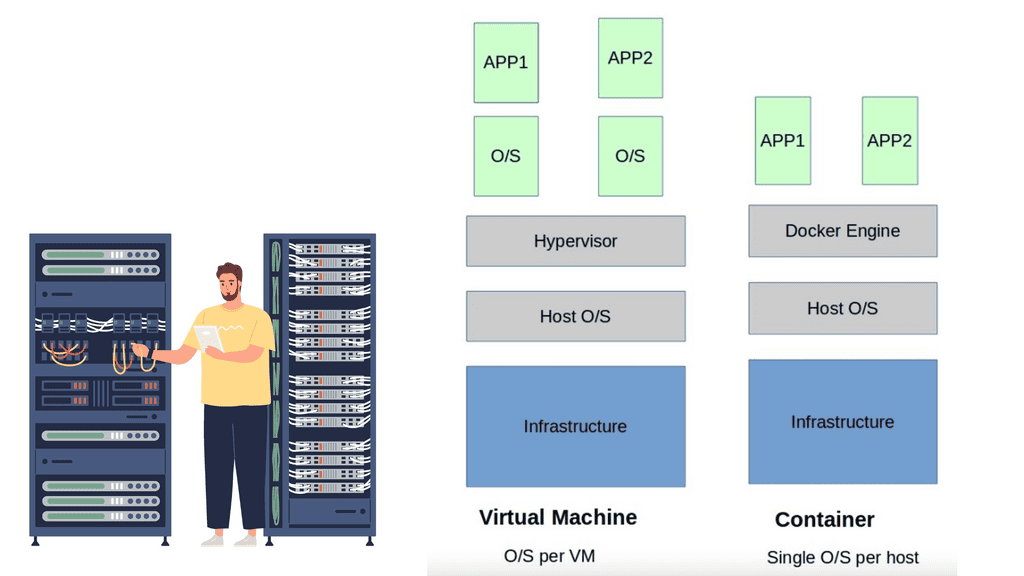
Detera and stateful applications
In Kubernetes, persistent volumes are critical as customers migrate from stateless workloads to stateful applications. Pet Sets have significantly improved Kubernetes’ support for stateful applications like MySQL, Kafka, Cassandra, and Couchbase. It was possible to automate the scaling of the “Pets” (applications that need persistent placement and consistent handling) using sequencing provisioning and startup procedures.
Datera integrates seamlessly with Kubernetes using FlexVolume, an elastic block storage system for cloud deployments. Based on the first principles of containers, Datera decouples the provisioning of application resources from the underlying physical infrastructure. Clean contracts (i.e., not dependent on physical infrastructure), declarative formats, and declarative formats can eventually make stateful applications portable.
With Datera, Kubernetes allows the underlying application infrastructure to be defined through YAML configurations, which are passed to the storage infrastructure. Datara AppTemplates can automate the scaling of stateful applications in a Kubernetes environment.
The Role of Kubernetes
Kubernetes Pets and PetSets are core components of Kubernetes operations. Firstly, Kubernetes is a container orchestration platform that runs and manages containers. It changes the focus of container deployment to an application level, not the machine. The shift of focus point enables an abstraction level and the removal of dependencies between the application and its physical deployment.
The Role of Decoupling
This act of decoupling services from the details of low-level physical deployment enables better service management. For anything to scale, you need to provide some abstraction. For container networking, we have seen this in the overlay world with underlay and abstraction enabling networks to support millions of tenants.
Kubernetes Networking 101
Kubernetes Networking 101 allows the deployment of applications to a “sea of abstracted computes,” enabling a self-healing orchestrated infrastructure. While this scaling and deployment have been helpful for stateless services, they fall short in the stateful world with the base Kubernetes distribution. Most of this has been solved today with Red Hat products, including OpenShift networking, which has several new network and security constructs that aid with stateful application support.
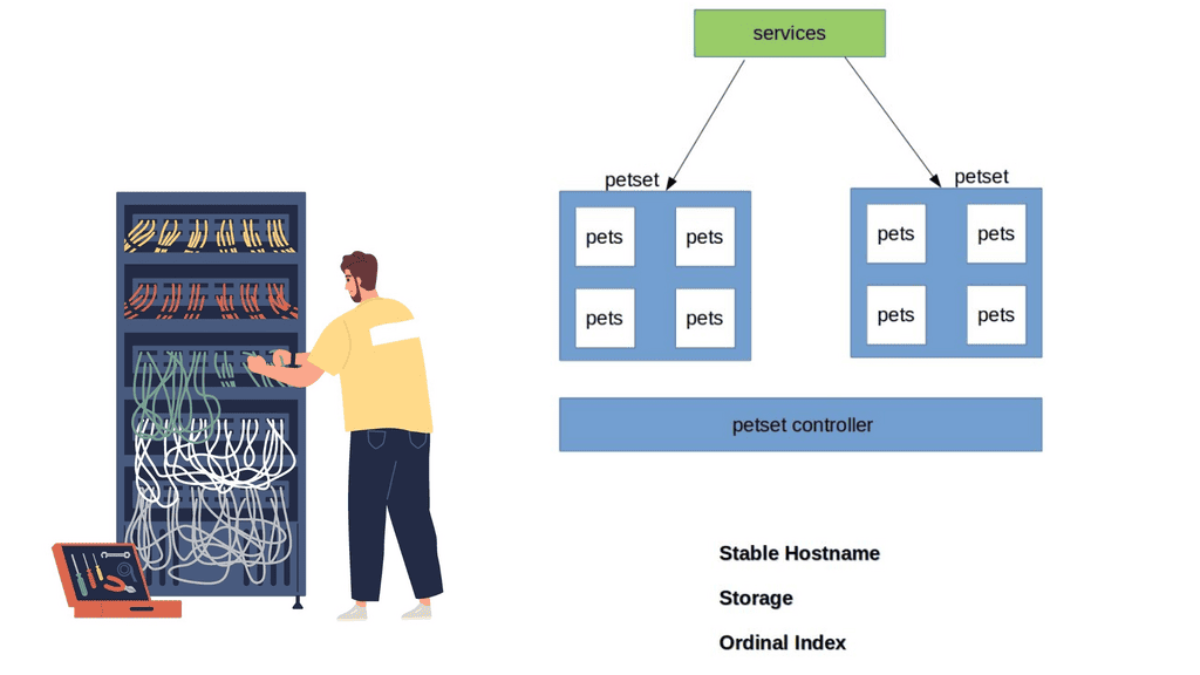
Kubernetes Pets. |
|
For pre-information, you may find the following useful
- SASE Model
- Chaos Engineering Kubernetes
- Kubernetes Security Best Practices
- OpenShift SDN
- Hands On Kubernetes
- Kubernetes Namespace
- Container Scheduler
Back to basics with Kubernetes PetSets
StatefulSets
Kubernetes started providing a resource to manage stateful workloads with the alpha release of PetSets in the 1.3 release. This capability has matured and is now known as StatefulSets. A StatefulSet has some similarities to a ReplicaSet in that it is responsible for managing the lifecycle of a set of Pods, but how it goes about this management has some noteworthy differences. PetSet might seem like an odd name for a Kubernetes resource, and it has since been replaced.
Still, it provides fascinating insights into the thought process of the Kubernetes community in supporting stateful workloads. The fundamental idea is that there are two ways of handling servers: to treat them as pets that require care, feeding, and nurturing, or to treat them as cattle, to which you don’t develop an attachment or provide much individual attention. If you’re logging into a server regularly to perform maintenance activities, you treat it as a pet.
Benefits of PetSets
PetSets offer several advantages over traditional Kubernetes deployments:
1. Stable Network Identity: PetSets assigns each pod a stable hostname and DNS identity, enabling seamless communication between pods and external services. This stability is essential for applications relying on peer-to-peer communication or distributed databases.
2. Ordered Deployment: PetSets ensure the ordered deployment and scaling of pods. This is particularly useful for applications where the order of creation or scaling matters, such as databases or distributed systems.
3. Persistent Volumes: PetSets facilitate the association of persistent volumes with pods, ensuring data durability and allowing applications to retain their state even if the pods are rescheduled.
4. Rolling Updates: PetSets supports rolling updates, enabling you to update your stateful applications without downtime. This process ensures that each pod is gracefully terminated and replaced by a new one with the updated configuration, minimizing service interruptions.
Use Cases
PetSets are ideal for various stateful applications, including databases, distributed systems, and legacy applications that require stable network identities and persistent storage. Some common use cases for PetSets include:
1. Running a replicated database cluster, such as MySQL or PostgreSQL, where each pod corresponds to a separate database node.
2. Managing distributed messaging systems, like Apache Kafka or RabbitMQ, where each pod represents a separate broker or message queue.
3. Deploying legacy applications that rely on stable network identities and persistent storage, such as content management systems or enterprise resource planning software.
Contrasting Application Models
As applications serve a growing user base around the globe, single cluster and data center solutions are no longer satisfied. Clustered applications and federations enable workload to spread across multiple locations and container clusters for improved efficiency and scale. There are contrasting deployment models when you examine the application types and scaling modes (for example, scale up & scale out clustering ).
There are substantial differences between deploying and running single applications to applications that operate within a cluster. Different application architectures require different deployment solutions and network identities. For example, a database node requires persistent volumes, or a node within a cluster uses specific elections where identity is essential.
Kubernetes Pets
Kubernetes has recently ramped up by introducing a new Kubernetes object called PetSets. PetSets is geared towards improving stateful support and is currently an alpha resource in Kubernetes release 1.3. PetSets is an object that holds a group of Kubernetes Pets, aka stateful applications that require stable hostnames, persistent disks, structured lifecycle process, and group identity.
PetSets are used for non-homogenous instances where each POD has a stable distinguishable identity. A different identity is viewed in terms of stable network and storage.
A ) Stable network identities such as DNS and hostname.
B ) Stable storage identity.
Before PetSets, stateful applications were supported but exceedingly difficult to deploy and manage, especially regarding distributed stateful clusters. In addition, PODs had random names that could not be relied upon. With the introduction of PetSets controllers and Kubernetes Pets, Kubernetes has sharpened its support for stateful and distributed stateful applications.
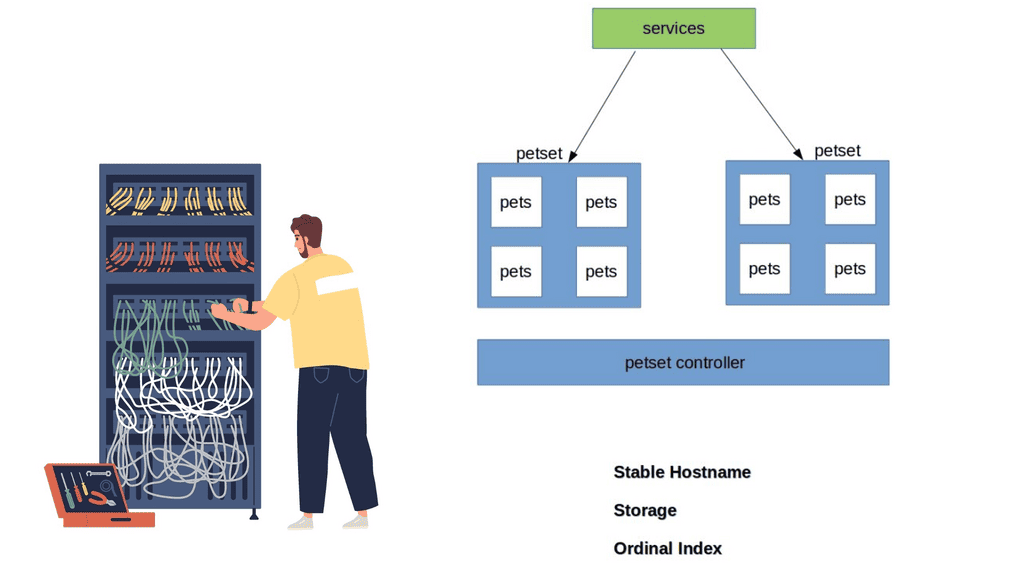
PODs and their shortcomings
Kubernetes enables the specification of applications as a POD file, expressed in YAML or JSON format. The file specifies what containers are to be in a POD. PODs are the smallest deployment unit in Kubernetes and present several challenges for some stateful services. They do not offer a singleton pattern and are ephemeral by design.
Their constructs are mortal as they are born and die but never resurrected. When a POD dies, it’s permanently gone and replaced with a new instance and fresh identity. This operation model may suit some applications but falls short for others who want to retain identity and storage across restart / reschedule.
Replication Controllers and their shortcomings
If you want a POD to resurrect, you need a Replication Controller ( RC ). The RC enables a singleton pattern to set replication patterns to a specific number of PODs.
The introduction of the RC is undoubtedly a step in the right direction, as it ensures the correct number of replicas are always running at any given time. The RC works alongside services before the RC, using labels to map inbound requests to certain PODs.
Services provide a level of abstraction so that the application endpoint never changes. RC is suitable for application deployments requiring weak uncoupled identities, and when naming individual PODs doesn’t matter to the application architecture.
However, they lack certain functionalities that the new PetSet controller provides. So you could say that a PetSet controller is an enhanced RC controller in shiny new clothes.
A key point: “Pets and Cattle.”
The best way to understand Kubernetes Pets and PetSets is to perceive the cloud infrastructure with the “Pets and Cattle” metaphor. A“Pet” is a special snowflake you have emotional ties towards and requires special handling, for example, when it’s sick, unlike “Cattle,” which is viewed as an easily replaceable commodity.
Cattle are similar enough to each other that you can treat them all as equals. Therefore, the application does not suffer too much if a cattle dies or needs to be replaced.
- Cattle refers to stateless applications, and Pets refer to stateful, “build once, run anywhere” applications.
Stateless applications
A stateless application takes in a request and responds, but nothing is left behind to fulfill subsequent connections. The stateless pattern derives from another independent system’s ability to satisfy subsequent requests/responses. Stateful applications store data for further use. These types of applications can be inspected with a stateful inspection firewall.
Stateful applications are grouped into what’s known as a PetSet object. The PetSet controller has a family-orientated approach, as opposed to the traditional RC, which is mainly concerned with the number of replicas. PODs are stateless disposable units that can be removed and interchanged without affecting the application. The Pets, conversely, are groups of stateful PODs requiring stronger different identities.
Within a PetSet, Pets ( stateful applications ) have a unique distinguishable identity. The identities stick and do not change when restarting / rescheduling. They have an explicit purpose/role in life that is known throughout the family – a definitive startup carried out in a structured order that fits within its responsibility in the framework of the application.
Initially, the cattle approach forced us to view cloud components as anonymous resources. However, this approach does not fit all application requirements. Stateful applications require us to rethink the new pet-style approach.
- Workloads and Application Types Suitable for Pets:
Stateful application within a PetSet object requires unique identities such as :
- Storage
- Ordinal index
- Stable Hostname
The PetSet object supports clustered applications that require stricter membership and identity requirements, such as :
- Discovery of peers for quorum
- Startup and Teardown
Workloads that benefit from PetSets include, for example :
- NoSQL databases – clustered software like Cassandra, Zookeeper, etcd, requiring regular membership.
- Relationshional Databases – MySQL or PostgreSQL requiring persistent volumes.
Applications have different roles and responsibilities, requiring different deployment models. For example, a Cassandra cluster has strict membership and identity requirements; specific nodes are designated seed nodes used during startup to discover the cluster.
They come first and act as the contact points for all other nodes to get information about the cluster. All nodes require one seed node, and all nodes within a cluster must have the same seed node. Without a seed node, no node can join the cluster, meaning their role is vital for the application framework.
Zookeeper or etcd requires the identification of peers and instances clients should contact. Other databases have a master/slave model where the master has unidirectional control over the slave. The “primary” server has a different role and identity requirements than the “slave.” Properly running these types of services requires more complex features in Kubernetes.
Kubernetes PetSets provides a powerful solution for managing stateful applications within Kubernetes clusters. By ensuring stable network identities, persistent volumes, and ordered deployment, PetSets enables the seamless orchestration of various stateful workloads. Whether you are running a database cluster, managing distributed systems, or deploying legacy applications, PetSets offers the necessary features to ensure the reliability and scalability of your infrastructure. Embrace the power of PetSets and unlock the full potential of your stateful applications in the Kubernetes ecosystem.