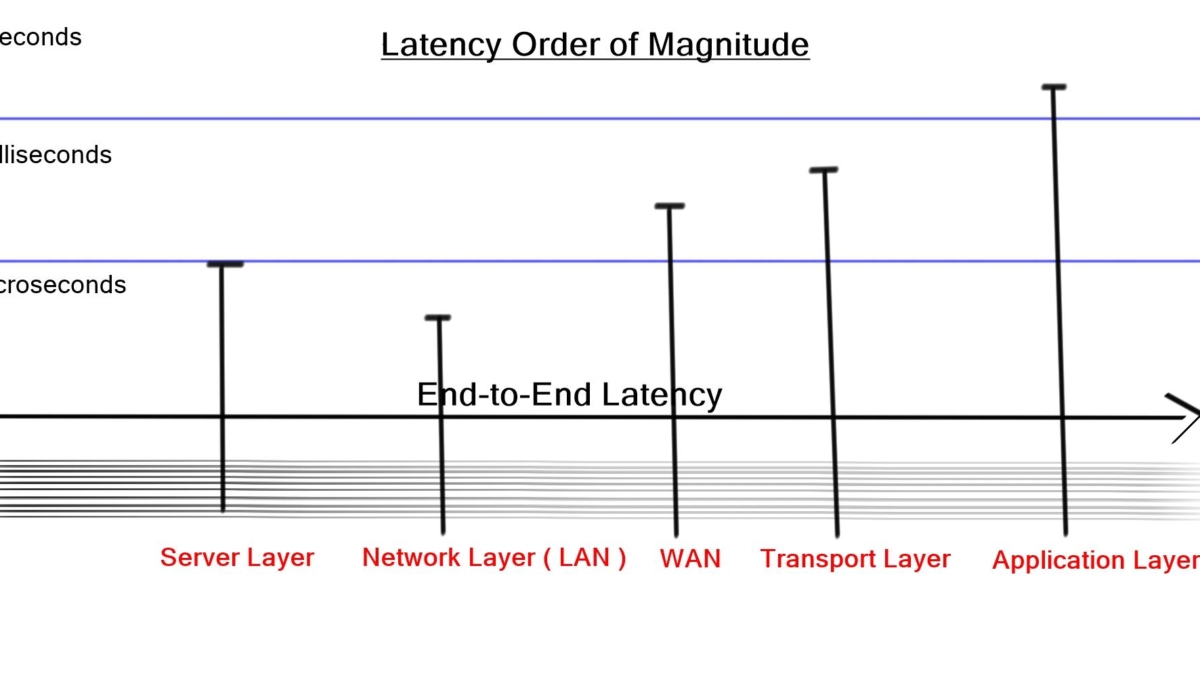
Understanding Low Latency
Low latency, in simple terms, refers to the minimal delay or lag in data transmission between systems. It measures how quickly information can travel from its source to its destination. In network design, achieving low latency involves optimizing various factors such as network architecture, hardware, and protocols. By minimizing latency, businesses can gain a competitive edge, enhance user experiences, and unlock new realms of possibilities.
Low latency is critical in various applications and industries. In online gaming, it ensures that actions occur in real-time, preventing lag that can ruin the gaming experience. In financial trading, low latency is essential for executing trades at the exact right moment, where milliseconds can mean the difference between profit and loss. For streaming services, low latency allows for a seamless viewing experience without buffering interruptions.
The Benefits of Low Latency
1: – ) Low-latency network design offers a plethora of benefits across different industries. In the financial sector, it enables lightning-fast trades, providing traders with a significant advantage in highly volatile markets.
2: – ) Low latency ensures seamless gameplay for online gaming enthusiasts, reducing frustrating lags and enhancing immersion.
3: – ) Beyond finance and gaming, low latency networks improve real-time collaboration, enable telemedicine applications, and enhance the performance of emerging technologies like autonomous vehicles and Internet of Things (IoT) devices.
**Achieving Low Latency**
Achieving low latency involves optimizing network infrastructure and using advanced technology. This can include using fiber optic connections, which offer faster data transmission speeds, and deploying edge computing, which processes data closer to its source to reduce delay. Moreover, Content Delivery Networks (CDNs) distribute content across multiple locations, bringing it closer to the end-user and, thus, reducing latency.
1. Network Infrastructure: To achieve low latency, network designers must optimize the infrastructure by reducing bottlenecks, eliminating single points of failure, and ensuring sufficient bandwidth capacity.
2. Proximity: Locating servers and data centers closer to end-users can significantly reduce latency. By minimizing the physical distance, data can travel faster, resulting in lower latency.
3. Traffic Prioritization: Prioritizing latency-sensitive traffic within the network can help ensure that critical data packets are given higher priority, reducing the overall latency.
4. Quality of Service (QoS): Implementing QoS mechanisms allows network administrators to allocate resources based on application requirements. By prioritizing latency-sensitive applications, low latency can be maintained.
5. Optimization Techniques: Various optimization techniques, such as caching, compression, and load balancing, can further reduce latency by minimizing the volume of data transmitted and efficiently distributing the workload.
Traceroute – Testing for Latency and Performance
**How Traceroute Works**
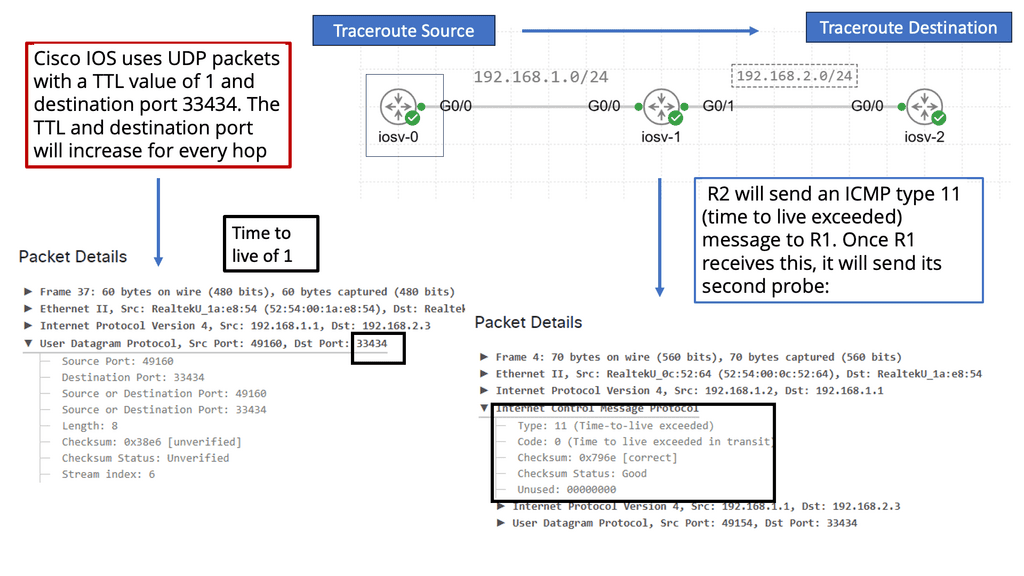
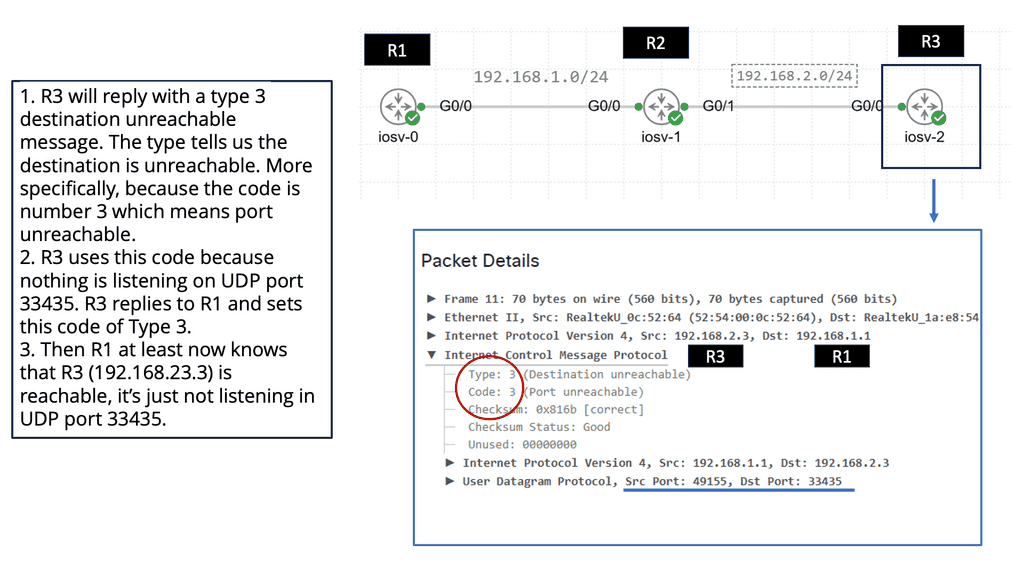
At its core, traceroute operates by sending packets with increasing time-to-live (TTL) values. Each router along the path decrements the TTL by one before forwarding the packet. When a router’s TTL reaches zero, it discards the packet and sends back an error message to the sender. Traceroute uses this response to identify each hop, gradually mapping the entire route from source to destination. By analyzing the time taken for each response, traceroute also highlights latency issues at specific hops.
**Using Traceroute Effectively**
Running traceroute is simple, yet understanding its output requires some insight. The command displays a list of routers (or hops) with their respective IP addresses and the round-trip time (RTT) for packets to reach each router and return. This information can be used to diagnose network issues, such as identifying a slow or problematic hop. Network engineers often rely on traceroute to determine whether a bottleneck lies within their control or further along the internet’s infrastructure.
**Common Challenges and Solutions**
While traceroute is a powerful tool, it comes with its own set of challenges. Some routers may be configured to deprioritize or block traceroute packets, resulting in missing information. Additionally, asymmetric routing paths, where outbound and return paths differ, can complicate the analysis. However, understanding these limitations allows users to interpret traceroute results more accurately, using supplementary tools or methods to gain a comprehensive view of network health.
**Key Challenges in Reducing Latency**
Achieving low latency is a complex undertaking that involves several challenges. One of the primary hurdles is network distance. The physical distance between servers and users can significantly affect data transmission speed. Additionally, network congestion can lead to delays, making it difficult to maintain low latency consistently. Another challenge is the processing time required by servers to handle requests, which can introduce unwanted delays. This section delves into these challenges, examining how they hinder efforts to reduce latency.
**Technological Solutions and Innovations**
Despite the challenges, technological advancements offer promising solutions for reducing latency. Edge computing is one such innovation, bringing data processing closer to the user to minimize transmission time. Content delivery networks (CDNs) also play a crucial role by caching content in multiple locations worldwide, thereby reducing latency for end-users. Moreover, advancements in hardware and software optimization techniques contribute significantly to lowering processing times. In this section, we’ll explore these solutions and their potential to overcome latency challenges.
Google Cloud Machine Types
**Understanding Google Cloud’s Machine Type Offerings**
Google Cloud’s machine type families are categorized primarily based on workload requirements. These categories are designed to cater to various use cases, from general-purpose computing to specialized machine learning tasks. The three main families include:
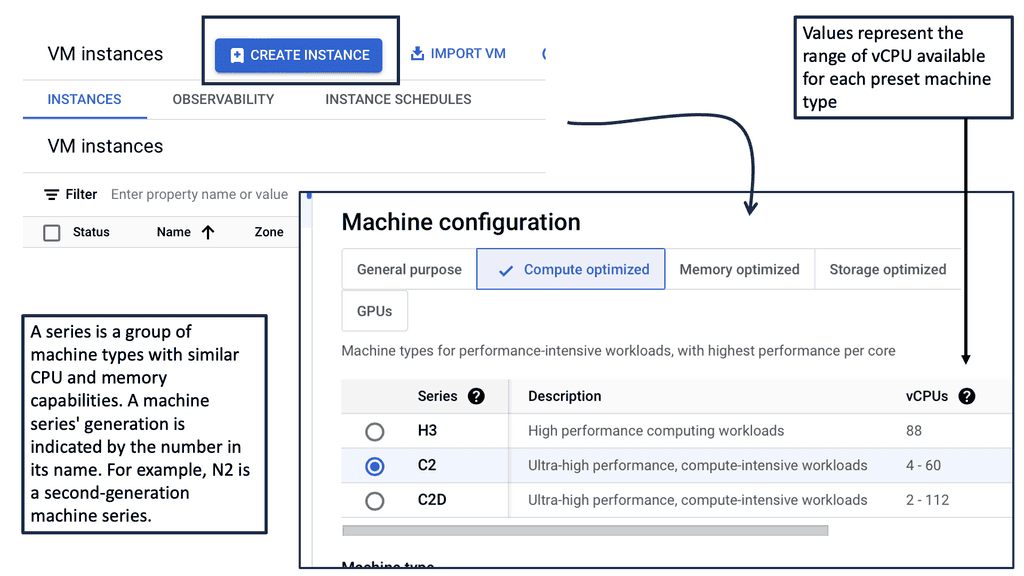
1. **General Purpose**: This category is ideal for balanced workloads. It offers a mix of compute, memory, and networking resources. The e2 and n2 series are popular choices for those seeking cost-effective options with reasonable performance.
2. **Compute Optimized**: These machines are designed for high-performance computing tasks that require more computational power. The c2 series, for instance, provides excellent performance per dollar, making it ideal for CPU-intensive workloads.
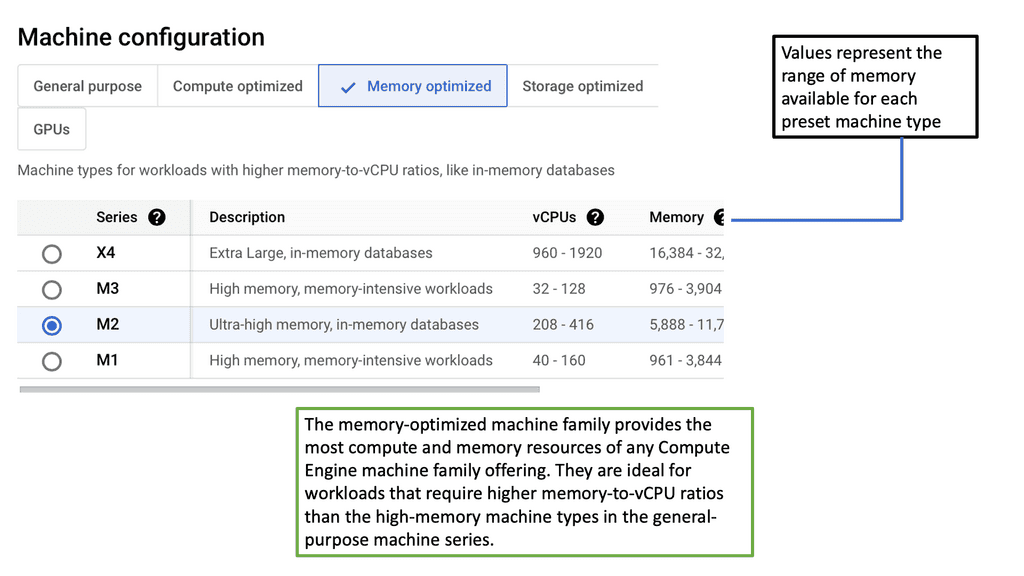
3. **Memory Optimized**: For applications requiring substantial memory, such as large databases or in-memory analytics, the m1 and m2 series offer high memory-to-vCPU ratios, ensuring that memory-hungry applications run smoothly.
—
**The Importance of Low Latency Networks**
One of the critical factors in the performance of cloud-based applications is network latency. Google Cloud’s low latency network infrastructure is engineered to minimize delays, ensuring rapid data transfer and real-time processing capabilities. By leveraging a global network of data centers and high-speed fiber connections, Google Cloud provides a robust environment for latency-sensitive applications such as gaming, video streaming, and financial services.
—
**Choosing the Right Machine Type for Your Needs**
Selecting the appropriate machine type family is crucial for optimizing both performance and cost. Factors to consider include the nature of the workload, budget constraints, and the importance of scalability. For instance, a startup with a limited budget may prioritize cost-effective general-purpose machines, while a media company focusing on video rendering might opt for compute-optimized instances.
Additionally, Google Cloud’s flexible pricing models, including sustained use discounts and committed use contracts, offer further opportunities to save while scaling resources as needed.

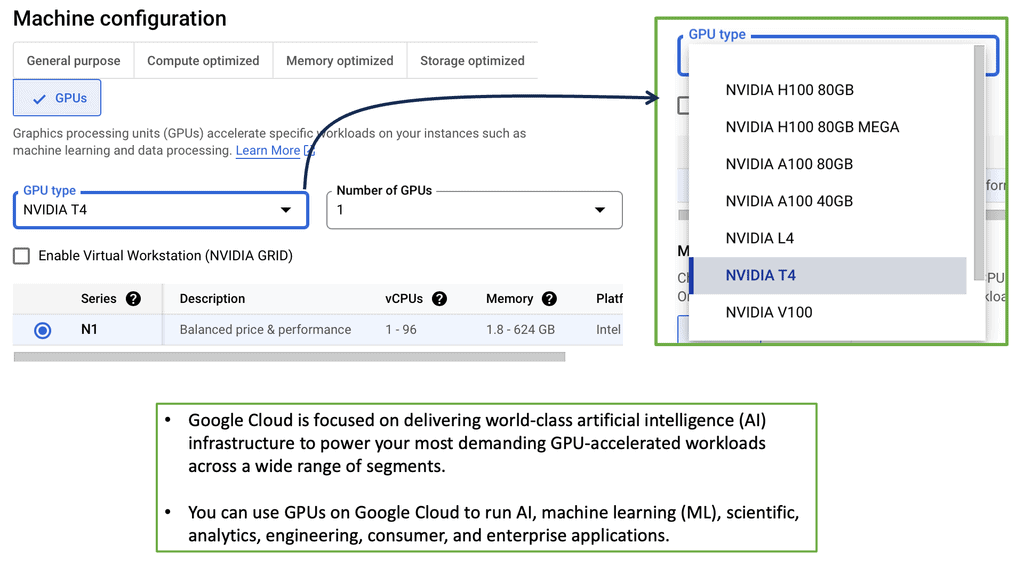
**Optimizing Cloud Performance with Google Cloud**
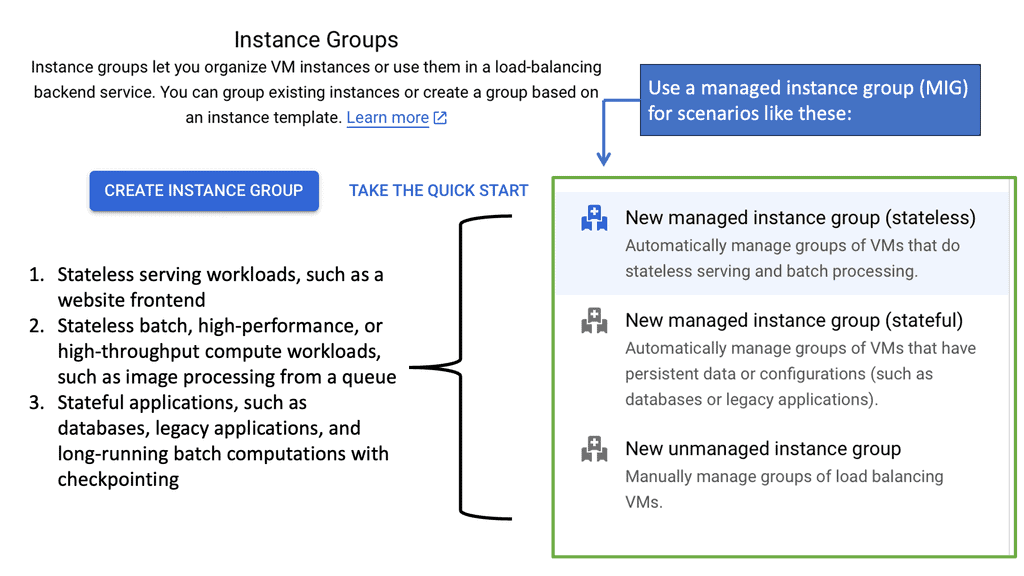
### Understanding Managed Instance Groups
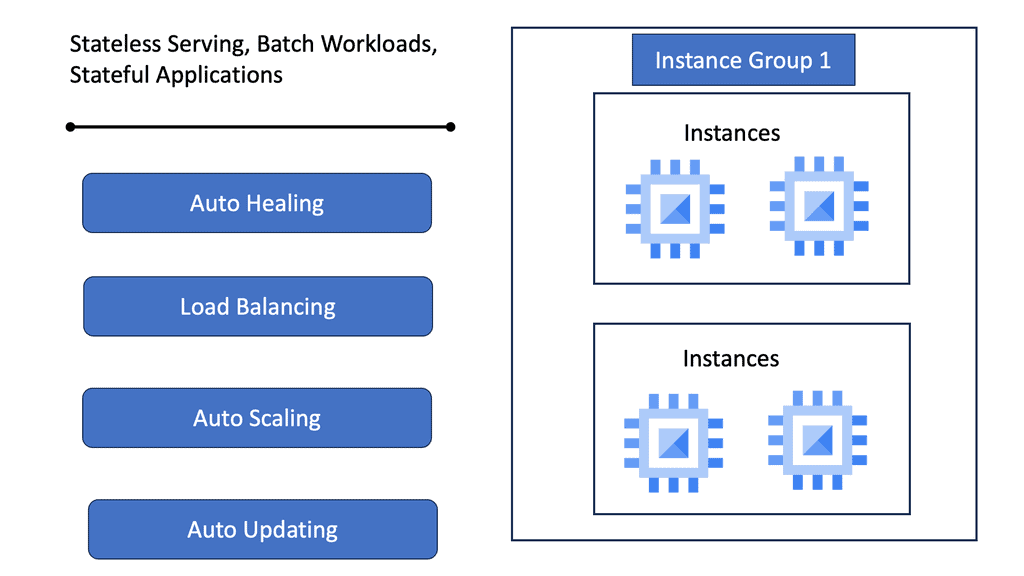
In the ever-evolving world of cloud computing, Managed Instance Groups (MIGs) have emerged as a critical component for maintaining and optimizing infrastructure. Google Cloud, in particular, offers robust MIG services that allow businesses to efficiently manage a fleet of virtual machines (VMs) while ensuring high availability and low latency. By automating the process of scaling and maintaining VM instances, MIGs help streamline operations and reduce manual intervention.
### Benefits of Using Managed Instance Groups
One of the primary benefits of utilizing Managed Instance Groups is the automatic scaling feature. This enables your application to handle increased loads by dynamically adding or removing VM instances based on demand. This elasticity ensures that your applications remain responsive and maintain low latency, which is crucial for providing a seamless user experience.
Moreover, Google Cloud’s MIGs facilitate seamless updates and patches to your VMs. With rolling updates, you can deploy changes gradually across instances, minimizing downtime and ensuring continuous availability. This process allows for a safer and more controlled update environment, reducing the risk of disruption to your operations.
### Achieving Low Latency with Google Cloud
Low latency is a critical factor in delivering high-performance applications, especially for real-time processing and user interactions. Google Cloud’s global network infrastructure, coupled with Managed Instance Groups, plays a vital role in achieving this goal. By distributing workloads across multiple instances and regions, you can minimize latency and ensure that users worldwide have access to fast and reliable services.
Additionally, Google Cloud’s load balancing services work in tandem with MIGs to evenly distribute traffic, preventing any single instance from becoming a bottleneck. This distribution ensures that your application can handle high volumes of traffic without degradation in performance, further contributing to low latency operations.
—
### Best Practices for Implementing Managed Instance Groups
When implementing Managed Instance Groups, it’s essential to follow best practices to maximize their effectiveness. Start by clearly defining your scaling policies based on your application’s needs. Consider factors such as CPU utilization, request count, and response times to determine when new instances should be added or removed.
It’s also crucial to monitor the performance of your MIGs continuously. Utilize Google Cloud’s monitoring and logging tools to gain insights into the health and performance of your instances. By analyzing this data, you can make informed decisions on scaling policies and infrastructure optimizations.
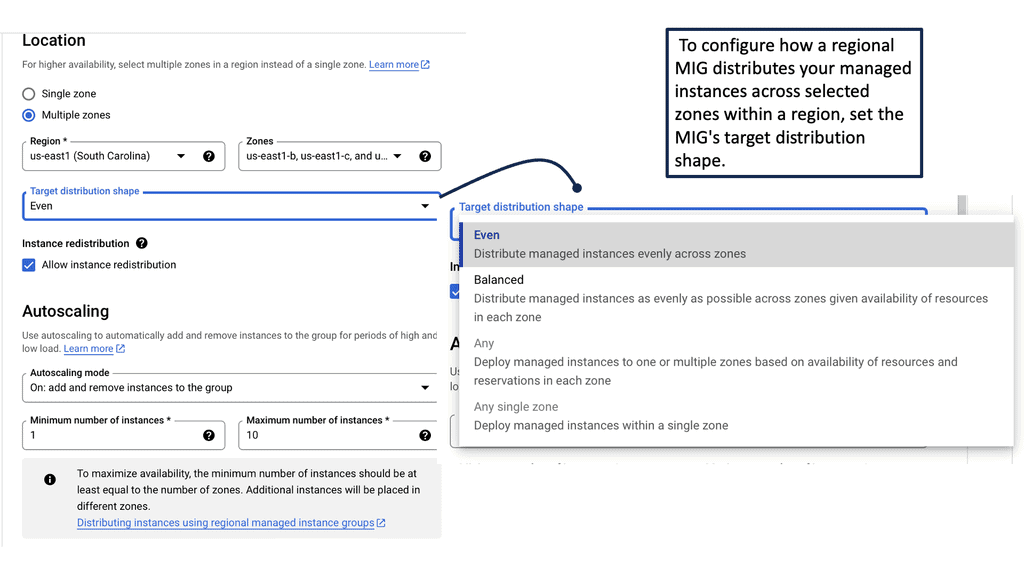
### The Role of Health Checks in Load Balancing
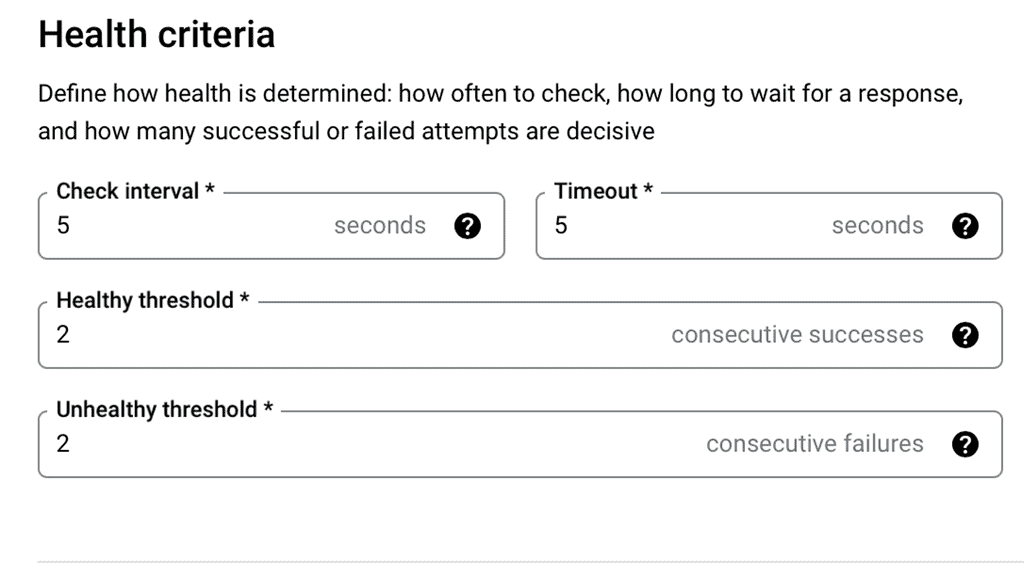
Health checks are the sentinels of your load balancing strategy. They monitor the status of your server instances, ensuring that traffic is only directed to healthy ones. In Google Cloud, health checks can be configured to check the status of backend services via various protocols like HTTP, HTTPS, TCP, and SSL. By setting parameters such as check intervals and timeout periods, you can fine-tune how Google Cloud determines the health of your instances. This process helps in avoiding downtime and maintaining a seamless user experience.
—
### Configuring Health Checks for Low Latency
Latency is a critical factor when it comes to user satisfaction. High latency can lead to slow-loading applications, frustrating users, and potentially driving them away. By configuring health checks appropriately, you can keep latency to a minimum. Google Cloud allows you to set up health checks that are frequent and precise, enabling the load balancer to quickly detect any issues and reroute traffic to healthy instances. Fine-tuning these settings helps in maintaining low latency, thus ensuring that your application remains responsive and efficient.
—
### Best Practices for Effective Health Checks
Implementing effective health checks involves more than just setting up default parameters. Here are some best practices to consider:
1. **Customize Check Frequency and Timeout**: Depending on your application’s needs, customize the frequency and timeout settings. More frequent checks allow for quicker detection of issues but may increase resource consumption.
2. **Diverse Protocols**: Utilize different protocols for different services. For example, use HTTP checks for web applications and TCP checks for database services.
3. **Monitor and Adjust**: Regularly monitor the performance of your health checks and adjust settings as necessary. This ensures that your system adapts to changing demands and maintains optimal performance.
4. **Failover Strategies**: Incorporate failover strategies to handle instances where the primary server pool is unhealthy, ensuring uninterrupted service.

Google Cloud Data Centers
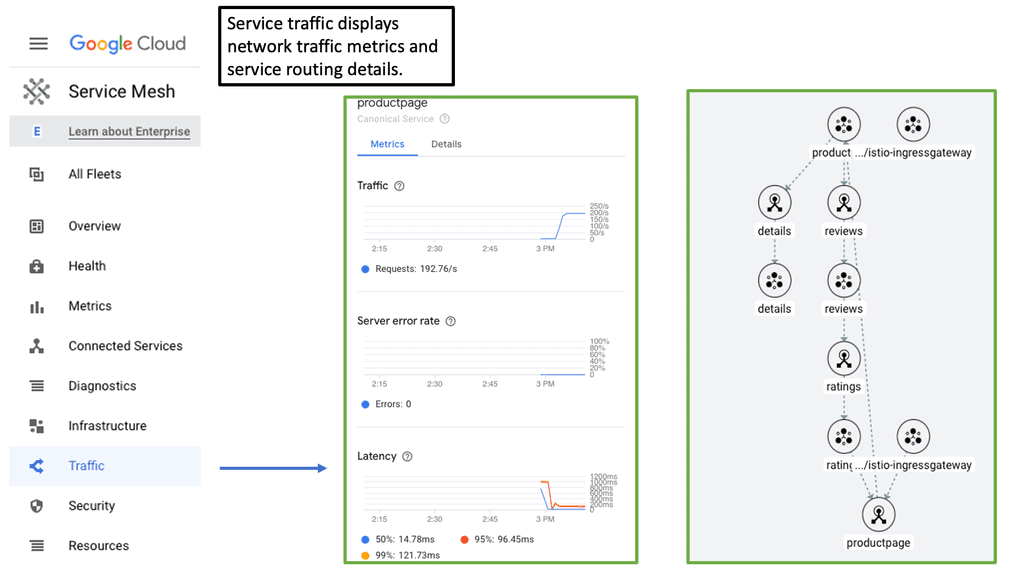
#### What is a Cloud Service Mesh?
A cloud service mesh is a configurable infrastructure layer for microservices applications that makes communication between service instances flexible, reliable, and fast. It provides a way to control how different parts of an application share data with one another. A service mesh does this by introducing a proxy for each service instance, which handles all incoming and outgoing network traffic. This ensures that developers can focus on writing business logic without worrying about the complexities of communication and networking.
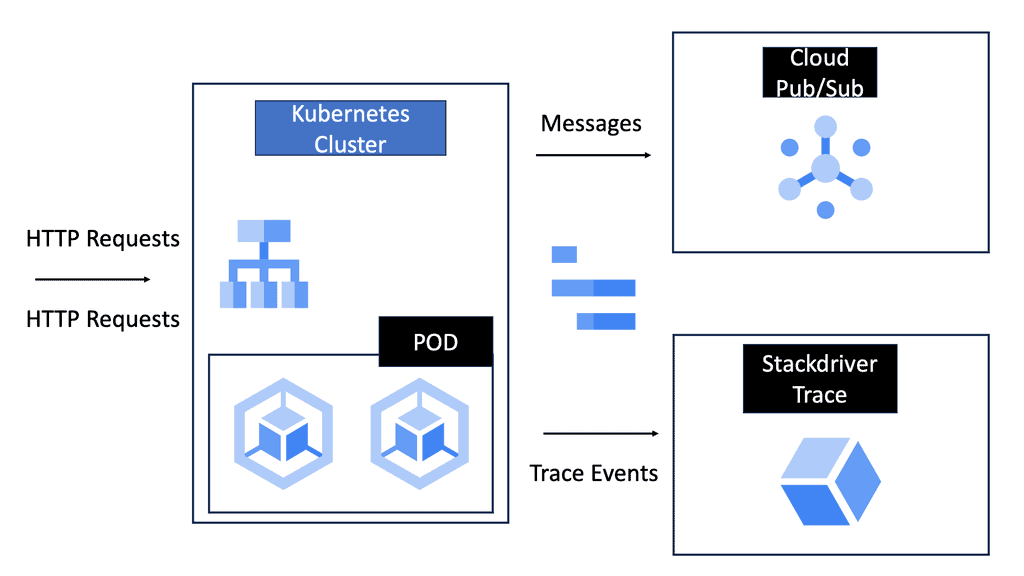
#### Importance of Low Latency
In today’s digital landscape, low latency is crucial for providing a seamless user experience. Whether it’s streaming video, online gaming, or real-time financial transactions, users expect instantaneous responses. A cloud service mesh optimizes the communication paths between microservices, ensuring that data is transferred quickly and efficiently. This reduction in latency can significantly improve the performance and responsiveness of applications.


#### Key Features of a Cloud Service Mesh
1. **Traffic Management**: One of the fundamental features of a service mesh is its ability to manage traffic between services. This includes load balancing, traffic splitting, and fault injection, which can help in maintaining low latency and high availability.
2. **Security**: Security is another critical aspect. A service mesh can enforce policies for mutual TLS (mTLS) authentication and encryption, ensuring secure communication between services without adding significant overhead that could affect latency.
3. **Observability**: With built-in observability features, a service mesh provides detailed insights into the performance and health of services. This includes metrics, logging, and tracing, which are essential for diagnosing latency issues and optimizing performance.
#### Implementing a Cloud Service Mesh
Implementing a service mesh involves deploying a set of proxies alongside your microservices. Popular service mesh solutions like Istio, Linkerd, and Consul provide robust frameworks for managing this implementation. These tools offer extensive documentation and community support, making it easier for organizations to adopt service meshes and achieve low latency performance.

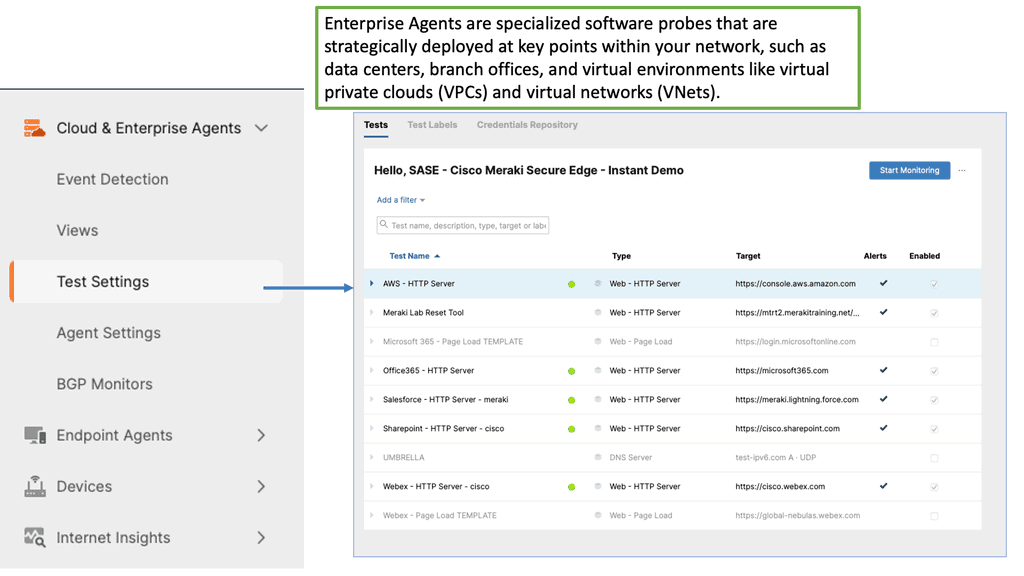
Example Product: Cisco ThousandEyes
### What is Cisco ThousandEyes?
Cisco ThousandEyes is a powerful network intelligence platform designed to monitor, diagnose, and optimize the performance of your data center. It provides end-to-end visibility into network paths, application performance, and user experience, giving you the insights you need to maintain optimal operations. By leveraging cloud-based agents and enterprise agents, ThousandEyes offers a holistic view of your network, enabling you to identify and resolve performance bottlenecks quickly.
### Key Features and Benefits
#### Comprehensive Visibility
One of the standout features of Cisco ThousandEyes is its ability to provide comprehensive visibility across your entire network. Whether it’s on-premises, in the cloud, or a hybrid environment, ThousandEyes ensures you have a clear view of your network’s health and performance. This visibility extends to both internal and external networks, allowing you to monitor the entire data flow from start to finish.
#### Proactive Monitoring and Alerts
ThousandEyes excels in proactive monitoring, continuously analyzing your network for potential issues. The platform uses advanced algorithms to detect anomalies and performance degradation, sending real-time alerts to your IT team. This proactive approach enables you to address problems before they escalate, minimizing downtime and ensuring a seamless user experience.
#### Detailed Performance Metrics
With Cisco ThousandEyes, you gain access to a wealth of detailed performance metrics. From latency and packet loss to application response times and page load speeds, ThousandEyes provides granular data that helps you pinpoint the root cause of performance issues. This level of detail is crucial for effective troubleshooting and optimization, empowering you to make data-driven decisions.

### Use Cases: How ThousandEyes Transforms Data Center Performance
#### Optimizing Application Performance
For organizations that rely heavily on web applications, ensuring optimal performance is critical. ThousandEyes allows you to monitor application performance from the end-user perspective, identifying slowdowns and bottlenecks that could impact user satisfaction. By leveraging these insights, you can optimize your applications for better performance and reliability.
#### Enhancing Cloud Service Delivery
As more businesses move to the cloud, maintaining high performance across cloud services becomes increasingly important. ThousandEyes provides visibility into the performance of your cloud services, helping you ensure they meet your performance standards. Whether you’re using AWS, Azure, or Google Cloud, ThousandEyes can help you monitor and optimize your cloud infrastructure.
#### Improving Network Resilience
Network outages can have devastating effects on your business operations. ThousandEyes helps you build a more resilient network by identifying weak points and potential failure points. With its detailed network path analysis, you can proactively address vulnerabilities and enhance your network’s overall resilience.
Achieving Low Latency
A: Understanding Latency: Latency, simply put, is the time it takes for data to travel from its source to its destination. The lower the latency, the faster the response time. To comprehend the importance of low latency network design, it is essential to understand the factors that contribute to latency, such as distance, network congestion, and processing delays.
B: Bandwidth Optimization: Bandwidth plays a significant role in network performance. While it may seem counterintuitive, optimizing bandwidth can actually reduce latency. By implementing techniques such as traffic prioritization, Quality of Service (QoS), and efficient data compression, network administrators can ensure that critical data flows smoothly, reducing latency and improving overall performance.
C: Minimizing Network Congestion: Network congestion is a common culprit behind high latency. To address this issue, implementing congestion control mechanisms like traffic shaping, packet prioritization, and load balancing can be highly effective. These techniques help distribute network traffic evenly, preventing bottlenecks and reducing latency spikes.
D: Proximity Matters: Content Delivery Networks (CDNs): Content Delivery Networks (CDNs) are a game-changer when it comes to optimizing latency. By distributing content across multiple geographically dispersed servers, CDNs bring data closer to end-users, reducing the time it takes for information to travel. Leveraging CDNs can significantly enhance latency performance, particularly for websites and applications that serve a global audience.
E: Network Infrastructure Optimization: The underlying network infrastructure plays a crucial role in achieving low latency. Employing technologies like fiber optics, reducing signal noise, and utilizing efficient routing protocols can contribute to faster data transmission. Additionally, deploying edge computing capabilities can bring computation closer to the source, further reducing latency.
Google Cloud Network Tiers
Understanding Network Tiers
When it comes to network tiers, it is essential to comprehend their fundamental principles. Network tiers refer to the different levels of service quality and performance offered by a cloud provider. In the case of Google Cloud, there are two primary network tiers: Premium Tier and Standard Tier. Each tier comes with its own set of capabilities, pricing structures, and performance characteristics.
The Premium Tier is designed to provide businesses with unparalleled performance and reliability. It leverages Google’s global network infrastructure, ensuring low latency, high throughput, and robust security. This tier is particularly suitable for applications that demand real-time data processing, high-speed transactions, and global reach. While the Premium Tier might come at a higher cost compared to the Standard Tier, its benefits make it a worthwhile investment for organizations with critical workloads.
The Standard Tier, on the other hand, offers a cost-effective solution for businesses with less demanding network requirements. It provides reliable connectivity and reasonable performance for applications that do not heavily rely on real-time data processing or global scalability. By opting for the Standard Tier, organizations can significantly reduce their network costs without compromising the overall functionality of their applications.


Understanding VPC Peering
VPC peering is a method of connecting VPC networks using private IP addresses. It enables secure and direct communication between VPCs, regardless of whether they belong to the same or different projects within Google Cloud. This eliminates the need for complex and less efficient workarounds, such as external IP addresses or VPN tunnels.
VPC peering offers several advantages for organizations using Google Cloud. Firstly, it simplifies network architecture by providing a seamless connection between VPC networks. It allows resources in one VPC to directly access resources in another VPC, enabling efficient collaboration and resource sharing. Secondly, VPC peering reduces network latency by bypassing the public internet, resulting in faster and more reliable data transfers. Lastly, it enhances security by keeping the communication within the private network and avoiding exposure to potential threats.

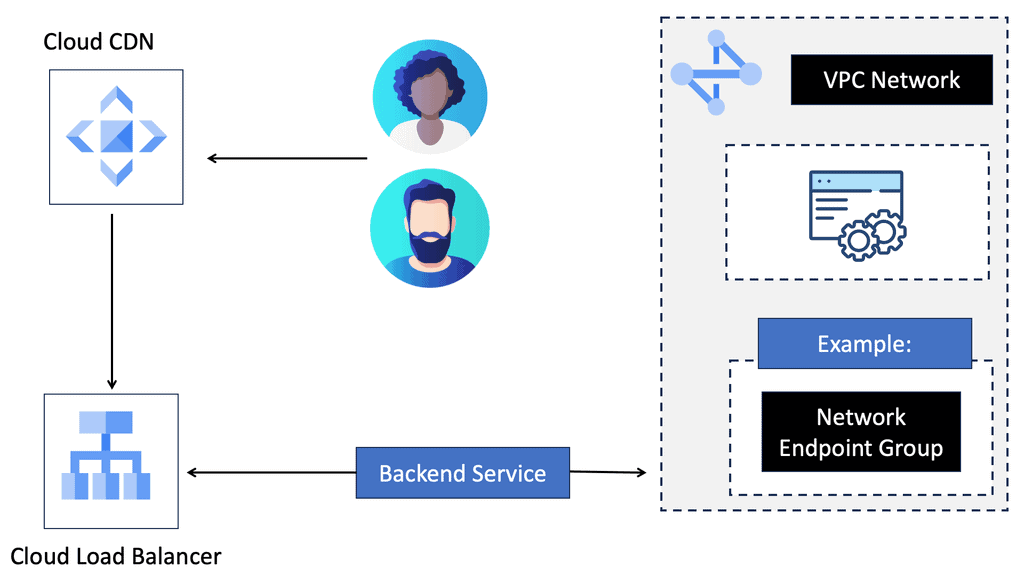
Understanding Google Cloud CDN
Google Cloud CDN is a content delivery network service offered by Google Cloud Platform. It leverages Google’s extensive network infrastructure to cache and serve content from worldwide locations. Bringing content closer to users significantly reduces the time it takes to load web pages, resulting in faster and more efficient content delivery.
Implementing Cloud CDN is straightforward. It requires configuring the appropriate settings within the Google Cloud Console, such as defining the origin server, setting cache policies, and enabling HTTPS support. Once configured, Cloud CDN seamlessly integrates with your existing infrastructure, providing immediate performance benefits.
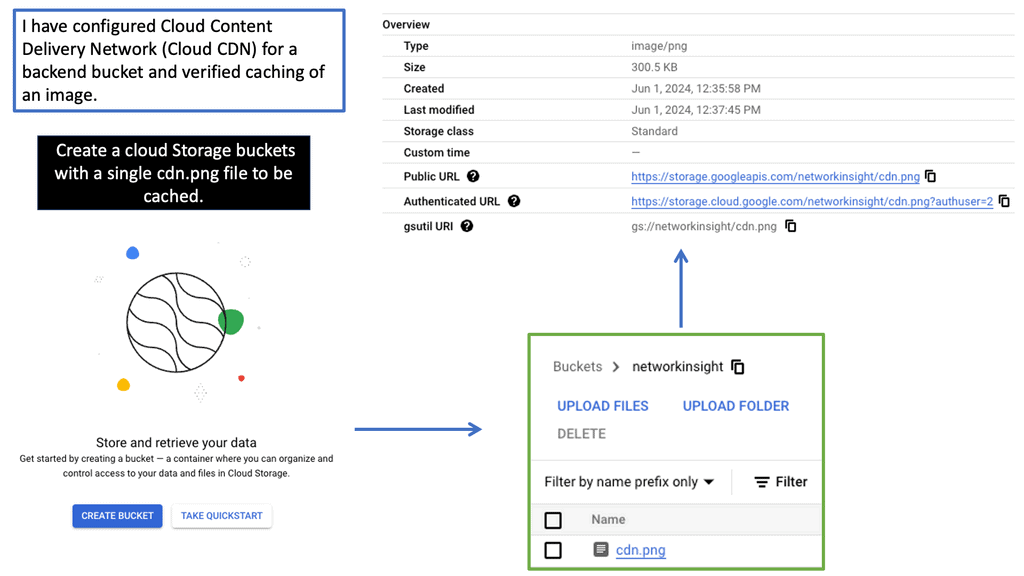
– Cache-Control: Leveraging cache control headers lets you specify how long content should be cached, reducing origin server requests and improving response times.
– Content Purging: Cloud CDN provides easy mechanisms to purge cached content, ensuring users receive the most up-to-date information when necessary.
– Monitoring and Analytics: Utilize Google Cloud Monitoring and Cloud Logging to gain insights into CDN performance, identify bottlenecks, and optimize content delivery further.
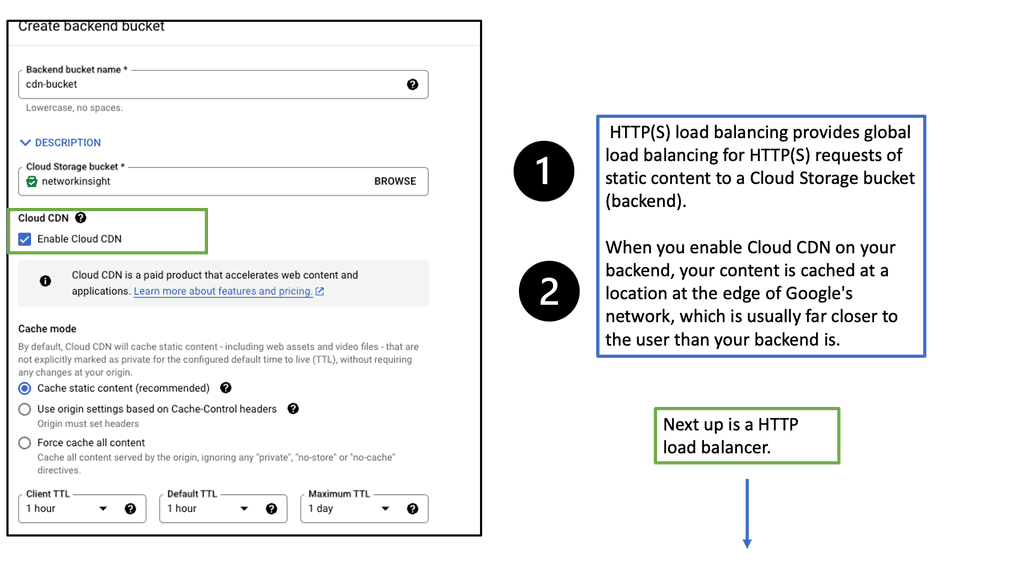
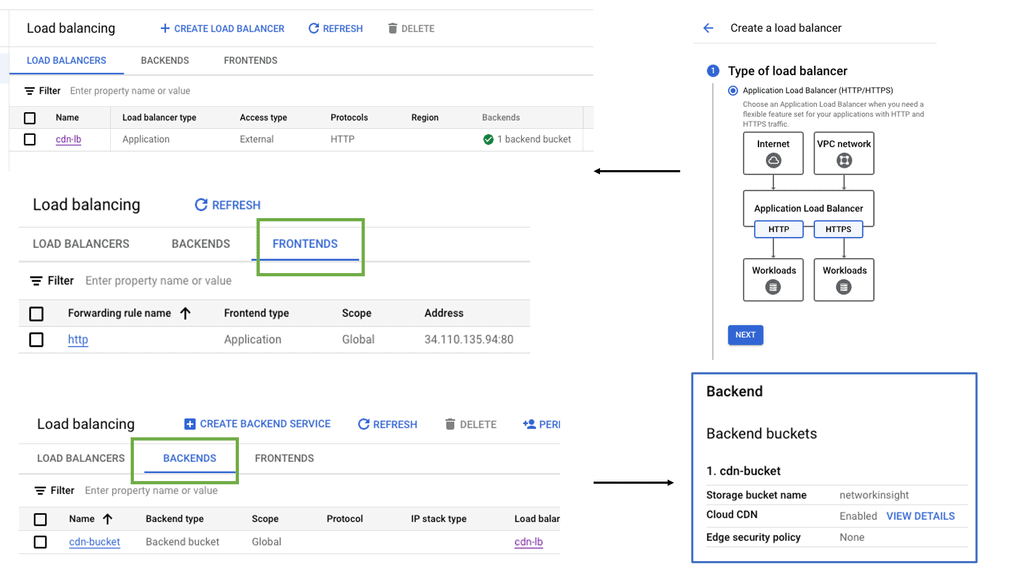
Use Case: Understanding Performance-Based Routing
Performance-based routing is a dynamic routing technique that selects the best path for data transmission based on real-time network performance metrics. Unlike traditional static routing, which relies on predetermined paths, performance-based routing considers factors such as latency, packet loss, and available bandwidth. Continuously evaluating network conditions ensures that data is routed through the most efficient path, improving overall network performance.
Enhanced Reliability: Performance-based routing improves reliability by dynamically adapting to network conditions and automatically rerouting traffic in case of network congestion or failures. This proactive approach minimizes downtime and ensures uninterrupted connectivity.
Optimized Performance: Performance-based routing facilitates load balancing by distributing traffic across multiple paths based on their performance metrics. This optimization reduces latency, enhances throughput, and improves overall user experience.
Cost Optimization: Through intelligent routing decisions, performance-based routing can optimize costs by leveraging lower-cost paths or utilizing network resources more efficiently. This cost optimization can be particularly advantageous for organizations with high bandwidth requirements or regions with varying network costs.
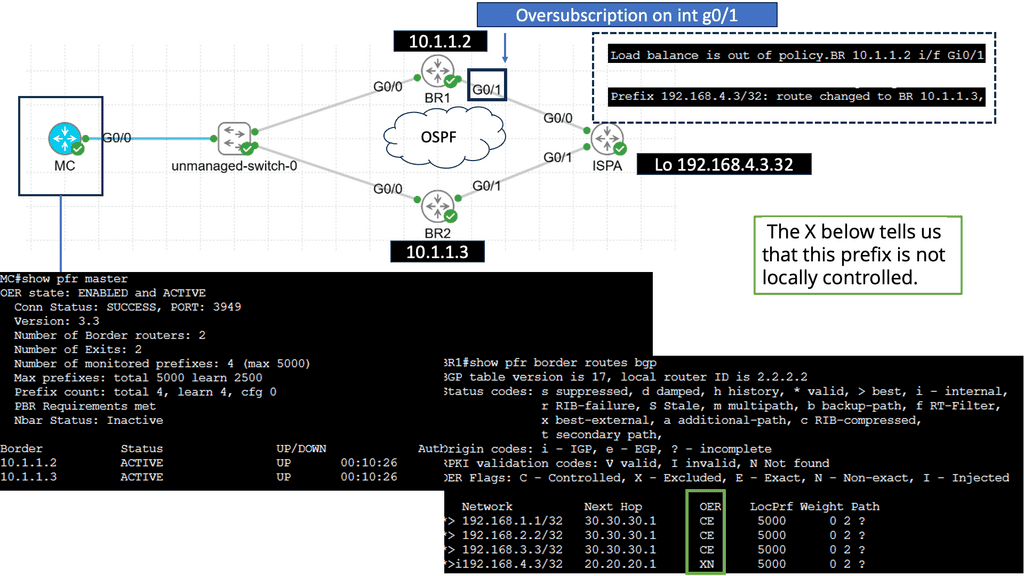
Routing Protocols:
Routing protocols are algorithms determining the best path for data to travel from the source to the destination. They ensure that packets are directed efficiently through network devices such as routers, switches, and gateways. Different routing protocols, such as OSPF, EIGRP, and BGP, have advantages and are suited for specific network environments.
Routing protocols should be optimized.
Routing protocols determine how data packets are forwarded between network nodes. Different routing protocols use different criteria for choosing the best path, including hop count, bandwidth, delay, cost, or load. Some routing protocols have fixed routes since they do not change unless manually updated. In addition, some are dynamic, allowing them to adapt automatically to changing network conditions. You can minimize latency and maximize efficiency by choosing routing protocols compatible with your network topology, traffic characteristics, and reliability requirements.
Optimizing routing protocols can significantly improve network performance and efficiency. By minimizing unnecessary hops, reducing congestion, and balancing network traffic, optimized routing protocols help enhance overall network reliability, reduce latency, and increase bandwidth utilization.
**Strategies for Routing Protocol Optimization**
a. Implementing Route Summarization:
Route summarization, also known as route aggregation, is a process that enables the representation of multiple network addresses with a single summarized route. Instead of advertising individual subnets, a summarized route encompasses a range of subnets under one address. This technique contributes to reducing the size of routing tables and optimizing network performance.
The implementation of route summarization offers several advantages. First, it minimizes routers’ memory requirements by reducing the number of entries in their routing tables. This reduction in memory consumption leads to improved router performance and scalability.
Second, route summarization enhances network stability and convergence speed by reducing the number of route updates exchanged between routers. Lastly, it improves security by hiding internal network structure, making it harder for potential attackers to gain insights into the network topology.
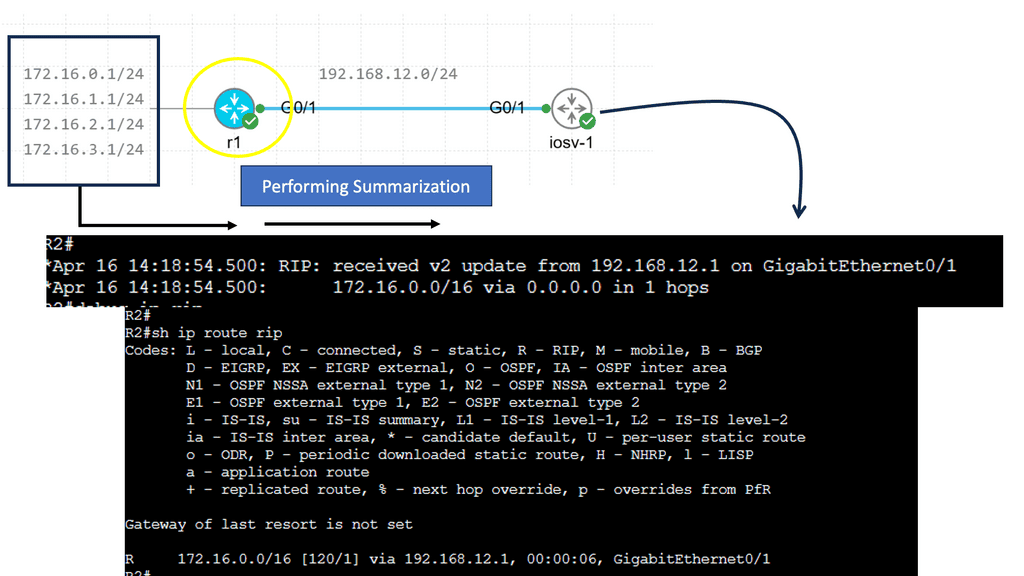
b. Load Balancing:
Load balancing distributes network traffic across multiple paths, preventing bottlenecks and optimizing resource utilization. Implementing load balancing techniques, such as equal-cost multipath (ECMP) routing, can improve network performance and avoid congestion. Load balancing is distributing the workload across multiple computing resources, such as servers or virtual machines, to ensure optimal utilization and prevent any single resource from being overwhelmed. By evenly distributing incoming requests, load balancing improves performance, enhances reliability, and minimizes downtime.
There are various load-balancing methods employed in different scenarios. Let’s explore a few popular ones:
-Round Robin: This method distributes requests equally among available resources cyclically. Each resource takes turns serving incoming requests, ensuring a fair workload allocation.
-Least Connections: The least connections method directs new requests to the resource with the fewest active connections. This approach prevents any resource from becoming overloaded and ensures efficient utilization of available resources.
-IP Hashing: With IP hashing, requests are distributed based on the client’s IP address. This method ensures that requests from the same client are consistently directed to the same resource, enabling session persistence and maintaining data integrity.
c. Convergence Optimization:
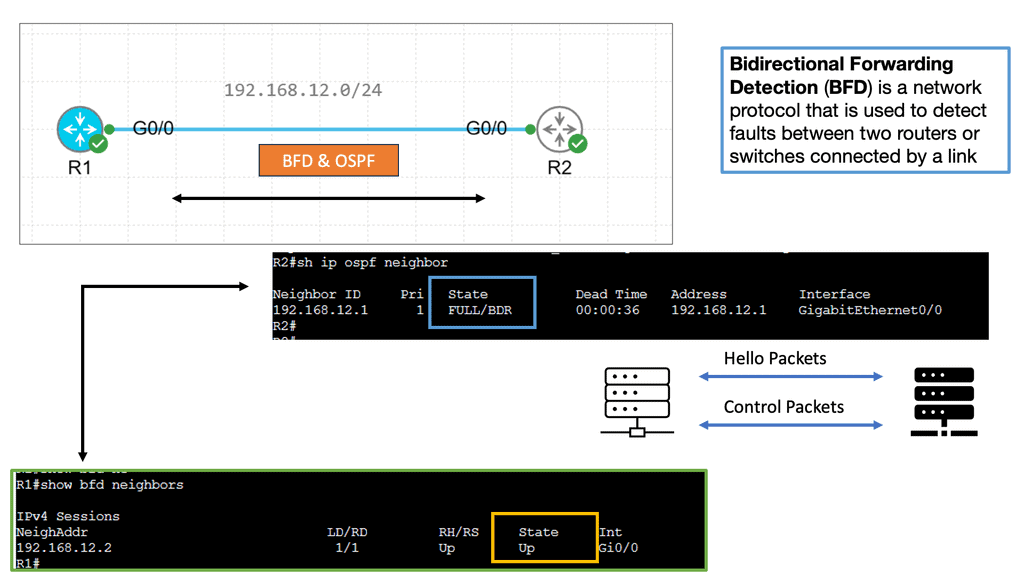
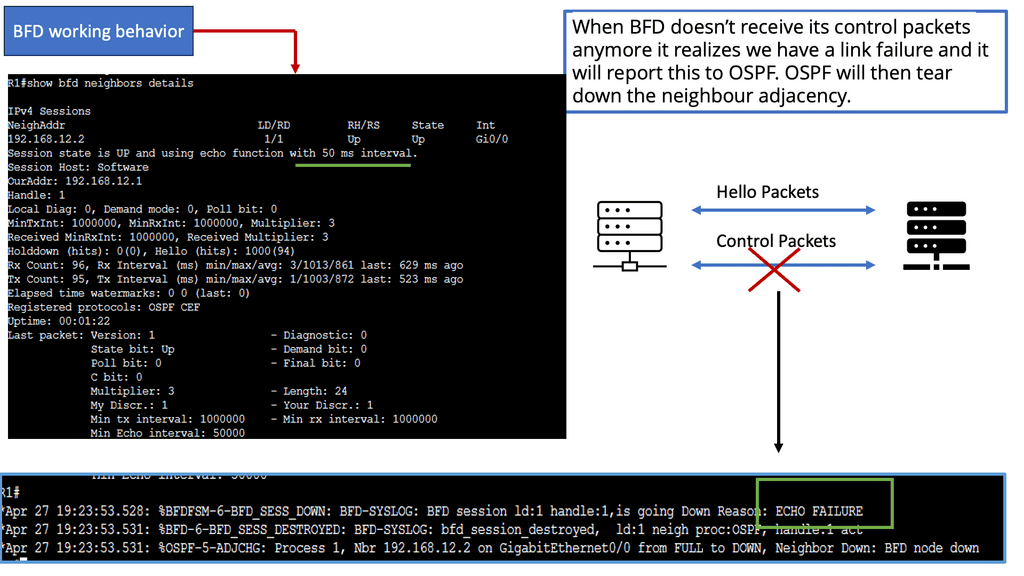
Convergence refers to the process by which routers learn and update routing information. Optimizing convergence time is crucial for minimizing network downtime and ensuring fast rerouting in case of failures. Techniques like Bidirectional Forwarding Detection (BFD) and optimized hello timers can expedite convergence. BFD, in simple terms, is a protocol used to detect faults in the forwarding path between network devices. It provides a mechanism for quickly detecting failures, ensuring quick convergence, and minimizing service disruption. BFD enables real-time connectivity monitoring between devices by exchanging control packets at a high rate.
The implementation of BFD brings several notable benefits to network operators. Firstly, it offers rapid failure detection, reducing the time taken for network convergence. This is particularly crucial in mission-critical environments where downtime can have severe consequences. Additionally, BFD is lightweight and has low overhead, making it suitable for deployment in resource-constrained networks.
Understanding Layer 3 Etherchannel
Layer 3 Etherchannel, or routed Etherchannel, is a network technology that bundles multiple physical links into a single logical interface. Unlike Layer 2 Etherchannel, which operates at the Data Link Layer, Layer 3 Etherchannel extends its capabilities to the Network Layer. This enables load balancing, redundancy, and increased bandwidth utilization across multiple routers or switches.
Configuring Layer 3 Etherchannel involves several steps. Firstly, the physical interfaces that will be part of the Etherchannel need to be identified. Secondly, the appropriate channel protocol, such as Protocol Independent Multicast (PIM) or Open Shortest Path First (OSPF), needs to be chosen. Next, the Layer 3 Etherchannel interface is configured with the desired parameters, including load-balancing algorithms and link priorities. Finally, the Etherchannel is linked to the chosen routing protocol to facilitate dynamic routing and optimal path selection.

Choose the correct topology:
Nodes and links in your network are arranged and connected according to their topology. Topologies have different advantages and disadvantages regarding latency, scalability, redundancy, and cost. A star topology, for example, reduces latency and simplifies management, but it carries a higher load and creates a single point of failure. Multiple paths connect nodes in mesh topologies, increasing complexity overhead, redundancy, and resilience. Choosing the proper topology depends on your network’s size, traffic patterns, and performance goals.
Understanding BGP Route Reflection
BGP Route Reflection allows network administrators to simplify the management of BGP routes within their autonomous systems (AS). It introduces a hierarchical structure by dividing the AS into clusters, where route reflectors are the focal points for route propagation. By doing so, BGP Route Reflection reduces the number of required BGP peering sessions and optimizes route distribution.
The implementation of BGP Route Reflection offers several advantages. Firstly, it reduces the overall complexity of BGP configurations by eliminating the need for full-mesh connectivity among routers within an AS. This simplification leads to improved scalability and easier management of BGP routes. Additionally, BGP Route Reflection enhances route convergence time, as updates can be disseminated more efficiently within the AS.
Route Reflector Hierarchy
Route reflectors play a vital role within the BGP route reflection architecture. They are responsible for reflecting BGP route information to other routers within the same cluster. Establishing a well-designed hierarchy of route reflectors is essential to ensure optimal route propagation and minimize potential issues such as routing loops or suboptimal path selection. We will explore different hierarchy designs and their implications.


Use quality of service techniques.
In quality of service (QoS) techniques, network traffic is prioritized and managed based on its class or category, such as voice, video, or data. Reducing latency by allocating more bandwidth, reducing jitter, or dropping less important packets with QoS techniques for time-sensitive or critical applications is possible.
QoS techniques implemented at the network layer include differentiated services (DiffServ) and integrated services (IntServ). Multiprotocol label switching (MPLS) and resource reservation protocol (RSVP) are implemented at the application layer. It would be best to use QoS techniques to guarantee the quality and level of service you want for your applications.
TCP Performance Optimizations
Understanding TCP Performance Parameters
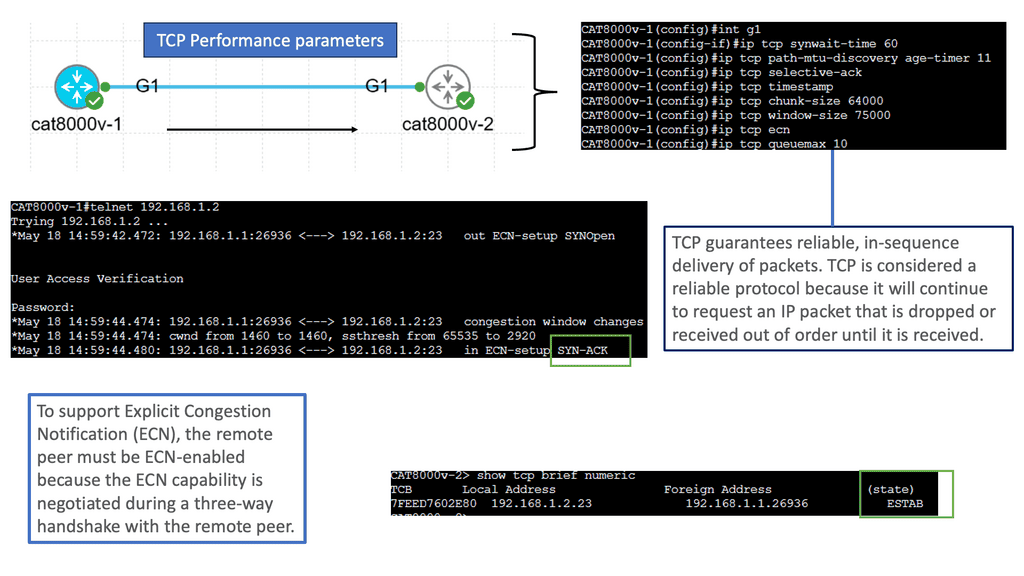
TCP, or Transmission Control Protocol, is a fundamental component of Internet communication. It ensures reliable and ordered delivery of data packets, but did you know that TCP performance can be optimized by adjusting various parameters?
TCP performance parameters are configurable settings that govern the behavior of the TCP protocol. These parameters control congestion control, window size, and timeout values. By fine-tuning these parameters, network administrators can optimize TCP performance to meet specific requirements and overcome challenges.
Congestion Control and Window Size: Congestion control is critical to TCP performance. It regulates the rate at which data is transmitted to avoid network congestion. TCP utilizes a window size mechanism to manage unacknowledged data in flight. Administrators can balance throughput and latency by adjusting the window size to optimize network performance.
Timeout Values and Retransmission: Timeout values are crucial in TCP performance. When a packet is not acknowledged within a specific time frame, it is considered lost, and TCP initiates retransmission. Administrators can optimize the trade-off between responsiveness and reliability by adjusting timeout values. Fine-tuning these values can significantly impact TCP performance in scenarios with varying network conditions.
Bandwidth-Delay Product and Buffer Sizes: The bandwidth-delay product is a metric that represents the amount of data that can be in transit between two endpoints. It is calculated by multiplying the available bandwidth by the round-trip time (RTT). Properly setting buffer sizes based on the bandwidth-delay product helps prevent packet loss and ensures efficient data transmission.
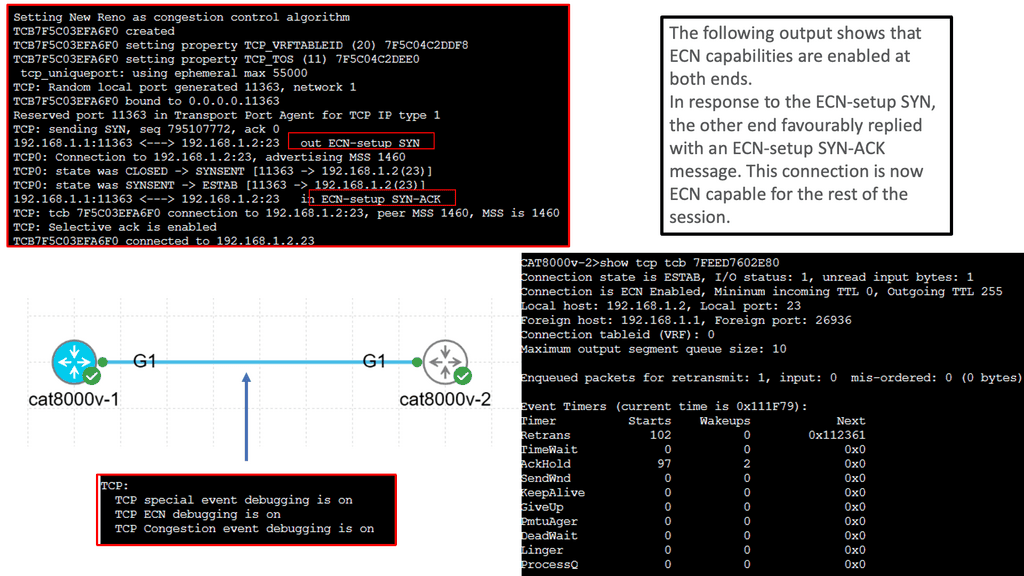
Understanding TCP MSS
TCP MSS refers to the maximum amount of data transmitted in a single TCP segment. It plays a vital role in maintaining efficient and reliable communication between hosts in a network. By limiting the segment size, TCP MSS ensures compatibility and prevents fragmentation issues.
The significance of TCP MSS lies in its ability to optimize network performance. By setting an appropriate MSS value, network administrators can balance between efficient data transfer and minimizing overhead caused by fragmentation and reassembly. This enhances the overall throughput and reduces the likelihood of congestion.
Several factors influence the determination of TCP MSS. For instance, the network infrastructure, such as routers and switches, may limit the maximum segment size. Path MTU Discovery (PMTUD) techniques also help identify the optimal MSS value based on the path characteristics between source and destination.
Configuring TCP MSS requires a comprehensive understanding of the network environment and its specific requirements. It involves adjusting the MSS value on both communication ends to ensure seamless data transmission. Network administrators can employ various methods, such as adjusting router settings or utilizing specific software tools, to optimize TCP MSS settings.

What is TCP MSS?
TCP MSS refers to the maximum amount of data sent in a single TCP segment without fragmentation. It is primarily determined by the underlying network’s Maximum Transmission Unit (MTU). The MSS value is negotiated during the TCP handshake process and remains constant for the duration of the connection.
Optimizing TCP MSS is crucial for achieving optimal network performance. When the MSS is set too high, it can lead to fragmentation, increased overhead, and reduced throughput. On the other hand, setting the MSS too low can result in inefficiency due to smaller segment sizes. Finding the right balance can enhance network efficiency and minimize potential issues.
1. Path MTU Discovery (PMTUD): PMTUD is a technique in which the sender determines the maximum path MTU by allowing routers along the path to send ICMP messages indicating the required fragmentation. This way, the sender can dynamically adjust the MSS to avoid fragmentation.
2. MSS Clamping: In situations where PMTUD may not work reliably, MSS clamping can be employed. It involves setting a conservative MSS value guaranteed to work across the entire network path. Although this may result in smaller segment sizes, it ensures proper transmission without fragmentation.
3. Jumbo Frames: Jumbo Frames are Ethernet frames that exceed the standard MTU size. By using Jumbo Frames, the MSS can be increased, allowing for larger segments and potentially improving network performance. However, it requires support from both network infrastructure and end devices.
Understanding Switching
Layer 2 switching, also known as data link layer switching, operates at the second layer of the OSI model. It uses MAC addresses to forward data packets within a local area network (LAN). Unlike layer three routing, which relies on IP addresses, layer 2 switching occurs at wire speed, resulting in minimal latency and optimal performance.
One of the primary advantages of layer 2 switching is its ability to facilitate faster communication between devices within a LAN. By utilizing MAC addresses, layer 2 switches can make forwarding decisions based on the physical address of the destination device, reducing the time required for packet processing. This results in significantly lower latency, making it ideal for real-time applications such as online gaming, high-frequency trading, and video conferencing.
Implementing layer 2 switching requires the deployment of layer 2 switches, specialized networking devices capable of efficiently forwarding data packets based on MAC addresses. These switches are typically equipped with multiple ports to connect various devices within a network. By strategically placing layer 2 switches throughout the network infrastructure, organizations can create low-latency pathways for data transmission, ensuring seamless connectivity and optimal performance.
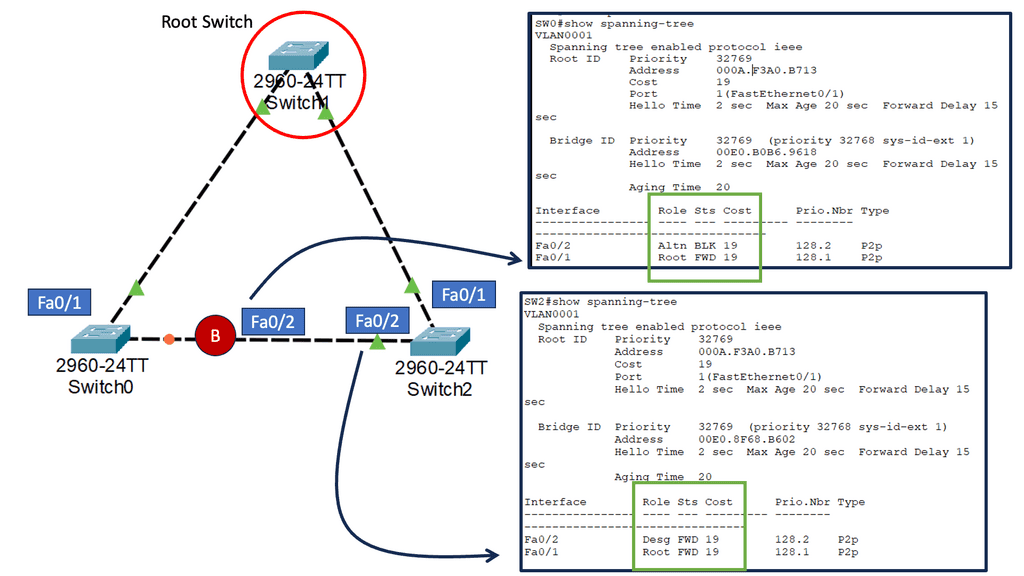
Spanning-Tree Protocol
STP, a layer 2 protocol, provides loop-free paths in Ethernet networks. It accomplishes this by creating a logical tree that spans all switches within the network. This tree ensures no redundant paths, avoiding loops leading to broadcast storms and network congestion.
While STP is essential for network stability, it can introduce delays during convergence. Convergence refers to the process where the network adapts to changes, such as link failures or network topology modifications. During convergence, STP recalculates the spanning tree, causing temporary disruptions in network traffic. In time-sensitive environments, these disruptions can be problematic.
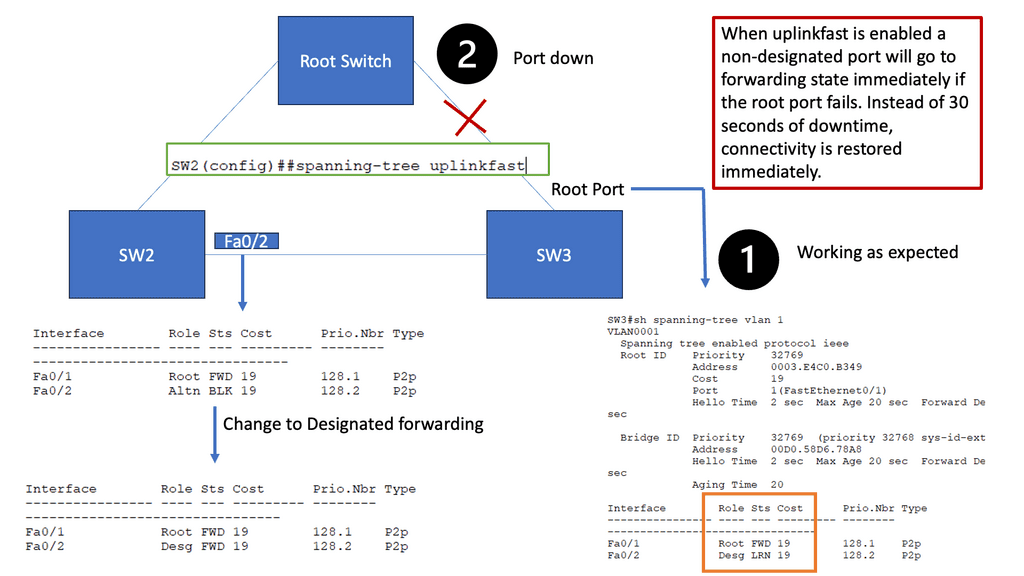
Introducing Spanning-Tree Uplink Fast
Spanning-Tree Uplink Fast is a Cisco proprietary feature designed to reduce the convergence time of STP. When a superior BPDU (Bridge Protocol Data Unit) is received, it immediately transitions from a blocked port to a forwarding state. This feature is typically used on access layer switches that connect to distribution or core switches.
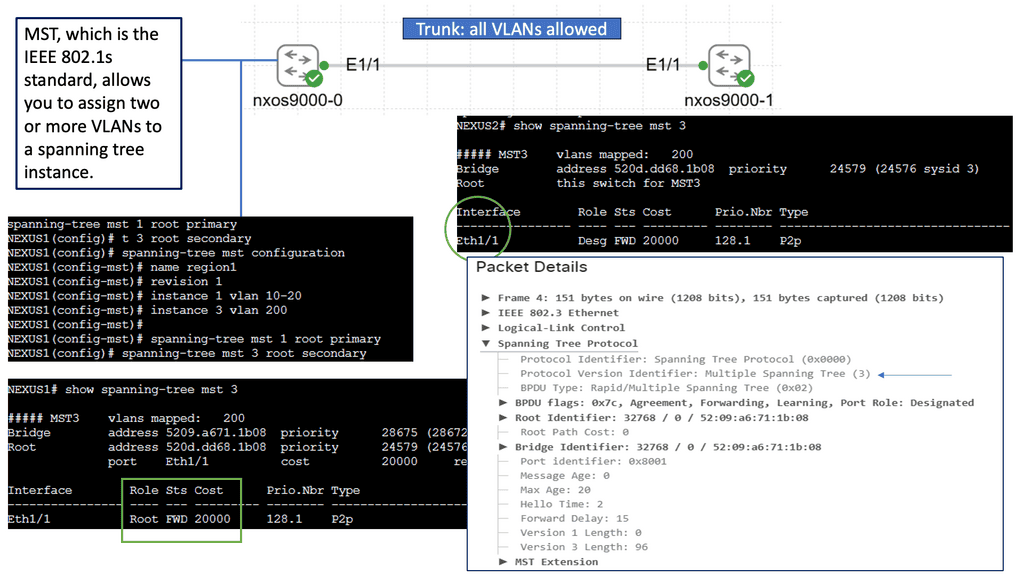
Understanding Spanning Tree Protocol (STP)
STP, a protocol defined by the IEEE 802.1D standard, is designed to prevent loops in Ethernet networks. STP ensures a loop-free network topology by dynamically calculating the best path and blocking redundant links. We will explore the inner workings of STP and its role in maintaining network stability.
Building upon STP, multiple spanning trees (MST) allow for creating multiple spanning trees within a single network. By dividing the network into multiple regions, MST enhances scalability and optimizes bandwidth utilization. We will delve into the configuration and advantages of MST in modern network environments.
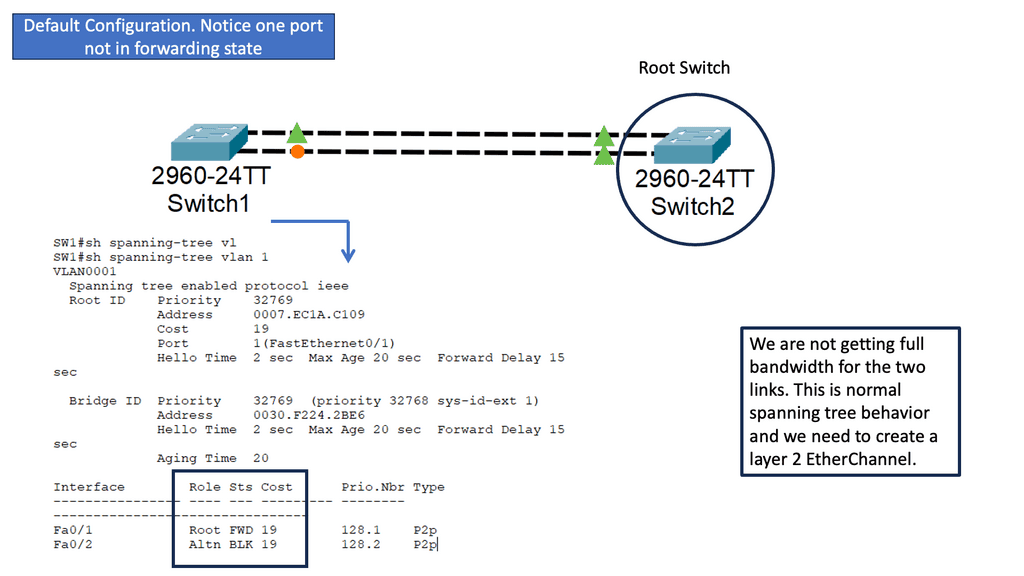
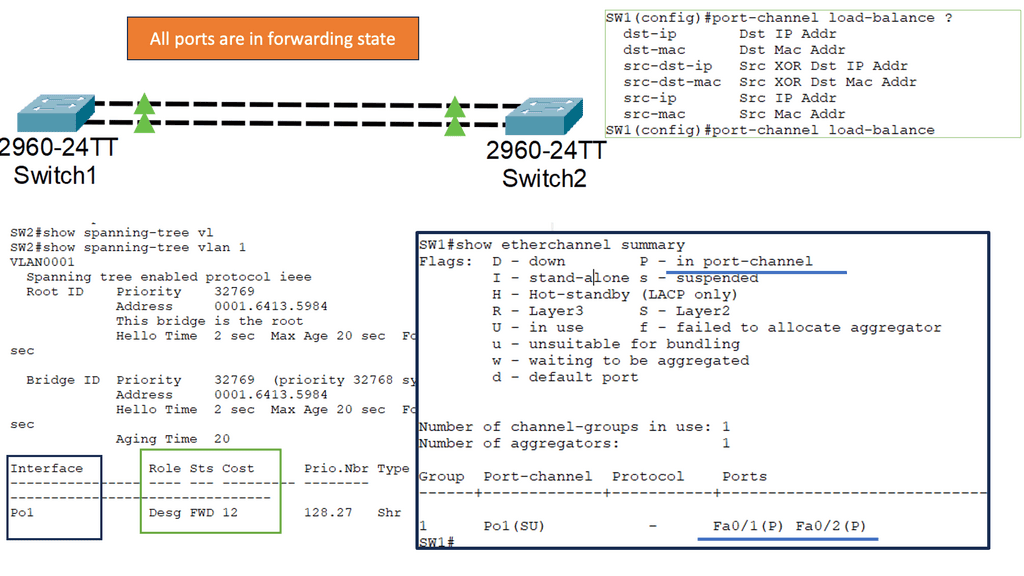
Understanding Layer 2 Etherchannel
Layer 2 Etherchannel, or link aggregation, combines physical links into a single logical link. This provides increased bandwidth and redundancy, enhancing network performance and resilience. Unlike Layer 3 Etherchannel, which operates at the IP layer, Layer 2 Etherchannel operates at the data-link layer, making it suitable for various network topologies and protocols.
Implementing Layer 2 Etherchannel offers several key benefits. Firstly, it allows for load balancing across multiple links, distributing traffic evenly and preventing bottlenecks. Secondly, it provides link redundancy, ensuring uninterrupted network connectivity even during link failures. Moreover, Layer 2 Etherchannel simplifies network management by treating multiple physical links as a single logical interface, reducing complexity and easing configuration tasks.
**Keep an eye on your network and troubleshoot any issues.**
Monitoring and troubleshooting are essential to identifying and resolving any latency issues in your network. Tools and methods such as ping, traceroute, and network analyzers can measure and analyze your network’s latency and performance. These tools and techniques can also identify and fix network problems like packet loss, congestion, misconfiguration, or faulty hardware. Regular monitoring and troubleshooting are essential for keeping your network running smoothly.
**Critical Considerations in Low Latency Design**
Designing a low-latency network requires a thorough understanding of various factors. Bandwidth, network topology, latency measurement tools, and quality of service (QoS) policies all play pivotal roles. Choosing the right networking equipment, leveraging advanced routing algorithms, and optimizing data transmission paths are crucial to achieving optimal latency. Moreover, it is essential to consider scalability, security, and cost implications when designing and implementing low-latency networks.
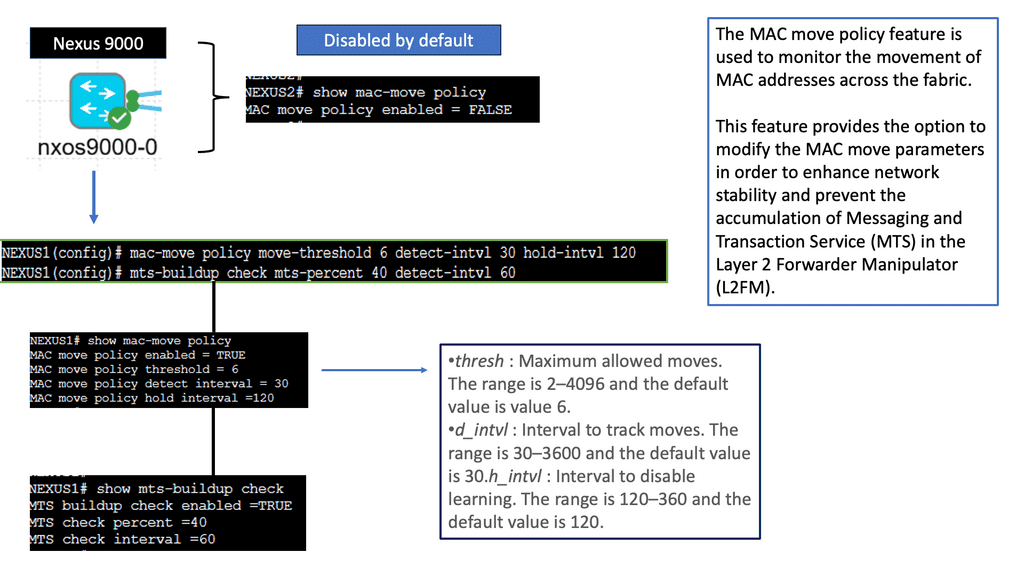
What is a MAC Move Policy?
In the context of Cisco NX-OS devices, a MAC move policy defines the rules and behaviors associated with MAC address moves within a network. It determines how the devices handle MAC address changes when moved or migrated. The policy can be customized to suit specific network requirements, ensuring efficient resource utilization and minimizing disruptions caused by MAC address changes.
By implementing a MAC move policy, network administrators can achieve several benefits. First, it enhances network stability by preventing unnecessary MAC address flapping and associated network disruptions. Second, it improves network performance by optimizing MAC address table entries and reducing unnecessary broadcasts. Third, it provides better control and visibility over MAC address movements, facilitating troubleshooting and network management tasks.
Proper management of MAC move policy significantly impacts network performance. When MAC addresses move frequently or without restrictions, it can lead to excessive flooding, where switches forward frames to all ports, causing unnecessary network congestion. By implementing an appropriate MAC move policy, administrators can reduce flooding, prevent unnecessary MAC address learning, and enhance overall network efficiency.
Understanding sFlow
– sFlow is a standards-based technology that enables real-time network traffic monitoring by sampling packets. It provides valuable information such as packet headers, traffic volumes, and application-level details. By implementing sFlow on Cisco NX-OS, administrators can gain deep visibility into network behavior and identify potential bottlenecks or security threats.
– Configuring sFlow on Cisco NX-OS is straightforward. By accessing the device’s command-line interface, administrators can enable sFlow globally or on specific interfaces. They can also define sampling rates, polling intervals, and destination collectors where sFlow data will be sent for analysis. This section provides detailed steps and commands to guide administrators through the configuration process.
– Network administrators can harness its power to optimize performance once sFlow is up and running on Cisco NX-OS. By analyzing sFlow data, they can identify bandwidth-hungry applications, pinpoint traffic patterns, and detect anomalies. This section will discuss various use cases where sFlow can be instrumental in optimizing network performance, such as load balancing, capacity planning, and troubleshooting.
– Integration with network monitoring tools is essential to unleash sFlow’s full potential on Cisco NX-OS. sFlow data can seamlessly integrate with popular monitoring platforms like PRTG, SolarWinds, or Nagios.

Use Case: Performance Routing
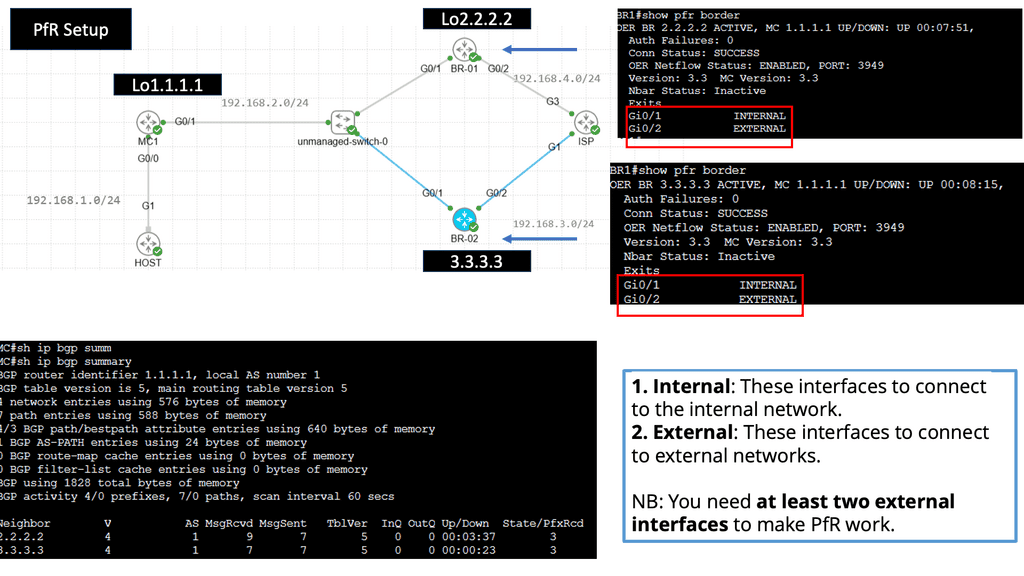
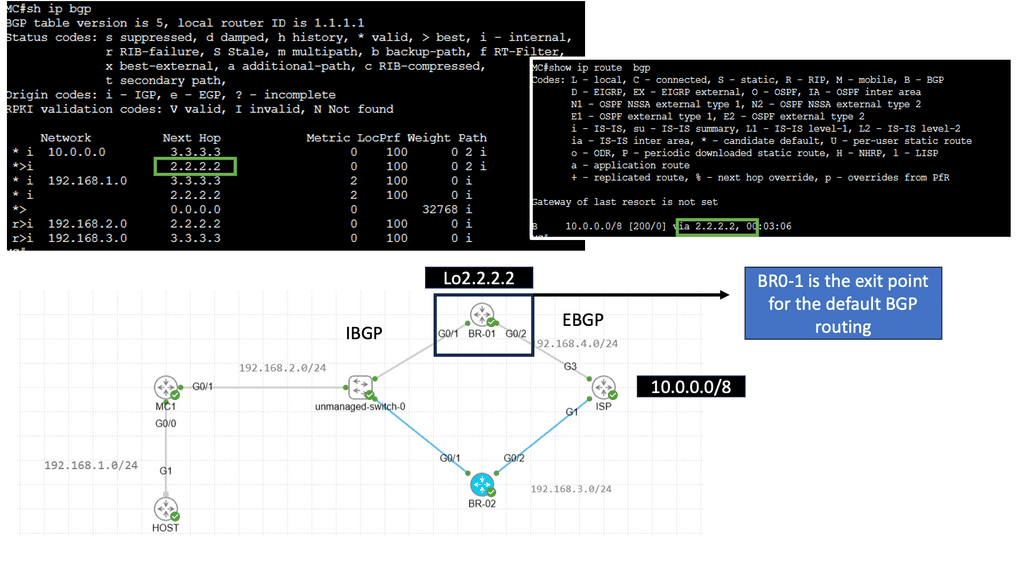
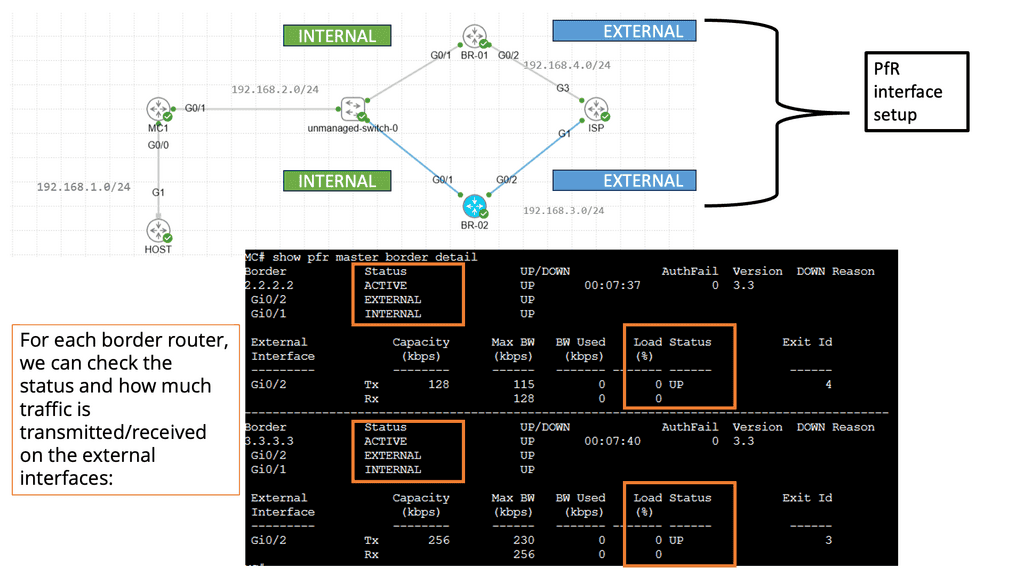
Understanding Performance Routing (PfR)
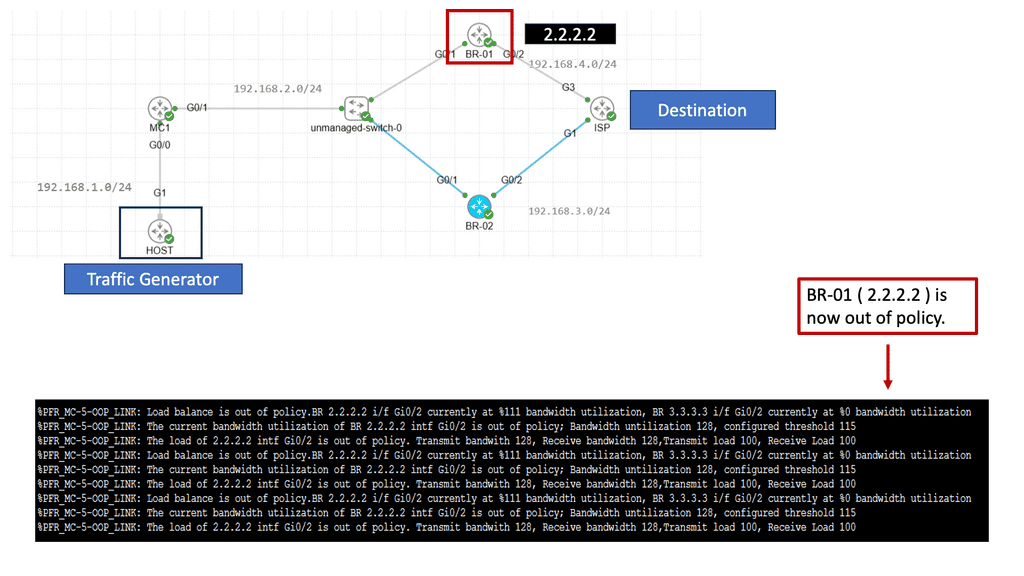
Performance Routing, or PfR, is an intelligent network routing technique that dynamically adapts to network conditions, traffic patterns, and application requirements. Unlike traditional static routing protocols, PfR uses real-time data and advanced algorithms to make dynamic routing decisions, optimizing performance and ensuring efficient utilization of network resources.
Enhanced Application Performance: PfR significantly improves application performance by dynamically selecting the optimal path based on network conditions. It minimizes latency, reduces packet loss, and ensures a consistent end-user experience despite network congestion or link failures.
Efficient Utilization of Network Resources: PfR intelligently distributes traffic across multiple paths, leveraging available bandwidth and optimizing resource utilization. This improves overall network efficiency and reduces costs by avoiding unnecessary bandwidth upgrades.
Simplified Network Management: With PfR, network administrators gain granular visibility into network performance, traffic patterns, and application behavior. This enables proactive troubleshooting, capacity planning, and streamlined network management, saving time and effort.

Advanced Topics
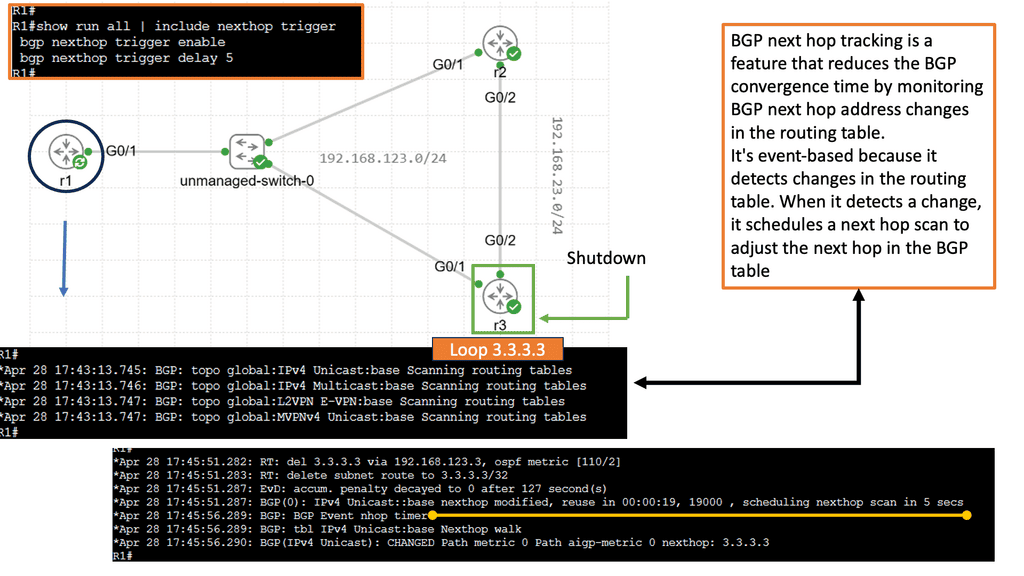
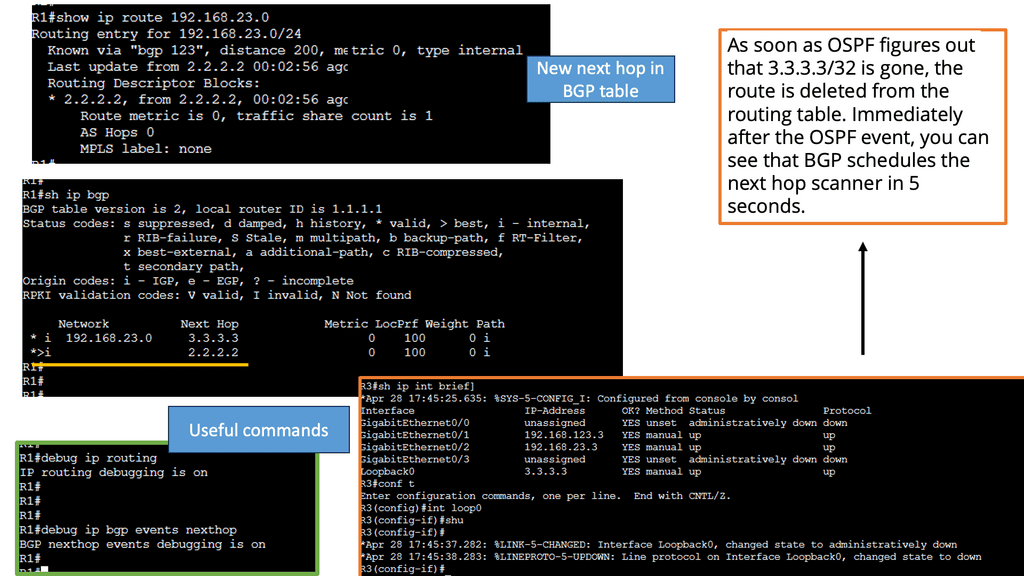
BGP Next Hop Tracking:
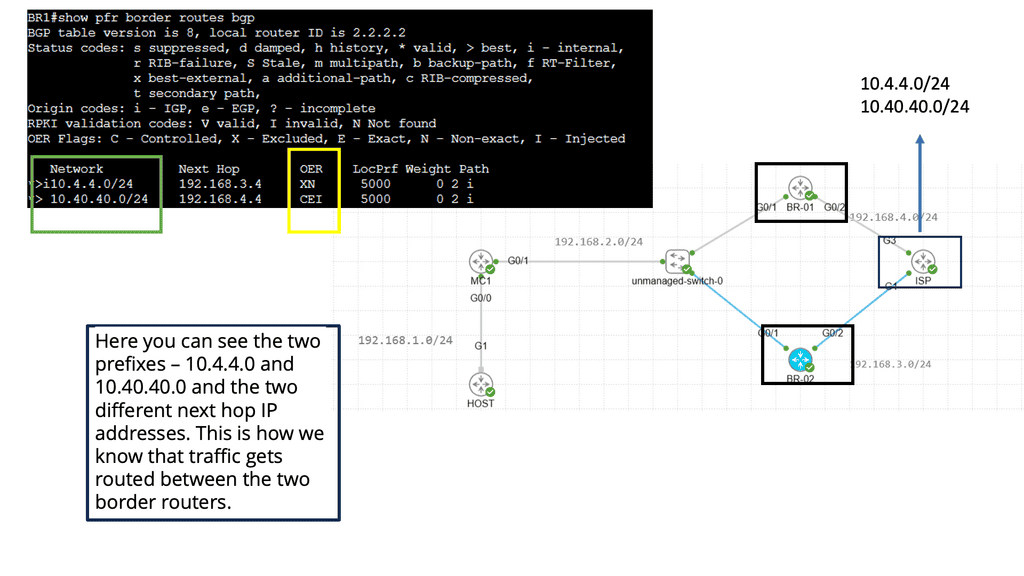
BGP next hop refers to the IP address used to reach the destination network. When a BGP router receives an advertisement for a route, it must determine the next hop IP address to forward the traffic. This information is crucial for proper routing and efficient packet delivery.
Next-hop tracking provides several benefits for network operators. First, it enables proactive monitoring of the next-hop IP address, ensuring its reachability and availability. Network administrators can detect and resolve issues promptly by tracking the next hop continuously, reducing downtime, and improving network performance. Additionally, next-hop tracking facilitates efficient load balancing and traffic engineering, allowing for optimal resource utilization.
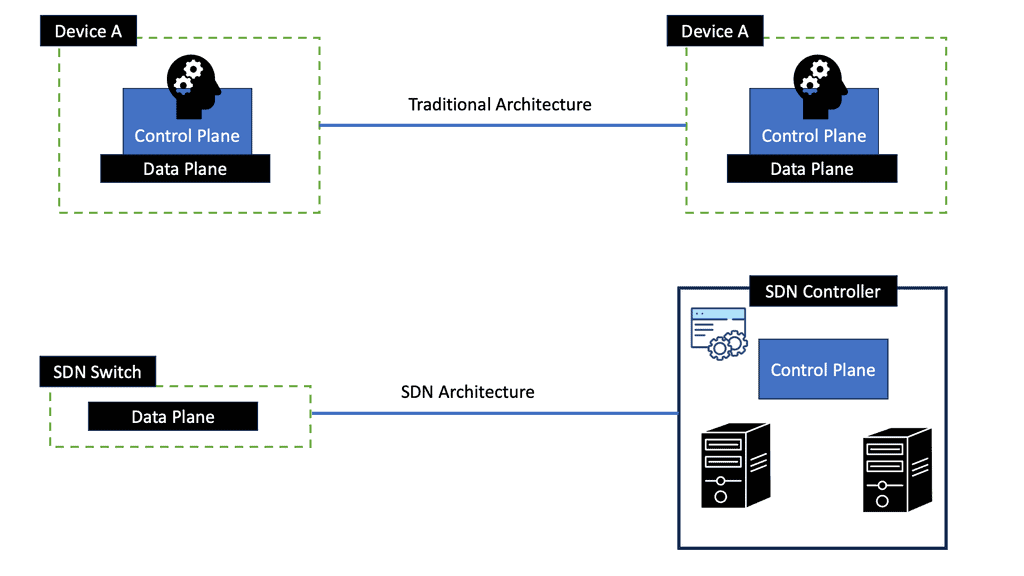
**Cutting-Edge Technologies**
Low-latency network design is constantly evolving, driven by technological advancements. Innovative solutions are emerging to address latency challenges, from software-defined networking (SDN) to edge computing and content delivery networks (CDNs). SDN, for instance, offers programmable network control, enabling dynamic traffic management and reducing latency. Edge computing brings compute resources closer to end-users, minimizing round-trip times. CDNs optimize content delivery by strategically caching data, reducing global audiences’ latency.
**A New Operational Model**
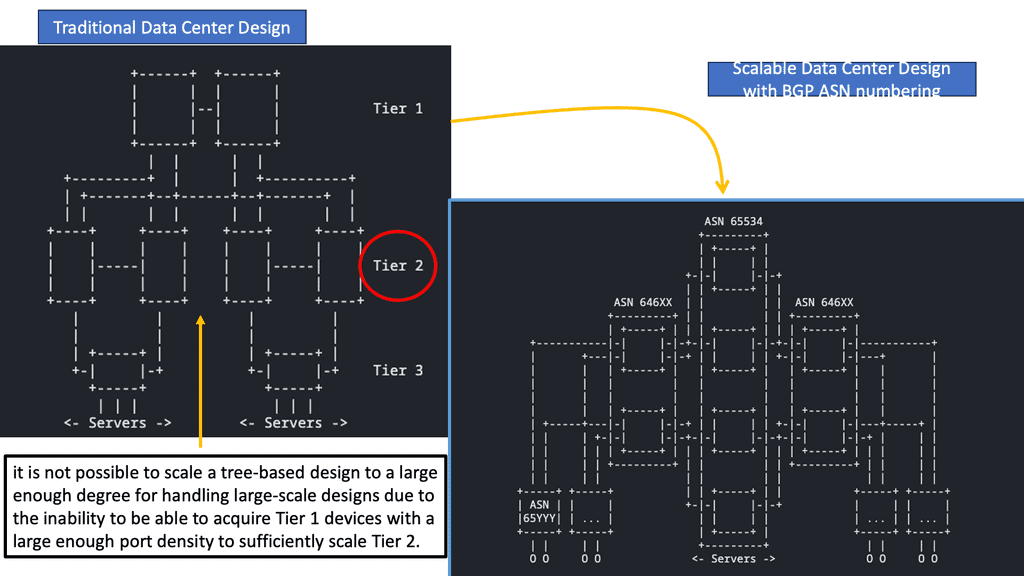
We are now all moving in the direction of the cloud. The requirement is for large data centers that are elastic and scalable. The result of these changes, influenced by innovations and methodology in the server/application world, is that the network industry is experiencing a new operational model. Provisioning must be quick, and designers look to automate network configuration more systematically and in a less error-prone programmatic way. It is challenging to meet these new requirements with traditional data center designs.
**Changing Traffic Flow**
Traffic flow has changed, and we have a lot of east-to-west traffic. Existing data center designs focus on north-to-south flows. East-to-west traffic requires changing the architecture from an aggregating-based model to a massive multipathing model. Referred to as Clos networks, leaf and spine designs allow building massive networks with reasonably sized equipment, enabling low-latency network design.
Vendor Example: High-Performance Switch: Cisco Nexus 3000 Series
Featuring switch-on-a-chip (SoC) architecture, the Cisco Nexus 3000 Series switches offer 1 gigabit, 10 gigabit, 40 gigabit, 100 gigabit and 400 gigabit Ethernet capabilities. This series of switches provides line-rate Layer 2 and 3 performance and is suitable for ToR architectures. Combining high performance and low latency with innovations in performance visibility, automation, and time synchronization, this series of switches has established itself as a leader in high-frequency trading (HFT), high-performance computing (HPC), and big data environments. Providing high performance, flexible connectivity, and extensive features, the Cisco Nexus 3000 Series offers 24 to 256 ports.
Related: Before you proceed, you may find the following post helpful:
Network Testing
A stable network results from careful design and testing. Although many vendors often perform exhaustive systems testing and provide this via third-party testing reports, they cannot reproduce every customer’s environment. So, to determine your primary data center design, you must conduct your tests.
Effective testing is the best indicator of production readiness. On the other hand, ineffective testing may lead to a false sense of confidence, causing downtime. Therefore, you should adopt a structured approach to testing as the best way to discover and fix the defects in the least amount of time at the lowest possible cost.
What is low latency?
Low latency is the ability of a computing system or network to respond with minimal delay. Actual low latency metrics vary according to the use case. So, what is a low-latency network? A low-latency network has been designed and optimized to reduce latency as much as possible. However, a low-latency network can only improve latency caused by factors outside the network.
We first have to consider latency jitters when they deviate unpredictably from an average; in other words, they are low at one moment and high at the next. For some applications, this unpredictability is more problematic than high latency. We also have ultra-low latency measured in nanoseconds, while low latency is measured in milliseconds. Therefore, ultra-low latency delivers a response much faster, with fewer delays than low latency.
Data Center Latency Requirements
Latency requirements
Intra-data center traffic flows concern us more with latency than outbound traffic flow. High latency between servers degrades performance and results in the ability to send less traffic between two endpoints. Low latency allows you to use as much bandwidth as possible.
A low-lay network design known as Ultra-low latency ( ULL ) data center design is the race to zero. The goal is to design as fast as possible with the lowest end-to-end latency. Latency on an IP/Ethernet switched network can be as low as 50 ns.
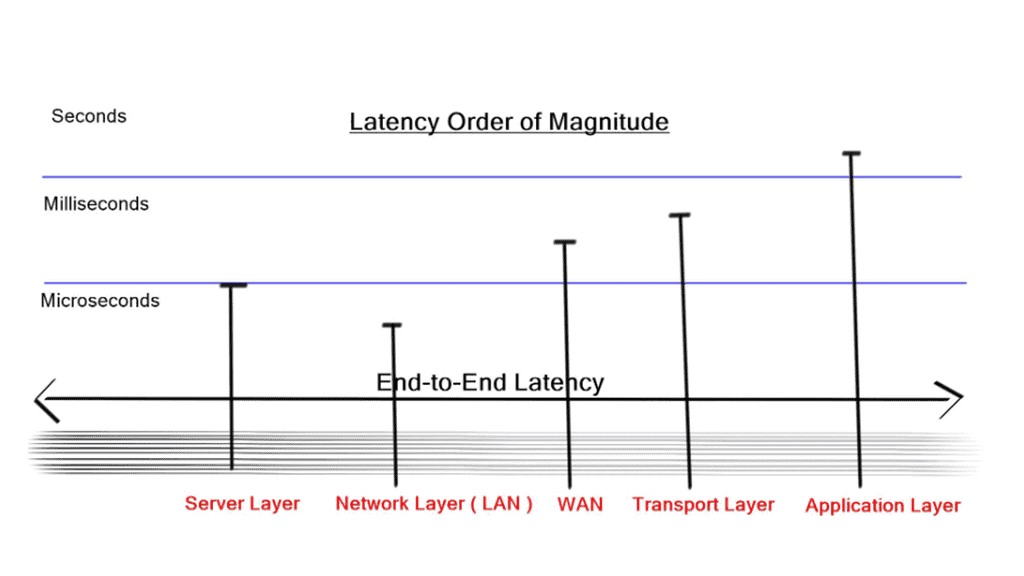
High-frequency trading ( HFT ) environments push for this trend, where providing information from stock markets with minimal delay is imperative. HFT environments are different than most DC designs and don’t support virtualization. The Port count is low, and servers are designed in small domains.
It is conceptually similar to how Layer 2 domains should be designed as small Layer 2 network pockets. Applications are grouped to match optimum traffic patterns where many-to-one conversations are reduced. This will reduce the need for buffering, increasing network performance. CX-1 cables are preferred over the more popular optical fiber.
Oversubscription
The optimum low-latency network design should consider and predict the possibility of congestion at critical network points. An unacceptable oversubscription example is a ToR switch with 20 Gbps traffic from servers but only 10 Gbps uplink. This will result in packet drops and poor application performance.
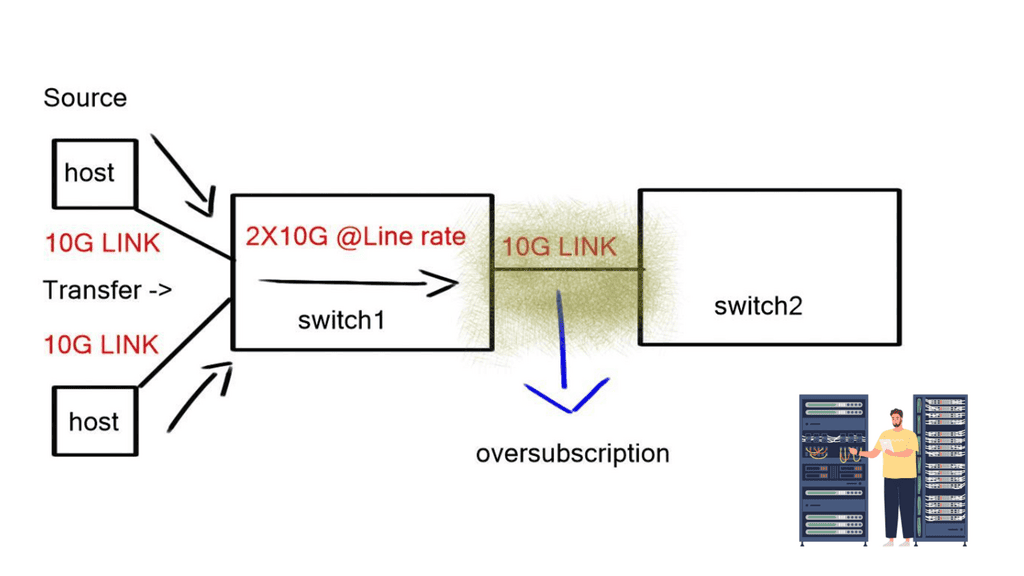
Previous data center designs were 3-tier aggregation model-based ( developed by Cisco ). Now, we are going for 2-tier models. The main design point for this model is the number of ports on the core; more ports on the core result in more extensive networks. Similar design questions would be a) how much routing and b) how much bridging will I implement c) where do I insert my network services modules?
We are now designing networks with lots of tiers—Clos Network. The concept comes from voice networks from around 1953, previously built voice switches with crossbar design. Clos designs give optimum any-to-any connectivity. They require low latency and non-blocking components. Every element should be non-blocking. Multipath technologies deliver a linear increase in oversubscription with each device failure and are better than architectures that degrade during failures.
Lossless transport
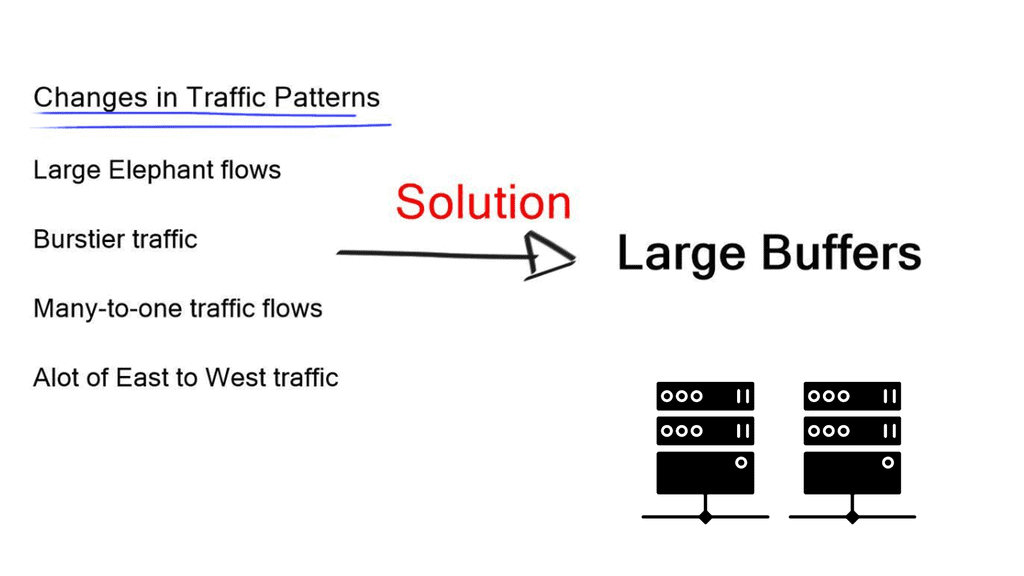
Data Center Bridging ( DCB ) offers standards for flow control and queuing. Even if your data center does not use ISCSI (the Internet Small Computer System Interface), TCP elephant flows benefit from lossless transport, improving data center performance. However, research has shown that many TCP flows are below 100Mbps.
The remaining small percentage are elephant flows, which consume 80% of all traffic inside the data center. Due to their size and how TCP operates, when an elephant flows and experiences packet drops, it slows down, affecting network performance.
Distributed resource scheduling
VMmobiliy is a VMware tool used for distributed resource scheduling. Load from hypervisors is automatically spread to other underutilized VMs. Other use cases in cloud environments where DC requires dynamic workload placement, and you don’t know where the VM will be in advance.
If you want to retain sessions, keep them in the same subnet. Layer 3 VMotion is too slow, as routing protocol convergence will always take a few seconds. In theory, you could optimize timers for fast convergence, but in practice, Interior Gateway Protocols ( IGP ) give you eventual consistency.
VMmobility
Data Centers require bridging at layer 2 to retain the IP addresses for VMobility. The TCP stack currently has no separation between “who” and “where” you are; the IP address represents both functions. Future implementation with Locator/ID Separation Protocol ( LISP ) divides these two roles, but bridging for VMobility is required until fully implemented.
Spanning Tree Protocol ( STP )
Spanning Tree reduces bandwidth by 50%, and massive multipathing technologies allow you to scale without losing 50% of the link bandwidth. Data centers want to move VMs without distributing traffic flow. VMware has VMotion. Microsoft Hyper-V has Live migration.
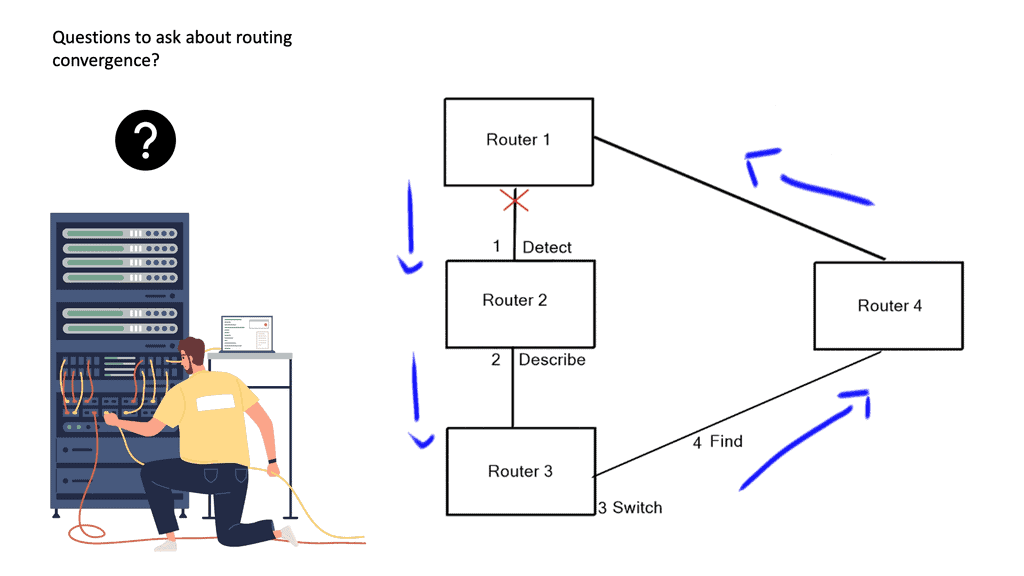
Network convergence
The layer 3 network requires many events to be completed before it reaches a fully converged state. In layer 2, when the first broadcast is sent, every switch knows precisely where that switch has moved. There are no mechanisms with Layer 3 to do something similar. Layer 2 networks result in a large broadcast domain.
You may also experience large sub-optimal flows as the Layer 3 next hop will stay the same when you move the VM. Optimum Layer 3 forwarding – what Juniper is doing with Q fabric. Every Layer 3 switch has the same IP address; they can all serve as the next hop—resulting in optimum traffic flow.
Deep packet buffers
We have more DC traffic and elephant flows from distributed databases. Traffic is now becoming very bursty. We also have a lot of microburst traffic. The bursts are so short that they don’t register as high link utilization but are big enough to overflow packet buffers and cause drops. This type of behavior with TCP causes TCP to start slowly, which is problematic for networks.
Final Points – Low Latency Network Design
Several strategies can be employed to minimize latency in network design. Firstly, utilizing edge computing can bring computational resources closer to users, reducing the distance data must travel. Secondly, implementing Quality of Service (QoS) policies can prioritize critical data traffic, ensuring it reaches its destination promptly. Lastly, optimizing hardware and software configurations, such as using high-performance routers and switches, can also contribute to reducing latency.
Low latency networks are essential in various industries. In finance, milliseconds can make the difference between profit and loss in high-frequency trading. Online gaming relies on low latency to ensure smooth gameplay and prevent lag. In healthcare, low latency networks enable real-time telemedicine consultations and remote surgeries. These examples underscore the importance of designing networks that prioritize low latency.
While the benefits are clear, designing low latency networks comes with its own set of challenges. Balancing cost and performance can be tricky, as achieving low latency often requires significant investment in infrastructure. Additionally, maintaining low latency across geographically dispersed networks can be challenging due to varying internet conditions and infrastructure limitations.
Designing a low latency network is a complex but rewarding endeavor. By understanding the fundamentals, employing effective strategies, and acknowledging the challenges, network designers can create systems that offer lightning-fast connectivity. As technology continues to evolve, the demand for low latency networks will only grow, making it an exciting field with endless possibilities for innovation.

- DMVPN - May 20, 2023
- Computer Networking: Building a Strong Foundation for Success - April 7, 2023
- eBOOK – SASE Capabilities - April 6, 2023
[…] Within the DC, every point is connected together and you can assume unconstrained capacity. A common data centre design is a leaf and spine architecture, where all nodes have equidistant endpoints. This is not the case in the WAN. The WAN has […]