
– 1: Load balancing evenly distributes incoming network traffic across multiple servers, ensuring no single server is overwhelmed with excessive requests. By intelligently managing the workload, load balancing enhances applications’ or websites’ overall performance and availability. It acts as a traffic cop, directing users to different servers based on various algorithms and factors.
– 2: Load balancing evenly distributes incoming network traffic or computational workload across multiple resources, such as servers, to prevent any single resource from becoming overloaded. By distributing the workload, load balancing ensures that resources are utilized efficiently, minimizing response times and maximizing throughput.
**Types of Load Balancers**
There are several types of load balancers, each with its unique characteristics and advantages. Hardware load balancers are physical devices often used in large-scale data centers. They are known for their robustness and reliability. On the other hand, software load balancers are applications that can be installed on any server, offering flexibility and scalability. Finally, cloud-based load balancers have gained popularity due to their ability to adapt to varying loads and their seamless integration with cloud services.
**Benefits of Implementing Load Balancing**
The advantages of a well-implemented load balancing strategy are manifold. Firstly, it improves the availability and reliability of applications, ensuring that users can access services without interruption. Secondly, it enhances performance by reducing response times and optimizing resource utilization. Lastly, load balancing contributes to security by detecting and mitigating potential threats before they can impact the system.
**Challenges in Load Balancing**
Despite its benefits, load balancing is not without its challenges. Network administrators must carefully configure load balancers to ensure they distribute traffic effectively. Misconfigurations can lead to uneven loads and potential downtimes. Furthermore, as the digital landscape evolves, load balancers must adapt to new technologies and protocols, requiring ongoing maintenance and updates.
Example: Load Balancing with HAProxy
Understanding HAProxy
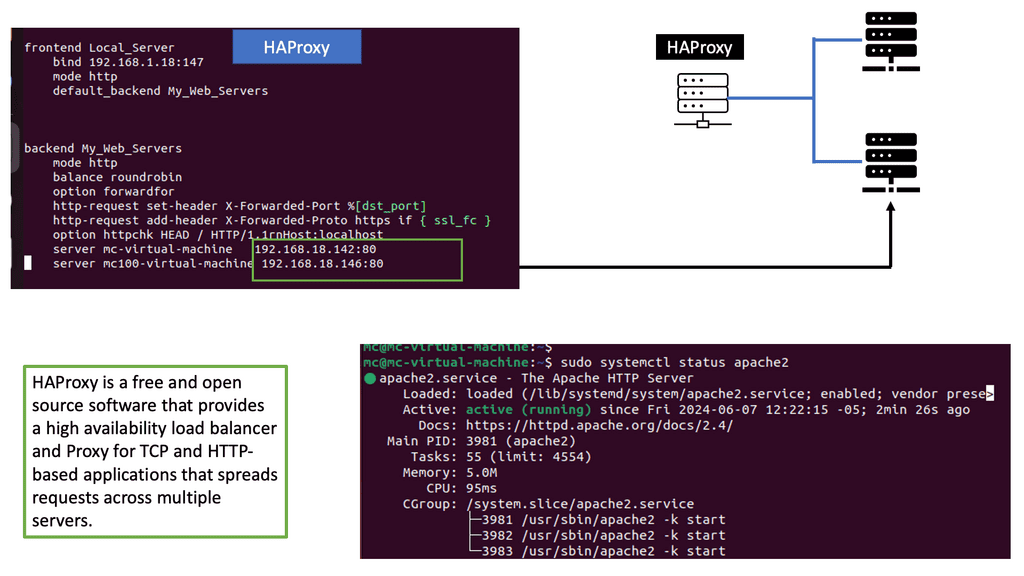
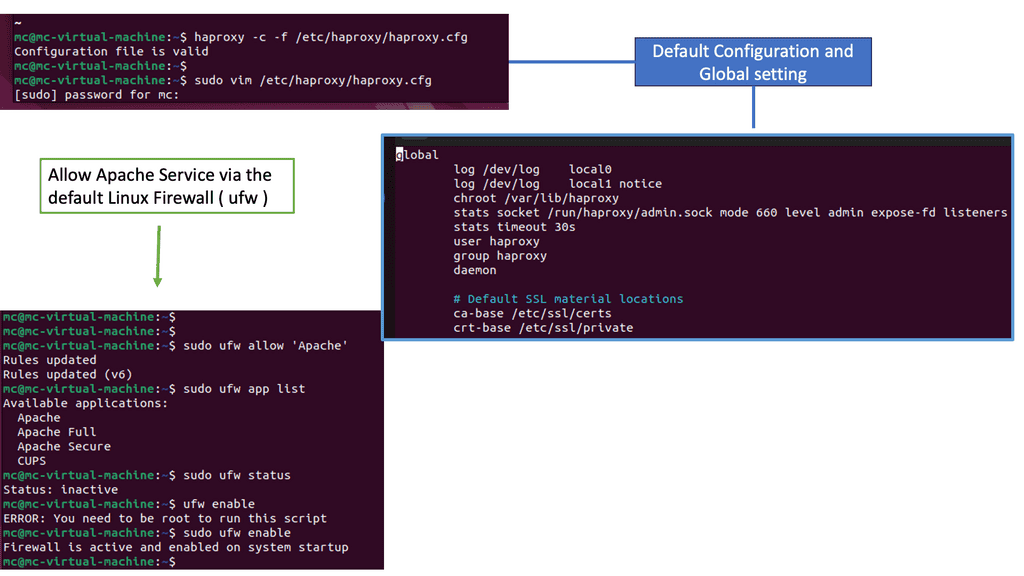
HAProxy, short for High Availability Proxy, is an open-source load balancer and proxy server solution. It acts as an intermediary between clients and servers, distributing incoming requests across multiple backend servers to ensure optimal performance and reliability. With its robust architecture and extensive configuration options, HAProxy is a versatile tool for managing and optimizing web traffic.
HAProxy offers a wide range of features that make it an ideal choice for handling web traffic. Some notable features include:
1. Load Balancing: HAProxy intelligently distributes incoming requests across multiple backend servers, ensuring optimal resource utilization and preventing overload.
2. SSL/TLS Termination: HAProxy can handle SSL/TLS encryption and decryption, offloading the processing burden from backend servers and improving overall performance.
3. Health Checks: HAProxy regularly monitors the health of backend servers, automatically removing or adding them based on their availability, ensuring seamless operation.
4. Content Switching: HAProxy can route requests based on different criteria such as URL, headers, cookies, or any other custom parameters, allowing for advanced content-based routing.
Exploring Scale-Out Architecture
Scale-out architecture, also known as horizontal scaling, involves adding more servers to a system to handle increasing workload. Unlike scale-up architecture, which involves upgrading existing servers, scale-out architecture focuses on expanding the resources horizontally. By distributing the workload across multiple servers, scale-out architecture enhances performance, scalability, and fault tolerance.
To implement load balancing and scale-out architecture, various approaches and technologies are available. One common method is to use a dedicated hardware load balancer, which offers advanced traffic management features and high-performance capabilities. Another option is to utilize software-based load balancing solutions, which can be more cost-effective and provide flexibility in virtualized environments. Additionally, cloud service providers often offer load balancing services as part of their infrastructure offerings.
Example: Understanding Squid Proxy
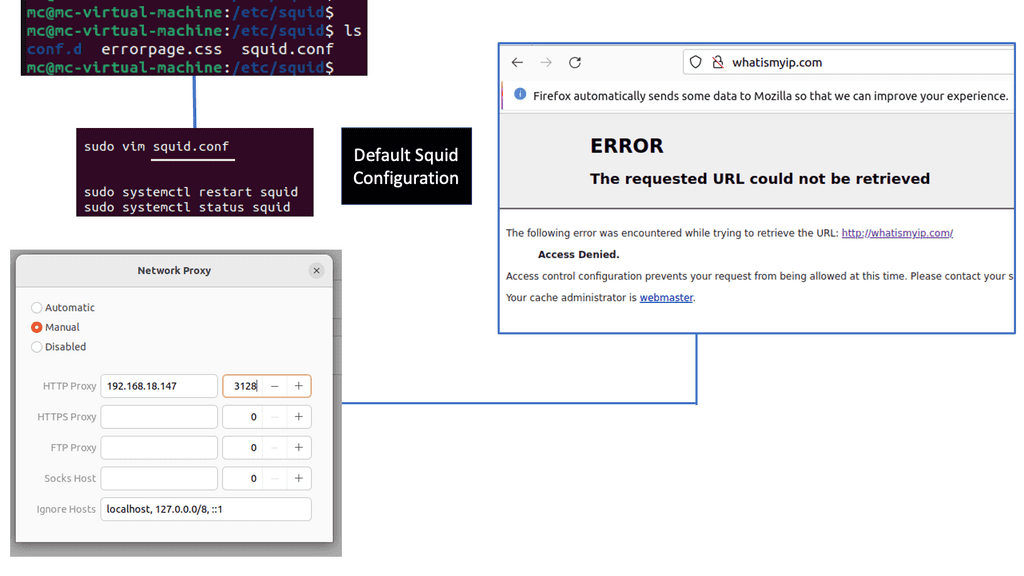
Squid Proxy is a widely used caching and forwarding HTTP web proxy server. It acts as an intermediary between the client and the server, providing enhanced security and performance. By caching frequently accessed web content, Squid Proxy reduces bandwidth usage and accelerates web page loading times.
Bandwidth Optimization: One of the key advantages of Squid Proxy is its ability to optimize bandwidth usage. By caching web content, Squid Proxy reduces the amount of data that needs to be fetched from the server, resulting in faster page loads and reduced bandwidth consumption.
Improved Security: Squid Proxy offers advanced security features, making it an ideal choice for organizations and individuals concerned about online threats. It can filter out malicious content, block access to potentially harmful websites, and enforce user authentication, ensuring a safer browsing experience.
Content Filtering and Access Control: With Squid Proxy, administrators can implement content filtering and access control policies. This allows for fine-grained control over the websites and content that users can access, making it an invaluable tool for parental controls, workplace enforcement, and compliance with regulatory requirements.

Load Balancing Algorithms
Various load-balancing algorithms are employed to distribute traffic effectively. Round Robin, the most common algorithm, cyclically assigns requests to resources sequentially. On the other hand, Weighted Round Robin assigns a higher weight to more powerful resources, enabling them to handle a more significant load. The Least Connections Algorithm also directs requests to the server with the fewest active connections, promoting resource utilization.
- Round Robin Load Balancing: Round-robin load balancing is a simple yet effective technique in which incoming requests are sequentially distributed across a group of servers. This method ensures that each server receives an equal workload, promoting fairness. However, it does not consider the actual server load or capacity, which can lead to uneven distribution in specific scenarios.
- Weighted Round Robin Load Balancing: Weighted round-robin load balancing improves the traditional round-robin technique by assigning weights to each server. This allows administrators to allocate more resources to higher-capacity servers, ensuring efficient utilization. By considering server capacities, weighted round-robin load balancing achieves a better distribution of incoming requests.
- Least Connection Load Balancing: Least connection load balancing dynamically assigns incoming requests to servers with the fewest active connections, ensuring an even workload distribution based on real-time server load. This technique is beneficial when server capacity varies, as it intelligently routes traffic to the least utilized resources, optimizing performance and preventing server overload.
- Layer 7 Load Balancing: Layer 7 load balancing operates at the application layer of the OSI model, making intelligent routing decisions based on application-specific data. This advanced technique considers factors such as HTTP headers, cookies, or URL paths, allowing for more granular load distribution. Layer 7 load balancing is commonly used in scenarios where different applications or services reside on the same set of servers.
Google Cloud Load Balancing
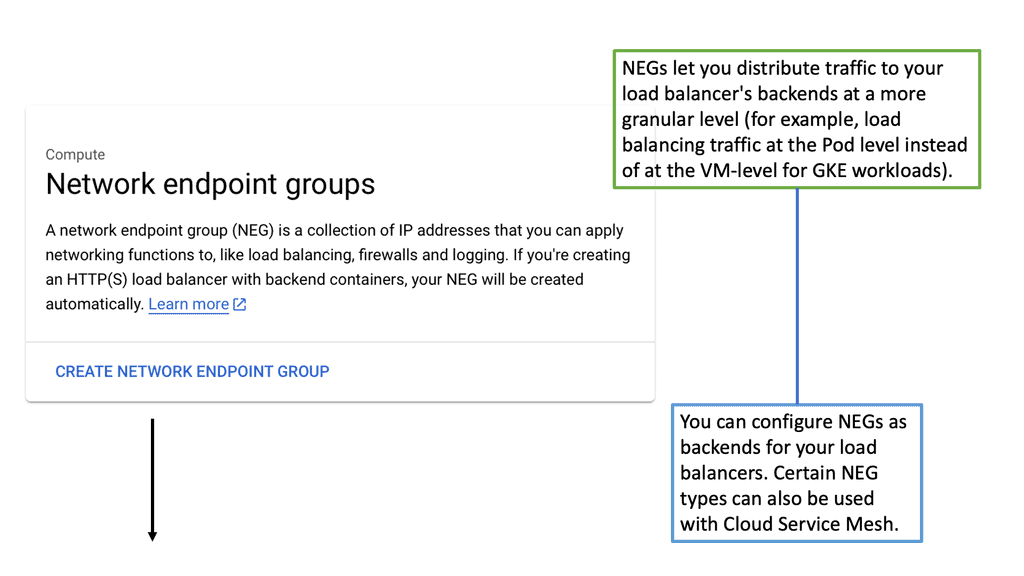
### Understanding the Basics of NEGs
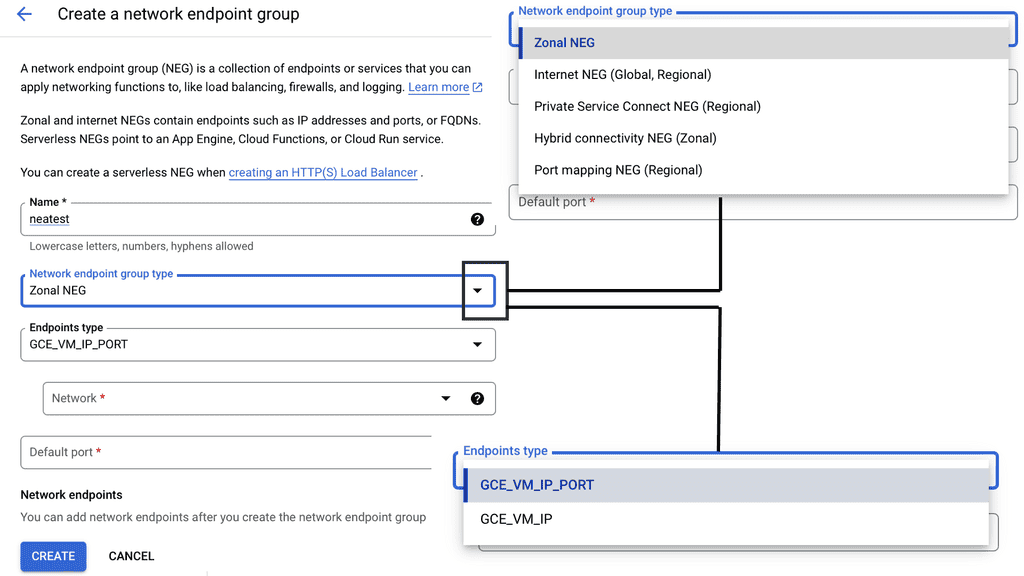
Network Endpoint Groups are essentially collections of IP addresses, ports, and protocols that define how traffic is directed to a set of endpoints. In GCP, NEGs can be either zonal or serverless, each serving a unique purpose. Zonal NEGs are tied to virtual machine (VM) instances within a specific zone, offering a way to manage traffic within a defined geographic area.
On the other hand, serverless NEGs are used to connect to serverless services, such as Cloud Run, App Engine, or Cloud Functions. By categorizing endpoints into groups, NEGs facilitate more granular control over network traffic, allowing for optimized load balancing and resource allocation.
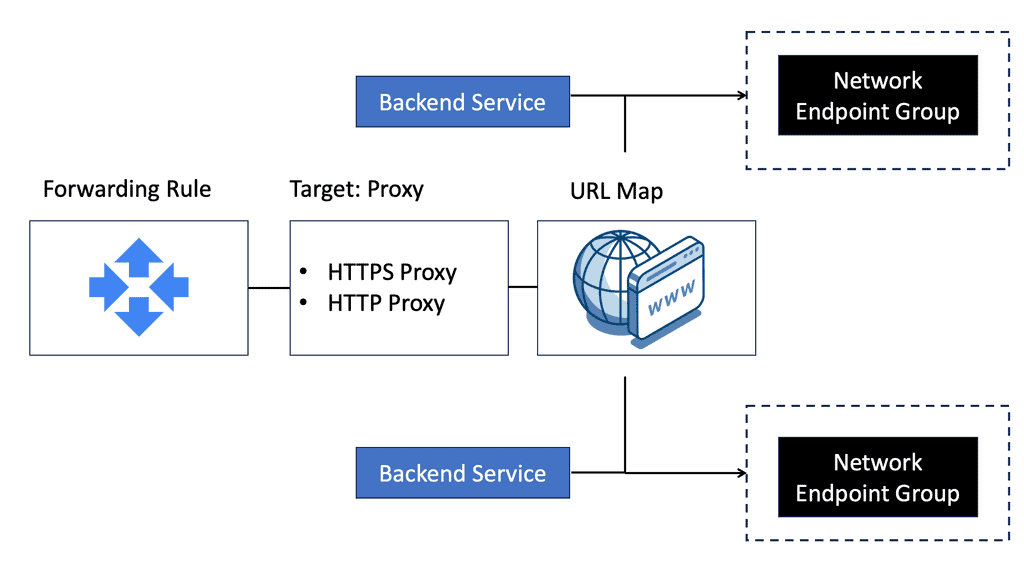
### The Role of NEGs in Load Balancing
One of the primary applications of NEGs is in load balancing, a critical component of network infrastructure that ensures efficient distribution of traffic across multiple servers. In GCP, NEGs enable sophisticated load balancing strategies by allowing users to direct traffic based on endpoint health, proximity, and capacity.
This flexibility ensures that applications remain responsive and resilient, even during peak traffic periods. By integrating NEGs with GCP’s load balancing services, businesses can achieve high availability and low latency, enhancing the user experience and maintaining uptime.
### Leveraging NEGs for Scalability and Flexibility
As businesses grow and evolve, so too do their network requirements. NEGs offer the scalability and flexibility needed to accommodate these changes without significant infrastructure overhauls. Whether expanding into new geographic regions or deploying new applications, NEGs provide a seamless way to integrate new endpoints and manage traffic. This adaptability is particularly beneficial for organizations leveraging hybrid or multi-cloud environments, where the ability to quickly adjust to changing demands is crucial.
### Best Practices for Implementing NEGs
Implementing NEGs effectively requires a thorough understanding of network architecture and strategic planning. To maximize the benefits of NEGs, consider the following best practices:
1. **Assess Traffic Patterns**: Understand your application’s traffic patterns to determine the optimal configuration for your NEGs.
2. **Monitor Endpoint Health**: Regularly monitor the health of endpoints within your NEGs to ensure optimal performance and reliability.
3. **Utilize Automation**: Take advantage of automation tools to manage NEGs and streamline operations, reducing the potential for human error.
4. **Review Security Protocols**: Implement robust security measures to protect the endpoints within your NEGs from potential threats.
By adhering to these practices, organizations can effectively leverage NEGs to enhance their network performance and resilience.
Google Managed Instance Groups
### Understanding Managed Instance Groups
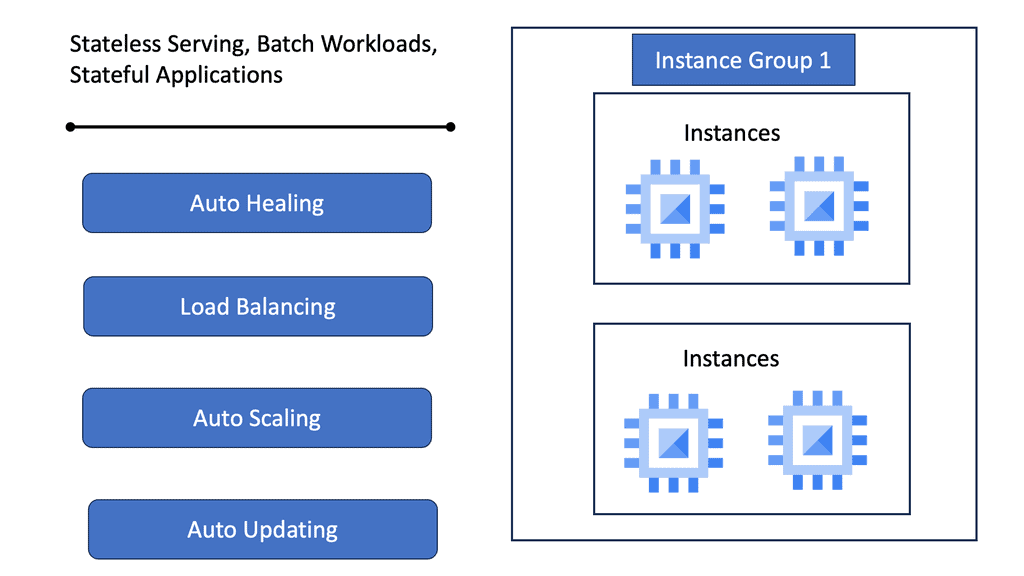
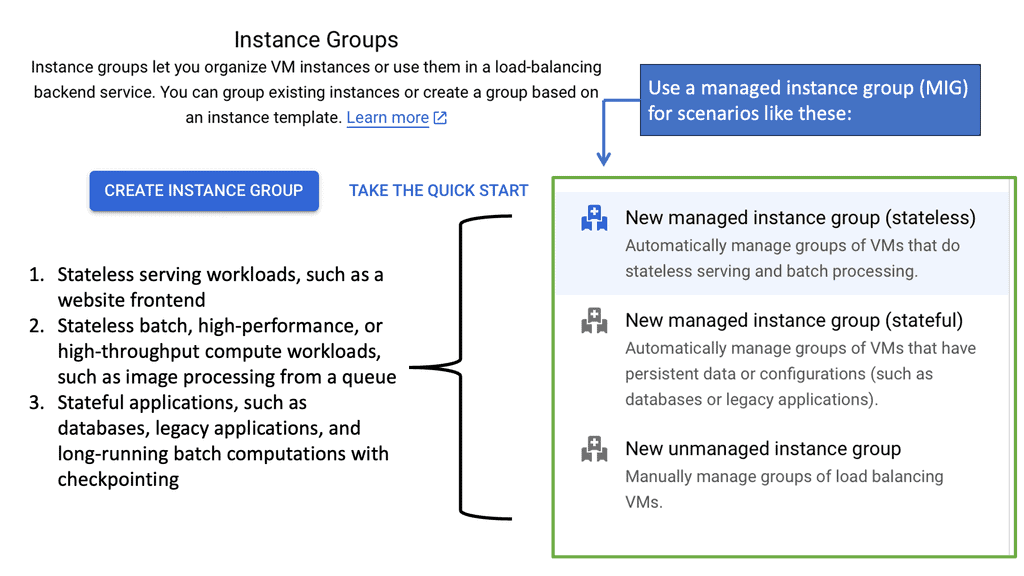
Managed Instance Groups (MIGs) are a powerful feature offered by Google Cloud, designed to simplify the management of virtual machine instances. MIGs allow developers and IT administrators to focus on scaling applications efficiently without getting bogged down by the complexities of individual instance management. By automating the creation, deletion, and management of instances, MIGs ensure that applications remain highly available and responsive to user demand.
### The Benefits of Using Managed Instance Groups
One of the primary advantages of using Managed Instance Groups is their ability to facilitate automated scaling. As your application demands increase or decrease, MIGs can automatically adjust the number of instances running, ensuring optimal performance and cost efficiency. Additionally, MIGs offer self-healing capabilities, automatically replacing unhealthy instances with new ones to maintain the overall integrity of the application. This automation reduces the need for manual intervention and helps maintain service uptime.
### Setting Up Managed Instance Groups on Google Cloud
Getting started with Managed Instance Groups on Google Cloud is straightforward. First, you’ll need to define an instance template, which specifies the configuration for the instances in your group. This includes details such as the machine type, boot disk image, and any startup scripts required. Once your template is ready, you can create a MIG using the Google Cloud Console or gcloud command-line tool, specifying parameters like the desired number of instances and the autoscaling policy.
### Best Practices for Using Managed Instance Groups
To make the most of Managed Instance Groups, it’s important to follow some best practices. Firstly, ensure that your instance templates are up-to-date and optimized for your application’s needs. Secondly, configure health checks to monitor the status of your instances, allowing MIGs to replace any that fail to meet your defined criteria. Lastly, regularly review your autoscaling policies to ensure they align with your application’s usage patterns, preventing unnecessary costs while maintaining performance.
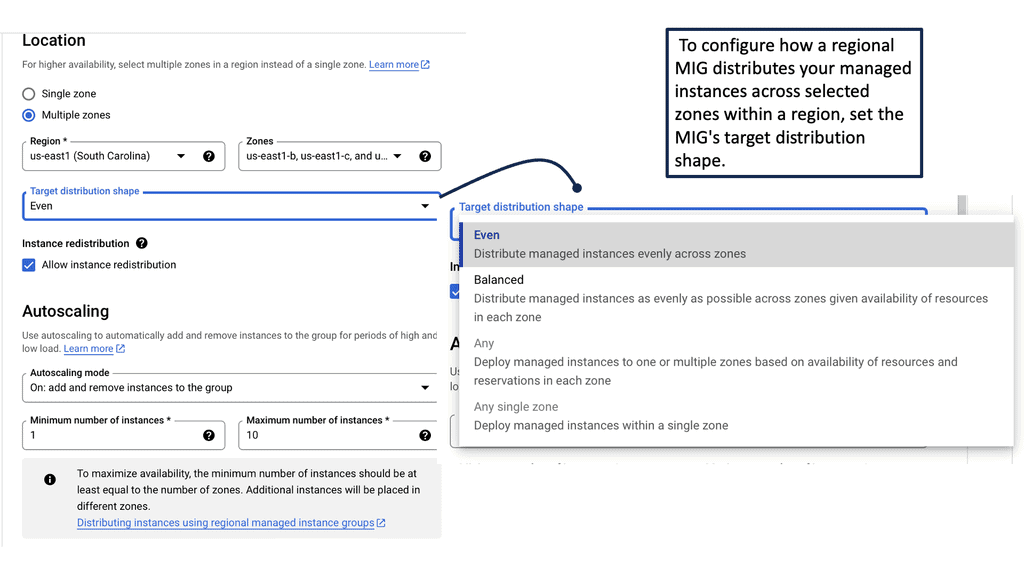
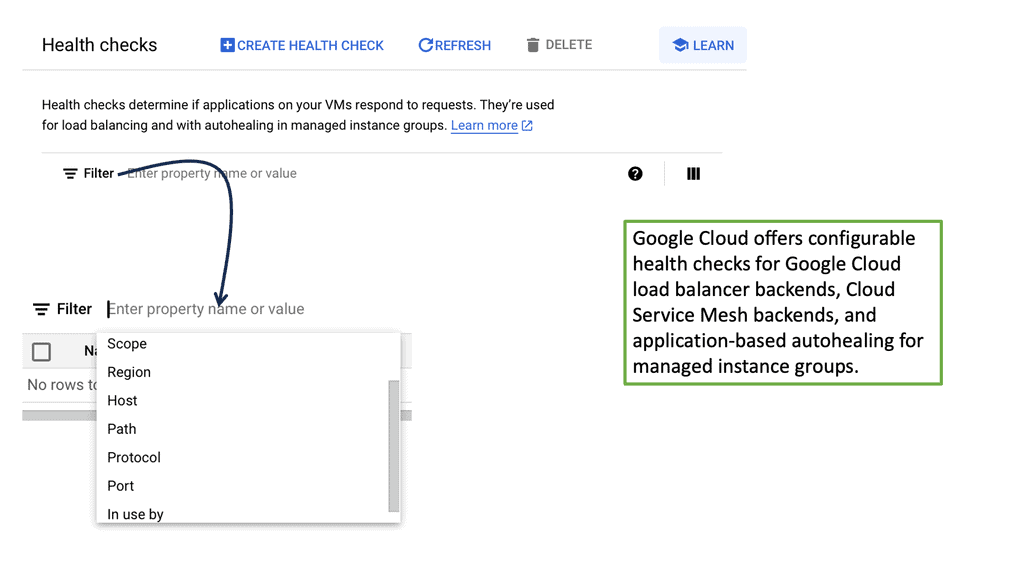
### What are Health Checks?
Health checks are automated tests that help determine the status of your servers in a load-balanced environment. These checks monitor the health of each server, ensuring that requests are only sent to servers that are online and functioning correctly. This not only improves the reliability of the application but also enhances user experience by minimizing downtime.
### Google Cloud and Its Approach
Google Cloud offers robust solutions for cloud load balancing, including health checks that are integral to its service. These checks can be configured to suit different needs, ranging from simple HTTP checks to more complex TCP and SSL checks. By leveraging Google Cloud’s health checks, businesses can ensure their applications are resilient and scalable.
### Types of Health Checks
There are several types of health checks available, each serving a specific purpose:
– **HTTP/HTTPS Checks:** These are used to test the availability of web applications. They send HTTP requests to the server and evaluate the response to determine server health.
– **TCP Checks:** These are used to test the connectivity of a server. They establish a TCP connection and check for a successful handshake.
– **SSL Checks:** These are similar to TCP checks but provide an additional layer of security by verifying the SSL handshake.
### Configuring Health Checks in Google Cloud
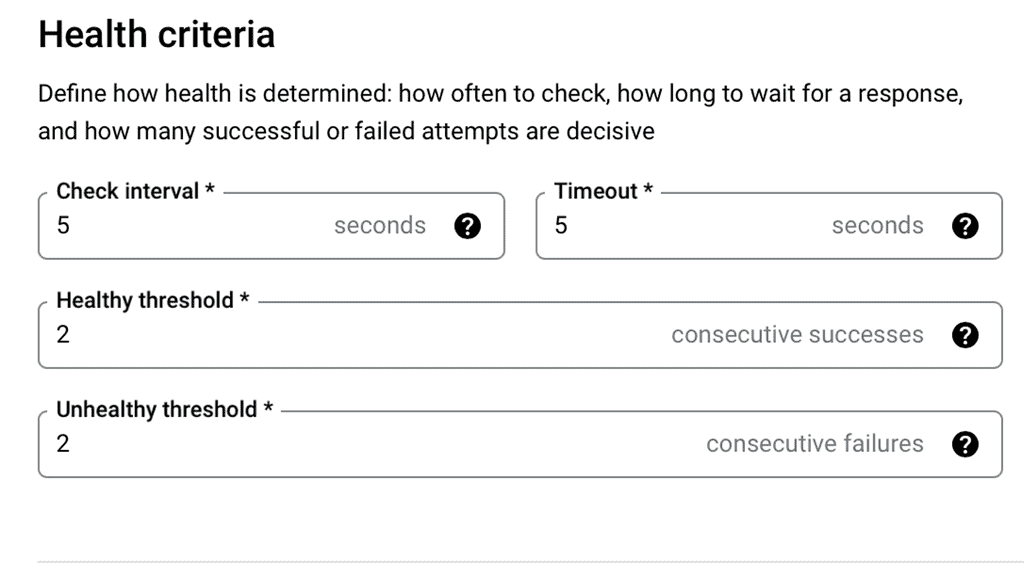
Setting up health checks in Google Cloud is straightforward. Users can access the Google Cloud Console, navigate to the load balancing section, and configure health checks based on their requirements. It’s essential to choose the appropriate type of health check and set parameters such as check interval, timeout, and threshold values to ensure optimal performance.

Cross-Region Load Balancing
Understanding Cross-Region Load Balancing
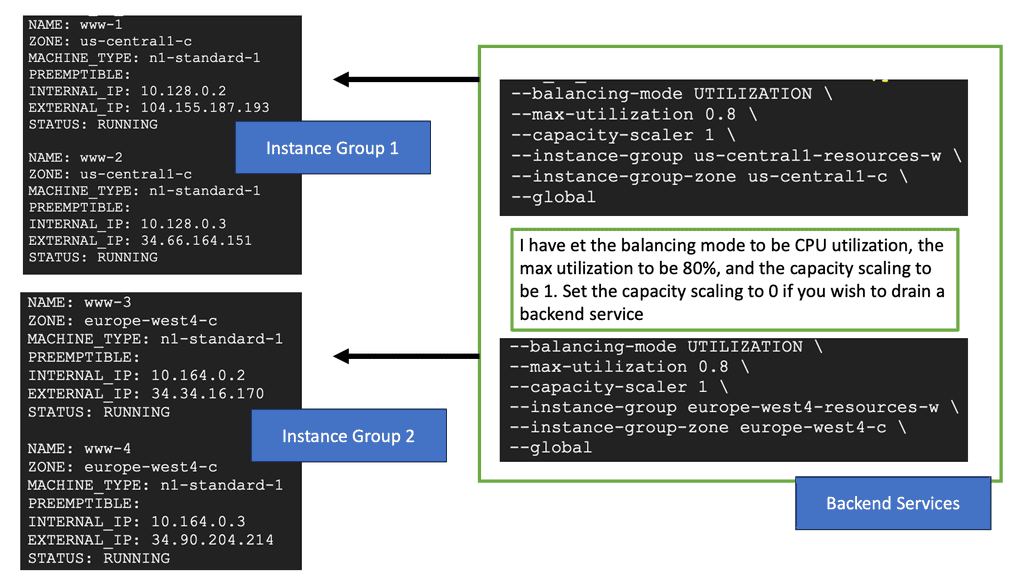
Cross-region load balancing allows you to direct incoming HTTP requests to the most appropriate server based on various factors such as proximity, server health, and current load. This not only enhances the user experience by reducing latency but also improves the system’s resilience against localized failures. Google Cloud offers powerful tools to set up and manage cross-region load balancing, enabling businesses to serve a global audience efficiently.
## Setting Up Load Balancing on Google Cloud
Google Cloud provides a comprehensive load balancing service that supports multiple types of traffic and protocols. To set up cross-region HTTP load balancing, you need to start by defining your backend services and health checks. Next, you configure the frontend and backend configurations, ensuring that your load balancer has the necessary information to route traffic correctly. Google Cloud’s intuitive interface simplifies these steps, allowing you to deploy a load balancer with minimal hassle.
## Best Practices for Effective Load Balancing
When implementing cross-region load balancing, several best practices can help optimize your configuration. Firstly, always use health checks to ensure that traffic is only routed to healthy instances. Additionally, make use of Google’s global network to minimize latency and ensure consistent performance. Regularly monitor your load balancer’s performance metrics to identify potential bottlenecks and adjust configurations as needed.
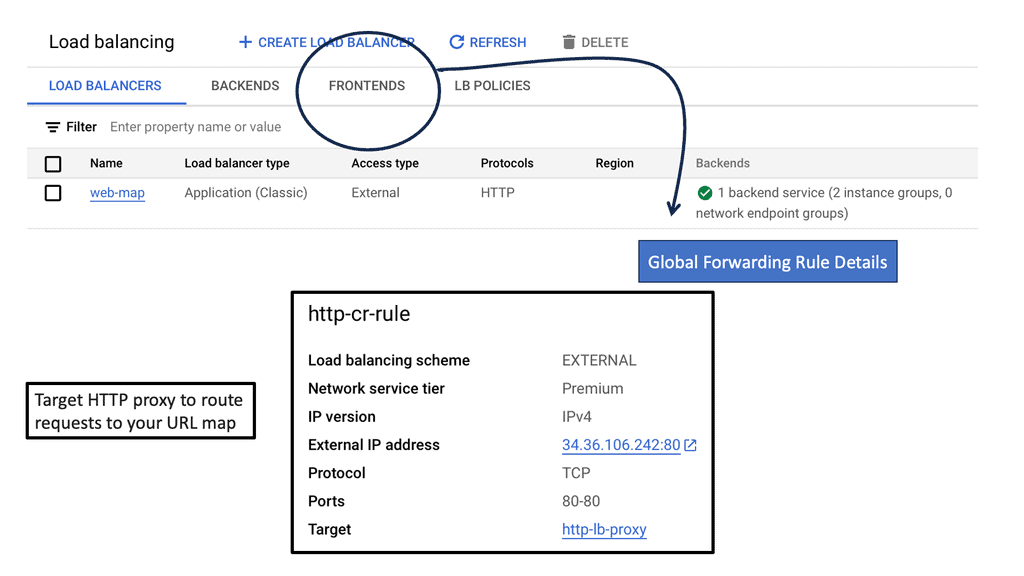
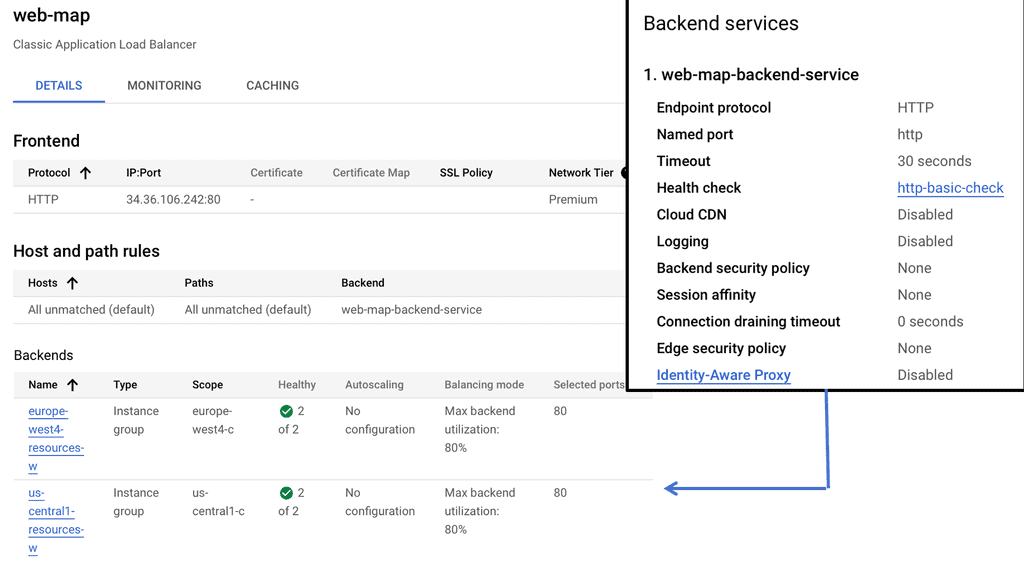
Distributing Load with Cloud CDN
Understanding Cloud CDN
Cloud CDN is a powerful content delivery network offered by Google Cloud Platform. It works by caching your website’s content across a distributed network of servers strategically located worldwide. This ensures that your users can access your website from a server closest to their geographical location, reducing latency and improving overall performance.
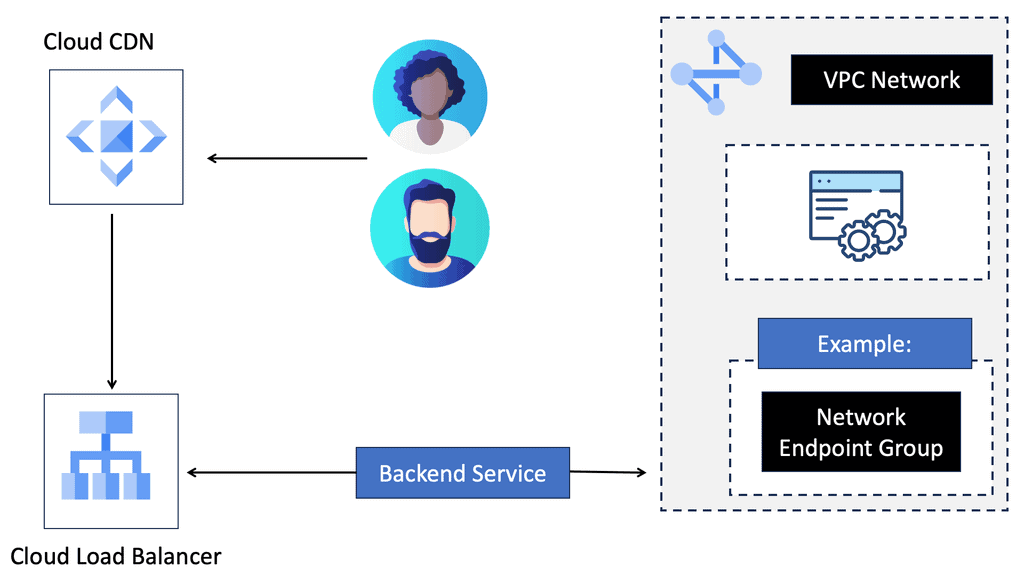
Accelerated Content Delivery: By caching static and dynamic content, Cloud CDN reduces the distance between your website and its users, resulting in faster content delivery times. This translates to improved page load speeds, reduced bounce rates, and increased user engagement.
Scalability and Global Reach: Google’s extensive network of CDN edge locations ensures that your content is readily available to users worldwide. Whether your website receives hundreds or millions of visitors, Cloud CDN scales effortlessly to meet the demands, ensuring a seamless user experience.
Integration with Google Cloud Platform: One of the remarkable advantages of Cloud CDN is its seamless integration with other Google Cloud Platform services. By leveraging Google Cloud Load Balancing, you can distribute traffic evenly across multiple backend instances while benefiting from Cloud CDN’s caching capabilities. This combination ensures optimal performance and high availability for your website.
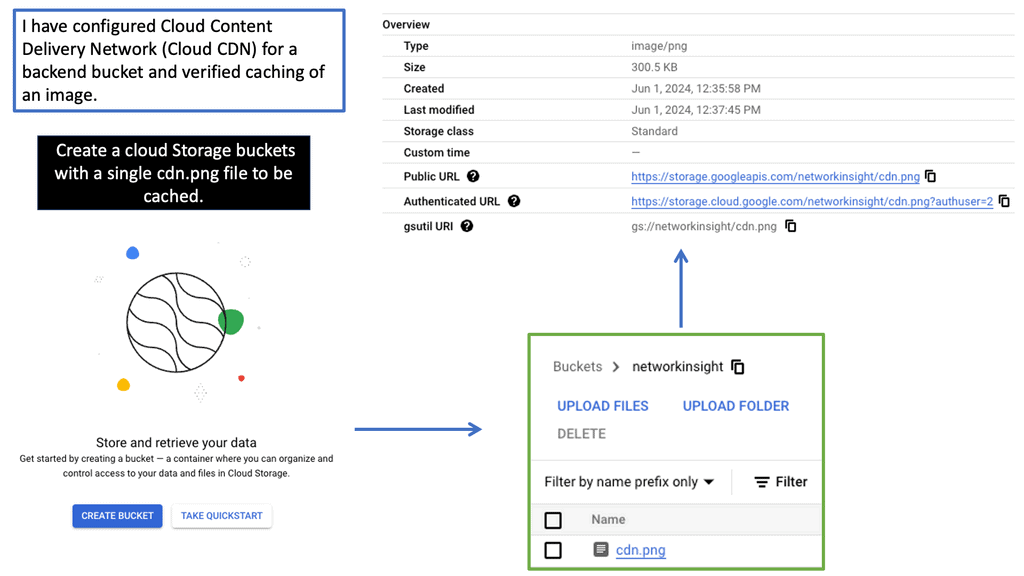
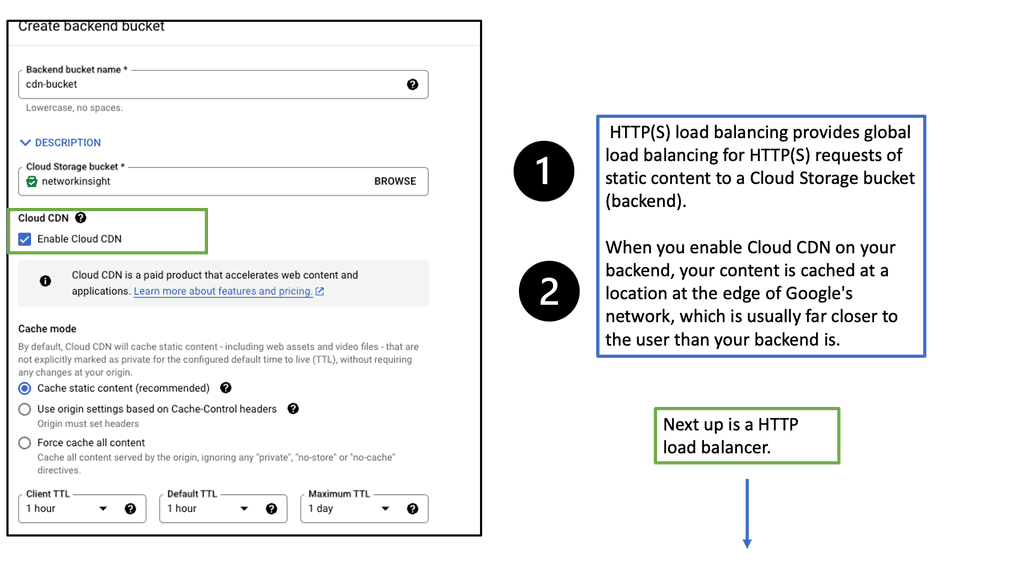
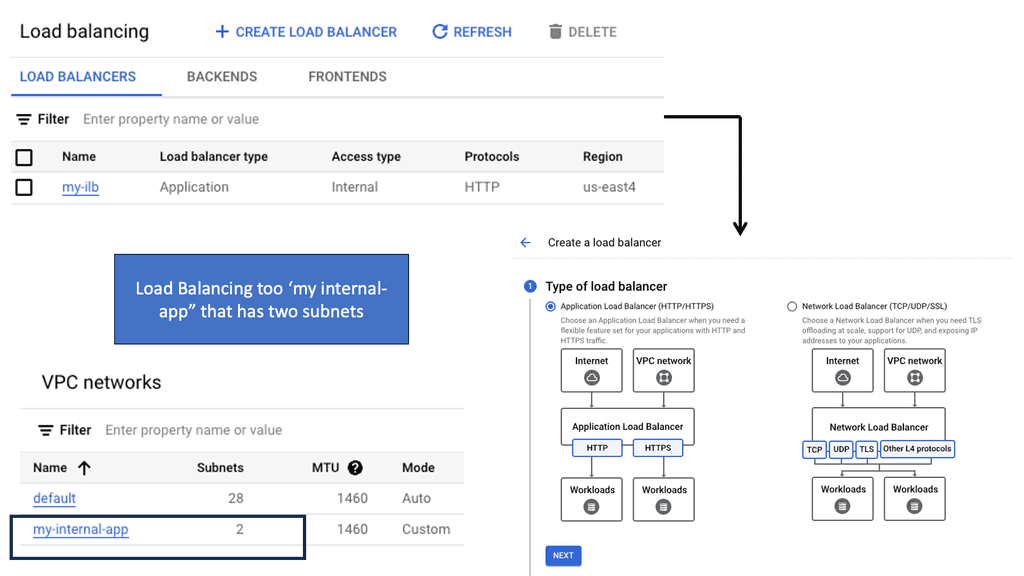
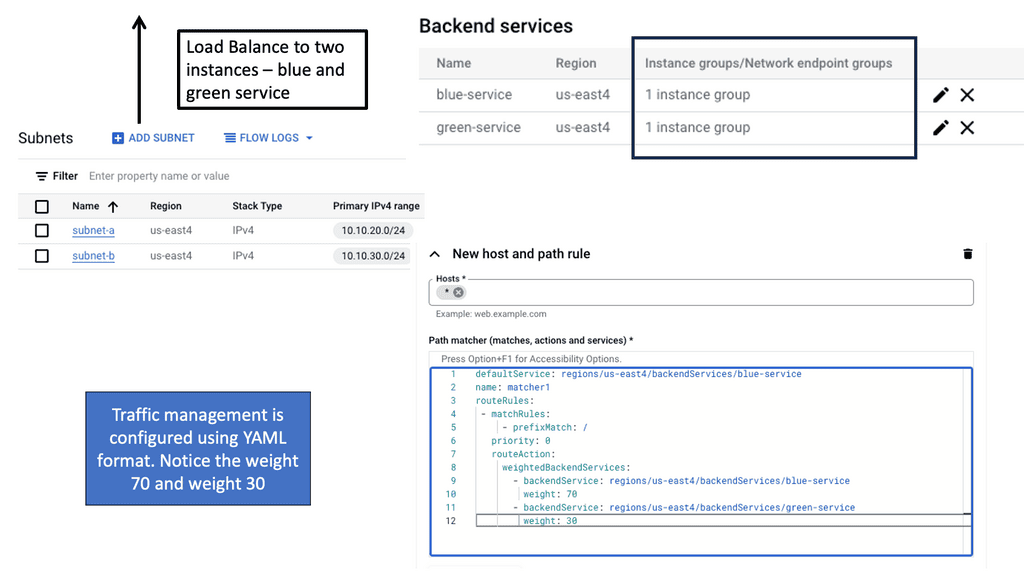
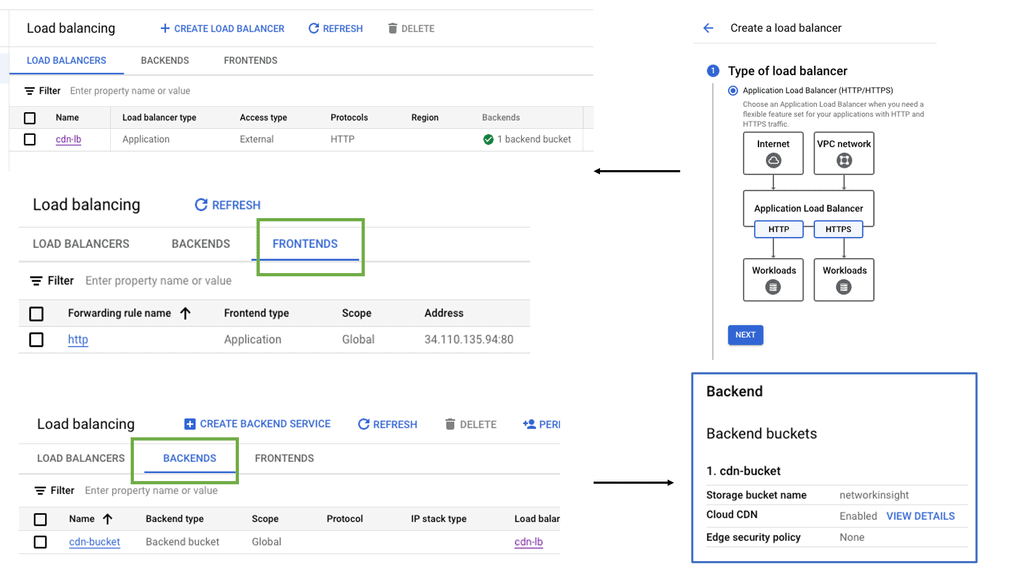 Regional Internal HTTP(S) Load Balancers
Regional Internal HTTP(S) Load Balancers
Regional Internal HTTP(S) Load Balancers provide a highly scalable and fault-tolerant solution for distributing traffic within a specific region in a Google Cloud environment. Designed to handle HTTP and HTTPS traffic, these load balancers intelligently distribute incoming requests among backend instances, ensuring optimal performance and availability.
Traffic Routing: Regional Internal HTTP(S) Load Balancers use advanced algorithms to distribute traffic across multiple backend instances evenly. This ensures that each instance receives a fair share of requests, preventing overloading and maximizing resource utilization.
Session Affinity: To maintain session consistency, these load balancers support session affinity, also known as sticky sessions. With session affinity enabled, subsequent requests from the same client are directed to the same backend instance, ensuring a seamless user experience.
Health Checking: Regional Internal HTTP(S) Load Balancers constantly monitor the health of backend instances to ensure optimal performance. If an instance becomes unhealthy, the load balancer automatically stops routing traffic to it, thereby maintaining the application’s overall stability and availability.
What is Cloud CDN?
Cloud CDN is a globally distributed CDN service offered by Google Cloud. It works by caching static and dynamic content from your website on Google’s edge servers, which are strategically located worldwide. When a user requests content, Cloud CDN delivers it from the nearest edge server, reducing latency and improving load times.
Scalability and Global Reach: Cloud CDN leverages Google’s extensive network infrastructure, ensuring scalability and global coverage. With a vast number of edge locations worldwide, your content can be quickly delivered to users, regardless of their geographical location.
Performance Optimization: By caching your website’s content at the edge, Cloud CDN reduces the load on your origin server, resulting in faster response times. It also helps minimize the impact of traffic spikes, ensuring consistent performance even during peak usage periods.
Cost Efficiency: Cloud CDN offers cost-effective pricing models, allowing you to optimize your content delivery expenses. You pay only for the data transfer and cache invalidation requests, making it an economical choice for websites of all sizes.
Cloud CDN seamlessly integrates with Google Cloud Load Balancing, providing an enhanced and robust content delivery solution. Load Balancing distributes incoming traffic across multiple backend instances, while Cloud CDN caches and delivers content to users efficiently.
Additional Performance Techniques
What are TCP Performance Parameters?
TCP (Transmission Control Protocol) is a fundamental communication protocol in computer networks. TCP performance parameters refer to various settings and configurations that govern the behavior and efficiency of TCP connections. These parameters can be adjusted to optimize network performance based on specific requirements and conditions.
1) – Window Size: The TCP window size determines the amount of data a receiver can accept before sending an acknowledgment. Adjusting the window size can impact throughput and response time, striking a balance between efficient data transfer and congestion control.
2) – Maximum Segment Size (MSS): The MSS defines the maximum amount of data transmitted in a single TCP segment. Optimizing the MSS can enhance network performance by reducing packet fragmentation and improving data transfer efficiency.
3) – Congestion Window (CWND): CWND regulates the amount of data a sender can transmit without receiving acknowledgment from the receiver. Properly tuning the CWND can prevent network congestion and ensure smooth data flow.
4) – Bandwidth-Delay Product (BDP): BDP represents the amount of data in transit between the sender and receiver at any given time. Calculating BDP helps determine optimal TCP performance settings, including window size and congestion control.
5) – Delay-Based Parameter Adjustments: Specific TCP performance parameters, such as the retransmission timeout (RTO) and the initial congestion window (ICW), can be adjusted based on network delay characteristics. Fine-tuning these parameters can improve overall network responsiveness.
6) – Network Monitoring Tools: Network monitoring tools allow real-time monitoring and analysis of TCP performance parameters. These tools provide insights into network behavior, helping identify bottlenecks and areas for optimization.
7) – Performance Testing: Conducting performance tests by simulating different network conditions can help assess the impact of TCP parameter adjustments. This enables network administrators to make informed decisions and optimize TCP settings for maximum efficiency.
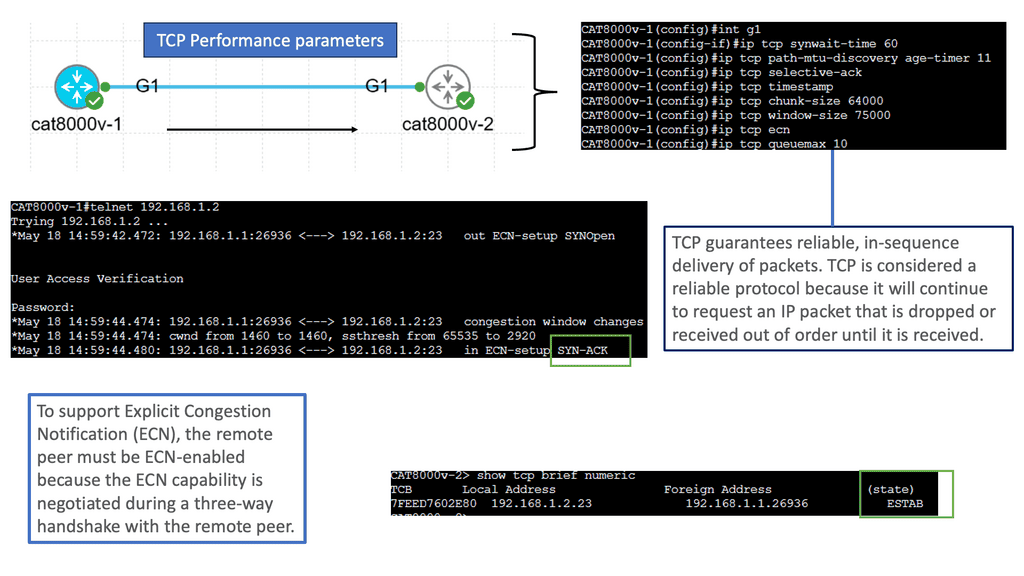
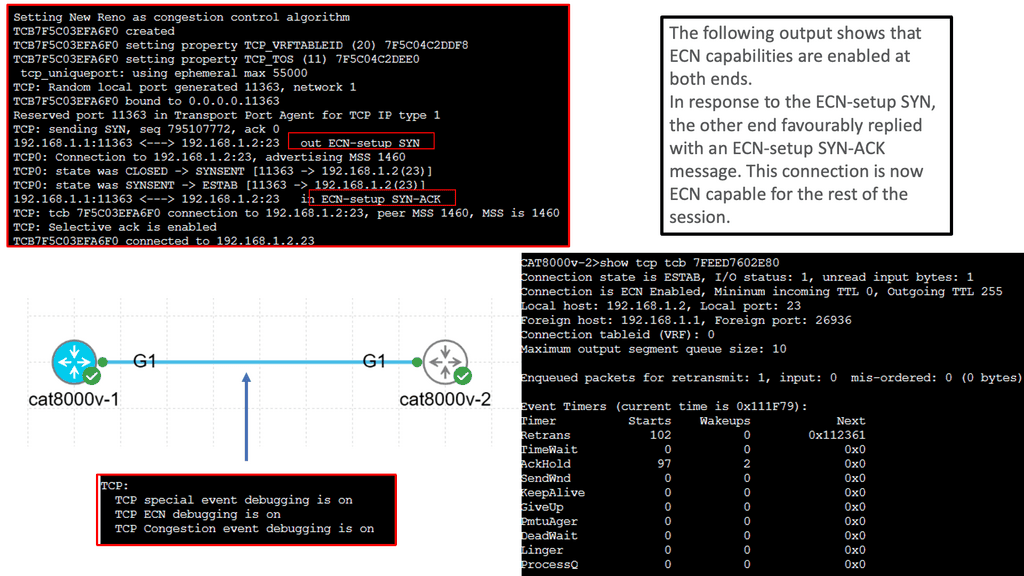
Understanding TCP MSS
TCP MSS refers to the maximum amount of data encapsulated in a single TCP segment. It plays a vital role in determining data transmission efficiency across networks. By limiting the segment size, TCP MSS ensures that data packets fit within the underlying network’s Maximum Transmission Unit (MTU), preventing fragmentation and reducing latency.
Various factors influence the determination of TCP MSS. One crucial aspect is the MTU size of the network path between the source and the destination. Additionally, network devices, such as routers and firewalls, can affect the MSS, which might have MTU limitations. Considering these factors while configuring the TCP MSS for optimal performance is essential.
Configuring the TCP MSS requires adjusting the settings on both communication ends. The sender and receiver need to agree on a mutually acceptable MSS value. This can be achieved through negotiation during the TCP handshake process. Different operating systems and network devices may have different default MSS values. Understanding the specific requirements of your network environment is crucial for effective configuration.
Optimizing TCP MSS can yield several benefits for network performance. Ensuring that TCP segments fit within the MTU minimizes fragmentation, reducing the need for packet reassembly. This leads to lower latency and improved overall throughput. Optimizing TCP MSS can also enhance bandwidth utilization efficiency, allowing for faster data transmission across the network.

Load Balancer Types
Load balancers can be categorized into two main types: hardware load balancers and software load balancers. Hardware load balancers are dedicated devices designed to distribute traffic, while software load balancers are implemented as software applications or virtual machines. Each type has advantages and considerations, including cost, scalability, and flexibility.
A. Hardware Load Balancers:
Hardware load balancers are physical devices dedicated to distributing network traffic. They often come with advanced features like SSL offloading, session persistence, and health monitoring. While they offer exceptional performance and scalability, they can be costly and require specific expertise for maintenance.
B. Software Load Balancers:
Software load balancers are applications or modules that run on servers, effectively utilizing the server’s resources. They are flexible and easily configurable, making them a popular choice for small to medium-sized businesses. However, their scalability may be limited compared to hardware load balancers.
C. Virtual Load Balancers:
Virtual load balancers are software-based instances that run on virtual machines or cloud platforms. They offer the advantages of software load balancers while providing high scalability and easy deployment in virtualized environments. Virtual load balancers are a cost-effective solution for organizations leveraging cloud infrastructure.
In computing, you’ll do something similar. Your website receives many requests, which puts a lot of strain on it. There’s nothing unusual about having a website, but if no one visits it, there is no point in having one.
You run into problems when your server is overloaded with people turning on their appliances. At this point, things can go wrong; if too many people visit your site, your performance will suffer. Slowly, as the number of users increases, it will become unusable. That’s not what you wanted.
The solution to this problem lies in more resources. The choice between scaling up and scaling out depends on whether you want to replace your current server with a larger one or add another smaller one.
The scaling-up process
Scaling up is quite common when an application needs more power. The database may be too large to fit in memory, the disks are full, or more requests are causing the database to require more processing power.
Scaling up is generally easy because databases have historically had severe problems when run on multiple computers. If you try to make things work on various machines, they fail. What is the best method for sharing tables between machines? This problem has led to the development of several new databases, such as MongoDB and CouchDB.
However, it can be pretty expensive to scale up. A server’s price usually increases when you reach a particular specification. A new type of processor (that looks and performs like the previous one but costs much more than the old one) comes with this machine, a high-spec RAID controller, and enterprise-grade disks. Scaling up might be cheaper than scaling out if you upgrade components, but you’ll most likely get less bang for your buck this way. Nevertheless, if you need a couple of extra gigabytes of RAM or more disk space or if you want to boost the performance of a particular program, this might be the best option.
Scaling Out
Scaling out refers to having more than one machine. Scaling up has the disadvantage that you eventually reach an impossible limit. A machine can’t hold all the processing power and memory it needs. If you need more, what happens?
If you have a lot of visitors, people will say you’re in an envious position if a single machine can’t handle the load. As strange as it may sound, this is a good problem! Scaling out means you can add machines as you go. You’ll run out of space and power at some point, but scaling out will undoubtedly provide more computing power than scaling up.
Scaling out also means having more machines. Therefore, if one machine fails, other machines can still carry the load. Whenever you scale up, if one machine fails, it affects everything else.
There is one big problem with scaling out. You have three machines and a single cohesive website or web application. How can you make the three machines work together to give the impression of one machine? It’s all about load balancing!
Finally, load balancing
Now, let’s get back to load balancing. The biggest challenge in load balancing is making many resources appear as one. How can you make three servers look and feel like a single website to the customer?
How does the Web work?
This journey begins with an examination of how the Web functions. Under the covers of your browser, what happens when you click Go? The book goes into great detail, even briefly discussing the TCP (Transmission Control Protocol) layer.
While someone might be able to make an awe-inspiring web application, they may not be as familiar with the lower-level details that make it all function.
Fortunately, this isn’t an issue since kickass software doesn’t require knowledge of the Internet’s inner workings. It would be best to have a much better understanding of how it works to make your software quickly pass the competition.
**Challenge: Lack of Visibility**
Existing service provider challenges include a lack of network visibility into customer traffic. They are often unaware of the granular details of traffic profiles, leading them to over-provision bandwidth and link resilience. There are a vast amount of over-provisioned networks. Upgrades at a packet and optical layer occur without complete traffic visibility and justification. Many core networks are left at half capacity, just in a spike. Money is wasted on underutilization that could be spent on product and service innovation. You might need the analytical information for many reasons, not just bandwidth provisioning.
**Required: Network Analytics**
Popular network analytic capability tools are sFlow and NetFlow. Nodes capture and send sFlow information to a sFlow collector, where the operator can analyze it with the sFlow collector’s graphing and analytical tools. An additional tool that can be used is a centralized SDN controller, such as an SD-WAN Overlay, that can analyze the results and make necessary changes to the network programmatically. A centralized global viewpoint enabling load balancing can aid in intelligent multi-domain Traffic Engineering (TE) decisions.
Load Balancing with Service Mesh
### How Service Mesh Enhances Microservices
Microservices architecture breaks down applications into smaller, manageable services that can be independently deployed and scaled. However, this complexity introduces challenges in communication, monitoring, and security. A cloud service mesh addresses these issues by providing a dedicated layer for facilitating, managing, and orchestrating service-to-service communication.
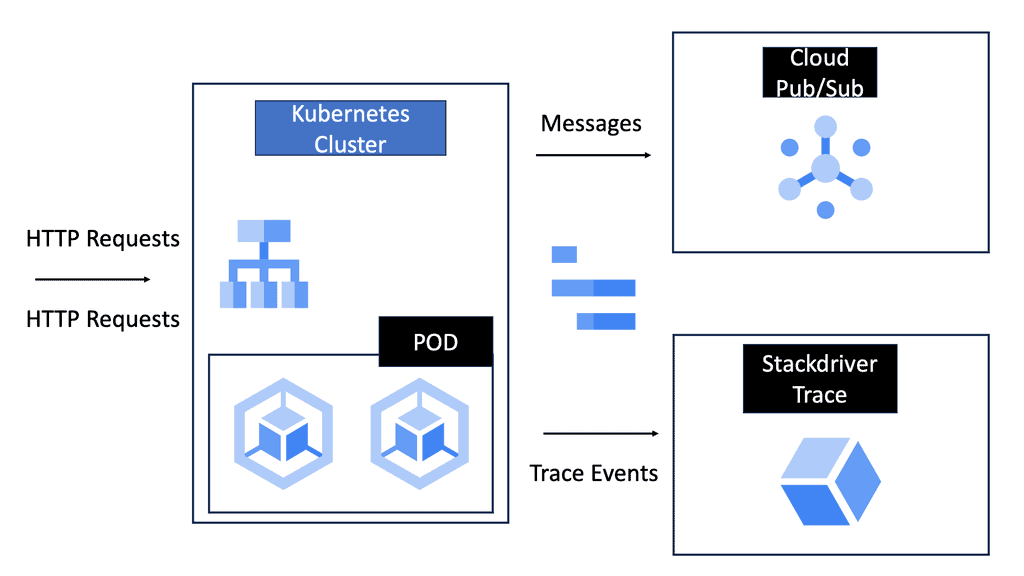
### The Role of Load Balancing in a Service Mesh
One of the most significant features of a cloud service mesh is its ability to perform load balancing. Load balancing ensures that incoming traffic is distributed evenly across multiple servers, preventing any single server from becoming a bottleneck. This not only improves the performance and reliability of applications but also enhances user experience by reducing latency and downtime.


### Security and Observability
Security is paramount in any networked system, and a cloud service mesh significantly enhances it. By implementing mTLS (mutual Transport Layer Security), a service mesh encrypts communications between services, ensuring data integrity and confidentiality. Additionally, a service mesh offers observability features, such as tracing and logging, which provide insights into service behavior and performance, making it easier to identify and resolve issues.
### Real-World Applications
Many industry giants have adopted cloud service mesh technologies to streamline their operations. For instance, companies like Google and Netflix utilize service meshes to manage their vast array of microservices. This adoption underscores the importance of service meshes in maintaining seamless, efficient, and secure communication pathways in complex environments.

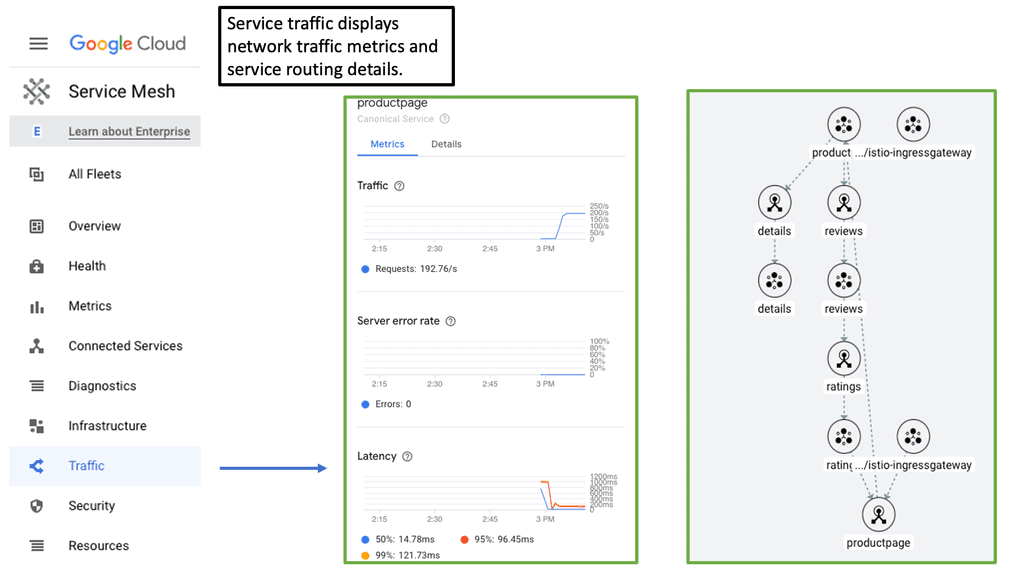
Before you proceed, you may find the following posts of interest:
One use case for load balancers to solve is availability. At some stage in time, machine failure happens. This is 100%. Therefore, you should avoid single points of failure whenever feasible. This signifies that machines should have replicas. In the case of front-end web servers, there should be at least two. When you have replicas of servers, a machine loss is not a total failure of your application. Therefore, your customer should notice as little during a machine failure event as possible.
Load Balancing and Traffic Engineering
We need network traffic engineering for load balancing that allows packets to be forwarded over non-shortest paths. Tools such as Resource Reservation Protocol (RSVP) and Fast Re-Route (FRR) enhance the behavior of TE. IGP-based TE uses a distributed routing protocol to discover the topology and run algorithms to find the shortest path. MPLS/RSVP-TE enhances standard TE and allows more granular forwarding control and the ability to differentiate traffic types for CoS/QoS purposes.
Constrained Shortest Path First
The shortest path algorithm, Constrained Shortest Path First (CSPF), provides label switch paths (LSP) to take any available path in the network. The MPLS control plane is distributed and requires a distributed IGP and label allocation protocol. The question is whether a centralized controller can solve existing traffic engineering problems. It will undoubtedly make orchestrating a network more manageable.
The contents of a TED have IGP scope domain visibility. Specific applications for TE purposes require domain-wide visibility to make optimal TE decisions. The IETF has defined the Path Computation Element (PCE) used to compute end-to-end TE paths.
Link and TE attributes are shared with external components. Juniper’s SD-WAN product, NorthStar, adopts these technologies and promises network-wide visibility and enhanced TE capabilities.
Use Case: Load Balancing with NorthStar SD-WAN controller
NorthStar is a new SD-WAN product by Juniper aimed at Service Providers and large enterprises that follow the service provider model. It is geared for the extensive network that owns Layer 2 links. NorthStar is an SD-WAN Path Computation Engine (PCE), defined in RFC 5440, that learns network state by Path Computation Element Protocol (PCEP).
It provides centralized control for path computation and TE purposes, enabling you to run your network more optimally. In addition, NorthStar gives you a programmable network with global visibility. It allowed you to spot problems and deploy granular control over traffic.

They provide a simulation environment where they learn about all the traffic flows on the network. This allows you to simulate what “might” happen in specific scenarios. With a centralized view of the network, they can optimize flows throughout it, enabling a perfectly engineered and optimized network.
The controller can find the extra and unused capacity, allowing the optimization of underutilized spots in the network. The analytics provided is helpful for forecasting and capacity planning. It has an offline capability, providing offline versions of your network with all its traffic flows.
It takes inputs from:
- The network determines the topology and views link attributes.
- Human operators.
- Requests by Northbound REST API.
These inputs decide TE capabilities and where to place TE LSP in the network. In addition, it can modify LSP and create new ones, optimizing the network traffic engineering capabilities.
Understand network topology
Traditional networks commonly run IGP and build topology tables. This can get overly complicated when a multi-area or multi-IGP is running on the network. For network-wide visibility, NorthStar recommends BGP-LS. BGP-LS enables routers to export the contents of the TE database to BGP. It uses a new address family, allowing BGP to carry node and link attributes (metric, max amount of bandwidth, admin groups, and affinity bits) related to TE. BGP-LS can be used between different regions.
As its base is BGP, you can use scalable and high-availability features, such as route reflection, to design your BGP-LS network. While BGP is very scalable, its main advantage is reduced network complexity.
While NorthStar can peer with existing IGP (OSPF and ISIS), BGP-LS is preferred. Knowing the topology and attributes, the controller can set up LSP; for example, if you want a diverse LSP, it can perform a diverse LSP path computation.
LSP & PCEP
There are three main types of LSPs in a NorthStar WAN-controlled network:
- A Vanilla-type LSP. It is a standard LSP, configured on the ingress router and signaled by RSVP.
- A delegated LSP is configured on the ingress router and then delegated to the controller, who is authorized to change this LSP.
- The controller initiates the third LSP via a human GUI or Northbound API operation.
PCEP (Path Computation Elements Protocol) communicates between all nodes and the controller. It is used to set up and modify LSP and enable dynamic and inter-area, inter-domain traffic, and engineered path setup. It consists of two entities, PCE and PCC. Path Computation Client (PCC) and Path Computation Element (PCE) get established over TCP.
Once the session is established, PCE builds the topology database (TED) using the underlying IGP or BGP-LS. BGP-LS has enhanced TLV capabilities that have been added for PCE to learn and develop this database. RSVP is still used to signal the LSP.
Closing Points on Load Balancing
Load balancing is a technique used to distribute network or application traffic across multiple servers. It ensures that no single server bears too much demand, which can lead to slowdowns or crashes. By spreading the load, it enhances the responsiveness and availability of websites and applications. At its core, load balancing helps in managing requests from users efficiently, ensuring each request is directed to the server best equipped to handle it at that moment.
There are several mechanisms and strategies employed in load balancing, each serving different needs and environments:
1. **Round Robin**: This is one of the simplest methods, where each server is assigned requests in a rotating order. It’s effective for servers with similar capabilities.
2. **Least Connections**: This method directs traffic to the server with the fewest active connections, ensuring a more even distribution of traffic during peak times.
3. **IP Hash**: This technique uses the client’s IP address to determine which server receives the request, providing a consistent experience for users.
Each method has its strengths and is chosen based on the specific requirements of the network environment.
The benefits of implementing load balancing are extensive:
– **Improved Scalability**: As demand increases, load balancing allows for the seamless addition of more servers to handle the load without downtime.
– **Enhanced Reliability**: By distributing traffic, load balancing minimizes the risk of server overload, thus reducing the chances of downtime.
– **Optimized Resource Use**: It ensures that all available server resources are utilized efficiently, reducing wastage and improving performance.
By leveraging these advantages, organizations can provide faster, more reliable digital services.
While load balancing offers numerous benefits, it is not without its challenges. Selecting the right load balancing strategy requires a deep understanding of the network environment and the specific needs of the application. Additionally, ensuring security during the load balancing process is crucial, as it involves the handling of sensitive data across multiple servers.