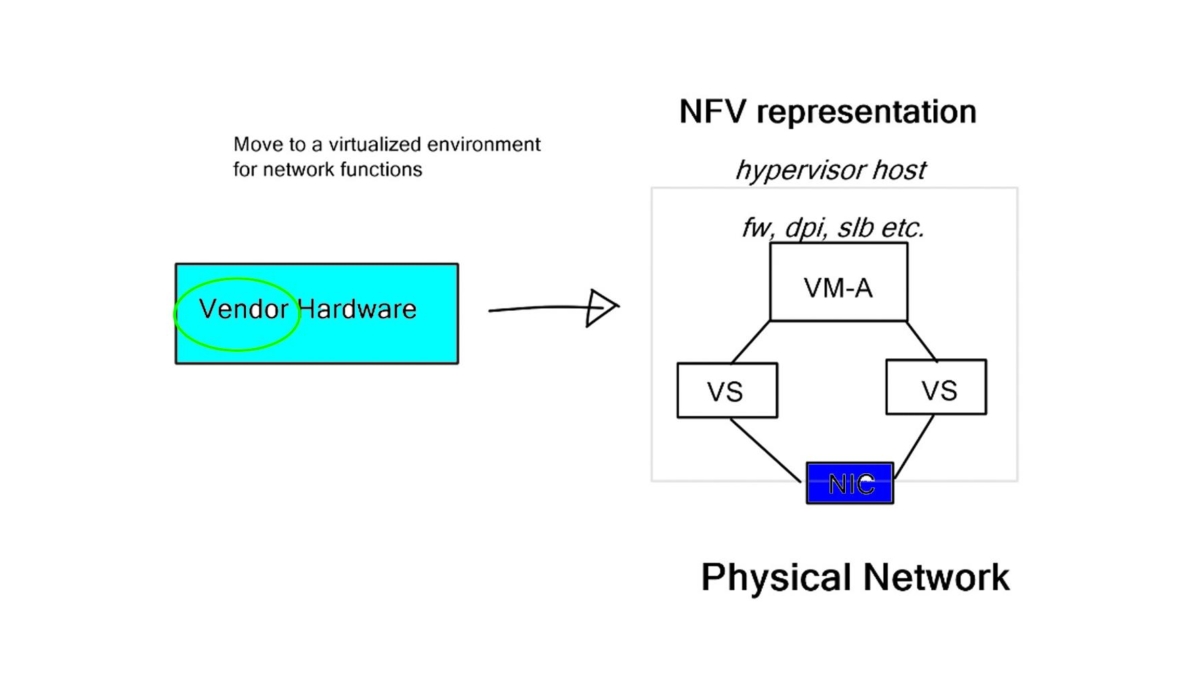
Network Virtualization
In network virtualization, endpoints are grouped logically on a network. As a result of this abstraction, VMs (and other assets) appear, behave, and can be managed as if they were all located on the same physical segment of the network. Even though it is an old technology, it is essential in virtual environments, where assets are created and moved without much regard for location. Automation and management tools have been designed specifically for scalable and elastic virtualized data centers and clouds.
Network Functions Virtualization
Within NFV, Layer 4 through 7 services such as load balancing and firewalling are virtualized. Virtualization enables certain types of network appliances to be easily deployed wherever needed by converting them into virtual machines. Inefficiencies caused by virtualization led to the creation of NFV. Virtualization has been discussed primarily for its benefits but has also caused many problems.
Data center traffic was routed to and from network appliances at the network’s edge. There is a problem for fixed appliances since VMs are springing up and moving around. Virtualizing functions like firewalls can be easily “spun up” and placed where needed, just like virtual machines.
Virtual Networks with VXLAN
Virtual machines supporting applications or services require physical switching and routing to connect to the data center or cloud and clients over a WAN link or the Internet. Data center networks must be secure in addition to load balancing and security. As traffic leaves the VM, it encounters a virtual switch (hypervisor), and then a physical switch at the top or end of the rack. The physical network cannot cope with the rapidly shifting state of virtual machines once traffic leaves the hypervisor.
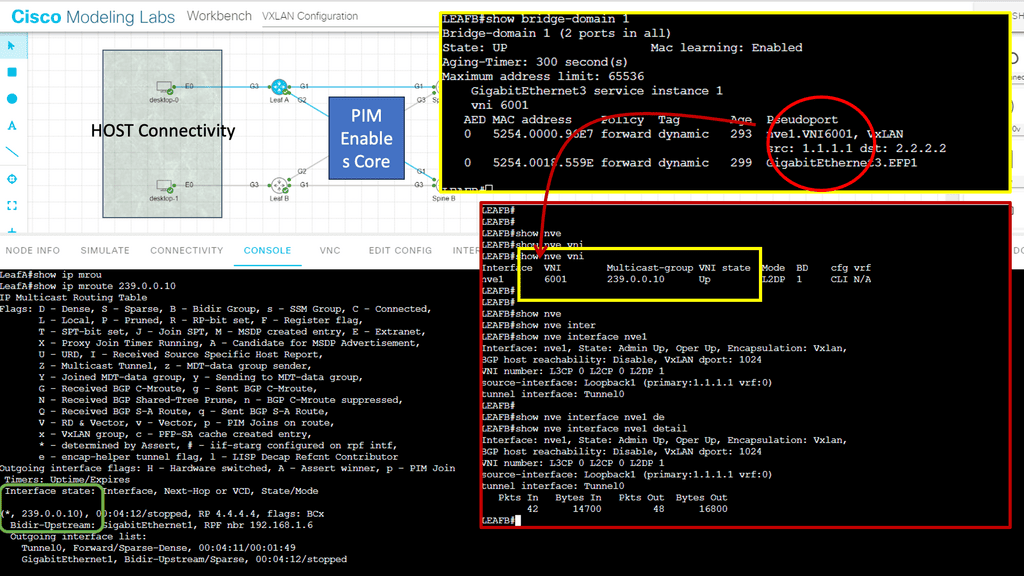
The issue can be circumvented by creating a logical network of VMs that spans the physical networks. Encapsulation is used to accomplish this in VXLAN, as in most other network virtualization forms. In contrast to simple VLANs, which can create only 4096 logical networks per physical network, VXLAN can create about 16 million logical networks per physical network. That scale is necessary for a large data center or cloud.
A shift from hardware-centric
NFV, at its core, is the virtualization of network functions traditionally performed by dedicated hardware appliances. It enables the decoupling of network functions from specialized hardware, allowing them to be run as software on general-purpose servers. This shift from hardware-centric to software-centric network infrastructure brings immense flexibility, agility, and resource optimization advantages.
SDN and NFV
While Software Defined Networking (SDN) and Network Function Virtualization (NFV) are used in the same context, they satisfy separate functions in the network. NFV is used to program network functions, like network overlays, QoS, VPNs, etc., enabling a series of SDN NFV use cases. SDN is used to program the network flows. They have entirely different heritages. SDN was born in academic labs and found roots in the significant hyper-scale data center topologies of Google, Amazon, and Microsoft.
Its use case moves from the internal data center to the service provider and mobile networks. NFV, on the other hand, was pushed by service providers in 20012-2013, and work is driven out of the European Telecommunications Standard Institute (ETSI) working group. The ETSI has proposed an NFV reference architecture, several white papers, and technology leaflets.
You may find the following valuable post for pre-information:
- Ansible Tower
- What is OpenFlow
- LISP Protocol
- Open Networking
- OpenFlow Protocol
- What is BGP protocol in Networking
- Removing State From Network Functions
SDN NFV Use Cases. |
|
Back to Basics: NFV
Over the past few years, it has become increasingly popular for companies operating within different industrial and commercial sectors to use network function virtualization (NFV) to solve multiple networking challenges. With the expansion of the Internet of Things (IoT) and advances in network communications technologies, along with the growing demand for ever more advanced services, network function virtualization is allowing enterprises to design, provide, and ease into much more advanced services and operations as well as reduce outgoings through cost savings.
Highlighting NFV
Network Function Virtualization (NFV) is a network architecture concept that uses software-defined networking (SDN) principles to virtualize entire classes of network node functions into building blocks that can be connected, composed, and reconfigured to create communication services. This virtualization approach to developing a programmable network layer is essential to realizing a Software Defined Network (SDN).
NFV enables the network administrator to rapidly create, deploy, and configure network services across data centers and remote locations, eliminating the need to deploy and maintain dedicated hardware for each service. In addition, by virtualizing the network functions, the network administrator can use a single instance of the service across the entire network, reducing complexity and management overhead.
NFV Benefits
The main benefit of NFV is that it simplifies network management, allowing the network administrator to create, deploy, and configure services as needed quickly. It also reduces costs associated with managing multiple instances of the same service. Additionally, NFV enables the network administrator to quickly deploy new services, allowing for rapid deployment and testing of new network services.
In addition to these benefits, NFV also provides flexibility and scalability. By leveraging virtualization, the network administrator can quickly scale the network up or down as needed without purchasing additional hardware. Additionally, NFV allows for more efficient use of resources, eliminating the need to buy dedicated hardware for each service.
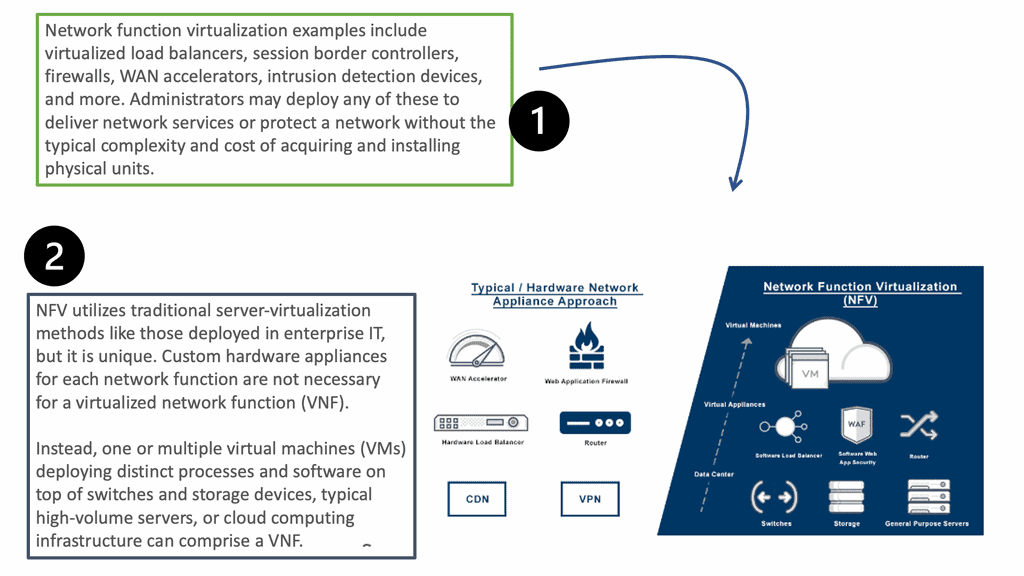
NFV Advanced
Network function virtualization (NFV) denotes a significant transformation for telecommunications/service provider networks, pushed by reducing cost, increasing flexibility, and providing personalized services. NFV leverages cloud computing principles to change how NFs such as gateways and middleboxes are offered. Unlike today’s tight coupling between the NF software and dedicated hardware, the loosely coupled software and hardware in NFV can relieve the upgrade cost and increase innovation flexibility.
NFV Use Cases
1. Telecommunications:
NFV has revolutionized the telecommunications sector by enabling the virtualization of crucial network functions. Service providers can now deploy virtualized network functions (VNFs) such as routers, firewalls, and load balancers, reducing the reliance on dedicated hardware. This allows for dynamic scaling, faster service deployment, and increased operational efficiency.
2. Cloud Computing:
NFV is playing a pivotal role in the evolution of cloud computing. By virtualizing network functions, NFV enables the creation of software-defined networking (SDN) architectures, which offer greater agility and flexibility in managing network resources. This allows cloud service providers to quickly adapt to changing demands, optimize resource allocation, and deliver services with enhanced performance and reliability.
3. Internet of Things (IoT):
The proliferation of IoT devices has created new challenges for network infrastructure. NFV has emerged as a solution to meet the dynamic demands of IoT deployments. By virtualizing network functions, NFV enables the efficient management and orchestration of network resources to support the massive scale and diverse requirements of IoT applications. This ensures seamless connectivity, efficient data processing, and improved overall performance.
4. Enterprise Networking:
NFV significantly benefits enterprise networking by simplifying network management and reducing costs. With NFV, enterprises can deploy virtualized network functions to replace traditional hardware appliances, reducing hardware and maintenance costs. This enables enterprises to rapidly deploy new services, scale their networks as per demand, and improve overall network performance and security.
5. Service Chaining:
NFV enables service chaining, which refers to the sequential routing of network traffic through a series of virtualized network functions. Service chaining allows for the creation of complex network service workflows, enabling the delivery of advanced services such as network security, traffic optimization, and deep packet inspection. NFV’s ability to dynamically chain and orchestrate virtualized network functions opens up new possibilities for service providers to deliver innovative and personalized services to their customers.
SDN NFV Use Cases: ASIC and Intel x86 Processor
To understand network function virtualization, consider the inside of proprietary network devices and standard servers. The inside of a network device looks similar to that of a standard server. They have several components, including Flash, PCI bus, RAM, etc. Apart from the number of physical ports, the architecture is very similar. The ASIC (application-specific integrated circuit) is not as important as vendors would like you to believe.
When buying a networking device, you are not paying for the hardware—the hardware is cheap—but for the software and maintenance costs. Hardware is a minor component of the total price. Why can’t you run network services on Intel x86? Why is there a need to run these services on vendor-proprietary software? x86 general-purpose OSs can perform just as well as some routers with dedicated silicon.
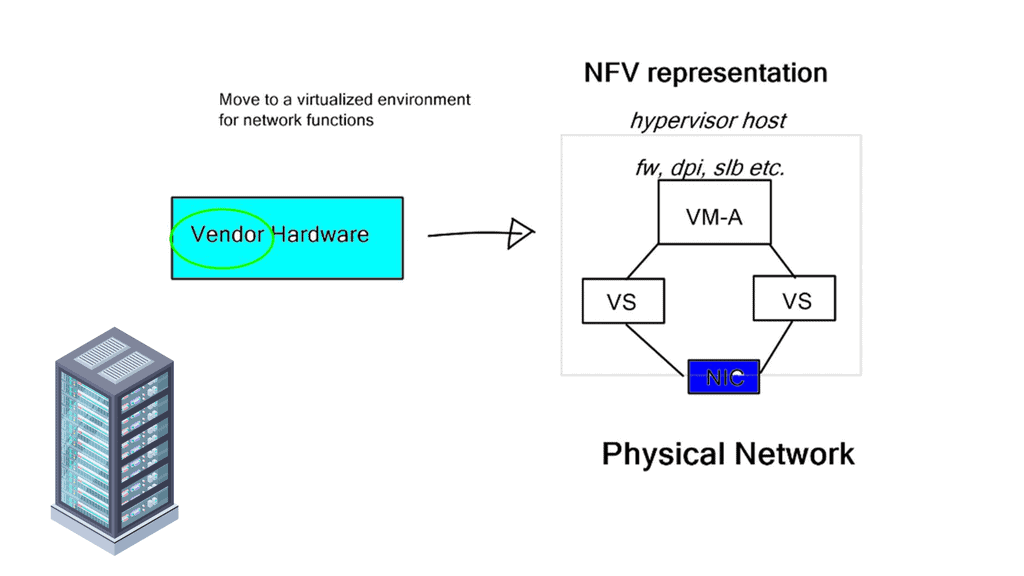
Network Function Virtualization Architecture
The concept of NFV is simple: Let’s deploy network services in VM format on generic, non-proprietary hardware. NFV increases network agility by deploying services in seconds, not weeks. The time-to-deployment is quicker, enabling the introduction of new concepts and products in line with the business deployment speeds needed for today’s networks.
In addition, NFV reduces the number of redundant devices. For example, why have two firewall devices on active / standby when you can insert or replace a failed firewall in seconds with NFV? It also simplifies the network and reduces the shared state in network components.
A shared state is always bad for a network, and too much device complexity leads to “holy cows.” A holy cow is a network device ingrained so much in the network with obsolete and old configurations it cannot be moved quickly or cheaply (everything can be moved at a cost).
NFV use cases
However, not everything can be expressed in software. You can’t replace a Terabit switch with an Intel CPU. Replacing a top-end Cisco GSR or CSR with an Intel x86 server may be cheaper, but it is far from practical functionally. There will always be a requirement for hardware-based forwarding, which will likely never change. But if your existing hardware uses Intel’s x86 forwarding, there is no reason it can’t run on generic hardware.
Possible SDN NFV use cases with network function for NFV include Firewalls with stateful inspection firewall capabilities, Deep Packet Inspection (DPI) devices, Intrusion Detection Systems, SP CE and PE devices, and Server Load Balancers. DPI is never usually done in hardware, so why can’t we put it on an x86 server?
Load balancing can be scaled out among many virtual devices in a pay-as-you-grow model, making it an accepted NFV candidate. There is no need to put 20 IP addresses on a load balancer when you can quickly scale 20 independent load balancing instances in NFV format.
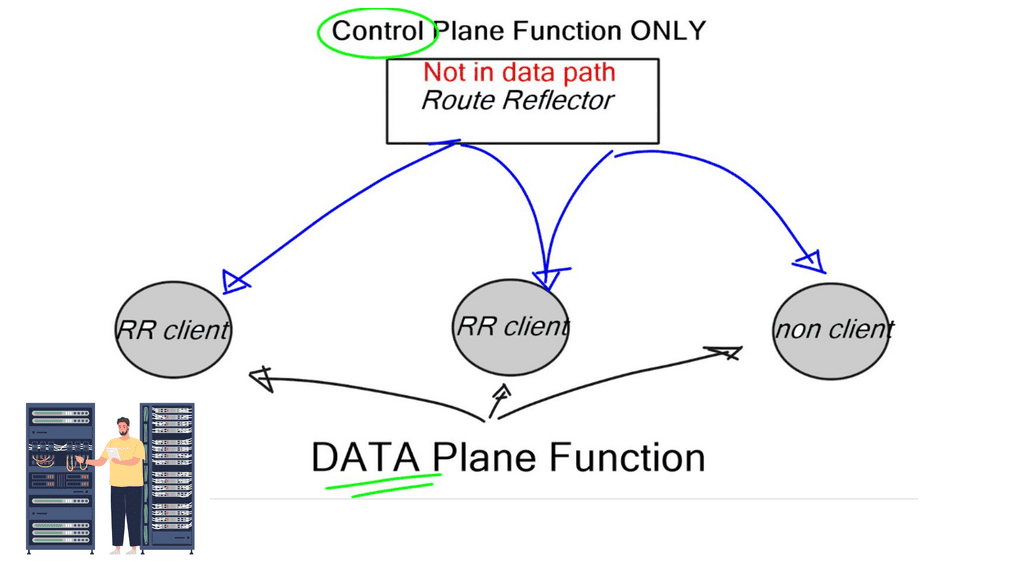
Control plane functionality
While the relevant use cases of NFV continue to evolve, an immediate and widely accepted use case would be with control plane functionality. Control plane functions don’t require intensive hardware-based forwarding functions. Instead, they provide reachability and control information for end-to-end communication.
BGP RR and LISP Mapping Database
For example, take the case of a BGP Route-Reflector (RR) or LISP Mapping Database. An RR does not participate in data plane forwarding. It is usually designed in a redundant route reflector cluster for control plane services, reflecting routes from one node to another. It is not in the data transit path.
We have used proprietary vendor hardware as route reflectors for ages as they had the best BGP stack. But buying a high-end Cisco or Juniper device just to run RR control plane services wastes money and hardware resources. Why buy a router with suitable forwarding hardware when you only need the control plane software element?
LISP mapping databases
LISP Mapping Databases are commonly deployed on x86, not a dedicated routing appliance. This is how the lispers.net open ecosystem mapping server is deployed. All routers needed for control plane services can be put in a VM. Control plane functionality is not the only one for NFV use cases. Service providers are also implementing NFV for virtual PE and virtual CE devices.
They offer per-customer use cases by building a unique service chain for each customer. Some providers want to allow customers to build their own service chains. This allows you to quickly create new services and test service adoption rates to determine if anyone is buying the product—a great way to test new services.
Network Function Virtualization performance
There are three elements relating to performance – management, control, and data plane. Management and control plane performance is not as critical as the data plane. As long as you get decent protocol convergence timers, it should be good enough. But generally speaking, they are not as crucial as data plane forwarding, which is critical for performance.
The performance you get out of the box with an x86 device isn’t outstanding; maybe 1 or 2 GiG of forwarding performance. If you do something simple like switching Layer 2 packets, the performance will increase to 2 or 3 gigs per core. Unfortunately, this is considerably less than what the actual hardware can do. The hardware can push 50 to 100GiG through a mid-range server. Why is out-of-the-box performance so bad?
TCP stack and Linux kernel
The problem lies with the TCP stack and Linux Kernel. The Linux Kernel was never designed for high-speed packet forwarding. It could offer a better data plane but an excellent control plane function. To improve performance, you may need multi-core processing. Sometimes, the forwarding path taken by the virtual switch is so long that it kills performance.
Significantly, when the encapsulation and decapsulation process of tunneling is involved, in the past, when you started to use Open vswitch (OVS) ( what is OVS ) with GRE tunneling – VPNoverview performance fell drastically.
They never had this problem with VLANS because they used a different code path. With the latest version of OVS, performance is not an issue. On the contrary, it’s faster than most of its alternatives, such as the Linux Bridge.
The performance has increased due to the changes in architecture for multithreading, megaflows, and additional classification improvements. It can be optimized further with Intel DPDK. DPDK is a set of enhanced libraries and drivers that enable kernel bypass, gaining impressive performance. Performance may also be achieved by moving the hypervisor out of the picture with SR-IOV.
SR-IOV slices a single physical NIC into multiple virtual NICs, and then you connect the VM to one of the virtual NICs. You are allowing the VM to work with the hardware directly.

- DMVPN - May 20, 2023
- Computer Networking: Building a Strong Foundation for Success - April 7, 2023
- eBOOK – SASE Capabilities - April 6, 2023