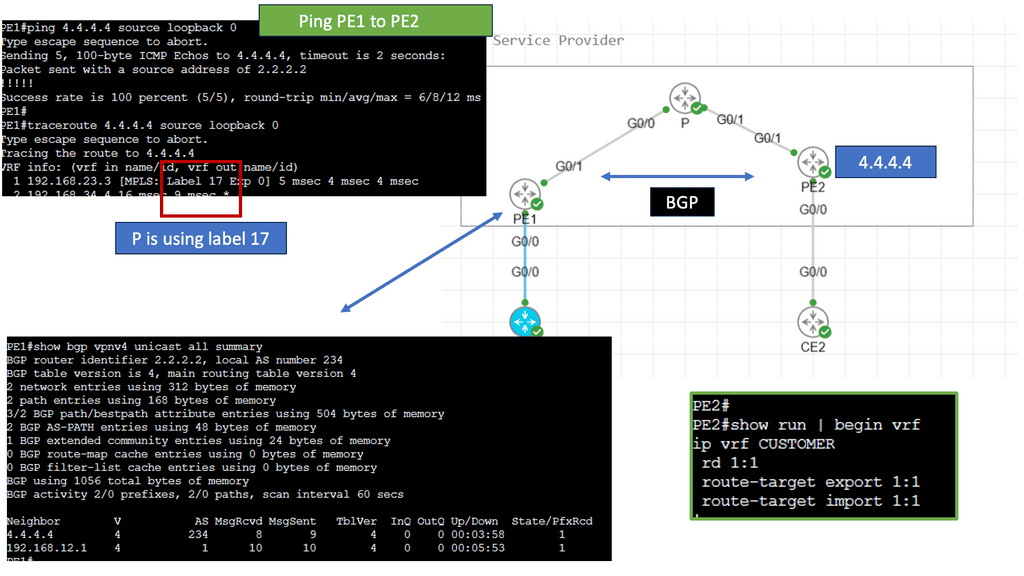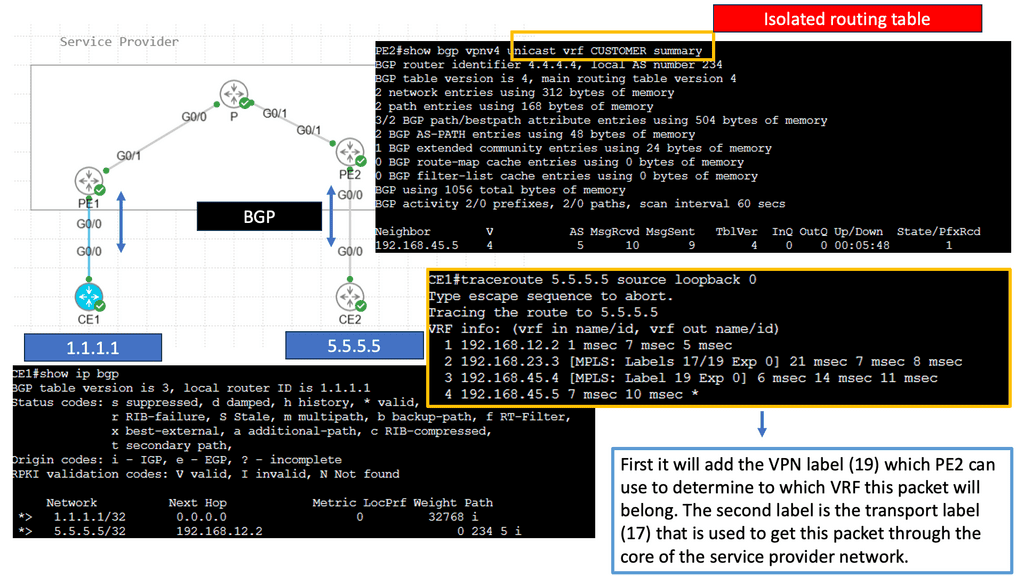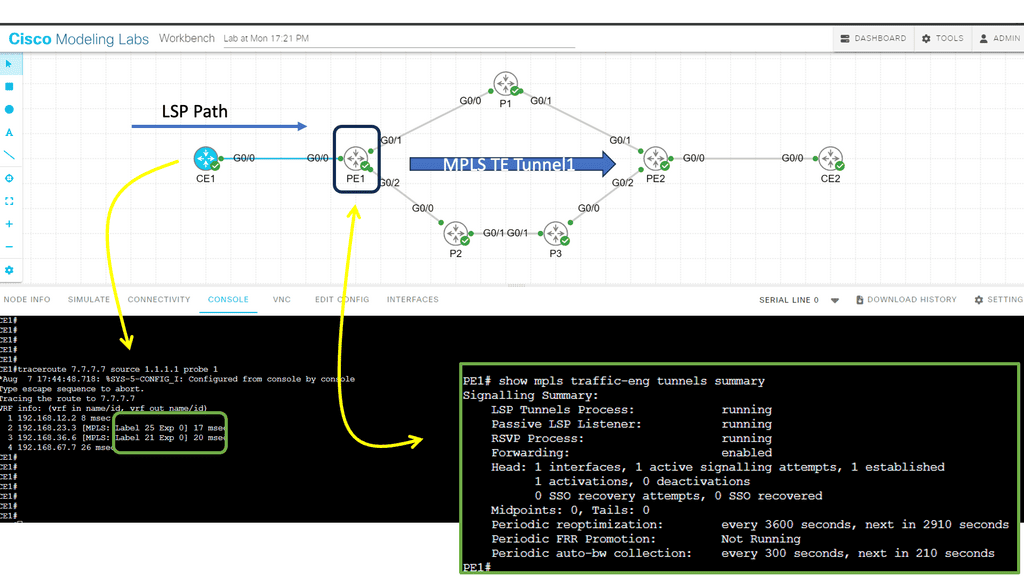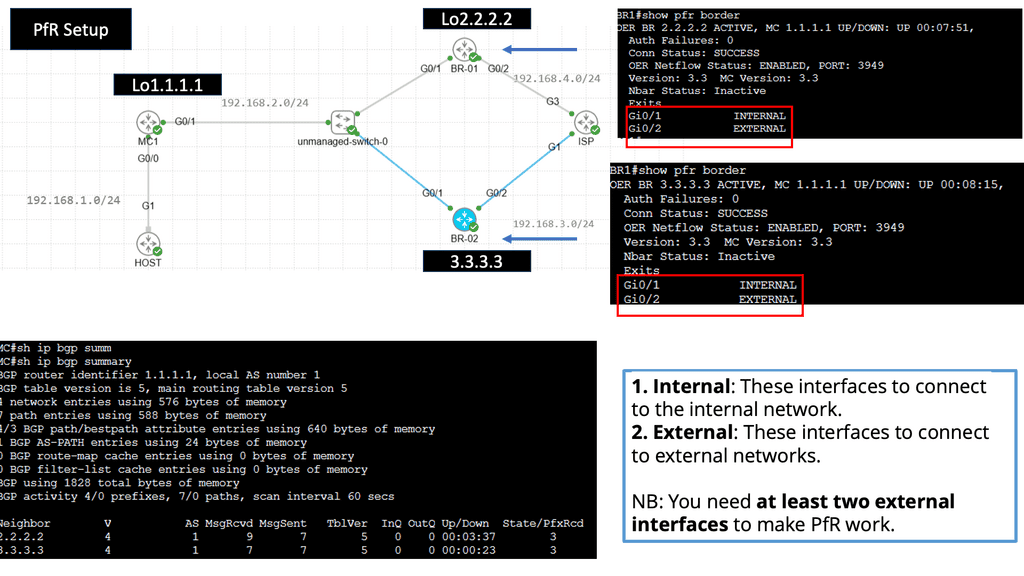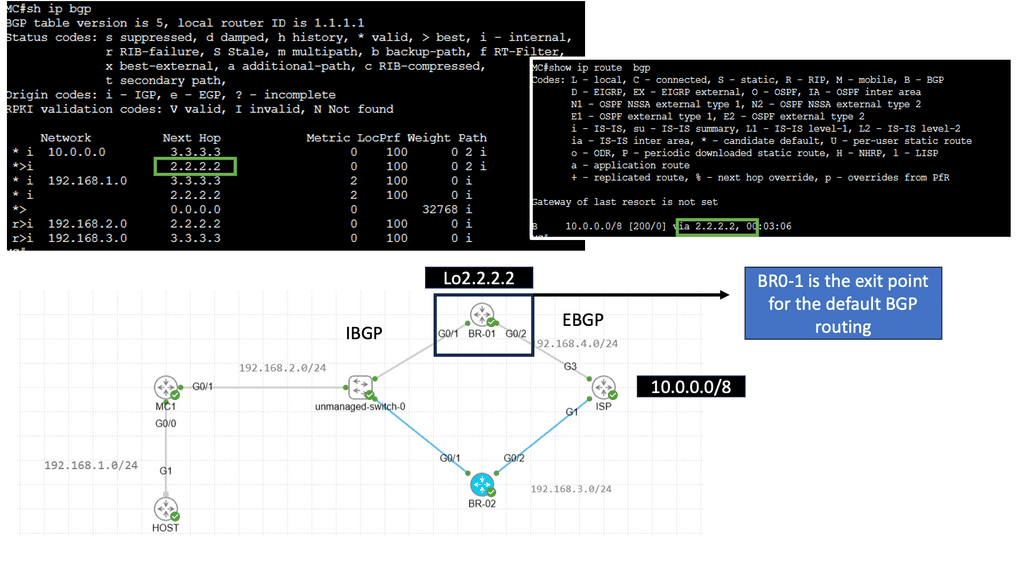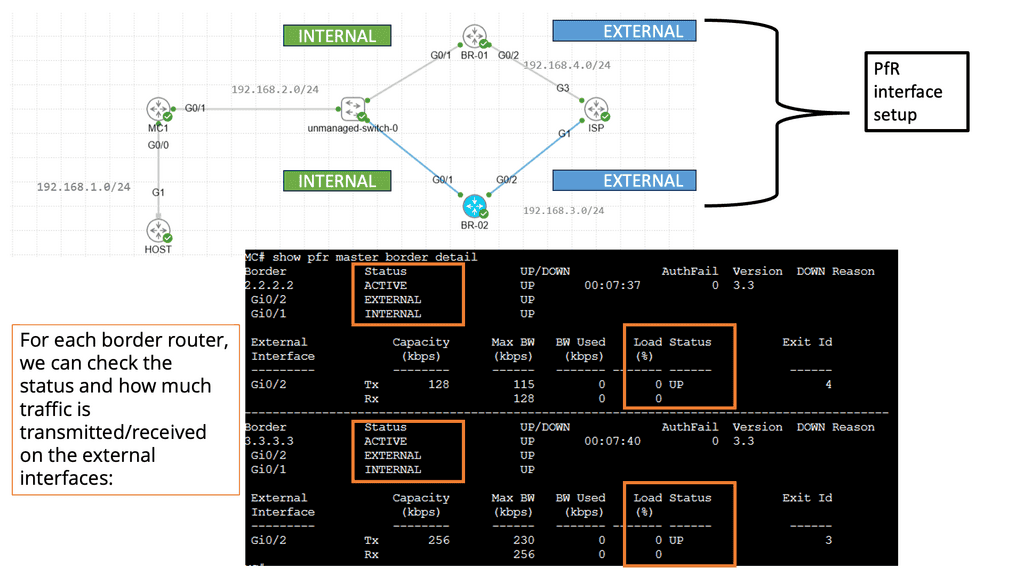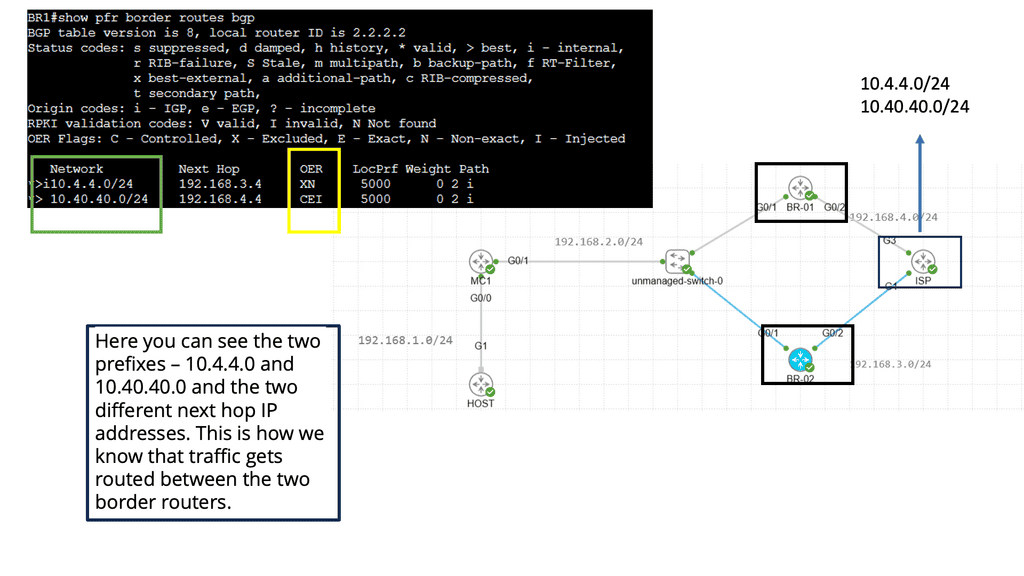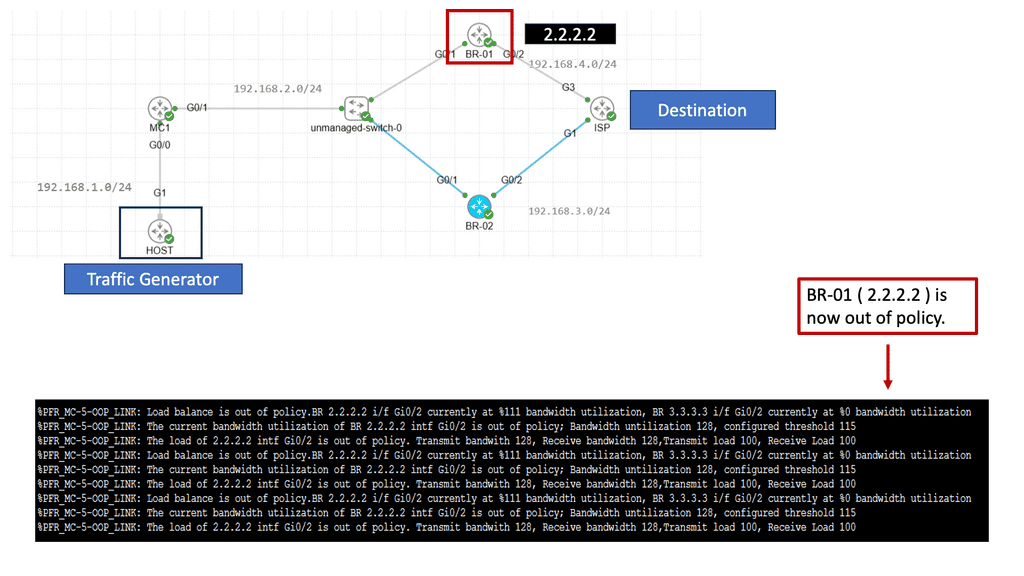
Understanding BGP and SDN
1- BGP (Border Gateway Protocol) is a routing protocol used to exchange routing information between different networks on the internet. On the other hand, SDN is an architectural approach that separates the control plane from the data plane, allowing network administrators to centrally manage and configure networks through software.
2- BGP-based SDN combines the power of BGP routing with the flexibility and programmability of SDN. Network operators gain enhanced control, scalability, and agility in managing their networks by leveraging BGP as the control plane protocol in an SDN architecture. This marriage of BGP and SDN opens up new possibilities for network automation, policy-driven routing, and dynamic traffic engineering.
3- One critical advantage of BGP-based SDN is its ability to simplify network management. With centralized control and programmability, network operators can define policies and rules that govern their networks’ behavior.
4- This paves the way for efficient traffic engineering and the ability to respond dynamically to changing network conditions. Additionally, BGP-based SDN provides better scalability, allowing for the distribution of control plane functions across multiple controllers.
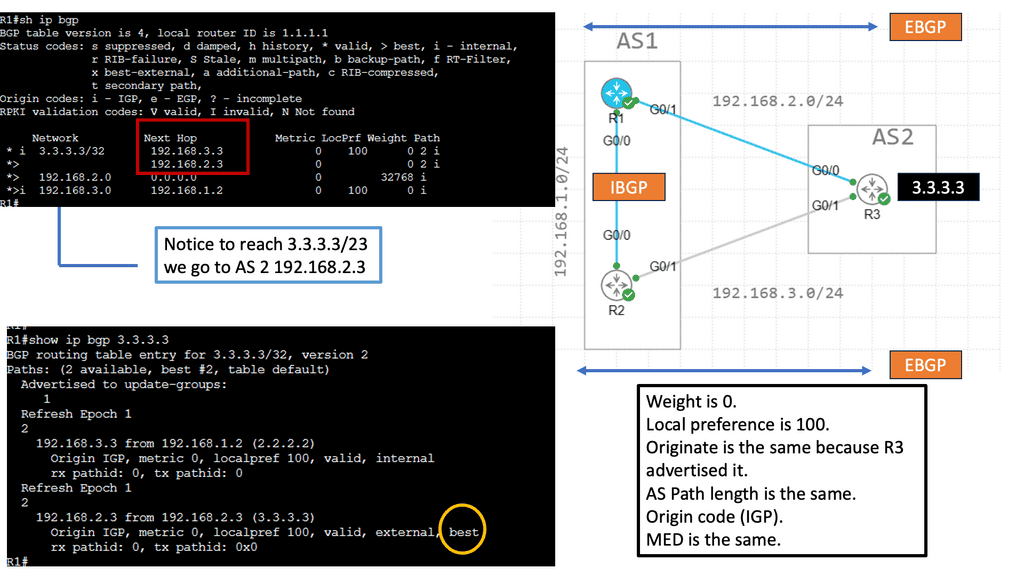
Knowledge Check: Prefer EBGP over iBGP
### What is eBGP?
eBGP, or External BGP, is used for routing between different autonomous systems (AS). An autonomous system is essentially a collection of IP networks and routers under the control of a single organization. eBGP is employed when these networks communicate with each other. Its primary purpose is to exchange routing information between these independent systems, ensuring data can travel from one network to another across the globe.
eBGP is characterized by its scalability and efficiency in handling large amounts of routing information. It operates by sending updates about network reachability, allowing each AS to determine the best path for data transmission. This makes it an indispensable tool for ISPs and large enterprises managing extensive network infrastructures.
### Understanding iBGP
On the other hand, iBGP, or Internal BGP, operates within a single autonomous system. Its purpose is to distribute routing information obtained from eBGP to all routers within the same AS. Unlike eBGP, which is concerned with external communication, iBGP ensures that all routers within the AS have a consistent view of the network topology.
iBGP is crucial for maintaining the integrity and efficiency of a network’s internal routing. It prevents routing loops and ensures that data packets find the most optimal path within the AS. Additionally, it works seamlessly with other interior gateway protocols like OSPF and IS-IS to enhance network performance.
### Key Differences Between eBGP and iBGP
While both eBGP and iBGP are integral parts of the BGP protocol, they serve distinct purposes and operate under different conditions. Here are some key differences:
1. **Operational Scope**: eBGP is used between different AS, whereas iBGP operates within a single AS.
2. **Path Selection**: eBGP selects routes based on the AS path, preferring shorter paths, while iBGP relies on the IGP metrics to determine the best route within the AS.
3. **Hop Count**: eBGP sessions are typically limited to a single hop, although multi-hop configurations are possible. iBGP sessions, however, can span multiple hops within the AS.
4. **Route Propagation**: eBGP routes are advertised to iBGP peers, but iBGP routes are not automatically advertised to other iBGP peers, requiring additional configuration to propagate routes.
### Practical Applications and Considerations
Network administrators must carefully consider their use of eBGP and iBGP when designing and managing network infrastructures. eBGP is essential for connecting to external networks and the internet, while iBGP ensures efficient internal routing. Balancing both is key to achieving optimal network performance and reliability.
When configuring BGP, it is also important to implement security measures to prevent attacks such as route hijacking. This includes using route filtering, authentication, and monitoring tools to safeguard network operations.
## The Role of BGP in Traditional Networking ##
BGP has long been the backbone of internet routing, enabling data to traverse global networks efficiently. Its robust, policy-driven approach allows for complex routing decisions based on a variety of factors like path attributes and network policies. However, traditional BGP setups can be rigid, often requiring manual configurations that are time-consuming and error-prone. This is where SDN comes into play, offering a more dynamic and programmable approach to network management.
## Integrating BGP with SDN: A New Era
The integration of BGP with SDN is not just about replacing old systems but augmenting them. By leveraging SDN’s centralized control and programmability, BGP-based SDN allows for automated policy changes and real-time network optimization. This results in a more agile network that can adapt to changing demands and conditions. The centralized SDN controller can dynamically manage BGP routes, reducing the complexity and improving the responsiveness of the network.
## BGP SDN Challenges
Despite its advantages, implementing BGP-based SDN is not without its challenges. Integrating SDN with existing BGP infrastructures can be complex and requires careful planning and execution. There is also the need for network professionals to acquire new skills and knowledge to effectively manage these advanced systems. Furthermore, ensuring compatibility between different SDN solutions and traditional network devices remains a critical consideration.
## Note: New Attack Surface
While BGP-based SDN holds immense potential, it also poses certain challenges. One of the primary concerns is the complexity of implementation and migration. Integrating BGP with SDN requires careful planning and coordination to ensure a smooth transition. Moreover, security and privacy considerations must be considered when deploying BGP-based SDN, as centralized control introduces new attack vectors that must be mitigated.
Critical Components of BGP SDN:
a. BGP Routing: BGP SDN leverages the BGP protocol to manage the routing decisions between different networks. This enables efficient and optimized routing and seamless communication across various domains.
b. SDN Controller: The SDN controller acts as the centralized brain of the network, providing a single point of control and management. It enables network administrators to define and enforce network policies, configure routing paths, and allocate network resources dynamically.
c. OpenFlow Protocol: BGP SDN uses the OpenFlow protocol to communicate between the SDN controller and the network switches. OpenFlow enables the controller to programmatically control the forwarding behavior of switches, resulting in greater flexibility and agility.
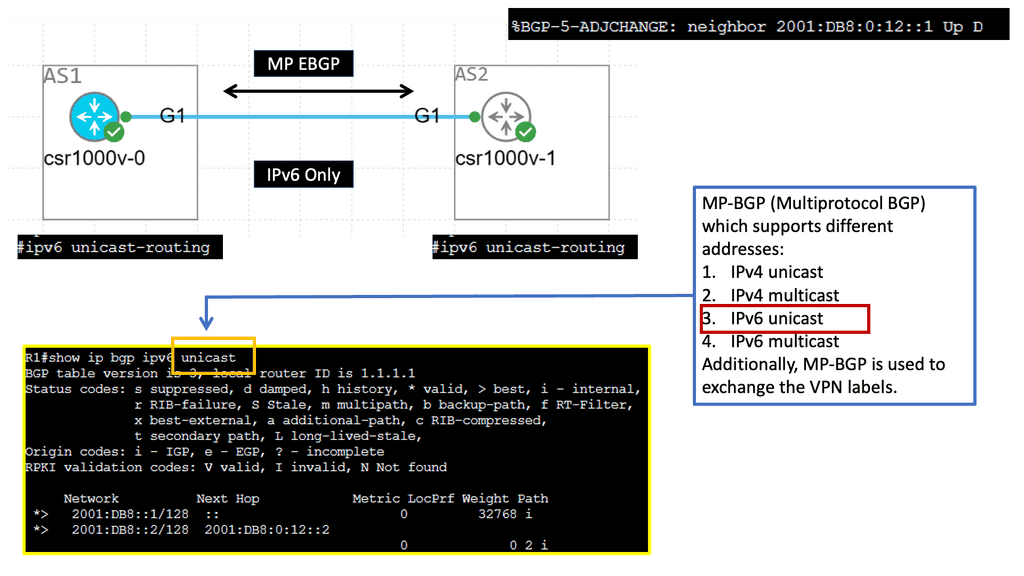
Example BGP Technology: IPv6 BGP
### IPv6 and BGP: A Synergistic Relationship
Transitioning to IPv6 doesn’t just mean more addresses; it means enhancing the operational capacity of BGP. IPv6 introduces features like simplified header formats and improved multicast routing, which can streamline the BGP process. This section will explore how IPv6 enhances BGP operations, offering benefits such as reduced latency, improved security, and better support for mobile networks.
### Challenges and Considerations in IPv6 BGP Deployment
Despite its advantages, the deployment of IPv6 within BGP is not without challenges. Network engineers face hurdles such as compatibility with existing IPv4 infrastructure, the complexity of dual-stack configurations, and the need for updated hardware and software. We’ll examine these challenges and provide insights into how organizations can navigate them to successfully implement IPv6 in their BGP configurations.
Benefits of BGP SDN:
a. Enhanced Flexibility: BGP SDN allows network administrators to tailor their network infrastructure to meet specific requirements. With centralized control, network policies can be easily modified or updated, enabling rapid adaptation to changing business needs.
b. Improved Scalability: Traditional network architectures often struggle to handle the growing demands of modern applications. BGP SDN provides a scalable solution by enabling dynamic allocation of network resources, optimizing traffic flow, and ensuring efficient bandwidth utilization.
c. Simplified Network Management: BGP SDN’s centralized management simplifies network operations. Network administrators can configure, monitor, and manage the entire network from a single interface, reducing complexity and improving overall efficiency.
Use Cases for BGP SDN:
a. Data Centers: BGP SDN is well-suited for data center environments, where rapid provisioning, scalability, and efficient workload distribution are critical. By leveraging BGP SDN, data centers can seamlessly integrate physical and virtual networks, enabling efficient resource allocation and workload migration.
b. Service Providers: BGP SDN allows service providers to offer their customers flexible and customizable network services. It enables the creation of virtual private networks, traffic engineering, and service chaining, resulting in improved service delivery and customer satisfaction.
BGP Technologies in BGP SDN
Understanding BGP Route Reflection
A – 🙂 BGP route reflection is a technique used to alleviate the burden of full-mesh connectivity in BGP networks. Traditionally, in a fully meshed BGP configuration, all routers must establish a direct peer-to-peer connection with every other router, resulting in complex and resource-intensive setups. Route reflection introduces a hierarchical approach that reduces the number of required connections, providing a more scalable alternative.
B – 🙂 Route reflectors act as centralized points within a BGP network and reflect and propagate routing information to other routers. They collect BGP updates from their clients and reflect them to other clients, ensuring a simplified and efficient distribution of routing information. Route reflectors maintain the overall consistency of the BGP network while reducing the number of required peer connections.
C- 🙂 To implement BGP route reflection, one or more routers within the network need to be configured as route reflectors. These route reflectors should be strategically placed to ensure efficient routing information dissemination. Clients, also known as non-route reflectors, establish peering sessions with the route reflectors and send their BGP updates to be reflected. Route reflector clusters can also be formed to provide redundancy and load balancing.


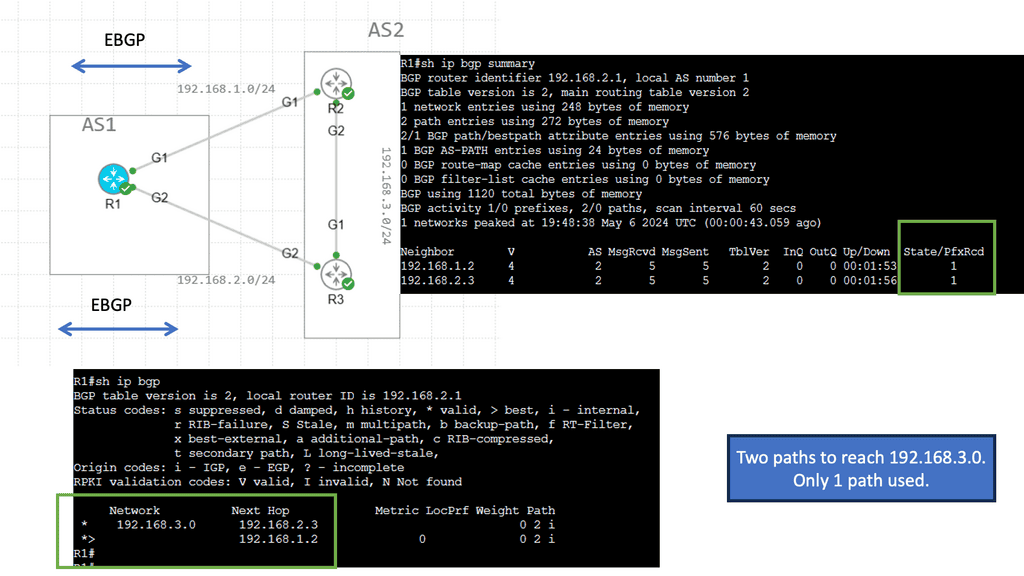
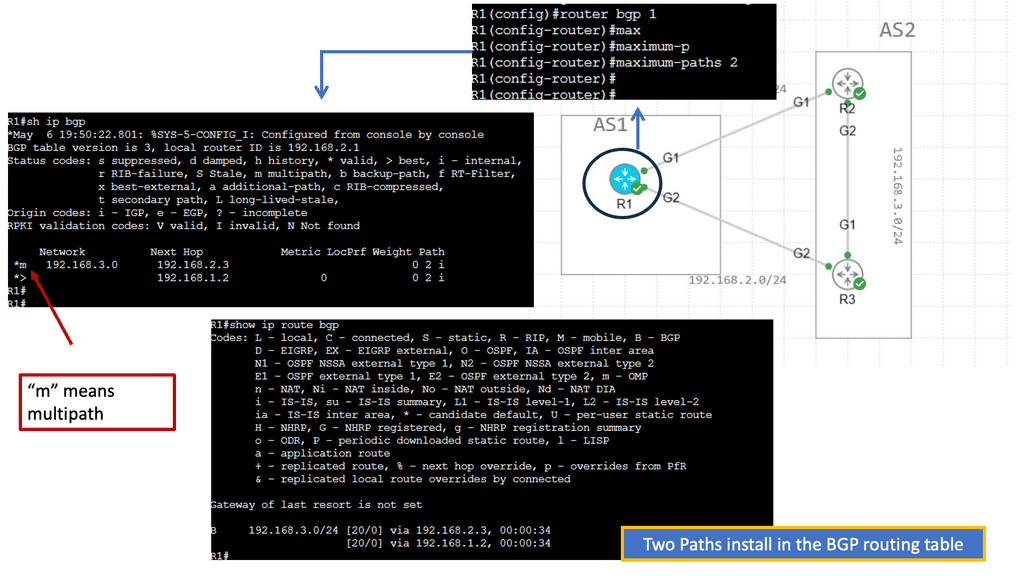
Understanding BGP Multipath
BGP multipath, short for Border Gateway Protocol multipath, is a feature that enables the use of multiple paths for traffic forwarding in a network. Traditionally, BGP selects a single best path based on attributes like AS path length, origin type, and MED (Multi-Exit Discriminator) value. However, with BGP multipath, multiple paths can be utilized simultaneously, distributing traffic across multiple links.
Enhanced Network Performance: BGP multipath optimizes network performance by load-balancing traffic using multiple paths. This helps avoid congestion on specific links and ensures efficient utilization of available bandwidth, resulting in faster and more reliable data transmission.
Improved Resilience: BGP multipath enhances network resilience by providing redundancy. In case of link failures or congestion, traffic can be automatically rerouted through alternative paths, minimizing downtime and ensuring continuous connectivity. This dramatically improves the overall reliability of the network infrastructure.
SDN and BGP
BGP SDN, or Border Gateway Protocol Software-Defined Networking, combines two powerful technologies: the Border Gateway Protocol (BGP) and Software-Defined Networking (SDN). BGP, a routing protocol, facilitates inter-domain routing, while SDN provides centralized control and programmability of the network. Together, they offer a dynamic and adaptable networking environment.
While Border Gateway Protocol (BGP) was initially designed to connect networks operated by different companies, such as transit service providers, providers of large-scale data centers discovered that it could be used for spine and leaf fabrics.
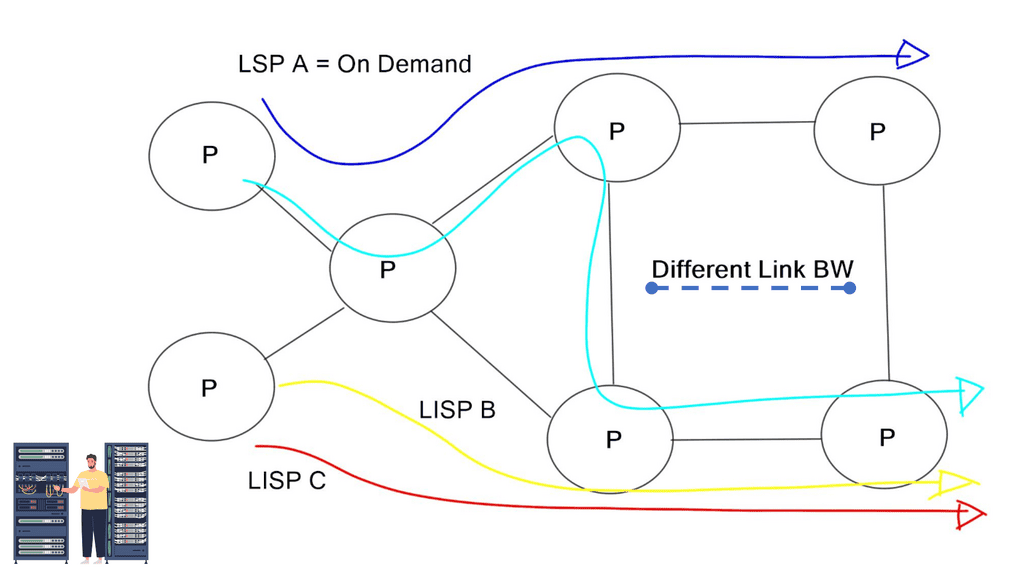
BGP can also be used as an SDN because it already runs on all routers. According to the diagram below, each router in the fabric is connected to an iBGP controller.
Augmented Model
After the iBGP sessions are established, the controller can read the entire topology to determine which path the flow should be pinned to and which flows should avoid the path over which the flow is passing.
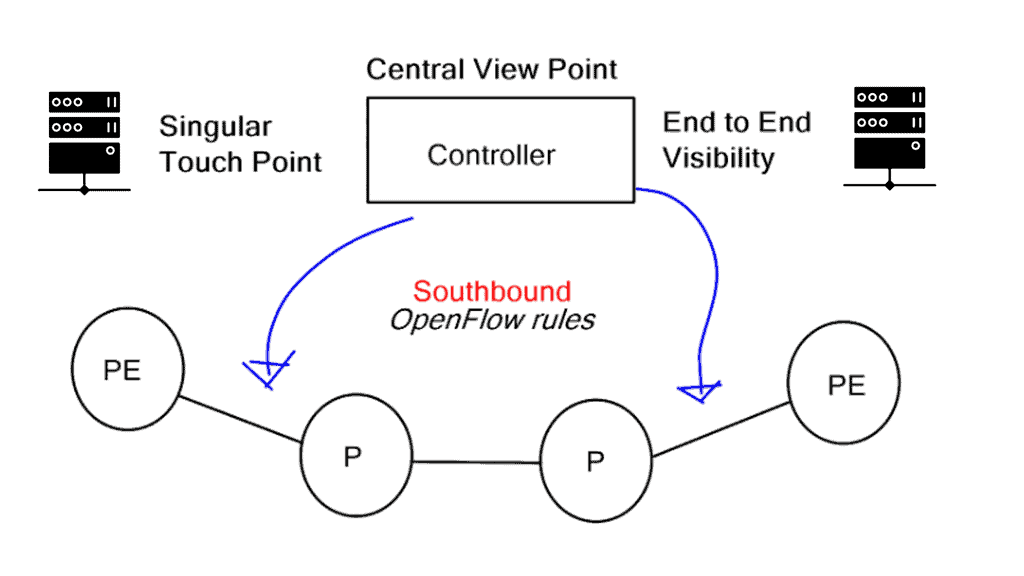
An augmented model uses a centralized control plane that interacts directly with a distributed control plane (eBGP). Interestingly, the same protocol used to push policy (the southbound interface) is also used to discover and distribute topology and reachability information in this hybrid model implementation.
The Role of SDN
Before we start our journey on BGP SDN, let us first address what SDN means. The Software-Defined Networking (SDN) framework has a large and varied context. Multiple components, including the OpenFlow protocol, may or may not be used. Some evolving SDN use cases leverage the capabilities of the OpenFlow protocol, while others do not require it.
OpenFlow is only one of those protocols within the SDN architecture. This post addresses using the Border Gateway Protocol (BGP) as the transfer protocol between the SDN controller and forwarding devices, enabling BGP-based SDN, also known as BGP SDN.
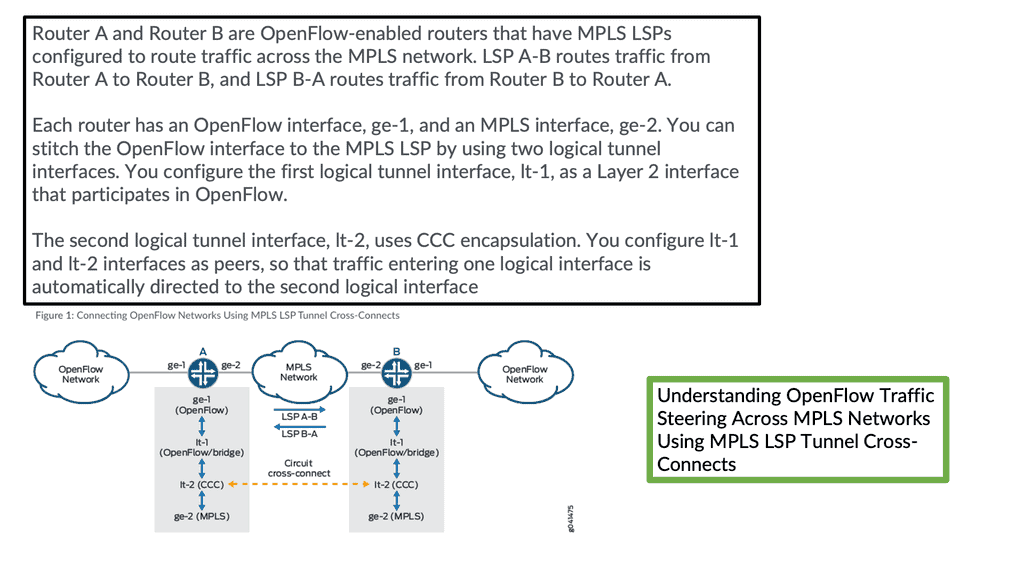
BGP and OpenFlow
– BGP and OpenFlow are monolithic, meaning they are not used simultaneously. Integrating BGP to SDN offers several use cases, such as DDoS mitigation, exception routing, forwarding optimizations, graceful shutdown, and integration with legacy networks.
– Some of these use cases are available using OpenFlow Traffic Engineering; others, like graceful shutdown and integration with the legacy network, are easier to accomplish with BGP SDN.
– When BGP and OpenFlow are combined, they create a powerful synergy that enhances network control and performance. BGP provides the foundation for inter-domain routing and connectivity, while OpenFlow facilitates granular traffic engineering within a domain.
– Together, they enable network administrators to fine-tune routing decisions, balance traffic across multiple paths, and enforce quality of service (QoS) policies.
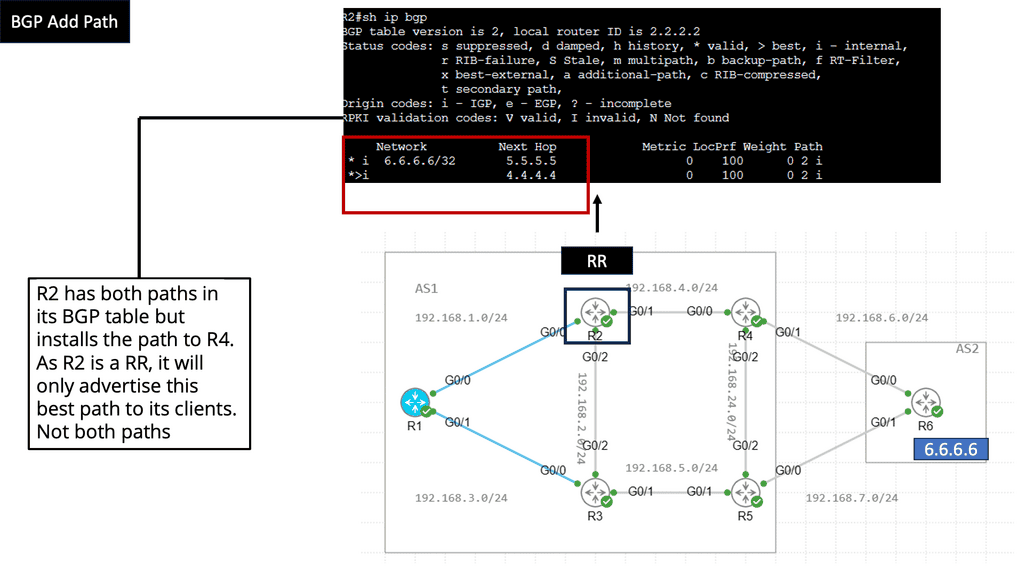
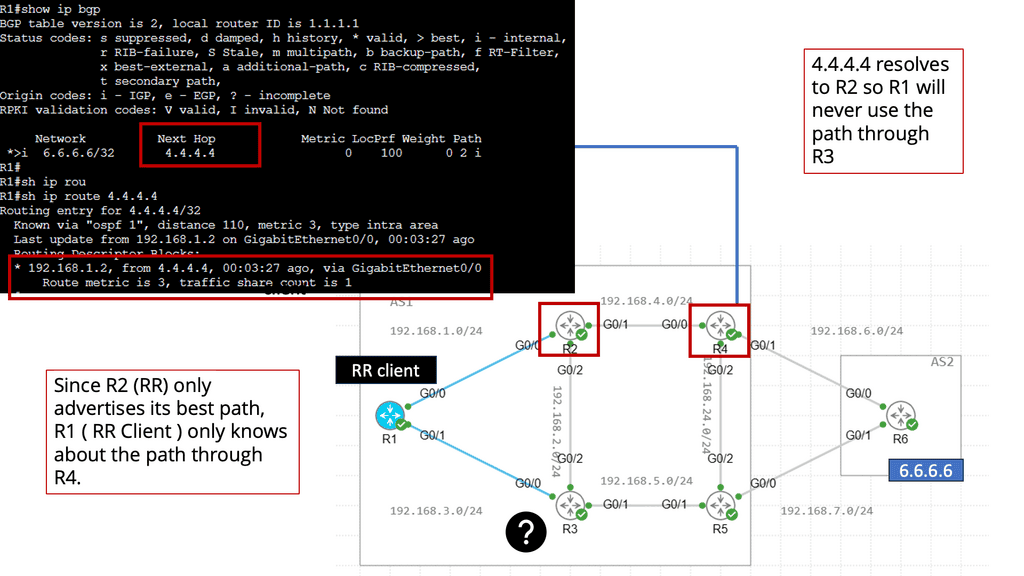
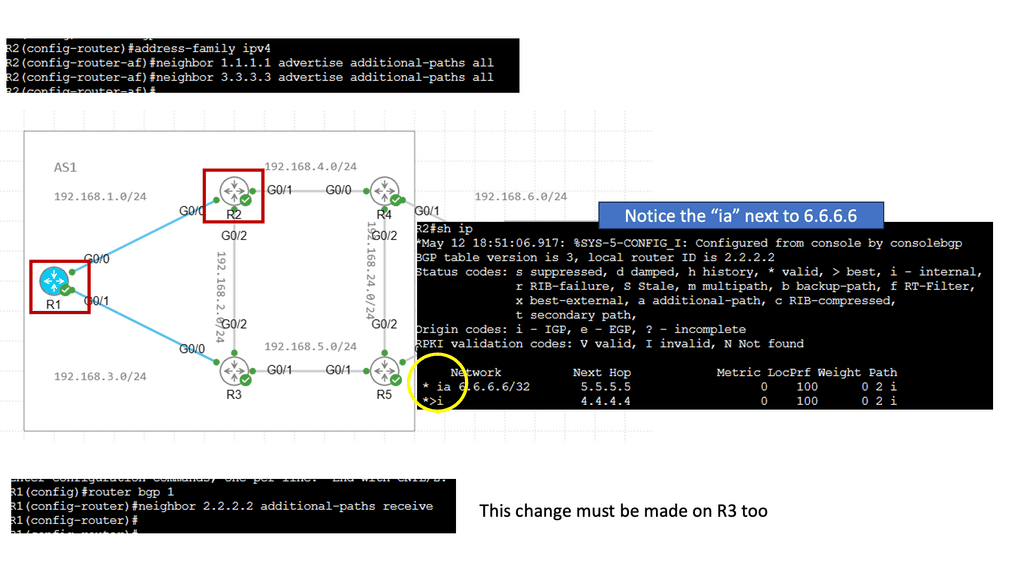
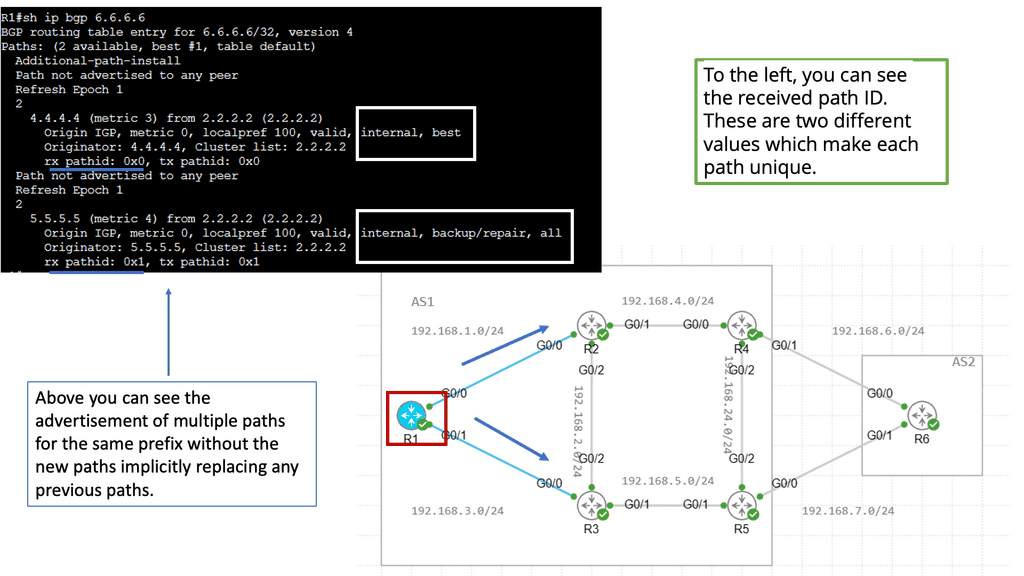
BGP Add Path Feature
The BGP Add Path feature is designed to address the limitations of traditional BGP routing, where only the best path to a destination is advertised. With Add Path, BGP routers can advertise multiple paths to a destination network, providing increased routing options and allowing for more efficient traffic engineering.
Introducing the Add Path feature brings several benefits to network administrators and service providers. Firstly, it enables better load balancing and traffic distribution across multiple paths, leading to optimized network utilization. Additionally, it enhances network resiliency by providing alternative paths in case of link failures or congestion.
Before you proceed, you may find the following post helpful:
What is BGP?
What is the BGP protocol in networking? Border Gateway Protocol (BGP) is the routing protocol under the Exterior Gateway Protocol (EGP) category. In addition, we have separate protocols, which are Interior Gateway Protocols (IGPs). However, IGP can have some disadvantages.
Firstly, policies are challenging to implement with an IGP because of the need for more flexibility. Usually, a tag is the only tool available that can be problematic to manage and execute on a large-scale basis. In the age of increasingly complex networks in both architecture and services, BGP presents a comprehensive suite of knobs to deal with complex policies, such as the following:
• Communities
• AS_PATH filters
• Local preference
• Multiple exit discriminator (MED
Highlighting BGP-based SDN
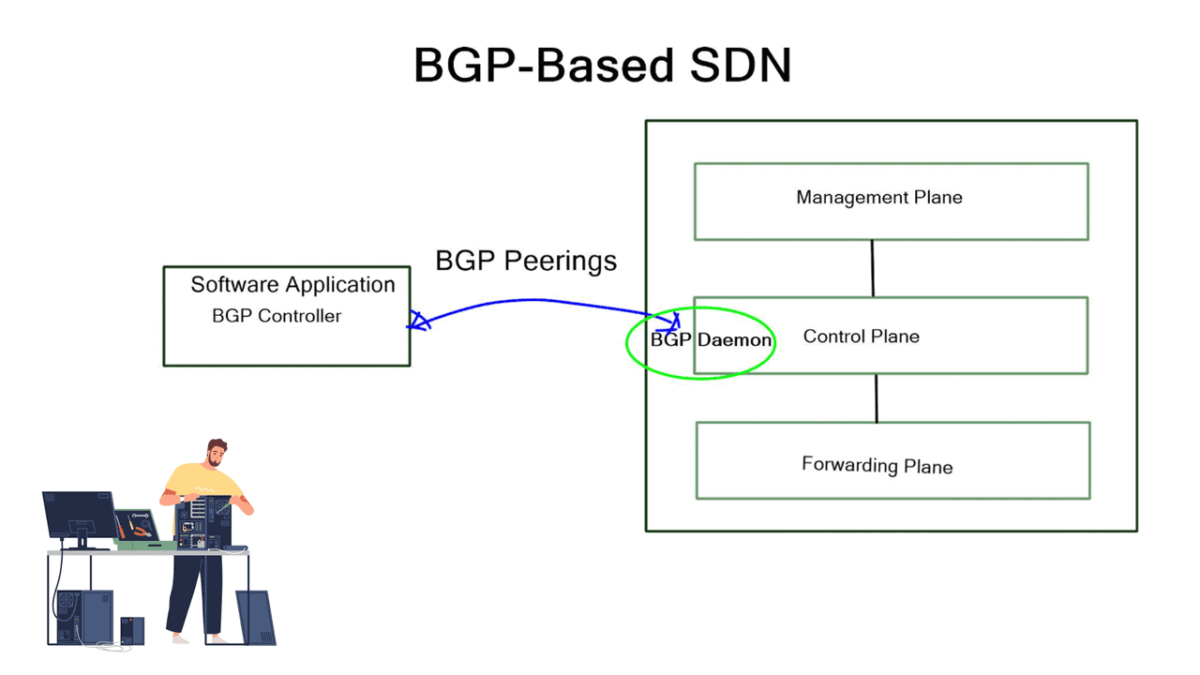
BGP-based SDN involves two main solution components that may be integrated into several existing BGP technologies. First, we have an SDN controller component that speaks BGP and decides what needs to be done. Second, we have a BGP originator component that sends BGP updates to the SDN controller and other BGP peers. For example, the controller could be a BGP software package running on Open Daylight. BGP originators are Linux daemons or traditional proprietary vendor devices running the BGP stack.
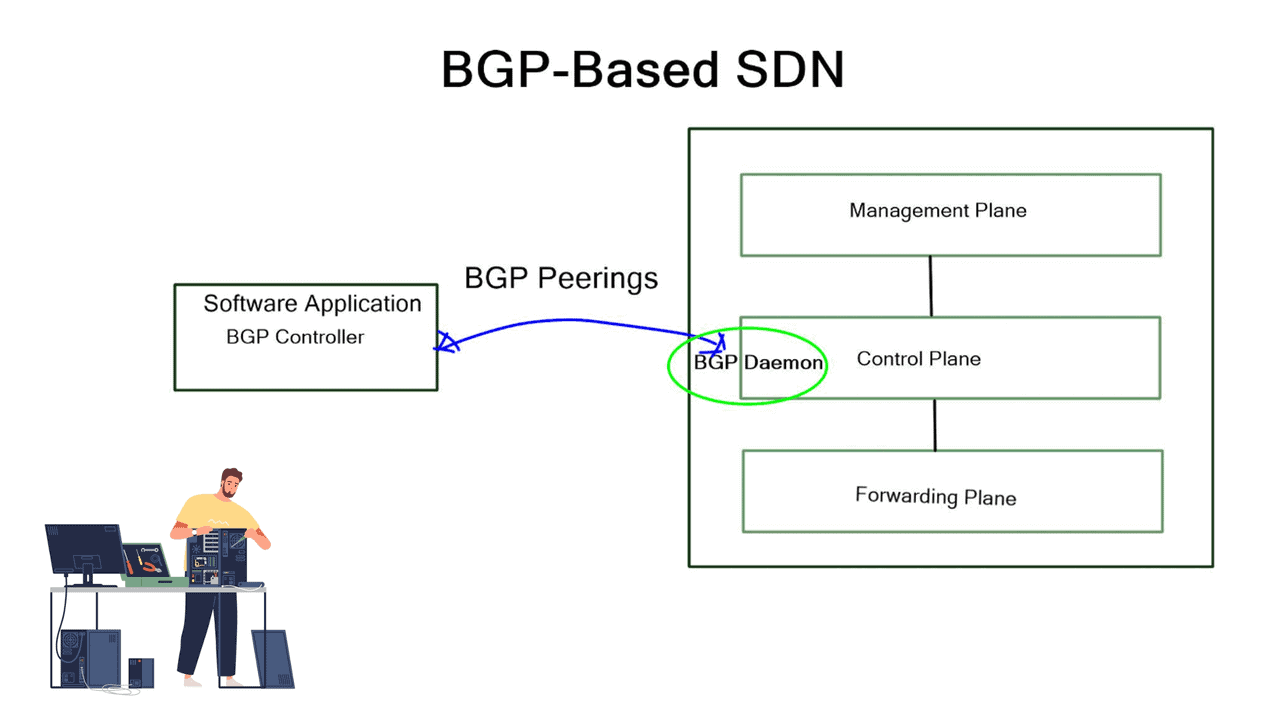
Creating an SDN architecture
To create the SDN architecture, these components are integrated with existing BGP technologies, such as BGP FlowSpec (RFC 5575), L3VPN (RFC4364), EVPN (RFC 7432), and BGP-LS. BGP FlowSpec distributes forwarding entries, such as ACL and PBR, to devices’ TCAMs. L3VPN and EVPN offer the mechanism to integrate with legacy networks and service insertion. BGP-LS extracts IGP network topology information and passes it to the SDN controller via BGP updates.
**Central policy, visibility, and control**
Introducing BGP into the SDN framework does not mean a centralized control plane. We still have a central policy, visibility, and control, but this is not a centralized control plane. A centralized control plane would involve local control plane protocols establishing adjacencies or other ties to the controller. In this case, the forwarding devices outright require the controller to forward packets; forwarding functionality is limited when the controller is down.
If the BGP SDN controller acts as a BGP route reflector, all announcements go to the controller, but the network runs fine without it. The controller is just adding value to the usual forwarding process. BGP-based SDN architecture augments the network; it does not replace it.
Decentralizing the control plane is the only way; look at Big Switch and NEC’s SDN design changes over the last few years. Centralized control planes cannot scale.
Why use BGP?
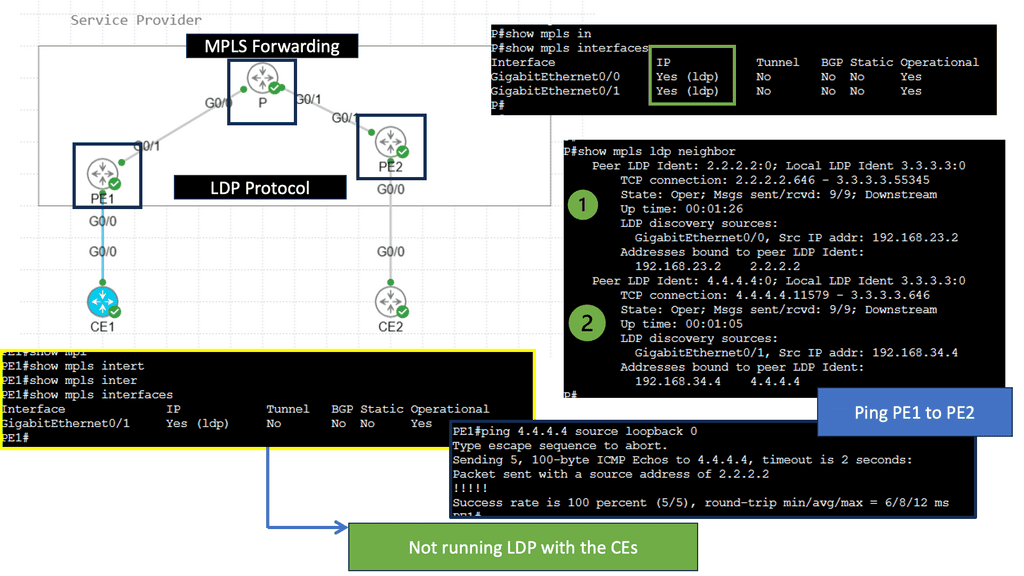
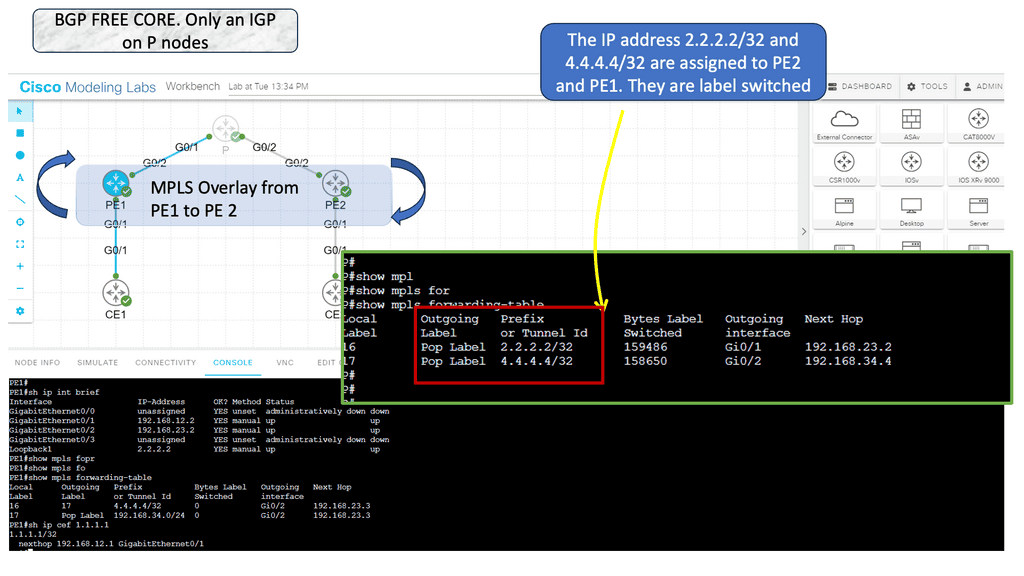
BGP is well-understood and field-tested. It has been extended on many occasions to carry additional types of information, such as MAC addresses and labels. Technically, BGP can be used as a replacement for Label Distribution Protocol (LDP) in an MPLS core. Labels can be assigned to IPv6 prefixes (6PE) and labeled switched across an IPv4-only MPLS core.
BGP is very extensible. It started with IPv4 forwarding, and address families were added for multicast and VPN traffic. Using multiple addresses inside a single BGP process was widely accepted and implemented as a core technology. The entire Internet is made up of BGP, and it carries over 500,000 prefixes. It’s very scalable and robust. Some MPLS service providers are carrying over 1 million customer routes.
The use of open-source BGP daemons
There are many high-quality open-source BGP daemons available. Quagga is one of the most popular, and its quality has improved since it adopted Cumulus and Google. Quagga is a routing suite that provides IGP support for IS-IS and OSPF. Also, a BIRD daemon is available. The implementation is based around Internet exchange points as the route server element. BIRD is currently carrying over 100,000 prefixes.
Using BGP-based SDN on an SDN controller integrates easily with your existing network. You don’t have to replace any existing equipment, deploy the controller, and implement the add-on functionality that BGP SDN offers. It enables a preferred step-by-step migration approach, not a risky big bang OpenFlow deployment.
IGP to the controller?
Why not run OSPF or ISIS to the controller? IS-IS is extendable with TLVs and, too, can carry a variety of information. The real problem is not extensibility but the lack of trust and policy control. IGP extension to the SDN controller with few controls could present a problem. OSPF sends LSA packets; there is no input filter. BGP is designed with policy control in mind and acts as a filter by implementing controls on individual BGP sessions.
BGP offers control on the network side and predicts what the controller can do. For example, the blast radius is restricted if the controller encounters a bug or is compromised. BGP also provides excellent policy mechanisms between the SDN controller and physical infrastructure.
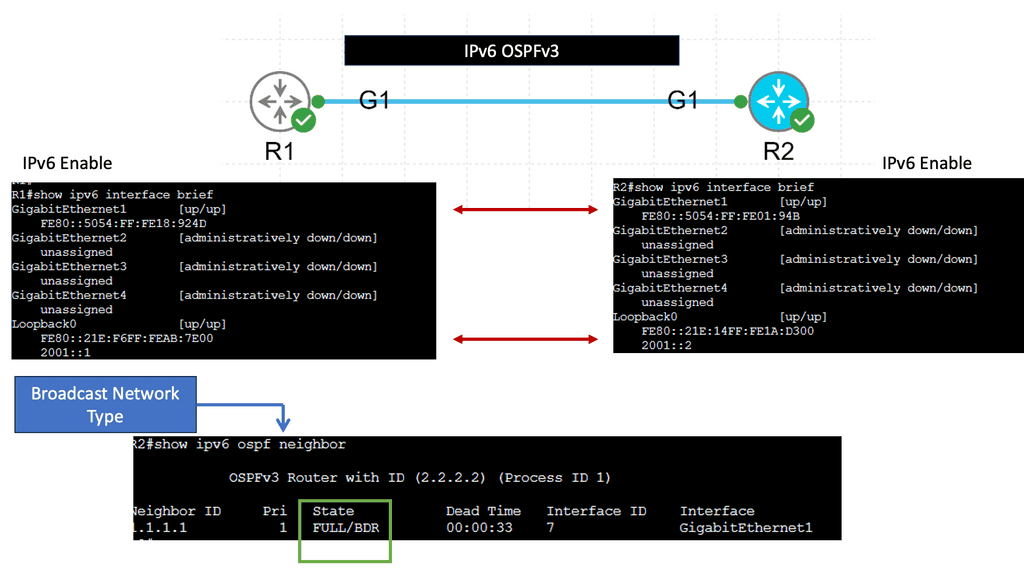
Example IGP Technology: IPv6 OSPFv3
**The Evolution from OSPFv2 to OSPFv3**
OSPFv2, originally developed for IPv4, has been a reliable protocol for decades. However, with the transition to IPv6, a more robust solution was needed to handle the complexities of the new addressing scheme. Enter OSPFv3. This updated version retains the core principles of OSPFv2, such as using link-state routing and the Dijkstra algorithm, but introduces significant improvements. OSPFv3 supports larger address spaces, offers better security options, and is more flexible in its deployment, making it a natural choice for IPv6 networks.
**Key Features of OSPFv3**
One of the standout features of OSPFv3 is its address family support, which allows for the simultaneous routing of both IPv4 and IPv6. This dual capability is essential for networks transitioning between the two protocols. Additionally, OSPFv3 enhances security through the use of IPsec for authentication and confidentiality, addressing the vulnerabilities present in OSPFv2. The protocol also introduces a simplified packet structure, reducing overhead and increasing efficiency in data transmission.
**Implementing OSPFv3 in Your Network**
For network administrators, implementing OSPFv3 can seem daunting, but the benefits far outweigh the challenges. The protocol’s compatibility with both IPv4 and IPv6 means that it can be integrated into existing infrastructure with minimal disruption. When setting up OSPFv3, it’s crucial to ensure that all routers in the network are configured correctly to prevent routing loops and ensure seamless data flow. Regularly updating network configurations and monitoring performance can help maintain optimal operation.
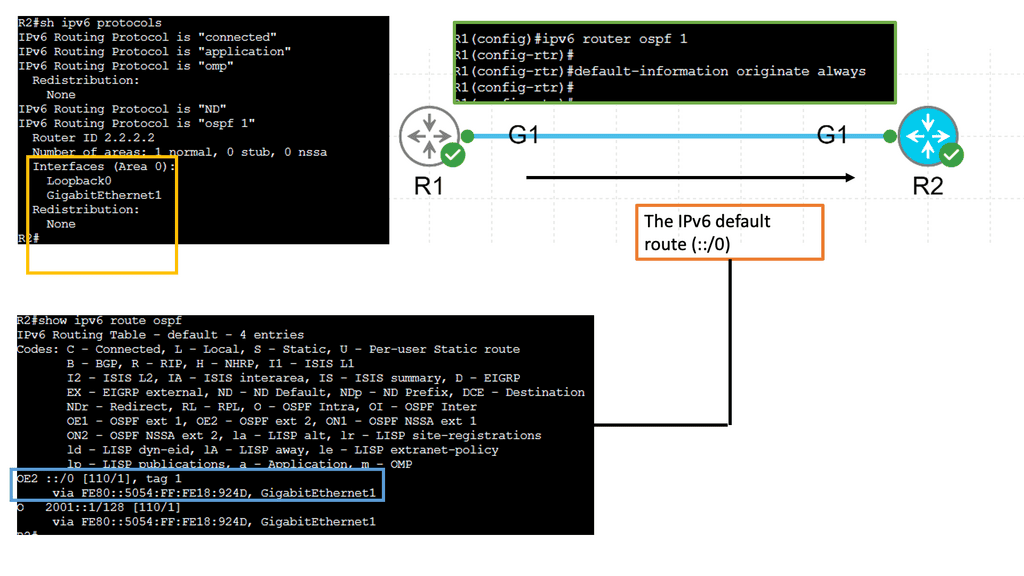
Introducing BGP-LS
SDN requires complete topology visibility. The picture is incomplete if some topology information is hidden in IGP and other NLRIs in BGP. If you have an existing IGP, how do you propagate this information to the BGP controller? Border Gateway Protocol Link-State (BGP-LS) is cleaner than establishing an IGP peering relationship with the SDN controller.
BGP-LS extracts network topology information and updates it to the BGP controller. Once again, BGPv4 is extended to provide the capability to include the new Network Layer Reachability Information (NLRI) encoding format. It sends information from IS-IS or OSPF topology database through BGP updates to the SDN controller. BGP-LS can configure the session to be unidirectional and stop incoming updates to enhance security between the physical and SDN worlds.
SDN controller cannot leak information back
As a result, the SDN controller cannot leak information back into the running network. BGP-LS is a relatively new concept. It focuses on the mechanism to export IGP information and does not describe how the SDN controller can use it. Once the controller has the complete topology information, it may be integrated with traffic engineers and external path computing solutions to interact with information usually only carried by an IGP database.
For example, the Traffic Engineering Database (TED), built by ISIS and OSPF-TE extensions, is typically distributed by IGPs within the network. Previously, each node maintained its own TED, but now, this can be exported to a BGP RR SDN application for better visibility.
BGP scale-out architectures
SDN controller will always become the scalability bottleneck. It can scale better when it’s not participating in data plane activity, but eventually, it will reach its limits. Every controller implementation eventually hits this point. The only way to grow is to scale out.
Reachability and policy information is synchronized between individual controllers. For example, reachability information can be transferred and synchronized with MP-BGP, L3VPN for IP routing, or EVPN for layer-2 forwarding.
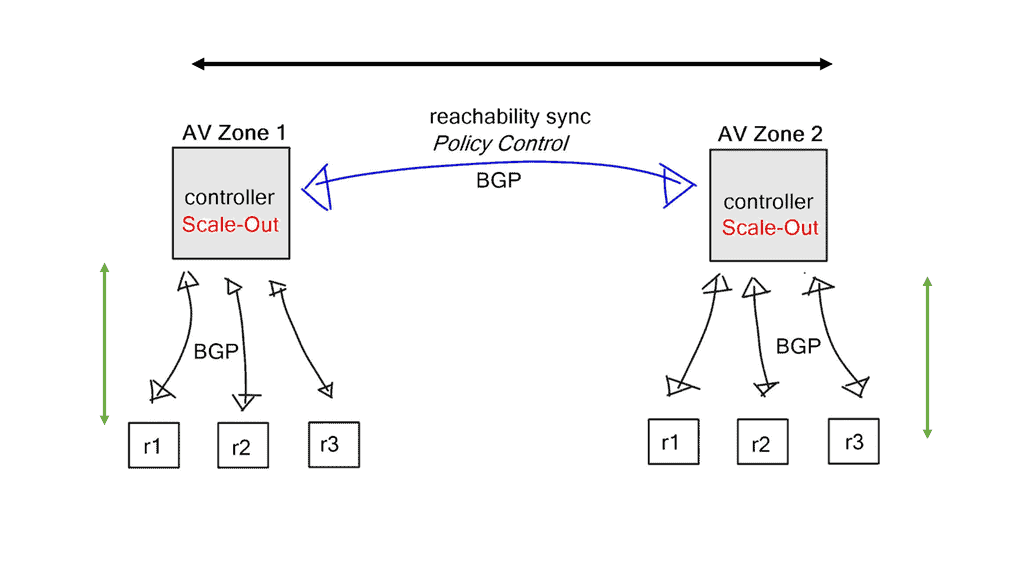
Utilizing BGP between controllers offers additional benefits. Each controller can be placed in a separate availability zone, and tight BGP policy controls are implemented on BGP sessions connecting those domains, offering a clean failure domain separation.
An error in one available zone is not propagated to the next available zone. BGP is a very scalable protocol, and the failure domains can be as large as you want, but the more significant the domain, the longer the convergence times. Adjust the size of failure domains to meet scalability and convergence requirements.
Final Points: BGP-Based SDN
To appreciate the value of BGP-based SDN, it is essential to understand its components. BGP, the protocol that powers the internet by determining the best paths for data transmission, offers unparalleled scalability and stability. On the other hand, SDN introduces a dynamic and flexible approach to network management by decoupling the control plane from the data plane. When combined, BGP’s robust path selection and SDN’s centralized control create a network environment that is both resilient and adaptive to changing demands.
One of the primary advantages of integrating BGP with SDN is its ability to enhance network visibility and control. With centralized management, network administrators can implement comprehensive policies that optimize traffic flow, reduce latency, and improve security. Additionally, BGP-based SDN facilitates rapid deployment of new services and applications, enabling businesses to respond swiftly to market changes. This synergy also simplifies network troubleshooting and maintenance, leading to reduced operational costs and increased uptime.
BGP-based SDN is not just a theoretical concept; it is being actively implemented across various sectors. In data centers, it enables efficient resource utilization and supports the seamless scaling of services. Telecommunications companies leverage BGP-based SDN for efficient routing and traffic engineering, ensuring optimal performance and reliability. Furthermore, enterprises adopting hybrid cloud environments benefit from the enhanced connectivity and simplified management that this approach offers, allowing them to maintain competitive advantage in a digital-first world.






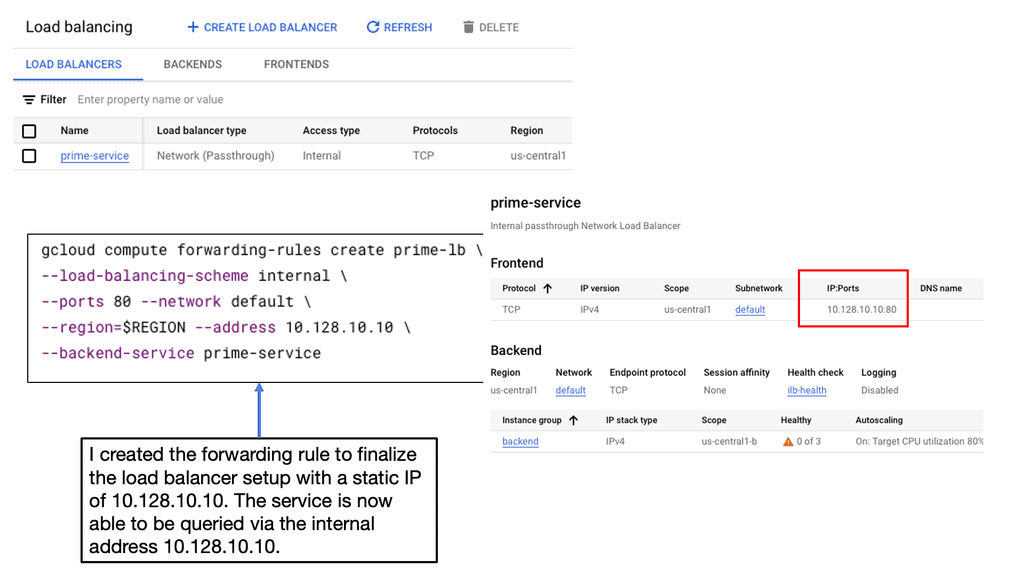
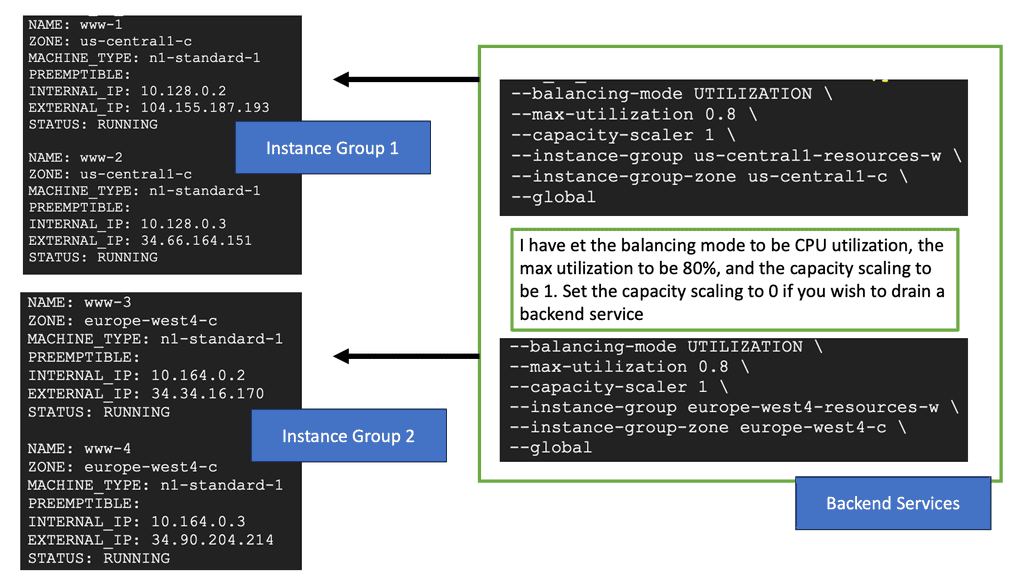
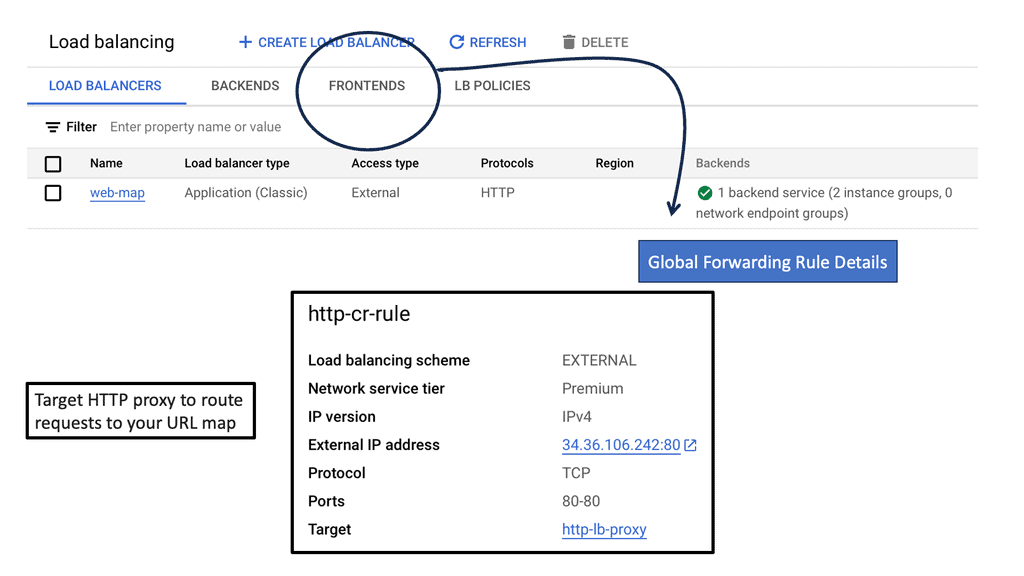
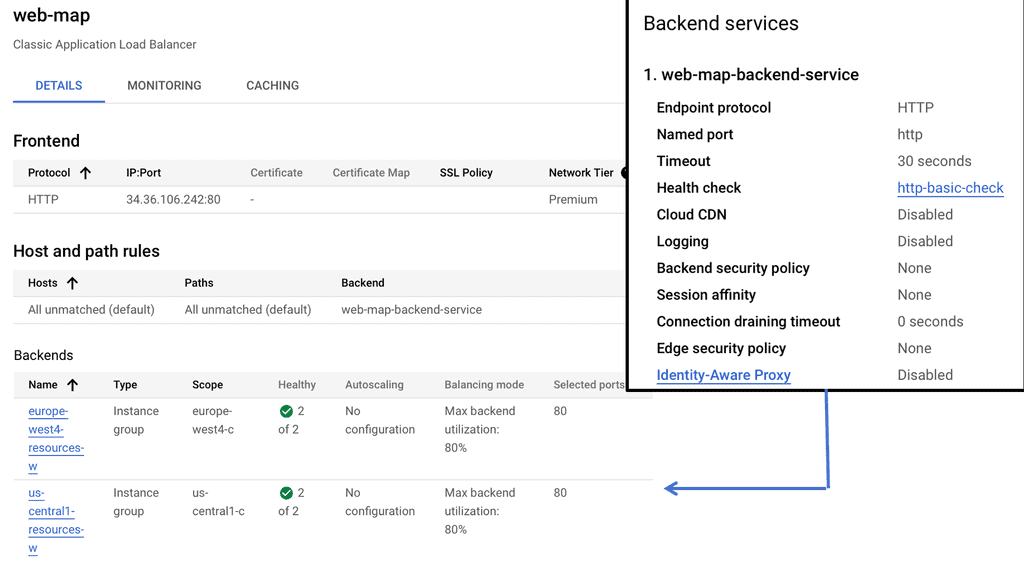


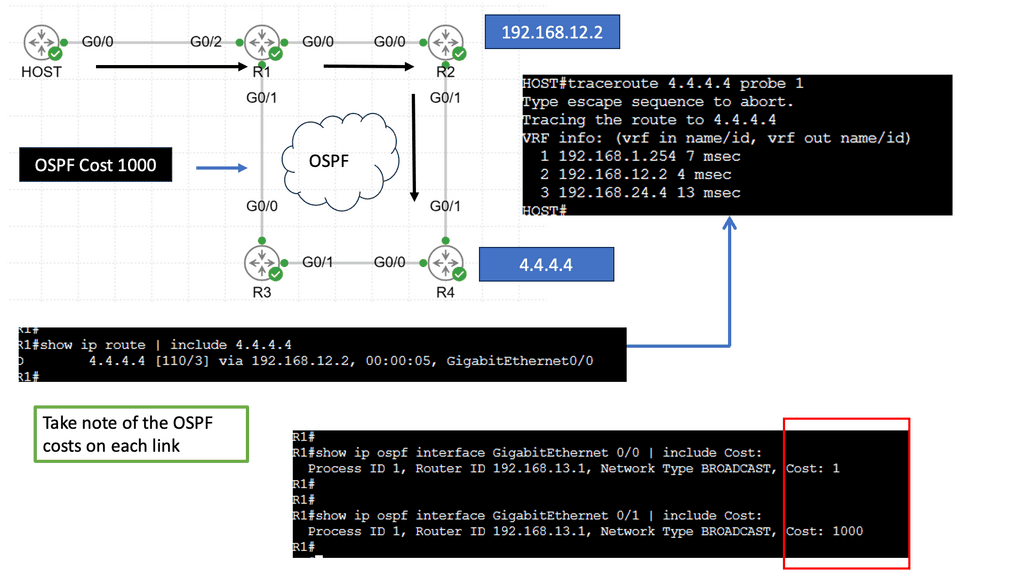
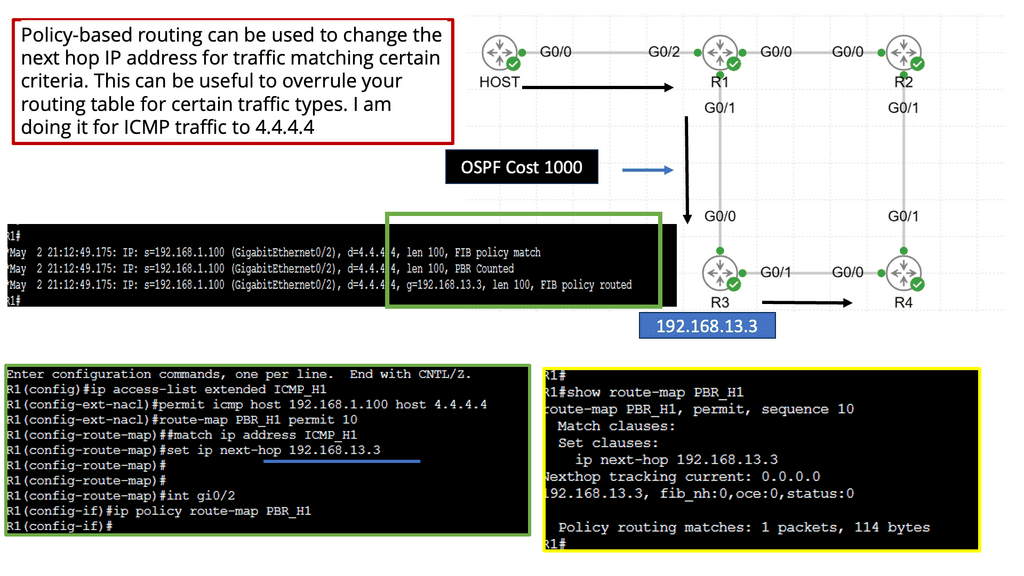
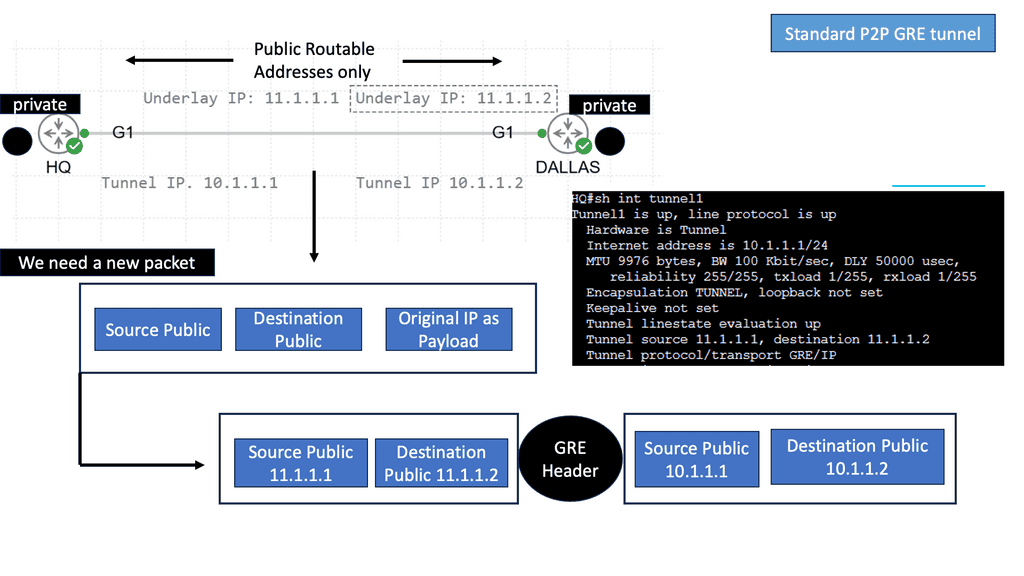
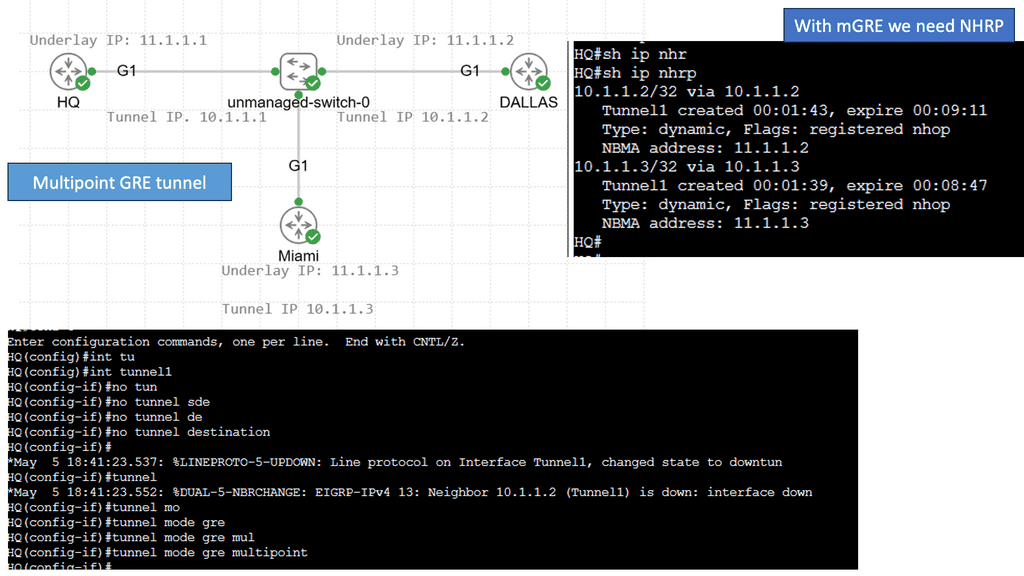

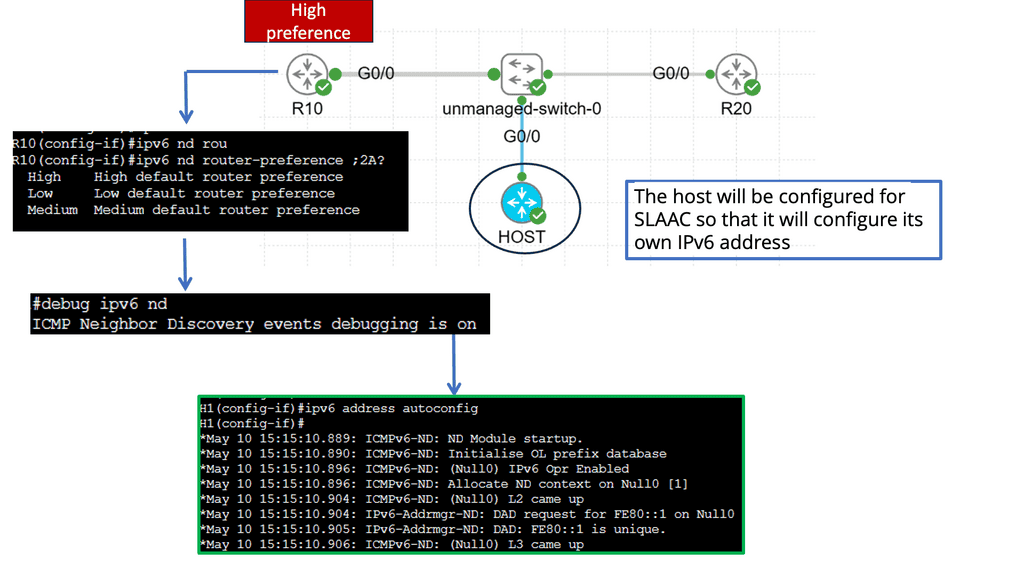
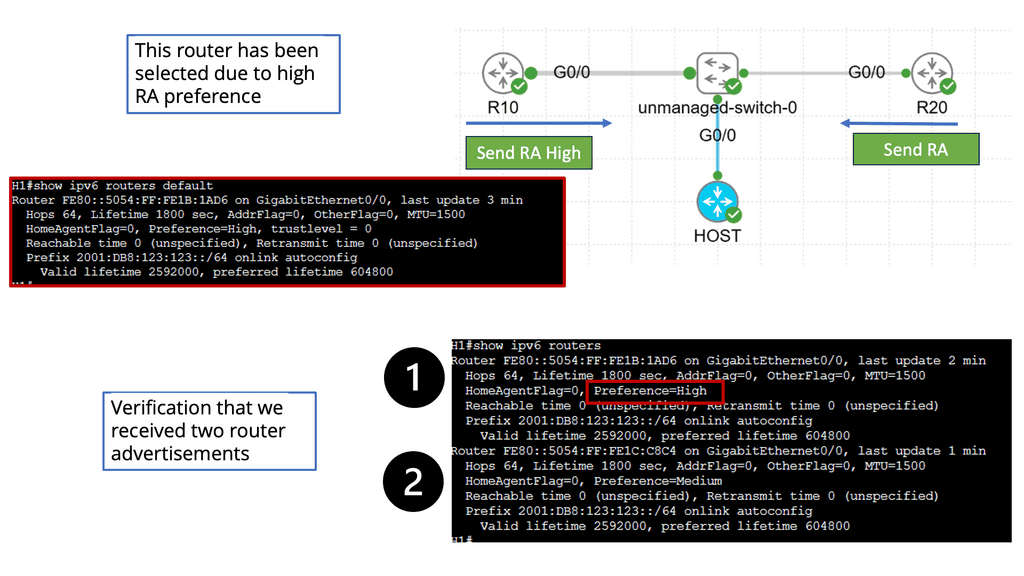
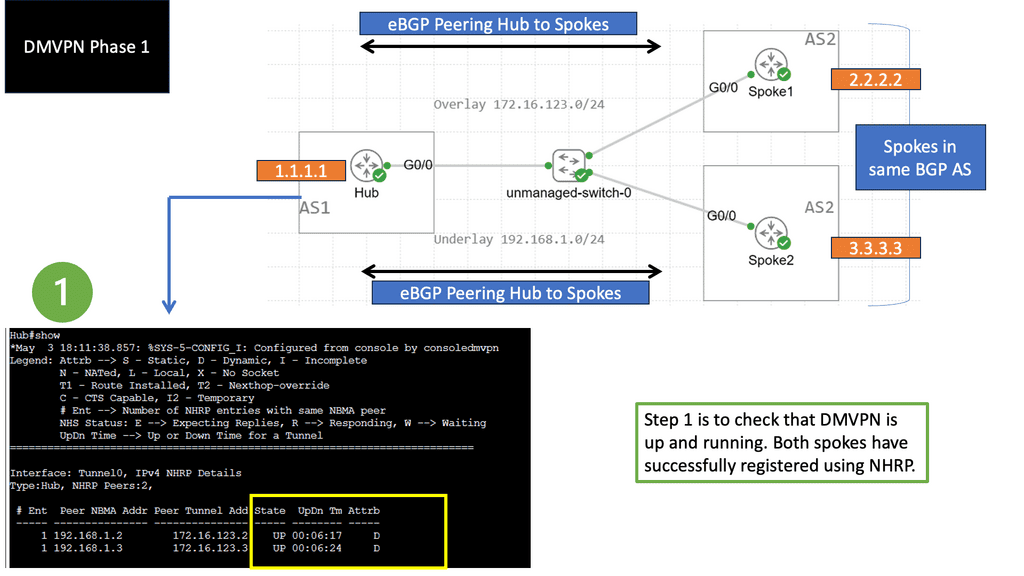
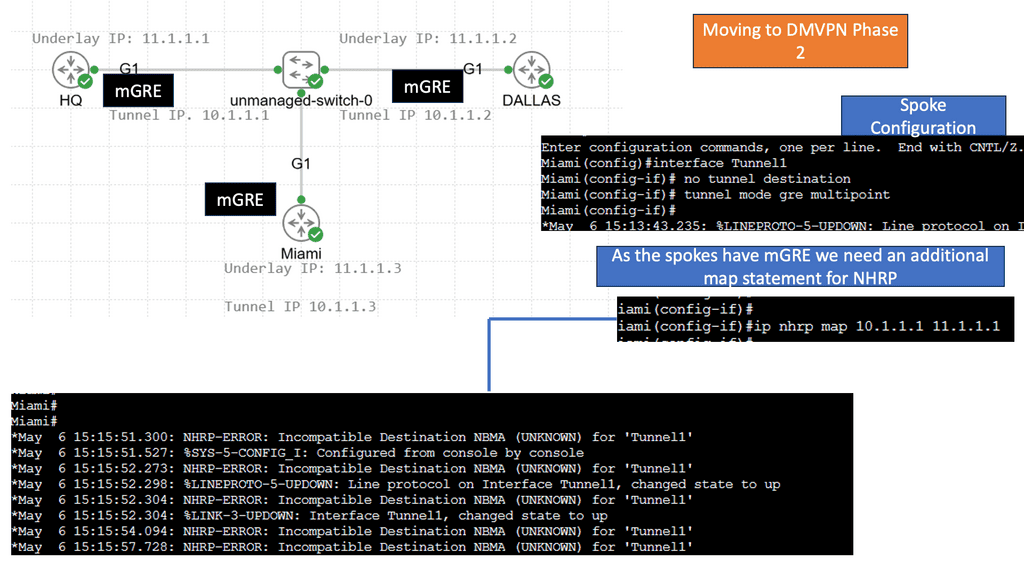
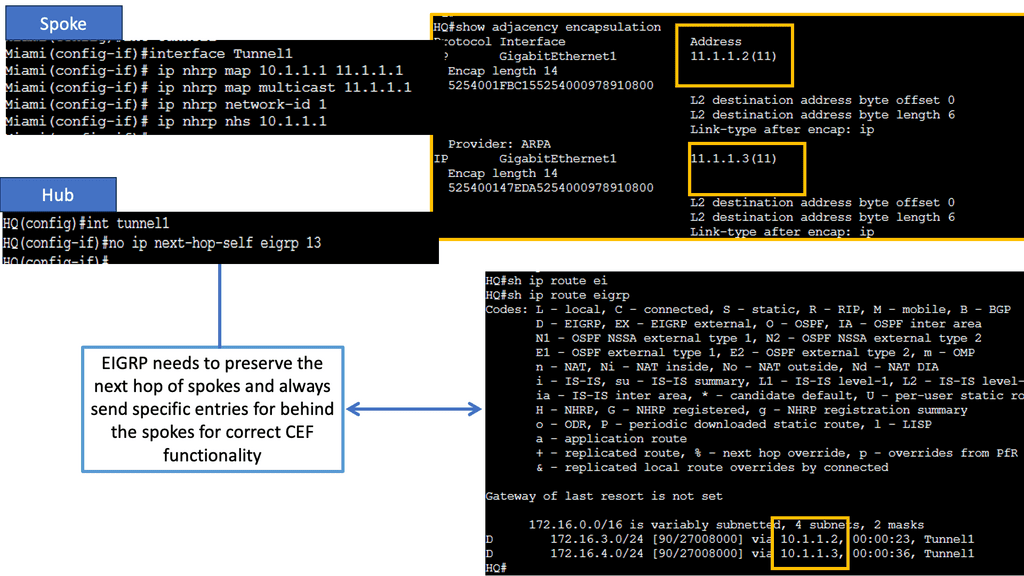
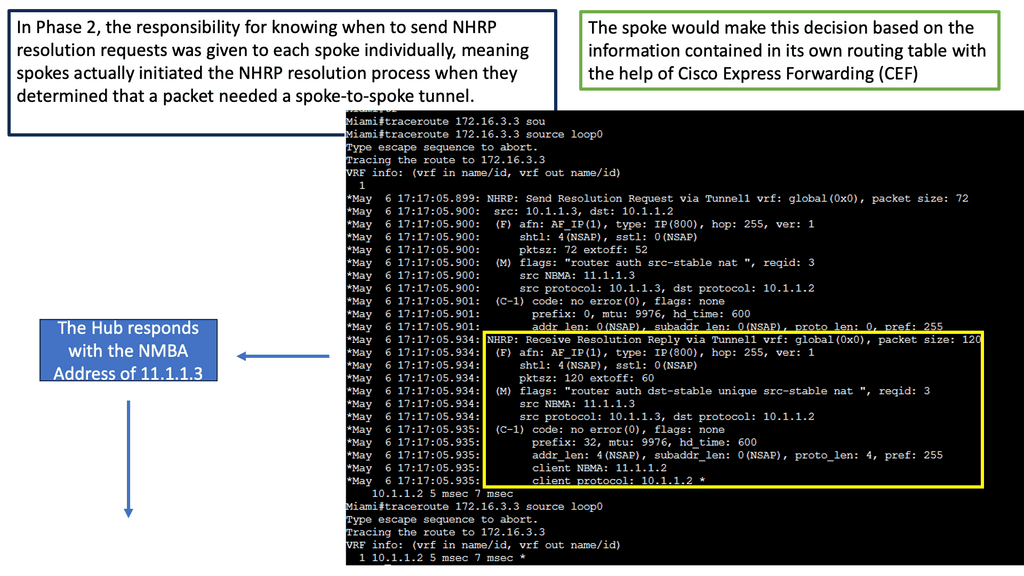
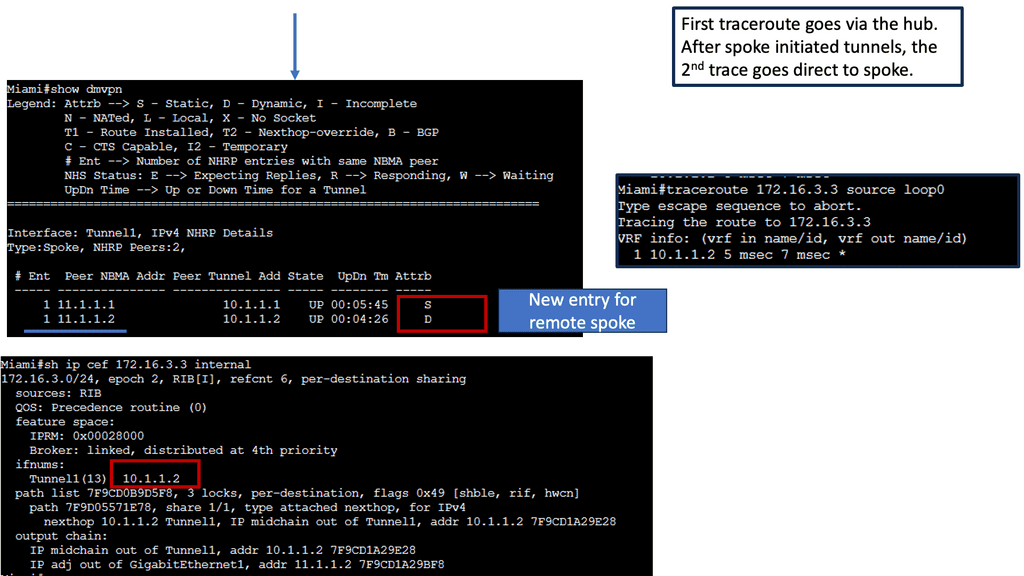
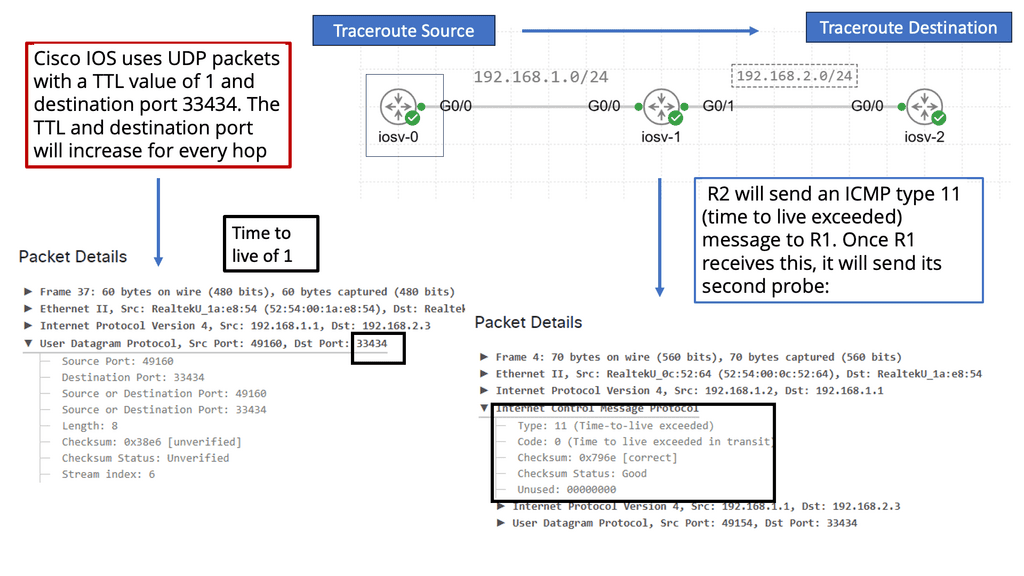
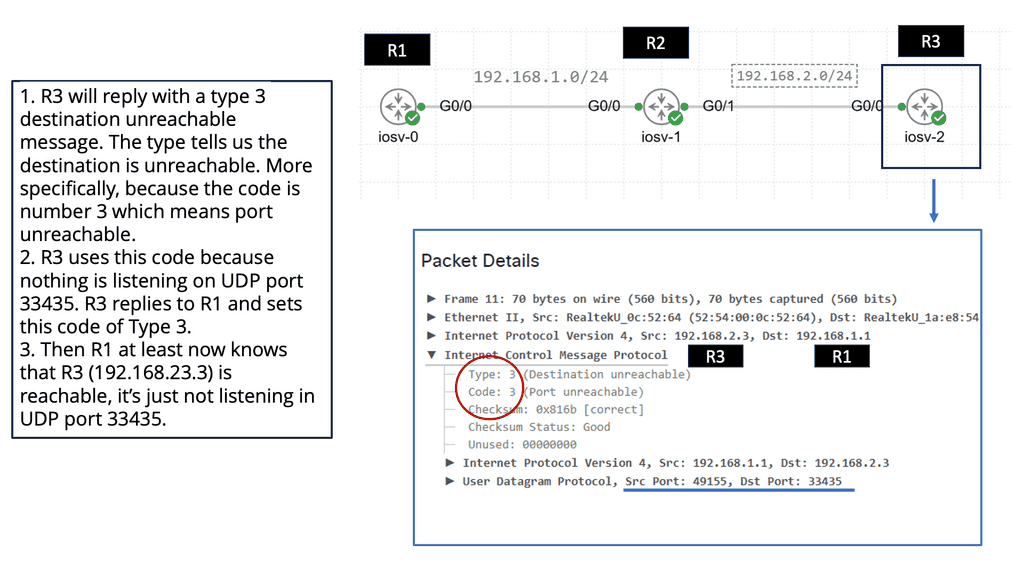
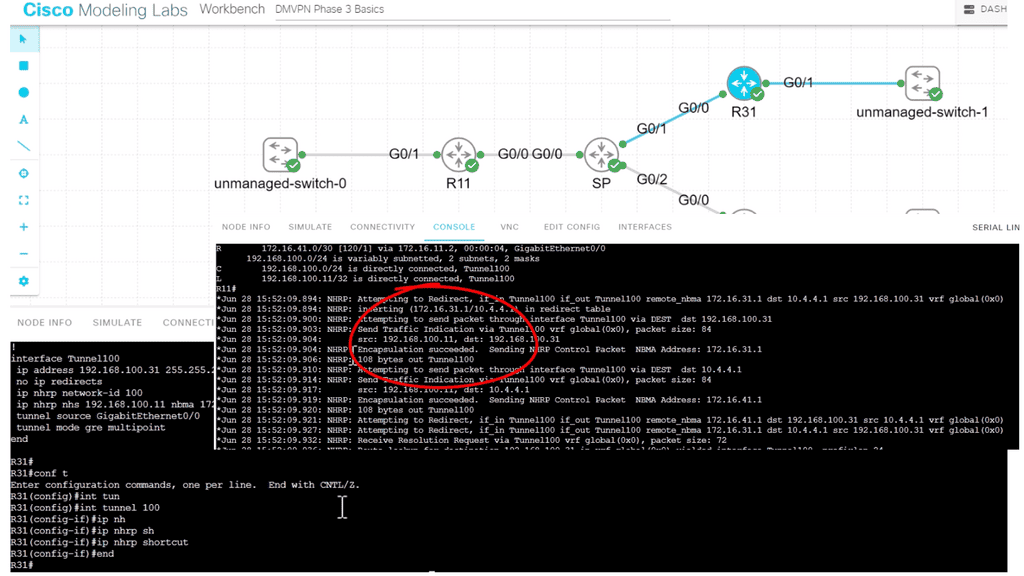
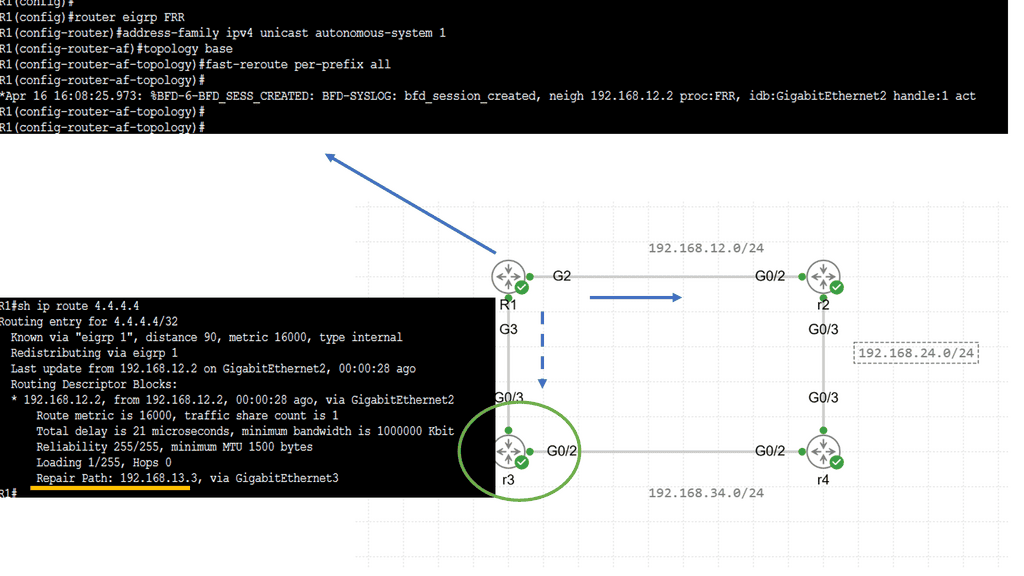 Example: BGP Traffic Engineering with DMVPM
Example: BGP Traffic Engineering with DMVPM