
The Role of Data Centers
An enterprise’s data center houses the computational power, storage, and applications needed to run its operations. All content is sourced or passed through the data center infrastructure in the IT architecture. Performance, resiliency, and scalability must be considered when designing the data center infrastructure. Furthermore, the data center design should be flexible so that new services can be deployed and supported quickly. The many considerations required for such a design are port density, access layer uplink bandwidth, actual server capacity, and oversubscription.
Modern data centers
A few short years ago, data centers were very different from what they are today. In a multi-cloud environment, virtual networks have replaced physical servers that support applications and workloads across pools of physical infrastructure. Nowadays, data exists across multiple data centers, the edge, and public and private clouds. Communication between these locations must be possible in the on-premises and cloud data centers. Public clouds are also collections of data centers. In the cloud, applications use the cloud provider’s data center resources.
Example: Spine-Leaf Network
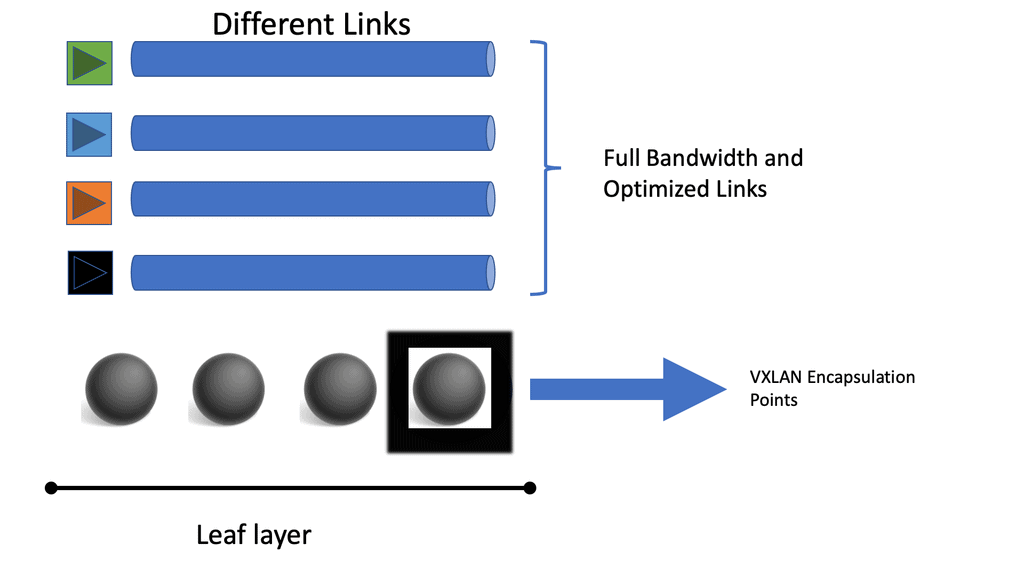
A full-mesh topology is achieved by connecting every lower-tier switch (leaf layer) to each top-tier switch (spine layer). Devices such as servers are connected to the leaf layer by access switches. All leaf switches are interconnected through the spine layer, the network’s backbone. The leaf switches in the fabric are connected to the spine switches. The top-tier switches are evenly distributed based on the path chosen at random. Data center performance would only be slightly affected if one of the top-tier switches failed.
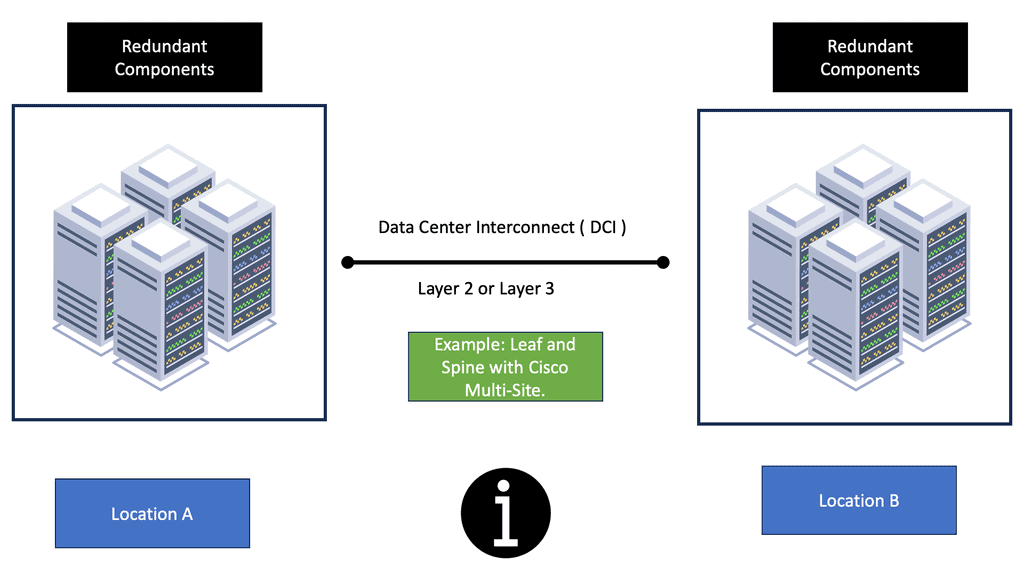
Redundant data centers
Redundant data centers are essentially two or more in different physical locations. This enables organizations to move their applications and data to another data center if they experience an outage. This also allows for load balancing and scalability, ensuring the organization’s services remain available.
Redundant data centers are generally located in geographically dispersed locations. This ensures that if one of the data centers experiences an issue, the other can take over, thus minimizing downtime. These data centers should also be connected via a high-speed networks connection, such as a dedicated line or virtual private network, to allow seamless data transfers between the locations.
Expansion and scalability
Expanding capacity is straightforward if a link is oversubscribed (more traffic than can be aggregated on the active link simultaneously). Expanding every leaf switch’s uplinks is possible, adding interlayer bandwidth and reducing oversubscription by adding a second spine switch. New leaf switches can be added by connecting them to every spine switch and configuring them as network switches if device port capacity becomes a concern. Scaling the network is made more accessible through ease of expansion. A nonblocking architecture can be achieved without oversubscription between the lower-tier switches and their uplinks.
Defining an active-active data center strategy isn’t easy when you talk to network, server, and compute teams that don’t usually collaborate when planning their infrastructure. An active-active Data center design requires a cohesive technology stack from end to end. Establishing the idea usually requires an enterprise-level architecture drive. In addition, it enables the availability and traffic load sharing of applications across DCs with the following use cases.
- Business continuity
- Mobility and load sharing
- Consistent policy and fast provisioning capability across
Active-active Transport Technologies
Transport technologies interconnect data centers. As part of the transport domain, redundancies and links are provided across the site to ensure HA and resiliency. Redundancy may be provided for multiplexers, GPONs, DCI network devices, dark fibers, diversity POPs for surviving POP failure, and 1+1 protection schemes for devices, cards, and links.
In addition, the following list contains the primary considerations to consider when designing a data center interconnection solution.
- Recovery from various types of failure scenarios: Link failures, module failures, node failures, etc.
- Traffic round-trip requirements between DCs based on link latency and applications
- Requirements for bandwidth and scalability
Active-Active Network Services
Network services connect all devices in data centers through traffic switching and routing functions. Applications should be able to forward traffic and share load without disruptions on the network. Network services also provide pervasive gateways, L2 extensions, and ingress and egress path optimization across the data centers. Most of the major network vendors’ SDN solutions also integrate VxLAN overlay solutions to achieve L2 extension, path optimization, and gateway mobility.
Designing active-active network services requires consideration of the following factors:
- Recovery from various types of failure scenarios, such as links, modules, and network devices, is possible.
- Availability of the gateway locally as well as across the DC infrastructure
- Using a VLAN or VxLAN between two DCs to extend the L2 domain
- Policies are consistent across on-premises and cloud infrastructure – including naming, segmentation rules for integrating various L4/L7 services, hypervisor integration, etc.
- Optimizing path ingresses and regresses.
- Centralized management includes inventory management, troubleshooting, AAA capabilities, backup and restore traffic flow analysis, and capacity dashboards.
Active-Active L4-L7 Services
ADC and security devices must be placed in both DCs before active-active L4-L7 services can be built. The major solutions in this space include global traffic managers, application policy controllers, load balancers, and firewalls. Furthermore, these must be deployed at different tiers for perimeter, extranet, WAN, core server farm, and UAT segments. Also, it should be noted that most of the leading L4-L7 service vendors currently offer clustering solutions for their products across the DCs. As a result of clustering, its members can share L4/L7 policies, traffic loads, and failover seamlessly in case of an issue.
Below are some significant considerations related to L4-L7 service design
- Various failure scenarios can be recovered, including link, module, and L4-L7 device failure.
- In addition to naming policies, L4-L7 rules for various traffic types must be consistent across the on-premises infrastructure and in the multiple clouds.
- Network management centralized (e.g., inventory, troubleshooting, AAA capabilities, backups, traffic flow analysis, capacity dashboards, etc.)
Active-Active Storage Services
Active-active data centers rely on storage and networking solutions. They refer to the storage in both DCs that serve applications. Similarly, the design should allow for uninterrupted read and write operations. Therefore, real-time data mirroring and seamless failover capabilities across DCs are also necessary. The following are some significant factors to consider when designing a storage system.
- Recover from single-disk failures, storage array failures, and split-brain failures.
- Asynchronous vs. synchronous replication: With synchronized replication, data is simultaneously written for primary storage and replica. In addition, it typically requires dedicated FC links, which consume more bandwidth.
- High availability and redundancy of storage: Storage replication factors and the number of disks available for redundancy
- Failure scenarios of storage networks: Links, modules, and network devices
Active-Active Server Virtualization
Over the years, server virtualization has evolved. Microservices and containers are becoming increasingly popular among organizations. The primary consideration here is to extend hypervisor/container clusters across the DCs to achieve seamless virtual machine/ container instance movement and fail-over. VMware Docker and Microsoft are the two dominant players in this market. Other examples include KVM, Kubernetes (container management), etc.
Here are some key considerations when it comes to virtualizing servers
- Creating a cross-DC virtual host cluster using a virtualization platform
- HA protects the VM in normal operational conditions and creates affinity rules that prefer local hosts.
- VMs in two DCs can take over the load in real time when the host machine is unavailable by deploying the same service.
- A symmetric configuration with failover resources is provided across the compute node devices and DCs.
- Managing computing resources and hypervisors centrally
Active-Active Applications Deployment
The infrastructure needs to be in place for the application to function. Additionally, it is essential to ensure high application availability across DCs. Applications can also fail over and get proximity access to locations. It is necessary to have Web, App, and DB tiers available at both data centers, and if the application fails in one, it should allow fail-over and continuity.
Here are a few key points to consider
- Use multiple servers to form independent clusters per DC to deploy the Web services on virtual or physical machines (VMs).
- VM or physical machine can be used to deploy App services. If the application supports distributed deployment, multiple servers within the DC can form a cluster, or various servers across DCs can create a cluster (preferred IP-based access).
- The databases should be deployed on physical machines to form a cross-DC cluster (active-standby or active-active). For example, Oracle RAC, DB2, SQL with Windows server failover cluster (WSFC)
Knowledge Check: Default Gateway Redundancy
A first-hop redundancy protocol (FHRP) always provides an active default IP gateway. To transparently failover at the first-hop IP router, FHRPs use two or more routers or Layer 3 switches.
The default gateway facilitates network communication. Source hosts send data to their default gateways. Default gateways are IP addresses on routers (or Layer 3 switches) connected to the same subnet as the source hosts. End hosts are usually configured with a single default gateway IP address when the network topology changes. The local device cannot send packets off the local network segment if the default gateway is not reached. There is no dynamic method by which end hosts can determine the address of a new default gateway, even if there is a redundant router that may serve as the default gateway for that segment.
Related: Before you proceed, you may find the following useful:
- Data Center Topologies
- LISP Protocol
- Data Center Network Design
- ASA Failover
- LISP Hybrid Cloud
- LISP Control Plane
Active active data center | |
Increased dependence on East-West traffic | |
Clustered Applications | |
Multi-Tenancy | |
Business Continuity | |
Workload Mobility |
Back to Basics: Active-active Data Center Design Cisco.
At its core, an active active data center is based on fault tolerance, redundancy, and scalability principles. This means that the active data center should be designed to withstand any hardware or software failure, have multiple levels of data storage redundancy, and scale up or down as needed.
The data center also provides an additional layer of security. It is designed to protect data from unauthorized access and malicious attacks. It should also be able to detect and respond to any threats quickly and in a coordinated manner.
A comprehensive monitoring and management system is essential to ensure that the data center is functioning correctly. This system should be designed to track the data center’s performance, detect problems, and provide the necessary alerting mechanisms. It should also provide insights into how the data center operates so that any necessary changes can be made.
Cisco Validated Design
Cisco has validated this design, freely available on the Cisco site. In summary, they have tested a variety of combinations, such as VSS-VSS, VSS-vPV, and vPC-vPC, and validated the design with 200 Layer 2 VLANs and 100 SVIs or 1000 VLANs and 1000 SVI with static routing.
At the time of writing, the M series for the Nexus 7000 supports native encryption of Ethernet frames through the IEEE 802.1AE standard. This implementation uses Advanced Encryption Standard ( AES ) cipher and a 128-bit shared key.
1st Lab Guide: Cisco ACI
In the following lab guide, we demonstrate Cisco ACI. To extend Cisco ACI, we have different designs, such as multi-site and multi-pod. This type of design overcomes many challenges of raising a data center, which we will discuss in this post, such as extending layer 2 networks.
One crucial value of the Cisco ACI is the COOP database that maps endpoints in the network. The following screenshots show the synchronized COOP database across spines, even in different data centers. Notice that the bridge domain VNID is mapped to the MAC address. The COOP database is unique to the Cisco ACI.

The Challenge: Layer 2 is Weak.
The challenge of data center design is “Layer 2 is weak & IP is not mobile.” In the past, best practices recommended that networks from distinct data centers be connected through Layer 3 ( routing ), isolating the known Layer 2 turmoil. However, the business is driving the application requirements, changing the connectivity requirements between data centers. The need for an active data center has been driven by the following. It is generally recommended to have Layer 3 connections with path separation through Multi-VRF, P2P VLANs, or MPLS/VPN, along with a modular building block data center design.
Yet, some applications cannot function over a Layer 3 environment. For example, most geo clusters require Layer 2 adjacency between their nodes, whether for heartbeat and connection ( status and control synchronization ) state information or the requirement to share virtual IP.
MAC addresses to facilitate traffic handling in case of failure. However, some clustering products ( Veritas, Oracle RAC ) support communication over Layer 3 but are a minority and don’t represent the general case.
Defining active data centers
The term active-active refers to using at least two data centers where both can service an application at any time, so each functions as an active application site. The demand for active-active data center architecture is to accomplish seamless workload mobility and enable distributed applications along with the ability to pool and maximize resources.
We must first have active-active data center infrastructure for an active/active application setup. Remember that the network is just one key component of active/active data centers). An active-active DC can be divided into two halves from a pure network perspective:-
- Ingress Traffic – inbound traffic
- Egress Traffic – outbound traffic
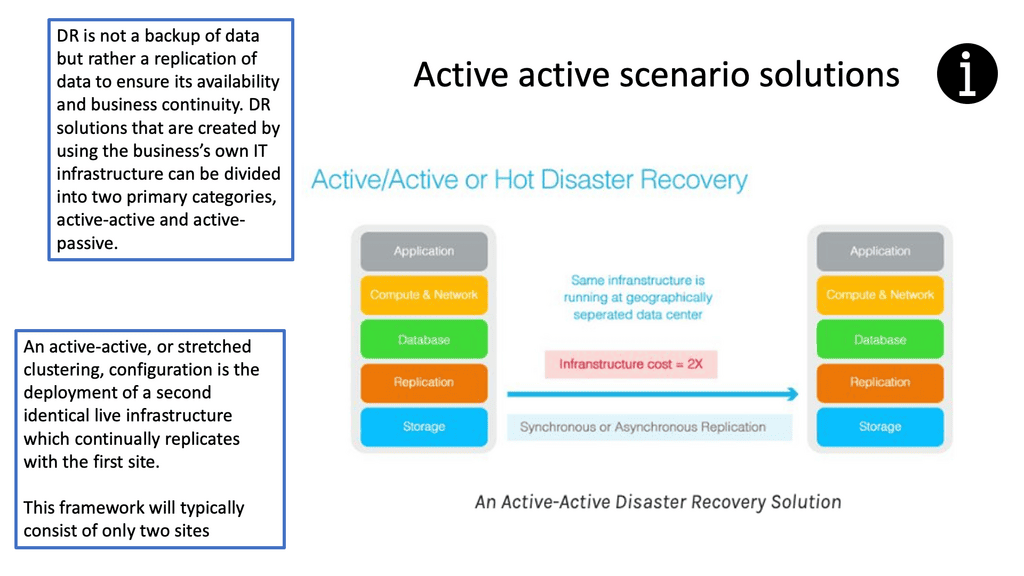
Active Active Data Center and VM Migration
Migrating applications and data to virtual machines (VMs) are becoming increasingly popular as organizations seek to reduce their IT costs and increase the efficiency of their services. VM migration moves existing applications, data, and other components from a physical server to a virtualized environment. This process is becoming increasingly more cost-effective and efficient for organizations, eliminating the need for additional hardware, software, and maintenance costs.
Virtual Machine migration between data centers increases application availability, Layer 2 network adjacency between ESX hosts is currently required, and a consistent LUN must be maintained for stateful migration. In other words, if the VM loses its IP address, it will lose its state, and the TCP sessions will drop, resulting in a cold migration ( VM does a reboot ) instead of a hot migration ( VM does not reboot ).
Due to the stretched VLAN requirement, data center architects started to deploy traditional Layer 2 over the DCI and, unsurprisingly, were faced with exciting results. Although flooding and broadcasts are necessary for IP communication in Ethernet networks, they can become dangerous in a DCI environment.
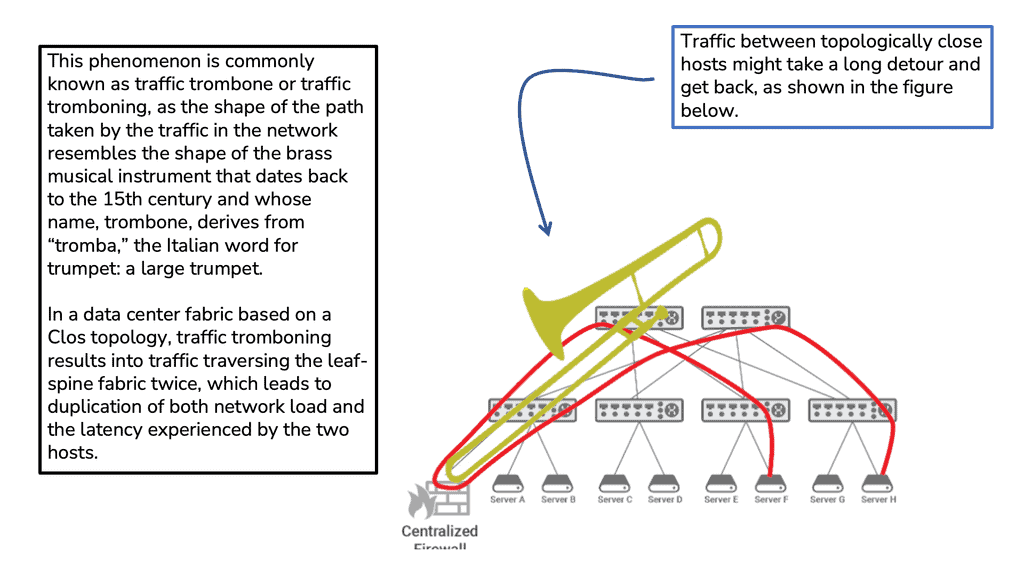
Traffic Tramboning
Traffic tromboning can also be formed between two stretched data centers, so nonoptimal internal routing happens within extended VLANs. Trombones, by their very nature, create a network traffic scalability problem. Addressing this through load balancing among multiple trombones is challenging since their services are often stateful.
Traffic tromboning can affect either ingress or egress traffic. On egress, you can have FHRP filtering to isolate the HSRP partnership and provide an active/active setup for HSRP. On ingress, you can have GSLB, Route Injection, and LISP.
Cisco Active-active data center design and virtualization technologies
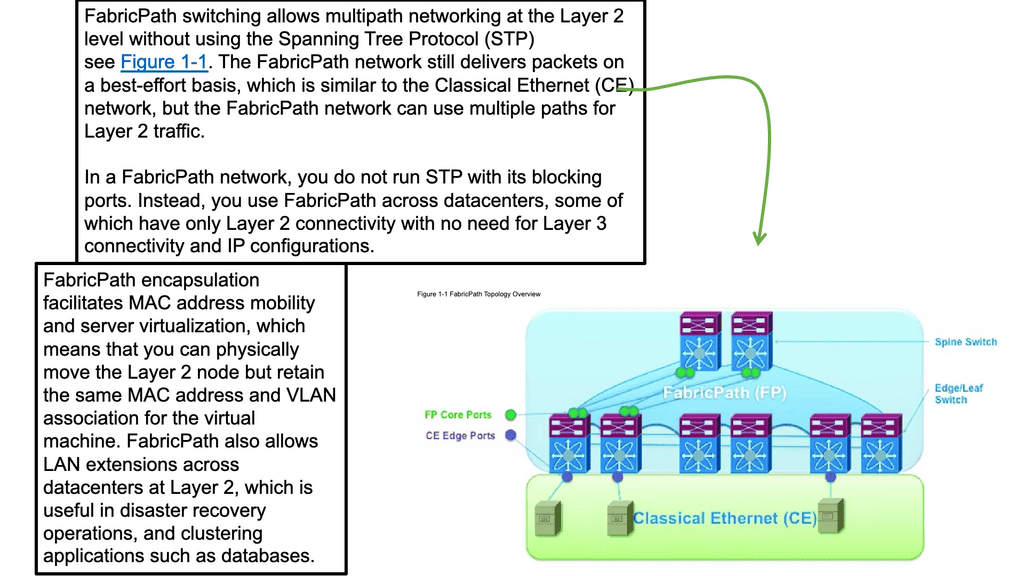
Virtualization technologies can be used for Layer 2 extensions between data centers to overcome many of these problems. They include vPC, VSS, Cisco FabricPath, VPLS, OTV, and LISP with its Internet locator design. In summary, different technologies can be used for LAN extensions, and the primary mediums in which they can be deployed are Ethernet, MPLS, and IP.
- Ethernet: VSS and vPC or Fabric Path
- MLS: EoMPLS and A-VPLS and H-VPLS
- IP: OTV
- LISP
Ethernet Extensions and Multi-Chassis EtherChannel ( MEC )
It requires protected DWDM or direct fibers and works only between two data centers. It cannot support multi-datacenter topology, i.e., a full mesh of data centers, but can help hub and spoke topologies.
Previously, LAG could only terminate on one physical switch. Both VSS-MEC and vPC are port-channeling concepts that extend link aggregation to two separate physical switches. This allows for creating L2 typologies based on link aggregation, eliminating the dependency on STP, and thus enabling you to scale available Layer 2 bandwidth by bonding the physical links.
Because vPC and VSS create a single connection from an STP perspective, disjoint STP instances can be deployed in each data center. Such isolation can be achieved with BPDU Filtering on the DCI links or Multiple Spanning Tree ( MST ) regions on each site.
At the time of writing, vPC does not support Layer 3 peering, but if you want an L3 link, create one, as this does not need to run on dark fiber or protected DWDM, unlike the extended Layer 2 links.
Ethernet Extension and Fabric path
The fabric path allows network operators to design and implement a scalable Layer 2 fabric, allowing VLANs to help reduce the physical constraints on server location. It provides a high-availability design with up to 16 active paths at layer 2, with each path a 16-member port channel for Unicast and Multicast.
This enables the MSDC networks to have flat typologies, separating nodes by a single hop ( equidistant endpoints ). Cisco has not targeted Fabric Path as a primary DCI solution as it does not have specific DCI functions compared to OTV and VPLS.
Its primary purpose is for Clos-based architectures. But if you need to interconnect 3 or more sites, the Fabric path is a valid solution when you have short distances between your DCs via high-quality point-to-point optical transmission links.
Your WAN links must support Remote Port Shutdown and microflapping protection. By default, OTV and VPLS should be the first solutions considered as they are Cisco-validated designs with specific DCI features, e.g., OTV can flood unknown unicast for particular VLANs.
IP Core with Overlay Transport Virtualization ( OTV ).
OTV provides dynamic encapsulation with multipoint connectivity of up to 10 sites ( NX-OS 5.2 supports 6 sites, and NX-OS 6.2 supports 10 sites ). OTV, also known as Over-The-Top virtualization, is a specific DCI technology that enables Layer 2 extension across data center sites by employing a MAC in IP encapsulation with built-in loop prevention and failure boundary preservation.
There is no data plane learning. Instead, the overlay control plane ( Layer 2 IS-IS ) on the provider’s network facilitates all unicast and multicast learning between sites. OTV has been supported on the Nexus 7000 since the 5.0 NXOS Release and ASR 1000 since the 3.5 XE Release. OTV as a DCI has robust high availability, and most failures can be sub-sec convergence with only extreme and very unlikely failures such as device down resulting in <5 seconds.
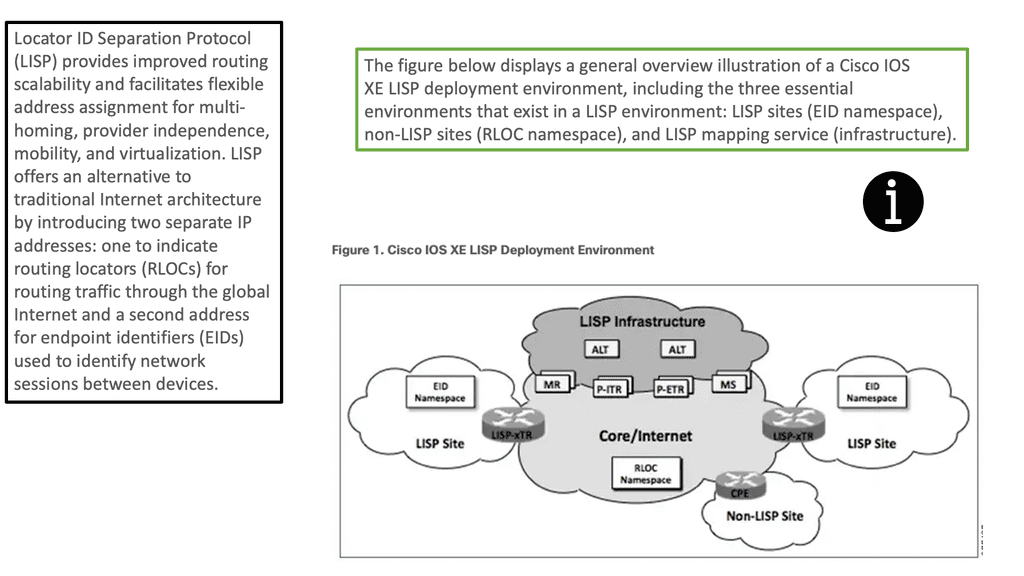
Locator ID/Separator Protocol ( LISP)
Locator ID/Separator Protocol ( LISP) has many applications. As the name suggests, it separates the location and identifier of the network hosts, making it possible for VMs to move across subnet boundaries while still retaining their IP address and enabling advanced triangular routing designs.
LISP works well when you have to move workloads and distribute workloads across data centers, making it a perfect complementary technology for an active-active data center design. It provides you with the following:
- a) Global IP mobility across subnets for disaster recovery and cloud bursting ( without LAN extension ) and optimized routing across extended subnet sites.
- b) Routing with extended subnets for active/active data centers and distributed clusters ( with LAN extension).
LISP answers the problems with ingress and egress traffic tromboning. It has a location mapping table, so when a host move is detected, updates are automatically triggered, and ingress routers (ITRs or PITRs) send traffic to the new location. From an ingress path flow inbound on the WAN perspective, LISP can answer our little problems with BGP in controlling ingress flows. Without LISP, we are limited to specific route filtering, meaning if you have a PI Prefix consisting of a /16.
If you break this up and advertise into 4 x /18, you may still get poor ingress load balancing on your DC WAN links; even if you were to break this up to 8 x /19, the results might still be unfavorable.
LISP works differently than BGP because a LISP proxy provider would advertise this /16 for you ( you don’t advertise the /16 from your DC WAN links ) and send traffic at 50:50 to our DC WAN links. LISP can get a near-perfect 50:50 conversion rate at the DC edge.
Benefits of Active-Active Data Center Design:
1. Enhanced Redundancy: With active-active design, organizations can achieve higher levels of redundancy by distributing the workload across multiple data centers. This redundancy ensures that even if one data center experiences a failure or maintenance downtime, the other data center seamlessly takes over, minimizing the impact on business operations.
2. Improved Performance and Scalability: Active-active design enables organizations to scale their infrastructure horizontally by distributing the load across multiple data centers. This approach ensures that the workload is evenly distributed, preventing any single data center from becoming a performance bottleneck. It also allows businesses to accommodate increasing demands without compromising performance or user experience.
3. Reduced Downtime: The active-active design significantly reduces the risk of downtime compared to traditional architectures. In the event of a failure, the workload can be immediately shifted to the remaining active data center, ensuring continuous availability of critical services. This approach minimizes the impact on end-users and helps organizations maintain their reputation for reliability.
4. Disaster Recovery Capabilities: Active-active data center design provides a robust disaster recovery solution. By having multiple geographically distributed data centers, organizations can ensure that their critical systems and applications remain operational despite a catastrophic failure at one location. This design approach minimizes the risk of data loss and provides a seamless failover mechanism.
Implementation Considerations:
Implementing an active-active data center design requires careful planning and consideration of various factors. Here are some key considerations:
1. Network Design: A robust and resilient network infrastructure is crucial for active-active data center design. Implementing load balancers, redundant network links, and dynamic routing protocols can help ensure seamless failover and optimal traffic distribution.
2. Data Synchronization: Organizations need to implement effective data synchronization mechanisms to maintain data consistency across multiple data centers. This may involve deploying real-time replication, distributed databases, or file synchronization protocols.
3. Application Design: Applications must be designed to be aware of the active-active architecture. They should be able to distribute the workload across multiple data centers and seamlessly switch between them in case of failure. Application-level load balancing and session management become critical in this context.
Active-active data center design offers organizations a robust solution for high availability and fault tolerance. Businesses can ensure uninterrupted access to critical systems and applications by distributing the workload across multiple data centers. The enhanced redundancy, improved performance, reduced downtime, and disaster recovery capabilities make active-active design an ideal choice for organizations striving to provide seamless and reliable services in today’s digital landscape.