefits: Distributed Tracing
Despite the challenges, distributed systems offer a wide array of benefits. One notable advantage is enhanced fault tolerance. Distributing tasks and data across multiple nodes improves system reliability, as a single point of failure does not bring down the entire system.
Additionally, distributed systems enable improved scalability, accommodating growing demands by adding more nodes to the network. The applications of distributed systems are vast, ranging from cloud computing and large-scale data processing to peer-to-peer networks and distributed databases.
Google Cloud Trace
Understanding Cloud Trace
Cloud Trace, an integral part of Google Cloud’s observability offerings, provides developers with a detailed view of their application’s performance. It enables tracing and analysis of requests as they flow through different components of a distributed system. By visualizing the latency, bottlenecks, and dependencies, Cloud Trace empowers developers to optimize their applications for better performance and user experience.
Cloud Trace offers a range of features to simplify the monitoring and troubleshooting process. With its distributed tracing capabilities, developers can gain insights into how requests traverse various services, identify latency issues, and pinpoint the root causes of performance bottlenecks. The integration with Google Cloud’s ecosystem allows seamless correlation between traces and other monitoring data, enabling a comprehensive view of application health.
Improve Performance & Reliability
By leveraging Cloud Trace, developers can significantly improve the performance and reliability of their applications. The ability to pinpoint and resolve performance issues quickly translates into enhanced user satisfaction and higher productivity. Moreover, Cloud Trace enables proactive monitoring, ensuring that potential bottlenecks and inefficiencies are identified before they impact end-users. For organizations, this translates into cost savings, improved scalability, and better resource utilization.
Adopting Cloud Trace
Cloud Trace has been adopted by numerous organizations across various industries, with remarkable outcomes. From optimizing the response time of e-commerce platforms to enhancing the efficiency of complex microservices architectures, Cloud Trace has proven its worth in diagnosing performance issues and driving continuous improvement. The real-time visibility provided by Cloud Trace empowers organizations to make data-driven decisions and deliver exceptional user experiences.
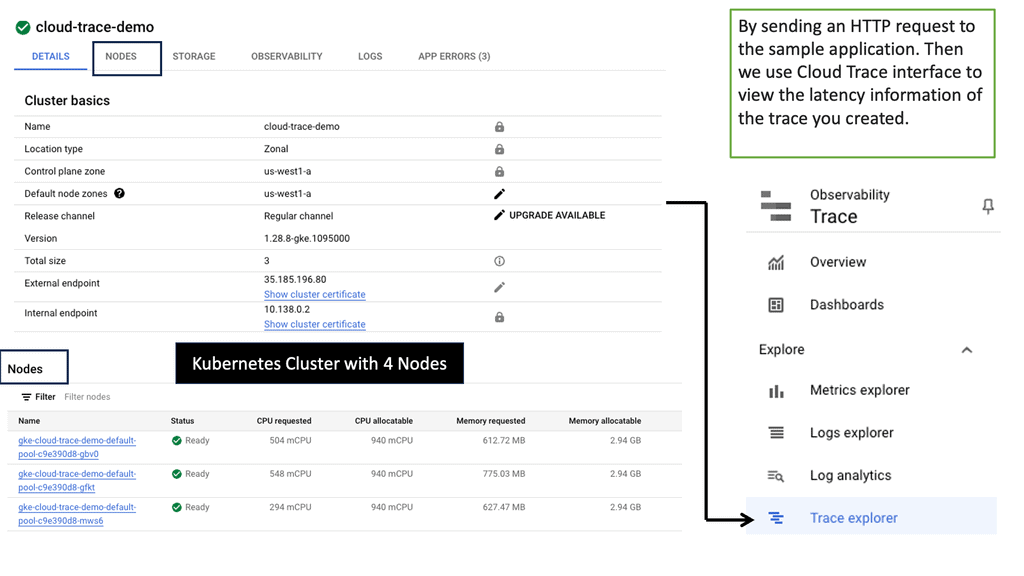
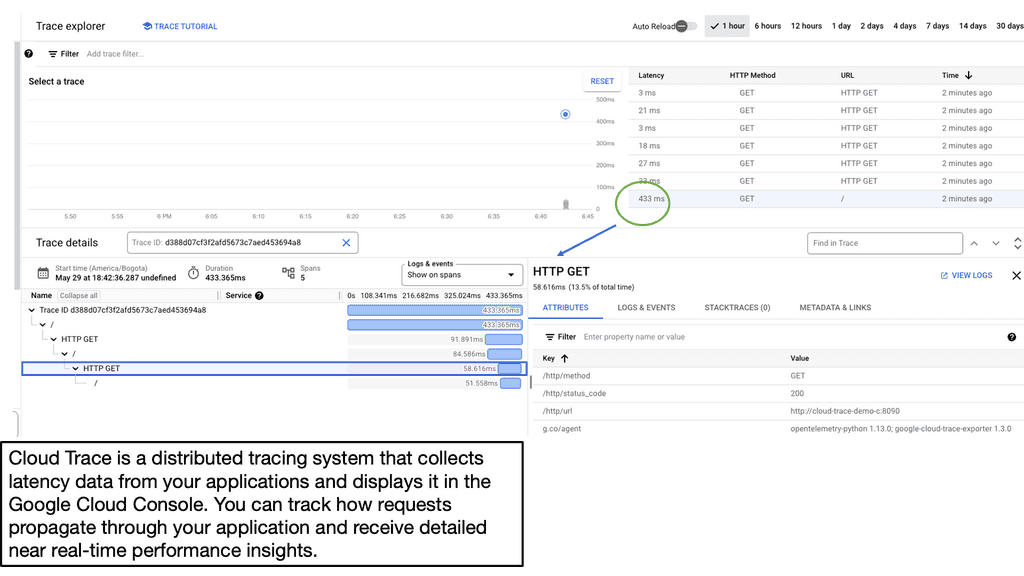
Related: Before you proceed, you may find the following post helpful:
Adopting Distributed Systems
Distributed systems refer to a network of interconnected computers that communicate and coordinate their actions to achieve a common goal. Unlike traditional centralized systems, where a single entity controls all components, distributed systems distribute tasks and data across multiple nodes. This decentralized approach enables enhanced scalability, fault tolerance, and resource utilization.
**Key Components of Distributed Systems**
To comprehend the inner workings of distributed systems, we must familiarize ourselves with their key components. These components include nodes, communication channels, protocols, and distributed file systems. Nodes represent individual machines or devices within the network; communication channels facilitate data transmission, protocols ensure reliable communication and distributed file systems enable data storage across multiple nodes.
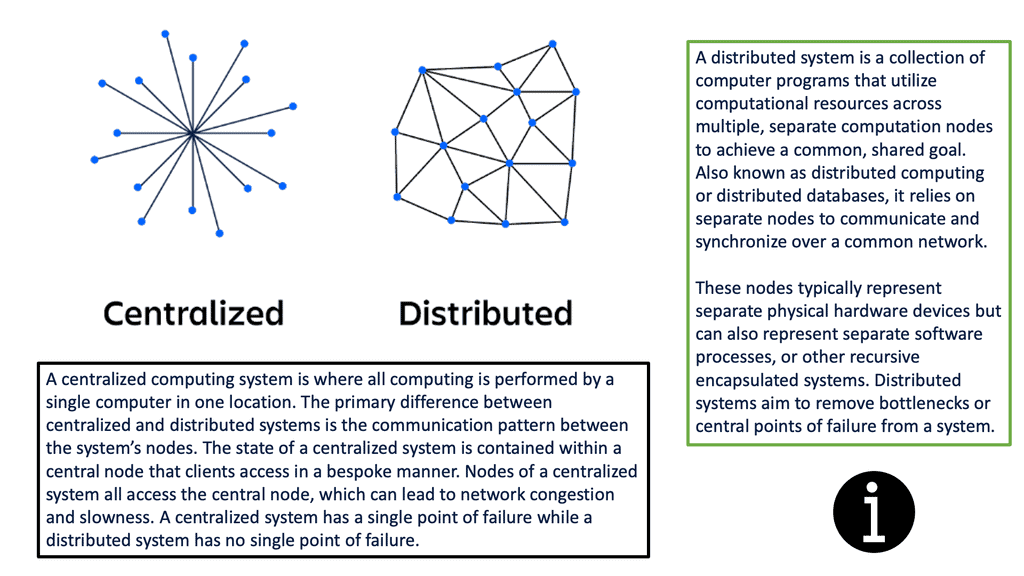
**Distributed Systems Use Cases**
Many modern applications use distributed systems, including mobile and web applications with high traffic. Web browsers or mobile applications serve as clients in a client-server environment, and the server becomes its own distributed system. The modern web server follows a multi-tier system pattern. Requests are delegated to several server logic nodes via a load balancer.
Kubernetes is popular among distributed systems since it enables containers to be combined into a distributed system. Kubernetes orchestrates network communication between the distributed system nodes and handles dynamic horizontal and vertical scaling of the nodes.
Cryptocurrencies like Bitcoin and Ethereum are also peer-to-peer distributed systems. The currency ledger is replicated at every node in a cryptocurrency network. To bootstrap, a currency node connects to other nodes and downloads its full ledger copy. Additionally, cryptocurrency wallets use JSON RPC to communicate with the ledger nodes.
Challenges in Distributed Systems
While distributed systems offer numerous advantages, they also pose various challenges. One significant challenge is achieving consensus among distributed nodes. Ensuring that all nodes agree on a particular value or decision can be complex, especially in the presence of failures or network partitions. Additionally, maintaining data consistency across distributed nodes and mitigating issues related to concurrency control requires careful design and implementation.
**Example: Distributed System of Microservices**
Microservices are one type of distributed system since they decompose an application into individual components. A microservice architecture, for example, may have services corresponding to business features (payments, users, products, etc.), with each element handling the corresponding business logic. Multiple redundant copies of the services will then be available, so there is no single point of failure.
**Distributed Systems: The Challenge**
Distributed systems are required to implement the reliability, agility, and scale expected of modern computer programs. Distributed systems are applications of many different components running on many other machines. Containers are the foundational building block, and groups of containers co-located on a single device comprise the atomic elements of distributed system patterns.
The significant shift we see with software platforms is that they evolve much quicker than the products and paradigms we use to monitor them. We need to consider new practices and technologies with dedicated platform teams to enable a new era of system reliability in a distributed system. Along with the practices of Observability that are a step up to the traditional monitoring of static infrastructure: Observability vs monitoring.
Knowledge Check: Distributed Systems Architecture
-
Client-Server Architecture
A client-server architecture has two primary responsibilities. The client presents user interfaces and is connected to the server via a network. The server handles business logic and state management. Unless the server is redundant, a client-server architecture can quickly degrade into a centralized architecture. A truly distributed client-server setup will consist of multiple server nodes that distribute client connections. In modern client-server architectures, clients connect to encapsulated distributed systems on the server.
-
Multi-tier Architecture
Multi-tier architectures are extensions of client-server architectures. Multi-tier architectures decompose servers into further granular nodes, decoupling additional backend server responsibilities like data processing and management. By processing long-running jobs asynchronously, these additional nodes free up the remaining backend nodes to focus on responding to client requests and interacting with the data store.
-
Peer-to-Peer Architecture
Peer-to-peer distributed systems contain complete instances of applications on each node. There is no separation between presentation and data processing at the node level. A node consists of a presentation layer and a data handling layer. Peer nodes may contain the entire system’s state data.
Peer-to-peer systems have a great deal of redundancy. When initiated and brought online, peer-to-peer nodes discover and connect to other peers, thereby synchronizing their local state with the system’s. As a result of this feature, nodes on a peer-to-peer network won’t be disrupted by the failure of one. Additionally, peer-to-peer systems will persist.
-
Service-orientated Architecture
A service-oriented architecture (SOA) is a precursor to microservices. Microservices differ from SOA primarily in their node scope, which is at the feature level. Each microservice node encapsulates a specific set of business logic, such as payment processing—multiple nodes of business logic interface with independent databases in a microservice architecture. In contrast, SOA nodes encapsulate an entire application or enterprise division. Database systems are typically included within the service boundary of SOA nodes.
Because of their benefits, microservices have become more popular than SOA. The small service nodes provide functionality that teams can reuse through microservices. The advantages of microservices include greater robustness and a more extraordinary ability for vertical and horizontal scaling to be dynamic.
Reliability in Distributed Systems: Components
A- Redundancy and Replication:
Redundancy and replication are two fundamental concepts distributed systems use to enhance reliability. Redundancy involves duplicating critical system components, such as servers, storage devices, or network links, so the redundant component can seamlessly take over if one fails. Replication, on the other hand, involves creating multiple copies of data across different nodes in a system, enabling efficient data access and fault tolerance. By incorporating redundancy and replication, distributed systems can continue to operate even when individual components fail.
B – Fault Tolerance:
Fault tolerance is a crucial aspect of achieving reliability in distributed systems. It involves designing systems to operate correctly even when one or more components encounter failures. Several techniques, such as error detection, recovery, and prevention mechanisms, are employed to achieve fault tolerance.
C – Error Detection:
Error detection techniques, such as checksums, hashing, and cyclic redundancy checks (CRC), identify errors or data corruption during transmission or storage. By verifying data integrity, these techniques help identify and mitigate potential failures in distributed systems.
D – Error Recovery:
Error recovery mechanisms, such as checkpointing and rollback recovery, aim to restore the system to a consistent state after a failure. Checkpointing involves periodically saving the system’s state and data, allowing recovery to a previously known good state in case of failures. On the other hand, rollback recovery involves undoing the effects of failed operations and returning the system to a consistent state.
E – Error Prevention:
Distributed systems employ error prevention techniques, such as redundancy elimination, consensus algorithms, and load balancing to enhance reliability. Redundancy elimination reduces unnecessary duplication of data or computation, thereby reducing the chances of errors. Consensus algorithms ensure that all nodes in a distributed system agree on a shared state despite failures or message delays. Load balancing techniques distribute computational tasks evenly across multiple nodes to prevent overloading and potential shortcomings.
Challenges: Traditional Monitoring
**Lack of Connective Event**
If you examine traditional monitoring systems, they look to capture and investigate signals in isolation. They work in a siloed environment, similar to that of developers and operators before the rise of DevOps. Existing monitoring systems cannot detect the “Unknowns Unknowns” that are familiar with modern distributed systems. This often leads to service disruptions. So, you may be asking what an “Unknown Unknown” is.
I’ll put it to you this way: the distributed systems we see today lack predictability—certainly not enough predictability to rely on static thresholds, alerts, and old monitoring tools. If something is fixed, it can be automated, and we have static events, such as in Kubernetes, a POD reaching a limit.
Then, a replica set introduces another pod on a different node if specific parameters are met, such as Kubernetes Labels and Node Selectors. However, this is only a tiny piece of the failure puzzle in a distributed environment. Today, we have what’s known as partial failures and systems that fail in very creative ways.
Reliability In Distributed System: Creative ways to fail
So, we know that some of these failures are quickly predicted, and actions are taken. For example, if this Kubernetes POD node reaches a specific utilization, we can automatically reschedule PODs on a different node to stay within our known scale limits.
Predictable failures can be automated in Kubernetes and with any infrastructure. An Ansible script is useful when these events occur. However, we have much more to deal with than POD scaling; we have many partial and complicated failures known as black holes.
**In today’s world of partial failures**
Microservices applications are distributed and susceptible to many external factors. On the other hand, if you examine the traditional monolithic application style, all the functions reside in the same process. It was either switched ON or OFF!! Not much happened in between. So, if there is a failure in the procedure, the application as a whole will fail. The results are binary, usually either a UP or Down.
This was easy to detect with some essential monitoring, and failures were predictable. There was no such thing as a partial failure. In a monolith application, all application functions are within the same process. A significant benefit of these monoliths is that you don’t have partial failures.
However, in a cloud-native world, where we have broken the old monolith into a microservices-based application, a client request can go through multiple hops of microservices, and we can have several problems to deal with.
There is a lack of connectivity between the different domains. Many monitoring tools and knowledge will be tied to each domain, and alerts are often tied to thresholds or rate-of-change violations that have nothing to do with user satisfaction, which is a critical metric to care about.
**System reliability: Today, you have no way to predict**
So, the new, modern, and complex distributed systems place very different demands on your infrastructure—considerably different from the simple three-tier application, where everything is generally housed in one location. We can’t predict anything anymore, which breaks traditional monitoring approaches.
When you can no longer predict what will happen, you can no longer rely on a reactive approach to monitoring and management. The move towards a proactive approach to system reliability is a welcomed strategy.
**Blackholes: Strange failure modes**
When considering a distributed system, many things can happen. A service or region can disappear or disappear for a few seconds or ms and reappear. We believe this is going into a black hole when we have strange failure modes. So when anything goes into it will disappear. Peculiar failure modes are unexpected and surprising.
Strange failure modes are undoubtedly unpredictable. So, what happens when your banking transactions are in a black hole? What if your banking balance is displayed incorrectly or if you make a transfer to an external account and it does not show up?
Site Reliability Engineering (SRE) and Observability
Site reliability engineering (SRE) and observational practices are needed to manage these types of unpredictability and unknown failures. SRE is about making systems more reliable. And everyone has a different way of implementing SRE practices. Usually, about 20% of your issues cause 80% of your problems.
You need to be proactive and fix these issues upfront. You need to be able to get ahead of the curve and do these things to prevent incidents from occurring. This usually happens in the wake of a massive incident. This usually acts as a teachable moment. It gives the power to be the reason to listen to a Chaos Engineering project.
New tools and technologies:
1 – Distributed tracing
We have new tools, such as distributed tracing. So, what is the best way to find the bottleneck if the system becomes slow? Here, you can use Distributed Tracing and Open Telemetry. The tracing helps us instrument our system, figuring out where the time has been spent and where it can be used across distributed microservice architecture to troubleshoot problems. Open Telemetry provides a standardized way of instrumenting our system and providing those traces.
2 – SLA, SLI, SLO, and Error Budgets
So we don’t just want to know when something has happened and then react to an event that is not looking from the customer’s perspective. We need to understand if we are meeting SLA by gathering the number and frequency of the outages and any performance issues.
Service Level Objectives (SLO) and Service Level Indicators (SLI) can assist you with measurements. Service Level Objectives (SLOs) and Service Level Indicators (SLI) not only help you with measurements but also offer a tool for having better reliability and forming the base for the reliability stack.