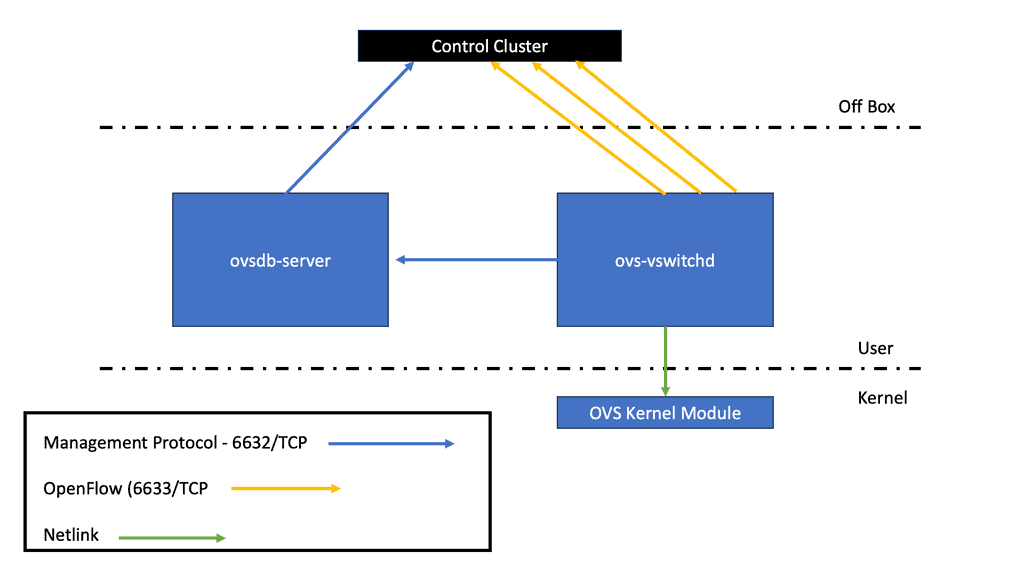
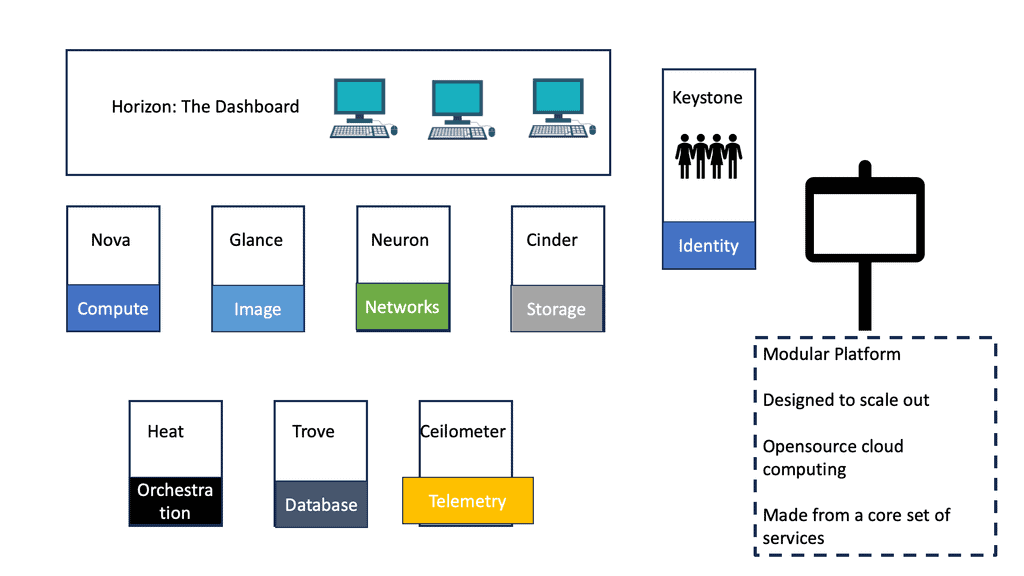
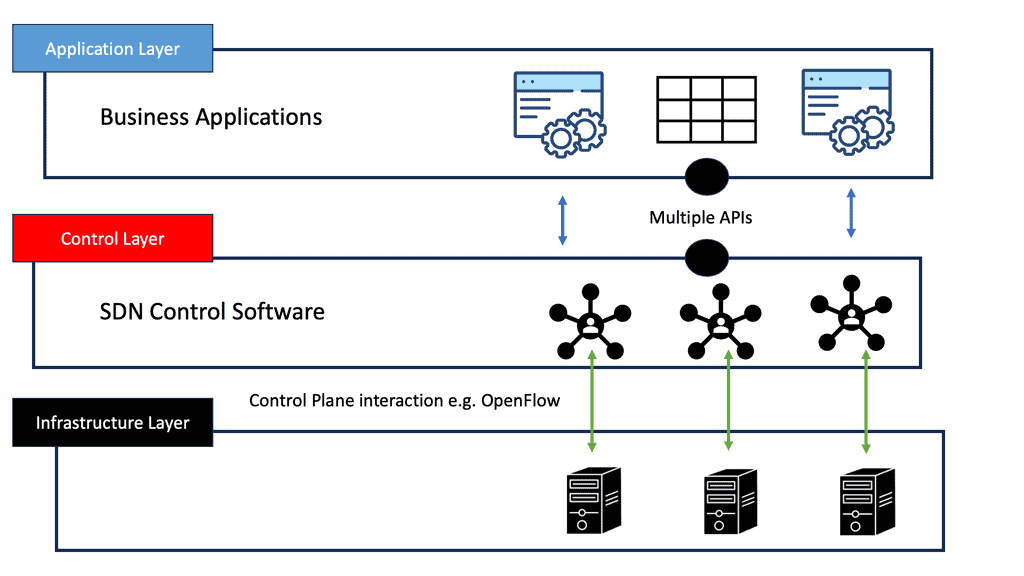
The adoption of cloud technology has transformed how companies run their IT services. By leveraging new strategies for resource use, several cloud solutions came into play with different categories: private, public, hybrid, and community. OpenStack falls into the private cloud category. However, deploying OpenStack is still tricky, requiring a good understanding of its beneficial returns to a given organization regarding automation, orchestration, and flexibility.
The New Data Center Paradigm
n cloud computing, infrastructure services such as Software as a Service (SaaS), Platform as a Service (PaaS), and Infrastructure as a Service (IaaS) are provided. Agility, speed, and self-service are the challenges the public cloud sets. Most companies have expensive IT systems, which they have developed and deployed over the years, but these systems are siloed and require human intervention.
As public cloud services become more agile and faster, IT systems struggle to keep up. Today’s agile service delivery environment may make the traditional data center model and siloed infrastructure unsustainable. To achieve next-generation data center efficiency, enterprise data centers must focus on speed, flexibility, and automation.
Fully Automated Infrastructure
Admins and operators can deploy fully automated infrastructures with a software infrastructure within a minute. Next-generation data centers reduce infrastructure to a single, significant, agile, scalable, and automated unit. The result is an infrastructure that is programmable, scalable, and multi-tenant-aware. In this regard, OpenStack stands out as the next generation of data center operating systems.
Several sizeable global cloud enterprises, such as VMware, Cisco, Juniper, IBM, Red Hat, Rackspace, PayPal, and eBay, have benefited from OpenStack. Many are running a private cloud based on OpenStack in their production environment. Your IT infrastructure should use OpenStack if you wish to be a part of an innovative, winning cloud company.
The main components of OpenStack are:
While different services cater to various needs, they follow a common theme in their design:
In OpenStack, Python is used to develop most services, making it easier for them to be developed rapidly.
REST APIs are available for all OpenStack services. The APIs are the primary communication interfaces for other services and end users.
Different components may be used to implement the OpenStack service. A message queue communicates between the service components and has several advantages, including queuing requests, loose coupling, and load distribution.
1. Nova: Nova is the compute service responsible for managing and provisioning virtual machines (VMs) and other instances. It provides an interface to control and automate the deployment of instances across multiple hypervisors.
2. Neutron: Neutron is a networking service that enables the creation and management of virtual networks within the cloud environment. It offers a range of networking options, including virtual routers, load balancers, and firewalls, allowing users to customize their network configurations.
3. Cinder: Cinder provides block storage to OpenStack instances. It allows users to create and manage persistent storage volumes, which can be attached to cases for data storage. Cinder supports various storage backends, including local disks and network-attached storage (NAS) devices.
4. Swift: Swift is an object storage service that provides scalable and durable storage for unstructured data. It enables users to store and retrieve large amounts of data, making it suitable for applications that require high scalability and fault tolerance.
5. Keystone: Keystone serves as the identity service for OpenStack, providing authentication and authorization mechanisms. It manages user credentials and assigns access rights to the various components and services within the cloud infrastructure.
6. Glance: Glance is an image service that enables users to discover, register, and retrieve virtual machine images. It provides a catalog of images that can be used to launch instances, making it easy to create and manage VM templates.
7. Horizon: Horizon is the web-based dashboard for OpenStack, providing a graphical user interface (GUI) for managing and monitoring the cloud infrastructure. It allows users to perform administrative tasks like launching instances, managing networks, and configuring security settings.
These components work together to provide a comprehensive cloud computing platform that offers scalability, high availability, and efficient resource management. OpenStack’s architecture is designed to be highly modular and extensible, allowing users to add or replace components per their specific requirements.
Keystone
Architecturally, Keystone is the most straightforward service in OpenStack. OpenStack’s core component provides an identity service that enables tenant authentication and authorization. By authorizing communication between OpenStack services, Keystone ensures that the correct user or service can access the requested OpenStack service.
Keystone integrates with numerous authentication mechanisms, including usernames, passwords, tokens, and authentication-based systems. It can also be integrated with existing backends like Lightweight Directory Access Protocol (LDAP) and Pluggable Authentication Module (PAM).
Swift
Swift is one of the storage services that OpenStack users can use. REST APIs provide access to its object-based storage service. Object storage differs from traditional storage solutions, such as file shares and block-based access, in that it treats data as objects that can be stored and retrieved. An overview of Object Storage can be summarized as follows. In the Object Store, data is split into smaller chunks and stored in separate containers. A cluster of storage nodes maintains redundant copies of these containers to provide high availability, auto-recovery, and horizontal scalability.
Cinder
Another way to provide storage to OpenStack users may be to use the Cinder service. This service manages persistent block storage, which provides block-level storage for virtual machines. Virtual machines can use Cinder raw volumes as hard drives.
Some of the features that Cinder offers are as follows:
Volume management: This allows the creation or deletion of a volume
Snapshot management: This allows the creation or deletion of a snapshot of volumes
Attaching or detaching volumes from instances
Cloning volumes
Creating volumes from snapshots
Copy of images to volumes and vice versa
Like Keystone services, Cinder features can be delivered by orchestrating various backend volume providers, such as IBM, NetApp, Nexenta, and VMware storage products, through configurable drivers.
Manila
As well as the blocks and objects we discussed in the previous section, OpenStack has had a file-share-based storage service called Manila since the Juno release. Storage is provided as a remote file system. Unlike Cinder, it is similar to the Storage Area Network (SAN) service as opposed to the Network File System (NFS) we use on Linux. The Manila service supports NFS, SAMBA, and CIFS as backend drivers. The Manila service orchestrates shares on the share servers.
Glance
An OpenStack user can launch a virtual machine from the Glance service based on images and metadata. Depending on the hypervisor, various image formats are supported. With Glance, you can access images for KVM/Qemu, XEN, VMware, Docker, etc.
When you’re new to OpenStack, you might wonder, What’s the difference between Glance and Swift? Both handle storage. How do they differ? What is the need for such a solution?
Swift is a storage system, whereas Glance is an image registry. In contrast, Glance keeps track of virtual machine images and their associated metadata. Metadata can include kernels, disk images, disk formats, etc. Glance uses REST APIs to make this information available to OpenStack users. Images can be stored in Glance utilizing a variety of backends. Directories are the default approach, but other methods, such as NFS and Swift, can be used in massive production environments.
In contrast, Swift is a storage system. This solution allows you to store data such as virtual disks, images, backup archiving, and more.
As an image registry, Glance serves as a resource for users. Glance focuses on an architectural approach to storing and querying image information via the Image Service API. In contrast, storage systems typically offer highly scalable and redundant data stores, whereas Glance allows users (or external services) to register virtual disk images. You, as a technical operator, must find the right storage solution at this level that is cost-effective and performs well.
**OpenStack Features**
Scalability and Elasticity
OpenStack’s architecture enables seamless scalability and elasticity, allowing businesses to allocate and manage resources dynamically based on their needs. By scaling up or down on demand, organizations can efficiently handle periods of high traffic and optimize resource utilization.
Multi-Tenancy and Isolation
One of OpenStack’s standout features is its robust multi-tenancy support, which enables the creation of isolated environments for different users or projects within a single infrastructure. This ensures enhanced security, privacy, and efficient resource allocation across various departments or clients.
Flexible Deployment Models
OpenStack offers a variety of deployment options, including private, public, and hybrid clouds. This flexibility allows businesses to choose the most suitable model based on their specific requirements, whether maintaining complete control over their infrastructure or leveraging the benefits of public cloud providers.
Comprehensive Service Catalog
With an extensive service catalog, OpenStack provides a wide range of services such as compute, storage, networking, and more. Users can quickly provision and manage these services through a unified dashboard, simplifying the management and deployment of complex infrastructure components.
Open and Vendor-Agnostic
OpenStack’s open-source nature ensures vendor-agnosticism, allowing organizations to choose hardware, software, and services from various vendors. This eliminates the risk of vendor lock-in and fosters a competitive market, driving innovation and cost-effectiveness.
OpenStack Architecture in Cloud Computing
OpenStack Fundations and Origins
OpenStack Foundations is a software platform for orchestrating and automating data center environments. It provides APIs enabling users to create virtual machines, network topologies, and scale applications to business requirements. It does not just let you control your cloud; you may make it available to customers for unique self-service and management.
It’s a collection of projects (each with a specific mission) to create a shared cloud infrastructure maintained by a community. It enables any organization type to build its public or private cloud stack. A key differentiator from OpenStack and other platforms is that it’s open-source, run by an independent community continually updating and reviewing publicly accessible information. The key to its adoption is that customers do not fear vendor lock-in.
The pluggable framework is supported by multiple vendors, allowing customers to move away from the continuous path of yearly software license renewal costs. There is real momentum behind it. The lead-up to OpenStack and cloud computing started with Amazon Web Service (AWS) in 2006. They offered a public IaaS and virtual instances with an API. However, there was no SLA or data guarantee, so research academies mainly used it.
NASA and Rackspace
Historically, OpenStack was founded by NASA and Rackspace. NASA was creating a project called Nebula, which was used for computing. Rackspace was involved in a storage project ( object storage platform ) called Cloud Files. The two projects mentioned above led to a community of collaborating developers working on open projects and components.
There are plenty of vendors behind it and across the entire I.T. stack. For servers, we have Dell and H.P.; Storage consists of NetApp and SolidFire; Networking has Cisco and Software with VMware and IBM.
Initially, OpenStack foundations started with three primary services: NOVA computer service, SWIFT storage service, and GLANCE virtual disk image service. Soon after, many additional services, such as network connectivity, were added. The initial implementations were simple, providing only basic networking via Linux Layer 2 VLANs and IPtables.
Now, with the Neutron networks, you can achieve a variety of advanced topologies and rich network policies. Most networking is based on tunneling ( GRE or VXLAN ). Tunnels are used within the hypervisor, so it fits nicely with multi-tenancy. Tunnels are created between the host over the Layer 3 network within the hypervisor. As a result, tenancy V.M.s can spin up where they want and communicate over the tunnel.
What is an API?
The application programming interface ( API ) is the engine under the cloud hood. The messenger takes requests, tells the systems what you want to do, and then returns the response to you—ultimately creating connectivity.
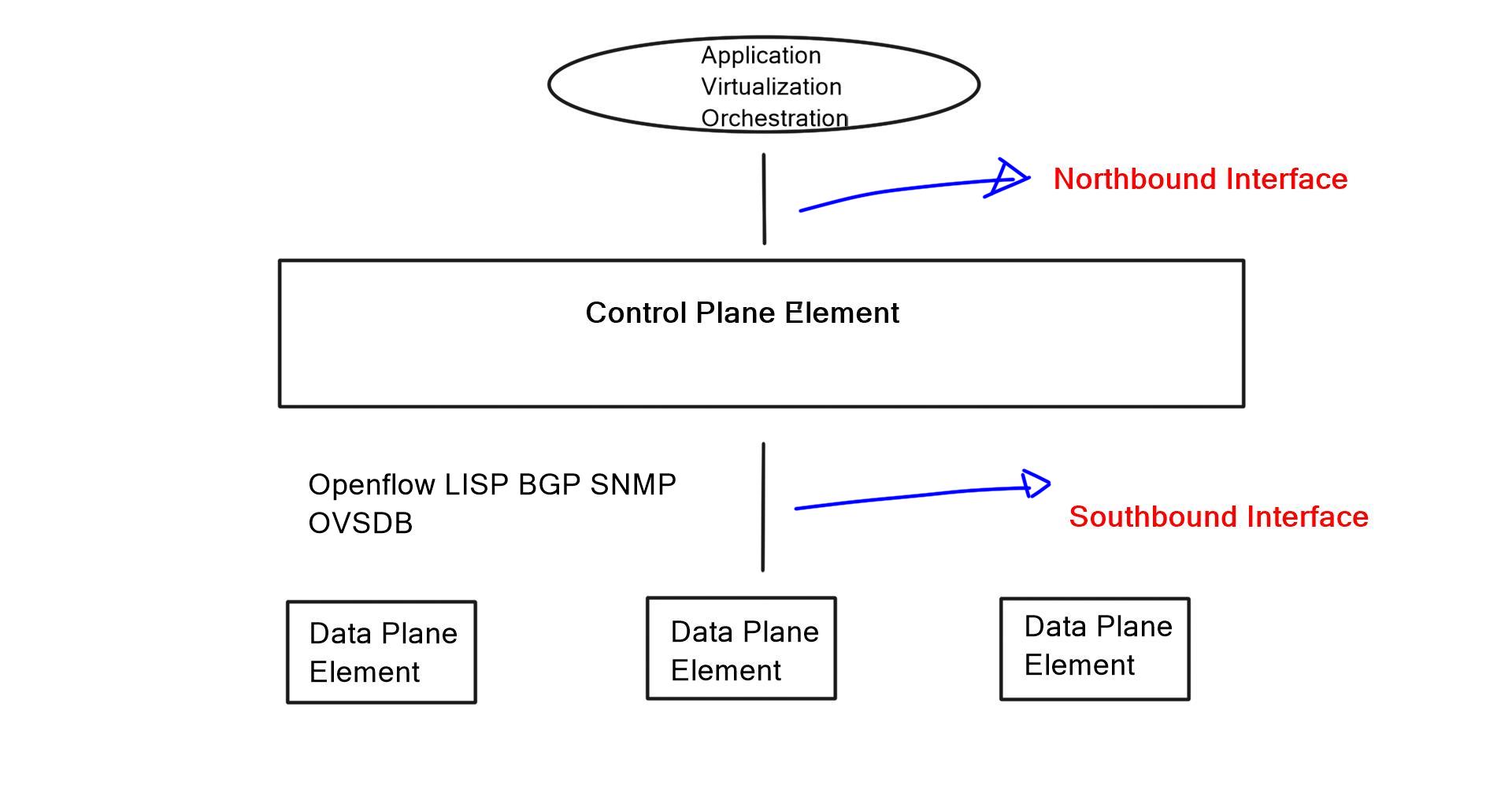
Each core project (compute, network, etc.) will expose one or more HTTP/RESTful interfaces for public or managed access. This is known as a Northbound REST API. Northbound API faces some programming interfaces. It conceptualizes lower-level detail functions. Southbound faces the forwarding plane and allows components to communicate with a lower-level part.
For example, a southbound protocol could be OpenFlow or NETCONF. Northbound and southbound are software directions from the reference point of the network operating systems. We now have an East-West interface. At the time of writing, this protocol is not fully standardized, but eventually, it will be used to communicate between federations of controllers for state synchronization and high availability.
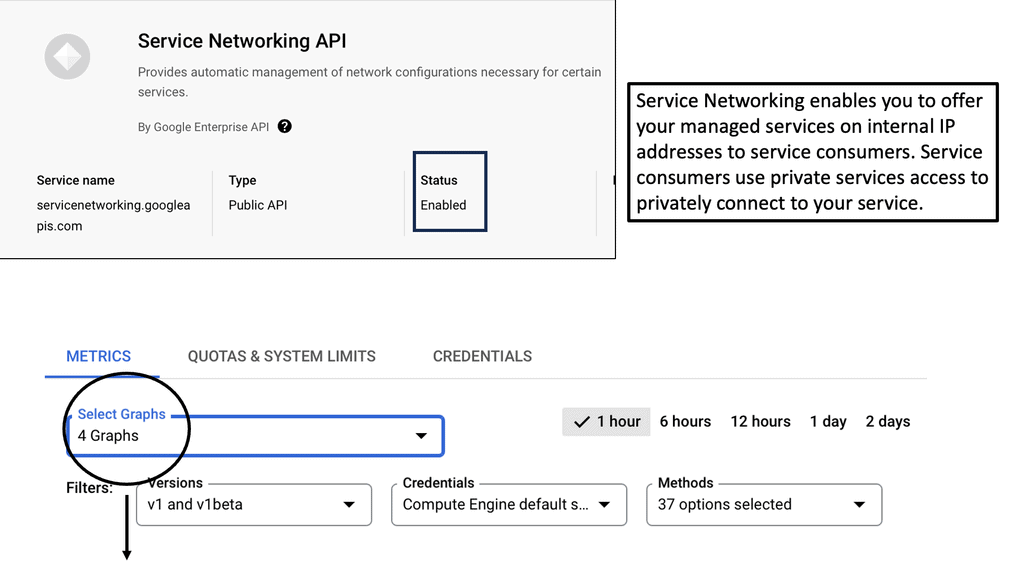
Example API Technology: Service Networking API
**Understanding the Basics of Service Networking**
Service Networking APIs primarily serve as the bridge connecting disparate services, allowing them to communicate efficiently. They are designed to simplify the process of integrating services, reducing the complexity associated with managing network connections. On Google Cloud, Service Networking APIs facilitate a variety of use cases, including hybrid cloud setups, service mesh architectures, and microservices communication.
**Key Benefits of Service Networking APIs on Google Cloud**
Google Cloud’s Service Networking APIs offer a plethora of advantages. Firstly, they enhance scalability by allowing services to communicate seamlessly without manual network configurations. Secondly, they bolster security through integrated policies that help safeguard data in transit. Additionally, these APIs support automated service discovery, which significantly reduces the time and effort required for service integrations and deployments.
**Implementing Service Networking APIs**
Implementing Service Networking APIs on Google Cloud is a straightforward process, designed to cater to both novice and experienced developers. Google Cloud provides comprehensive documentation and support, streamlining the setup and configuration of these APIs. Moreover, with tools like Google Kubernetes Engine (GKE) and Anthos, developers can leverage Service Networking APIs to manage and deploy services across hybrid and multi-cloud environments effortlessly.
OpenStack Architecture: The Foundations
- OpenStack Compute – Nova is comparable to AWS EC2. She is used to provisioning instances for applications.
- OpenStack Storage – Swift is comparable to AWS S3. Provides object storage functions for application objects.
- OpenStack Storage – Cinder is comparable to AWS Elastic Block Storage. Provides persistent block storage functions for stateless instances.
- OpenStack Orchestration – Heat is comparable to AWS Cloud formation. Orchestrates deployment of cloud services
- OpenStack Networking—Neutron Network is comparable to AWS VPC and ELB. It creates networks, topologies, ports, and routers.
There are others, such as Identity, Image Service, Trove, Ceilometer, and Sahara.
Each OpenStack foundation component has an API that can be called from either CURL, Python, or CLI. CURL is a command-line tool that lets you send HTTP requests and receive responses. Python is a widely used programming language within the OpenStack ecosystem. It automates scripts to create and manage resources in your OpenStack cloud. Finally, command-line interfaces (CLI) can access and send requests to APIs.
OpenStack Architecture & Deployment
OpenStack has a very modular design, and the diagram below displays key OpenStack components. Logically, it can be divided into three groups: a) Control, b) Network, and c) Compute. All of the features use a database or a message bus. The database can either be MySQL, MariaDB, or PostgreSQL. The message bus can be RabbitMQ, Qpid, and ActiveMQ.
The messaging and database could run on the same control node for small or DevOps deployments but could be separated for redundancy. The cloud controller on the left consists of numerous components, which are often disaggregated into separate nodes. It is the logical interface to the cloud and provides the API service.

The network controller includes the networking service Neutron. It offers an API for orchestrating network connectivity. Extension plugins provide additional network services such as VPNs, NAT, security firewalls, and load balancing. Generally, it is separate from the cloud controller, as traffic may flow through it. The compute nodes are the instances. This is where the application instances are deployed.
Leverage vagrant
Vagrant is a valuable tool for setting up Dev OpenStack environments to automate and build virtual machines ( with OpenStack ). It’s a wrapper around a virtualization platform, so you are not running the virtualization in Vagrant. The Vagrant V.M. gives you a pure environment to work with as it isolates dependencies from other V.M. applications. Nothing can interfere with the V.M., offering a full testing scope. An excellent place to start is Devstack. It’s the best tool for setting up small single-node non-production/testing installs.
Closing Points: OpenStack Architecture in Cloud Computing
OpenStack is composed of several core services, each responsible for specific functionalities within the cloud infrastructure. These services include:
– **Nova**: This is the compute service of OpenStack, responsible for managing virtual machines and instances. Nova acts as the brain of the OpenStack ecosystem, ensuring efficient allocation and management of resources.
– **Swift**: OpenStack’s object storage system, Swift, is designed to store and retrieve unstructured data at scale. It ensures data redundancy, scalability, and durability, making it suitable for applications requiring massive storage capabilities.
– **Cinder**: Cinder handles block storage needs, allowing users to manage persistent storage independently of compute instances. This flexibility is essential for applications requiring high-performance storage.
– **Neutron**: Neutron manages networking for OpenStack, providing a framework for users to create and manage networking services like routers, switches, and firewalls.
– **Keystone**: Serving as the identity service, Keystone authenticates and authorizes users and services in an OpenStack environment, ensuring secure access control.
– **Horizon**: This is the dashboard component, allowing users to interact with the OpenStack services through a web-based interface. Horizon offers an intuitive and user-friendly way to manage cloud resources.
One of the key advantages of OpenStack is its ability to scale efficiently. Organizations can start with a small cloud infrastructure and expand it effortlessly as their needs grow. OpenStack’s modular design allows new services to be added without disrupting existing ones, making it an ideal choice for businesses anticipating rapid growth or fluctuating workloads.
Security is paramount in cloud computing, and OpenStack addresses this with a variety of tools and practices. Keystone provides a solid foundation for identity management, while additional security measures are implemented through OpenStack’s extensive community of developers and contributors. Regular updates and compliance checks ensure that OpenStack remains at the forefront of cloud security standards.