
Understanding Service Level Objectives
A ) Service Level Objectives, or SLOs, refer to predefined goals that outline the level of service a company aims to provide to its customers. They act as measurable targets that help organizations assess and improve service quality. To ensure consistent and reliable service delivery, SLOs define various metrics and performance indicators, such as response time, uptime, error rates, etc.
B ) Implementing SLOs offers numerous benefits for both businesses and customers. First, they provide a clear framework for service expectations, giving customers a transparent understanding of what to anticipate. Second, SLOs enable companies to align their internal goals with customer needs, fostering a customer-centric approach. Additionally, SLOs are crucial in driving accountability and continuous improvement within organizations, leading to enhanced operational efficiency and customer satisfaction.
C ) Setting Effective SLOs: To set effective SLOs, organizations need to consider several key factors. First, they must identify the critical metrics that directly impact customer experience. These could include response time, resolution time, or system availability. Second, SLOs should be realistic and achievable, taking into account the organization’s capabilities and resources. Moreover, SLOs should be regularly reviewed and adjusted to align with evolving customer expectations and business objectives.
D ) The Significance of SLOs in Business Success: Service Level Objectives are a theoretical and vital tool for achieving business success. Organizations can enhance customer satisfaction, loyalty, and retention by defining clear service goals. This, in turn, leads to positive word-of-mouth, increased customer acquisition, and, ultimately, revenue growth. SLOs also enable businesses to identify and address service gaps proactively, mitigating potential issues before they escalate and impacting the overall customer experience.
**Service Level Objectives**
Key Note: We need to start thinking differently about things than we have in the past to make sure our services are reliable with complex systems. It might be your responsibility to maintain a globally distributed service with thousands of moving parts, or it might just be to keep a few virtual machines. No matter how far removed humans are from those things, they almost certainly rely on them at some point. It is also necessary to consider things from the perspective of human users once you have considered their needs.
SLOs are percentages you use to help drive decision-making, while SLAs are promises to customers that include compensation in case you do not meet your targets. Violations of your SLO generate data you use to evaluate the reliability of your service. Whenever you violate an SLO, you can choose to take action.
I reiterate that SLOs are not contracts; they are objectives. You are free to update or change your targets at any time. In the world, things will change, and your service’s operations may also change.
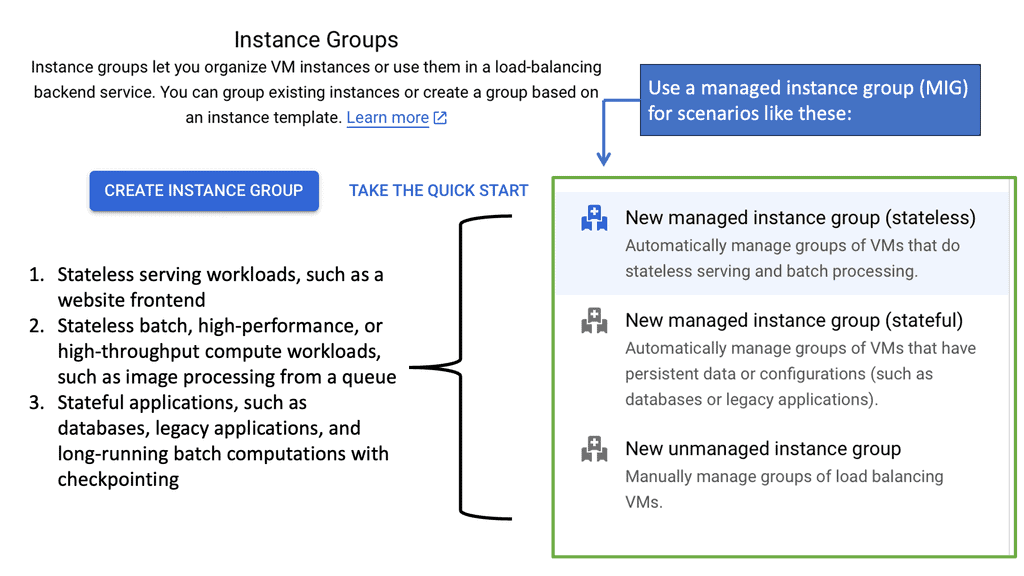
**The Mechanics of Managed Instance Groups**
At its core, a managed instance group is a collection of VM instances that are treated as a single entity. This allows for seamless scaling, load balancing, and automated updates. By utilizing Google Cloud’s MIGs, you can configure these groups to dynamically adjust the number of instances in response to changes in demand, ensuring optimal performance and cost-efficiency. This flexibility is crucial for businesses that experience fluctuating workloads, as it allows for resources to be used judiciously, meeting service level objectives without unnecessary expenditure.
—
**Achieving Service Level Objectives with MIGs**
Service level objectives (SLOs) are critical benchmarks that dictate the expected performance and availability of your applications. Managed instance groups help you meet these SLOs by offering auto-healing capabilities, ensuring that any unhealthy instances are automatically replaced. This minimizes downtime and maintains the reliability of your services. Additionally, Google Cloud’s integration with load balancing allows for efficient distribution of traffic, further enhancing your application’s performance and adherence to SLOs.
—
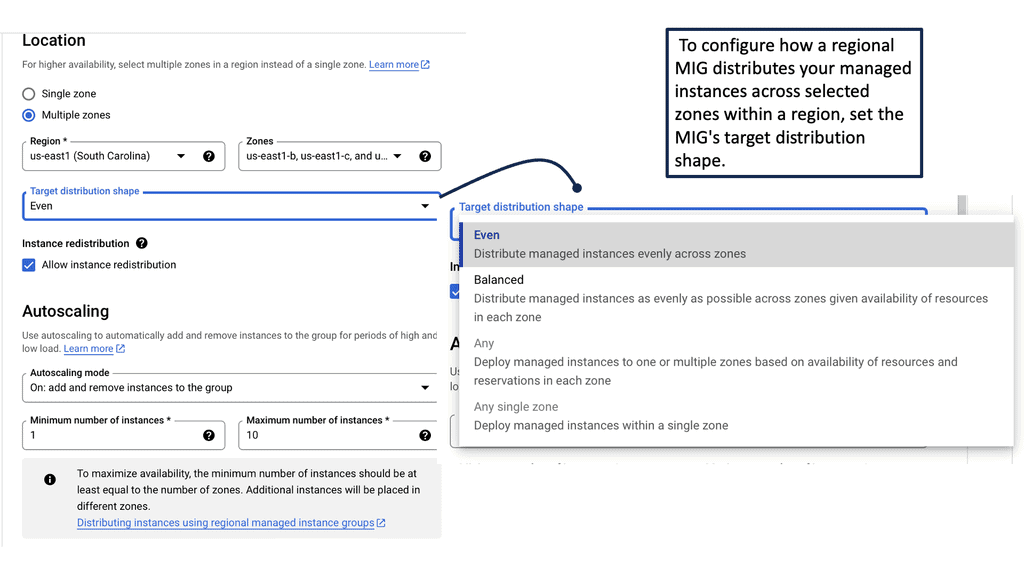
**Advanced Features for Enhanced Management**
Google Cloud’s managed instance groups come equipped with advanced features that elevate their utility. With instance templates, you can standardize the configuration of your VM instances, ensuring consistency across your deployments. The use of regional managed instance groups provides additional resilience, as instances can be spread across multiple zones, safeguarding against potential outages in a single zone. These features collectively empower you to build robust, fault-tolerant applications tailored to your specific needs.
Why are SLOs Important?
SLOs play a vital role in ensuring customer satisfaction and meeting business objectives. Here are a few reasons why SLOs are essential:
1. Accountability: SLOs provide a framework for holding service providers accountable for meeting the promised service levels. They establish a baseline for evaluating the performance and quality of the service.
2. Customer Experience: By setting SLOs, businesses can align their service offerings with customer expectations. This helps deliver a superior customer experience, foster customer loyalty, and gain a competitive edge in the market.
3. Performance Monitoring and Improvement: SLOs enable businesses to monitor their services’ performance and continuously identify improvement areas. Regularly tracking SLO metrics allows for proactive measures and optimizations to enhance service reliability and availability.
Critical Elements of SLOs:
To effectively implement SLOs, it is essential to consider the following key elements:
1. Metrics: SLOs should be based on relevant, measurable metrics that accurately reflect the desired service performance. Standard metrics include response time, uptime percentage, error rate, and throughput.
2. Targets: SLOs must define specific targets for each metric, considering customer expectations, industry standards, and business requirements. Targets should be achievable yet challenging enough to drive continuous improvement.
3. Monitoring and Alerting: Establishing robust monitoring and alerting mechanisms allows businesses to track the performance of their services in real time. This enables timely intervention and remediation in case of deviations from the defined SLOs.
4. Communication: Effective communication with customers is crucial to ensure transparency and manage expectations. Businesses should communicate SLOs, including the metrics, targets, and potential limitations, to foster trust and maintain a healthy customer-provider relationship.
**The Value of SRE Teams**
Site Reliability Engineering (SRE) teams have tools such as Service Level Objectives (SLOs), Service Level Indicators (SLIs), and Error Budgets that can guide them on the road to building a reliable system with the customer viewpoint as the metric. These new tools or technologies form the basis for reliability in distributed system and are the core building blocks of a reliable stack that assist with baseline engineering. The first thing you need to understand is the service’s expectations. This introduces the areas of service-level management and its components.
**The Role of Service-Level Management**
The core concepts of service level management are Service Level Agreement (SLA), Service Level Objectives (SLO), and Service Level Indicators (SLIs). The common indicators used are Availability, latency, duration, and efficiency. Monitoring these indicators to catch problems before your SLO is violated is critical. These are the cornerstone of developing a good SRE practice.
- SLI: Service level Indicator: A well-defined measure of “successful enough.” It is a quantifiable measurement of whether a given user interaction was good enough. Did it meet the users’ expectations? Does a web page load within a specific time? This allows you to categorize whether a given interaction is good or bad.
- SLO: Service level objective: A top-line target for a fraction of successful interactions.
- SLA: Service level agreement: consequences. It’s more of a legal construct.
Related: For pre-information, you may find the following helpful:
Site Reliability Engineering (SRE)
Google pioneered SRE to create more scalable and reliable large-scale systems. SRE has become one of today’s most valuable software innovation opportunities. It is a concrete, opinionated implementation of the DevOps philosophy. The main goal is to create scalable and highly reliable software systems.
According to Benjamin Treynor Sloss, the founder of Google’s Site Reliability Team, “SRE is what happens when a software engineer is tasked with what used to be called operations.”
So, reliability is not so much a feature as a practice that must be prioritized and considered from the very beginning. It should not be added later, for example, when a system or service is in production. Reliability is the essential feature of any system, and it’s not a feature that a vendor can sell you.
Personal Note:
So, if someone tries to sell you an add-on solution called Reliability, don’t buy it, especially if they offer 100% reliability. Nothing can be 100% reliable all the time. If you strive for 100% reliability, you will miss out on opportunities to perform innovative tasks and the need to experiment and take risks that can help you build better products and services.
Nothing can be 100% reliable all the time
Components of a Reliable System
### Distributed systems
At its core, a distributed system is a network of independent computers that work together to achieve a common goal. These systems can be spread across multiple locations and connected through communication networks. The architecture of distributed systems can vary widely, ranging from client-server models to peer-to-peer networks. One of the key features of distributed systems is their ability to provide redundancy and fault tolerance, ensuring that if one component fails, the system as a whole continues to function.
### Building Reliable Systems
To build reliable systems that can tolerate various failures, the system needs to be distributed so that a problem in one location doesn’t mean your entire service stops operating. So you need to build a system that can handle, for example, a node dying or perform adequately with a particular load.
To create a reliable system, you need to understand it fully and what happens when the different components that make up the system reach certain thresholds. This is where practices such as Chaos engineering kubernetes can help you.
### Chaos Engineering
We can have practices like Chaos Engineering that can confirm your expectations, give you confidence in your system at different levels, and prove you can have certain tolerance levels to Reliability. Chaos Engineering allows you to find weaknesses and vulnerabilities in complex systems. It is an important task that can be automated into your CI/CD pipelines.
You can have various Chaos Engineering verifications before you reach production. These tests, such as load and Latency tests, can all be automated with little or no human interaction. Site Reliability Engineering (SRE) teams often use Chaos Engineering to improve resilience, which must be part of your software development/deployment process.
### Integrating Chaos Engineering with Service Mesh
Integrating chaos engineering with a service mesh brings numerous benefits to organizations striving for resilience and reliability. Firstly, it enhances fault tolerance by exposing vulnerabilities before they become critical issues. Secondly, it provides a deeper understanding of system behavior under duress, enabling teams to optimize service performance and reliability. Lastly, it fosters a culture of experimentation and learning, encouraging teams to continuously improve and innovate.



Perception: Customer-Centric View
Reliability is all about perception. Suppose the user considers your service unreliable. In that case, you will lose consumer trust because of poor service perception, so it’s important to provide consistency with your services as much as possible. For example, it’s OK to have some outages. Outages are expected, but you can’t have them all the time and for long durations.
Users expect to have outages at some point in time, but not for so long. User Perception is everything; if the user thinks you are unreliable, you are. Therefore, you need to have a customer-centric view, and using customer satisfaction is a critical metric to measure.
This is where the critical components of service management, such as Service Level Objectives (SLO) and Service Level Indicators (SLI), come into play. It would be best if you found a balance between Velocity and Stability. You can’t stop innovation, but you can’t take too many risks. An Error Budget will help you with Site Reliability Engineering (SRE) principles.
Users experience Static thresholds.
User experience means different things to different groups of users. We now have a model where different service users may be routed through the system in other ways, using various components and providing experiences that can vary widely. We also know that the services no longer tend to break in the same few predictable ways over and over.
With complex microservices and many software interactions, we have many unpredictable failures that we have never seen before. These are often referred to as black holes. We should have a few alerts triggered by only focusing on symptoms that directly impact user experience and not because a threshold was reached.
Example: Issues with Static Thresholds
1.If your POD network reaches a certain threshold, this does not tell you anything about user experience. You can’t rely on static thresholds anymore, as they have no relationship to customer satisfaction.
2.If you use static thresholds, they can’t reliably indicate any issues with user experience. Alerts should be set up to detect failures that impact user experience. Traditional monitoring falls short of trying this as it usually has predefined dashboards that look for something that has happened before.
3.This brings us back to the challenges with traditional metrics-based monitoring; we rely on static thresholds to define optimal system conditions, which have nothing to do with user experience. However, modern systems change shape dynamically under different workloads. Static thresholds for monitoring can’t reflect impacts on user experience. They lack context and are too coarse.
How to Approach Reliability
**New tools and technologies**
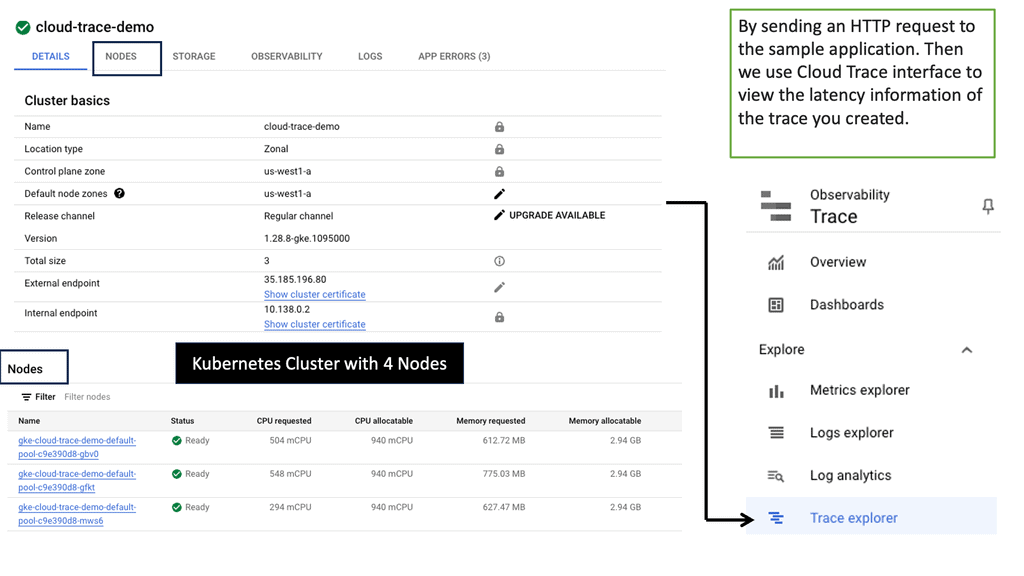
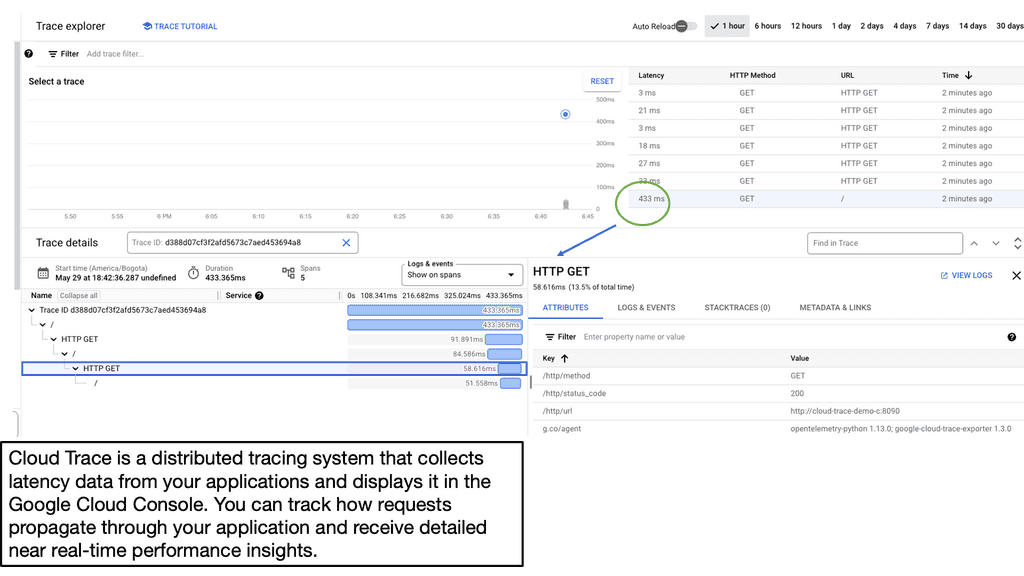
– 1: We have new tools, such as distributed tracing. What is the best way to find the bottleneck if the system becomes slow? Here, you can use Distributed Tracing and Open Telemetry. Tracing helps us instrument our system so we figure out where the time has been spent. It can be used across distributed microservice architecture to troubleshoot problems. Open Telemetry provides a standardized way of instrumenting our system and providing those traces.
– 2: have already touched on Service Level Objectives, Indicators, and Error Budget. You want to know why and how something has happened. So we don’t just want to know when something has happened and then react to an event that is not looking from the customer’s perspective.
– 3: need to understand if we are meeting the Service Level Agreement (SLA) by gathering the number and frequency of the outages and any performance issues. Service Level Objectives (SLO) and Service Level Indicators (SLI) can assist you with measurements.
– 4: Level Objectives (SLO) and Service Level Indicators (SLI) assist you with measurements. They also offer a tool for better system reliability and form the base for the Reliability Stack. SLIs and SLOs help us interact with Reliability differently and provide a path for building a reliable system.
So now we have the tools and a disciple to use the tools within. Can you recall what that disciple is? The discipline is Site Reliability Engineering (SRE)
Example: Distributed Tracing with Cloud Trace
**SLO-based approach to reliability**
If you’re too reliable all the time, you’re also missing out on some of the fundamental features that SLO-based approaches give you. The main area you will miss is the freedom to do what you want, test, and innovate. If you’re too reliable, you’re missing out on opportunities to experiment, perform chaos engineering, ship features quicker than before, or even introduce structured downtime to see how your dependencies react.
To learn a system, you need to break it. So, if you are 100% reliable, you can’t touch your system, so you will never truly learn and understand your system. You want to give your users a good experience, but you’ll run out of resources in various ways if you try to ensure this good experience happens 100% of the time. SLOs let you pick a target that lives between those two worlds.
**Balance velocity and stability**
You can’t just have Reliability; you must also have new features and innovation. Therefore, you need to find a balance between velocity and stability. We need to balance Reliability with other features you have and are proposing to offer. Suppose you have access to a system with a fantastic feature that doesn’t work. The users who have the choice will leave.
Site Reliability Engineering is the framework for balancing velocity and stability. How do you know what level of Reliability you need to provide your customer? This all goes back to the business needs that reflect the customer’s expectations. With SRE, we have a customer-centric approach.
The primary source of outages is making changes even when the changes are planned. This can come in many forms, such as pushing new features, applying security patches, deploying new hardware, and scaling up to meet customer demand, which will significantly impact if you strive for a 100% reliability target.
There will always be changes
If nothing changes to the physical/logical infrastructure or other components, we will not have bugs. We can freeze our current user base and never have to scale the system. In reality, this will not happen. There will always be changes. So it would be best if you found a balance.
Service Level Objectives (SLOs) are a cornerstone for delivering reliable and high-quality services in today’s technology-driven world. By setting measurable targets, businesses can align their service performance with customer expectations, drive continuous improvement, and ultimately enhance customer satisfaction.
Implementing and monitoring SLOs allows companies to proactively address issues, optimize service delivery, and stay ahead of the competition. By embracing SLOs, companies can pave the way for successful service delivery and long-term growth.