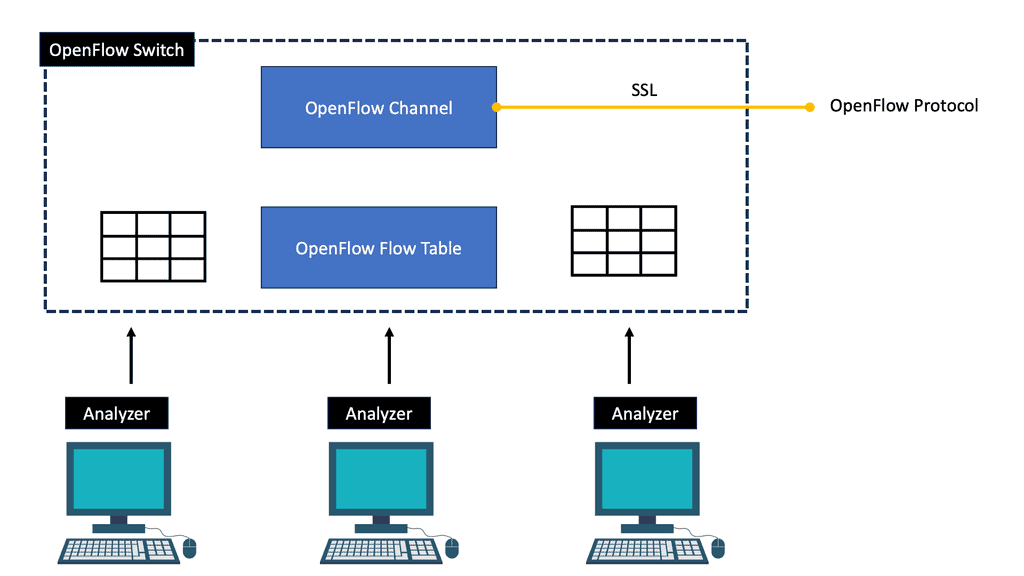
Understanding OpenFlow
OpenFlow serves as a communication interface between a network’s control and forwarding layers. It enables centralized control, allowing network administrators to manage and control network traffic dynamically. OpenFlow provides a flexible and programmable network infrastructure by separating the control plane from the data plane.
Critical Concepts of OpenFlow Application Engineering
Understanding the fundamental concepts of OpenFlow application engineering is crucial to grasp its full potential. These include the flow table, rules, match fields, and actions. The flow table acts as the core component, storing flow rules that define how packets are processed within the network. Match fields specify the criteria for matching incoming packets, while actions determine how the matched packets should be processed.
OpenFlow application engineering finds applications in various domains. One notable use case is in Software-Defined Networking (SDN), where OpenFlow provides the foundation for implementing dynamic and agile networks. It also finds utility in traffic engineering, network virtualization, and network security. The versatility of OpenFlow application engineering makes it a valuable tool across different industry sectors.
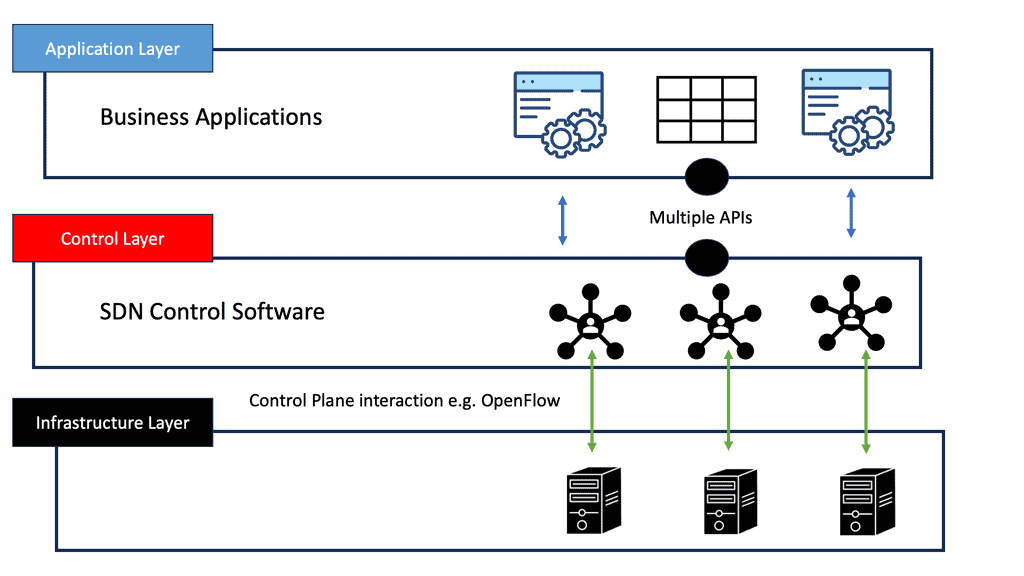
Understanding SDN Application Engineering
SDN application engineering creates software applications that run on top of SDN controllers. These applications utilize the programmability and centralized control offered by SDN to provide innovative network services and functionalities. By separating the control plane from the data plane, SDN enables developers to build applications that dynamically control network behavior.
Tools and Technologies in SDN Application Engineering
Engineers utilize a range of tools and technologies to develop SDN applications. SDN controllers like OpenDaylight and ONOS are the foundation for building applications. Programming languages such as Python and Java are commonly used for application development. Additionally, frameworks like Ryu and Floodlight provide libraries and APIs to simplify the development process.
Use Cases and Applications
SDN application engineering opens up a world of possibilities for network innovation. Some popular use cases include traffic engineering, network monitoring and analytics, load balancing, and security. For example, an SDN application can intelligently reroute traffic to avoid congestion or analyze network data in real-time to detect anomalies and potential security threats.
The Challenges With Traditional Data Centers
Considering application-aware networking, mobility, and dynamic bandwidth provisioning forces us to rethink how we design networks. Traditional data center topologies utilize a hierarchical approach, encompassing several bandwidth aggregation points at different layers. We build networks with a fixed size and adapt the application to the network. Data centers are designed to have a fixed oversubscription ratio, for example, 2:1, 4:1, etc.
The Role of ECMP and LAG
But what if you want better oversubscription ratios for individual sets of applications? Equal-cost multipathing (ECMP) and Link aggregation (LAG) mechanisms improve performance, but you still have a reasonably static network. Non-blocking and low oversubscription designs are costly, leaving many sections underused during low utilization periods.
In addition, the following pre-information you may find helpful.
- LISP Protocol
- Triangular Routing
- OpenStack Neutron Security Groups
- What is BGP Protocol in Networking
- Overlay Virtual Networks
- Hyperscale Networking
- Virtual Switch
- HP SDN Controller
Application Aware Network. |
|
Back to Basics With Application-Aware Networking
Traditional Routing Decision Making
So, we have routing algorithms that are used by routing devices. Routing tables are populated by two routing protocols: static and dynamic. The process of making their routing decisions is simple:
- A router receives data from another device and checks the destination IP address.
- If it is its address, it will process it internally and do nothing more.
- However, if the address is for one of the networks connected to it or a remote network, the router looks it up in its routing table. The routing tables are on each router and hold all the destinations.
- It then identifies the next router’s IP address, the next hop, and the interface to which the data needs to be sent.
Benefits of Application-Aware Networking:
1. Enhanced Performance: By understanding the requirements of various applications, AAN can allocate network resources dynamically and prioritize critical traffic, ensuring optimal performance for time-sensitive applications such as video streaming, voice-over IP (VoIP), or real-time collaboration tools.
2. Improved User Experience: AAN provides a better user experience by reducing latency, packet loss, and jitter. It ensures that applications with high bandwidth demands, like video conferencing or cloud-based applications, receive the necessary network resources, resulting in smooth and uninterrupted user experiences.
3. Increased Efficiency: AAN optimizes network utilization by identifying and classifying different types of traffic. This allows network administrators to implement Quality of Service (QoS) policies, ensuring that critical applications receive the necessary bandwidth while preventing non-business-related applications from consuming excessive network resources.
4. Network Security: AAN enables the implementation of more granular security policies by identifying and controlling application-level traffic. It allows network administrators to enforce security measures specific to each application, protecting the network from potential threats and unauthorized access.
Case study: Plexxi and Application Aware Networking
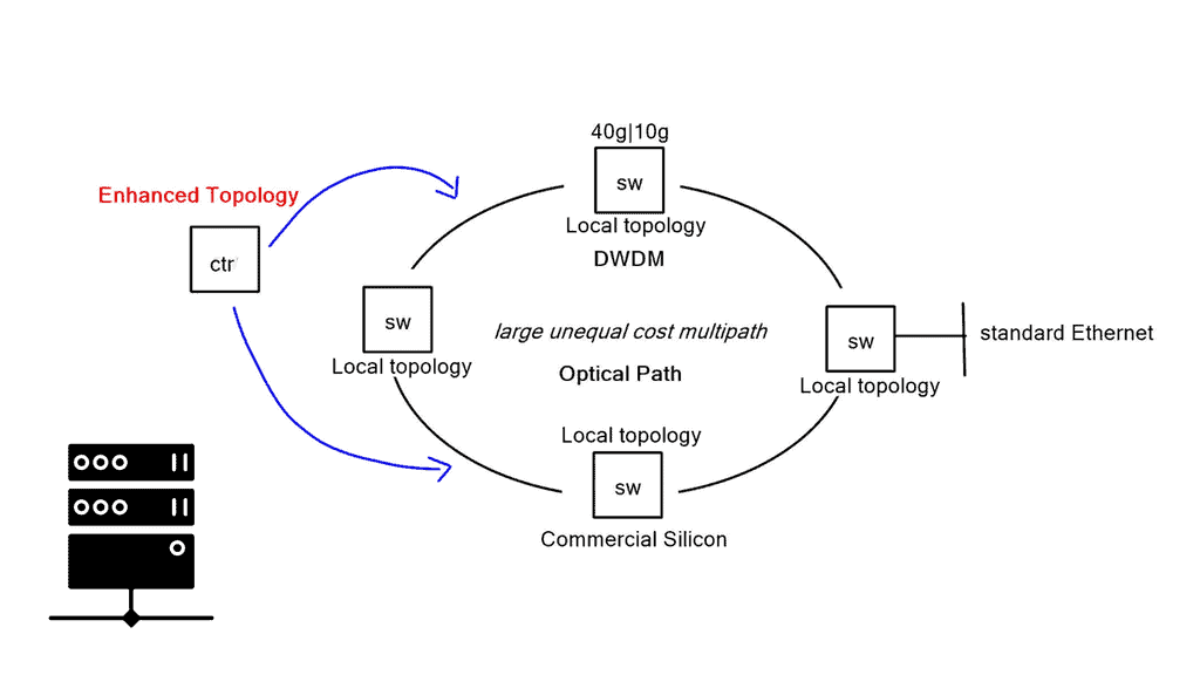
Plexxi has a solution encompassing a central controller, ethernet switches, and an optical backplane. The switches are physically connected with a Ring topology, and dense wavelength division multiplexing (DWDM) operates on top for topology flexibility. At a basic level, they group applications into affinity groups and tie them together with an expression. Different bandwidth and path characteristics are tied to individual affinity groups, and the controller downloads traffic topology optimizations to local nodes. Plexxi aims to reverse the traditional design process and let the application dictate what kind of network it wants.
A key point in Application-aware networking
Application-aware networking is the idea that application visibility combined with network dynamism will create an environment where the network can react to the changing behavior of application mobility and bandwidth allocation requirements. Networks should be designed around conversions, but when you design a network, it is usually designed around reachability.
A conversational view measures network resources differently, such as application SLA and end-to-end performance. The focus is not just uptime. We need a mechanism to describe applications abstractly and design the network around conversations. The Plexxi affinity model is about taking a high-level abstraction of what you want to do, letting the controller influence the network, and taking care of the low-level details.
Affinity is a policy language that dictates how you want the network to behave to a specific affinity group. Specific bandwidth and conservation priority are set to affinity groups, prioritizing them over standard types of traffic.
Plexxi components of application-aware networking
Plexxi provides ethernet hardware switching equipment with an optical fabric backplane. The optical backplane fabric allows better scaling, end-to-end latency, and dynamic path control. They use DWDM optics and cross-connect technology built into the switch, creating a wired Ring topology. The physical cabling is based on Ring, but they use DWDM technology to connect switches flexibly and logically.
They have chosen DWDM as the transport due to its flexibility. DWDM enables topology changes based on where the light waves are terminating. For direct switch-to-switch connectivity, it can passively pass through intermediate switches. They are effectively permitting any-to-any or partial mesh connectivity models.
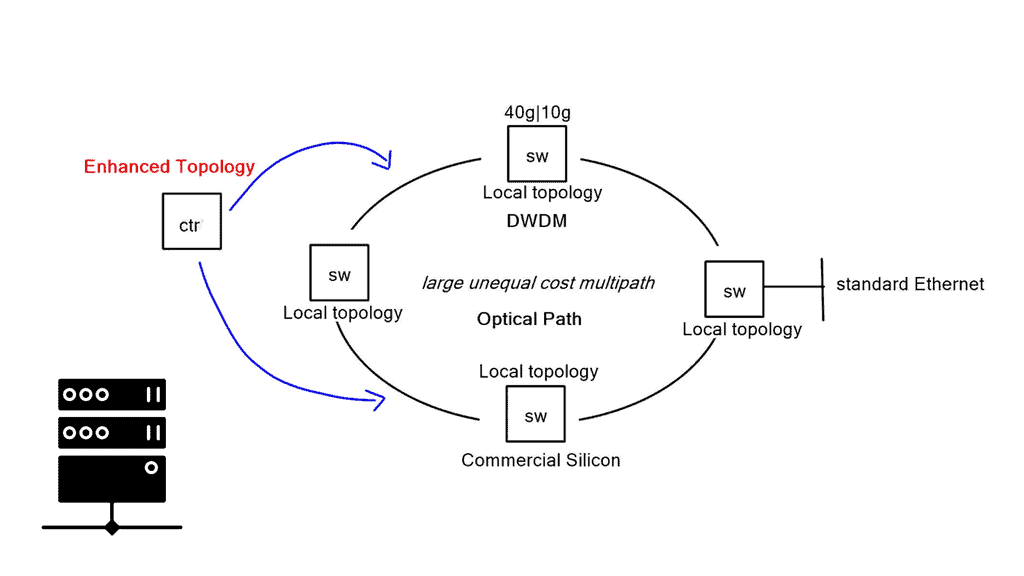
Ring based design
The ring-based design allows you to do large, unequal-cost multipath flat designs. As traffic traverses the Ring, it is not constantly traversing hop-by-hop; it may skip devices by having a direct Lambda interconnect. Now, there is a load of interconnecting paths between switches, forcing Plexxi to revisit how we forward packets.
Traditional Layer 2 and Layer 3 is always the shortest path between two points. They are resulting in ECMP-style load sharing. Plexxi switches have many possible combinations, and the typical ECMP forwarding model wouldn’t let you get all the bandwidth from these links.
The controller
At a Packet level, the controller discovers the topology and runs algorithms. It determines all the possible paths and sets a policy for optimal forwarding to the local switches. The controller solves the paths algorithmically. Potentially, there could be hundreds of different possible topologies available through the fabric. As a result, the Plexxi solution allows massive unequal cost load balancing between each endpoint.
They can stitch optical paths from one point to another at an Optical level. If you require high bandwidth between two switches, dedicate bandwidth and tailor your topology based on Lambda. Forwarding policies are then pushed down to the fabric, which optimizes and isolates traffic between those points.
Affinity networking & grouping
Affinity fabrics classify two types of traffic: affinity (priority) and Normal. Affinity traffic is explicitly controlled by TCAM entries specified for network path control. It relates to hand-crafted traffic paths created by the controller. The TCAM rules are pre-engineered, and traffic forwarding is based on manual engineering. Regular traffic occurs when the controller picks a large set of non-ECMP paths and makes them available for endpoints.
Affinity networking
The application must tell us what they want from the network. This is the essence of affinity networking. At a high level, affinity groups are no more than applications grouped by MAC address. Once affinity groups are designed, you can create a line or expression between them. Expressions dictate network sensitivity.
The Role of the Controller
For example, the affinity group “Sales” may require a specific bandwidth or hop count for decreased latency. All this input is fed to the controller. The controller attempts to build the topology based on the MAC address endpoint and affinity groups. It runs algorithms and determines the best possible paths for these applications. Once decided, it downloads the topology information to the local switches.
The controller is not in the data path and holds no network state. If there is a controller failure, the switches can operate by themselves. When we connect Plexxi switches, they will operate like traditional switches because they will learn MAC addresses, flood, and pass packets. The controller optimizes the topology based on the affinity and provides the local switch with an optimization of the topology.
A final note: OpenFlow and TCAM download.
The controller-to-switch communication needs something more than OpenFlow—the TCAM download protocol. They are communication more than flows. They don’t use OpenFlow to communicate the topology to the local switches. The interface they use is proprietary. For the northbound interface, they have a REST API with a GUI. The API allows external companies to tie their provisioning systems to the controller and communicate to the switches.
Future Implications:
As application complexity and network traffic grow, the need for AAN becomes even more critical. The rise of cloud computing, the Internet of Things (IoT), and edge computing further emphasizes the importance of having a network infrastructure that can adapt to each application’s unique demands. AAN paves the way for more intelligent and automated networks, enabling organizations to achieve greater agility, scalability, and flexibility in their operations.
Application Aware Networking is revolutionizing the way networks are managed and optimized. By understanding and adapting to the requirements of different applications, AAN enables organizations to enhance network performance, improve user experiences, increase efficiency, and strengthen network security. As technology advances, AAN will play a pivotal role in meeting the growing demands of modern applications and services, ensuring a seamless and productive digital experience for businesses and individuals alike.

- DMVPN - May 20, 2023
- Computer Networking: Building a Strong Foundation for Success - April 7, 2023
- eBOOK – SASE Capabilities - April 6, 2023
[…] Insight Blogger and industry guru, Matt Conran, featured Plexxi in his October 6 post Application-aware Networking-Plexxi Networks. He believes, “Mobility and dynamic bandwidth provisioning force us to rethink how we design […]
Thank you!