
Traditional Design and the move to VPC
The architecture has three types of routers: core routers, aggregation routers (sometimes called distribution routers), and access switches. Layer 2 networks use the Spanning Tree Protocol to establish loop-free topologies between aggregation routers and access switches. The spanning tree protocol has several advantages. There are several advantages to using this technology, including its simplicity and ease of use. The IP address and default gateway setting do not need to be changed when servers move within a pod because VLANs are extended within each pod. In a VLAN, Spanning Tree Protocol never allows redundant paths to be used simultaneously.
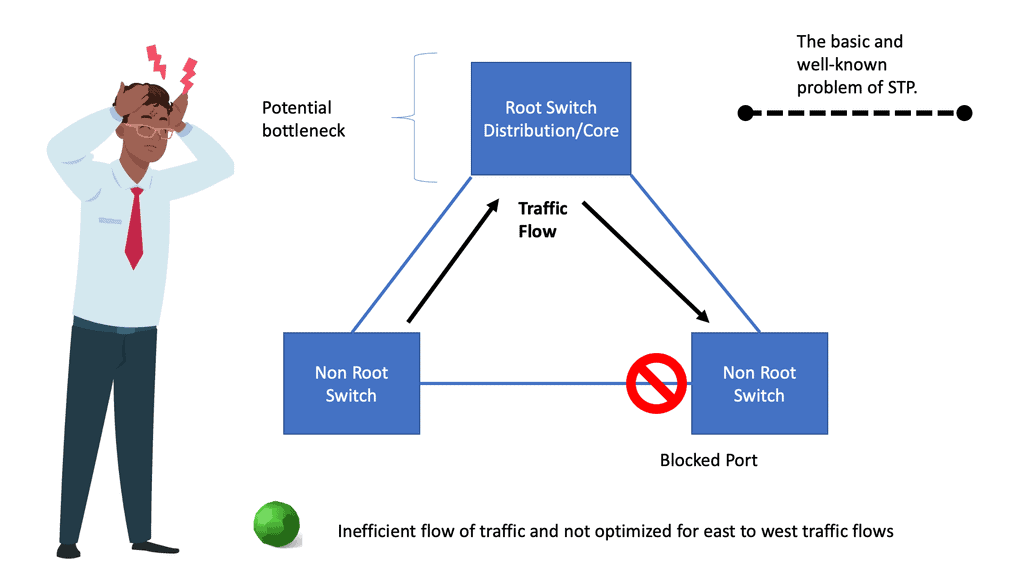
To overcome the limitations of the Spanning Tree Protocol, Cisco introduced virtual port channel (vPC) technology in 2010. A vPC eliminates blocked ports from spanning trees, provides active-active uplinks between access switches and aggregation routers, and maximizes bandwidth usage.
In 2003, virtual technology allowed computing, networking, and storage resources to be pooled previously segregated in pods in Layer 2 of the three-tier data center design. This revolutionary technology created a need for a larger Layer 2 domain.
Virtual Private Networks (VPNs) are new Layer 2 domains. It enabled organizations to establish secure, private connections between multiple sites. By deploying virtualized servers, applications are increasingly distributed, resulting in increased east-west traffic due to the ability to access and share resources securely. Latency must be low and predictable to handle this traffic efficiently. In a three-tier data center, bandwidth becomes a bottleneck when only two active parallel uplinks; however, vPC can provide four active parallel uplinks. Three-tier architectures also present the challenge of varying server-to-server latency.
To overcome these limitations, a new data center design based on the Clos network was developed. With this architecture, server-to-server communication is high-bandwidth, low-latency, and non-blocking.
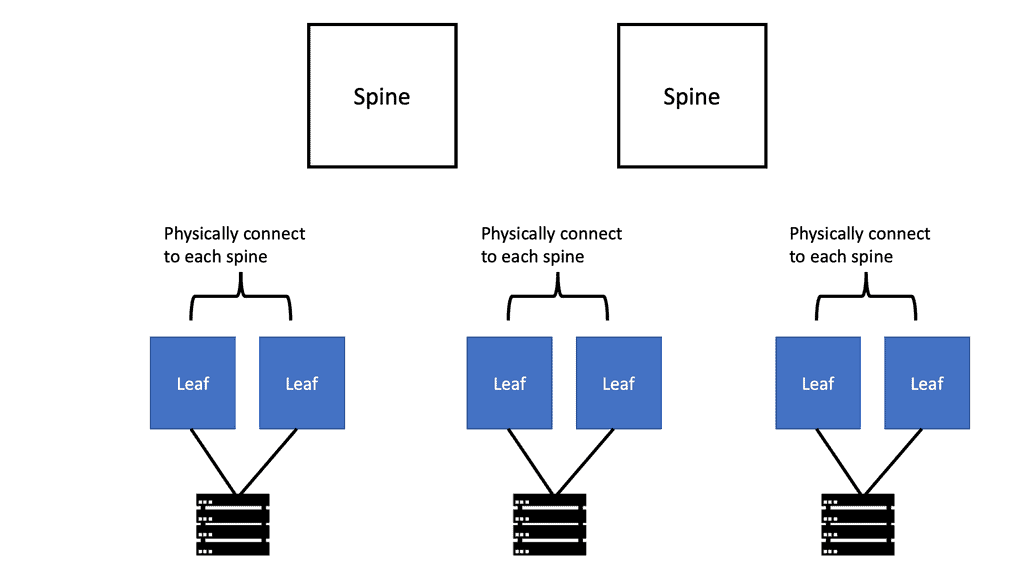
Switch Fabric Architecture
Switch fabric architecture is crucial to minimize packet loss and increase data center performance. A Gigabit (10GE to 100GE) data center network only takes milliseconds of congestion to cause buffer overruns and packet loss. Selecting the correct platforms that match the traffic mix and profiles is an essential phase of data center design. Specific switch fabric architectures are better suited to certain design requirements. Network performance has a direct relationship with switching fabric architecture.
The data center switch fabric aims to optimize end-to-end fabric latency with the ability to handle traffic peaks. Environments should be designed to send data as fast as possible, providing better application and storage performance. For these performance metrics to be met, several requirements must be set by the business and the architect team.
Switch Fabric Architecture. |
|
Before you proceed, you may find the following post helpful for pre-information.
- Dropped Packet Test
- Data Center Topologies
- Active Active Data Center Design
- IP Forwarding
- Data Center Fabric
Fabric Switch Requirements
|
Back to basics with network testing.
Several key factors influence data center performance:
a. Uptime and Reliability: Downtime can have severe consequences for businesses, resulting in financial losses, damaged reputation, and even legal implications. Therefore, data centers strive to achieve high uptime and reliability, minimizing disruptions to operations.
b. Speed and Responsiveness: With increasing data volumes and user expectations, data centers must deliver fast and responsive services. Slow response times can lead to dissatisfied customers and hamper business productivity.
c. Scalability: As businesses grow, their data requirements increase. A well-performing data center should be able to scale seamlessly, accommodating the organization’s expanding needs without compromising on performance.
d. Energy Efficiency: Data centers consume significant amounts of energy. Optimizing energy usage through efficient cooling systems, power management, and renewable energy sources can reduce costs and contribute to a sustainable future.
Impact on Businesses:
Data center performance directly impacts businesses in several ways:
a. Enhanced User Experience: A high-performing data center ensures faster data access, reduced latency, and improved website/application performance. This translates into a better user experience, increased customer satisfaction, and higher conversion rates.
b. Business Continuity: Data centers with robust performance measures, including backup and disaster recovery mechanisms, help businesses maintain continuity despite unexpected events. This ensures that critical operations can continue without significant disruption.
c. Competitive Advantage: In today’s competitive landscape, businesses that leverage the capabilities of a well-performing data center gain a competitive edge. Processing and analyzing data quickly can lead to better decision-making, improved operational efficiency, and innovative product/service offerings.
Proactive Testing
Although the usefulness of proactive testing is well known, most do not vigorously and methodically stress their network components in the ways that their applications will. As a result, testing that is too infrequent returns significantly less value than the time and money spent. In addition, many existing corporate testing facilities are underfunded and eventually shut down because of a lack of experience and guidance, limited resources, and poor productivity from previous test efforts. That said, the need for testing remains.
To understand your data center performance, you should undergo planned system testing. System testing is a proven approach for validating the existing network infrastructure and planning its future. It is essential to comprehend that in a modern enterprise network, achieving a high level of availability is only possible with some formalized testing.
Different Types of Switching
Cut-through switching
Cut-through switching allows you to start forwarding frames immediately. Switches process frames using a “first bit in, first bit out” method.
When a switch receives a frame, it makes a forwarding decision based on the destination address, known as destination-based forwarding. On Ethernet networks, the destination address is the first field following the start-of-frame delimiter. Due to the positioning of the destination address at the start of the frame, the switch immediately knows what egress port the frame needs to be sent to, i.e., there is no need to wait for the entire frame to be processed before you carry out the forwarding.
Buffer pressure at the leaf switch uplink and corresponding spine port is about the same, resulting in the same buffer size between these two network points. However, increasing buffering size at the leaf layer is more critical as more cases of speed mismatch occur in the cast ( many-to-one ) traffic and oversubscription. Speed mismatch, incast traffic, and oversubscription are the leading causes of buffer utilization.
Store-and-forwarding
Store-and-forwarding works in contrast to cut-through switching. However, store-and-forwarding switching increases latency with packet size as the entire frame is stored first before the forwarding decision is made. One of the main benefits of cut-through is consistent latency among packet sizes, which is suitable for network performance. However, there are motivations to inspect the entire frame using the store-and-forward method. Store-and-forward ensures a) Collision detection and b) No packets with errors are propagated.
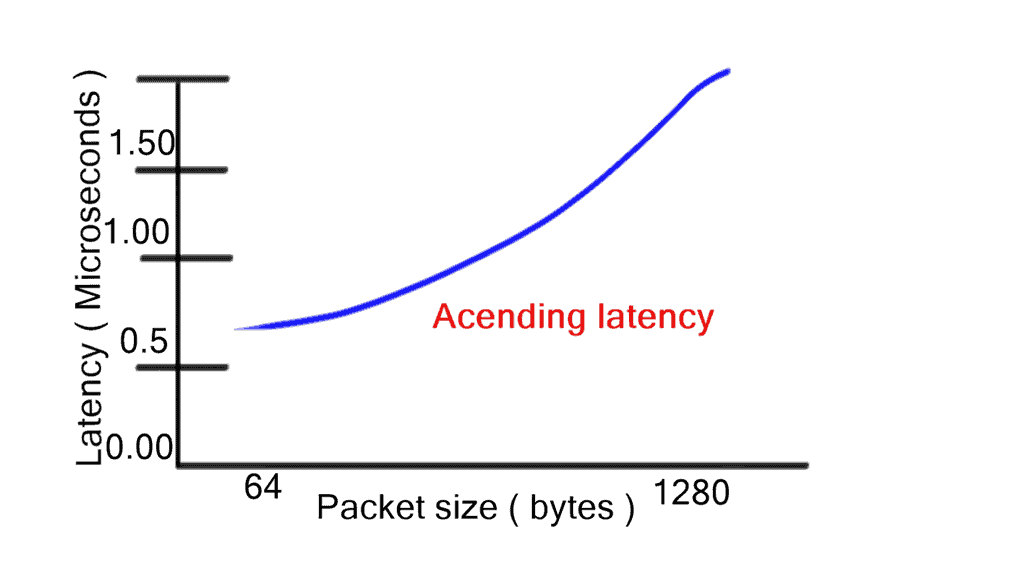
Cut-through switching is a significant data center performance improvement for switching architectures. Regardless of packet sizes, cut-through reduces the latency of the lookup-and-forwarding decision. Low and predictable latency results in optimized fabric and more minor buffer requirements. Selecting the correct platform with adequate interface buffer space is integral to data center design. For example, different buffering size requirements exist for leaf and spine switches. In addition, varying buffering utilization exists for other points of the network.
Switch Fabric Architecture
The main switch architectures used are the crossbar and SoC. A cut-through or store-and-forward switch can use either a crossbar fabric, a multistage crossbar fabric, an SoC, or a multistage SoC with either.
Crossbar Switch Fabric Architecture
In a crossbar design, every input is uniquely connected to every output through a “crosspoint. ” With a crosspoint design, crossbar fabric is strictly non-blocking and provides lossless transport. In addition, it has a feature known as over speed, which is used to achieve a 100% throughput (line rate) capacity for each port.
Overspeed clocks the switch fabric several times faster than the physical port interface connected to the fabric. Crossbar and cut-through switching enable line-rate performance with low latency regardless of packet size.
Cisco Nexus 6000 and 5000 series are cut-through with the crossbar. Nexus 7000 uses store-and-forward crossbar-switching mechanisms, which have large output-queuing memory or egress buffer.
Because of the large memory store-and-forward crossbar design offered, they provide large table sizes for MAC learning. Due to large table sizes, the density of ports is lower than that of other switch categories. The Nexus 7000 series with an M-series line card exemplifies this architecture.
Head-of-line blocking (HOLB)
When frames for different output ports arrive on the same ingress port, frames destined for a free output port can be blocked by a frame in front of it destined for a congested output port. For example, an extensive FTP transfer lands in the same path across the internal switching fabric in addition to the request-response protocol (HTTP), which handles short transactions.
This causes the frame destined for the free port to wait in a queue until the frame in front of it can be processed. This idle time degrades performance and can create out-of-order frames.
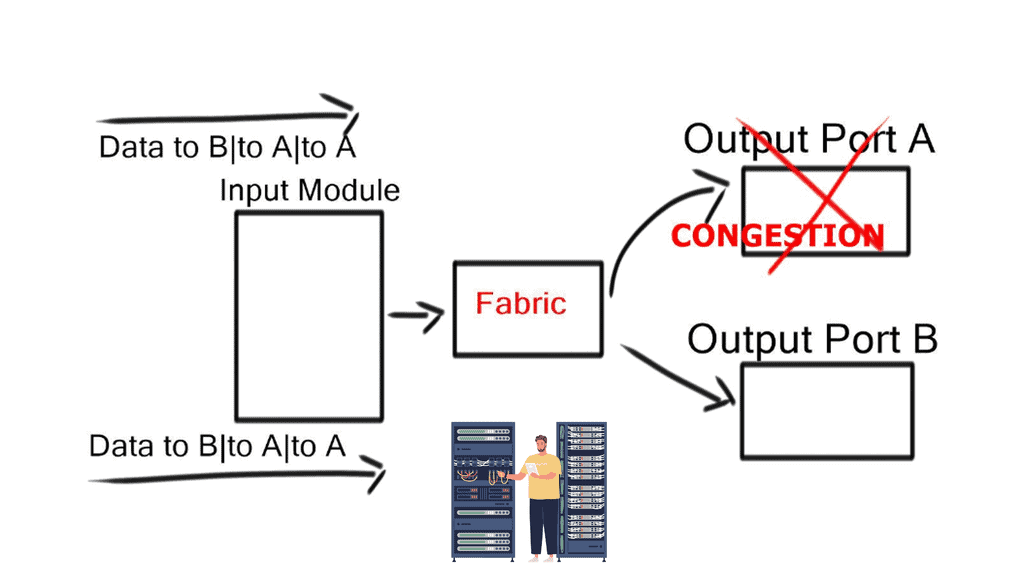
Virtual output queues (VoQ)
Instead of having a single per-class queue on an output port, the hardware implements a per-class virtual output queue (VoQ) on input ports. Received packets stay in the virtual output queue on the input line card until the output port is ready to accept another packet. With VoQ, data centers no longer experience HOLB. VoQ is effective at absorbing traffic loads at congestion points in the network.
It forces congestion on ingress/queuing before traffic reaches the switch fabric. Packets are held at the ingress port buffer until the egress queue frees up.
VoQ is not the same as ingress queuing. Ingress queuing occurs when the total ingress bandwidth exceeds backplane capacity, and actual congestion occurs, which ingress-queuing policies would govern. VoQ generates a virtual congestion scenario at a node before the switching fabric. They are governed by egress queuing policies, not ingress policies.
Centralized shared memory ( SoC )
SoC is another type of data center switch architecture. Lower bandwidth and port density switches usually have SoC architectures. SoC differs from the crossbar in that all inputs and outputs share all memory. This inherently reduces frame loss and drop probability. Unused buffers are given to ports under pressure from increasing loads.
Data center performance is a critical aspect of modern businesses. It impacts the overall user experience, business continuity, and competitive advantage. By investing in high-performing data centers, organizations can ensure seamless operations, improved productivity, and stay ahead in a digital-first world. As technology continues to evolve, data center performance will remain a key factor in shaping the success of businesses across various industries.