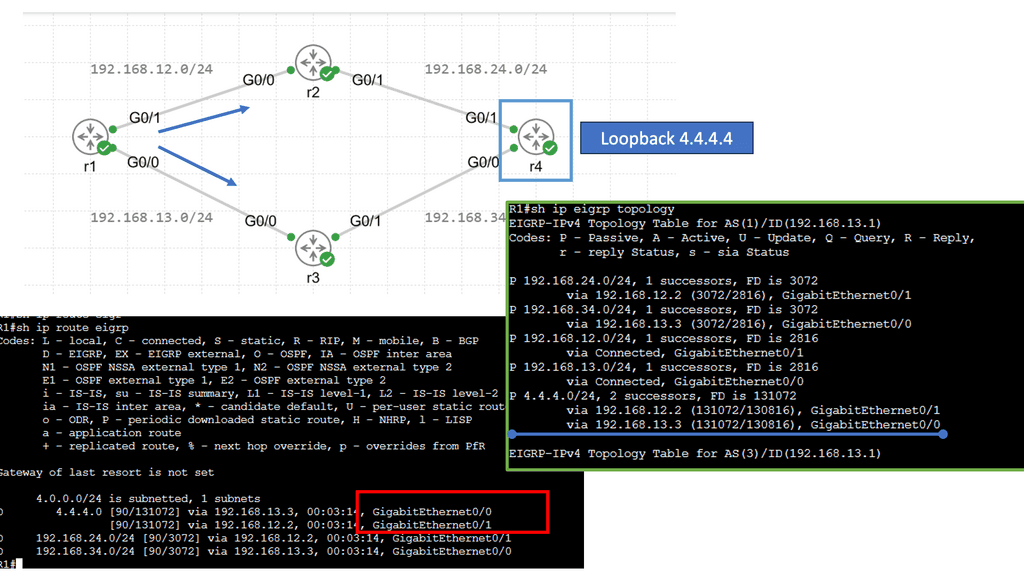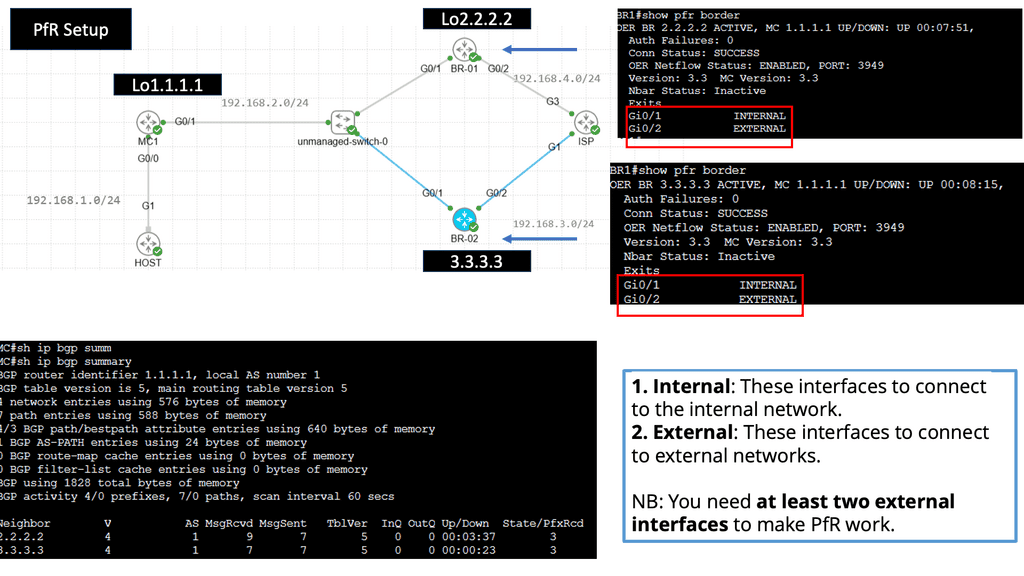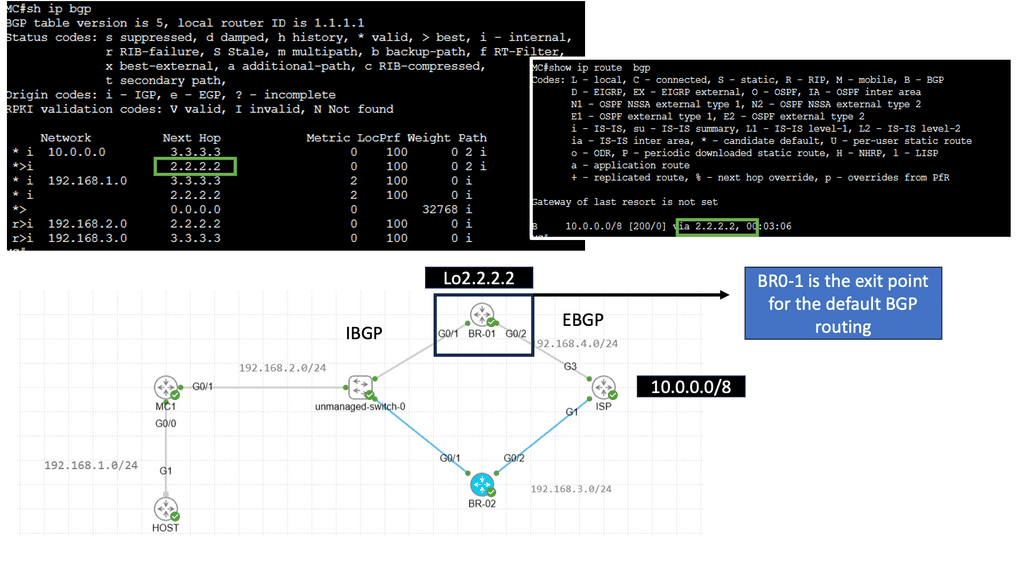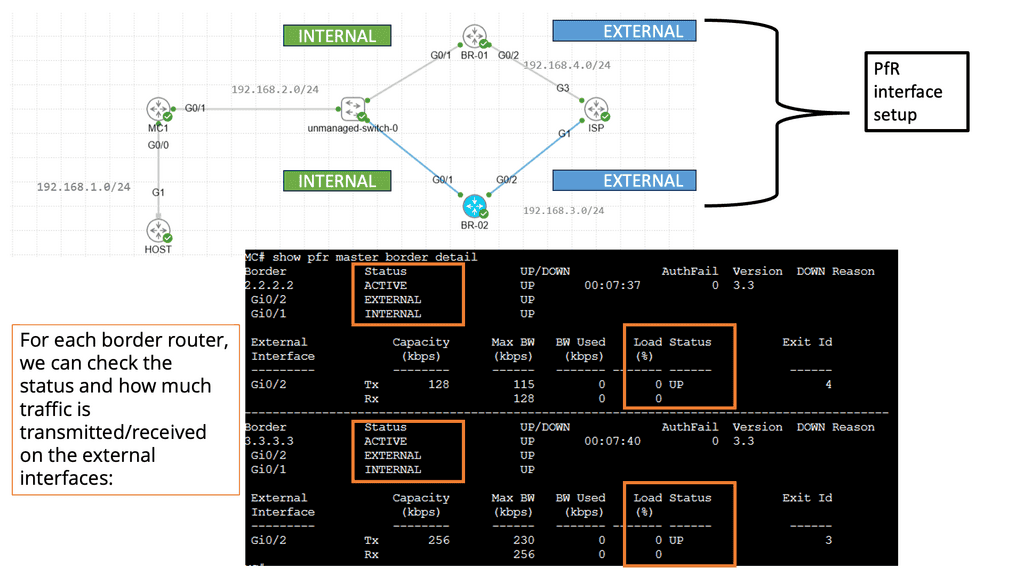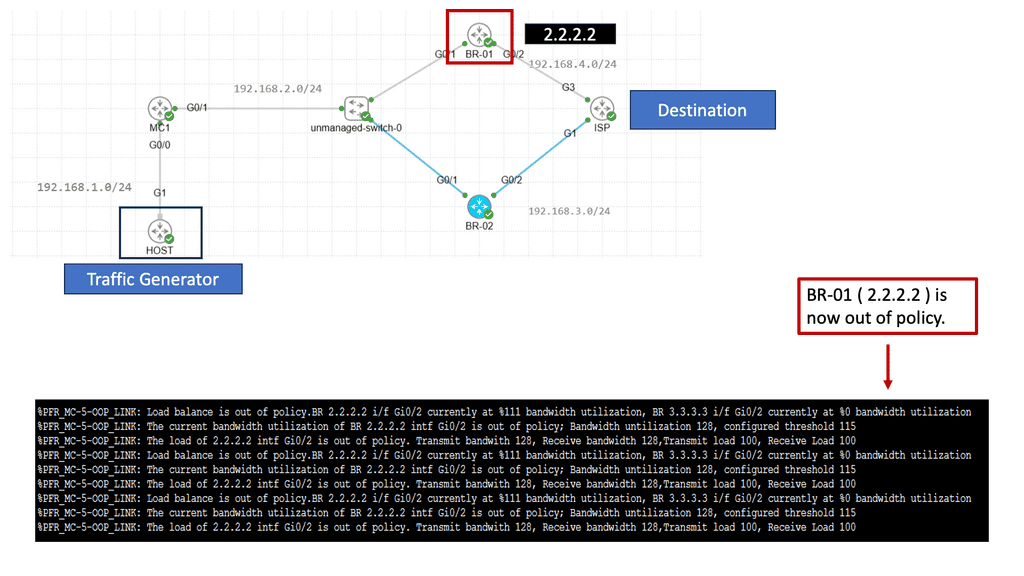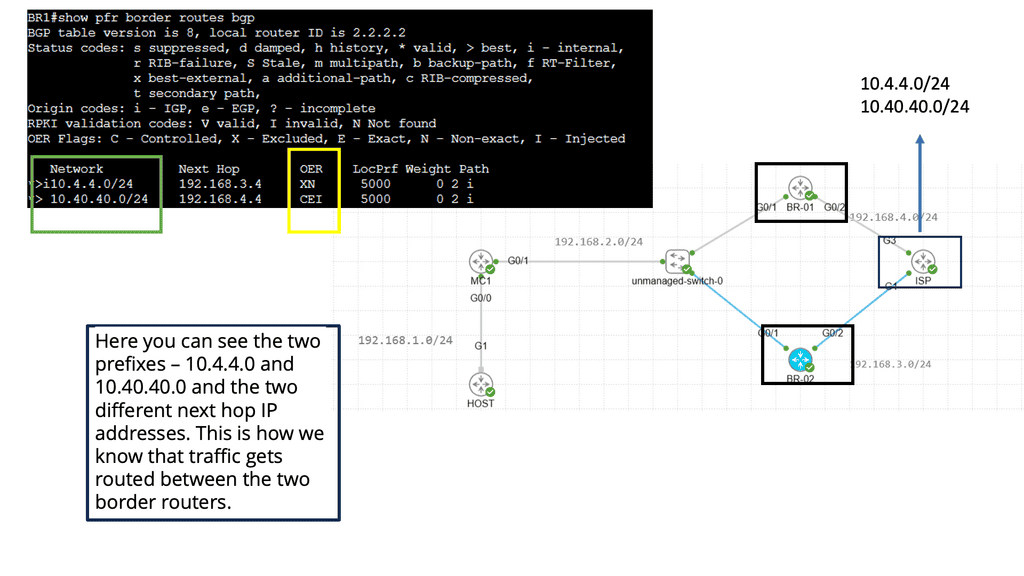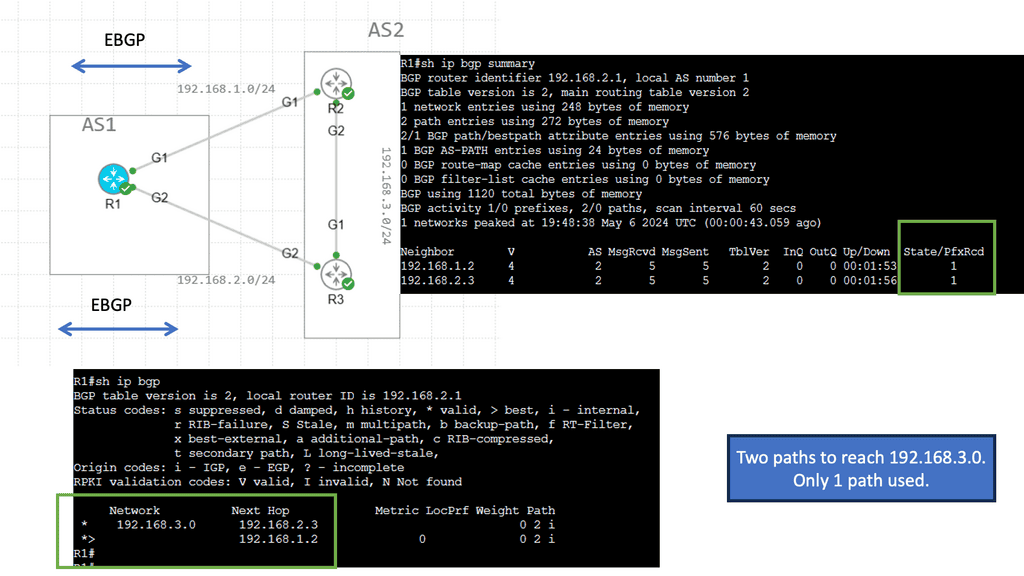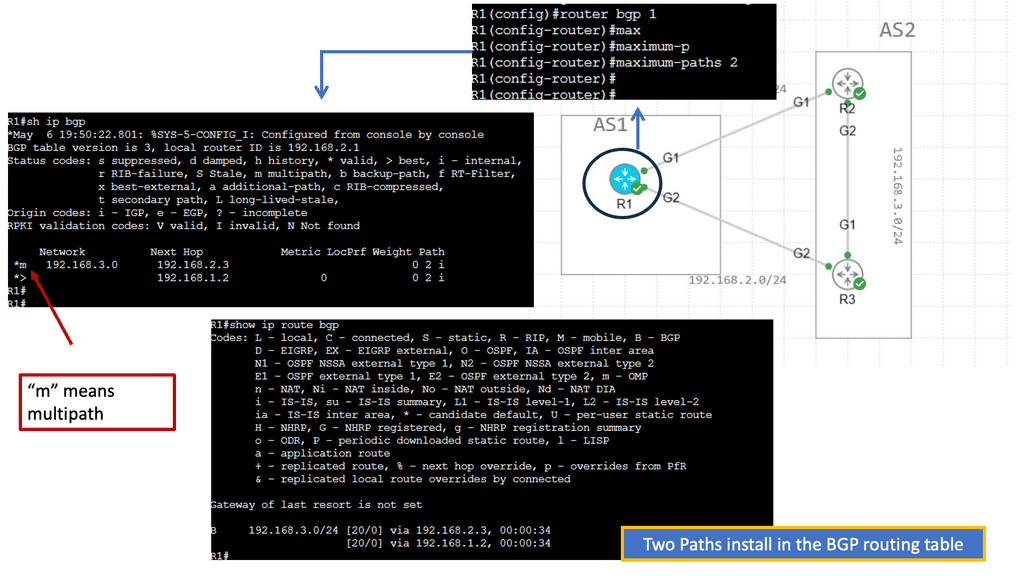
Understanding Application Delivery Architecture
Application Delivery Architecture refers to the framework, infrastructure, and processes involved in delivering applications to end-users. It encompasses various elements such as load balancers, web servers, caching mechanisms, content delivery networks (CDNs), and more. The primary goal is to ensure fast, secure, and reliable application delivery while optimizing resource utilization.
Additionally, ADNs employ caching techniques to store copies of frequently accessed content closer to the end-users, reducing the time it takes for data to travel across the network.
Security is another vital function of ADNs. They help protect applications from threats such as Distributed Denial of Service (DDoS) attacks and data breaches by filtering malicious traffic and encrypting sensitive information. This ensures that users can access applications securely without compromising on speed or performance.
Effective application delivery architecture is not just a theoretical concept but has real-world applications and benefits. For instance, e-commerce platforms rely heavily on efficient application delivery to handle large volumes of traffic during peak shopping seasons.
Similarly, streaming services use advanced application delivery techniques to provide high-quality, buffer-free viewing experiences to millions of users worldwide. By optimizing their application delivery architecture, businesses can enhance user satisfaction, reduce operational costs, and gain a competitive edge in the market.
ADN Components:
Load Balancers: Load balancers distribute incoming application traffic across multiple servers, ensuring efficient workload distribution and preventing any single server from being overwhelmed. They enhance application availability, scalability, and fault tolerance.
Web Servers: Web servers handle incoming requests from clients and deliver the requested web pages or content. They play a critical role in processing dynamic content, executing scripts, and interacting with backend databases or applications.
Caching Mechanisms: Caching mechanisms, such as content caching and session caching, reduce the load on backend servers by storing frequently accessed data or session information closer to the client. This improves response times and reduces network latency.
Content Delivery Networks (CDNs): CDNs are geographically distributed networks of servers that deliver web content to end-users based on their location. By caching content in multiple locations, CDNs ensure faster delivery, lower latency, and improved user experience.
**Best Practices: Optimizing Application Delivery Architecture**
a: – Scalability and Redundancy: Designing an architecture that allows for horizontal scalability and redundancy is crucial for handling increasing application loads and ensuring high availability. Implementing auto-scaling mechanisms and replicating critical components across multiple servers or data centers helps achieve this.
b: – Security and Performance Optimization: Implementing robust security measures, such as firewalls, intrusion detection systems, and SSL certificates, protects applications from cyber threats. Additionally, optimizing performance through techniques like content compression, connection pooling, and query optimization enhances overall application speed and responsiveness.
c: – Monitoring and Analytics: Monitoring the performance and health of application delivery infrastructure is essential for proactive issue identification and resolution. Utilizing real-time analytics and logging tools helps in identifying bottlenecks, optimizing resource allocation, and ensuring peak performance.
d: – Adopt Microservices Architecture: Transitioning from monolithic to microservices architecture can significantly boost scalability and flexibility. By breaking down applications into smaller, independent services, businesses can deploy and scale components individually, optimizing resource usage and improving delivery times.
e: – Embracing Automation and Monitoring: Automation and monitoring are essential components of a modern application delivery strategy. Automated deployment pipelines ensure consistent and error-free delivery, while monitoring tools provide real-time insights into performance and potential bottlenecks. By continuously analyzing data, businesses can make informed decisions and swiftly adapt to changing demands and conditions.
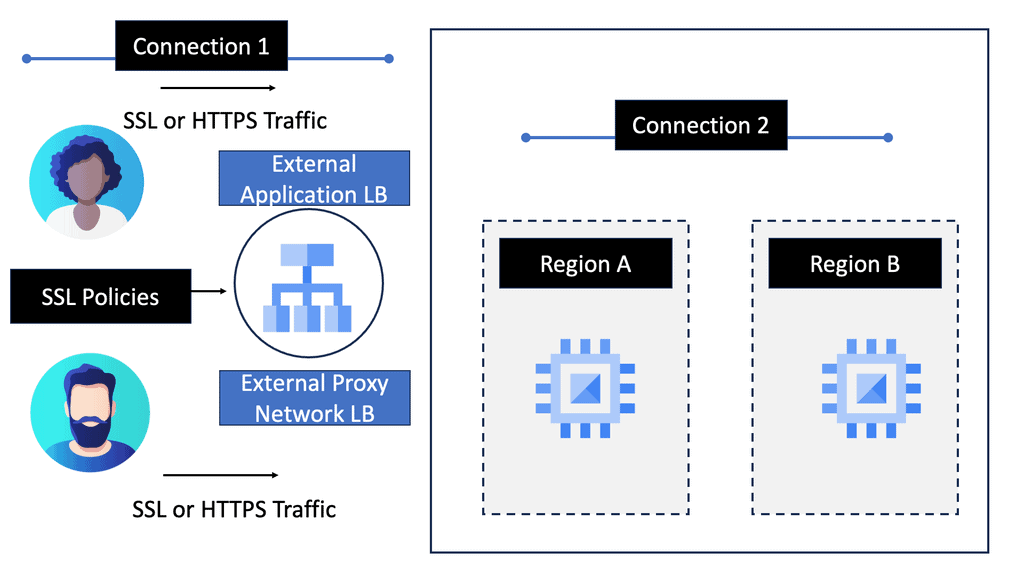
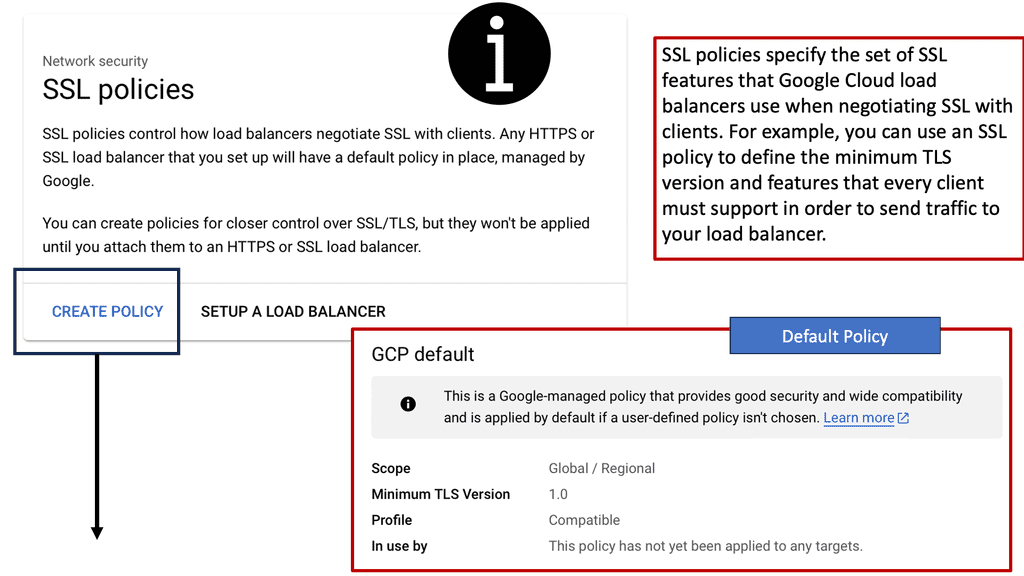
Example ADN Technology: SSL Policies
#### What Are SSL Policies?
SSL policies are configurations that determine the security level of a connection between a client and a server. They enable users to define the minimum and maximum TLS (Transport Layer Security) versions allowed for their applications. By setting these parameters, businesses can ensure that their data remains encrypted and secure during transmission, protecting it from potential eavesdroppers or malicious attacks.
#### Importance of SSL Policies in Google Cloud
Google Cloud offers a robust infrastructure for businesses looking to leverage cloud technology. However, with great power comes great responsibility; securing data is paramount. Implementing SSL policies in Google Cloud allows businesses to establish secure connections between their clients and services. These policies help mitigate risks associated with outdated protocols and encryption algorithms, ultimately ensuring that data is transmitted safely.
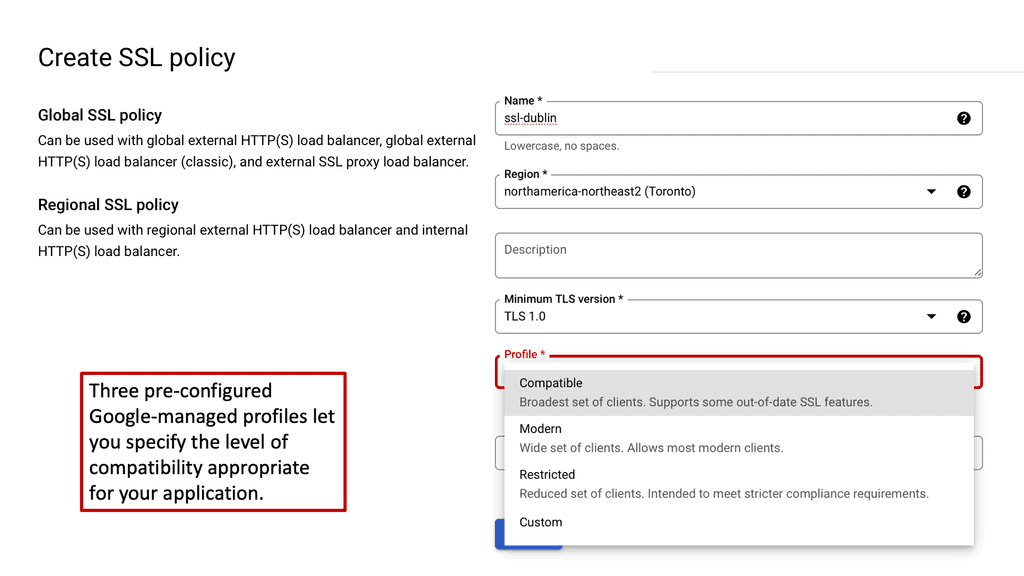
#### Configuring SSL Policies in Google Cloud
Setting up SSL policies in Google Cloud is a straightforward process that can significantly enhance data security. Users can create, modify, and apply SSL policies to their load balancers, ensuring that only the desired security protocols are used. It is crucial to regularly update these policies to align with the latest security standards and best practices. Google Cloud provides intuitive tools and documentation to guide users through the configuration process, making it accessible even for those with limited technical expertise.
#### Best Practices for SSL Policy Management
To maximize the security benefits of SSL policies, businesses should adhere to several best practices. First, always enforce the use of the latest TLS versions, as older versions are more susceptible to vulnerabilities. Second, regularly review and update SSL policies to adapt to evolving security threats. Finally, ensure comprehensive logging and monitoring of SSL traffic to quickly identify and respond to potential security incidents.
 Proxy Servers
Proxy Servers
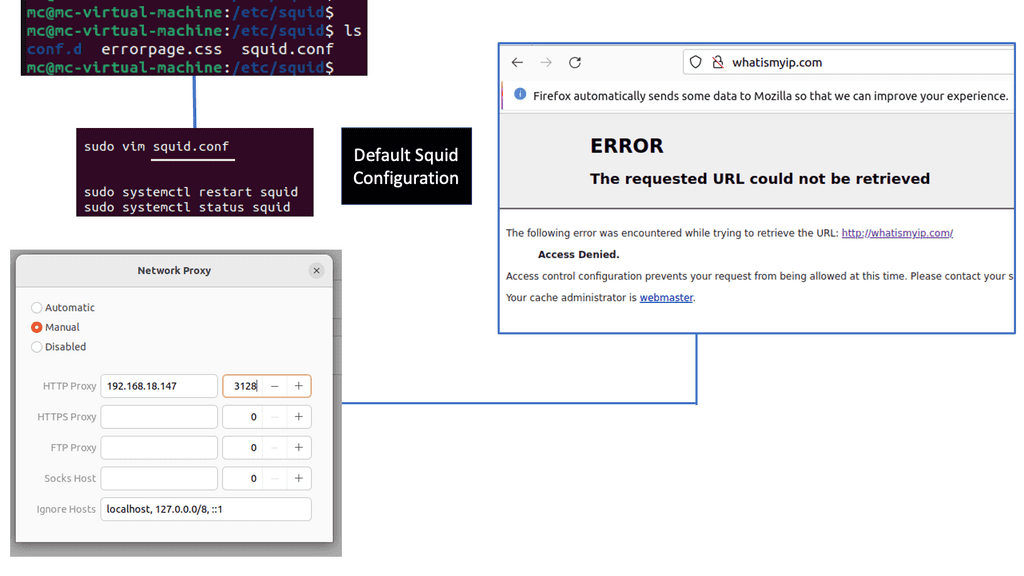
Understanding Squid Proxy Server
Squid Proxy Server is an open-source caching and forwarding HTTP web proxy server. It acts as an intermediary between the client and the server, allowing client requests to be fulfilled by caching and forwarding the server’s responses. With its robust architecture and extensive configuration options, Squid Proxy Server provides enhanced performance, security, and control over internet traffic.
Caching Capabilities:
Squid Proxy Server excels in caching web content, which leads to faster response times and reduced bandwidth consumption. By storing frequently accessed web content locally, Squid significantly minimizes the load on the network and accelerates subsequent requests.
Access Control and Security:
One of the notable advantages of Squid Proxy Server is its robust access control mechanisms. It allows administrators to define granular policies, restrict access to specific websites, block malicious content, and enforce authentication protocols, thereby enhancing security and ensuring compliance with organizational requirements.
Bandwidth Management:
With its comprehensive bandwidth management features, Squid Proxy Server enables organizations to optimize network utilization efficiently. It provides options to prioritize or limit bandwidth for different types of traffic, ensuring a fair distribution of resources and preventing congestion.

Highlighting the components:
According to Gartner, application delivery networking combines WAN optimization controllers (WOCs) with application delivery controllers (ADCs). ADNs have Advanced Traffic Management Devices (ADCs), often called web switches, content switches, or multilayer switches. Traffic is distributed between servers or geographically dispersed sites based on application-specific criteria. In addition to caching and compression, ADNs utilize TCP traffic optimization techniques such as prioritization and other methods to reduce the amount of data flowing over the network.
Data centers usually install some WOC components, while PCs and mobile devices install others. Some CDN vendors also offer application delivery networks.
Application delivery systems that optimize network availability rely on the following three components: high availability, which benefits both users and businesses by ensuring a seamless user experience, faster application response times, and efficient resource usage.
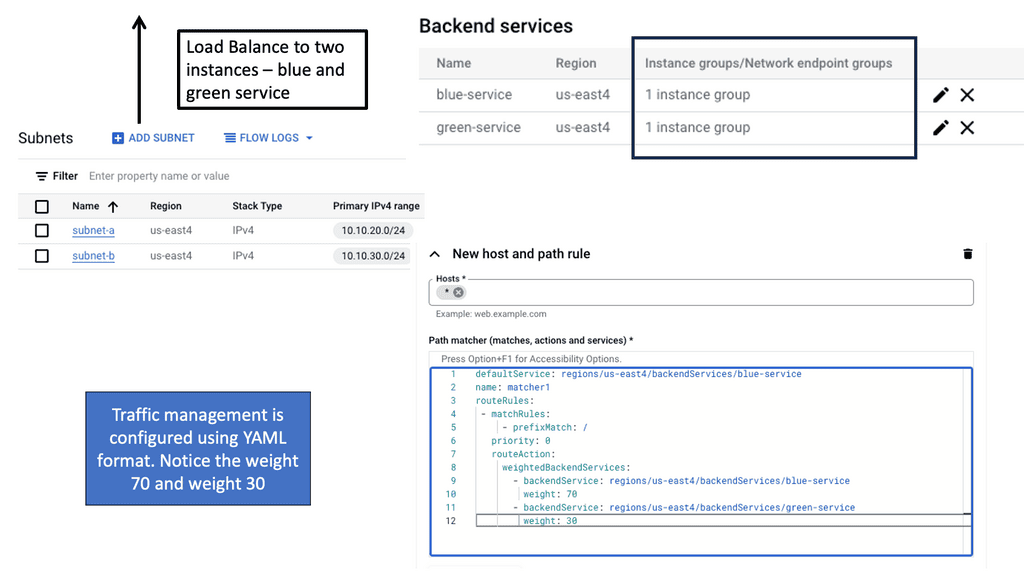
1: Load Balancer
A load balancer distributes incoming network traffic across multiple server instances, ensuring application or service availability and performance. It also ensures redundancy and failover capabilities if one server becomes unavailable or overloaded. Load balancers use various algorithms to determine how traffic should be distributed to backend servers.
Modern networked environments require load balancing to manage and optimize traffic flows. This ensures a seamless and responsive user experience while maintaining system availability and responsiveness, even under heavy load or when servers fail.
2: Caching
Caching is a critical component of an ADN that improves application response times. Caches store frequently accessed data, such as web pages or images, closer to the end-user. When a user requests the same content again, the cache delivers it quickly, reducing the need for data retrieval from the source. This accelerates application delivery and reduces the load on backend servers.
3: Content Delivery Networks (CDNs)
CDNs, distributed servers strategically located in various geographic locations, cache and serve content such as web pages, images, videos, and other static assets. When a user makes a request, content is delivered from the nearest edge server to reduce latency, improve load times, and increase application efficiency.
CDNs benefit both content providers and end users by optimizing the delivery of web content and applications. Most CDNs have servers around the globe, so users can access content quickly, regardless of where they are. Security features are also often included in CDNs, including DDoS protection, web application firewall capabilities, and encryption to guard against malicious traffic and cyberattacks.
4: Application Delivery Network (ADN)
ADNs optimize the performance, availability, and security of web applications. In addition to CDNs, they provide web apps, APIs, and other transactional services that overcome the complexities associated with dynamic, interactive, and personalized content delivery. ADNs are primarily responsible for ensuring that web apps and services are delivered efficiently, reliably, and securely.
CDNs and ADNs are similar in optimizing content and applications but serve distinct purposes. A CDN reduces latency and increases the speed of content retrieval for static content, such as images, videos, and scripts. By optimizing the entire application stack, ADNs go beyond static content delivery and are suited for web applications, e-commerce platforms, and services that require efficient transactional handling. To achieve a more vital, holistic approach to content and application delivery, many organizations integrate both CDNs and ADNs into their infrastructure.
5: Application Acceleration
Techniques and technologies used to accelerate applications are known as application acceleration. Data compression reduces data sent over the network, improves response times, and reduces bandwidth consumption by reducing the amount of data sent. Streaming videos, playing games online, and participating in video conferences require real-time or low-latency communication. Another technique to accelerate applications is data caching, which stores frequently accessed data at edge locations in a cache. The cache is checked first when a user or application requests data. A cached version of the data can be delivered much faster than a source-based one.
Web and application servers, application delivery controllers, and load balancers can perform applications such as data caching and compression outside CDNs.
Vendor Example: AVI Networks
Avi networks offer load balancing as a hyper-scale application delivery architecture and optimization service. Hyperscale can be defined as the ability of the architect to scale as demand increases for the system. At the same time, application demand changes, so the system architecture is automatically based on traffic load. The Avi load balancer requires no capacity pre-provisioning, making it a perfect cloud application delivery platform.
When companies buy load balancers ( application delivery platforms ), they buy 2 x 10G load balancer appliances and check they can support x of Secure Sockets Layer ( SSL ) connections—probably purchased without application analytics, causing the appliance to be under or over-utilized. Avi scaling feature enables application delivery services to be elastically scaled out and scaled in on-demand. They are maximizing network resources and enabling hyper-scale application delivery architecture.
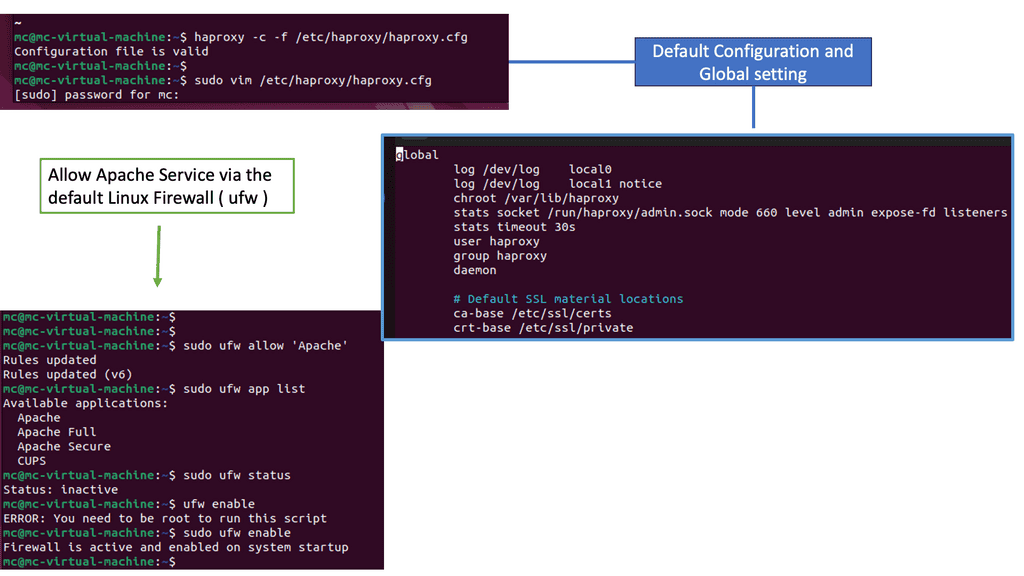
Understanding Load Balancing
Load balancing is the process of distributing incoming network traffic across multiple servers to ensure efficient resource utilization and prevent overload. By intelligently managing requests, load balancers like HAProxy enhance performance and reliability. In this section, we will explore the fundamental concepts of load balancing and its importance in modern web applications.
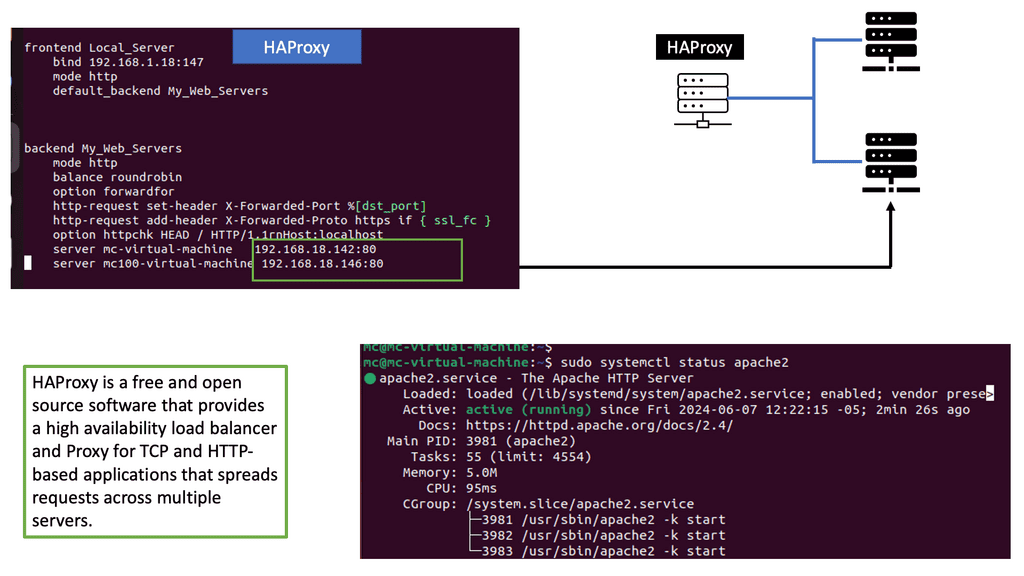
Load Balancing – HAProxy
HAProxy, an abbreviation for High Availability Proxy, is an open-source, software-based load balancer renowned for its speed, reliability, and flexibility. It acts as an intermediary between clients and servers, efficiently distributing incoming requests based on various algorithms and configurations. In this section, we will dive into the features, benefits, and use cases of HAProxy.
To unleash the power of HAProxy, it is essential to set it up correctly. In this section, we will walk you through the step-by-step installation and configuration process for HAProxy on your preferred operating system. From securing your system to fine-tuning load balancing rules, we will cover everything you need to get started with HAProxy.
Google Cloud Google Network Tiers
Understanding Network Tiers
– Network tiers refer to the different levels of network performance and availability offered by cloud service providers. In the case of Google Cloud, there are three tiers: Premium, Standard, and Subnet. Each tier comes with its own set of features, pricing structures, and service level agreements (SLAs). Understanding these tiers is crucial for making informed decisions about network configuration.
– The Premium Tier offers the highest network performance and lowest latency, making it ideal for mission-critical applications that require real-time interactions and high bandwidth. By utilizing the Premium Tier for such workloads, businesses can ensure maximum reliability and responsiveness, guaranteeing a seamless user experience even during peak traffic periods.
– For applications that don’t require the ultra-low latency of the Premium Tier, Google Cloud’s Standard Tier presents a cost-effective alternative. This tier provides a balance between performance and affordability, making it suitable for a wide range of workloads. By strategically deploying applications on the Standard Tier, businesses can achieve substantial cost savings without compromising on network performance.


VPC Networking
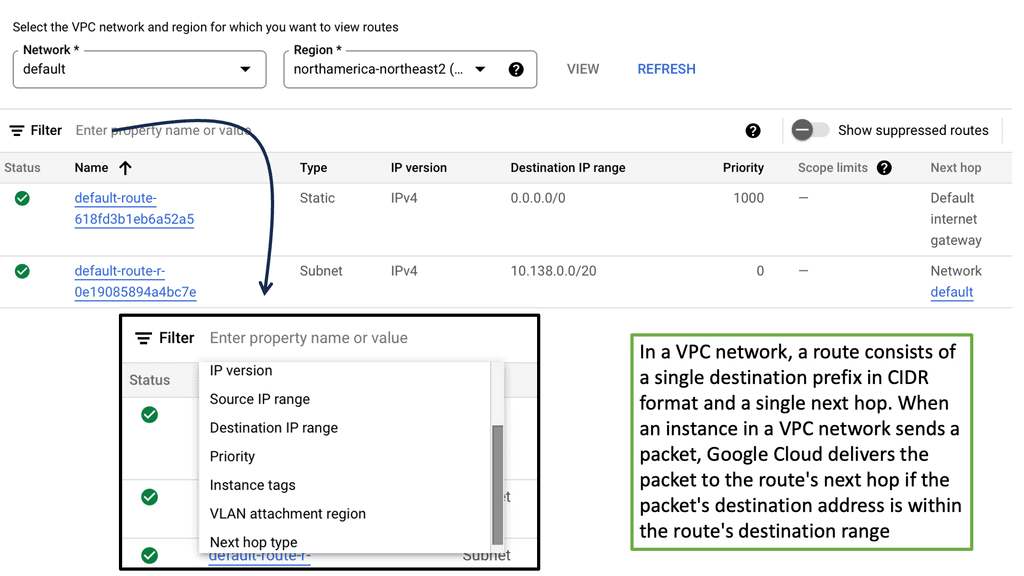
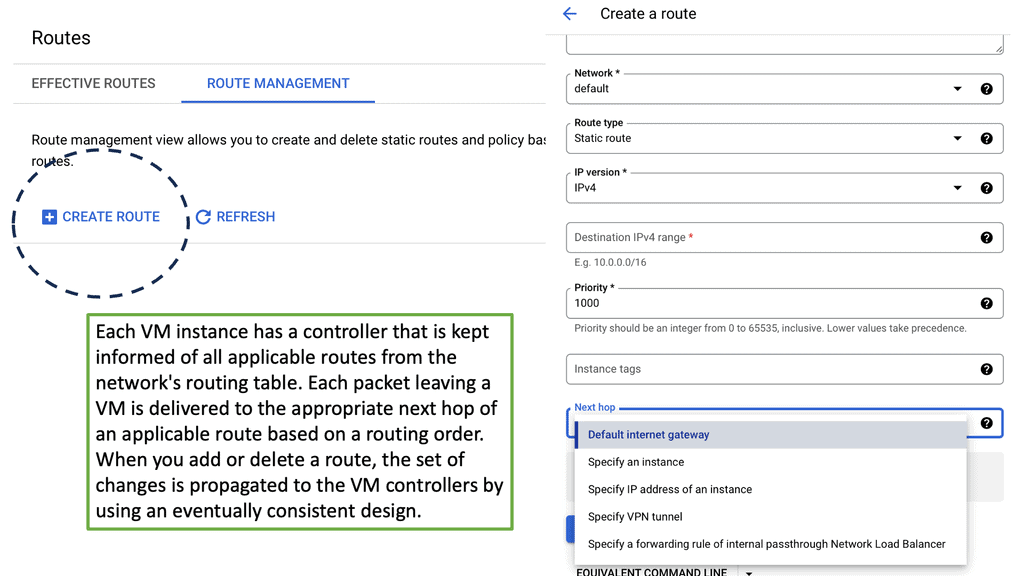
VPC networking is a vital feature provided by cloud service providers, such as Amazon Web Services (AWS) and Google Cloud Platform (GCP). It enables users to create isolated virtual networks within the cloud infrastructure, mirroring the functionality of traditional on-premises networks. By defining their own virtual network environment, users gain complete control over IP addressing, subnets, routing, and security.

Within the realm of VPC networking, several key components play crucial roles. These include subnets, route tables, security groups, network access control lists (NACLs), and internet gateways. Subnets divide the VPC IP address range into smaller segments, while route tables control the traffic flow between subnets. Security groups and NACLs enforce access control and traffic filtering, ensuring the security of the VPC. Internet gateways act as the entry and exit points for internet traffic.


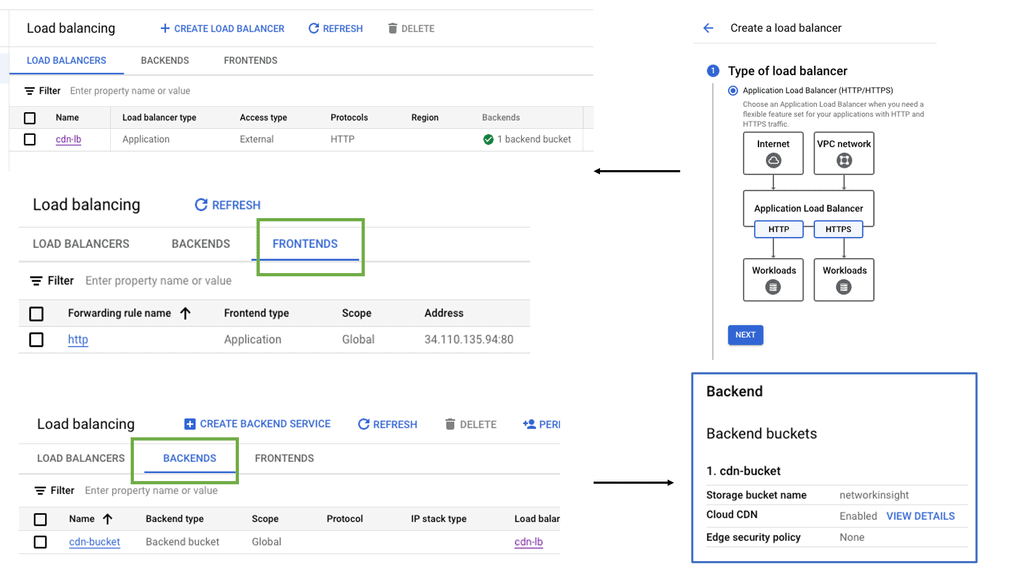
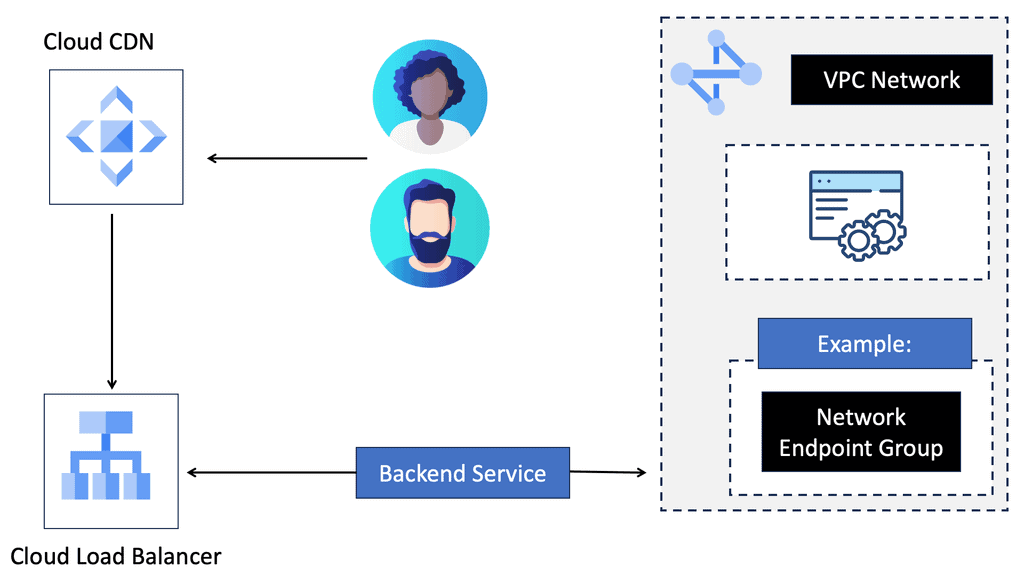
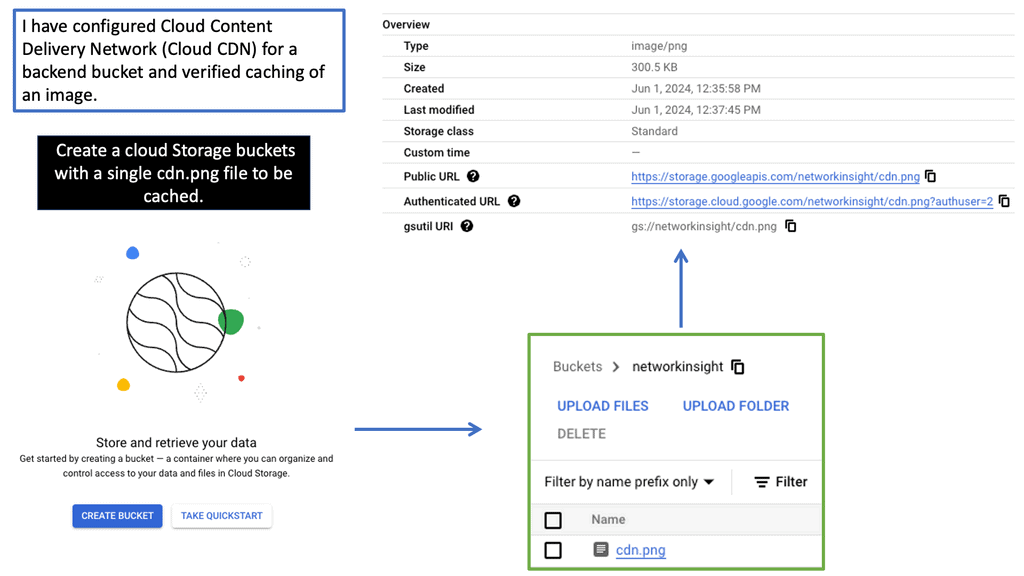
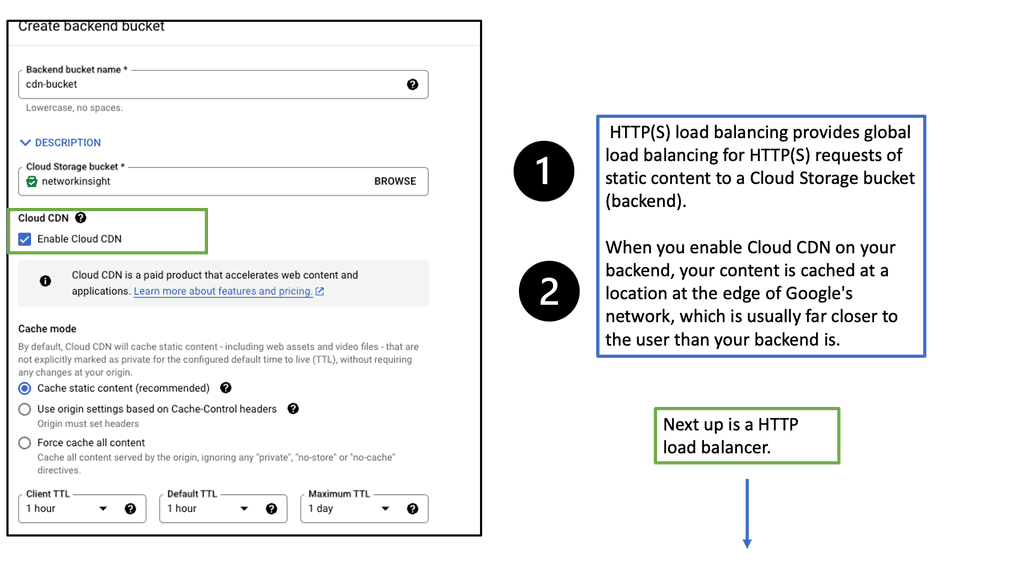
Understanding Cloud CDN
Cloud CDN, powered by Google Cloud, is a network of servers strategically placed across the globe. Its primary function is to efficiently distribute content to end-users by reducing latency and increasing website loading speeds. By caching static content and delivering it from the nearest server to the user, Cloud CDN ensures a seamless browsing experience.
1: – Improved Performance: With Cloud CDN, businesses can significantly reduce latency, resulting in faster loading times for their websites and applications. This enables a smoother user experience and increases customer satisfaction.
2: – Enhanced Scalability: Cloud CDN automatically scales resources based on demand, ensuring high availability and preventing performance degradation, even during peak traffic periods. This scalability eliminates concerns about sudden traffic spikes and allows businesses to focus on their core operations.
3: – Cost-Effective: By leveraging Cloud CDN, businesses can reduce bandwidth costs and decrease the load on their origin servers. The distributed nature of Cloud CDN optimizes content delivery and minimizes the need for additional infrastructure investments.
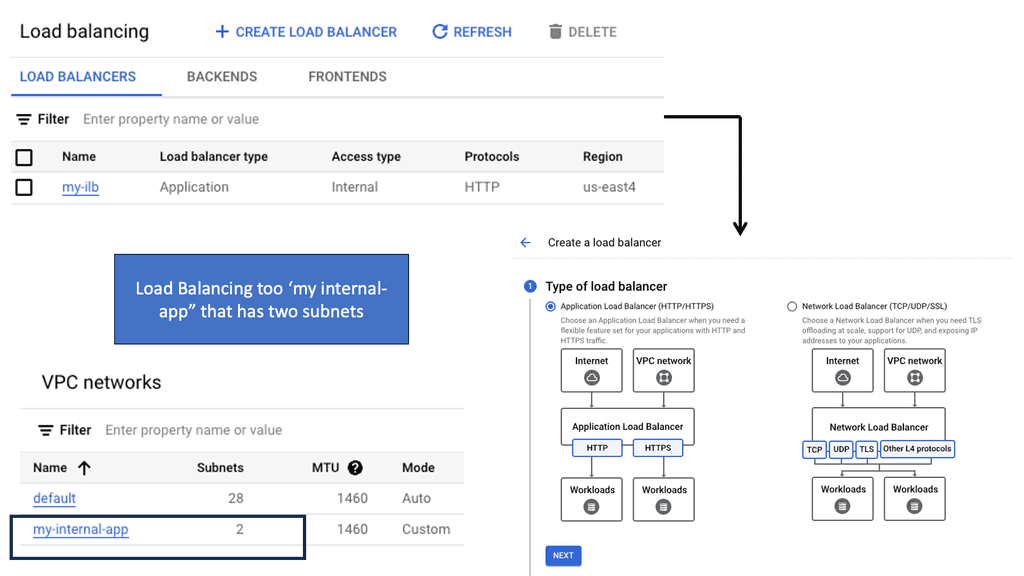
Understanding Load Balancing in Google Cloud
Before we dive into the specifics of network and HTTP load balancers, it’s essential to grasp the fundamental concept of load balancing in Google Cloud. Load balancing distributes incoming traffic across multiple instances or backend services, enabling efficient resource utilization and improved application performance.
Network Load Balancing: Network Load Balancing is a powerful service provided by Google Cloud that operates at the transport layer (Layer 4) of the OSI model. It efficiently distributes traffic to backend instances based on configurable forwarding rules and health checks. With network load balancers, you can achieve high throughput, low latency, and fault tolerance for your applications.
HTTP Load Balancing: HTTP Load Balancing, on the other hand, works at the application layer (Layer 7) and provides advanced features specific to HTTP and HTTPS traffic. With HTTP load balancers, you can perform content-based routing, SSL offloading, and session affinity, among other capabilities. It’s an excellent choice for web applications that require intelligent traffic distribution and flexibility.
To ensure optimal performance and reliability of your load balancers, it’s crucial to follow best practices. Some key recommendations include setting up health checks to monitor backend instances, using multiple regions for high availability, optimizing load balancer configurations based on your application’s requirements, and regularly reviewing and adjusting capacity settings.
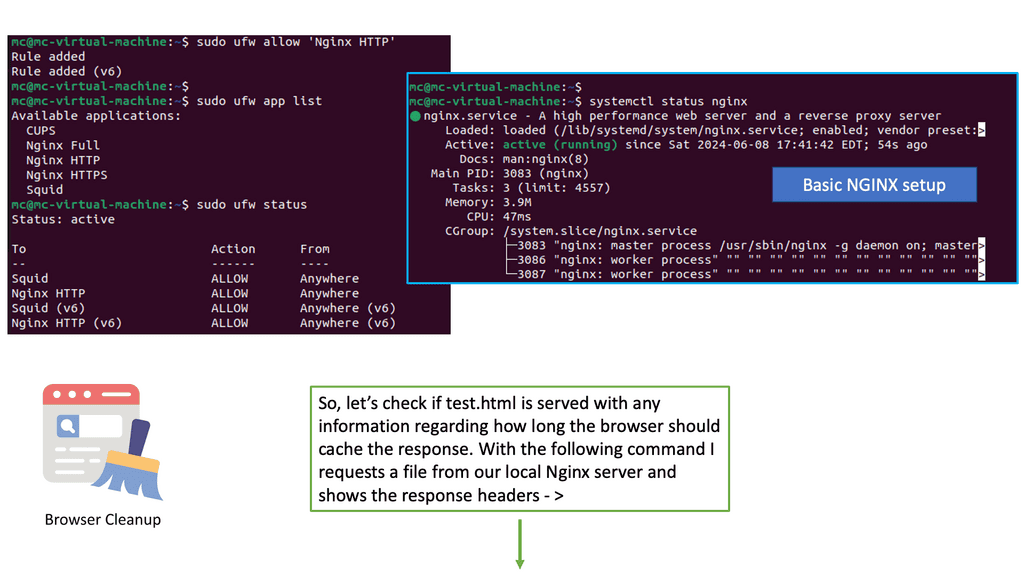
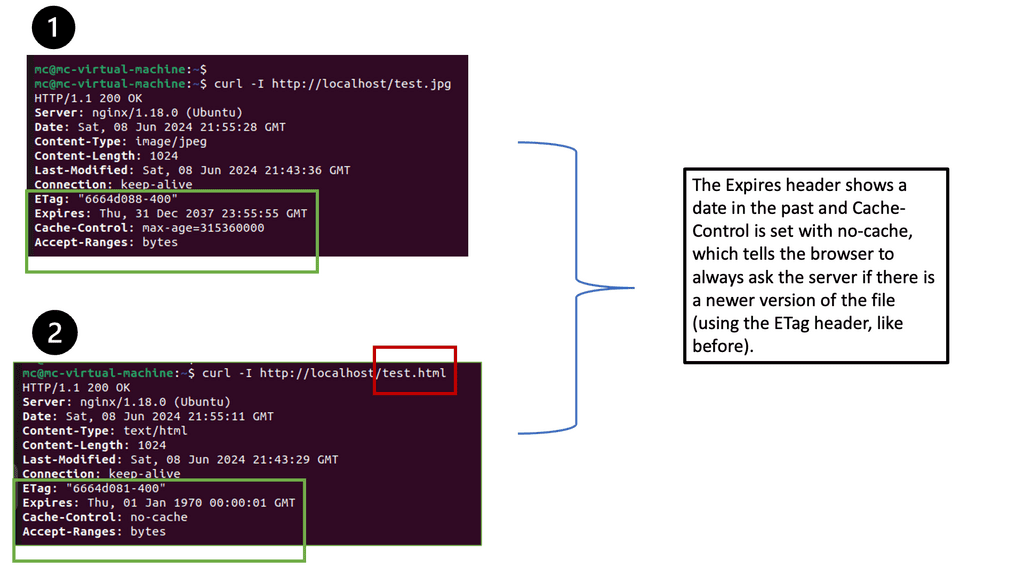
Understanding Browser Caching
Browser caching is a mechanism that allows web browsers to store certain resources locally. By doing so, subsequent visits to the website can be significantly faster, as the browser retrieves the cached resources instead of fetching them from the server. This reduces the amount of data that needs to be transferred, resulting in faster page load times.
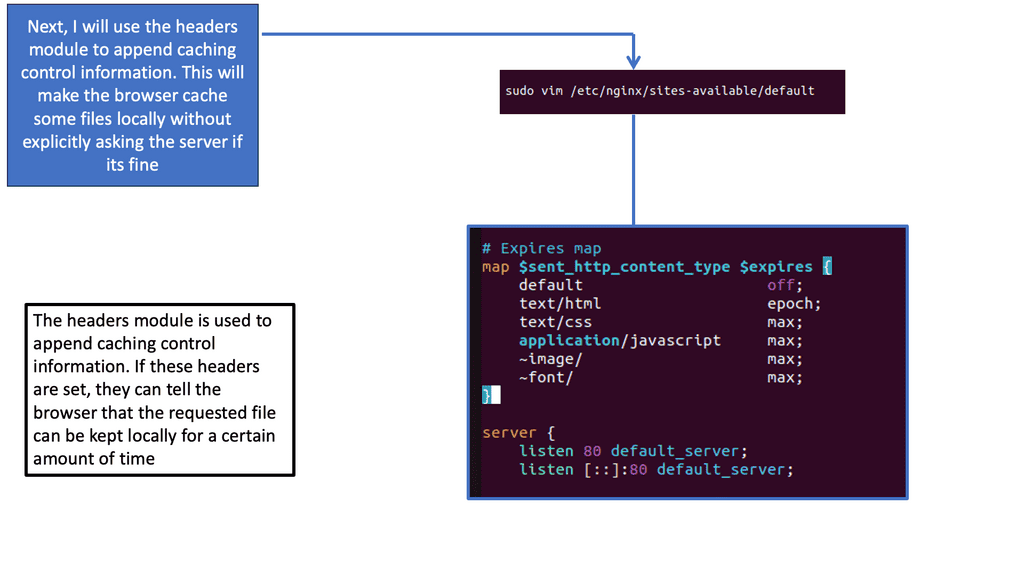
Nginx, a popular web server and reverse proxy server, offers a powerful module called “header” that enables fine-grained control over HTTP headers. These headers can be leveraged to implement browser caching directives, instructing the browser on how long it should cache specific resources.
One of the key directives provided by Nginx’s header module is “Cache-Control.” By properly configuring the Cache-Control header, we can specify caching behavior for different resources. For example, we can set a longer cache duration for static resources like CSS and JavaScript files, while ensuring that dynamic content remains fresh by setting appropriate cache-control directives.
While setting cache durations is important, it’s equally crucial to handle cache invalidation effectively. Nginx’s header module offers various mechanisms to achieve this. By using techniques like cache busting and cache purging, we can ensure that updated resources are fetched by the browser when necessary, while still benefiting from the performance gains of browser caching.

The Role of Applications
Applications are delivered to end users using a variety of technologies and processes. Modern digital landscapes require flawless application delivery to meet user expectations, maintain business operations, remain competitive, and adapt to changing needs.
Many organizations and individuals rely on applications every day to conduct their day-to-day operations and daily lives. Secure and reliable application delivery is a keystone of the modern app economy. Many applications must respond instantly and reliably to millions of concurrent users to boost customer satisfaction and revenue.
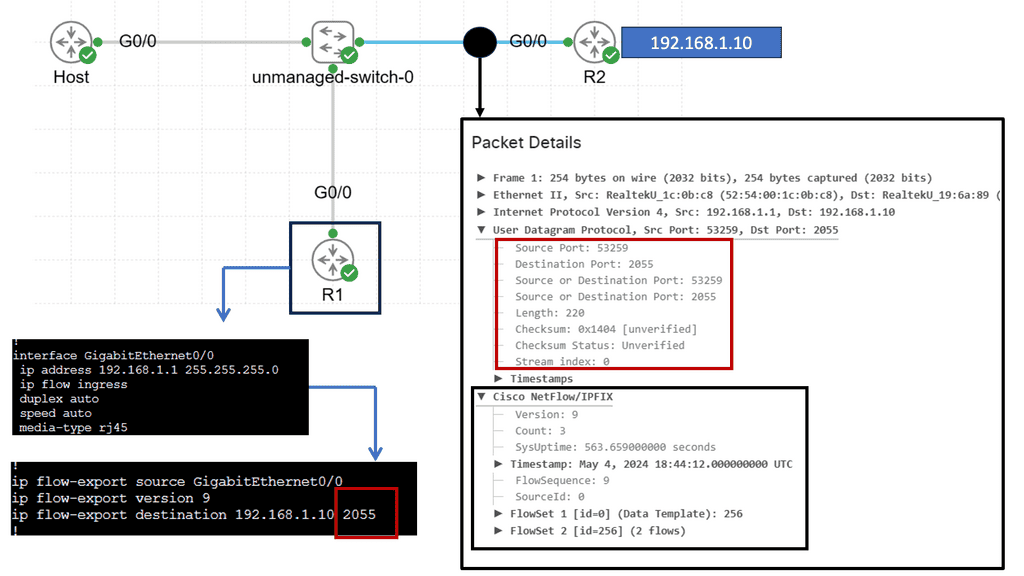
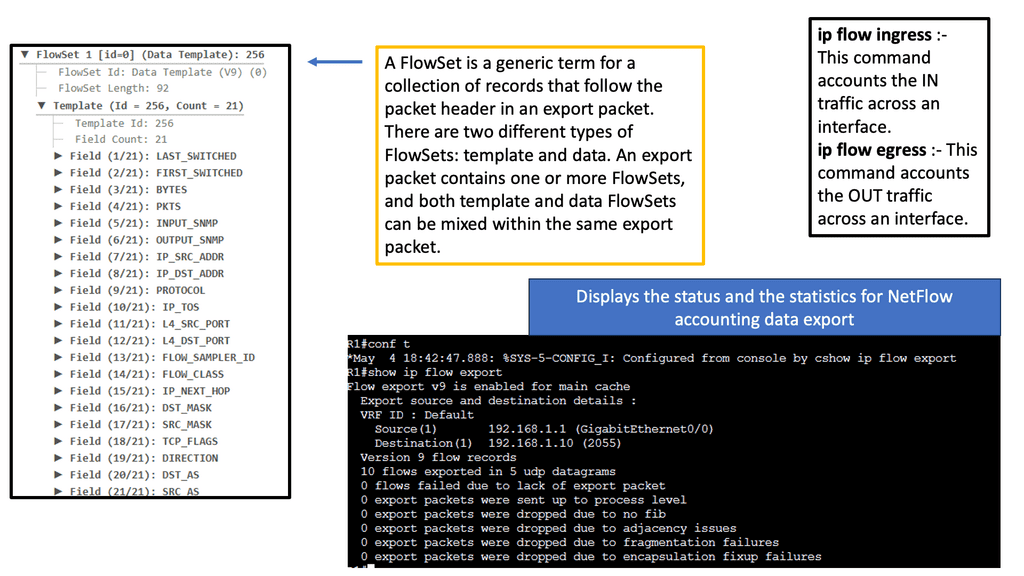
Example Technology: Netflow
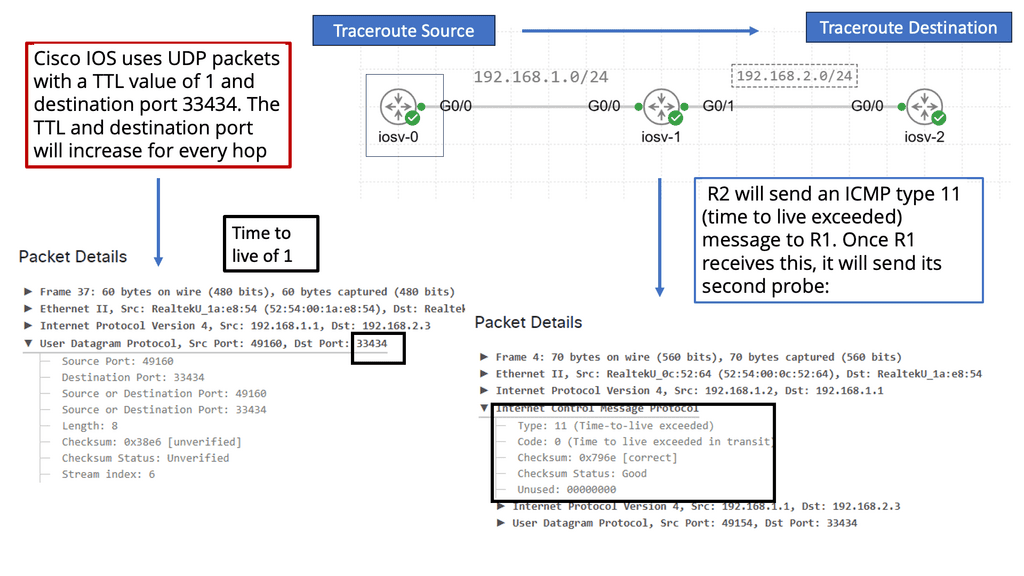
Netflow is a network protocol developed by Cisco Systems that enables the collection and analysis of IP traffic data. It records information about the source and destination IP addresses, ports, protocol types, and other relevant network flow details. Netflow allows network administrators to gain visibility into the traffic traversing their networks by capturing this information.
Netflow offers a multitude of benefits for network monitoring and management. Firstly, it provides valuable insights into network traffic patterns, allowing administrators to identify bandwidth-hungry applications, detect anomalies, and optimize network performance. Additionally, Netflow data can aid in identifying and mitigating security threats, as it provides detailed information about potential malicious activities and suspicious traffic behavior.
Application Delivery and Its Role
Optimizing the speed and responsiveness of applications is one of the primary roles of application delivery. Our increasingly digital lives require end users to have fast and efficient access to the applications they use to shop, bank, work, and play. In addition to ensuring business continuity and user convenience, application delivery focuses on ensuring that applications are available and accessible at all times. Securing applications is vital, protecting sensitive data, preventing cyberattacks, and maintaining user trust.
Delivering applications effectively is essential
User frustration can result from frequent downtime or interruptions of service. When sluggish or unresponsive, applications can frustrate users and negatively affect their overall experience. Users expect smooth and fast application loading. Consistently accessible and fast-loading applications contribute to user satisfaction.
Application performance directly impacts customer experience in industries where customer-facing applications are critical to business, such as e-commerce or online services. High availability and high-performance applications give companies a competitive advantage, increasing market share and revenue. When customers are satisfied, the likelihood of making purchases is higher.
Delivering Applications
Application Delivery Architecture is a crucial aspect of modern software development and deployment. It plays a significant role in ensuring the efficient delivery of applications to end-users. With the increasing demand for high-performance applications and the need for seamless user experiences, organizations are investing heavily in optimizing their application delivery architecture.
In a nutshell, application delivery architecture refers to the framework and infrastructure that enables the delivery of applications to end-users. It encompasses various components, including networking, load balancing, security, and scalability. The ultimate goal is to ensure that applications are delivered efficiently, reliably, and securely, regardless of the user’s location or device.
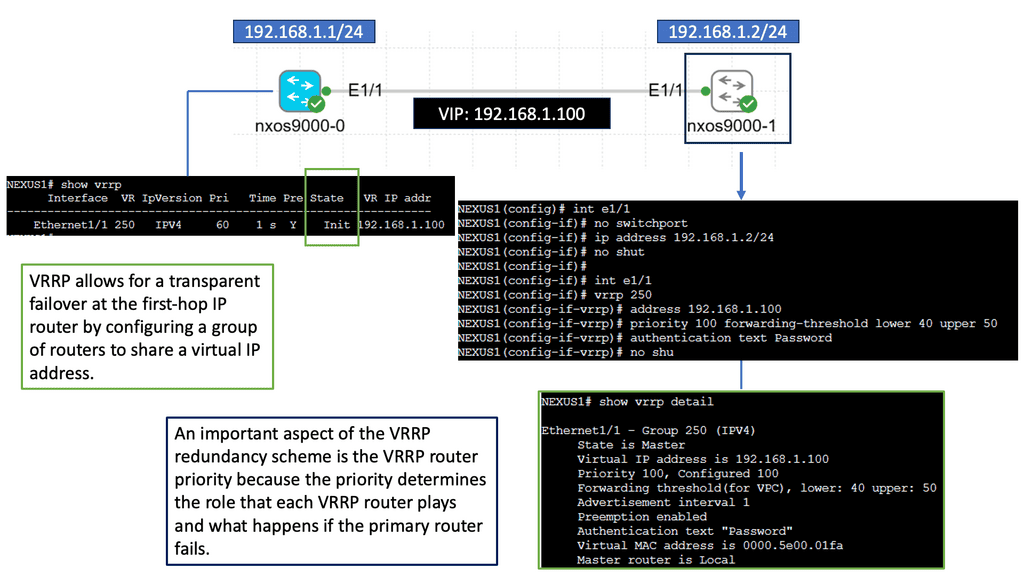
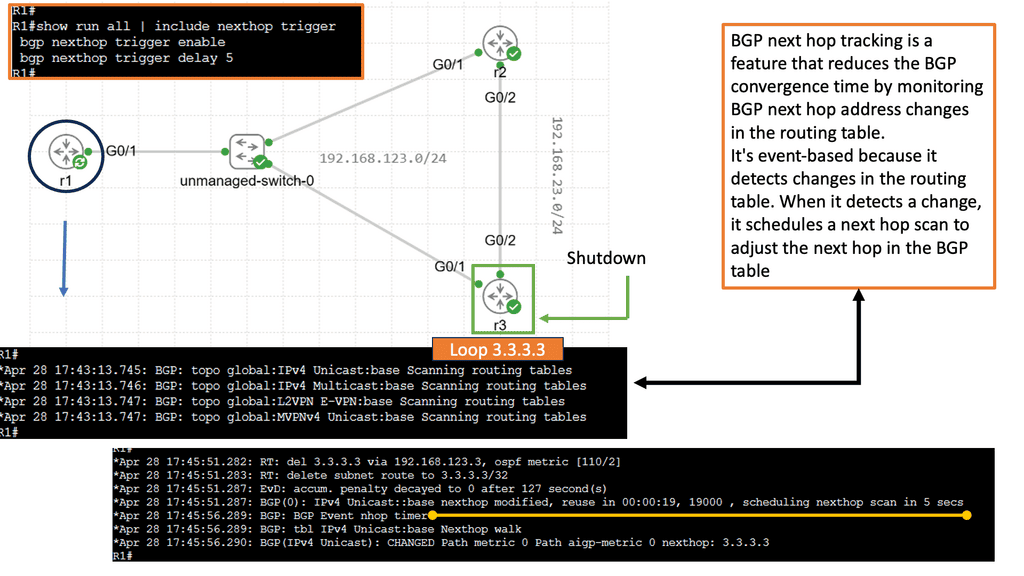
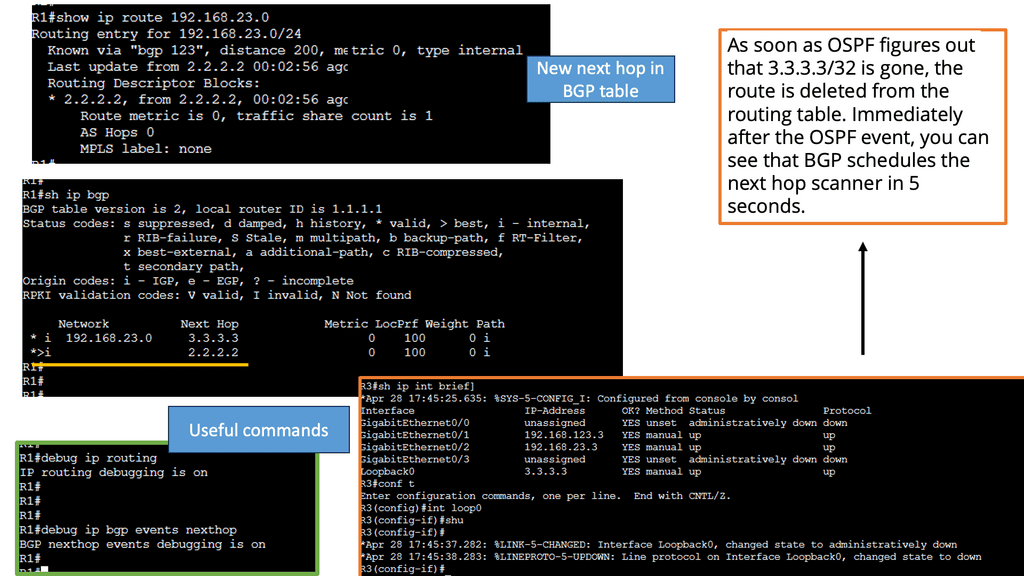
Example Technology: Fault Tolerance
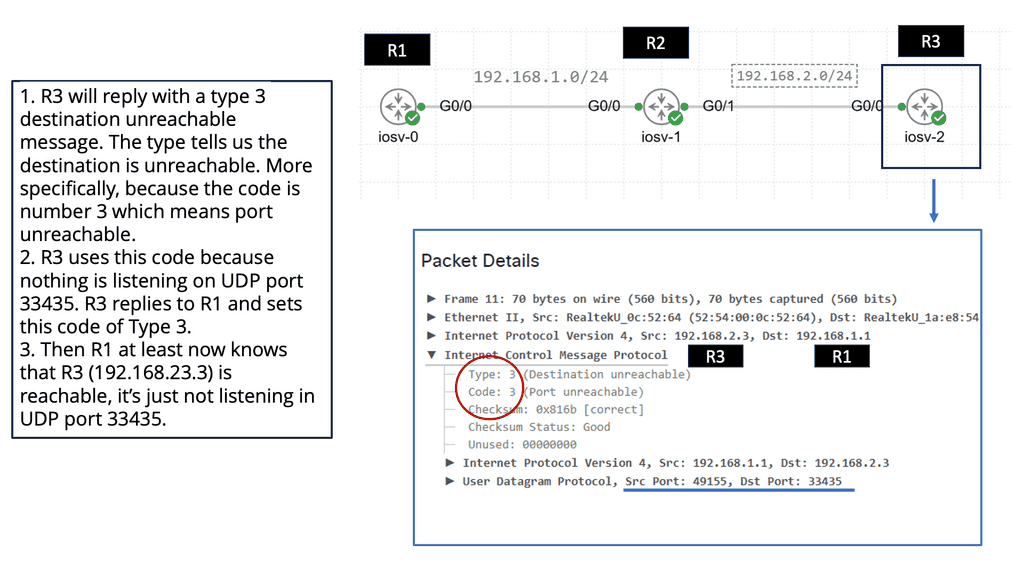
Fault tolerance is provided at the server level, within pools and farms. If the primary server(s) in the pool fails, the ADN activates a backup server automatically.
In case of a hardware or software failure, the ADN ensures application availability and reliability by seamlessly switching to a secondary device. In this way, traffic continues to flow even if one device fails, ensuring application fault tolerance. ADNs implement fault tolerance either through network connections or serial connections.
Failover based on the network.
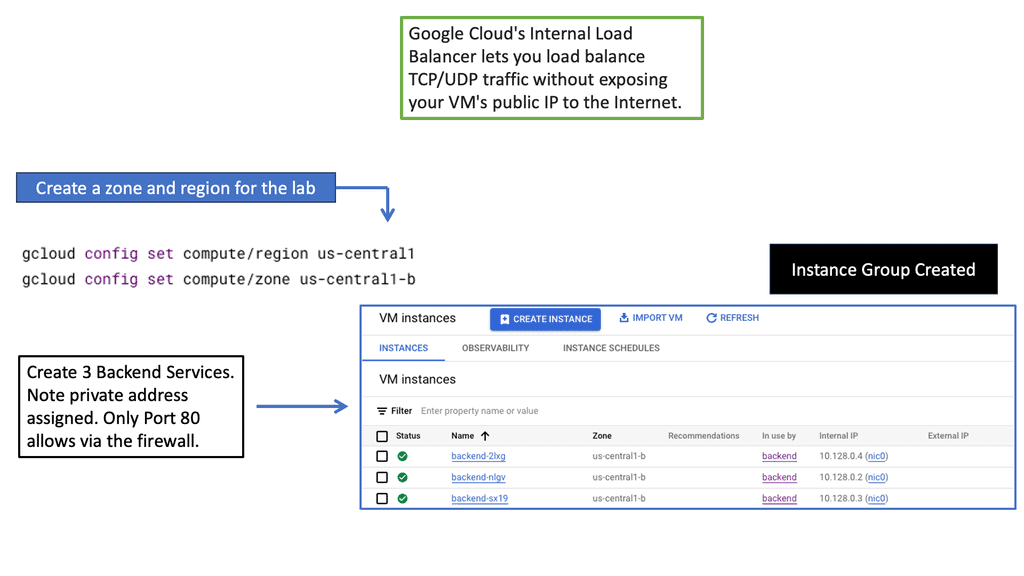
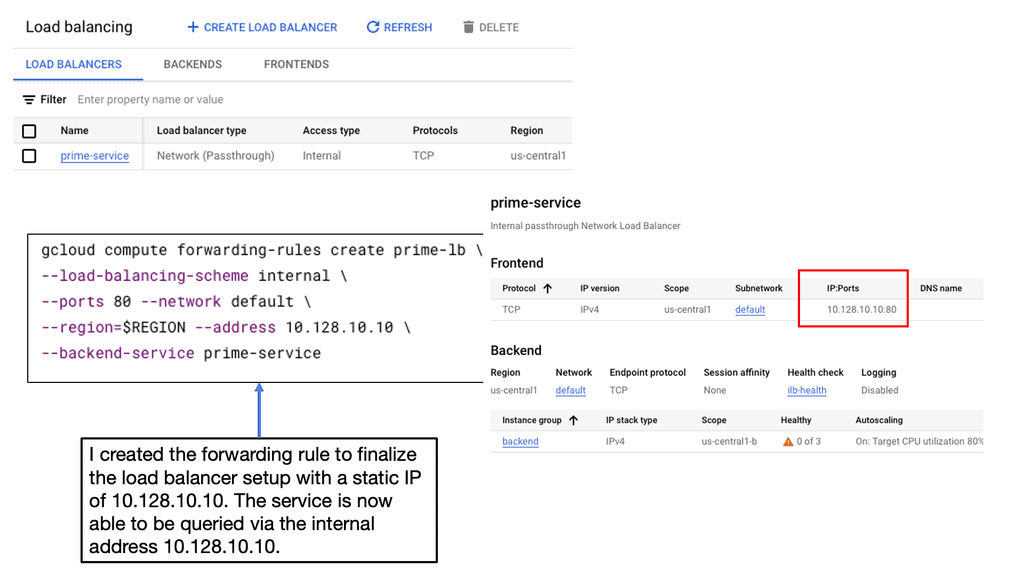
Two devices share a Virtual IP Address (VIP). A heartbeat daemon on the secondary device verifies the primary device to be active. If the heartbeat is lost, the secondary device takes over the VIP. Although most ADN replicate sessions from the primary to the secondary, this is not an immediate process, and there is no way to guarantee that sessions initiated before the secondary assumes the VIP will be maintained.Before you proceed, you may find the following useful:
A load balancer is a physical or virtual appliance that sits before your servers and routes client requests across all servers. A load balancer has a lot of additional capabilities that can fulfill those requests in a manner that maximizes speed and capacity utilization and ensures that no one server is overworked, which could degrade application performance.
It does all of this with a load balancer algorithm. Consider a load balancer to act as a reverse proxy and distribute network or application traffic across several servers. Load balancers increase applications’ capacity (concurrent users) and reliability.
High Availability and Low Latency
One of the critical components of application delivery architecture is the network infrastructure. A robust network infrastructure is essential for ensuring high availability and low latency. This involves deploying multiple data centers in geographically diverse locations, interconnected with high-speed links. Organizations can achieve improved performance, fault tolerance, and resilience by distributing application delivery across multiple data centers.
Load balancing is another critical aspect of application delivery architecture. It involves distributing network traffic across multiple servers to optimize resource utilization and ensure high availability. Load balancers act as intermediaries between the user and the application servers, intelligently routing requests to the most suitable server based on server load, response time, and server health. This helps to prevent any single server from becoming overwhelmed and ensures that applications are accessible and responsive.
Security is paramount
Security is a paramount concern in application delivery architecture. With increasing cyber threats, organizations must implement robust security measures to protect sensitive data and prevent unauthorized access. This includes implementing firewalls, intrusion detection systems, and encryption technologies to safeguard the application infrastructure and user data. Additionally, application delivery controllers can provide advanced security features such as web application firewalls and SSL/TLS termination to protect against common web-based attacks.
Scalability
Scalability is another important consideration in application delivery architecture. As user demand fluctuates, organizations must scale their application infrastructure accordingly to accommodate increasing traffic. This can be achieved through horizontal scaling, where additional servers are added to handle the increased load, or vertical scaling, which involves upgrading existing servers with more powerful hardware. By adopting a scalable architecture, organizations can ensure that their applications can handle peak traffic without compromising performance or user experience.
The Need for Application Delivery Architecture
Today’s application – less deterministic
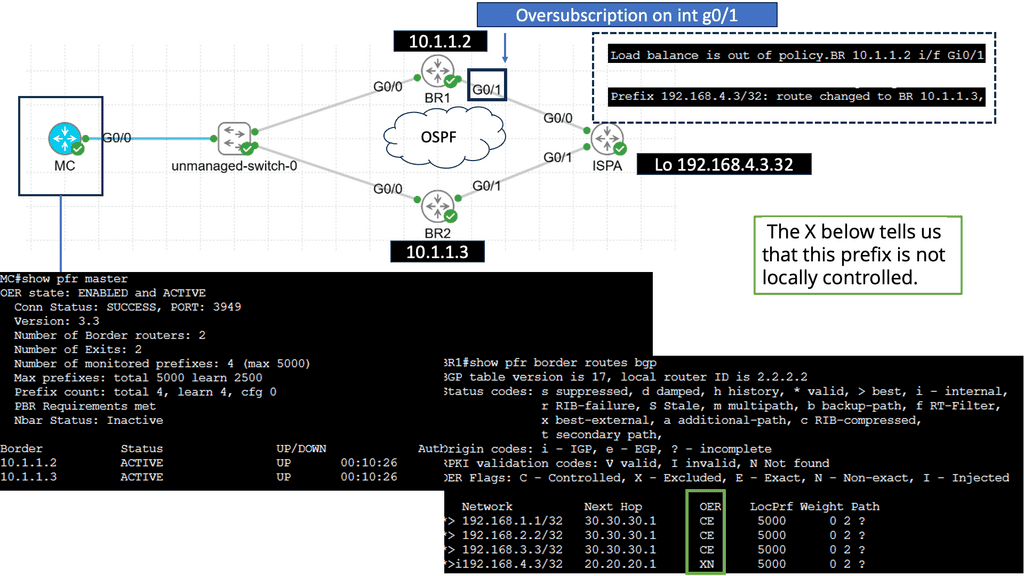
Application flows are becoming less deterministic, and architects can no longer rely on centralized appliances for efficient application delivery. Avi Networks overcome this problem by offering a scale-out application delivery controller. Avi describes their product as a cloud application delivery platform. The core of its technology is based on analyzing application and network telemetry.
From this information, the application delivery appliance can efficiently balance the load. The additional information gained from analytic gathering arms Avi networks against unpredictable application experiences and “Black Friday” events. Traditional load balancers route user requests or sessions to servers based on the request’s characteristics. Avi operates with the same principles and adds additional value by analyzing other telemetry parameters of request characteristics.
A lot has changed in the data center with emerging trends such as mobile and cloud. Customers are looking to redesign the data center with increasing user experience. As a result, the quality of user experience becomes increasingly unpredictable and inconsistent. Load balancers should be analytics-driven, but unfortunately, many enterprise customers do not have that type of network assessment. Avi networks aim to bring the enterprise the additional benefits of analytically driven load-balancing decisions.
Hyperscale application delivery: How does it work?
They offer a scalable load balancer; the critical point is that it is driven by analytics. It tracks real-time users, servers, and network telemetry and feeds all this information to databases that influence the application’s decision. Application visibility and load balancing are combined under one hood creating an elastic software load balancer.
In terms of scalability, if the application gets too many requests, it can spin up new virtual load balancers in VM format to deal with requests and additional loads. You do not have to provision upfront. This type of use case is ideal for “Black Friday” events. But you can see the load in advance since you are tracking the real-time analytics. They typically run in VM format, so you do not need additional hardware. Mid-sized companies are getting the same benefits as massive hyper-scale companies—an ideal solution for retail companies dealing with sporadic peak loads at random intervals.
Avi does not implement any caps on input. So, if you have a short period of high throughput, it is not capped – invoicing is backdated based on traffic peak events. In addition, Avi does not have controls to limit the appliance, so if you need additional capacity in the middle of the night, it will give it to you.
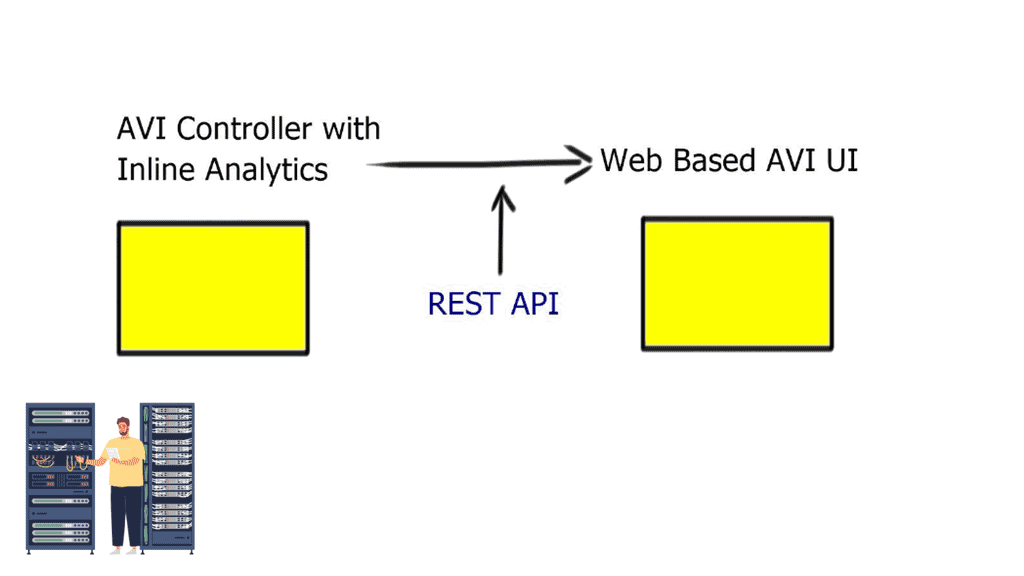
Control and Data Plane
If you want to deal with a scale-out architecture, you need a data plane that can scale out, too. Something must control that data plane, i.e., the control plane. So Avi consists of two components. The first component is the scale-out controller, which has a REST API. The second component is the Service Engine ( SE ).
SE is similar to an HTTP proxy. However, they are terminating one TCP session and opening a different session to the server, so you have to do Source NAT. Source NAT changes the source address in the IP header of a packet. It may also change the source port in the TCP/UDP headers.
With this method, the client IP addresses are Assigned to the load balancer’s local IP. This ensures that server responses go through the correct load-balancing device. However, it also hides the original client’s source IP address.
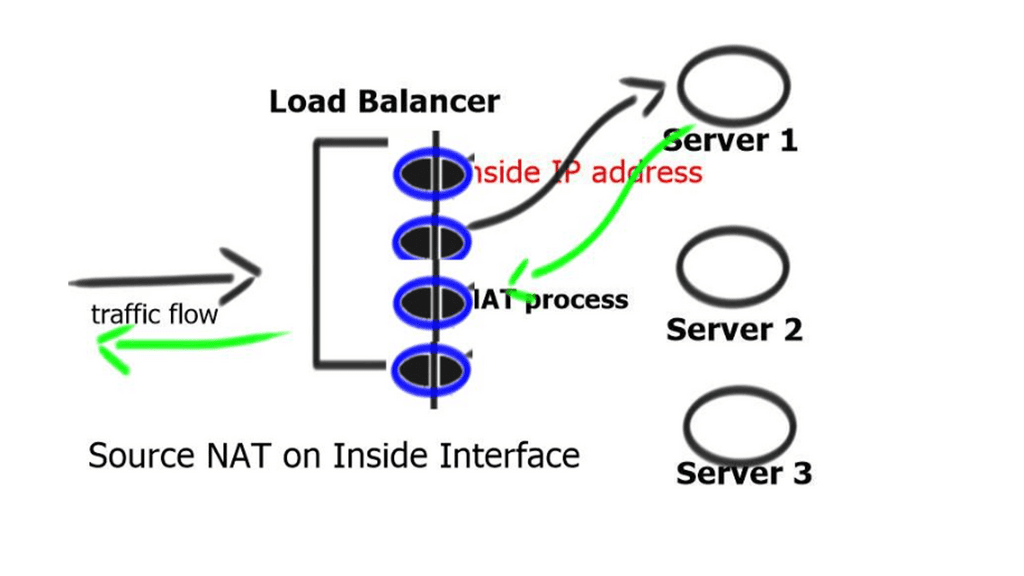
And since you are sitting at layer 7, you can intercept and do what you want with the HTTP headers. This is not a problem with an HTTP application as they can put the client IP in the HTTP header – X-Forwarded-For (XFF) HTTP header field. The XFF HTTP Header field is the de facto standard for identifying the originating client IP address that is connected to the web server via an HTTP proxy or load balancer. From this, you can tell who the source client is, and because they know the client telemetry, they can do various TCP optimizations for high latency links, high band links, low bandwidth, and low latency links.
The SE sites in the data plane provide essential load-balancing services. Depending on throughput requirements, you can have as many SEs as you want—up to 200. Potentially, you can carve up the SE into admin domains so that sure tenants can access an exact amount of SE regardless of network throughput.
SE assignments can be fixed or flexible. You can spin up the virtual machine for load-balancing services or have a certain VM per tenant. For example, the DEV test can have a couple of dedicated engines. It depends on the resources you want to dedicate.
Final Points: Application Delivery Networks (ADN)
To fully grasp ADA, it’s essential to understand its key components. These include load balancing, which distributes network traffic across multiple servers to ensure no single server becomes overwhelmed, and caching, which stores frequently accessed data closer to the user to speed up delivery times. Additionally, application performance monitoring tools play a vital role in identifying bottlenecks and optimizing performance.
Security is a cornerstone of any robust ADA strategy. With the increasing sophistication of cyber threats, integrating security measures such as firewalls, intrusion detection systems, and SSL encryption is crucial. These tools help protect sensitive data and maintain the integrity of applications throughout the delivery process.
Cloud computing has revolutionized the field of ADA by offering scalable resources and flexible deployment options. Leveraging cloud services allows organizations to adapt quickly to changing demands and enhance their application delivery capabilities without the need for significant on-premise infrastructure investments.