
Creating Redundancy with Network Virtualization
In network virtualization, multiple physical networks are consolidated and operated as single or numerous independent networks by combining their resources. A virtual network is created to deploy and manage network services, while the hardware-based physical network only forwards packets. Network virtualization abstracts network resources traditionally delivered as hardware into software.
Overlay Network Protocols: Abstracting the data center
Modern virtualized data center fabrics must meet specific requirements to accelerate application deployment and support DevOps. To support multitenant support on shared physical infrastructure, fabrics must support scaling of forwarding tables, network segments, extended Layer 2 segments, virtual device mobility, forwarding path optimization, and virtualized networks. To achieve these requirements, overlay network protocols such as NVGRE, Cisco OTV, and VXLAN are used. To begin, let’s define underlay and overlay to understand various overlay protocols better.
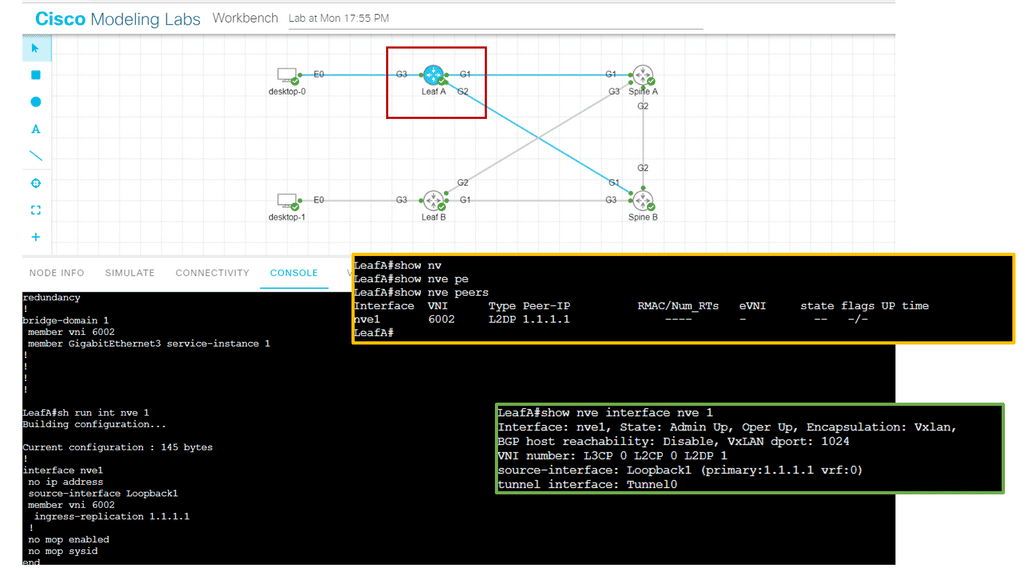
The underlay network is the physical infrastructure for an overlay network. It delivers packets as part of the underlying network across networks. Physical underlay networks provide unicast IP connectivity between any physical devices (servers, storage devices, routers, switches) in data center environments. However, technology limitations make underlay networks less scalable.
With network overlays, applications that demand specific network topologies can be deployed without modifying the underlying network. Overlays are virtual networks of interconnected nodes sharing a physical network. Multiple overlay networks can coexist simultaneously.
Note: Blog Series
This blog discusses the tail of active-active data centers and data center failover. The first blog focuses on the GTM Load Balancer and introduces failover challenges. The 3rd addresses Data Center Failure, focusing on the challenges and best practices for Storage. Much of this post addresses database challenges; the third is storage best practices; the final post will focus on ingress and egress traffic flows.
Database Management Series
A Database Management System (DBMS) is a software application that interacts with users and other applications. It sits behind other elements known as “middleware” between the application and storage tier. It connects software components. Not all environments use databases; some store data in files, such as MS Excel. Also, data processing is not always done via query languages. For example, Hadoop has a framework to access data stored in files. Popular DBMS include MySQL, Oracle, PostgreSQL, Sybase, and IBM DB2. Database storage differs depending on the needs of a system.
Related: Before you proceed, you may find the following posts helpful:
- DNS Security Solutions
- DNS Security Designs
- ASA Failover
- DNS Reflection Attack
- Network Security Components
- Dropped Packet Test
Data Center Failover. |
|
Back to Basics: Data Center Failover
Why is Data Center Failover Crucial?
1. Minimizing Downtime: Downtime can have severe consequences for businesses, leading to revenue loss, decreased productivity, and damaged customer trust. Failover mechanisms enable organizations to reduce downtime by quickly redirecting traffic and operations to a secondary data center.
2. Ensuring High Availability: Providing uninterrupted services is crucial for businesses, especially those operating in sectors where downtime can have severe implications, such as finance, healthcare, and e-commerce. Failover mechanisms ensure high availability by swiftly transferring operations to a secondary data center, minimizing service disruptions.
3. Preventing Data Loss: Data loss can be catastrophic for businesses, leading to financial and reputational damage. By implementing failover systems, organizations can replicate and synchronize data across multiple data centers, ensuring that in the event of a failure, data remains intact and accessible.
How Does Data Center Failover Work?
Datacenter failover involves several components and processes that work together to ensure smooth transitions during an outage:
1. Redundant Infrastructure: Failover mechanisms rely on redundant hardware, power systems, networking equipment, and storage devices. Redundancy ensures that if one component fails, another can seamlessly take over to maintain operations.
2. Automatic Detection: Monitoring systems constantly monitor the health and performance of the primary data center. In the event of a failure, these systems automatically detect the issue and trigger the failover process.
3. Traffic Redirection: Failover mechanisms redirect traffic from the primary data center to the secondary one. This redirection can be achieved through DNS changes, load balancers, or routing protocols. The goal is to ensure that users and applications experience minimal disruption during the transition.
4. Data Replication and Synchronization: Data replication and synchronization are crucial in data center failover. By replicating data across multiple data centers in real-time, organizations can ensure that data is readily available in case of a failover. Synchronization ensures that data remains consistent across all data centers.
What does a DBMS provide for applications?
It provides a means to access massive amounts of persistent data. Databases handle terabytes of data every day, usually much larger than what can fit into the memory of a standard O/S system. The size of the data and the number of connections mean that the database’s performance directly affects application performance. Databases carry out thousands of complex queries per second over terabytes of data.
The data is often persistent, meaning the data on the database system outlives the period of application execution. The data does not go away and sits. After that, the program stops running. Many users or applications access data concurrently, and measures are in place so concurrent users do not overwrite data. These measures are known as concurrency controls. They ensure correct results for simultaneous operations. Concurrency controls do not mean exclusive access to the database. The control occurs on data items, allowing many users to access the database but accessing different data items.
Example Technology: Cisco Overlay Transport Virtualization
OTV (Cisco Overlay Transport Virtualization) is a MAC-in-IP method for extending Layer 2 LANs and Multiprotocol Label Switching networks. Through MAC address-based routing and IP-encapsulated forwarding across a transport network, OTV provides Layer 2 connectivity between remote network sites for applications such as clusters and virtualization that need Layer 2 adjacency. Each site deploys OTV on its edge devices. Neither the sites nor the transport network need to be modified for OTV.
OTV builds Layer 2 reachability information between edge devices through the overlay protocol. All edge devices are connected through the overlay protocol. Once a device is adjacent to all other edge devices, its MAC address reachability information is shared with other edge devices on the same overlay network.
Multicast is preferred for communicating with multiple sites because of its flexibility and lower overhead. To encapsulate and exchange OTV control-plane protocol updates, one multicast address is used (the control-group address). All edge devices in the overlay network share the same control group address. As soon as the control-group address and the join interface are configured, the edge device sends an IGMP report message to join the control group.
Data Center Failover and Database Concepts
The Data Model refers to how the data is stored in the database. Several options exist, such as the relational data model, which is a set of records. Also available is stored in XML, a hierarchical structure of labeled values. Finally, another solution includes a graph model where nodes represent all data.
The Schema sets up the structure of the database. You have to structure the data before you build the application. The database designers are the ones who establish the Schema for the database. All data is stored within the Schema.
The Schema doesn’t change much, but data changes quickly and constantly. The Data Definition Language (DDL) sets up the Schema. It’s a standard of commands that define different data structures. Once the Schema is set up and the data is loaded, you start the query process and modify the data. This is done with the Data Manipulation Language (DML). DML statements are used to retrieve and work with data.
The SQL query language
The SQL query language is a standardized language based on relational algebra. It is a programming language used to manage data in a relational database and is supported by all major database systems. The SQL query engages with the database Query optimizer, which takes SQL queries and determines the optimum way to execute them on the database.
The language has two parts – the Data Definition Language (DDL) and a Data Manipulation Language (DML). DDL creates and drops tables, and the DML (already mentioned) is used to query and modify the database with Select, Insert, Delete, and update statements. The Select statement is the most commonly used and performs the database query.
Database Challenges
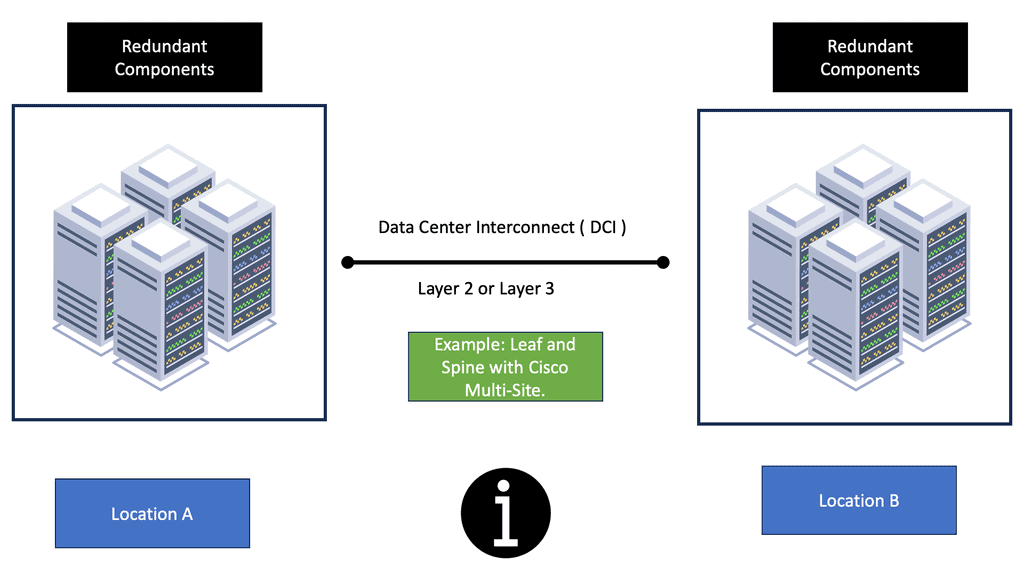
The database design and failover appetite is a business and non-technical decision. First, the company must decide on values acceptable to RTO (recovery time objective) and RPO (recovery point objective). How accurate do you want your data, and how long can a client application be in the read-only state? There are three main options a) Distributed databases with two-phase commit, b) Log shipping c) Read-only and read-write with synchronous replication.
With distributed databases and a two-phase commit, you have multiple synchronized copies of the database. It’s very complex, and latency can be a real problem affecting application performance. Many people don’t use this and go for log shipping instead. Log shipping maintains a separate copy of the database on the standby server.
Two copies of a single database on different computers or the same computer with separate instances, primary and secondary databases. Only one copy is available at any given time. Any changes to the primary databases are log shipped or propagated to the other database copy.
Some environments have a 3rd instance, known as a monitor server. A monitor server records history, checks status, and tracks details of log shipping. A drawback to log shipping is that it has a non-zero RPO. It may be that a transaction was written just before the failure and, as a result, will be lost. Therefore, log shipping cannot guarantee zero data loss. An enhancement to log shipping is read-only and read-write copies of the database with synchronous replication between the two. With this method, there is no data loss, and it’s not as complicated as distributed databases with two-phase commit.
Data Center Failover Solution
If you have a transaction database and all the data is in one data center, you will have a problem with latency between the write database and the database client when you start the VM in the other DC. There is not much you can do about latency but shorten the link. Some believe that WAN optimization will decrease latency, but many solutions will add.
How well-written the application is will determine how badly the VM is affected. With very severely written applications, a few milliseconds can destroy performance. How quickly can you send SQL queries across the WAN link? How many queries per transaction does the application do? Poorly written applications require transactions encompassing many queries.
Multiple application stacks
A better approach would be to use multiple application stacks in different data centers. Load balancing can then be used to forward traffic to each instance. It is better to have various application stacks ( known as swim lanes ) that are entirely independent. Multiple instances on the same application allow you to take offline an instance without affecting others.
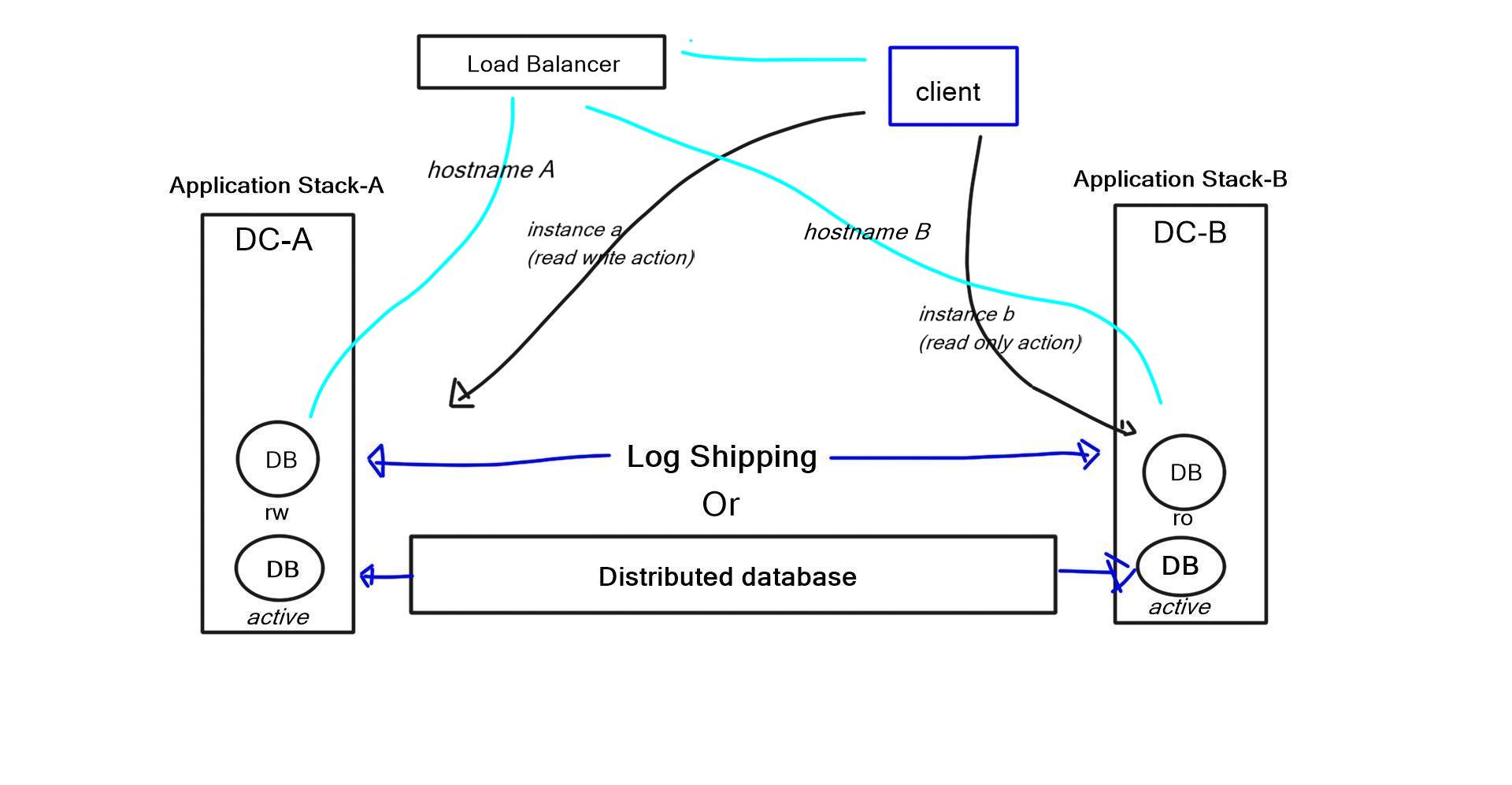
A better approach is to have a single database server and ship the changes to the read-only database server. With the example of a two-application stack, one of the application stacks is read-only and eventually consistent, and the other is read-write. So if the client needs to make a change, for example, submit an order, how do you do this from the read-only data center? There are several ways to do this.
One way is with the client software. The application knows the transaction, uses a different hostname, and redirects requests to the read-write database. The hostname request can be used with a load balancer to redirect queries to the correct database. Another method is having applications with two database instances – read-only and read-write. So, every transaction will know if it’s read-only or read-write and will use the appropriate database instance. For example, carrying out a purchase would trigger the read-write instance, and browsing products would trigger read-only.
Most things we do are eventually consistent at a user’s face level. If you buy something online, even in the shopping cart, it’s not guaranteed until you select the buy button. Exceptions that are not fulfilled are made manually by sending the user an email.
Closing Points: Data Center Failover
Datacenter failover is a vital component of modern business operations. By implementing failover mechanisms, organizations can minimize downtime, ensure high availability, and prevent data loss. With the increasing reliance on digital infrastructure, investing in robust failover systems has become necessary for businesses aiming to provide uninterrupted services and maintain a competitive edge in today’s rapidly evolving digital landscape.